Command Palette
Search for a command to run...
Online-Tutorial | DeepSeek-OCR 2: Verbesserungen Bei Der Formel-/Tabellenanalyse – Erzielen Sie Einen Leistungssprung Von Fast 41 TP3T Bei Geringen Visuellen Token-Kosten

Bei der Entwicklung visueller Sprachmodelle (VLMs) stand die Dokumenten-OCR immer wieder vor zentralen Herausforderungen wie der Analyse komplexer Layouts und der Ausrichtung der semantischen Logik. Traditionelle Modelle verwenden meist eine feste Rasterabtastreihenfolge von links oben nach rechts unten, um visuelle Token zu verarbeiten. Dieses starre Verfahren widerspricht dem semantikgesteuerten Abtastmuster des menschlichen Sehsystems, insbesondere bei Dokumenten mit komplexen Formeln und Tabellen, was leicht zu Analysefehlern führt, da semantische Beziehungen vernachlässigt werden. Die Frage, wie Modelle visuelle Logik ähnlich wie Menschen „verstehen“ können, ist daher ein entscheidender Durchbruch für die Verbesserung des Dokumentenverständnisses.
Kürzlich hat DeepSeek-AI DeepSeek-OCR 2 veröffentlicht, das die neuesten Antworten liefert.Kernstück ist die Übernahme der brandneuen DeepEncoder V2-Architektur:Das Modell verzichtet auf den traditionellen visuellen CLIP-Encoder und führt ein visuelles Kodierungsparadigma im LLM-Stil ein. Durch die Kombination von bidirektionaler und kausaler Aufmerksamkeit erreicht es eine semantisch gesteuerte Neuanordnung visueller Token und eröffnet so einen neuen Weg des „zweistufigen 1D-Kausalschlussfolgerns“ für das Verständnis von 2D-Bildern.
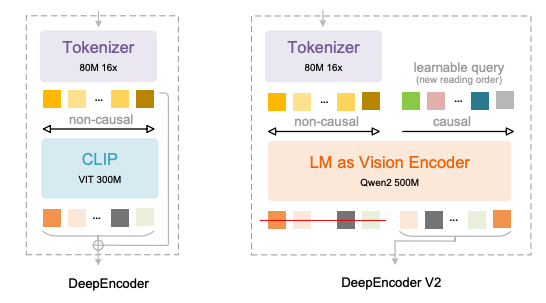
Die wichtigsten Neuerungen von DeepEncoder V2 spiegeln sich in vier Aspekten wider:
* Ersetzen Sie CLIP durch Qwen2-0.5B compact LLM, um visuelle Kodierungs- und Kausalitätslogikfähigkeiten in einem Umfang von etwa 500 Millionen Parametern zu ermöglichen;
* Einführung der „Causal Flow Query“ mit der gleichen Länge wie die Anzahl der visuellen Tokens, die eine benutzerdefinierte Aufmerksamkeitsmaske verwendet, um visuelle Tokens global zu berücksichtigen und gleichzeitig Abfrage-Tokens die semantische Neuordnung der visuellen Reihenfolge zu ermöglichen;
* Unterstützt mehrere Pruning-Strategien für 256 bis 1.120 visuelle Token, die mit dem Token-Budget gängiger großer Modelle übereinstimmen und gleichzeitig die Effizienz erhalten;
Durch die Verwendung einer verketteten Struktur aus „visuellem Token + kausaler Anfrage“ werden semantische Neuordnung und autoregressive Generierung entkoppelt, wodurch eine natürliche Anpassung an den unidirektionalen Aufmerksamkeitsmechanismus von LLM erreicht wird.
Dieses Design beseitigt effektiv die räumliche Ordnungsverzerrung traditioneller Modelle und ermöglicht es dem Modell, Texte, Formeln und Tabellen dynamisch auf der Grundlage semantischer Beziehungen zu organisieren, genau wie beim menschlichen Lesen, anstatt mechanisch Pixelpositionen zu folgen.
Es wurde bestätigt, dass im OmniDocBench v1.5 Benchmark-Test,DeepSeek-OCR 2 erreichte eine Gesamtgenauigkeit von 91.091 TP3T bei einem visuellen Token-Limit von 1.120.Im Vergleich zum Vorgängermodell verbesserte sich die Leistung um 3,731 TP3T, während die Editierdistanz (ED) der Lesereihenfolge von 0,085 auf 0,057 reduziert wurde. Dies belegt eine signifikante Verbesserung des visuellen Logikverständnisses. Bei spezifischen Aufgaben verbesserte sich die Genauigkeit der Formelanalyse um 6,171 TP3T, das Tabellenverständnis um 2,51–3,051 TP3T und die Text-Editierdistanz sank um 0,025. Damit wurden in allen Kernmetriken deutliche Fortschritte erzielt.
Gleichzeitig ist auch die technische Praktikabilität hervorragend: Bei gleichbleibender visueller Token-Komprimierungsrate von 16x konnte die Wiederholungsrate von Online-Diensten von 6,25% auf 4,17% und die Wiederholungsrate der PDF-Stapelverarbeitung von 3,69% auf 2,88% reduziert werden, wobei sowohl akademische Innovationen als auch industrielle Anwendungsbedürfnisse berücksichtigt wurden.Im Vergleich zu ähnlichen Modellen erzielt DeepSeek-OCR 2 Ergebnisse, die nahe an denen von Modellen mit hohem Parameterwert liegen oder diese sogar übertreffen, und das bei geringeren Kosten für visuelle Token.Es bietet eine kostengünstigere Lösung für die hochpräzise Dokumenten-OCR in ressourcenbeschränkten Szenarien.
Aktuell ist „DeepSeek-OCR 2: Visual Causal Flow“ im Bereich „Tutorials“ auf der HyperAI-Website verfügbar. Klicken Sie auf den unten stehenden Link, um das Tutorial zur Ein-Klick-Bereitstellung zu starten ⬇️
Link zum Tutorial:https://go.hyper.ai/2ma8d
Verwandte Artikel ansehen:https://go.hyper.ai/hE1wW
Effektdemonstration:
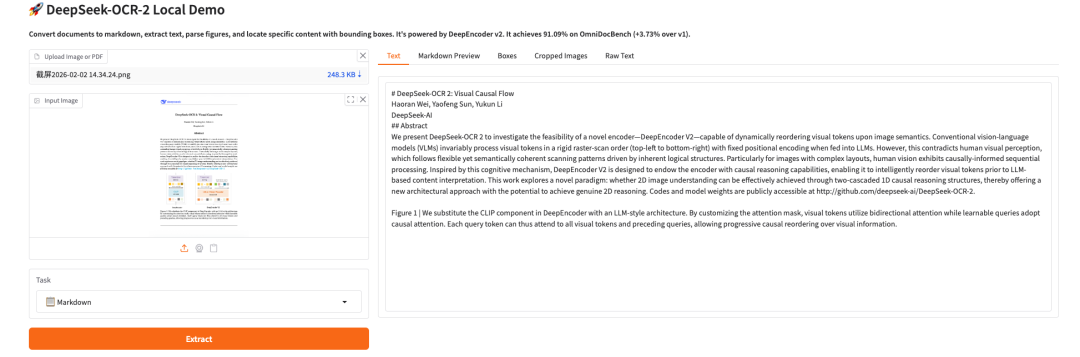
Demolauf
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „DeepSeek-OCR 2 Visual Causal Flow“ aus und klicken Sie auf „Dieses Tutorial online ausführen“.

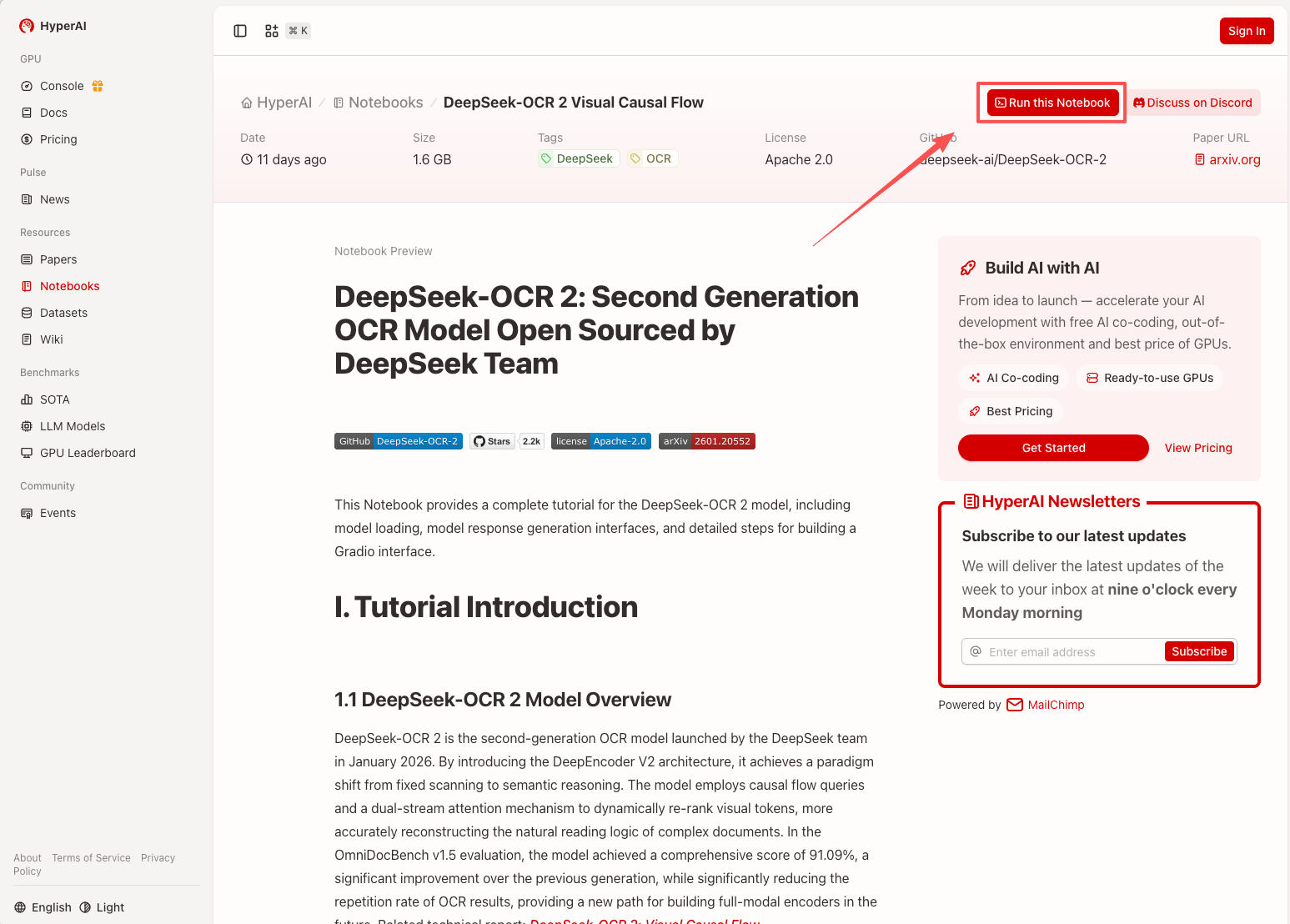
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
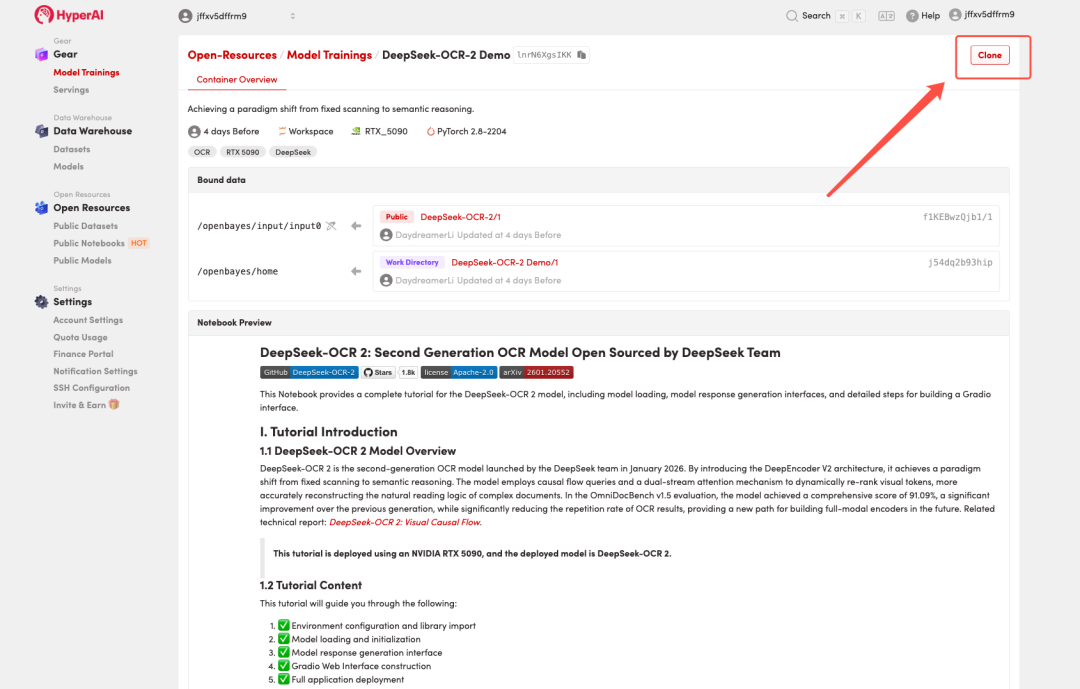
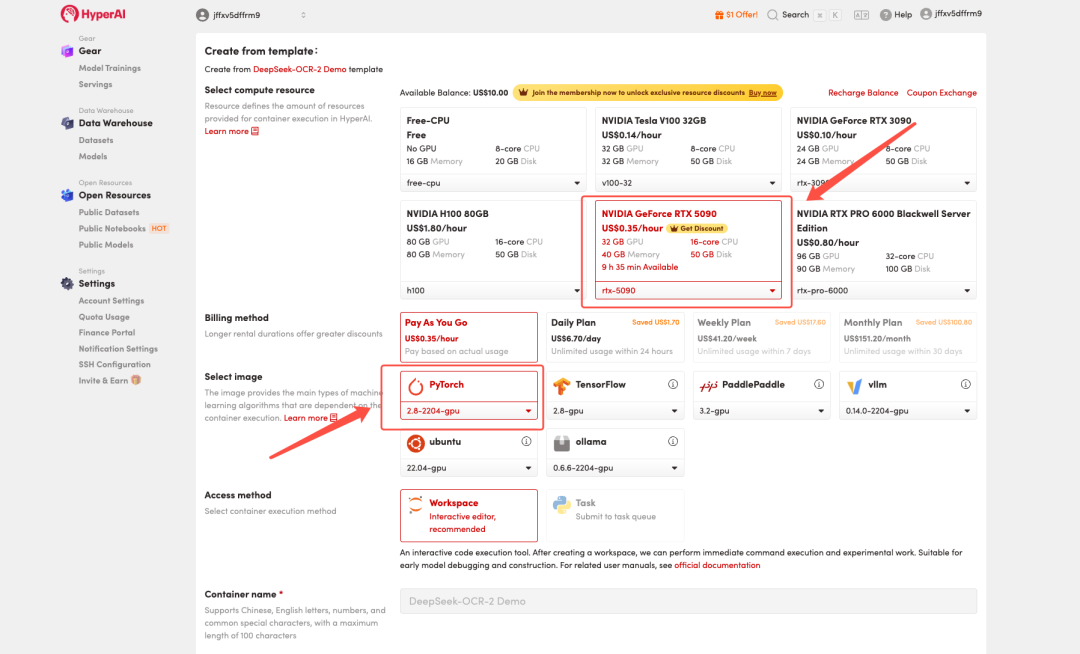
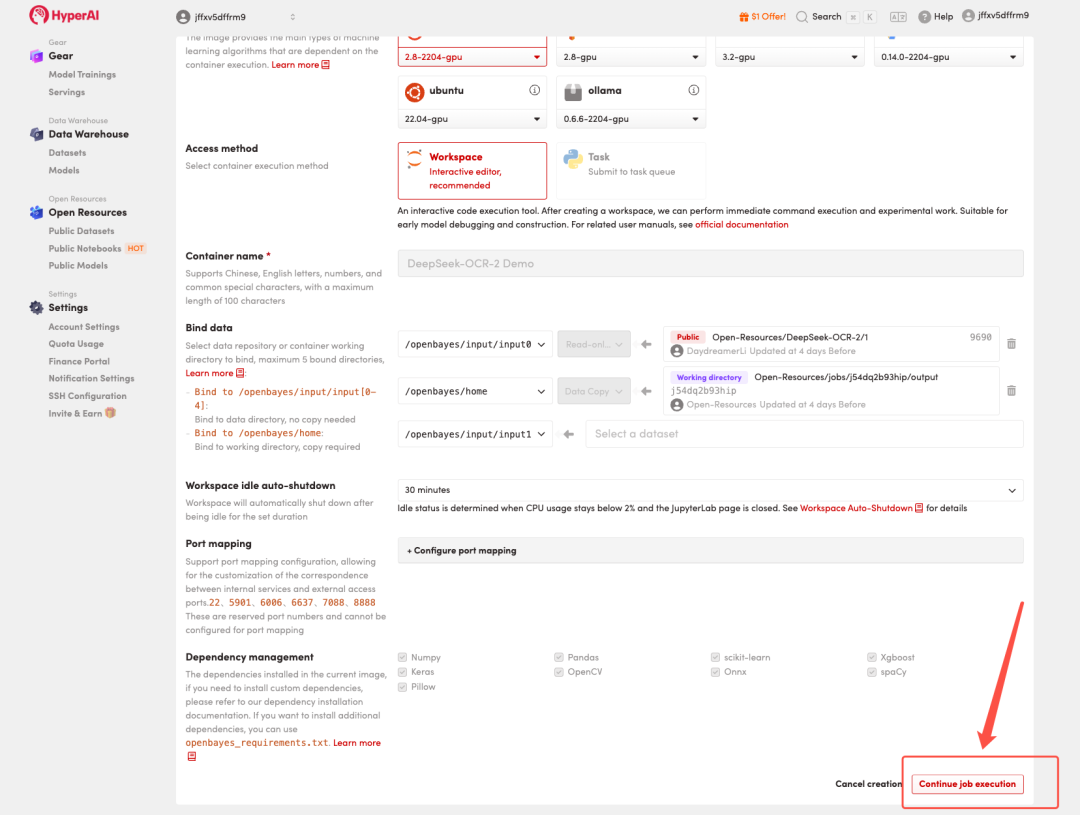
3. Wählen Sie die Images „NVIDIA GeForce RTX 5090“ und „PyTorch“ aus und wählen Sie je nach Bedarf „Pay As You Go“ oder „Tagesplan/Wochenplan/Monatsplan“. Klicken Sie anschließend auf „Auftragsausführung fortsetzen“.
HyperAI bietet Neukunden Registrierungsvorteile.Sichern Sie sich eine RTX 5090 für nur 1 TP4T1. Hashrate(Originalpreis $7)Die Ressource ist dauerhaft gültig.
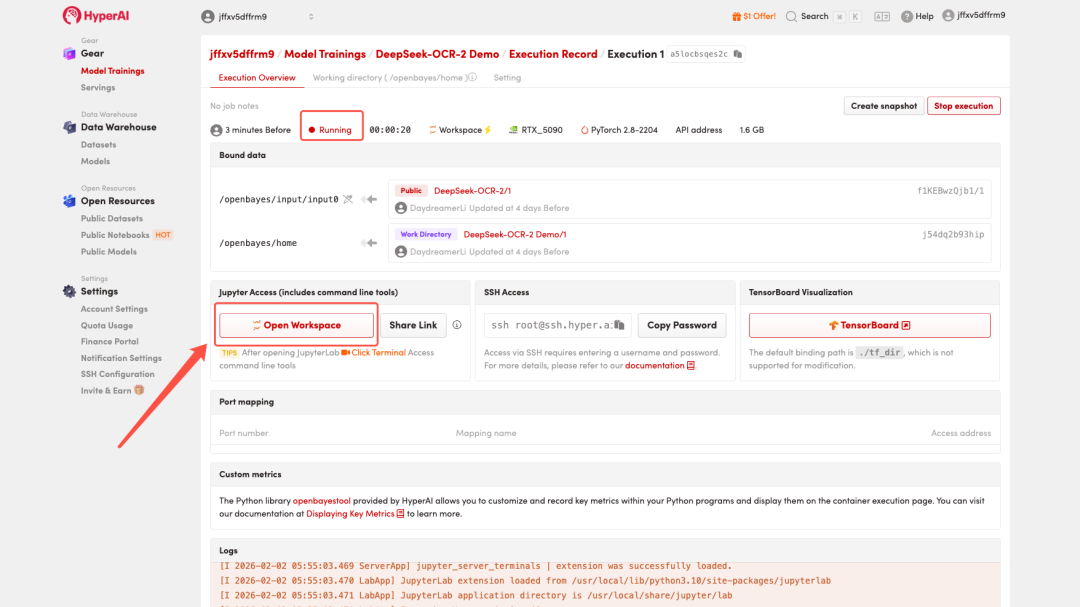
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
Effektdemonstration
Nachdem die Seite weitergeleitet wurde, klicken Sie links auf die README-Seite und anschließend oben auf Ausführen.
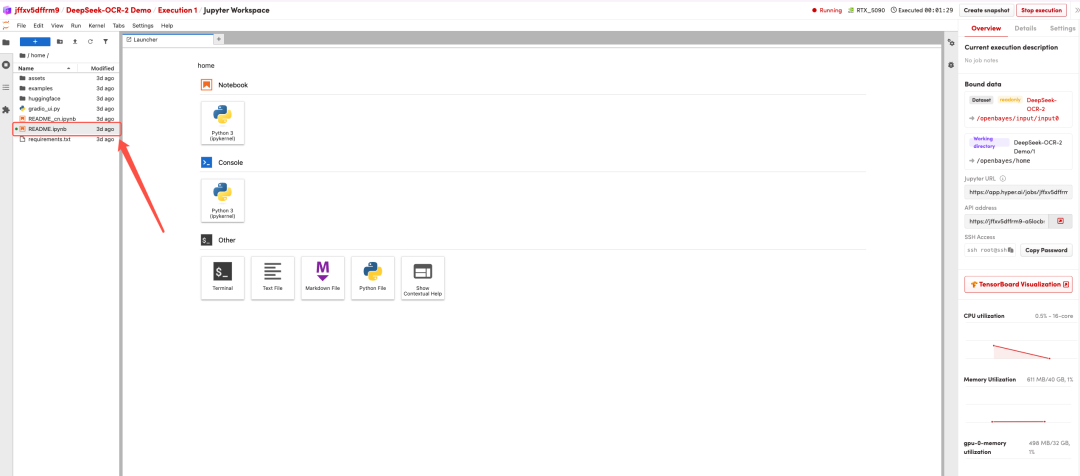
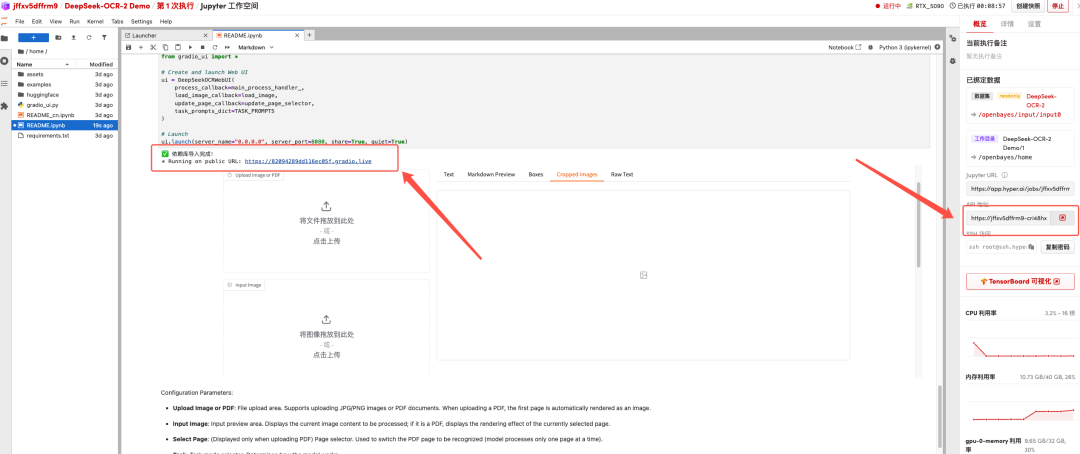
Sobald der Vorgang abgeschlossen ist, klicken Sie auf die API-Adresse rechts, um zur Demoseite zu gelangen.
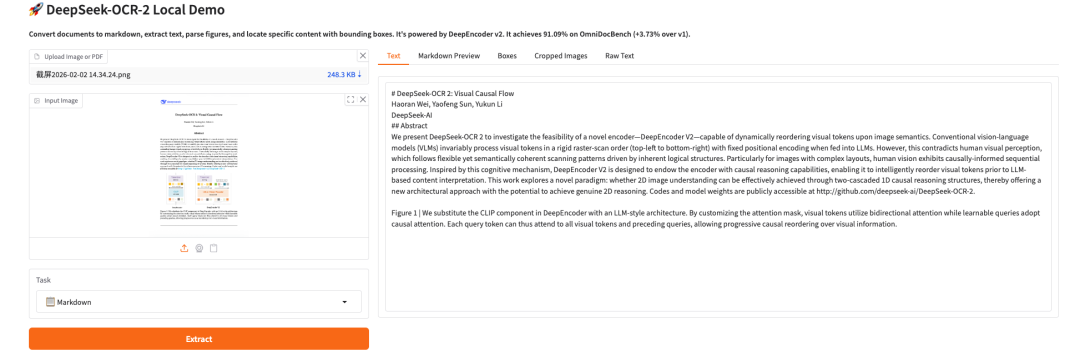
Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!
Link zum Tutorial:https://go.hyper.ai/2ma8d








