Command Palette
Search for a command to run...
LightOnOCR-2-1B: Hochpräzise End-to-End-OCR Basierend Auf RLVR-Training; Google Streetview National Street View Images: Eine Open-Source-Bibliothek Für Panoramabilder, Basierend Auf Erstklassiger Geokartierungstechnologie.

Aktuell basiert die OCR-Technologie auf einer komplexen, sequenziellen Pipeline: Zuerst werden Textbereiche erkannt, dann erfolgt die Erkennung und schließlich die Nachbearbeitung.Dieses Modell ist umständlich und fehleranfällig bei Dokumenten mit komplexen Layouts und unterschiedlichen Formaten. Jeder Fehler in einem beliebigen Schritt kann zu schlechten Gesamtergebnissen führen, und eine durchgängige Optimierung ist schwierig, was hohe Wartungs- und Anpassungskosten zur Folge hat.
In diesem ZusammenhangLightOn hat das Modell LightOnOCR-2-1B als Open Source veröffentlicht.Dieses durchgängige Bild-Sprach-Modell mit nur einer Milliarde Parametern erzielt auf dem maßgeblichen Benchmark OlmOCR-Bench eine neue Bestleistung (State of the Art, SOTA) und übertrifft das bisher beste Modell mit neun Milliarden Parametern. Gleichzeitig wurde die Größe um das Neunfache reduziert und die Inferenzgeschwindigkeit um ein Vielfaches erhöht. LightOnOCR-2-1B verwendet ein einheitliches Modell, um direkt aus Pixeln strukturierte, geordnete Text- und Bildbegrenzungsrahmen zu generieren. Durch die Integration vortrainierter Komponenten, hochwertiger, destillierter Daten und Strategien wie RLVR wird der Prozess vereinfacht und die Effizienz der Verarbeitung komplexer Dokumente deutlich verbessert.
Das „LightOnOCR-2-1B Lightweight High-Performance End-to-End OCR Model“ ist jetzt auf der HyperAI-Website erhältlich. Probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/8zlVw
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 2. bis 6. Februar:
* Hochwertige öffentliche Datensätze: 6
* Eine Auswahl hochwertiger Tutorials: 9
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefristen im Februar: 4
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. RubricHub Multi-Domain Generative Task Dataset
RubricHub ist ein umfangreicher, domänenübergreifender Datensatz für generative Aufgaben, der von Li Auto und der Zhejiang-Universität gemeinsam veröffentlicht wurde. Dieser Datensatz bietet hochwertige Unterstützung auf Basis von Bewertungskriterien für offene generative Aufgaben. Er wurde mithilfe eines automatisierten Frameworks zur Generierung von Bewertungskriterien erstellt, das von grob zu fein vorgeht und Strategien wie prinzipiengeleitete Synthese, Multi-Modell-Aggregation und Schwierigkeitsentwicklung integriert, um umfassende und hochgradig differenzierende Bewertungskriterien zu erzeugen.
Direkte Verwendung:https://go.hyper.ai/g3Htm
2. Nemotron-Personas-Brazil Brasilianischer Datensatz synthetischer Charaktere
Nemotron-Personas-Brazil ist ein synthetischer Charakterdatensatz für Brasilien, der von NVIDIA in Zusammenarbeit mit WideLabs veröffentlicht wurde. Er soll die Vielfalt und den Reichtum der brasilianischen Bevölkerung aufzeigen und die multidimensionale potenzielle Bevölkerungsverteilung umfassender abbilden, einschließlich regionaler Unterschiede, ethnischer Zugehörigkeit, Bildungsniveau und Berufsverteilung.
Direkte Verwendung:https://go.hyper.ai/7xKKH
3. CL-bench Kontextlern-Evaluierungsbenchmark
CL-bench ist ein Benchmark-Datensatz zur Evaluierung der Kontextlernfähigkeiten eines großen Sprachmodells, der gemeinsam vom Tencent Hunyuan Team und der Fudan-Universität veröffentlicht wurde. Ziel ist es zu testen, ob ein Modell neue Regeln, Konzepte oder Domänenwissen aus einem gegebenen Kontext lernen kann, ohne auf vortrainiertes Wissen zurückzugreifen, und diese auf nachfolgende Aufgaben anwenden kann.
Direkte Verwendung:https://go.hyper.ai/w2MG3
4. RoVid-X-Roboter-Videogenerierungsdatensatz
RoVid-X ist ein von der Peking-Universität in Zusammenarbeit mit ByteDance Seed veröffentlichter Datensatz zur Roboter-Videogenerierung, der darauf abzielt, die physikalischen Herausforderungen zu bewältigen, mit denen Videogenerierungsmodelle bei der Erzeugung von Robotervideos konfrontiert sind.
Direkte Verwendung:https://go.hyper.ai/4P9hI
5. Nationaler Google Streetview-Bilddatensatz
Google Street View ist ein Datensatz mit Straßenansichtsbildern aus verschiedenen Ländern. Die Dateinamen der Bilder enthalten das Erstellungsdatum und den Kartennamen, und die Bilder für jedes Land sind in den jeweiligen Ordnern gespeichert.
Direkte Verwendung:https://go.hyper.ai/tZRlI

6. Datensatz zur Bewertung der langfristigen Planungsfähigkeit von DeepPlanning
DeepPlanning ist ein vom Qwen-Team veröffentlichter Datensatz zur Bewertung der Planungsfähigkeiten intelligenter Agenten mit dem Ziel, deren Denk- und Entscheidungsfähigkeit bei komplexen, langfristigen Planungsaufgaben zu beurteilen.
Direkte Verwendung:https://go.hyper.ai/yywsb
Ausgewählte öffentliche Tutorials
1. Qwen-Image-Edit mit vLLM-Omni bereitstellen
Qwen-Image-Edit ist ein multifunktionales Bildbearbeitungsprogramm des Tongyi Qianwen-Teams von Alibaba. Es bietet sowohl semantische als auch visuelle Bearbeitungsfunktionen und ermöglicht neben der Bearbeitung von Bildelementen (Hinzufügen, Entfernen oder Ändern) auch semantische Bearbeitungen (Erstellung von Bildmarken, Drehung von Objekten und Stilübertragung). Das Programm unterstützt die präzise Bearbeitung von chinesischem und englischem Text und erlaubt die direkte Änderung von Textinhalten in Bildern unter Beibehaltung von Schriftart, -größe und -stil.
Online ausführen:https://go.hyper.ai/DowYs
2. Qwen-Image-2512 mit vLLM-Omni bereitstellen
Qwen-Image-2512 ist das grundlegende Text-zu-Bild-Modell der Qwen-Image-Serie. Im Vergleich zu früheren Versionen wurde Qwen-Image-2512 in mehreren Schlüsselbereichen systematisch optimiert, wobei der Fokus auf der Verbesserung des Realismus und der Benutzerfreundlichkeit der generierten Bilder lag. Die Natürlichkeit der Porträtgenerierung wurde deutlich verbessert, sodass Gesichtsstruktur, Hauttextur und Lichtverhältnisse realistischeren Fotoeffekten ähneln. In natürlichen Szenen kann das Modell detailliertere Geländetexturen, Vegetationsdetails und hochfrequente Informationen wie Tierfell generieren. Gleichzeitig wurden die Textgenerierungs- und Typografiefunktionen verbessert, was eine stabilere Darstellung von lesbarem Text und komplexen Layouts ermöglicht.
Online ausführen:https://go.hyper.ai/Xk93p
3. Schritt 3-VL-10B: Multimodales visuelles Verständnis und grafischer Dialog
STEP3-VL-10B ist ein Open-Source-Modell für visuelle Sprache, entwickelt vom Stepping Star-Team, speziell für multimodales Verstehen und komplexe Denkaufgaben. Ziel dieses Modells ist es, das Verhältnis von Effizienz, Denkvermögen und Qualität des visuellen Verstehens innerhalb eines begrenzten Parameterbereichs von 10 Milliarden (10B) neu zu definieren. Es zeigt überragende Leistungen in der visuellen Wahrnehmung, im komplexen Denken und in der Umsetzung menschlicher Anweisungen. In mehreren Benchmark-Tests übertrifft es Modelle ähnlicher Größenordnung und ist bei einigen Aufgaben mit Modellen vergleichbar, deren Parameterbereich 10- bis 20-mal größer ist.
Online ausführen:https://go.hyper.ai/ZvOV0
4.vLLM+Open WebUI-Bereitstellung von GLM-4.7-Flash
GLM-4.7-Flash ist ein ressourcenschonendes MoE-Inferenzmodell von Zhipu AI, das ein optimales Verhältnis zwischen hoher Leistung und hohem Durchsatz bietet. Es unterstützt nativ Denkketten, Werkzeugaufrufe und Agentenfunktionen. Durch die Verwendung einer hybriden Expertenarchitektur und spärlicher Aktivierungsmechanismen wird der Rechenaufwand einzelner Inferenzvorgänge deutlich reduziert, während gleichzeitig die Leistungsfähigkeit großer Modelle erhalten bleibt.
Online ausführen:https://go.hyper.ai/bIopo

5. LightOnOCR-2-1B Leichtes, leistungsstarkes End-to-End-OCR-Modell
LightOnOCR-2-1B ist die neueste Generation des durchgängigen OCR-Modells (optische Texterkennung) von LightOn AI. Als Flaggschiff der LightOnOCR-Serie vereint es Dokumentenanalyse und Textgenerierung in einer kompakten Architektur, verfügt über eine Milliarde Parameter und läuft auf handelsüblichen GPUs (mit ca. 6 GB VRAM). Das Modell nutzt eine Transformer-Architektur für visuelle Sprache und integriert die RLVR-Trainingstechnologie, wodurch eine extrem hohe Erkennungsgenauigkeit und Inferenzgeschwindigkeit erreicht werden. Es wurde speziell für Anwendungen entwickelt, die die Verarbeitung komplexer Dokumente, handgeschriebener Texte und LaTeX-Formeln erfordern.
Online ausführen:https://go.hyper.ai/8zlVw
6.vLLM+Open WebUI-Bereitstellung von LFM2.5-1.2B-Thinking
LFM2.5-1.2B-Thinking ist das neueste, für Edge-Computing optimierte Hybridarchitekturmodell von Liquid AI. Als Version der LFM2.5-Serie, speziell für logische Inferenz optimiert, vereint es die Verarbeitung langer Sequenzen und effiziente Inferenzfunktionen in einer kompakten Architektur. Das Modell verfügt über 1,2 Milliarden Parameter und läuft flüssig auf handelsüblichen GPUs und sogar Edge-Geräten. Es nutzt eine innovative Hybridarchitektur, die höchste Speichereffizienz und einen hohen Durchsatz ermöglicht, und ist für Szenarien konzipiert, die Echtzeit-Inferenz direkt auf Endgeräten erfordern, ohne Kompromisse bei der Intelligenz einzugehen.
Online ausführen:https://go.hyper.ai/PACIr
7. TurboDiffusion: Bild- und textgesteuertes Videogenerierungssystem
TurboDiffusion ist ein hocheffizientes Videodiffusionsgenerierungssystem, das von einem Team der Tsinghua-Universität entwickelt wurde. Basierend auf einer 2.1-Architektur nutzt dieses Projekt Destillation höherer Ordnung, um die Probleme langsamer Inferenzgeschwindigkeit und hohen Rechenressourcenverbrauchs bei großen Videomodellen zu beheben und so in minimalen Schritten eine qualitativ hochwertige Videogenerierung zu erreichen.
Online ausführen:https://go.hyper.ai/YjCht
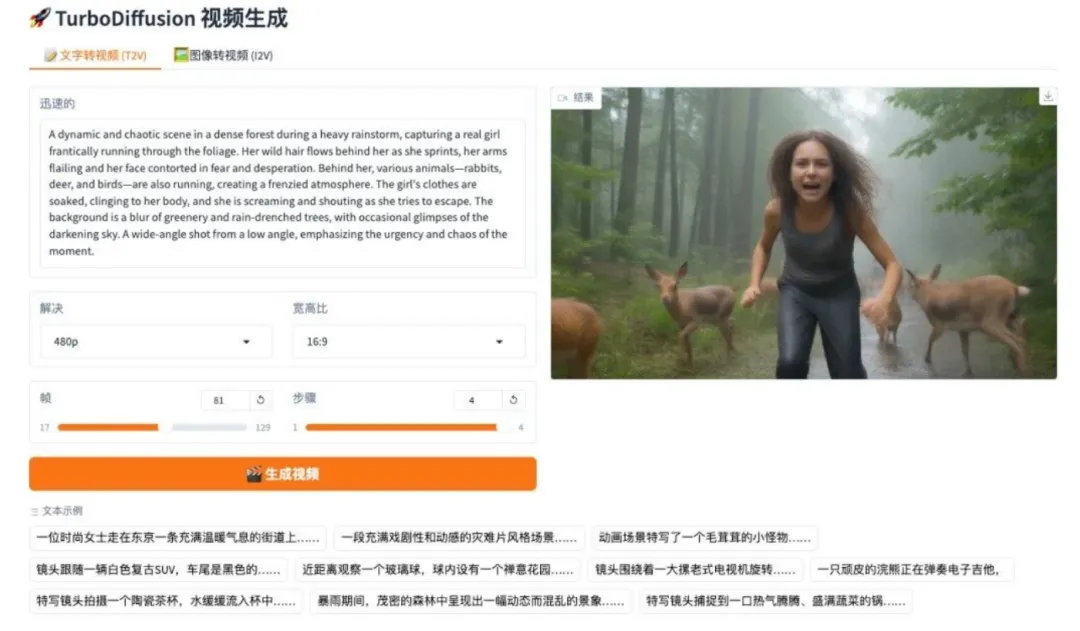
8. DeepSeek-OCR 2 Visueller Kausalfluss
DeepSeek-OCR 2 ist das OCR-Modell der zweiten Generation des DeepSeek-Teams. Durch die Einführung der DeepEncoder V2-Architektur gelingt ein Paradigmenwechsel vom statischen Scannen hin zum semantischen Schließen. Das Modell nutzt kausale Stream-Abfragen und einen Dual-Stream-Aufmerksamkeitsmechanismus, um visuelle Token dynamisch neu anzuordnen und so die natürliche Leselogik komplexer Dokumente präziser zu rekonstruieren. In der OmniDocBench v1.5-Evaluierung erzielte das Modell eine Gesamtpunktzahl von 91,09% – eine deutliche Verbesserung gegenüber dem Vorgängermodell. Gleichzeitig wurde die Wiederholungsrate der OCR-Ergebnisse erheblich reduziert, was einen neuen Weg für die Entwicklung eines vollmodalen Encoders in der Zukunft ebnet.
Online ausführen:https://go.hyper.ai/ITInm
9. Personaplex-7B-v1: Echtzeitdialog und charakterspezifische Sprachschnittstelle
PersonaPlex-7B-v1 ist ein von NVIDIA entwickeltes, multimodales, personalisiertes Dialogmodell mit 7 Milliarden Parametern. Es wurde für Echtzeit-Sprach-/Textinteraktion, Langzeitsimulation der Persona-Konsistenz und multimodale Wahrnehmungsaufgaben konzipiert und zielt darauf ab, ein immersives Rollenspiel- und multimodales Interaktionsdemonstrationssystem mit Reaktionsgeschwindigkeiten im Millisekundenbereich bereitzustellen.
Online ausführen:https://go.hyper.ai/ndoj0
Die Zeitungsempfehlung dieser Woche
1. Kollaboratives Multiagenten-Testzeit-Reinforcement-Learning für Schlussfolgerungen
Diese Arbeit stellt MATTRL vor, ein Reinforcement-Learning-Framework zur Testzeit, das das Multiagenten-Schlussfolgern durch die Integration strukturierter Texterfahrung in den Schlussprozess verbessert. Es erzielt Konsens durch die Zusammenarbeit mehrerer Expertenteams und die rundenweise Verteilung von Punkten und erreicht robuste Leistungsverbesserungen bei medizinischen, mathematischen und pädagogischen Benchmarks, ohne dass ein erneutes Training erforderlich ist.
Link zum Artikel:https://go.hyper.ai/ENmkT
2. A^3-Bench: Benchmarking von speichergetriebenem wissenschaftlichem Denken mittels Anker- und Attraktoraktivierung
Diese Arbeit stellt A³-Bench vor, einen Benchmark für wissenschaftliches Denken mit zwei Skalen und speicherbasierter Auswertung. Er bewertet die Aktivierung von Ankern und Attraktoren mithilfe des SAPM-Annotationsframeworks und der AAUI-Metrik und zeigt so, wie die Speichernutzung die Konsistenz des Denkens über die übliche Kohärenz oder Antwortgenauigkeit hinaus verbessern kann.
Link zum Artikel:https://go.hyper.ai/Ao5t9
3. PaCoRe: Lernen, die Testzeitberechnung mit parallelem koordiniertem Schließen zu skalieren
Diese Arbeit stellt PaCoRe vor, ein paralleles, kollaboratives Inferenzframework, das durch Nachrichtenaustausch zwischen mehreren Runden paralleler Inferenztrajektorien eine massive Skalierung der Testzeitberechnung (TTC) erreicht. Es übertrifft GPT-5 (93,21 TP3T) mit einer Genauigkeit von 94,51 TP3T auf HMMT 2025. PaCoRe integriert den Inferenzprozess von Millionen von Token effizient innerhalb einer festen Kontextbeschränkung und stellt Modell und Daten als Open Source zur Verfügung, um die Entwicklung skalierbarer Inferenzsysteme zu fördern.
Link zum Artikel:https://go.hyper.ai/fQrnt
4. Bewegungszuordnung für die Videogenerierung
Diese Arbeit stellt Motive vor, ein bewegungszentriertes, gradientenbasiertes Datenattributionsframework, das zeitliche Dynamiken mithilfe einer bewegungsgewichteten Verlustmaske von statischen Erscheinungen trennt. Dies ermöglicht die skalierbare Erkennung von Segmenten, die die Feinabstimmung beeinflussen, und verbessert so die Bewegungsglätte und physikalische Plausibilität bei der Text-zu-Video-Generierung. Motive erzielt eine menschliche Präferenzrate von 74,11 TP3T auf VPench.
Link zum Artikel:https://go.hyper.ai/2pU21
5. VIBE: Visueller, anweisungsbasierter Editor
Diese Arbeit stellt VIBE vor, einen kompakten, anweisungsbasierten Workflow zur Bildbearbeitung. Er nutzt ein Qwen3-VL-Modell mit 2 Milliarden Parametern zur Steuerung und ein Sana1.5-Diffusionsmodell mit 1,6 Milliarden Parametern zur Generierung. VIBE ermöglicht eine qualitativ hochwertige Bearbeitung, die die Konsistenz des Quellbildes bei extrem geringem Rechenaufwand strikt beibehält. Der Workflow läuft effizient auf 24 GB GPU-Speicher und generiert ein 2K-Bild auf einer H100 in nur etwa 4 Sekunden. Die Leistung von VIBE erreicht oder übertrifft die von größeren Vergleichsmodellen.
Link zum Artikel:https://go.hyper.ai/8YMEO
Interpretation von Gemeinschaftsartikeln
1. Nachdem innerhalb von drei Tagen 100 Millionen Datenpunkte des Hubble-Weltraumteleskops ausgewertet wurden, schlug die Europäische Weltraumorganisation AnomalyMatch vor und entdeckte dabei über tausend anomale Himmelsobjekte.
Aktuell katapultieren großflächige Himmelsdurchmusterungen mit mehreren Spektralbändern, großem Sichtfeld und hoher Auflösung die Astronomie in ein beispielloses datenintensives Zeitalter. Eines ihrer zentralen wissenschaftlichen Potenziale liegt in der systematischen Entdeckung und Identifizierung seltener Himmelsobjekte von besonderem astrophysikalischem Wert. Ihre Entdeckung beruhte jedoch lange Zeit stark auf zufälligen visuellen Beobachtungen von Forschern oder manuellen Sichtungen im Rahmen von Citizen-Science-Projekten. Diese Methoden sind nicht nur hochgradig subjektiv und ineffizient, sondern auch für die zukünftig anfallenden enormen Datenmengen ungeeignet. Um diesem Mangel zu begegnen, entwickelte und erprobte ein Forschungsteam des Europäischen Weltraumastronomiezentrums (ESAC), einer Einrichtung der Europäischen Weltraumorganisation (ESA), die neue Methode AnomalyMatch.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Jm3aq
2. Datensatzübersicht | 16 Datensätze zur verkörperten Intelligenz, die Greifen, Beantworten von Fragen, logisches Denken, Trajektorienlogik und andere Bereiche abdecken.
Lag der Hauptkampf der künstlichen Intelligenz im letzten Jahrzehnt im „Verstehen der Welt“ und der „Generierung von Inhalten“, so verschiebt sich die zentrale Frage der nächsten Phase hin zu einer deutlich komplexeren Herausforderung: Wie kann KI tatsächlich in die physische Welt eintreten und in ihr handeln, lernen und sich weiterentwickeln? In der einschlägigen Forschung und Diskussion taucht häufig der Begriff „verkörperte Intelligenz“ auf. Wie der Name schon sagt, handelt es sich bei verkörperter Intelligenz nicht um einen traditionellen Roboter, sondern vielmehr um die Intelligenz, die durch die Interaktion zwischen dem Akteur und seiner Umgebung in einem geschlossenen Kreislauf aus Wahrnehmung, Entscheidungsfindung und Handlung entsteht. Dieser Artikel stellt alle aktuell verfügbaren, qualitativ hochwertigen Datensätze zur verkörperten Intelligenz systematisch dar und gibt Empfehlungen dazu. Er dient als Grundlage für weiterführende Forschung und Lehre.
Den vollständigen Bericht ansehen:https://go.hyper.ai/lsCyF
3. Online-Tutorial | DeepSeek-OCR 2: Verbesserungen bei der Formel-/Tabellenanalyse – Erzielen Sie einen Leistungssprung von fast 41 TP3T bei geringen visuellen Token-Kosten
Bei der Entwicklung visueller Sprachmodelle (VLMs) stand die Dokumenten-OCR stets vor zentralen Herausforderungen wie der Analyse komplexer Layouts und der Ausrichtung semantischer Logik. Die Frage, wie Modelle visuelle Logik ähnlich wie Menschen „verstehen“ können, ist zu einem entscheidenden Durchbruch für die Verbesserung des Dokumentenverständnisses geworden. DeepSeek-AIs DeepSeek-OCR 2 bietet hierfür eine neue Lösung. Kernstück ist die neue DeepEncoder V2-Architektur: Das Modell verzichtet auf den traditionellen visuellen CLIP-Encoder und führt ein visuelles Kodierungsparadigma im LLM-Stil ein. Durch die Kombination von bidirektionaler und kausaler Aufmerksamkeit erreicht es eine semantisch gesteuerte Neuanordnung visueller Token und ebnet so den Weg für ein zweistufiges, eindimensionales kausales Schließen zur Interpretation zweidimensionaler Bilder.
Den vollständigen Bericht ansehen:https://go.hyper.ai/nMH13
4. Polymathic AI deckt 19 Szenarien ab, darunter Astrophysik, Geowissenschaften, Rheologie und Akustik, und erstellt 1,3 Milliarden Modelle, um eine genaue Simulation kontinuierlicher Medien zu erreichen.
In den Bereichen wissenschaftliches Rechnen und Ingenieursimulation stellt die effiziente und präzise Vorhersage der Entwicklung komplexer physikalischer Systeme seit jeher eine zentrale Herausforderung für Wissenschaft und Industrie dar. Fortschritte im Deep Learning, insbesondere in der Verarbeitung natürlicher Sprache und im Computer Vision, haben Forscher dazu angeregt, die potenziellen Anwendungen von „fundamentalen Modellen“ in physikalischen Simulationen zu untersuchen. Physikalische Systeme entwickeln sich jedoch häufig über mehrere zeitliche und räumliche Skalen hinweg, während die meisten Lernmodelle typischerweise nur auf kurzfristige Dynamiken trainiert werden. Bei der Anwendung für Langzeitprognosen akkumulieren sich Fehler in komplexen Systemen und führen zu Modellinstabilität. Darauf aufbauend entwickelte ein Forschungsteam der Polymathic AI Collaboration Walrus, ein fundamentales Modell mit 1,3 Milliarden Parametern, einer Transformer-basierten Architektur und primär für die Kontinuumsdynamik fluidartiger Systeme konzipiert.
Den vollständigen Bericht ansehen:https://go.hyper.ai/MJrny
Beliebte Enzyklopädieartikel
1. Umgekehrtes Sortieren in Kombination mit RRF
2. Kolmogorov-Arnold-Darstellungssatz
3. Groß angelegtes Multitasking-Sprachverstehen (MMLU)
4. Blackbox-Optimierer
5. Klassenbedingte Wahrscheinlichkeit
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








