Command Palette
Search for a command to run...
Praxiserfahrung | Übung Zur Elementweisen Operatoroptimierung Basierend Auf Der HyperAI Cloud-Computing-Plattform
Die HyperAI-Computing-Plattform wurde offiziell gestartet und bietet Entwicklern hochstabile Rechendienste. Durch eine sofort einsatzbereite Umgebung, kostengünstige GPU-Preise und reichlich vorhandene Ressourcen vor Ort wird die Umsetzung ihrer Ideen beschleunigt.
Im Folgenden werden die Erfahrungen von HyperAI-Nutzern bei der Optimierung von Elementwise-Operatoren auf Basis der Plattform geteilt ⬇️
Eine kurze Ankündigung zu einer Veranstaltung!
Das HyperAI-Beta-Testprogramm sucht noch Teilnehmer mit einer maximalen Prämie von $200. Klicken Sie hier, um mehr über das Programm zu erfahren:Bis zu $200 können erreicht werden! Die Rekrutierung für den HyperAI-Betatest ist offiziell eröffnet!
Kernziel:Optimieren Sie einen einfachen elementweisen Additionsoperator (C = A + B) von seiner Basisimplementierung aus, um sich der nativen Leistung von PyTorch anzunähern (d. h. sich der Speicherbandbreitengrenze der Hardware anzunähern).
Wichtigste Herausforderungen:Der elementweise Operator ist typischerweise ein speicherintensiver Operator.
- Die Rechenleistung ist nicht der Flaschenhals (GPUs führen Additionen unglaublich schnell durch).
- Der Engpass liegt im Ungleichgewicht zwischen Angebot und Nachfrage auf der „Befehlsausgabeseite“ und der „Videospeichertransportseite“.
- Das Wesen der Optimierung besteht darin, mit möglichst wenigen Anweisungen die größtmögliche Datenmenge (Bytes) zu übertragen.
Vorbereitung der experimentellen Umgebung und der Rechenleistung
Die Optimierung des Elementwise-Operators reizt die physikalischen Grenzen der GPU-Speicherbandbreite voll aus. Um möglichst genaue Benchmark-Daten zu erhalten, wurde diese praktische Übung auf der Cloud-Computing-Plattform von HyperAI (hyper.ai) durchgeführt. Ich habe gezielt eine Hochleistungsinstanz gewählt, um die maximale Leistung des Operators auszuschöpfen.
- GPU: NVIDIA RTX 5090 (32 GB VRAM)
- RAM: 40 GB
- Umfeld: PyTorch 2.8 / CUDA 12.8
Bonuszeit: Wenn auch Sie die RTX 5090 erleben und den Code in diesem Artikel nachbilden möchten, können Sie bei der Registrierung auf app.hyper.ai meinen exklusiven Einlösecode "EARLY_dnbyl" verwenden, um 1 Stunde kostenlose 5090-Rechenleistung zu erhalten (gültig für 1 Monat).
Starten Sie schnell eine RTX 5090-Instanz.
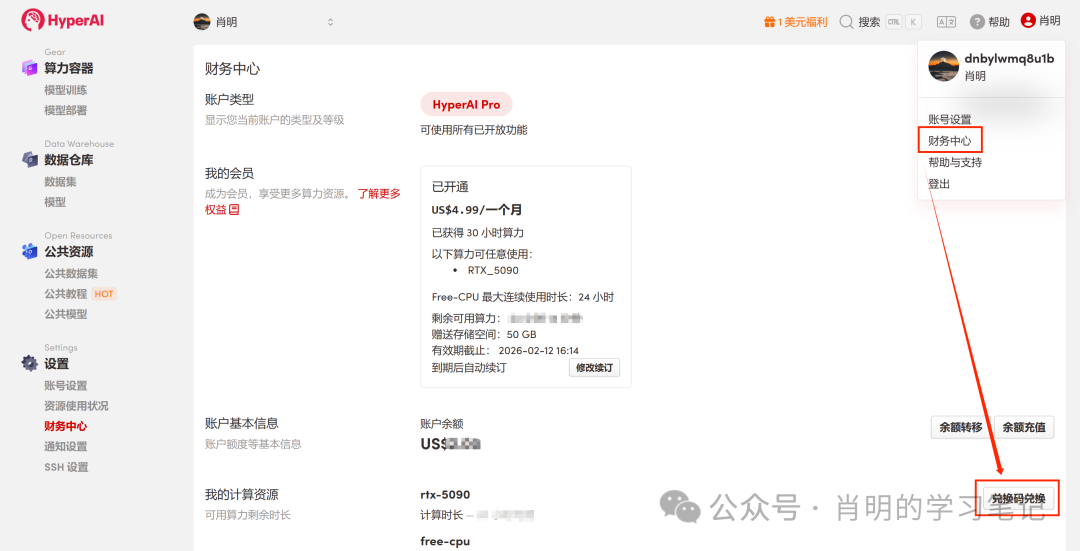
1. Registrierung und Anmeldung: Nach der Registrierung eines Kontos auf app.hyper.ai klicken Sie oben rechts auf „Finanzzentrum“, dann auf „Code einlösen“ und geben Sie „EARLY_dnbyl“ ein, um kostenlose Rechenleistung zu erhalten.
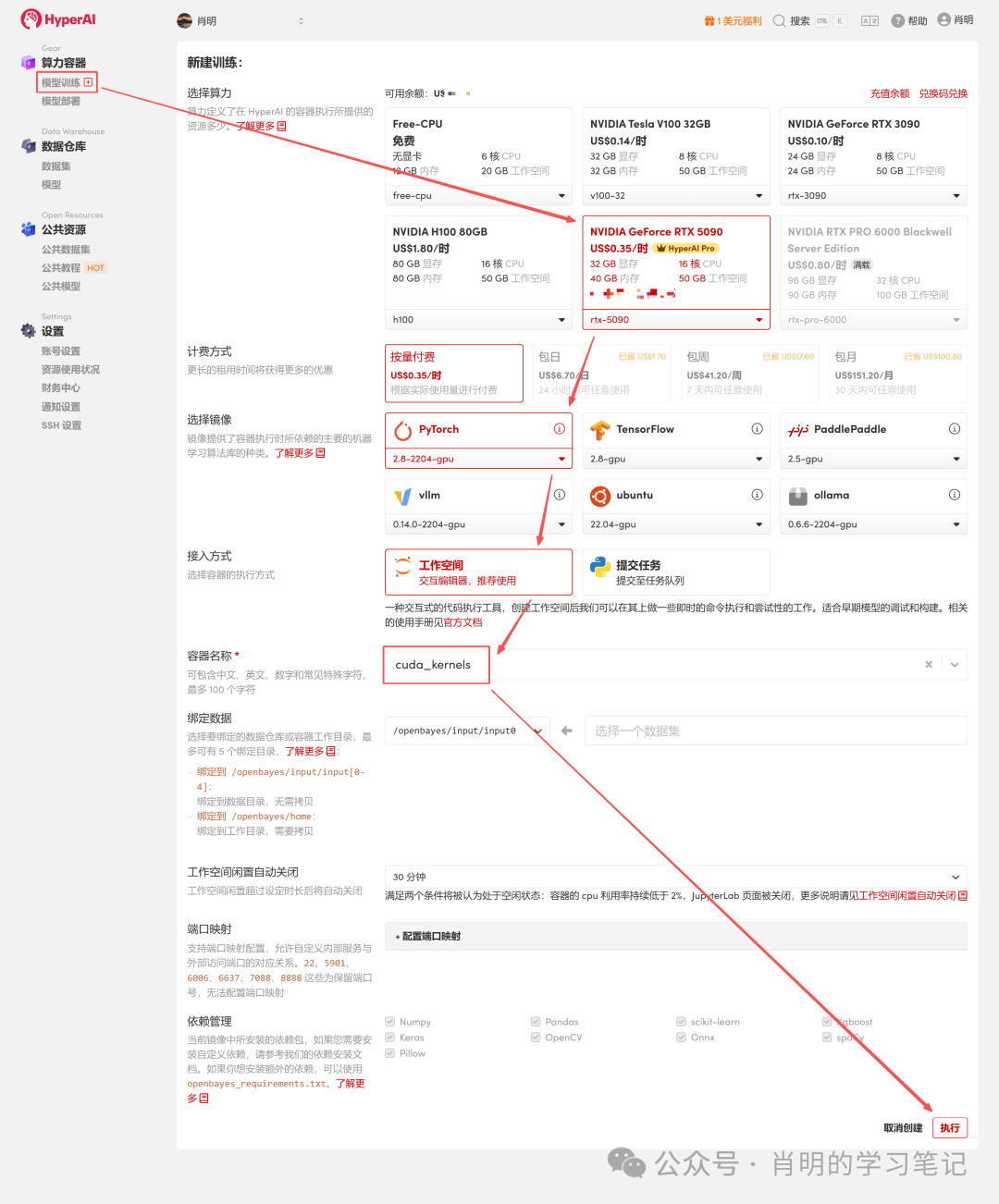
2. Erstellen Sie einen Container: Klicken Sie in der linken Seitenleiste auf „Modelltraining“ -> „Rechenleistung auswählen: 5090“ -> „Image auswählen: PyTorch 2.8“ -> „Zugriffsmethode: Jupyter“ -> „Containername: Geben Sie einen beliebigen Namen ein, z. B. cuda_kernels“ -> „Ausführen“.
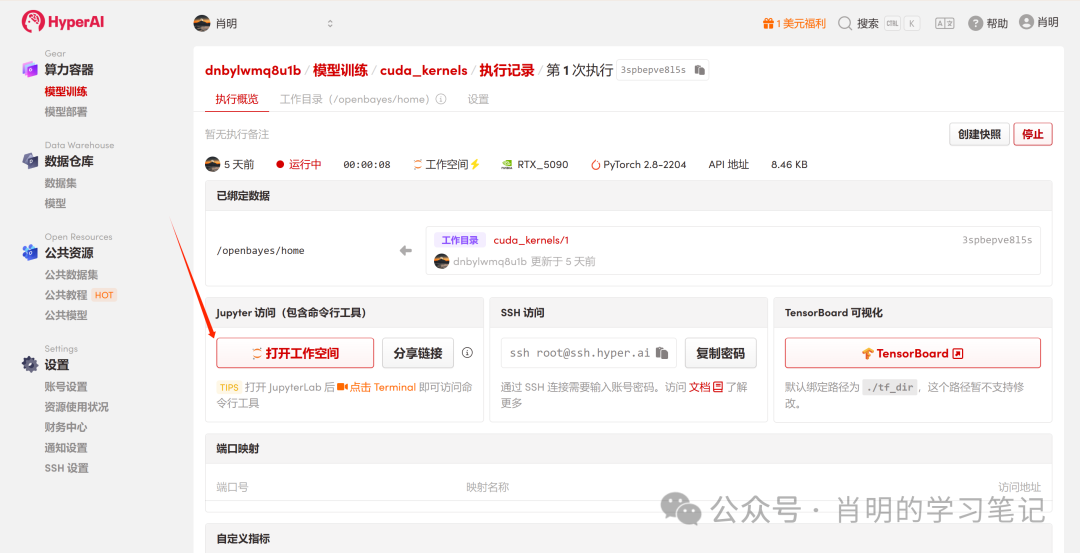
3. Jupyter öffnen: Sobald die Instanz gestartet ist (ihr Status ändert sich zu „Wird ausgeführt“), klicken Sie einfach auf „Arbeitsbereich öffnen“, um sie sofort zu verwenden.
Die Plattform unterstützt Verbindungen über Jupyter oder VS Code SSH Remote. Ich verwende Jupyter und habe folgenden Befehl in der ersten Zelle ausgeführt:
import os
import torch
from torch.utils.cpp_extension import loadPhase 1: FP32-Optimierungsreihe
Version 1: FP32 Baseline (Skalarversion)
Dies ist die intuitivste Art, es zu schreiben, aber hinsichtlich der Effizienz aus Sicht der GPU ist sie nur mäßig.
Detaillierte Analyse der Prinzipien:
- Befehlsebene:Der Scheduler gibt eine LD.E (32-Bit-Lade-)Anweisung aus.
- Ausführungsschicht (Warp)Gemäß dem SIMT-Prinzip führen alle 32 Threads im Warp diese Anweisung gleichzeitig aus.
- Datenvolumen:Jeder Thread bewegt 4 Bytes. Gesamtdatenvolumen =32 Threads × 4 Bytes = 128 Bytes .
- Speichertransaktionen:Die LSU (Load Store Unit) fasst diese 128 Bytes zu einer einzigen Videospeichertransaktion zusammen.
- Engpassanalyse:Obwohl Speicherzusammenführung genutzt wird, ist die Befehlseffizienz gering. Um 128 Byte Daten zu übertragen, benötigt der Streaming-Multiprozessor (SM) einen Befehlsausgabezyklus. Bei großen Datenmengen ist die Befehlsausgabeeinheit überlastet und wird zum Flaschenhals.
Code (v1_f32.cu):
%%writefile v1_f32.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
__global__ void elementwise_add_f32_kernel(float *a, float *b, float *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = a[idx] + b[idx];
}
}
void elementwise_add_f32(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f32_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32, "FP32 Add");
}Version 2: FP32x4 Vektorisiert
Optimierungsmethode: Verwenden Sie den Typ float4, um die Generierung von 128-Bit-Ladeanweisungen zu erzwingen.
Detaillierte Analyse der Prinzipien (zentrale Optimierungspunkte):
- Befehlsebene:Der Scheduler gibt eine LD.E.128 (128-Bit-Lade-)Anweisung aus.
- Ausführungsschicht (Warp):Der Warp hat 32 Threads, die gleichzeitig laufen, aber diesmal bewegt sich jeder Thread 16 Bytes (float4).
- Datenvolumen:Gesamtes Datenvolumen = 32 Threads x 16 Bytes = 512 Bytes.
- Speichertransaktionen:Wenn die LSU eine kontinuierliche Anforderung von 512 Bytes erkennt, initiiert sie vier aufeinanderfolgende Speichertransaktionen von jeweils 128 Bytes.
- Effizienzvergleich:Basisversion: 1 Befehl = 128 Bytes. Vektorisiert: 1 Befehl = 512 Bytes.
- abschließend:Die Effizienz des Unterrichts wird um das Vierfache verbessert. SM benötigt nur ein Viertel der ursprünglichen Befehlsanzahl, um dieselbe Speicherbandbreite voll auszunutzen. Dadurch wird die Befehlsverteilungseinheit vollständig entlastet, und der Flaschenhals verlagert sich tatsächlich zur Speicherbandbreite.
Code (v2_f32x4.cu):
%%writefile v2_f32x4.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
#define FLOAT4(value) (reinterpret_cast<float4 *>(&(value))[0])
__global__ void elementwise_add_f32x4_kernel(float *a, float *b, float *c, int N) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int idx = 4 * tid;
if (idx + 3 < N) {
float4 reg_a = FLOAT4(a[idx]);
float4 reg_b = FLOAT4(b[idx]);
float4 reg_c;
reg_c.x = reg_a.x + reg_b.x;
reg_c.y = reg_a.y + reg_b.y;
reg_c.z = reg_a.z + reg_b.z;
reg_c.w = reg_a.w + reg_b.w;
FLOAT4(c[idx]) = reg_c;
}
else if (idx < N){
for (int i = 0; i < 4; i++){
if (idx + i < N) {
c[idx + i] = a[idx + i] + b[idx + i];
}
}
}
}
void elementwise_add_f32x4(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 4;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f32x4_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32x4, "FP32x4 Add");Phase Zwei: FP16-Optimierungsreihe
3. Version 3: FP16 Baseline (Halbpräzisions-Skalar)
Verwenden Sie die Hälfte (FP16), um Videospeicher zu sparen.
Detaillierte Analyse der zugrunde liegenden Prinzipien (Warum ist es so langsam?):
- Speicherzugriffsmodus:Im Code ist idx fortlaufend, sodass der Zugriff durch 32 Threads vollständig zusammengefasst wird.
- Datenvolumen:32 Threads × 2 Bytes = 64 Bytes (Gesamtanforderungen für einen Warp).
- Hardwareverhalten:Der Speichercontroller (LSU) generiert zwei 32-Byte-Speichersektortransaktionen. Hinweis: Hierbei wird keine Bandbreite verschwendet; alle übertragenen Daten sind gültig.
Der eigentliche Flaschenhals:
1. Anweisungsgebunden:
Das ist der Hauptgrund. Um die Videospeicherbandbreite voll auszunutzen, müssen wir kontinuierlich Daten verschieben.In dieser Version kann ein Befehl nur 64 Bytes verschieben.Im Vergleich zur float4-Version (die 512 Bytes pro Befehl verschiebt) beträgt die Befehlseffizienz dieser Version nur 1/8.
als ErgebnisSelbst wenn der Befehlsverteiler des SM mit voller Geschwindigkeit läuft, kann die Datenmenge der ausgegebenen Befehle die enorme Videospeicherbandbreite nicht vollständig ausnutzen. Es ist, als würde der Vorarbeiter sich die Kehle heiser schreien (Befehle erteilen), aber die Arbeiter können trotzdem nicht genügend Ziegelsteine (Daten) bewegen.
2. Die Granularität der Speichertransaktionen ist zu gering:
* Physikalische Schicht:Die kleinste Einheit der Videospeicherübertragung ist ein 32-Byte-Sektor; Cache-Schichten werden typischerweise in Einheiten von 128-Byte-Cache-Zeilen verwaltet.
* Status quo:Obwohl die vom Warp angeforderten 64 Byte Daten zwei Sektoren füllten, nutzte er nur die Hälfte der 128 Byte großen Cache-Zeile.
* als Ergebnis:Diese Datenübertragung in kleinen Paketen („Einzelhandelsmodell“) ist bei diesem Durchsatz im Vergleich zur gleichzeitigen Übertragung von vier vollständigen Cache-Zeilen (512 Byte), wie sie mit float4 erfolgt, äußerst ineffizient und kann die hohe Latenz des Videospeichers nicht kompensieren. Um die Bandbreite des Videospeichers voll auszuschöpfen, ist eine kontinuierliche Datenübertragung erforderlich.
Code (v3_f16.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) { int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>( reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}4.Version 4: FP16 Vektorisiert (Half2)
Führe half2 ein.
Detaillierte Analyse der Prinzipien:
- Daten:half2 (4 Bytes).
- Befehlsebene:Führe einen 32-Bit-Ladebefehl aus.
- Rechenschicht:Mit __hadd2 (SIMD) können zwei Additionen gleichzeitig mit einem einzigen Befehl durchgeführt werden.
- Status Quo:Die Speicherzugriffseffizienz entspricht der FP32-Baseline.(1 Befehl = 128 Bytes). Obwohl es schneller als V3 ist, erreicht es immer noch nicht den Spitzenwert von 512 Bytes/Befehl von float4.
Code (v4_f16x2.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}Im Anhang finden Sie ein Beispiel für die Ausführung von Hyper Jupyter.
5. Version 5: FP16x8 Unroll (Manuelles Loop-Unroll)
Um die Leistung weiter zu untersuchen, haben wir versucht, einen Thread acht Hälften verarbeiten zu lassen (d. h. vier half2).
Detaillierte Analyse der zugrunde liegenden Prinzipien (Wo liegen die Verbesserungen gegenüber V4?):
- üben:Schreiben Sie manuell vier aufeinanderfolgende Zeilen mit half2-Leseoperationen in den Code.
- Wirkung:Der Scheduler gibt nacheinander vier 32-Bit-Ladebefehle aus.
- Einkommen:ILP (Instruction-Level Parallelism) und Latenzmaskierung. Probleme mit V4 (FP16x2):Eine Anweisung wird ausgeführt → auf die Rückgabe der Daten gewartet (Stillstand) → anschließend wird die Berechnung durchgeführt. Während der Wartezeit ist die GPU inaktiv. Verbesserungen in Version 5:Es werden vier Befehle in schneller Folge ausgeführt. Während die GPU noch auf die ersten Daten aus dem Speicher wartet, hat sie bereits den zweiten, dritten und vierten Befehl ausgeführt. Dadurch werden die Lücken in der Befehlspipeline optimal genutzt und die teure Speicherlatenz kaschiert.
- Einschränkungen:Die Befehlsdichte bleibt sehr hoch.Obwohl ILP verwendet wurde, wurden im Wesentlichen weiterhin vier 32-Bit-„Cart-Transports“ initiiert. Um 128 Bit Daten zu übertragen, benötigte SM nach wie vor vier Befehlsausgabezyklen. Der Befehlsaussteller war stark ausgelastet und konnte den Effekt, „mit einem einzigen Befehl einen Berg zu versetzen“, nicht erzielen.
Code (v5_f16x8.cu):
%%writefile v5_f16x8.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
if (idx + 7 < N) {
half2 ra0 = HALF2(a[idx + 0]);
half2 ra1 = HALF2(a[idx + 2]);
half2 ra2 = HALF2(a[idx + 4]);
half2 ra3 = HALF2(a[idx + 6]);
half2 rb0 = HALF2(b[idx + 0]);
half2 rb1 = HALF2(b[idx + 2]);
half2 rb2 = HALF2(b[idx + 4]);
half2 rb3 = HALF2(b[idx + 6]);
HALF2(c[idx + 0]) = __hadd2(ra0, rb0);
HALF2(c[idx + 2]) = __hadd2(ra1, rb1);
HALF2(c[idx + 4]) = __hadd2(ra2, rb2);
HALF2(c[idx + 6]) = __hadd2(ra3, rb3);
}
else if (idx < N) {
for(int i = 0; i < 8; i++){
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8, "FP16x8 Add");
}Im Anhang finden Sie ein Beispiel für die Ausführung von Hyper Jupyter.
Version 6: FP16x8-Paket (Ultimative Optimierung)
Dies ist die Obergrenze für die elementweise Operatoroptimierung. Wir kombinieren die „hohe Bandbreite beim Transport“ von V2 mit der „Befehlsparallelität“ von V5 und führen Register-Caching-Technologie ein.
Detaillierte Analyse der Kernmagie:
1. Adressfälschung:
* Frage:Unsere Daten sind vom Typ half, und die GPU verfügt nicht über einen nativen load_8_halfs-Befehl.
* Gegenmaßnahmen: Der Datentyp float4 belegt genau 128 Bit (16 Byte), und 8 Hälften belegen ebenfalls 128 Bit.
* bedienen:Wir haben die Adresse des halben Arrays (reinterpret_cast) zwangsweise in float4* umgewandelt.
* Wirkung:Wenn der Compiler auf `float4*` stößt, erzeugt er eine Zeile. LD.E.128 Anleitung. Dem Videospeichercontroller ist es egal, was Sie verschieben; er verschiebt immer nur 128-Bit-Binärströme gleichzeitig.
2. Register-Array:
half pack_a[8]: Obwohl dieses Array im Kernel definiert ist, wird es aufgrund seiner festen Größe und geringen Größe direkt in die Registerdatei der GPU anstatt in den langsamen lokalen Speicher abgebildet. Dies entspricht dem Öffnen eines schnellen Caches.
3. Neuinterpretation von Erinnerungen:
Makrodefinition LDST128BITS:Das ist der Kern des Codes. Er wandelt die Adresse einer beliebigen Variablen in einen float4*-Wert um und ruft deren Wert ab.
LDST128BITS(pack_a[0])=LDST128BITS(a[idx]);
* Rechte Seite:Gehe zu Global Memory a[idx] und rufe 128 Bit Daten ab.
* linksSchreibe diese 128-Bit-Daten direkt in das Array pack_a (beginnend mit dem 0. Element, wobei 8 Elemente sofort gefüllt werden).
* Ergebnis:Ein einziger Befehl genügt, um die Übertragung von 8 Datenelementen abzuschließen.
Code (v6_f16x8_pack.cu):
%%writefile v6_f16x8_pack.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define LDST128BITS(value) (reinterpret_cast<float4 *>(&(value))[0])
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_pack_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
half pack_a[8], pack_b[8], pack_c[8];
if ((idx + 7) < N) {
LDST128BITS(pack_a[0]) = LDST128BITS(a[idx]);
LDST128BITS(pack_b[0]) = LDST128BITS(b[idx]);
#pragma unroll
for (int i = 0; i < 8; i += 2) {
HALF2(pack_c[i]) = __hadd2(HALF2(pack_a[i]), HALF2(pack_b[i]));
}
LDST128BITS(c[idx]) = LDST128BITS(pack_c[0]);
}
else if (idx < N) {
for (int i = 0; i < 8; i++) {
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8_pack(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_pack_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8_pack, "FP16x8 Pack Add");
}Phase 3: Kombination von Benchmarks und visueller Analyse
Um den Optimierungseffekt umfassend zu bewerten, haben wir einen vollständigen Szenario-Testplan entworfen, der latenzempfindliche (kleine Daten) bis bandbreitenempfindliche (große Daten) Szenarien abdeckt.
1. Entwicklung einer Teststrategie
Wir haben drei repräsentative Datensätze ausgewählt, die jeweils unterschiedlichen Engpässen auf GPU-Speicherebene entsprechen:
- Cache-Latenz (1 Mio. Elemente):Die Datengröße ist extrem klein (4 MB), und der L2-Cache ist vollständig belegt.Im Mittelpunkt des Tests stehen der Overhead beim Kernelstart und die Effizienz der Befehlsausgabe.
- L2-Durchsatz (16 Mio. Elemente):Die Datengröße ist moderat (64 MB) und liegt nahe an der Kapazitätsgrenze des L2-Caches.Kern des Tests ist der Lese- und Schreibdurchsatz des L2-Caches.
- VRAM-Bandbreite (256M Elemente):Das Datenvolumen ist enorm (1 GB) und übersteigt den L2-Cache bei Weitem. Die Daten müssen aus dem Videospeicher (VRAM) verschoben werden.Dies ist das eigentliche Schlachtfeld für Großunternehmen; die entscheidende Bewährungsprobe besteht darin, ob die physische Speicherbandbreite voll ausgenutzt wird.
2. Benchmark-Skript (Python)
Das Skript lädt direkt die oben definierte .cu-Datei und berechnet automatisch die Bandbreite (GB/s) und die Latenz (ms).
import torch
from torch.utils.cpp_extension import load
import time
import os
# ==========================================
# 0. 准备工作
# ==========================================
# 确保你的文件路径和笔记里写的一致
kernel_dir = "."
flags = ["-O3", "--use_fast_math", "-U__CUDA_NO_HALF_OPERATORS__"]
print(f"Loading kernels from {kernel_dir}...")
# ==========================================
# 1. 分别加载 6 个模块
# ==========================================
# 我们分别编译加载,确保每个模块有独立的命名空间,避免符号冲突
try:
mod_v1 = load(name="v1_lib", sources=[os.path.join(kernel_dir, "v1_f32.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v2 = load(name="v2_lib", sources=[os.path.join(kernel_dir, "v2_f32x4.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v3 = load(name="v3_lib", sources=[os.path.join(kernel_dir, "v3_f16.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v4 = load(name="v4_lib", sources=[os.path.join(kernel_dir, "v4_f16x2.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v5 = load(name="v5_lib", sources=[os.path.join(kernel_dir, "v5_f16x8.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v6 = load(name="v6_lib", sources=[os.path.join(kernel_dir, "v6_f16x8_pack.cu")], extra_cuda_cflags=flags, verbose=False)
print("All Kernels Loaded Successfully!\n")
except Exception as e:
print("\n[Error] 加载失败!请检查目录下是否有这 6 个 .cu 文件,且代码已修正语法错误。")
print(f"详细报错: {e}")
raise e
# ==========================================
# 2. Benchmark 工具函数
# ==========================================
def run_benchmark(func, a, b, tag, out, warmup=10, iters=1000):
# 重置输出
out.fill_(0)
# Warmup (预热,让 GPU 进入高性能状态)
for _ in range(warmup):
func(a, b, out)
torch.cuda.synchronize()
# Timing (计时)
start = time.time()
for _ in range(iters):
func(a, b, out)
torch.cuda.synchronize()
end = time.time()
# Metrics (指标计算)
avg_time_ms = (end - start) * 1000 / iters
# Bandwidth Calculation: (Read A + Read B + Write C)
element_size = a.element_size() # float=4, half=2
total_bytes = 3 * a.numel() * element_size
bandwidth_gbs = total_bytes / (avg_time_ms / 1000) / 1e9
# Check Result (打印前 2 个元素用于验证正确性)
# 取数据回 CPU 检查
out_val = out.flatten()[:2].cpu().float().tolist()
out_val = [round(v, 4) for v in out_val]
print(f"{tag:<20} | Time: {avg_time_ms:.4f} ms | BW: {bandwidth_gbs:>7.1f} GB/s | Check: {out_val}")
# ==========================================
# 3. 运行测试 (从小到大)
# ==========================================
# 1M = 2^20
shapes = [
(1024, 1024), # 1M elems (Cache Latency)
(4096, 4096), # 16M elems (L2 Cache 吞吐)
(16384, 16384), # 256M elems (显存带宽压测)
]
print(f"{'='*90}")
print(f"Running Benchmark on {torch.cuda.get_device_name(0)}")
print(f"{'='*90}\n")
for S, K in shapes:
N = S * K
print(f"--- Data Size: {N/1e6:.1f} M Elements ({N*4/1024/1024:.0f} MB FP32) ---")
# --- FP32 测试 ---
a_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
b_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
c_f32 = torch.empty_like(a_f32)
# 注意:这里调用的是 .add 方法,因为你在 PYBIND11 里面定义的名字是 "add"
run_benchmark(mod_v1.add, a_f32, b_f32, "V1 (FP32 Base)", c_f32)
run_benchmark(mod_v2.add, a_f32, b_f32, "V2 (FP32 Vec)", c_f32)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f32, b_f32, "PyTorch (FP32)", c_f32)
# --- FP16 测试 ---
print("-" * 60)
a_f16 = a_f32.half()
b_f16 = b_f32.half()
c_f16 = c_f32.half()
run_benchmark(mod_v3.add, a_f16, b_f16, "V3 (FP16 Base)", c_f16)
run_benchmark(mod_v4.add, a_f16, b_f16, "V4 (FP16 Half2)", c_f16)
run_benchmark(mod_v5.add, a_f16, b_f16, "V5 (FP16 Unroll)", c_f16)
run_benchmark(mod_v6.add, a_f16, b_f16, "V6 (FP16 Pack)", c_f16)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f16, b_f16, "PyTorch (FP16)", c_f16)
print("\n")
3. Daten aus der Praxis: Leistung der RTX 5090
Nachfolgend die tatsächlichen Daten, die durch Ausführen des obigen Codes auf einer NVIDIA GeForce RTX 5090 erhalten wurden:
==========================================================================================
Running Benchmark on NVIDIA GeForce RTX 5090
==========================================================================================---
Data Size: 1.0 M Elements (4 MB FP32) ---
V1 (FP32 Base) | Time: 0.0041 ms | BW: 3063.1 GB/s | Check: [0.8656, 1.9516]
V2 (FP32 Vec) | Time: 0.0041 ms | BW: 3066.1 GB/s | Check: [0.8656, 1.9516]
PyTorch (FP32) | Time: 0.0044 ms | BW: 2868.9 GB/s | Check: [0.8656, 1.9516]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V4 (FP16 Half2) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V5 (FP16 Unroll) | Time: 0.0041 ms | BW: 1533.5 GB/s | Check: [0.8657, 1.9512]
V6 (FP16 Pack) | Time: 0.0041 ms | BW: 1533.6 GB/s | Check: [0.8657, 1.9512]
PyTorch (FP16) | Time: 0.0044 ms | BW: 1431.6 GB/s | Check: [0.8657, 1.9512]
--- Data Size: 16.8 M Elements (64 MB FP32) ---
V1 (FP32 Base) | Time: 0.1183 ms | BW: 1702.2 GB/s | Check: [-3.2359, -0.1663]
V2 (FP32 Vec) | Time: 0.1186 ms | BW: 1698.1 GB/s | Check: [-3.2359, -0.1663]
PyTorch (FP32) | Time: 0.1176 ms | BW: 1711.8 GB/s | Check: [-3.2359, -0.1663]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V4 (FP16 Half2) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V5 (FP16 Unroll) | Time: 0.0348 ms | BW: 2892.8 GB/s | Check: [-3.2363, -0.1664]
V6 (FP16 Pack) | Time: 0.0348 ms | BW: 2892.6 GB/s | Check: [-3.2363, -0.1664]
PyTorch (FP16) | Time: 0.0148 ms | BW: 6815.7 GB/s | Check: [-3.2363, -0.1664]
--- Data Size: 268.4 M Elements (1024 MB FP32) ---
V1 (FP32 Base) | Time: 2.0432 ms | BW: 1576.5 GB/s | Check: [0.4839, -2.6795]
V2 (FP32 Vec) | Time: 2.0450 ms | BW: 1575.2 GB/s | Check: [0.4839, -2.6795]
PyTorch (FP32) | Time: 2.0462 ms | BW: 1574.3 GB/s | Check: [0.4839, -2.6795]
------------------------------------------------------------
V3 (FP16 Base) | Time: 1.0173 ms | BW: 1583.2 GB/s | Check: [0.4839, -2.6797]
V4 (FP16 Half2) | Time: 1.0249 ms | BW: 1571.5 GB/s | Check: [0.4839, -2.6797]
V5 (FP16 Unroll) | Time: 1.0235 ms | BW: 1573.6 GB/s | Check: [0.4839, -2.6797]
V6 (FP16 Pack) | Time: 1.0236 ms | BW: 1573.4 GB/s | Check: [0.4839, -2.6797]
PyTorch (FP16) | Time: 1.0251 ms | BW: 1571.2 GB/s | Check: [0.4839, -2.6797]
4. Dateninterpretation
Diese Daten verdeutlichen die physikalischen Eigenschaften der RTX 5090 unter verschiedenen Lasten:
Phase 1: Sehr kleiner Maßstab (1 Mio. Elemente / 4 MB)
- Phänomen:Alle Versionen wiesen eine bemerkenswert konstante Ausführungszeit von 0,0041 ms auf.
- die Wahrheit:Dies ist eine latenzbegrenzte Situation. Unabhängig von der Datengröße beträgt der feste Startaufwand der GPU zum Starten eines Kernels etwa 4 Mikrosekunden. Aufgrund dieser zeitlichen Begrenzung ist das Datenvolumen für FP16 nur halb so groß wie für FP32, daher ist auch die berechnete Bandbreite nur halb so groß. Gemessen wird hier nicht die Übertragungsgeschwindigkeit, sondern die „Startgeschwindigkeit“.
Phase Zwei: Mittlere Größe (16 Millionen Elemente / 64 MB vs. 32 MB)
Dieser Bereich veranschaulicht die Funktion des L2-Caches am besten:
- FP32 (64 MB):Das gesamte Datenvolumen A+B+C beträgt ca. 192 MB. Dies übersteigt die L2-Cache-Kapazität der RTX 5090 (ca. 128 MB). Der Datenüberlauf zwang das System zum Lesen und Schreiben in den VRAM, wodurch die Bandbreite auf 1700 GB/s (nahe der physikalischen Bandbreite des Videospeichers) sank.
- FP16 (32 MB):Gesamtes Datenvolumen.Es passt perfekt in den L2-Cache! Die Daten zirkulieren im Cache, wodurch die Bandbreite auf 2890 GB/s ansteigt.
- Die dunkle Magie von PyTorch:PyTorch erreichte in FP16 6815 GB/s. Dies beweist, dass in einem reinen Cache-Szenario die Befehlspipeline-Optimierung des JIT-Compilers einem einfachen, handgeschriebenen Kernel immer noch überlegen ist.
Phase 3: Großflächig (268 Mio. Elemente / 1024 MB)
Dies ist ein reales Szenario für das Training/die Inferenz mit einem großen Modell (Speicherbegrenzung):
- Alle Wesen sind gleich:Ob FP32 oder FP16, ob Baseline oder Optimized, die Bandbreite ist immer auf 1570-1580 GB/s festgelegt.
- Physische Mauer:Wir haben die physikalische Grenze der GDDR7-Speicherbandbreite der RTX 5090 erreicht. Die Bandbreite ist begrenzt; eine Steigerung ist nicht möglich.
- Der Wert der Optimierung:Obwohl die Bandbreite gleich blieb.Es stellte sich jedoch heraus, dass die FP16-Zeit (1,02 ms) nur halb so lang war wie die FP32-Zeit (2,04 ms).Durch die Halbierung des Datenvolumens bei gleichzeitiger Maximierung der Bandbreite wird eine zweifache Beschleunigung der gesamten Datenübertragung erreicht. V6 vs V3Während V3 scheinbar mit voller Kapazität läuft, liegt dies an der automatischen Optimierung durch den NVCC-Compiler und der Latenzmaskierung der GPU-Hardware. Bei komplexeren Operatoren (wie z. B. FlashAttention) garantiert die V6-Implementierung jedoch eine optimale Leistung.
Häufig gestellte Fragen: Detaillierte Ableitung des Parameterdesigns
In allen Kernels dieses Experiments haben wir den Parameter threads_per_block einheitlich auf 256 gesetzt. Diese Zahl wurde nicht zufällig gewählt, sondern stellt eine mathematisch optimale Lösung zwischen Hardwarebeschränkungen und Scheduling-Effizienz dar.
F: Warum ist threads_per_block immer auf 128 oder 256 gesetzt?
A: Dies ist ein „optimaler Bereich“, der durch vier Screening-Stufen ermittelt wurde.
Wir betrachten den Auswahlprozess der Blockgröße als einen Trichter, der Schicht für Schicht filtert:
1. Warp-Ausrichtung -> Muss ein Vielfaches von 32 sein
Die kleinste Ausführungseinheit einer GPU ist ein Warp (Thread-Bundle), der aus 32 aufeinanderfolgenden Threads besteht (SIMT-Architektur, Single Instruction Multithreading).
- Harte Einschränkungen:Wenn Sie 31 Threads anfordern, plant die Hardware trotzdem einen vollständigen Warp-Vorgang ein. Obwohl die verbleibenden Thread-Positionen ungenutzt sind, belegen sie weiterhin dieselben Hardware-Ressourcen.
- abschließend: Die Blockgröße sollte idealerweise ein Vielfaches von 32 sein, um Rechenleistung nicht zu verschwenden.
2. Belegungsetage -> Muss >= 96 betragen
Auslastung = Anzahl der gleichzeitig auf dem SM ausgeführten Threads / Maximale Anzahl der vom SM unterstützten Threads.
- Hintergrund:Um die Speicherlatenz zu minimieren, benötigen wir eine ausreichende Anzahl aktiver Warps. Ist die Blockgröße zu klein, wird das Limit „Max Blocks“ des SM vor dem Limit „Max Threads“ erreicht.
- Schätzung:Gängige Architekturen (wie Turing/Ampere/Ada) erfordern typischerweise: Blockgröße > (maximale Anzahl an Threads im SM / maximale Anzahl an Blöcken im SM). Übliche Verhältnisse sind 64 oder 96.
- abschließend:Um theoretisch eine 100%-Auslastung zu erreichen, sollte die Blockgröße nicht weniger als 96 betragen.
3. Atomarität der Ablaufplanung -> Sperren 128, 256, 512
Ein Block ist die kleinste atomare Einheit, die einem SM zugewiesen wird. Der SM muss in der Lage sein, eine ganzzahlige Anzahl von Blöcken vollständig zu verarbeiten.
- Teilbarkeit:Um die Kapazität des SM nicht zu verschwenden, sollte die Blockgröße idealerweise durch die maximale Thread-Kapazität des SM teilbar sein.
- Filter:Die maximale Kapazität von SMs gängiger Architekturen beträgt typischerweise 1024, 1536, 2048 usw. Ihr gemeinsamer Teiler ist üblicherweise 512. Durch die Kombination der beiden vorherigen Schritte (>=96 und ein Vielfaches von 32) reduziert sich unsere Kandidatenliste auf: 128, 192, 256, 384, 512.
4. Registrierungsdruck -> 512+ ausschließen
Dies ist die endgültige "Obergrenze".
- Harte Einschränkungen:Die Gesamtzahl der für jeden Block verfügbaren Register ist begrenzt (die Gesamtzahl der Register im SM beträgt typischerweise 64K 32-Bit).
- Risiko:Ist die Blockgröße groß (z. B. 512) und der Kernel etwas komplexer (jeder Thread verwendet mehrere Register), dann tritt die Situation ein, in der 512 * Regs/Thread > Max_Regs_Per_Block.
- als Ergebnis:Startvorgang fehlgeschlagen: Direkte Fehlermeldung. Registerüberlauf: Registerüberlauf in langsamen lokalen Speicher, was zu einer Leistungskaskade führt.
- abschließend:Aus Sicherheitsgründen vermeiden wir im Allgemeinen die Verwendung von 512 oder 1024. Die Adressen 128 und 256 gelten als die sichersten „Wüstengebiete“.
Zusammenfassen
Nach vier Ausscheidungsrunden blieben nur noch zwei Kandidaten übrig:
- 128Es zeichnet sich durch seine Vielseitigkeit aus.Selbst mit einem komplexen Kernel (der viele Register verwendet) kann ein erfolgreicher Start und eine gute Auslastung gewährleistet werden.
- 256:Elementweiser Operator bevorzugtBei einfachen Operatoren wie elementweisen Operationen ist der Registerdruck minimal. 256 bietet ein besseres Speicherzusammenführungspotenzial als 128 und reduziert den Aufwand für die Blockplanung.
Dies erklärt auch, warum in der naiven Implementierung, sobald wir threads_per_block = 256 bestimmen, auch grid_size bestimmt wird (sofern die Gesamtmenge N abdeckt).
Anhang: Jupyter-Ausführungsbeispiele









