Command Palette
Search for a command to run...
Innovative Input-/Output-Technologie! Tencent Hunyuan Präsentiert HunyuanWorld-Mirror – Eine Revolutionäre 3D-Rekonstruktion, Die Netflix-Inhalte in Ihrer Ganzen Pracht Erschließt! Der Netflix-Film- Und Fernsehkatalog Liefert Wertvolle Einblicke in Entertainment-Trends.

Das Erlernen visueller Geometrie ist ein Kernthema der Computer Vision und findet breite Anwendung in Augmented Reality, Robotermanipulation und autonomer Navigation. Traditionelle Methoden wie Structure-of-Motion (SfM) und Multi-View-Stereo-Verfahren basieren typischerweise auf iterativer Optimierung, was zu hohen Rechenkosten führt.In den letzten Jahren hat sich das Gebiet schrittweise in Richtung durchgängiger Geometrie-Rekonstruktionsmodelle auf Basis von Feedforward-Neuronalen Netzen verlagert.
Trotz der beachtlichen Erfolge weisen die bestehenden Methoden nach wie vor deutliche Einschränkungen sowohl in der Eingabe- als auch in der Ausgabedimension auf.Auf der Eingabeseite kann das aktuelle Modell nicht auf leicht verfügbare Vorinformationen wie Kameraparameter, Ausgangsposition und Sensortiefe zurückgreifen, da es nur das Rohbild verarbeitet.Dies führt zu unzureichenden Ergebnissen bei Problemen wie Skalenunsicherheit, Inkonsistenzen zwischen verschiedenen Blickwinkeln und texturlosen Bereichen. Bestehende Methoden beschränken sich hinsichtlich der Ausgabe meist auf einzelne oder wenige geometrische Aufgaben (wie Tiefen- oder Lagebestimmung) und weisen eine hohe Spezialisierung sowie mangelnde Integration auf. Obwohl Forschungsarbeiten wie VGGT die Vereinheitlichung von Aufgaben vorangetrieben haben, sind grundlegende Aufgaben wie die Schätzung von Oberflächennormalen und die Synthese neuer Blickwinkel noch nicht in ein einheitliches Framework integriert.
Die zuvor genannten Einschränkungen werfen eine Schlüsselfrage auf: Ist es möglich, sowohl Input- als auch Output-Herausforderungen gleichzeitig innerhalb eines allgemeinen 3D-Rekonstruktionsrahmens anzugehen, indem verschiedene Vorinformationen effektiv einbezogen werden?
Auf dieser GrundlageDas Hunyuan-Team von Tencent hat HunyuanWorld-Mirror auf den Markt gebracht, ein vollständig integriertes Feedforward-Modell für vielseitige 3D-Geometrievorhersageaufgaben, das darauf ausgelegt ist, jegliches verfügbare geometrische Vorwissen zu nutzen, um allgemeine 3D-Rekonstruktionsaufgaben durchzuführen.Kern des Modells ist ein neuartiger multimodaler Mechanismus zur Einbindung von Vorinformationen. Dieser integriert flexibel verschiedene geometrische Vorinformationen, darunter Kameraposition, intrinsische Parameter und Tiefenkarten, und generiert gleichzeitig mehrere 3D-Repräsentationen: dichte Punktwolken, Tiefenkarten aus verschiedenen Perspektiven, Kameraparameter, Oberflächennormalen und 3D-Gaußverteilungen. Diese einheitliche Architektur nutzt verfügbare Vorinformationen, um strukturelle Mehrdeutigkeiten aufzulösen und liefert in einem einzigen Feedforward-Prozess geometrisch konsistente 3D-Ausgabe.
HunyuanWorld-Mirror nutzt vorhandene Vorinformationen, um eine robuste Rekonstruktion in anspruchsvollen Szenarien zu ermöglichen, und sein Multi-Task-Design gewährleistet geometrische Konsistenz über verschiedene Ausgaben hinweg.Bei einer Vielzahl von Benchmarks wurden Spitzenleistungen erzielt, von Kamera-, Punktkarten-, Tiefen- und Oberflächennormalenschätzung bis hin zur Synthese neuer Perspektiven.
Auf der HyperAI-Website findet ihr jetzt „HunyuanWorld-Mirror: Ein 3D-Weltgenerierungsmodell“. Schaut doch mal vorbei und probiert es aus!
Online-Nutzung:https://go.hyper.ai/Ptv69
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 24. bis 28. November:
* Hochwertige öffentliche Datensätze: 7
* Hochwertige Tutorial-Auswahl: 6
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefristen im Dezember: 2
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
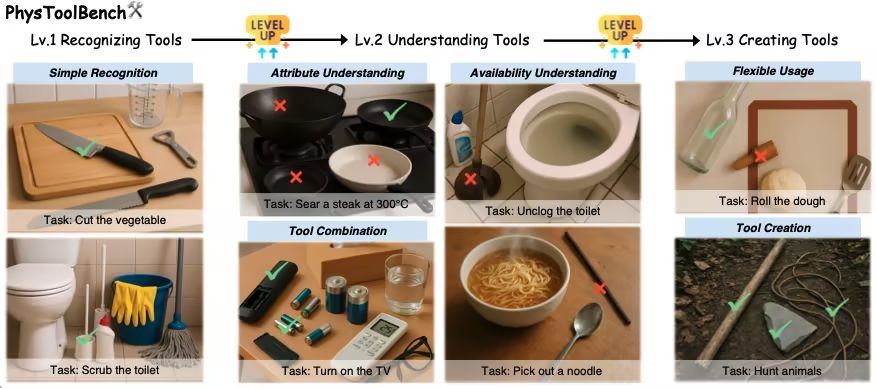
1. PhysToolBench Physik-Tool-Aufgabendatensatz
PhysToolBench ist ein Datensatz für visuelle Sprach-Frage-Antwort-Systeme (VQA), der von der Hong Kong University of Science and Technology (Guangzhou) in Zusammenarbeit mit der Hong Kong University of Science and Technology, der Beijing University of Aeronautics and Astronautics und weiteren Institutionen veröffentlicht wurde. Ziel ist die Evaluierung der Fähigkeit multimodaler großer Sprachmodelle (MLLMs), physische Werkzeuge zu erkennen, zu verstehen und zu erstellen. Der Datensatz umfasst über 1.000 Bild-Text-Paare aus verschiedenen Anwendungsbereichen wie Alltag, Industrie, Outdoor-Aktivitäten und Berufsleben.
Direkte Verwendung:https://go.hyper.ai/bP9Ad
2. CytoData-Datensatz für Blutzellbilder
Der CytoData-Datensatz mit Blutzellbildern ist ein anonymisierter Datensatz, der von einem Forschungsteam der Universität Cambridge (UK) in Nature veröffentlicht wurde. Er umfasst 2.904 Blutausstriche aus dem Addenbrooke’s Hospital in Cambridge mit insgesamt 559.808 Einzelzellbildern. Davon sind 4.996 Bilder mit zehn verschiedenen Blutzelltypen, darunter Erythroblasten und Eosinophile, gekennzeichnet.
Direkte Verwendung:https://go.hyper.ai/uLXKt
3. MeshCoder: Strukturierter 3D-Objektcode-Datensatz
MeshCoder ist ein multimodaler Datensatz zur Generierung editierbaren Codes aus 3D-Punktwolken. Er wurde vom Shanghai Artificial Intelligence Laboratory in Zusammenarbeit mit der Tsinghua-Universität, dem Harbin Institute of Technology (Shenzhen) und weiteren Institutionen veröffentlicht. Ziel ist die Förderung der Entwicklung großer Sprachmodelle für die 3D-Szenenanalyse, das Strukturverständnis und die programmierbare geometrische Rekonstruktion.
Direkte Verwendung:https://go.hyper.ai/x3zvv
4. Netflix-Film- und Fernsehkatalog-Datensatz
Der Netflix-Katalogdatensatz für Filme und Serien ist ein umfassender Katalog, der verschiedene Film- und Fernsehformate aus zahlreichen Ländern weltweit abdeckt. Er dient dazu, die gesamte Inhaltsverteilung auf der Netflix-Plattform darzustellen und Daten für die Forschung zu Unterhaltungstrends, Publikumspräferenzen und Content-Strategien bereitzustellen. Dieser Datensatz enthält Einträge für Filme und Serien, die bereits auf Netflix verfügbar sind. Jeder Eintrag repräsentiert einen Titel und enthält wichtige Informationen wie Titel, Inhaltstyp (Film oder Serie) und Regisseur.
Direkte Verwendung:https://go.hyper.ai/8gzcZ
5. InteractMove 3D Scene Human-Object Interaction Dataset
InteractMove ist ein Datensatz zur Generierung von Mensch-Objekt-Interaktionen in 3D-Szenen. Er wurde gemeinsam vom Institut für Informatik und Technologie der Peking-Universität und dem Pekinger Institut für Elektronische Wissenschaft und Technologie veröffentlicht. Ziel ist die Unterstützung und Förderung der Forschung zur textbasierten, steuerungsbasierten interaktiven Modellierung beweglicher Objekte. Der Datensatz umfasst verschiedene Arten beweglicher Objekte und diverse gescannte Szenen aus der realen Welt und bietet exakt auf die jeweilige Szene abgestimmte Aktionssequenzen für die Mensch-Objekt-Interaktion.
Direkte Verwendung:https://go.hyper.ai/uFrPd
6. Trainingsdatensatz für die GroundCUA-Schnittstellenbedienung
GroundCUA ist ein Datensatz realer Benutzeroberflächen (UI), der vom Mila Quebec Artificial Intelligence Institute in Zusammenarbeit mit der McGill University, der Universität Montreal und weiteren Institutionen veröffentlicht wurde. Er dient der Unterstützung der Forschung an multimodalen intelligenten Agenten, die mit Computern interagieren können. Der Datensatz basiert auf Demonstrationen von Experten und umfasst über 3,56 Millionen manuell verifizierte Annotationen auf Elementebene.
Direkte Verwendung:https://go.hyper.ai/5bDrX
7. Camera Clone Multi-view Dataset
Camera Clone, ein von der Universität Hongkong in Zusammenarbeit mit der Zhejiang-Universität, Kuaishou Technology und weiteren Institutionen entwickelter, umfangreicher Datensatz synthetischer Videos, basiert auf dem Rendering der Unreal Engine 5. Er dient der Unterstützung des Lernens von Kameraklonen, das die Kamerabewegung eines Referenzvideos nachbildet, während der Szeneninhalt unverändert bleibt, und so eine „Inhaltswiedergabe + Anpassung der Kamerabewegung“ ermöglicht.
Direkte Verwendung:https://go.hyper.ai/US4nY
Ausgewählte öffentliche Tutorials
1. Offizielles PyTorch-Tutorial: Deep Learning mit PyTorch implementieren
Ziel dieses Tutorials ist es, zu verstehen, wie man Tensoren verwendet und neuronale Netze in PyTorch erstellt, und ein kleines neuronales Netz zu trainieren, um Bilder zu klassifizieren.
Online ausführen:https://go.hyper.ai/Fb2c6
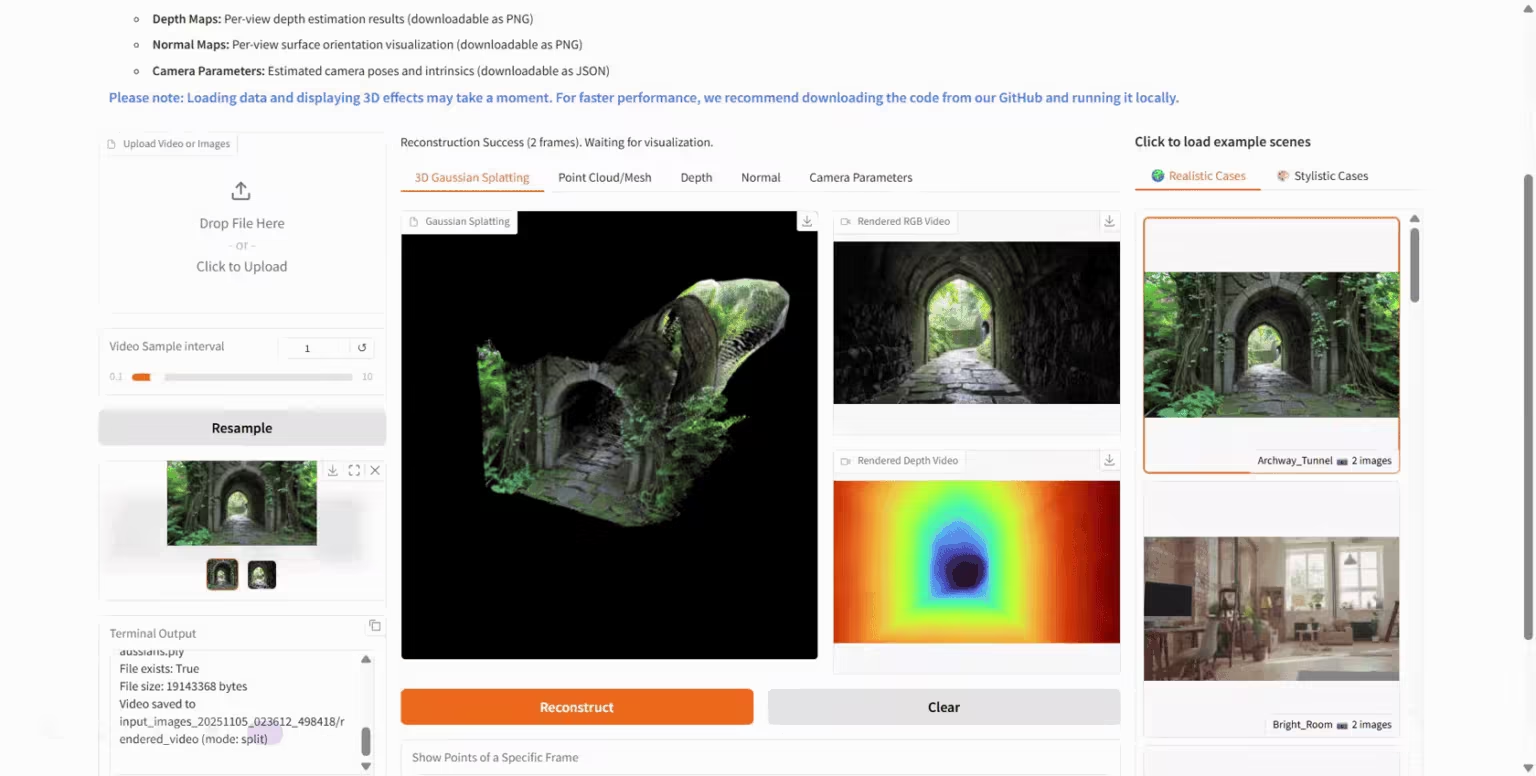
2. HunyuanWorld-Mirror: Ein 3D-Weltgenerierungsmodell
HunyuanWorld-Mirror ist ein Open-Source-Modell zur Generierung von 3D-Welten, das vom Hunyuan-Team von Tencent entwickelt wurde. Es unterstützt verschiedene Eingabemethoden, darunter Bilder und Videos aus mehreren Perspektiven, und kann diverse 3D-Geometrievorhersagen ausgeben, beispielsweise Punktwolken, Tiefenkarten und Kameraparameter. Das Modell verwendet eine reine Feedforward-Architektur, kann auf einer einzelnen Grafikkarte ausgeführt werden und verarbeitet 8 bis 32 Ansichtseingaben lokal in nur einer Sekunde, wodurch eine Inferenz zweiter Ordnung erreicht wird.
Online ausführen:https://go.hyper.ai/Ptv69
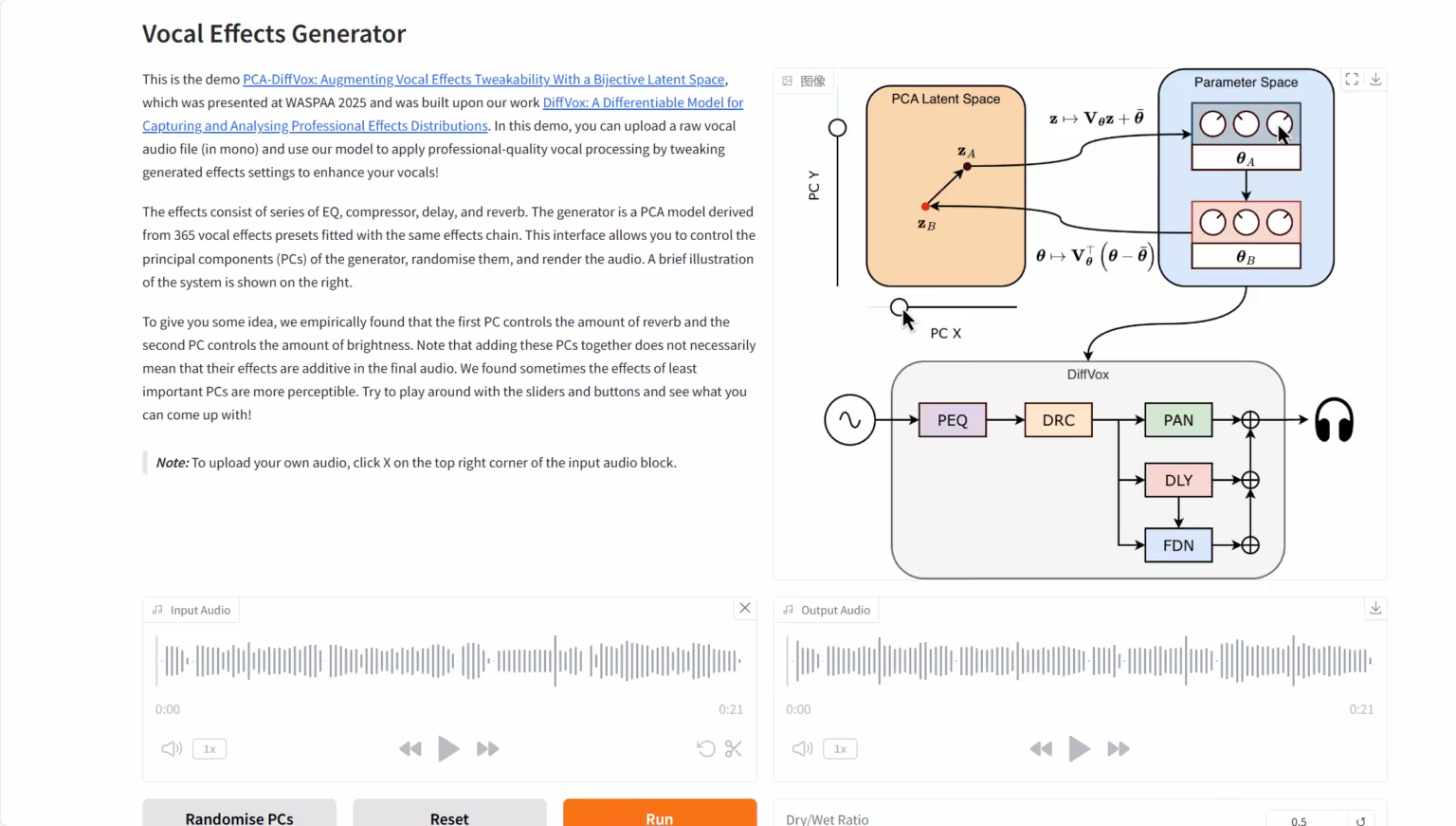
3. DiffVox: Modell zur Klangdifferenzierung
Das DiffVox-Projekt wurde gemeinsam von Sony AI, der Sony Group und einem Forschungsteam der Queen Mary University of London ins Leben gerufen. Die Kernkompetenz dieses Modells liegt in der Anwendung fortschrittlicher Methoden zur Optimierung der Inferenzzeit und der innovativen Einführung von Gaußschen Prior-Beschränkungen. Dadurch kann es eine rohe menschliche Sprachaufnahme intelligent in hochwertiges Audio umwandeln, das dem Zielreferenzwert hörbar nahe kommt und hinsichtlich der Parameter professionelle Mixing-Standards erfüllt.
Online ausführen:https://go.hyper.ai/Y19Wv
4. Bereitstellung des SmolLM3-3B-Modells mit einem Klick
SmolLM3-3B, veröffentlicht vom Hugging Face TB (Transformer Big) Team, positioniert sich als „Grenze der Edge-Performance“. Es handelt sich um ein revolutionäres Open-Source-Sprachmodell mit 3 Milliarden Parametern, das darauf abzielt, die Leistungsgrenzen kleiner Modelle in einer kompakten Größe von 3 Milliarden Parametern zu durchbrechen.
Online ausführen:https://go.hyper.ai/wZ48d
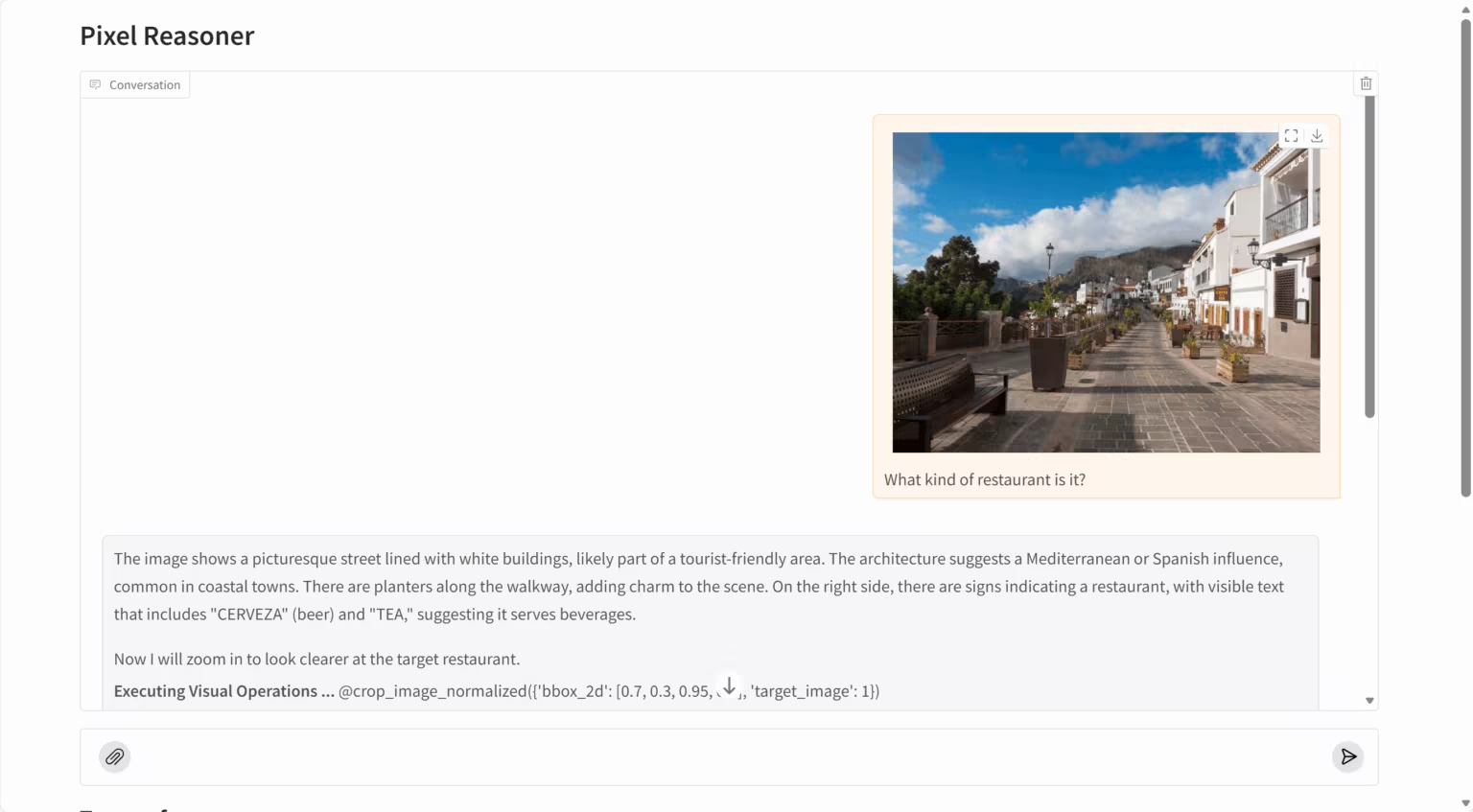
5. PixelReasoner-RL: Visuelles Inferenzmodell auf Pixelebene
PixelReasoner-RL-v1 ist ein bahnbrechendes visuelles Sprachmodell des TIGER AI Lab. Basierend auf der Qwen2.5-VL-Architektur nutzt das Projekt ein innovatives, neugiergetriebenes Reinforcement-Learning-Trainingsverfahren, um die Einschränkungen traditioneller visueller Sprachmodelle, die ausschließlich auf textbasiertem Schließen beruhen, zu überwinden. Das Modell kann direkt im Pixelraum schlussfolgern und unterstützt visuelle Operationen wie Skalierung und Frame-Auswahl. Dadurch wird sein Verständnis von Bilddetails, räumlichen Beziehungen und Videoinhalten deutlich verbessert.
Online ausführen:https://go.hyper.ai/t1rdr
6. Krea-realtime-video: Echtzeit-Videogenerierungsmodell
Krea Realtime 14B ist ein Echtzeit-Videogenerierungsmodell mit 14 Milliarden Parametern, das vom Krea-Team entwickelt wurde. Es ermöglicht die Generierung von längeren Videos in Echtzeit und ist eines der größten öffentlich verfügbaren Echtzeit-Videogenerierungsmodelle. Basierend auf dem Text-zu-Video-Modell Wan 2.1 14B nutzt dieses Modell selbstverstärkendes Destillationstraining, um das traditionelle Videodiffusionsmodell in eine autoregressive Struktur zu transformieren und so ein echtes Echtzeit-Videogenerierungserlebnis zu erzielen.
Online ausführen:https://go.hyper.ai/GS7oW

Die Zeitungsempfehlung dieser Woche
1. Allgemeines agentisches Gedächtnis durch Tiefenforschung
Diese Arbeit stellt ein neuartiges Framework namens General Agentic Memory (GAM) vor. GAM folgt dem Just-in-Time-Prinzip (JIT): Es speichert offline nur einfache, aber praktische Informationen und konzentriert sich zur Laufzeit auf die Erstellung optimierter Kontexte für seine Clients. Experimentelle Studien zeigen, dass GAM im Vergleich zu bestehenden Speichersystemen in verschiedenen Szenarien der speicherbasierten Aufgabenbearbeitung signifikante Leistungsverbesserungen erzielt.
Link zum Artikel:https://go.hyper.ai/sA1RN
2. ROOT: Robuster orthogonalisierter Optimierer für das Training neuronaler Netze
Diese Arbeit stellt ROOT vor, einen robusten, orthogonalisierten Optimierer, der die Trainingsstabilität durch einen dualen Robustheitsmechanismus deutlich verbessert. Umfangreiche experimentelle Ergebnisse zeigen, dass ROOT in verrauschten Umgebungen und nicht-konvexen Optimierungsszenarien eine signifikant höhere Robustheit aufweist. Im Vergleich zu Muon- und Adam-basierten Optimierern konvergiert er nicht nur schneller, sondern erzielt auch eine überlegene Endleistung.
Link zum Artikel:https://go.hyper.ai/gv0x2
3. GigaEvo: Ein Open-Source-Optimierungsframework basierend auf LLMs und Evolutionsalgorithmen
Dieser Artikel stellt GigaEvo vor, ein skalierbares Open-Source-Framework, das Forschende bei der Entwicklung und Erprobung hybrider LLM-evolutionärer Berechnungsmethoden, inspiriert von AlphaEvolve, unterstützt. Das GigaEvo-System bietet modulare Implementierungen mehrerer Kernkomponenten: den MAP-Elites-Algorithmus zur Qualitäts-Diversitäts-Analyse, eine asynchrone Auswertungspipeline basierend auf gerichteten azyklischen Graphen (DAGs), einen LLM-gesteuerten Mutationsoperator mit aussagekräftigen generativen Fähigkeiten sowie einen bidirektionalen Mechanismus zur Abstammungsverfolgung. Zudem unterstützt es flexible Multi-Insel-Evolutionsstrategien.
Link zum Artikel:https://go.hyper.ai/jN3Q1
4. SAM 3: Segmentieren Sie alles mit Konzepten
Diese Arbeit stellt das Segment Anything Model (SAM) 3 vor, ein einheitliches Modell zur Erkennung, Segmentierung und Verfolgung von Objekten in Bildern und Videos auf Basis von Konzeptvorgaben. SAM 3 erzielt die doppelte Genauigkeit bestehender Systeme bei Aufgaben der konzeptbasierten Objekterkennung (PCS) in Bildern und Videos und verbessert die Leistung vorheriger SAM-Generationen bei visuellen Segmentierungsaufgaben. SAM 3 ist nun Open Source, und mit Segment Anything with Concepts (SA-Co) wurde ein neuer Benchmark für die konzeptbasierte Segmentierung veröffentlicht.
Link zum Artikel:https://go.hyper.ai/KN3g7
5. OpenMMReasoner: Die Grenzen des multimodalen Denkens mit einem offenen und allgemeinen Ansatz erweitern
Diese Arbeit stellt OpenMMReasoner vor, ein vollständig transparentes, zweistufiges multimodales Inferenztrainingsverfahren, das überwachtes Feinabstimmen (SFT) und bestärkendes Lernen (RL) umfasst. In der SFT-Phase erstellten die Forscher einen Kaltstart-Datensatz mit 874.000 Beispielen und setzten einen strengen, schrittweisen Validierungsmechanismus ein, um eine solide Grundlage für die Inferenzfähigkeiten zu schaffen. Die darauffolgende RL-Phase nutzt einen Datensatz mit 74.000 Beispielen aus verschiedenen Domänen, um diese Fähigkeiten weiter zu stärken und zu stabilisieren und so einen robusteren und effizienteren Lernprozess zu erzielen.
Link zum Artikel:https://go.hyper.ai/OfXKY
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
1. Das erste multimodale astronomische Grundlagenmodell, AION-1, ist geboren! Die UC Berkeley und andere Institutionen haben erfolgreich ein verallgemeinertes multimodales astronomisches KI-Framework auf der Grundlage eines Vortrainings mit 200 Millionen astronomischen Objekten entwickelt.
Teams von über zehn Forschungseinrichtungen weltweit, darunter die University of California, Berkeley, die University of Cambridge und die University of Oxford, haben gemeinsam AION-1 entwickelt, die erste groß angelegte multimodale Modellfamilie für die Astronomie. Mithilfe eines einheitlichen, auf der frühen Fusion basierenden Kernnetzwerks integriert und modelliert sie heterogene Beobachtungsdaten wie Bilder, Spektren und Sternkatalogdaten. Sie erzielt nicht nur in Zero-Shot-Szenarien hervorragende Ergebnisse, sondern ihre lineare Detektionsgenauigkeit kann auch mit Modellen mithalten oder diese sogar übertreffen, die speziell für bestimmte Aufgaben trainiert wurden.
Den vollständigen Bericht ansehen:https://go.hyper.ai/2zA0f
2. Meituans Open-Source-Videogenerierungsmodell LongCat-Video verfügt über drei Hauptfunktionen: textbasierte Videogenerierung, bildbasierte Videogenerierung und Videofortsetzung, vergleichbar mit erstklassigen Open-Source- und Closed-Source-Modellen.
Meituan hat sein neuestes Videogenerierungsmodell LongCat-Video als Open Source veröffentlicht. Dieses Modell zielt darauf ab, verschiedene Videogenerierungsaufgaben mithilfe einer einheitlichen Architektur zu bewältigen, darunter Text-zu-Video, Bild-zu-Video und Videofortsetzung. Aufgrund seiner herausragenden Leistung bei allgemeinen Videogenerierungsaufgaben betrachtet das Forschungsteam LongCat-Video als einen wichtigen Schritt hin zum Aufbau eines echten „Weltmodells“.
Den vollständigen Bericht ansehen:https://go.hyper.ai/b6pzF
3. Kostenlose CPU-Nutzung / 30 Stunden GPU-Nutzungsguthaben / 70 GB extragroßer Speicherplatz: HyperAI Pro ist offiziell erschienen!
HyperAI hat Hunderte von Tutorials zum maschinellen Lernen zusammengestellt und in Jupyter Notebooks integriert. So können sowohl Anfänger als auch erfahrene Entwickler einfach auf hochwertige Open-Source-Projekte zugreifen oder völlig neue Modelle erstellen und einsetzen. HyperAI bietet stabile Rechenleistung, um KI-Projekte von der ersten Idee bis zur schnellen Implementierung zu begleiten. Um den Bedürfnissen seiner Nutzer noch besser gerecht zu werden und flexiblere sowie kostengünstigere Abrechnungsoptionen für Rechenleistung anzubieten, hat HyperAI offiziell sein HyperAI Pro-Mitgliedschaftssystem eingeführt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Oi7d3
4. Die Universität Cambridge entwickelt einen Bildklassifikator für Blutzellen; das Diffusionsmodell hilft bei der Leukämieerkennung und übertrifft die Fähigkeiten klinischer Experten.
Ein Forschungsteam der Universität Cambridge in Großbritannien hat CytoDiffusion entwickelt, eine Methode zur Klassifizierung von Blutzellbildern auf Basis eines Diffusionsmodells. Sie bildet die morphologische Verteilung der Blutzellen präzise ab und ermöglicht so eine genaue Klassifizierung. Gleichzeitig zeichnet sie sich durch eine hohe Anomalieerkennung, Robustheit gegenüber Verteilungsverschiebungen, Interpretierbarkeit, hohe Dateneffizienz und eine Unsicherheitsquantifizierung aus, die die Fähigkeiten klinischer Experten übertrifft.
Den vollständigen Bericht ansehen:https://go.hyper.ai/QSCmq
5. Der 72-jährige CEO von Broadcom, der sein Unternehmen durch Zukäufe aufgebaut hat, hat seinen Vertrag bis 2030 verlängert. Ziel ist es, den Umsatz des Unternehmens im Bereich KI auf 120 Milliarden US-Dollar zu steigern.
Betrachtet man Hock Tans Lebenslauf, so sind Fusionen und Übernahmen ein unvermeidliches Thema. Ihn jedoch ausschließlich aus der Perspektive eines Unternehmensinvestors zu beurteilen, greift zu kurz. Jeder seiner Schritte, der über Gewinn- und Umsatzrechnungen hinausgeht, trägt dazu bei, sein Unternehmen schrittweise in eine führende Position zu bringen; die zugrundeliegenden Trendprognosen sind dabei sogar noch entscheidender.
Den vollständigen Bericht ansehen:https://go.hyper.ai/6lPG5
Beliebte Enzyklopädieartikel
1. DALL-E
2. Hypernetzwerke
3. Pareto-Front
4. Bidirektionales Langzeit-Kurzzeitgedächtnis (Bi-LSTM)
5. Reziproke Rangfusion
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Top-Konferenz mit einer Frist im Dezember

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1800 öffentliche Datensätze
* Enthält über 600 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 600 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








