Command Palette
Search for a command to run...
Open Source, Bestes Preis-Leistungs-Verhältnis! Mistral AI Veröffentlicht Die Mistral 3-Modellreihe, Die Multimodales Verständnis Und Intelligente Ausführungsfunktionen Integriert; Vom Hochdynamischen Tanz Bis Zum Alltagsverhalten Ermöglicht Der X-Dance-Datensatz Multidimensionale Tests Für Die Generierung Menschlicher Animationen.

kürzlich,Das Mistral AI-Team hat seine hocheffiziente Modellreihe Mistral 3 als Open Source veröffentlicht und bietet drei Parametergrößen an: 3B, 8B und 14B.Jeder Parameter ist in drei Versionen verfügbar: Basic, Command und Inference. Alle drei Versionen sind unter der Apache 2.0-Lizenz lizenziert.
Der Ministral-3-14B, das Modell mit den größten Parametern der Serie, bietet die höchste Leistung seiner Klasse und ist vergleichbar mit dem noch größeren Modell Ministral Small 3.2-24B. Er ist für den lokalen Einsatz optimiert und gewährleistet eine hohe Leistung auch auf kleinen, ressourcenbeschränkten Geräten.
Ministral-3-14B integriert multimodales Verständnis und intelligente Ausführungsfunktionen:Im Bereich der Bildverarbeitung kann es Bildinhalte direkt analysieren und auf Basis visueller Informationen Textinhalte generieren; gleichzeitig deckt seine Mehrsprachigkeit Dutzende gängiger Sprachen ab, darunter Englisch, Chinesisch, Japanisch usw. Das Modell basiert auf seinem leistungsstarken 256K-Kontextfenster, das eine solide Unterstützung für die Verarbeitung komplexer Aufgaben mit langen Sequenzen bietet.
Die HyperAI-Website bietet jetzt die Möglichkeit, die Ministral-3-14B-Anweisung mit nur einem Klick bereitzustellen. Probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/EGIY2
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 1. bis 5. Dezember:
* Hochwertige öffentliche Datensätze: 5
* Hochwertige Tutorial-Auswahl: 5
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefristen im Dezember: 1
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Unicode-Datensatz zur Generierung von Problemen mithilfe evolutionärer Algorithmen
UniCode ist ein automatisierter Datensatz mit algorithmischen Problemen und Testfällen, der mithilfe einer evolutionären Generierungsstrategie erstellt wurde. Er soll herkömmliche, statische und manuell generierte Problemsätze ersetzen und vielfältigere, anspruchsvollere und robustere Ressourcen für Programmieraufgaben bereitstellen. Durch eine systematische Pipeline zur Problemgenerierung und -verifizierung erzeugt dieser Datensatz strukturierte, anspruchsvolle und fehlerfreie Problem- und Testdaten, die sich für die Algorithmenforschung, die Evaluierung von Codegenerierungsmodellen und das Training für Wettbewerbe eignen.
Direkte Verwendung:https://go.hyper.ai/YBBcI
2. VAP-Data Visual Motion Performance Dataset
VAP-Data, ein gemeinsames Projekt von ByteDance und der Chinesischen Universität Hongkong, ist derzeit der größte semantisch kontrollierte Datensatz für Videogenerierung. Er dient als hochwertiges Trainings- und Evaluierungssystem für kontrollierte Videogenerierung, kontrollierte Bewegungssynthese und multimodale Videomodelle. Der Datensatz umfasst über 90.000 sorgfältig ausgewählte Videopaare, die 100 detaillierte semantische Bedingungen in vier semantischen Kategorien abdecken: Konzept, Stil, Handlung und Einstellung. Jede semantische Kategorie enthält mehrere Sätze aufeinander abgestimmter Videoinstanzen.
Direkte Verwendung:https://go.hyper.ai/wUrHs

3. Pilze Multiklassen Mikroskopischer Pilzmikroskopischer Bilddatensatz
Fungi MultiClass Microscopic ist ein hochwertiger mikroskopischer Bilddatensatz für die Bildklassifizierung und die Forschung im Bereich Deep Learning. Er wurde entwickelt, um zuverlässige Trainings- und Evaluierungsdaten für Bereiche wie die medizinische Mykologie und die Diagnose von Agrarpathologie bereitzustellen.
Direkte Verwendung:https://go.hyper.ai/ZHUaY
4. X-Dance Bildgesteuerter Tanzbewegungsdatensatz
X-Dance ist ein Testdatensatz, der von der Universität Nanjing in Zusammenarbeit mit Tencent und dem Shanghai Artificial Intelligence Laboratory veröffentlicht wurde. Er wurde speziell für die Bild-zu-Video-Animationsgenerierung entwickelt und dient der Bewertung der Robustheit und Generalisierungsfähigkeit von Modellen in realen Szenarien bei Herausforderungen wie Identitätserhalt, zeitlicher Kohärenz und räumlich-zeitlicher Fehlausrichtung.
Direkte Verwendung:https://go.hyper.ai/QXsNo

5. 3EED-Datensatz für sprachgesteuertes 3D-Verständnis
3EED ist ein plattformübergreifender, multimodaler 3D-Datensatz zur visuellen Orientierung, der von der Hong Kong University of Science and Technology (Guangzhou) in Zusammenarbeit mit der Nanyang Technological University und weiteren Institutionen veröffentlicht wurde. Er wurde für die NeurIPS 2025 angenommen und dient dazu, Modelle bei der Durchführung sprachgesteuerter 3D-Ziellokalisierungsaufgaben in realen Außenszenen zu unterstützen und die plattformübergreifende Robustheit sowie das räumliche Verständnis der Modelle umfassend zu evaluieren.
Direkt verwenden: https://go.hyper.ai/gC8Fq
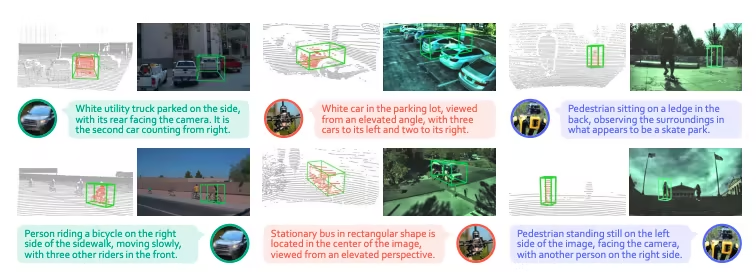
Ausgewählte öffentliche Tutorials
1. Ein 3D-Weihnachtsbaum basierend auf Gestenerkennung
3D Christmas Tree ist ein innovatives Projekt von moleculemmeng020425. Es bietet ein immersives, filmisches visuelles Erlebnis. Basierend auf React und Three.js (R3F) nutzt das Projekt fortschrittliche KI-Gestenerkennung, wodurch Benutzer die Form des Weihnachtsbaums (Zusammenziehen und Auseinanderziehen) einfach per Gesten steuern und den Blickwinkel frei drehen können.
Online ausführen:https://go.hyper.ai/LpApP
2. Bereitstellung von Ministry-3-14B-Instruct mit einem Klick
Ministral-3-14B-Instruct-2512 ist ein multimodales Modell von Mistral AI. Es unterstützt multimodale (Text und Bild) und mehrsprachige Funktionen und bietet hohe Leistung und Kosteneffizienz. In Kombination mit Optimierungstechnologien von Partnern wie NVIDIA läuft das Modell effizient auf unterschiedlicher Hardware und eignet sich für Edge Computing, Unternehmenseinsätze und weitere Szenarien. Entwickler erhalten damit leistungsstarke Werkzeuge zum Erstellen und Bereitstellen von KI-Anwendungen.
Online ausführen:https://go.hyper.ai/EGIY2
3. SAM3: Visuelles Segmentierungsmodell
SAM3 ist ein fortschrittliches Computer-Vision-Modell von Meta AI. Es erkennt, segmentiert und verfolgt Objekte in Bildern und Videos mithilfe von Text, Beispielen und visuellen Hinweisen. SAM3 unterstützt die Eingabe von Phrasen mit offenem Vokabular, bietet leistungsstarke intermodale Interaktionsmöglichkeiten und korrigiert Segmentierungsergebnisse in Echtzeit. Es erzielt überragende Ergebnisse bei der Bild- und Videosegmentierung, übertrifft bestehende Systeme um das Doppelte und unterstützt Zero-Shot-Learning.
Online ausführen:https://go.hyper.ai/PEaVo

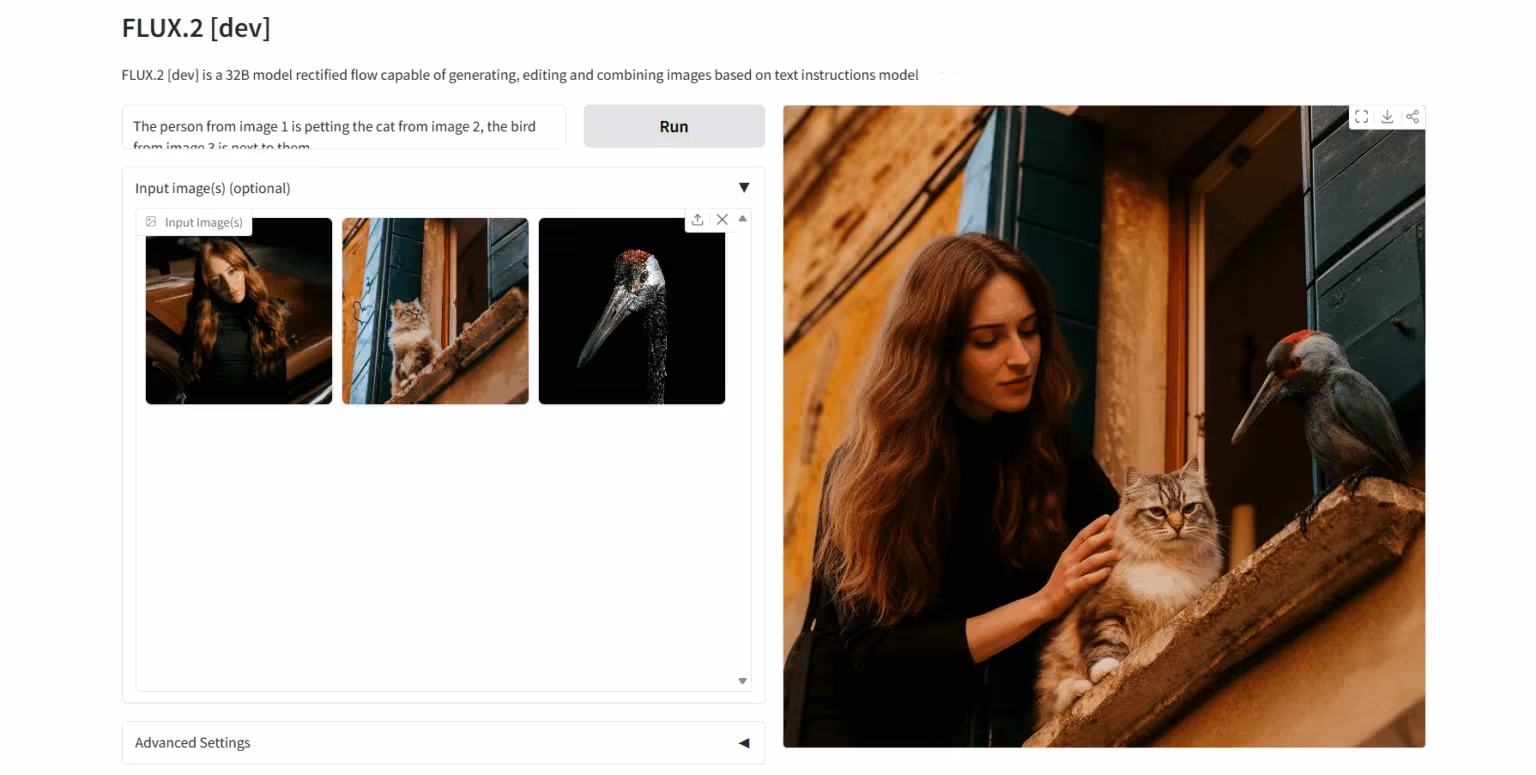
4. FLUX.2-dev: Bildgenerierungs- und Bearbeitungsmodell
FLUX.2 ist ein KI-Bildmodell von Black Forest Labs, das speziell für kreative Workflows in der Praxis entwickelt wurde. Das Modell unterstützt Referenzbilder mit bis zu zehn Bildern und generiert hochauflösende Bilder mit bis zu 4 MP, die sich durch außergewöhnliche Detailgenauigkeit und hervorragende Textdarstellung auszeichnen. Durch die Kombination eines visuellen Sprachmodells mit einer Stream-Transformer-Architektur verbessert das Modell das Verständnis realer Wissensstrukturen und die Qualität der Bildgenerierung signifikant und fördert so offene Innovationen und die breite Anwendung visueller Intelligenztechnologien.
Online ausführen:https://go.hyper.ai/4abhg
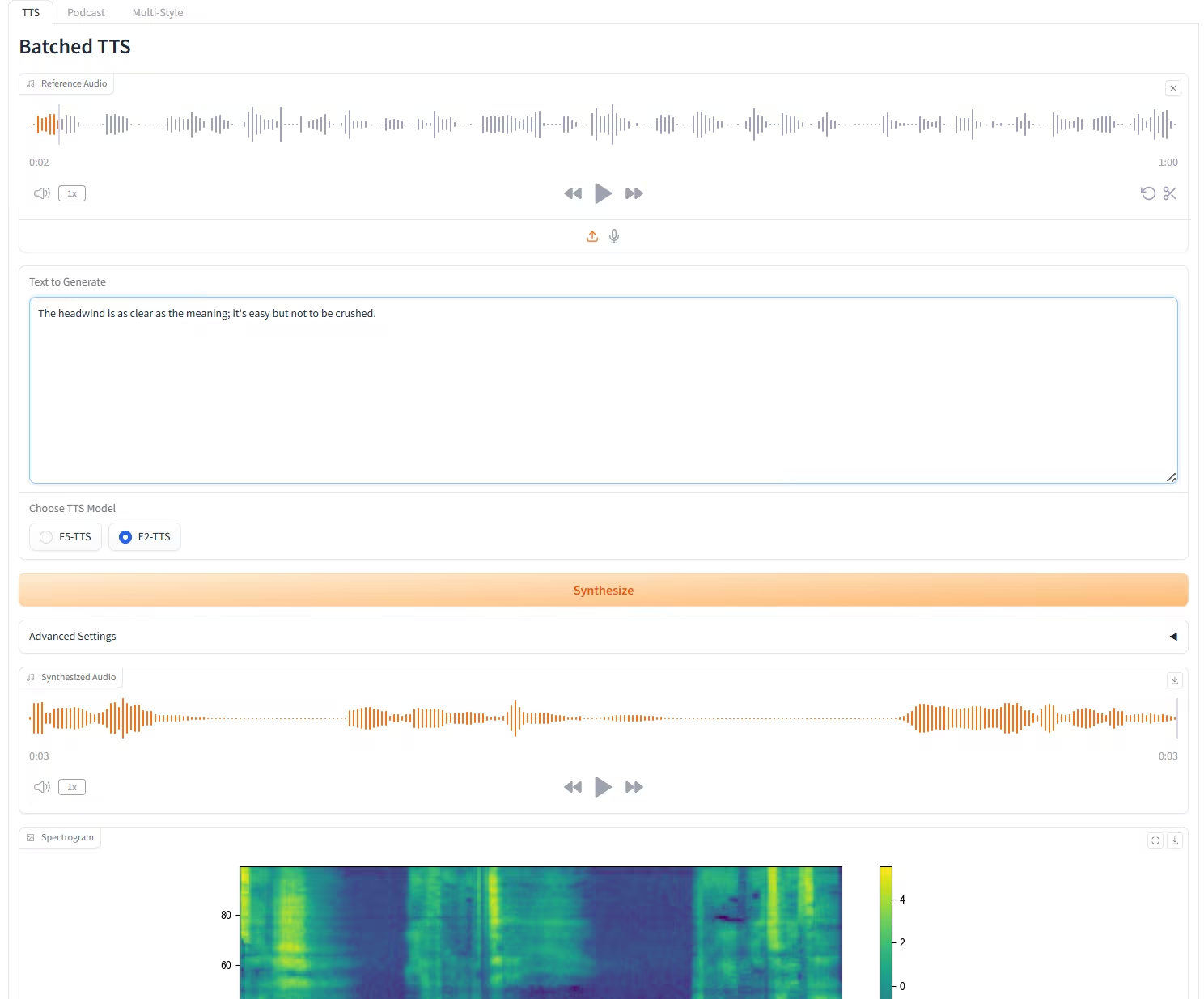
5. Das F5-E2 TTS kann jeden Ton in nur 3 Sekunden klonen.
F5-TTS ist ein leistungsstarkes Text-to-Speech-System (TTS), das von der Shanghai Jiao Tong University, der Universität Cambridge und dem Geely Automobile Research Institute (Ningbo) Co., Ltd. als Open Source veröffentlicht wurde. Es basiert auf einem nicht-autoregressiven Generierungsverfahren mit Stream-Matching in Kombination mit der Diffusion Transformer (DiT)-Technologie. Das System generiert schnell und ohne zusätzliche Überwachung natürliche, flüssige und originalgetreue Sprache aus dem Originaltext durch Zero-Shot-Learning. Es unterstützt die mehrsprachige Synthese, darunter Chinesisch und Englisch, und kann auch lange Texte effektiv in Sprache umwandeln.
Online ausführen:https://go.hyper.ai/8YCMD
Die Zeitungsempfehlung dieser Woche
1. Von Code-Fundamentmodellen zu Agenten und Anwendungen: Ein umfassender Überblick und praktischer Leitfaden zur Code-Intelligenz
Diese Studie integriert systematisch die Analyse und bietet eine umfassende Reihe von integrierten Praxisleitlinien (einschließlich einer Reihe analytischer und explorativer Experimente), um den gesamten Lebenszyklus codebasierter LLMs zu untersuchen. Dieser umfasst die Datenkonstruktion, das Vortraining, Prompting-Paradigmen, das Code-Vortraining, das überwachte Feinabstimmen, das Reinforcement Learning und die Konstruktion autonomer Programmieragenten.
Link zum Artikel:https://go.hyper.ai/xvPZN
2. DeepSeek-V3.2: Die Grenzen offener großer Sprachmodelle erweitern
Diese Arbeit stellt DeepSeek-V3.2 vor, ein Modell, das überlegene Inferenzfähigkeiten und Agentenleistung bei gleichzeitig hoher Recheneffizienz erzielt. Die wichtigsten technologischen Fortschritte von DeepSeek-V3.2 umfassen im Wesentlichen drei Aspekte: den Mechanismus für spärliche Aufmerksamkeit DeepSeek Sparse Attention (DSA), ein skalierbares Reinforcement-Learning-Framework und eine Pipeline zur Synthese umfangreicher Agentenaufgaben.
Link zum Artikel:https://go.hyper.ai/pVyE9
3. LongVT: Anreize für „Denken mit langen Videos“ durch native Tool-Aufrufe
Diese Arbeit stellt LongVT vor, ein intelligentes End-to-End-Framework, das durch eine verschachtelte multimodale Werkzeugkette „tiefes Nachdenken über lange Videos“ ermöglicht. Es nutzt die inhärenten Fähigkeiten von LMMs zur zeitlichen Positionierung als natives Video-Trimmwerkzeug, fokussiert präzise auf spezifische Videosegmente und führt ein feineres Resampling der Videoframes durch.
Link zum Artikel:https://go.hyper.ai/ho70t
4. Z-Image: Ein effizientes Grundlagenmodell zur Bildgenerierung mit Einzelstrom-Diffusionstransformator
Diese Arbeit stellt Z-Image vor, ein hocheffizientes generatives Modell mit 6 Milliarden Parametern, basierend auf der Scalable Single-Stream Diffusion Transformer (S3-DiT)-Architektur, das das bisherige „Skalierungsparadigma“ in Frage stellt. Darauf aufbauend entwickelten die Forscher das Z-Image-Turbo-Modell weiter, das ein mehrstufiges Destillationsverfahren mit Belohnung nach dem Training kombiniert. Dieses Modell erreicht Inferenzlatenzen im Subsekundenbereich auf H800-GPUs der Enterprise-Klasse und ist gleichzeitig mit Consumer-Hardware (weniger als 16 GB VRAM) kompatibel, wodurch die Implementierungshürde deutlich gesenkt wird.
Link zum Artikel:https://go.hyper.ai/qqSwp
5. Technischer Bericht Qwen3-VL
Dieser Artikel stellt Qwen3-VL vor, das bisher leistungsstärkste visuelle Sprachmodell der Qwen-Serie. Es demonstriert herausragende Ergebnisse in einer Vielzahl multimodaler Benchmarks. Das Modell unterstützt nativ verschachtelte Kontexte mit bis zu 256.000 Token und integriert nahtlos Text-, Bild- und Videoinformationen. Die Modellfamilie umfasst dichte Architekturen (2B/4B/8B/32B) und hybride Expertenarchitekturen (30B-A3B/235B-A22B), um den jeweiligen Anforderungen hinsichtlich Latenz und Qualität in unterschiedlichen Szenarien gerecht zu werden.
Link zum Artikel:https://go.hyper.ai/8HkMJ
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
1. Neugestaltung der Vorhersagekraft ungeordneter Proteinaggregate: NVIDIA, MIT, Universität Oxford, Universität Kopenhagen, Peptone und andere veröffentlichen generative Modelle und neue Benchmarks.
Ein gemeinsames Team von Peptone, einem britischen Entwickler von Proteinanalysetechnologien, NVIDIA und dem MIT hat zwei entscheidende Durchbrüche erzielt. Der erste ist das systematische Evaluierungsframework PeptoneBench: Dieses Framework integriert experimentelle Daten aus verschiedenen Quellen (SAXS, NMR, RDC und PRE) und kombiniert statistische Methoden wie die Maximum-Entropie-Gewichtung, um einen präzisen quantitativen Vergleich zwischen experimentellen Beobachtungen und theoretischen Vorhersagen zu ermöglichen. Der zweite Durchbruch ist das generative Modell PepTron: Trainiert mit einem erweiterten synthetischen IDR-Datensatz, verbessert es insbesondere die Modellierung ungeordneter Regionen und ermöglicht so eine bessere Erfassung der Konformationsvielfalt ungeordneter Proteine.
Den vollständigen Bericht ansehen:https://go.hyper.ai/YBd9t
2. Online-Tutorial | FLUX.2, ein neues, hochmodernes Bildgenerierungstool, ermöglicht die gleichzeitige Referenzierung von 10 Bildern für eine extrem hohe Zeichen-/Stilkonsistenz.
Nach langer Stille meldet sich Black Forest Labs mit der Veröffentlichung seines Bildgenerierungs- und Bearbeitungsmodells der nächsten Generation, FLUX.2, als Open Source zurück. FLUX.1, erschienen 2024, erzielte bereits nahezu realistische Ergebnisse bei der Generierung von Bildern von Personen, insbesondere von realen Personen. Das Upgrade auf FLUX.2 setzt nun neue Maßstäbe in Bildqualität und kreativer Flexibilität und erreicht modernste Standards (SOTA) in Bezug auf Befehlsverständnis, visuelle Qualität, Detailwiedergabe und Ausgabevielfalt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/wLDRW
3. Event-Vorschau | Shanghai Innovation Lab, TileAI, Huawei und Advanced Compiler Lab treffen sich in Shanghai; TVM, TileRT, PyPTO und Triton stellen ihre besonderen Stärken unter Beweis.
Der achte Meet AI Compiler Technical Salon findet am 27. Dezember in der Shanghai Innovation Academy statt. Experten der Shanghai Innovation Academy, der TileAI-Community, von Huawei HiSilicon und des Advanced Compiler Lab präsentieren in dieser Session Einblicke entlang der gesamten Technologiekette – vom Software-Stack-Design und der Operatorentwicklung bis hin zur Leistungsoptimierung. Zu den Themen gehören die ökosystemübergreifende Interoperabilität von TVM, die Optimierung der Fusionsoperatoren von PyPTO, latenzarme Systeme mit TileRT und die Multiarchitektur-Beschleunigung mit Triton. Damit wird ein vollständiger technischer Weg von der Theorie zur Implementierung aufgezeigt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/x6po9
4. Stanford, die Peking-Universität, UCL und UC Berkeley arbeiteten zusammen, um mithilfe von CNN sieben seltene linsenförmige Proben aus 810.000 Quasaren genau zu identifizieren.
Ein Team aus zahlreichen Forschungseinrichtungen, darunter die Stanford University, das SLAC National Accelerator Laboratory, die Peking University, das Brera-Observatorium des italienischen Nationalen Instituts für Astrophysik, das University College London und die University of California, Berkeley, hat einen datengesteuerten Arbeitsablauf entwickelt, um Quasare zu identifizieren, die in den Spektraldaten von DESI DR1 als starke Gravitationslinsen wirken, wodurch die zuvor kleine Stichprobengröße von Quasaren erheblich erweitert wird.
Den vollständigen Bericht ansehen:https://go.hyper.ai/6s2FB
5. Da erst 2% erreicht ist, steht Sam Altmans Wette auf eine Infrastruktur zur Überprüfung der menschlichen Identität vor einem globalen regulatorischen Dilemma.
In einer Zeit, in der die Authentizität von KI schwer zu erkennen ist, entwickeln Sam Altman und Alex Blania ein globales System zur „menschlichen Verifizierung“ mittels Iriserkennung. Doch die Expansion von Tools for Humanity steht unter enormem Druck. Die Philippinen haben ihre Datendienste mit Verweis auf Datenschutz und unzulässige Einflussnahme ausgesetzt, und mehrere andere Länder haben Überprüfungen eingeleitet. Die Kluft zwischen ihrer Vision von einer Milliarde Nutzern und den derzeit lediglich 17,5 Millionen Nutzern vergrößert sich stetig. Trotz ausreichender Finanzierung und eines hochkarätigen Teams werden Datenschutz und regulatorische Bedenken die Zukunft von Tools for Humanity langfristig prägen.
Den vollständigen Bericht finden Sie hier: https://go.hyper.ai/KL1Dq
Beliebte Enzyklopädieartikel
1. DALL-E
2. Hypernetzwerke
3. Pareto-Front
4. Bidirektionales Langzeit-Kurzzeitgedächtnis (Bi-LSTM)
5. Reziproke Rangfusion
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Top-Konferenz mit einer Frist im Dezember

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1800 öffentliche Datensätze
* Enthält über 600 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 600 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








