Command Palette
Search for a command to run...
Online-Tutorial | Deepseek-OCR Erreicht Modernste End-to-End-Modelle Mit Minimaler Anzahl Visueller Tokens

Bekanntermaßen steigt der Rechenaufwand bei der Verarbeitung von Texten mit Tausenden, Zehntausenden oder noch längeren Zeichen in großen Sprachmodellen oft dramatisch an und kann zu einem enormen Ressourcenverbrauch führen. Dies begrenzt auch die Effizienz von LLM bei der Verarbeitung von Texten mit hoher Informationsdichte.
Während die Branche kontinuierlich nach Möglichkeiten sucht, die Recheneffizienz zu optimieren, eröffnet Deepseek-OCR eine völlig neue Perspektive: Können wir Text effizient „lesen“ mit denselben Methoden, mit denen wir ihn „sehen“? Basierend auf dieser kühnen Idee haben Forscher entdeckt, dass ein einzelnes Bild mit Dokumenttext eine Fülle von Informationen mit weitaus weniger Symbolen darstellen kann als der entsprechende numerische Text. Das bedeutet: Wenn wir Textinformationen als Bilder in große Modelle zum Verstehen und Speichern einspeisen, lässt sich die Gesamteffizienz deutlich steigern. Dies ist weit mehr als nur Bildverarbeitung.Stattdessen handelt es sich um eine clevere „optische Kompression“ – die visuelle Modalitäten werden als effektives Kompressionsmedium für Textinformationen genutzt, wodurch ein Kompressionsverhältnis erreicht wird, das weit höher ist als das der traditionellen Textdarstellung.
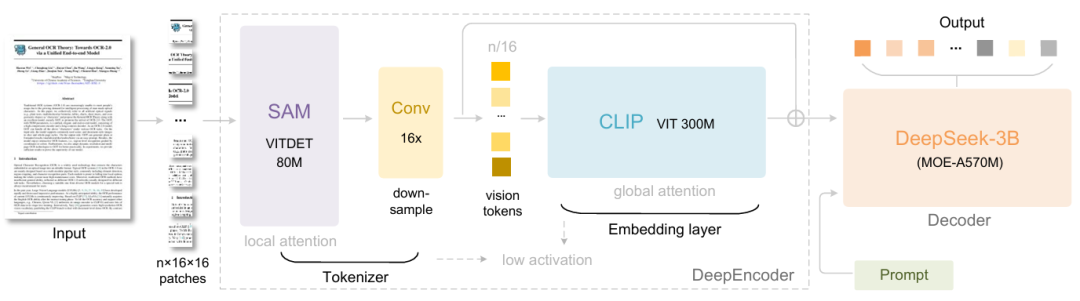
Genauer gesagt besteht DeepSeek-OCR aus zwei Komponenten: DeepEncoder und DeepSeek3B-MoE-A570M. Der Encoder (DeepEncoder) ist für die Extraktion von Bildmerkmalen, die Segmentierung von Wörtern und die Komprimierung visueller Darstellungen zuständig, während der Decoder (DeepSeek3B-MoE-A570M) verwendet wird, um die gewünschten Ergebnisse auf der Grundlage von Bildtags und Eingabeaufforderungen zu generieren.DeepEncoder ist als Kern-Engine so konzipiert, dass er bei hochauflösenden Eingaben einen niedrigen Aktivierungszustand beibehält und gleichzeitig eine hohe Komprimierungsrate erreicht, um sicherzustellen, dass die Anzahl der visuellen Token sowohl optimiert als auch einfach zu verwalten ist.Experimente zeigen, dass das Modell eine Dekodierungsgenauigkeit (OCR) von 971 TP3T erreicht, wenn die Anzahl der Text-Tokens weniger als das Zehnfache der Anzahl der visuellen Tokens beträgt (d. h. Kompressionsverhältnis < 10×). Selbst bei einem Kompressionsverhältnis von 20× liegt die OCR-Genauigkeit noch bei etwa 601 TP3T.
Die Veröffentlichung von DeepSeek-OCR ist nicht nur ein Fortschritt bei OCR-Aufgaben, sondern zeigt auch ein enormes Potenzial in zukunftsweisenden Forschungsbereichen wie der Komprimierung langer Kontexte und der Erforschung von Gedächtnisvergessensmechanismen in LLMs auf.
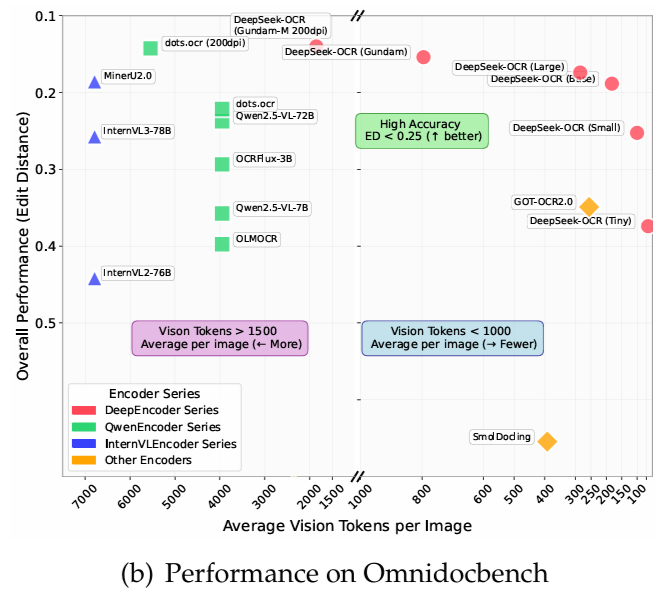
Auf OmniDocBench,Es übertrifft GOT-OCR2.0 (256 Tokens pro Seite) mit nur 100 visuellen Tokens.Darüber hinaus übertrifft es MinerU2.0 (durchschnittlich über 6000 Token pro Seite) bei Verwendung von weniger als 800 visuellen Token. In einer Produktionsumgebung kann DeepSeek-OCR täglich über 200.000 Seiten Trainingsdaten für LLMs/VLMs generieren (mit einem einzelnen A100-40G).
„DeepSeek-OCR: Visuelle Komprimierung ersetzt herkömmliche Zeichenerkennung“ ist jetzt im Bereich „Tutorials“ auf der HyperAI-Website (hyper.ai) verfügbar. Mit einem Klick einsetzen und ausprobieren!
* Link zum Tutorial:
* Verwandte Artikel ansehen:
https://hyper.ai/papers/DeepSeek_OCR
Demolauf
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie „DeepSeek-OCR: Visuelle Komprimierung statt herkömmlicher Zeichenerkennung“ oder gehen Sie zur Seite „Tutorials“ und wählen Sie „Dieses Tutorial online ausführen“.
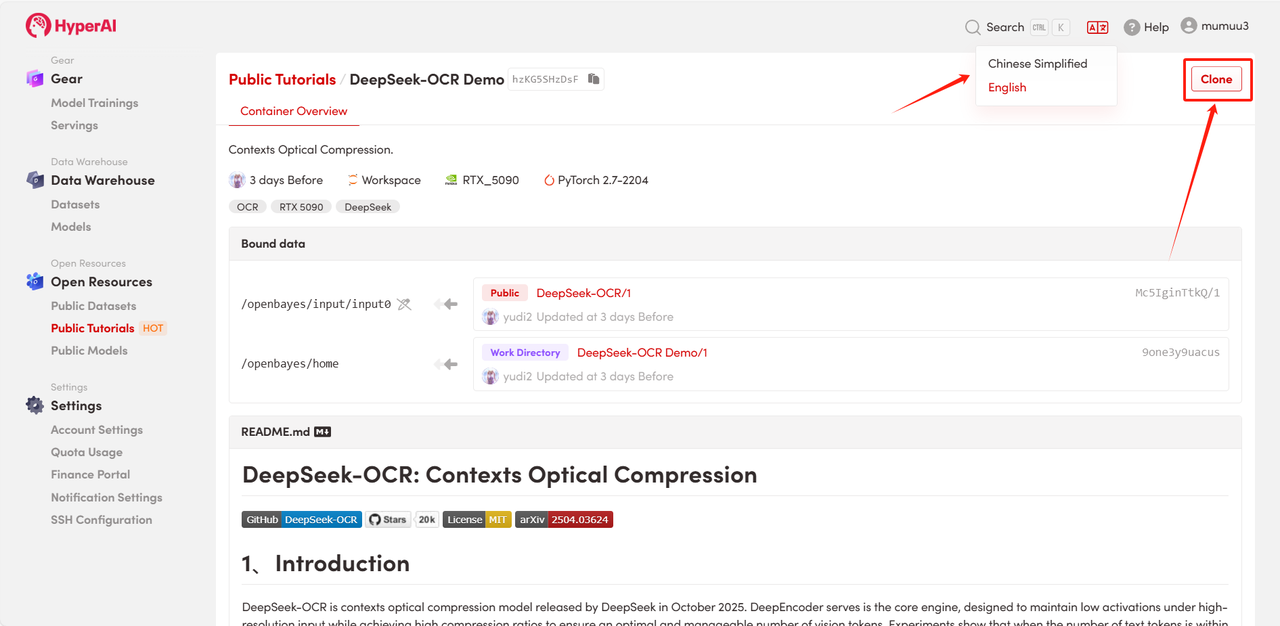
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
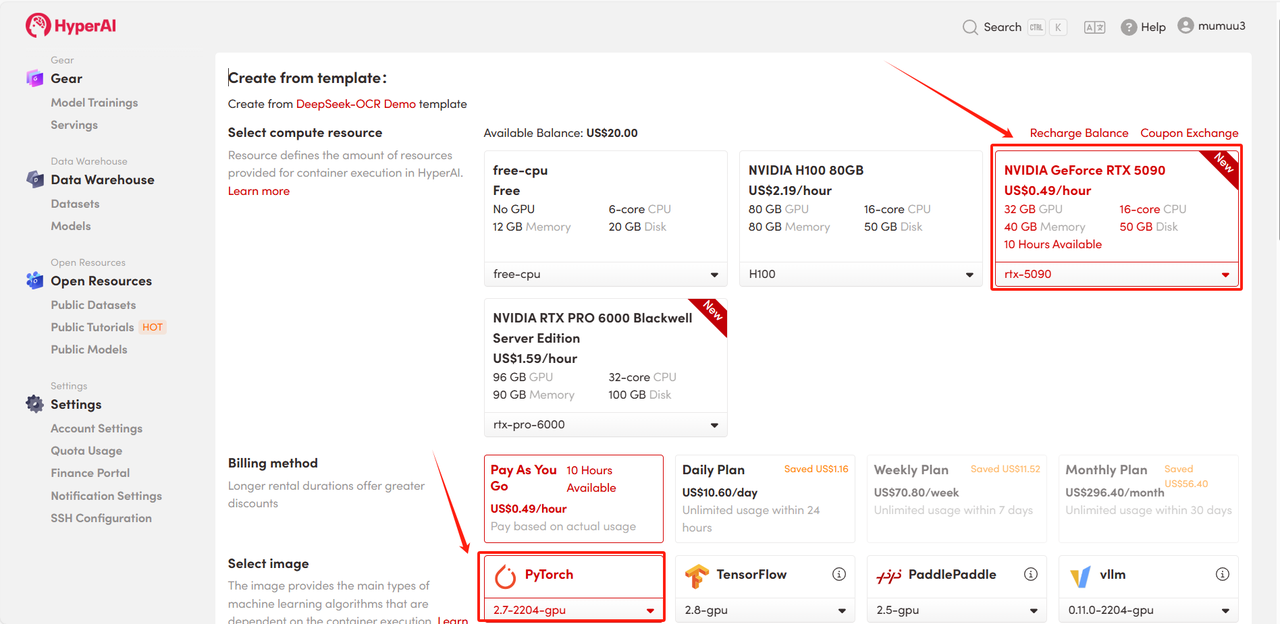
3. Wählen Sie die Images „NVIDIA GeForce RTX 5090“ und „PyTorch“ aus und wählen Sie je nach Bedarf „Pay As You Go“ oder „Tagesplan/Wochenplan/Monatsplan“. Klicken Sie anschließend auf „Auftragsausführung fortsetzen“.
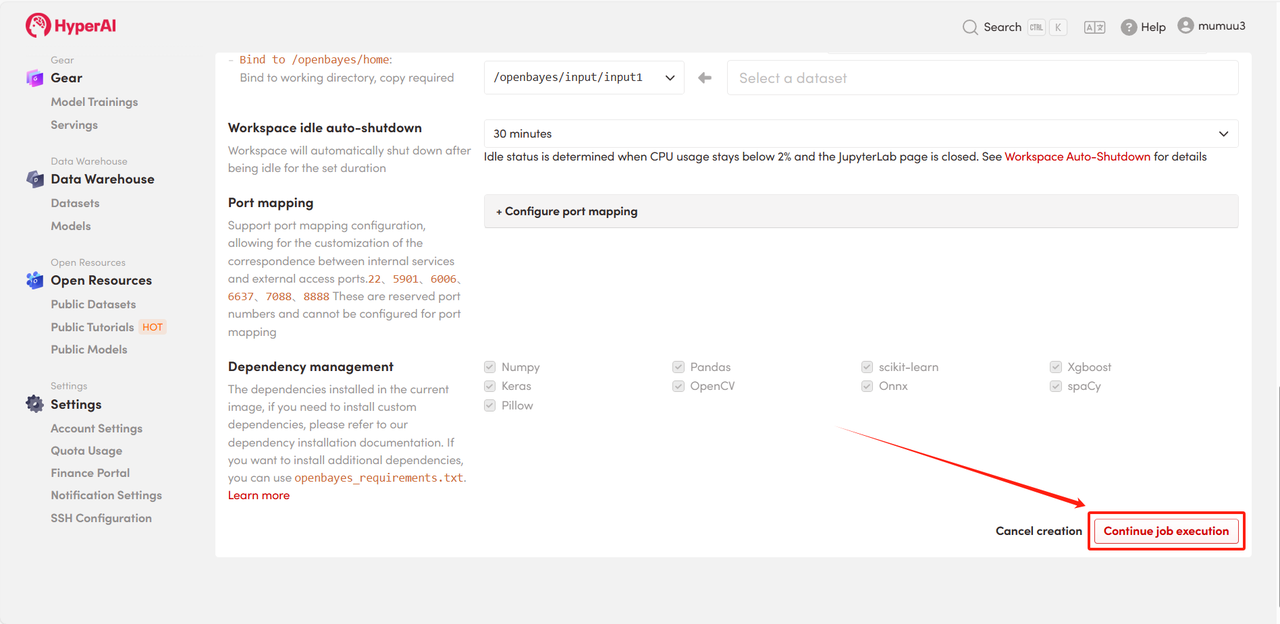
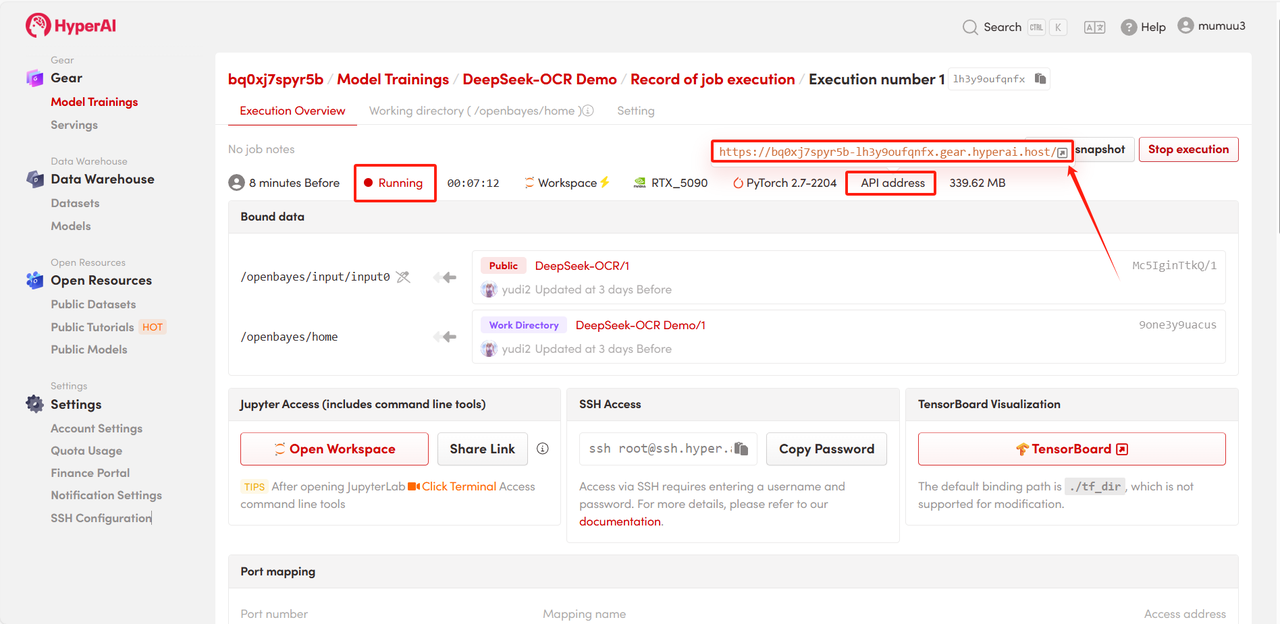
4. Warten Sie auf die Ressourcenzuweisung. Der erste Klonvorgang dauert etwa 3 Minuten. Sobald der Status auf „Wird ausgeführt“ wechselt, klicken Sie auf den Pfeil neben „API-Adresse“, um zur Demoseite zu gelangen.
Effektdemonstration
Nachdem Sie die Demo-Startseite aufgerufen haben, laden Sie das zu analysierende Dokumentenbild hoch und klicken Sie auf „Text extrahieren“, um mit der Analyse zu beginnen.
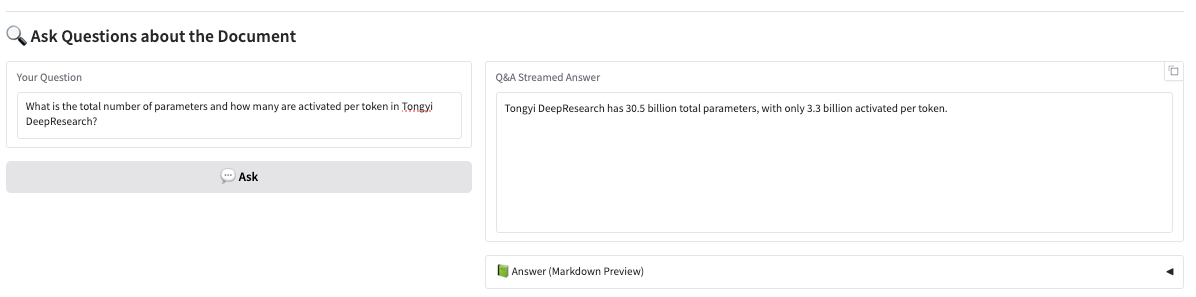
Das Modell unterteilt zunächst die Text- oder Diagrammmodule im Bild und gibt dann den Text im Markdown-Format aus.

Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!
* Link zum Tutorial:








