Command Palette
Search for a command to run...
Online-Tutorial | Microsoft Stellt VibeVoice Als Open Source Zur Verfügung Und Ermöglicht so 90 Minuten Natürliche Dialoge Zwischen 4 Rollen
Die Text-to-Speech-Technologie (TTS) hat in den letzten Jahren bedeutende Fortschritte erzielt und ermöglicht die Synthese von kurzen, natürlich klingenden Äußerungen in hoher Qualität für einen einzelnen Sprecher. Die skalierbare Synthese von längeren Dialogen mit mehreren Sprechern stellt jedoch weiterhin eine große Herausforderung dar, was ihren Einsatz in Bereichen wie Podcasts und Hörbüchern mit mehreren Sprechern einschränkt.
Herkömmliche Methoden, selbst wenn sie Audio durch die Aneinanderreihung unabhängig synthetisierter Äußerungen erzeugen, erreichen noch immer nicht die natürliche Dialogführung und inhaltsbezogene Generierung. Angesichts der steigenden Anforderungen industrieller Anwendungen hat die Forschung zur Generierung längerer Gespräche mit mehreren Sprechern in verschiedenen Sektoren an Bedeutung gewonnen.Allerdings wurden die meisten Ergebnisse noch nicht als Open Source veröffentlicht, oder es gibt noch ungelöste Probleme hinsichtlich der Generationslänge und Stabilität.
In diesem ZusammenhangMicrosoft hat VibeVoice als Open Source veröffentlicht, mit dem Ziel, skalierbare Sprachsynthese für lange Texte und mehrere Sprecher zu ermöglichen. VibeVoice verwendet einen Next-Token-Diffusionsansatz zur Synthese langer Mehrsprecher-Sprache, eine einheitliche Methode, die Diffusionsautoregression nutzt, um latente Vektoren zur Modellierung kontinuierlicher Daten zu generieren.
Zu diesem Zweck entwickelte das Forschungsteam einen neuartigen Segmentierer für kontinuierliche Sprache, der im Vergleich zum gängigen Encoder-Modell eine 80-fache Datenkomprimierung bei vergleichbarer Leistung ermöglicht und eine Kompressionsrate von bis zu 3200× (entsprechend einer Bildrate von 7,5 Hz) erzielt. Dies verbessert die Recheneffizienz bei der Verarbeitung langer Sequenzen erheblich und gewährleistet gleichzeitig die Audioqualität.
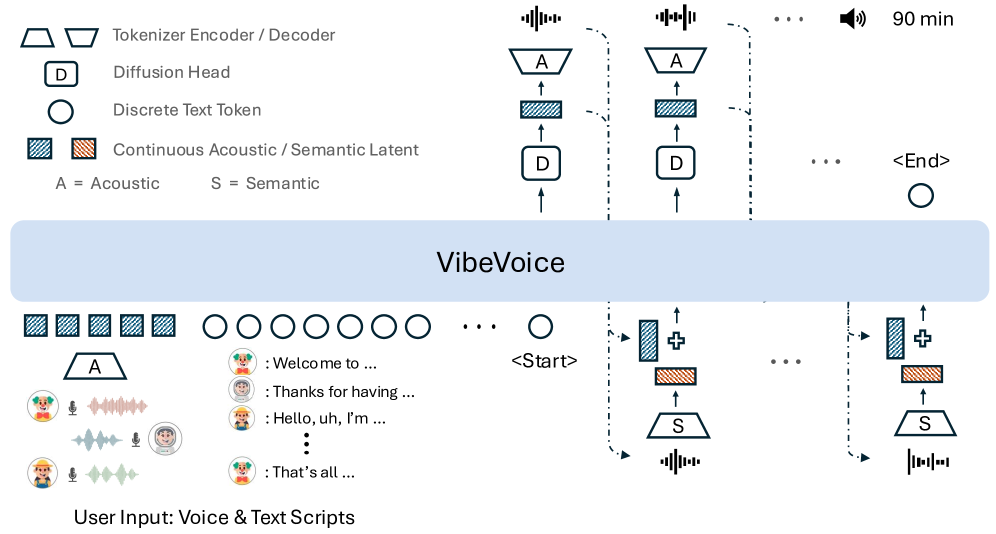
Trotz seiner einfachen Architektur weist VibeVoice außergewöhnliche Fähigkeiten auf.Es kann bis zu 90 Minuten Sprache mit bis zu vier Sprechern innerhalb eines 64K-Kontextfensters synthetisieren und erzeugt so einen reichhaltigeren Klang, eine natürlichere Intonation und fängt die Atmosphäre eines echten Gesprächs ein.Es weist eine stärkere Übertragbarkeit in sprachübergreifenden Anwendungen auf und seine Gesamtleistung übertrifft bestehende Open-Source- und proprietäre Dialogmodelle.
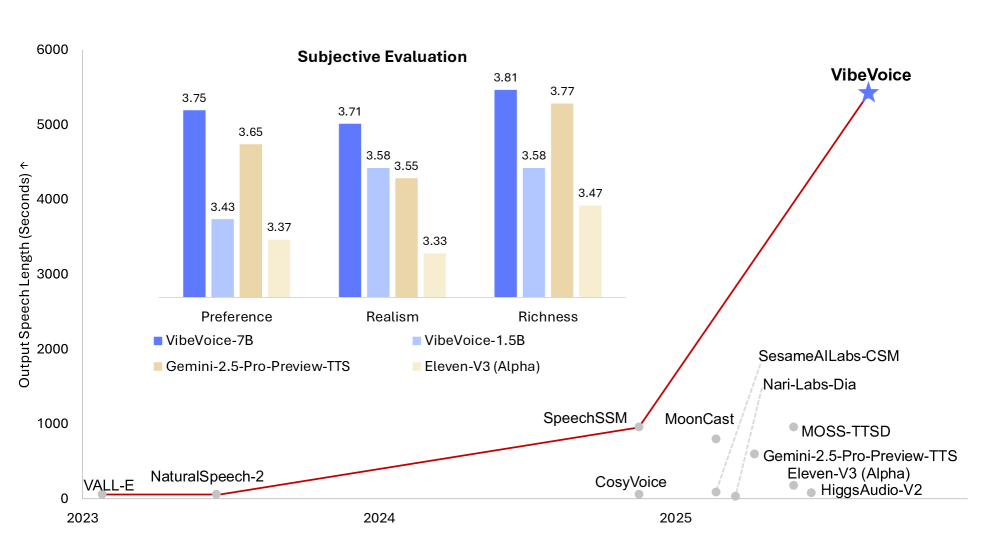
Zum Jahresende nutzt dieser Artikel VibeVoice, um einen 1:20 Minuten langen Audio-Clip mit Neujahrsgrüßen zu erstellen. Die Qualität ist deutlich verbessert; der monotone, „mechanische Klang“ verschwindet und der Clip präsentiert sich mit einem vollen, vielschichtigen Timbre voller emotionaler Spannung – warm und lebendig.
„VibeVoice-Realtime TTS: Echtzeit-Sprachsynthese-Service“ ist jetzt im Tutorial-Bereich der HyperAI-Website (hyper.ai) verfügbar. Sie können ihn mit nur einem Klick installieren und ausprobieren!
Link zum Tutorial:
Demolauf
1. Nachdem Sie die Startseite von hyper.ai aufgerufen haben, wählen Sie „VibeVoice-Realtime TTS: Echtzeit-Sprachsynthesedienst“ oder wählen Sie es auf der Seite „Tutorials“ aus. Klicken Sie anschließend auf „Dieses Tutorial online ausführen“.
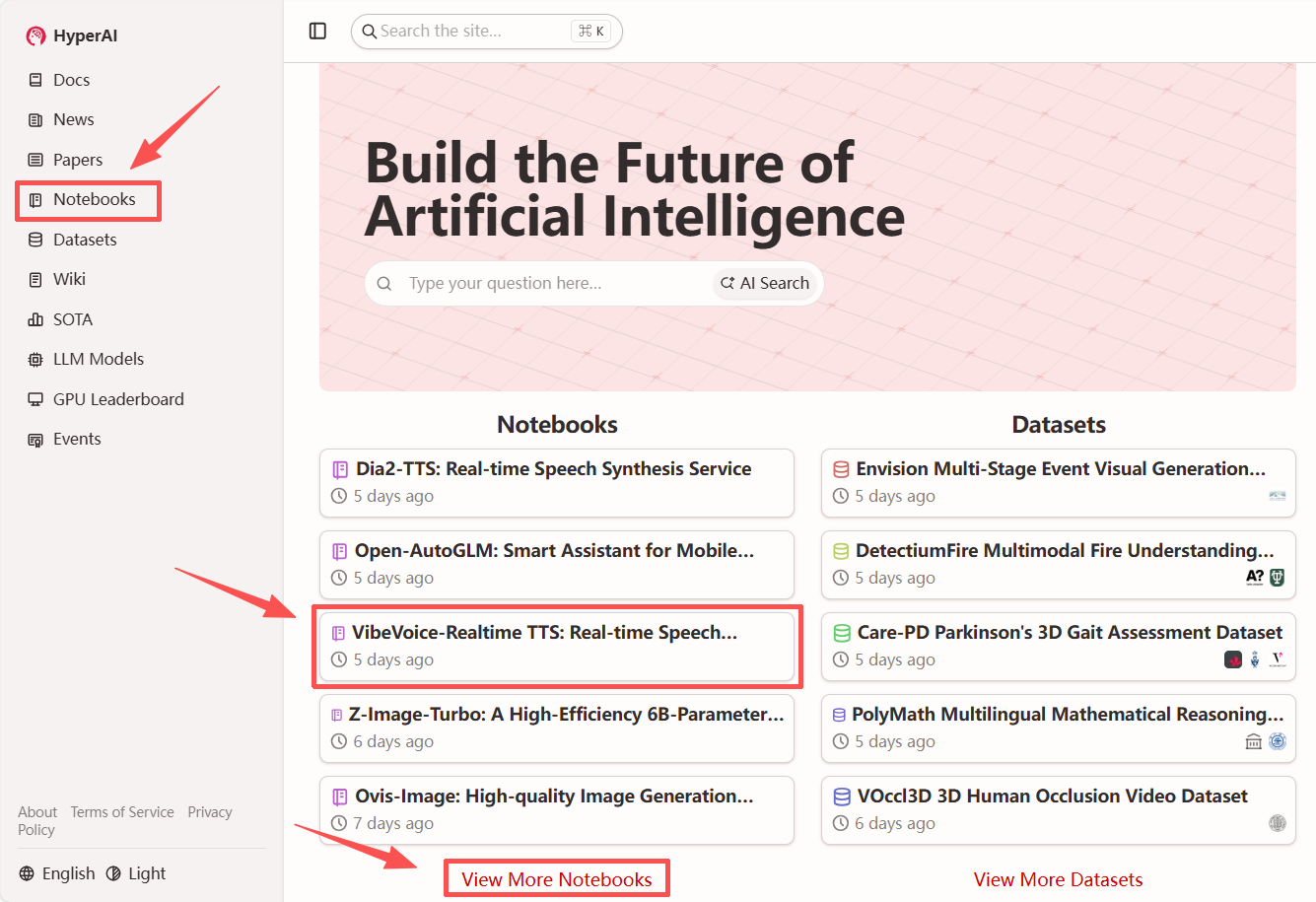
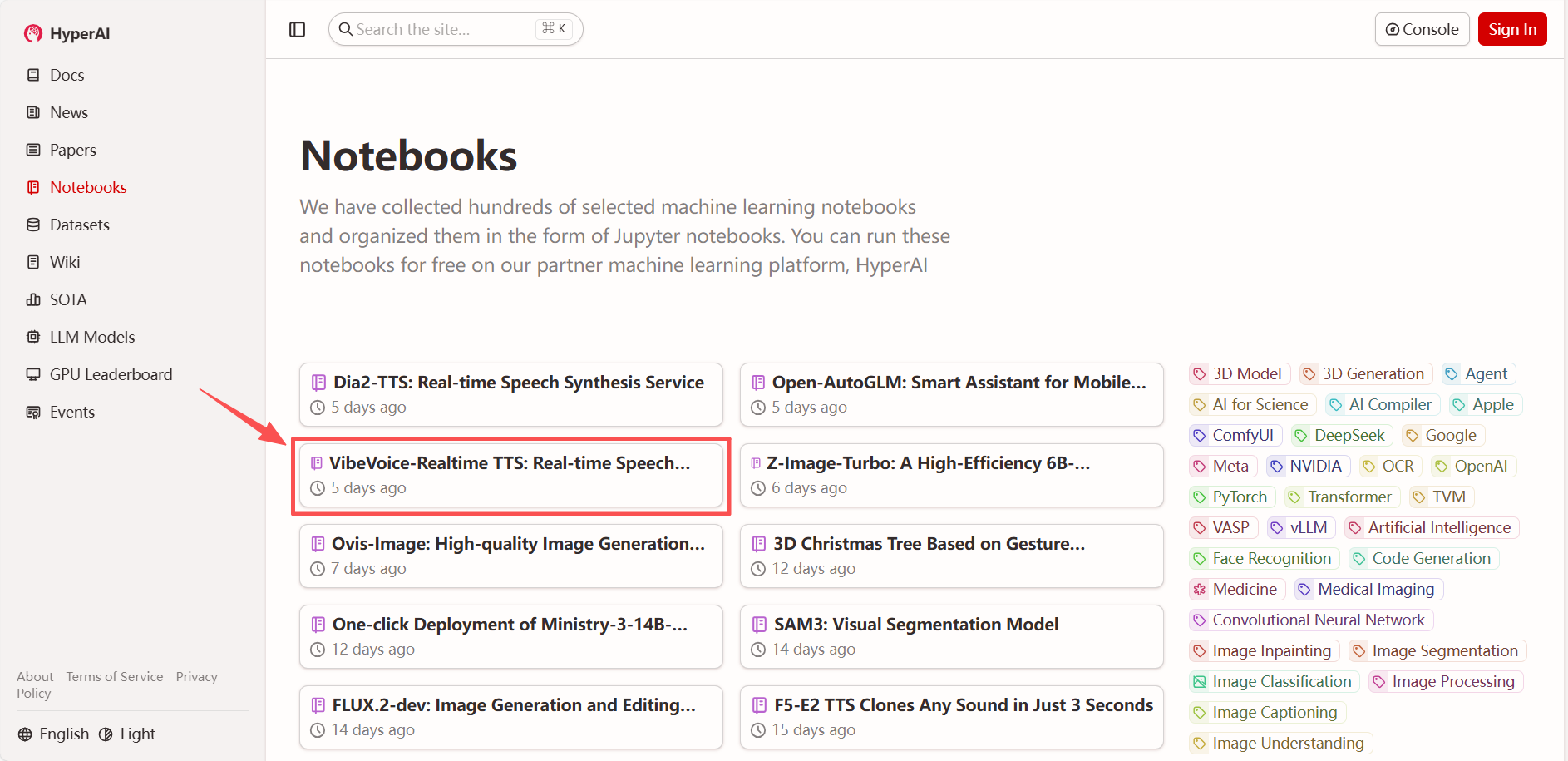
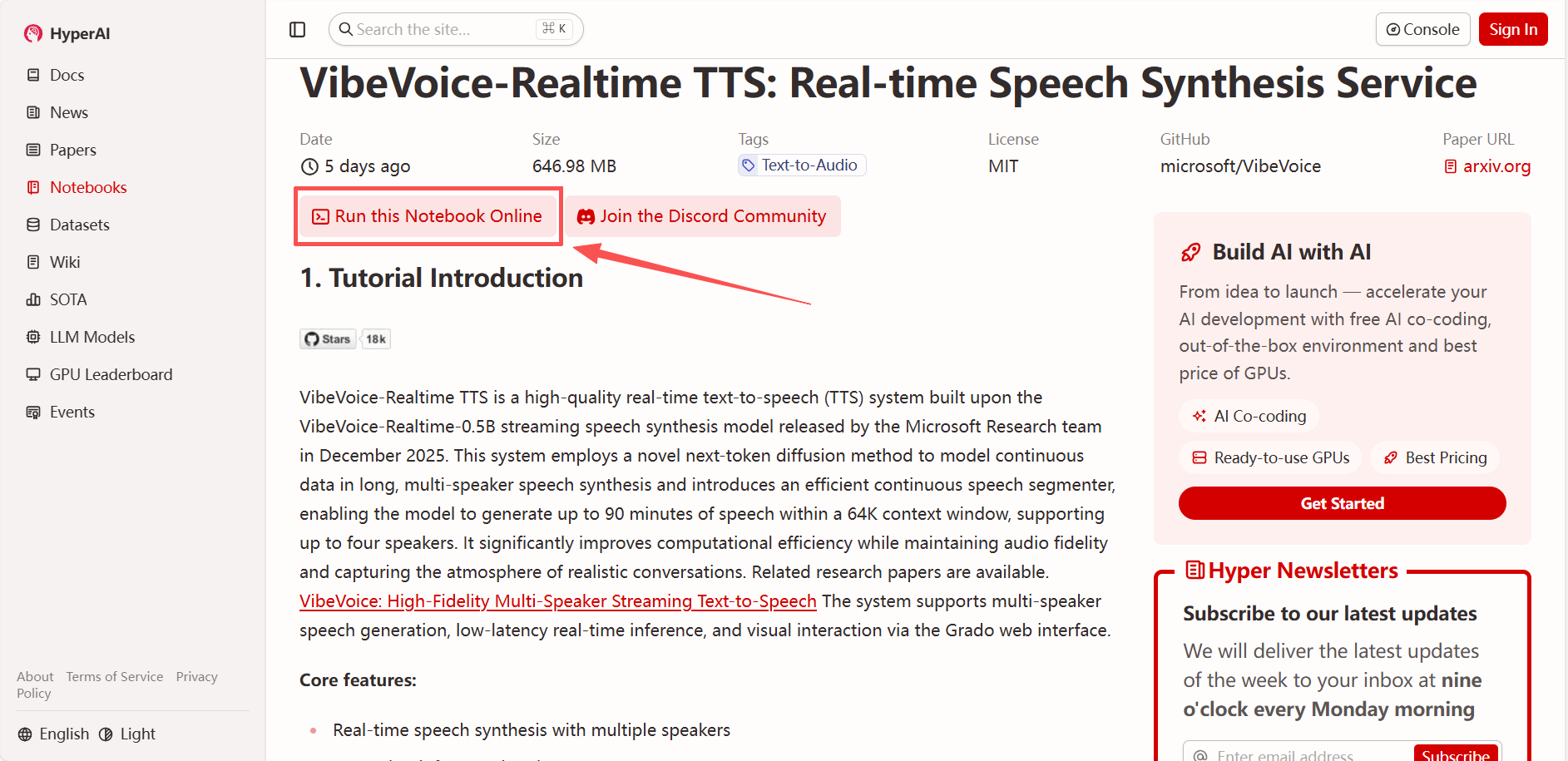
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
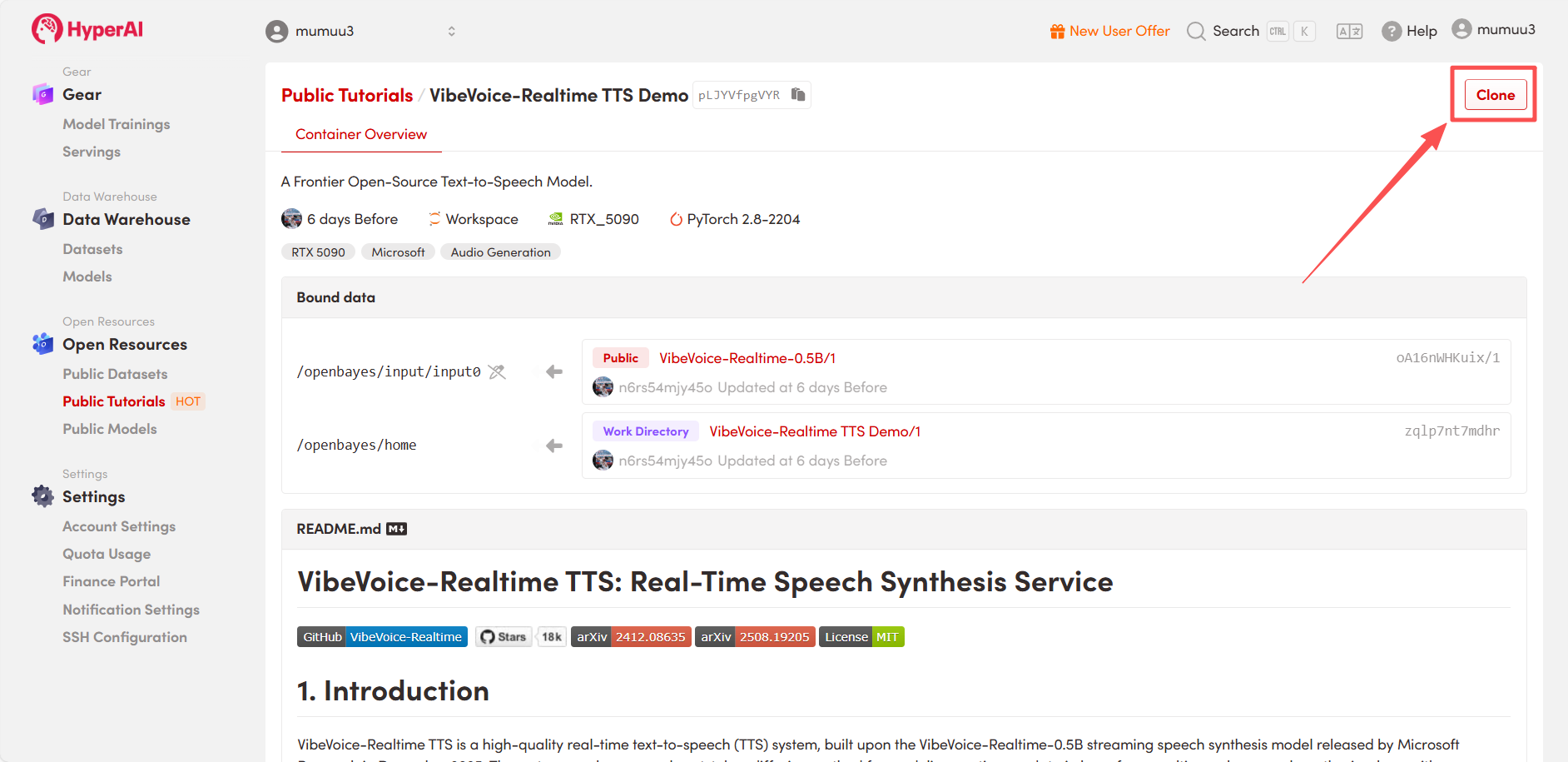
3. Wählen Sie die Images „NVIDIA GeForce RTX 5090“ und „PyTorch“ aus und wählen Sie je nach Bedarf „Pay As You Go“ oder „Tagesplan/Wochenplan/Monatsplan“. Klicken Sie anschließend auf „Auftragsausführung fortsetzen“.
HyperAI bietet Neukunden einen Registrierungsbonus: Für nur $1 erhalten Sie 5 Stunden RTX 5090 Rechenleistung (ursprünglich $2,45), und die Ressourcen sind unbegrenzt gültig.
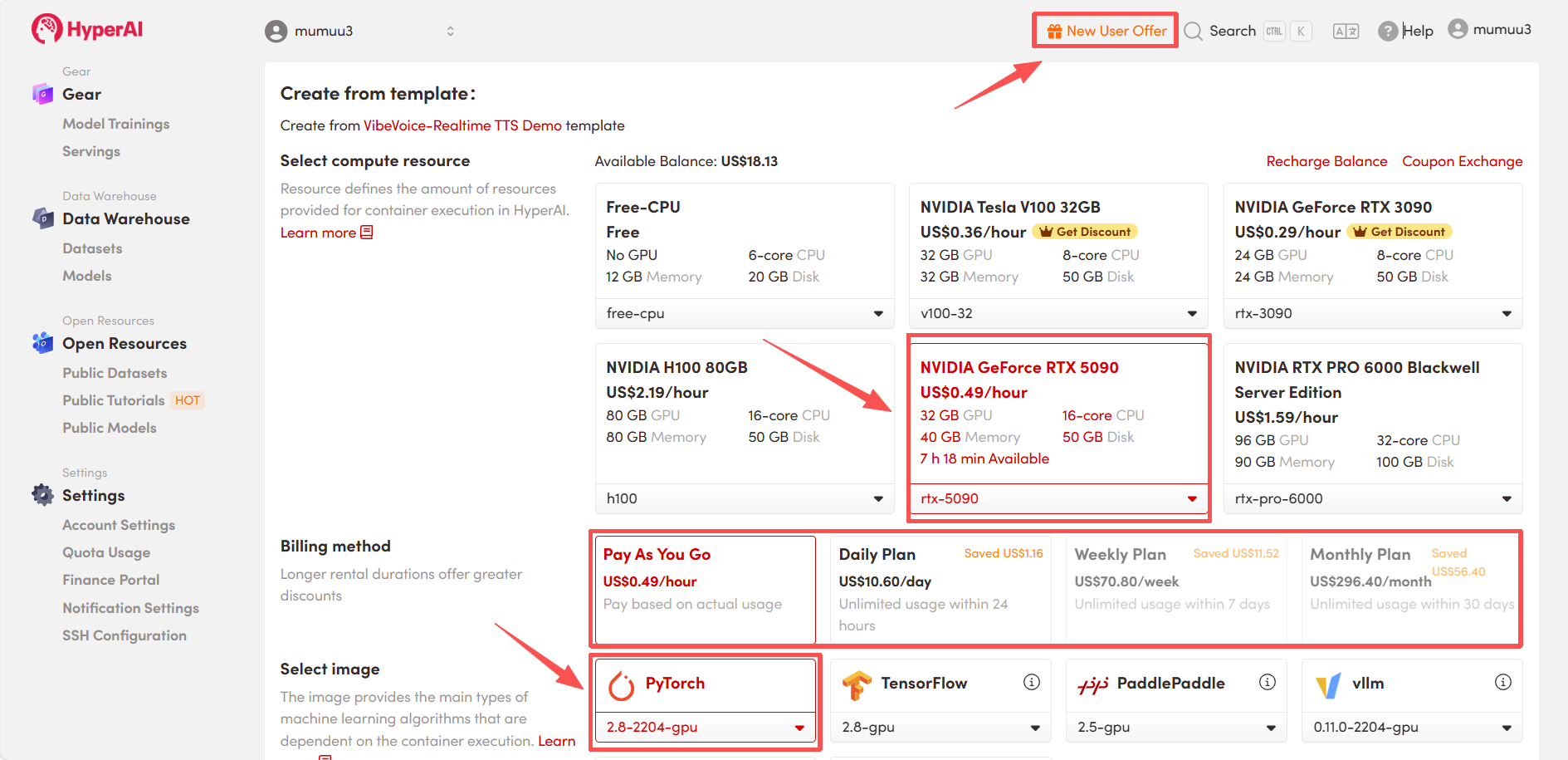
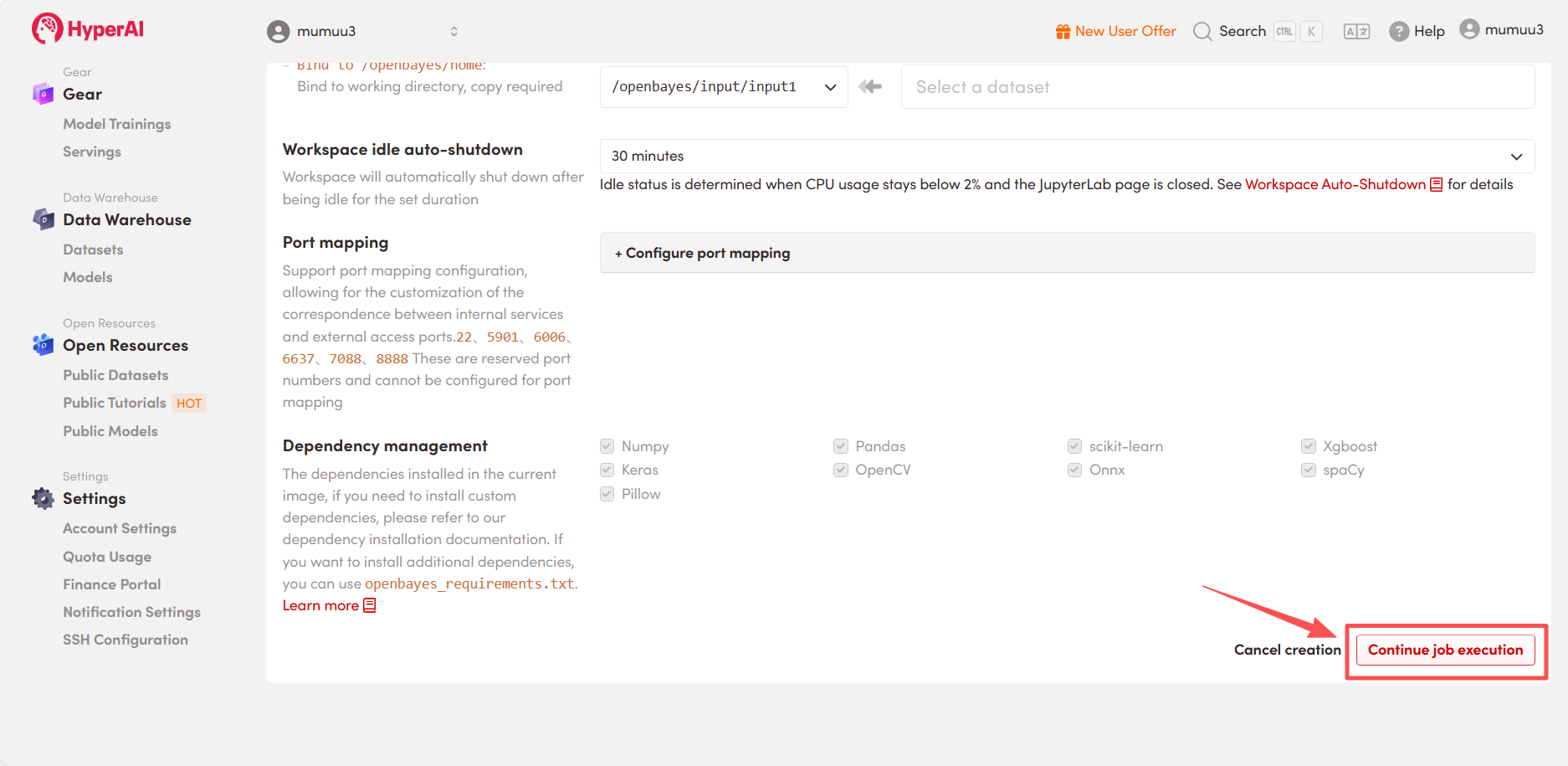
4. Warten Sie auf die Ressourcenzuweisung. Der erste Klonvorgang dauert etwa 3 Minuten. Sobald der Status auf „Wird ausgeführt“ wechselt, klicken Sie auf den Pfeil neben „API-Adresse“, um zur Demoseite zu gelangen.
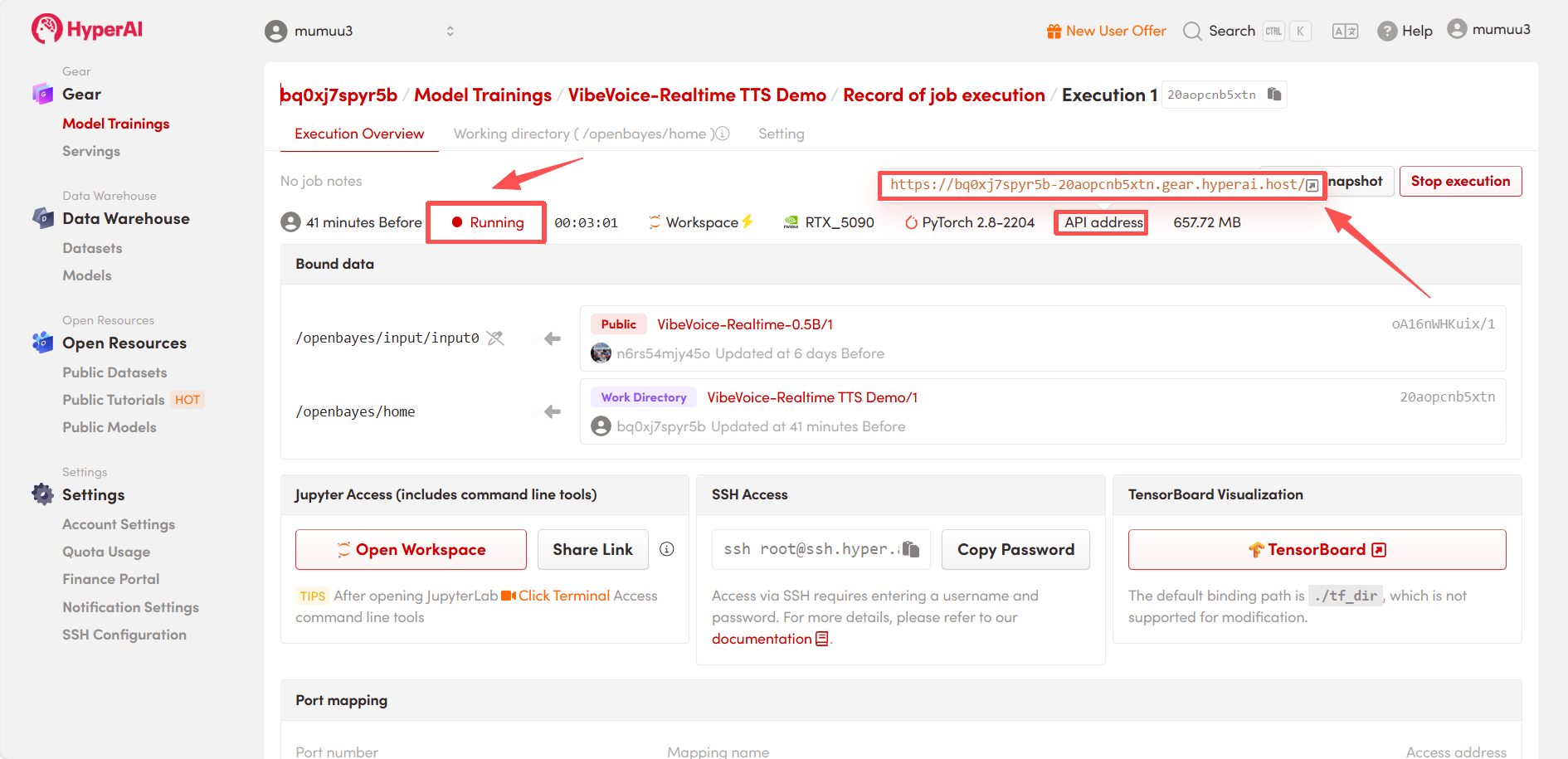
Effektdemonstration
Nachdem Sie die Demoseite aufgerufen haben, laden Sie Ihr Testvideo hoch, geben Sie Text in das Feld „Zu konvertierender Text“ ein und wählen Sie unter „Sprecherstimme“ eine von sieben wählbaren Stimmfarben aus. Mit der „CFG-Skala“ können Sie die Intensität des Sprachstils anpassen; ein höherer Wert bedeutet stärkere Emotionen. Klicken Sie abschließend auf „Sprache generieren“ und warten Sie einen Moment, bis die Audiodatei erstellt wurde.
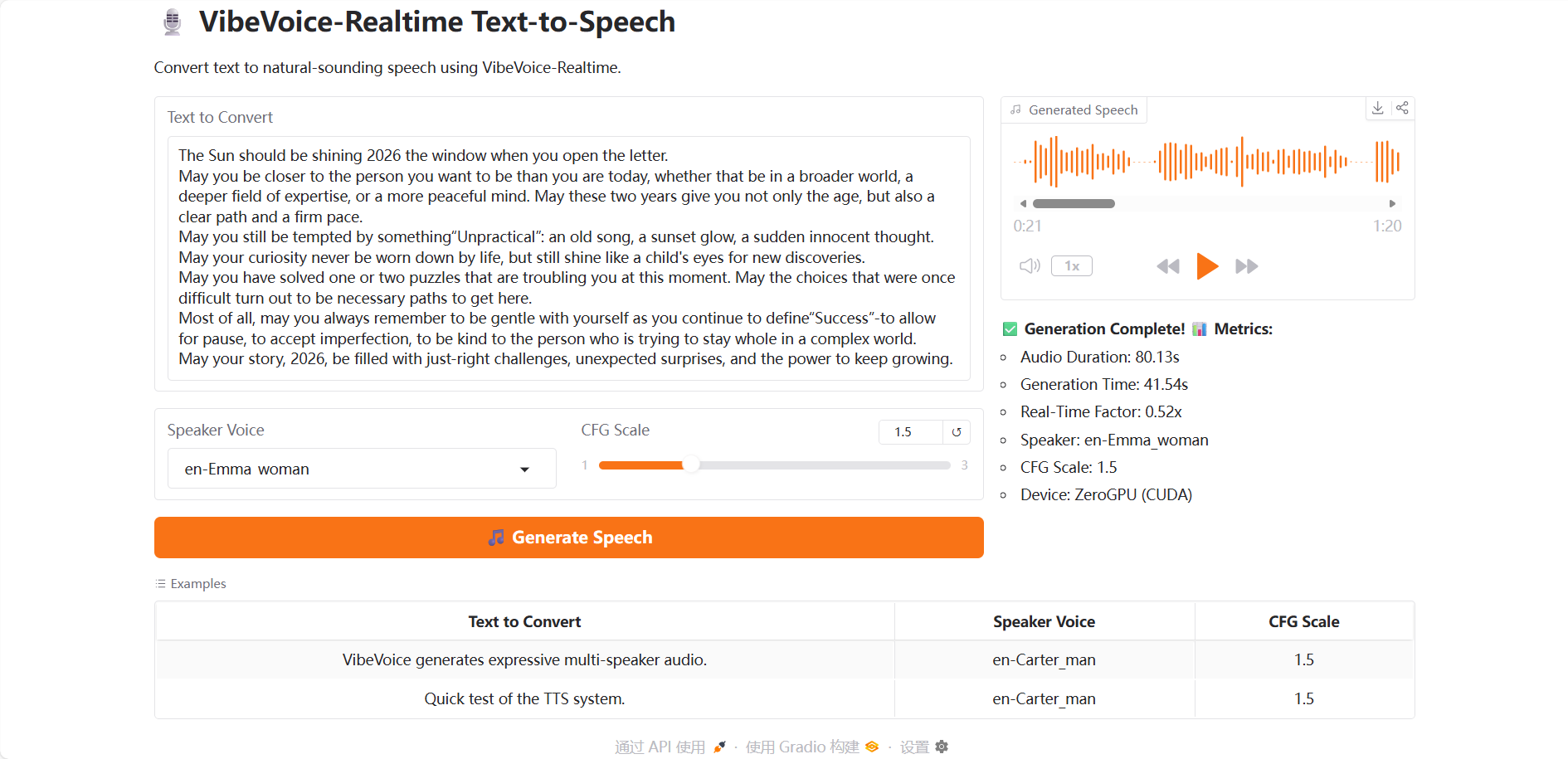
Zum Jahresende: Klicken Sie hier, um die Neujahrsgrüße von VibeVoice anzuhören!
Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!
Link zum Tutorial:








