Command Palette
Search for a command to run...
Online-Tutorial | SAM 3 Erreicht Segmentierung Von Hinweisen Mit Doppelter Leistungssteigerung Und Verarbeitet 100 Erkennungsobjekte in 30 Millisekunden

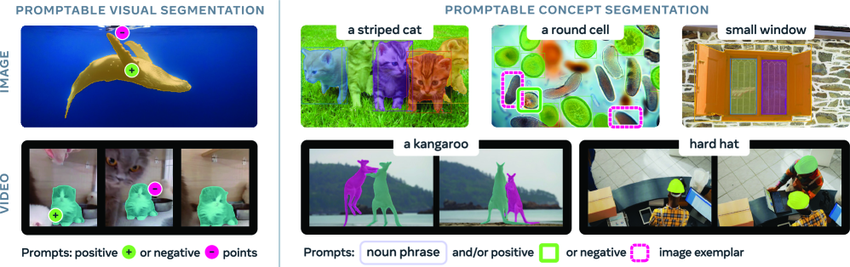
Die Fähigkeit, beliebige Objekte in visuellen Szenen zu identifizieren und zu segmentieren, ist eine entscheidende Grundlage für multimodale künstliche Intelligenz mit vielfältigen Anwendungsmöglichkeiten in Robotik, Content-Erstellung, Augmented Reality und Datenannotation. SAM (Segment Anything Model) ist ein universelles KI-Modell, das von Meta im April 2023 veröffentlicht wurde und eine hinweisbasierte Segmentierungsaufgabe für Bilder und Videos vorschlägt. Es unterstützt primär die Segmentierung einzelner Objekte anhand von Hinweisen wie Punkten, Begrenzungsrahmen oder Masken.
Obwohl die SAM- und SAM2-Modelle bedeutende Fortschritte bei der Bildsegmentierung erzielt haben, sind sie noch nicht in der Lage, alle Instanzen eines Konzepts innerhalb des Eingabeinhalts automatisch zu finden und zu segmentieren. Um diese Lücke zu schließen,Meta hat seine neueste Version, SAM 3, veröffentlicht, die nicht nur die Leistung ihres Vorgängers bei der cueable visual segmentation (PVS) deutlich übertrifft, sondern auch einen neuen Standard für cueable concept segmentation (PCS) Aufgaben setzt.
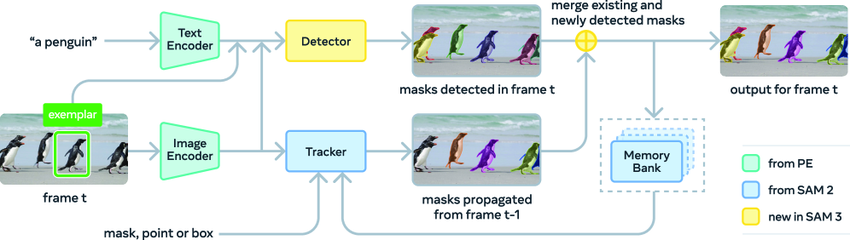
Die SAM 3-Architektur umfasst einen Detektor und einen Tracker, die beide denselben visuellen Encoder verwenden.Der Detektor basiert auf dem DETR-Framework und kann Text, geometrische Informationen oder Beispielbilder als bedingte Eingaben verarbeiten. Um die Herausforderungen der Konzepterkennung mit offenem Vokabular zu bewältigen, führten die Forscher einen separaten „Präsenzkopf“ ein, um die Erkennungs- und Lokalisierungsprozesse zu entkoppeln.
Der Tracker nutzt die Transformer-Encoder-Decoder-Architektur von SAM 2 und unterstützt Videosegmentierung und interaktive Optimierung. Durch die Trennung von Detektion und Tracking werden Konflikte zwischen den beiden Aufgaben effektiv vermieden: Der Detektor muss die Identitätsunabhängigkeit wahren, während der Tracker die Identität verschiedener Objekte im Video unterscheiden und beibehalten muss.
SAM 3 erzielte bei den Bild- und Video-PCS-Aufgaben des SA-Co-Benchmarks Ergebnisse auf dem neuesten Stand der Technik (SOTA) und bot eine doppelt so hohe Leistung wie sein Vorgänger.Darüber hinaus kann die neue Version auf der H200-GPU ein einzelnes Bild mit mehr als 100 Erkennungsobjekten in nur 30 Millisekunden verarbeiten.Das Modell kann auch auf den Bereich der 3D-Rekonstruktion erweitert werden und unterstützt Anwendungen wie die Vorschau von Einrichtungsideen, die kreative Videobearbeitung und die wissenschaftliche Forschung. Es bietet einen starken Impuls für die zukünftige Entwicklung der Computer Vision.
„SAM3: Visual Segmentation Model“ ist jetzt im Tutorial-Bereich der HyperAI-Website (hyper.ai) verfügbar. Starten Sie jetzt Ihre kreative Reise!
Link zum Tutorial:
Lesen Sie das Dokument:
https://hyper.ai/papers/2511.16719
Demolauf
1. Nachdem Sie die Startseite von hyper.ai aufgerufen haben, wählen Sie „SAM3: Visual Segmentation Model“ aus oder gehen Sie zur Seite „Tutorials“, um es auszuwählen. Klicken Sie anschließend auf „Dieses Tutorial online ausführen“.
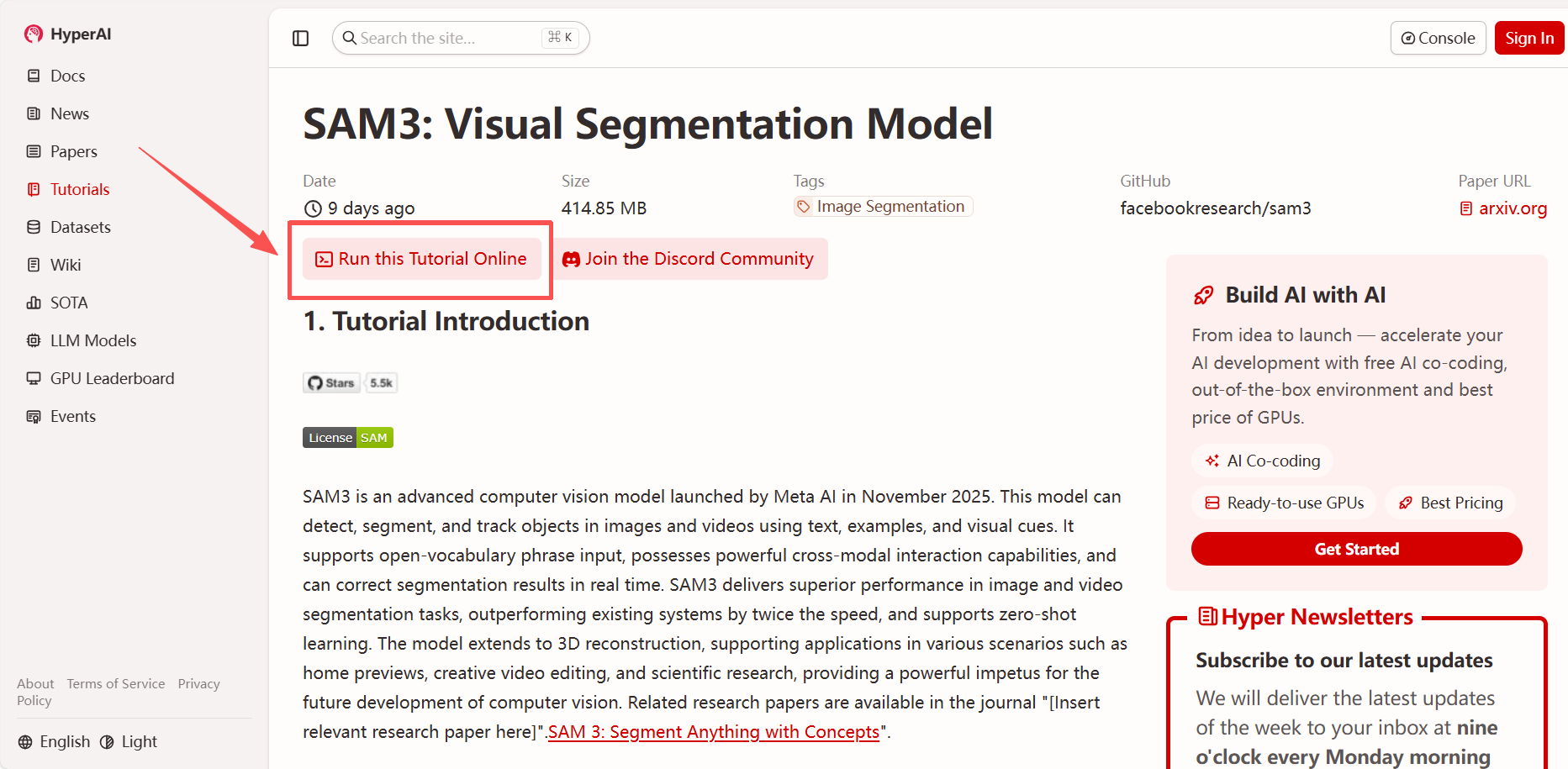
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
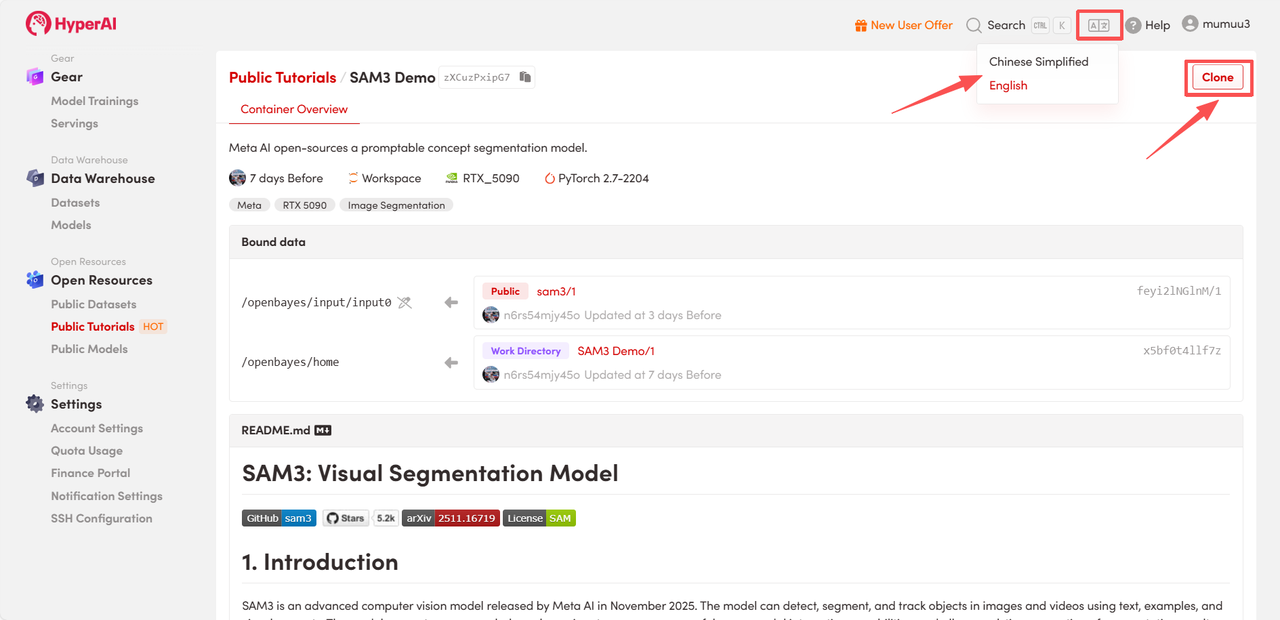
3. Wählen Sie die Images „NVIDIA GeForce RTX 5090“ und „PyTorch“ aus und wählen Sie je nach Bedarf „Pay As You Go“ oder „Tagesplan/Wochenplan/Monatsplan“. Klicken Sie anschließend auf „Auftragsausführung fortsetzen“.
HyperAI bietet Neukunden Registrierungsvorteile.Für nur $1 erhalten Sie 5 Stunden Rechenleistung einer RTX 5090 (ursprünglicher Preis $2,45).Die Ressource ist dauerhaft gültig.
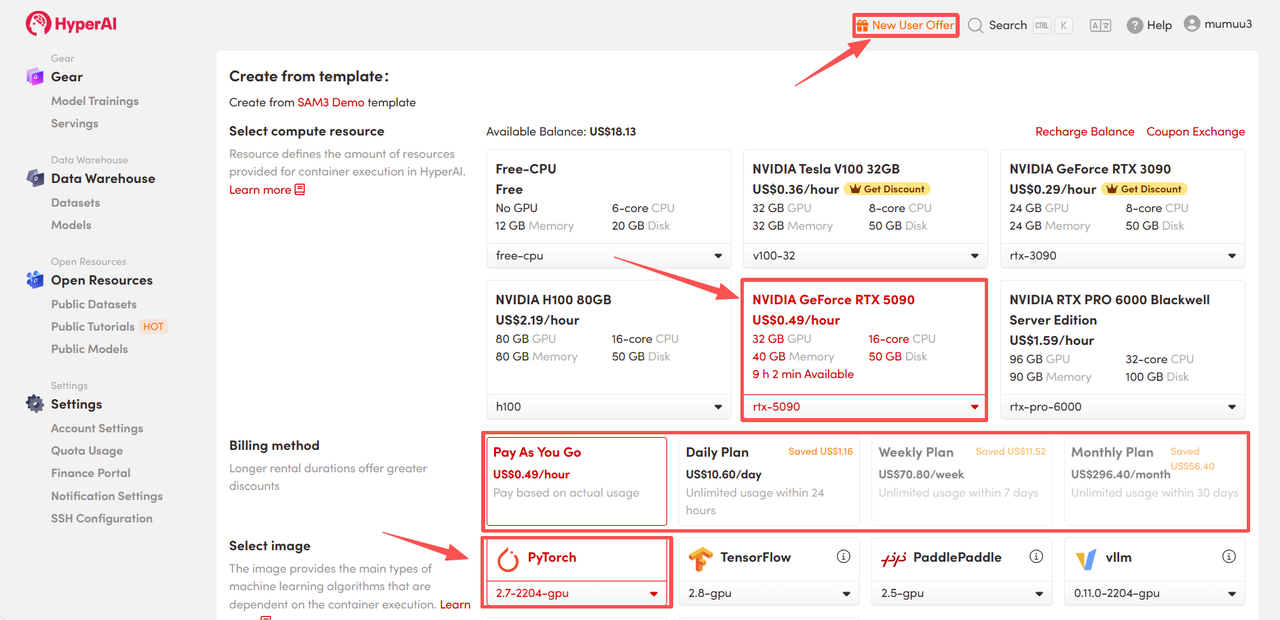
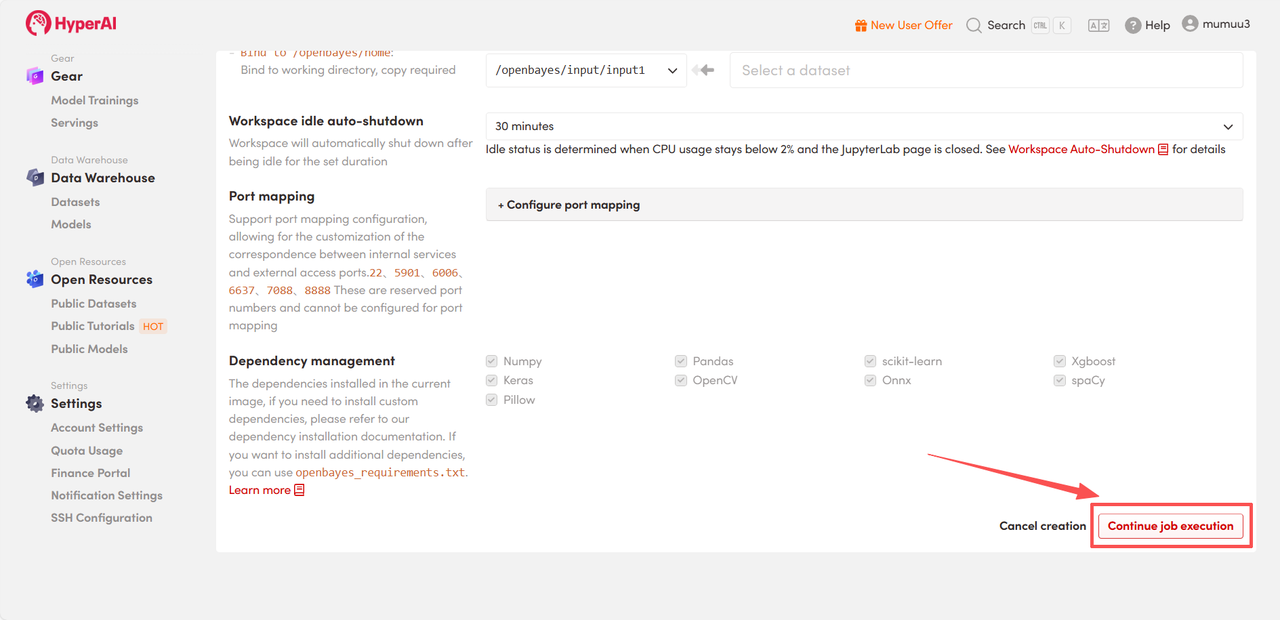
4. Warten Sie auf die Ressourcenzuweisung. Der erste Klonvorgang dauert etwa 3 Minuten. Sobald der Status auf „Wird ausgeführt“ wechselt, klicken Sie auf den Pfeil neben „API-Adresse“, um zur Demoseite zu gelangen.
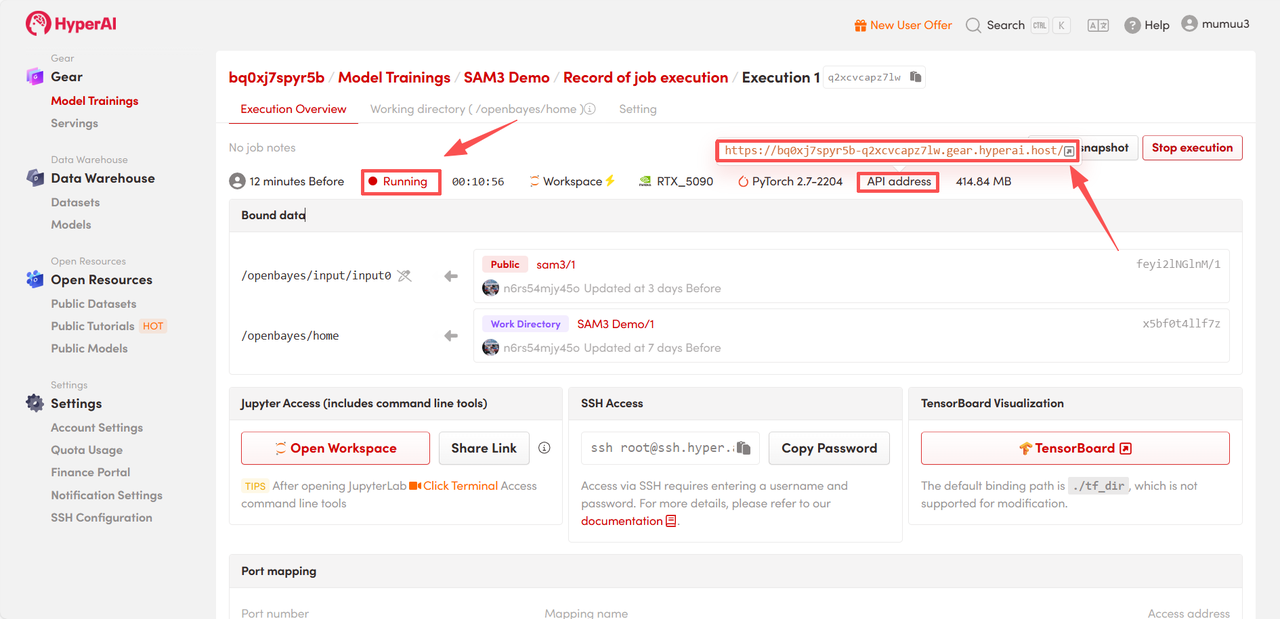
Effektdemonstration
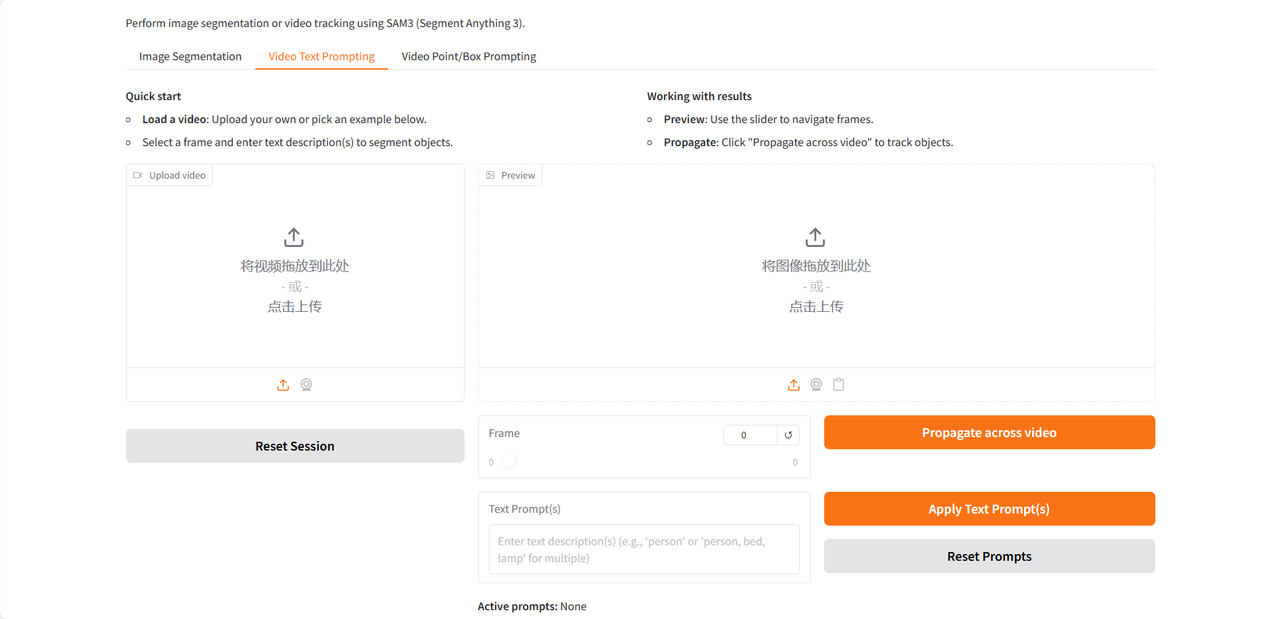
Die Demoseite bietet drei Funktionen: Bildsegmentierung, Video-Texteingabe und Video-Punkt-/Feldeingabe. Sie unterstützt ausschließlich englische Eingaben. Dieses Tutorial verwendet die Video-Texteingabe als Beispiel.
Nach dem Hochladen des Testvideos geben Sie die zu identifizierenden und zu segmentierenden Nominalphrasen in das Feld „Texteingabe(n)“ ein. Klicken Sie anschließend auf „Texteingabe(n) anwenden“ und „Auf Video übertragen“, um die Eingabeaufforderungen anzuwenden. Klicken Sie abschließend auf „MP4 für flüssige Wiedergabe rendern“, um ein Video mit dem hervorgehobenen Zielbereich zu generieren.
Werfen wir einen Blick auf den Test, den ich mit einem Ausschnitt aus dem Trailer des kürzlich erschienenen Films „Zootopia 2“ durchgeführt habe 👇
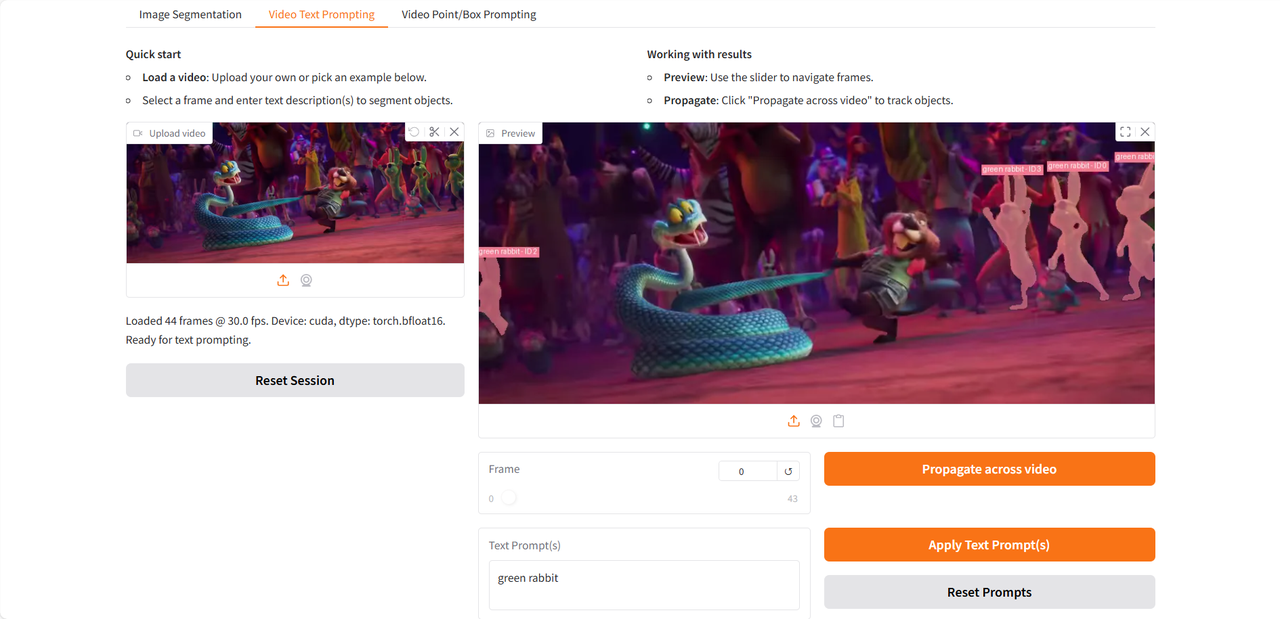
Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!
Link zum Tutorial:








