Command Palette
Search for a command to run...
FLUX.2-klein-4B: Erreicht Eine 4-stufige Bildgenerierung Im Subsekundenbereich Durch Destillation Und Ermöglicht so Die Echtzeitinteraktion Auf GPUs Der Consumer-Klasse; Vehicles OpenImages-Datensatz: Konzentriert Sich Auf Die Fahrzeugerkennung Und -lokalisierung.

Aktuell liefern gängige Bildgenerierungsmodelle zwar qualitativ hochwertige Ergebnisse, weisen jedoch langsame Inferenzgeschwindigkeiten, einen hohen Speicherbedarf und einen Interaktionsmodus auf, der noch immer auf „Offline-Tools“ basiert. Benutzer können nach der Eingabe von Befehlen nur passiv warten und erhalten keine Echtzeit-Reaktion oder -Interaktion.Dies schränkt den Einsatz von KI in Bereichen wie Echtzeit-Design und Rapid Prototyping ein.
In diesem ZusammenhangBlack Forest Labs hat das Open-Source-Modell FLUX.2-klein-4B veröffentlicht, das die Inferenzschritte durch Schrittdestillation auf 4 Schritte komprimiert und so eine End-to-End-Inferenz in unter einer Sekunde (≤0,5 s) erreicht.Seine einheitliche Architektur unterstützt Text-zu-Bild-, Bild-zu-Bild- und Multi-Referenz-Generierung und macht so das Umschalten zwischen verschiedenen Modellen überflüssig. Es benötigt lediglich ca. 13 GB Videospeicher für einen effizienten Betrieb auf handelsüblichen GPUs und unterstützt FP8/NVFP4-Quantisierung, wodurch die Geschwindigkeit um bis zu 2,7 Mal gesteigert wird. Es wandelt die KI-Bildgenerierung von einem umständlichen Offline-Werkzeug in einen reaktionsschnellen Echtzeit-Kollaborationspartner und bietet eine schlanke und effiziente Lösung für Anwendungsfälle wie Echtzeit-Design und interaktive Bearbeitung.
Auf der HyperAI-Website wird jetzt „FLUX.2-klein-4B: Ein Hochgeschwindigkeits-Bildgenerierungsmodell“ vorgestellt – probieren Sie es doch einmal aus!
Online-Nutzung:https://go.hyper.ai/N7D6c
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 26. bis 30. Januar:
* Hochwertige öffentliche Datensätze: 7
* Eine Auswahl hochwertiger Tutorials: 6
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefristen im Februar: 6
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Fahrzeuge OpenImages Fahrzeugbilddatensatz
Vehicles OpenImages basiert auf Googles großem öffentlichen OpenImages-Datensatz und konzentriert sich auf die Fahrzeugerkennung und -lokalisierung mit dem Ziel, das schnelle und effiziente Training von Fahrzeugerkennungsmodellen zu unterstützen.
Direkte Verwendung:https://go.hyper.ai/Y8nUj

2. Datensatz für Röntgenaufnahmen des Brustkorbs bei Lungenentzündung
Der Datensatz „Thorax X-ray Pneumonia“ enthält numerische Merkmale, die aus Röntgenbildern des Brustkorbs extrahiert wurden. Dieser Datensatz unterstützt statistische Analysen und klassisches maschinelles Lernen, indem er jedes Bild in strukturierte numerische Merkmale umwandelt. Dazu gehören globale Intensitätsstatistiken, Texturdeskriptoren (GLCM), Frequenzbereichsmerkmale (FFT), kantenbasierte Metriken und Local Binary Pattern (LBP)-Merkmale.
Direkte Verwendung:https://go.hyper.ai/RNgZD
3. Diabetes Mexiko (Mexiko-Diabetes-Datensatz)
Diabetes Mexico ist ein vom mexikanischen Nationalen Institut für öffentliche Gesundheit (INSP) veröffentlichter Datensatz zu Diabetes. Er basiert auf Daten der nationalen Gesundheits- und Ernährungsuntersuchung (ENSANUT) von 2024 und zielt darauf ab, die mit Diabetes verbundenen metabolischen Risikofaktoren in der mexikanischen Bevölkerung zu bewerten.
Direkte Verwendung:https://go.hyper.ai/2L4uw
4. Delhi Pollution AQI (Delhi Air Quality Dataset)
Der Delhi Pollution AQI ist ein Umweltdatensatz für die Analyse und Prognose der Luftqualität. Dieser Datensatz liefert stündliche Luftqualitäts- und Umweltdaten für die wichtigsten Städte der Delhi NCR-Region und eignet sich für Schadstoffanalysen, Zeitreihenprognosen und Anwendungen des maschinellen Lernens.
Direkte Verwendung:https://go.hyper.ai/cNuok
5. LightOnOCR-mix-0126 Texttranskriptionsdatensatz
LightOnOCR-mix-0126 ist ein von LightOn veröffentlichter, umfangreicher OCR-Texttranskriptionsdatensatz, der zur Überwachung von End-to-End-OCR- und Dokumentenverständnismodellen dient und natürlich geordneten, seitenlangen transkribierten Text ausgibt.
Direkte Verwendung:https://go.hyper.ai/tZRlI
6. Sonarsignal (Unterwasser-Sonarsignal-Datensatz)
Das Sonarsignal ist ein Datensatz von Sonarsignalen, der zur Unterwasserobjektklassifizierung verwendet wird. Dieser Datensatz eignet sich für binäre Klassifizierungsaufgaben, die darauf abzielen, zu unterscheiden, ob ein Sonarsignal von Felsen oder einem Bergwerksschacht stammt.
Direkte Verwendung:https://go.hyper.ai/uXIom
7. Datensatz mit Handgesten für ein Autospiel
Hand Gestures Labbled ist ein Bilddatensatz für gestenbasierte Autospiele, der zum Trainieren von Machine-Learning-Modellen für die Steuerung von Autospielen mit Gestensteuerung entwickelt wurde. Der Datensatz enthält insgesamt 330 Bilder aus vier Gestenkategorien: links, mvefrd, rechts und Stopp.
Direkte Verwendung:https://go.hyper.ai/sZmIc
Ausgewählte öffentliche Tutorials
1. WeDLM: Ein hocheffizientes Framework zur Dekodierung großer Sprachmodelle.
WeDLM (Window-based Efficient Decoding for Large Models) ist ein von Tencent entwickeltes, hocheffizientes Framework zur Dekodierung großer Sprachmodelle. Es wurde entwickelt, um KI-Dialogsysteme der nächsten Generation mit ultraschnellen, intelligenten und hochgradig adaptiven Sprachgenerierungsfunktionen auszustatten. Das Framework nutzt eine innovative, fensterbasierte parallele Dekodierungsarchitektur, die eine signifikante Verbesserung der Dekodierungsgeschwindigkeit bei gleichzeitig hoher Textqualität erzielt. Der technologische Durchbruch liegt in der Integration von Entropieschwellenwert-Entscheidungsfindung und Positionsstrafmechanismen. Dadurch wird das Geschwindigkeitsproblem der traditionellen autoregressiven Dekodierung bei der Generierung langer Sequenzen effektiv gelöst.
Online ausführen:https://go.hyper.ai/Cfahp
2. FLUX.2-klein-4B: Ultraschnelles Bildgenerierungsmodell
FLUX.2-klein-4B ist das neueste ultraschnelle Bildgenerierungsmodell von Black-Forest-Labs. Basierend auf der Rectified-Flow-Architektur nutzt es ein auf 4 Milliarden Parameter reduziertes Transformer-Design und vereint textbasierte Bildbearbeitung sowie Bildbearbeitung mit mehreren Referenzen in einem kompakten Modell. Es benötigt lediglich ca. 13 GB GPU-Speicher und erreicht auf handelsüblichen GPUs eine End-to-End-Inferenzgeschwindigkeit von unter einer Sekunde.
Online ausführen:https://go.hyper.ai/N7D6c
3. DiagGym-Diagnostikmittel
DiagAgent, ein Diagnoseagent (7B, 8B, 14B), entwickelt vom AI4Med-Team der Shanghai Jiao Tong University und dem Shanghai Artificial Intelligence Laboratory, steuert proaktiv den Diagnoseprozess. Er wählt die aussagekräftigsten Untersuchungen aus, entscheidet über den Abbruch der Untersuchungen und stellt eine präzise Enddiagnose. Im Gegensatz zu herkömmlichen großen medizinischen Modellen, die nur eine einmalige Antwort liefern, kann DiagAgent relevante Untersuchungen empfehlen und die Diagnose in mehrstufigen Dialogen adaptiv aktualisieren. Die endgültige Diagnose wird erst dann gestellt, wenn ausreichend Informationen vorliegen. DiagAgent ist in der DiagGym-Umgebung mittels durchgängigem Multi-Turn Reinforcement Learning (GRPO) optimiert. In jeder Interaktion beginnt der Agent mit einer Erstberatung, interagiert mit DiagGym, indem er Untersuchungen empfiehlt und Simulationsergebnisse empfängt, und entscheidet über den Zeitpunkt der endgültigen Diagnose.
Online ausführen:https://go.hyper.ai/FzOau
4. Pocket-TTS: Ein hochwertiges, leichtes Streaming-TTS-System
Pocket-TTS ist ein ultraleichtes Sprachsynthesemodell von Kyutai Labs. Dieses Modell konzentriert sich auf geringe Latenz und Streaming-Ausgabe und zielt darauf ab, qualitativ hochwertige Sprachgenerierungsfunktionen für ressourcenbeschränkte Umgebungen oder Szenarien bereitzustellen, die eine Echtzeitinteraktion erfordern (wie z. B. KI-Assistenten).
Online ausführen:https://go.hyper.ai/CwgHo
5. Triton Compiler Tutorial
Triton ist eine Sprache und ein Compiler für die parallele Programmierung, der eine Python-basierte Programmierumgebung für das effiziente Schreiben benutzerdefinierter DNN-Berechnungskerne bietet, die mit maximalem Durchsatz auf GPU-Hardware ausgeführt werden können.
Online ausführen:https://go.hyper.ai/Xqd8j
6. TVM-Tutorial 0.22.0
Apache TVM ist ein Open-Source-Compiler-Framework für maschinelles Lernen, das für CPUs, GPUs und Beschleuniger für maschinelles Lernen entwickelt wurde und es Ingenieuren im Bereich maschinelles Lernen ermöglicht, Berechnungen effizient zu optimieren und auf beliebigen Hardware-Backends auszuführen.
Online ausführen:https://go.hyper.ai/s3yot
Die Zeitungsempfehlung dieser Woche
1. Das Seltene belohnen: Einzigartigkeitsbewusstes Reinforcement Learning für kreative Problemlösung in LLMs
Diese Arbeit schlägt eine Methode des Reinforcement Learning vor, die auf die Einzigartigkeit von Lösungen achtet. Die Methode definiert eine Zielfunktion auf der Ebene des Rollouts und belohnt seltene, hochrangige Schlussfolgerungsstrategien, indem sie die Größe von Clustering und inversen Clustering basierend auf einem großen Sprachmodell (LLM) neu gewichtet. Dies verbessert die Lösungsdiversität und die Pass@k-Leistung bei Benchmarks für mathematisches, physikalisches und medizinisches Denken signifikant, ohne die Pass@1-Leistung zu beeinträchtigen.
Link zum Artikel:https://go.hyper.ai/k5A3R
2. DeepResearchEval: Ein automatisiertes Framework für die Erstellung von Aufgaben im Bereich Deep Research und die agentenbasierte Bewertung
Dieser Artikel stellt DeepResearchEval vor, ein automatisiertes Framework, das mithilfe rollenbasierter Ansätze realistische und komplexe Aufgaben der Tiefenforschung generiert und adaptive, aufgabenspezifische Qualitätsbewertungs- und proaktive Faktenprüfungsmechanismen einsetzt, um Agenten auf Basis großer Sprachmodelle zu evaluieren. Dies ermöglicht die Überprüfung von Behauptungen ohne Zitate und somit die zuverlässige Evaluierung mehrstufiger Netzwerkforschungssysteme.
Link zum Artikel:https://go.hyper.ai/b92V4
3. Kontrollierte Selbstevolution zur algorithmischen Codeoptimierung
Diese Arbeit schlägt eine Methode der kontrollierten Selbstevolution (CSE) vor, die die Effizienz der Codegenerierung durch die Wiederverwendung von Erfahrungen mittels diversifizierter Initialisierung, rückkopplungsgesteuerter genetischer Operationen und hierarchischem Speicher verbessert. Sie ermöglicht die effiziente Exploration und kontinuierliche Optimierung verschiedener LLM-Backbone-Netzwerke auf dem EffiBench-X-Benchmark.
Link zum Artikel:https://go.hyper.ai/RJHUC
4. MMFormalizer: Multimodale Autoformalisierung in der Praxis
In diesem Beitrag wird MMFORMALIZER vorgestellt, ein neuartiges multimodales automatisches Formalisierungsframework, das adaptive Lokalisierung mit perzeptuellen Primitiven kombiniert, um rekursiv Aussagen mit formalen Grundlagen in mathematischen und physikalischen Axiomen zu konstruieren. Dies ermöglicht maschinelles Schließen in Bereichen wie der klassischen Mechanik, der Relativitätstheorie, der Quantenmechanik und der Thermodynamik und demonstriert die Skalierbarkeit anhand des PHYX-AF-Benchmarks.
Link zum Artikel:https://go.hyper.ai/mC7NC
5. MAXS: Meta-adaptive Exploration mit LLM-Agenten
Diese Arbeit stellt MAXS vor, ein metaadaptives Framework für das Schließen von Agenten großer Sprachmodelle (LLM). Durch die Einführung von vorausschauender Planung und Trajektorienkonvergenzmechanismen werden die Probleme lokaler Kurzsichtigkeit und instabiler Schlussfolgerungen gemildert. In Kombination mit Vorteilsschätzung und konsistenzgetriebener Schrittweitenwahl ermöglicht es effizientes, stabiles und leistungsstarkes Multi-Tool-Schließen.
Link zum Artikel:https://go.hyper.ai/Wrhke
Interpretation von Gemeinschaftsartikeln
1. Kann ein „KI-Ein-Mann-Unternehmen“, das an der Spitze dieses Trends steht, von Moltrbot bis hin zu politischen Dividenden zu einem großen und starken Unternehmen heranwachsen?
Mit der zunehmenden Verbreitung von Technologien wie ChatGPT, KI-gestützten Design-Tools und intelligenten Datenanalysesystemen erlebt die Startup-Szene eine beispiellose Effizienzrevolution. Clawdbot (jetzt Moltrbot), der kürzlich viral ging, gilt als Open-Source-Assistent, der die Produktivität bis 2026 revolutionieren soll. Dieser KI-Agent, der als „hochkarätiger LLM mit Händen“ angepriesen wird, hat im Silicon Valley für Furore gesorgt: Seine GitHub-Sterne schnellten innerhalb von nur drei Tagen nach Veröffentlichung auf 57.500 in die Höhe. Noch wichtiger ist, dass diese neue Startup-Form positive politische Unterstützung erhält. Bereits 2016 ermutigten die „Meinungen des Staatsrats zur Förderung der nachhaltigen und gesunden Entwicklung von Risikokapital“ kapitalstarke und erfahrene Personen ausdrücklich dazu, sich durch die Gründung von Ein-Personen-Unternehmen im Risikokapitalbereich zu engagieren.
Den vollständigen Bericht ansehen:https://go.hyper.ai/2hKRe
2. Skild AI, ein Robotik-Startup, sammelt 1,4 Milliarden Dollar ein, unter anderem mit Beteiligung von SoftBank, Nvidia, Sequoia Capital und Bezos, um universelle Basismodelle zu entwickeln.
Mitte Januar 2026 gab das Robotik-Startup Skild AI den Abschluss einer Series-C-Finanzierungsrunde über rund 1,4 Milliarden US-Dollar bekannt, wodurch das Unternehmen mit über 14 Milliarden US-Dollar bewertet wurde. Die Runde wurde von der japanischen SoftBank Group angeführt, mit strategischen Investoren wie NVentures (Nvidia), Macquarie Capital und Bezos Expeditions (gegründet von Amazon-Gründer Jeff Bezos). Auch Samsung, LG, Schneider Electric und Salesforce Ventures beteiligten sich. Während sich die Roboterhardware stetig weiterentwickelt und die Anwendungsszenarien weiterhin stark fragmentiert sind, floss Kapital wiederholt und nahezu zeitgleich in wenige Unternehmen, die nicht ausschließlich Roboter herstellen. Dies spiegelt zum Teil die Gewinnorientierung des Kapitals wider und bestätigt, dass dieses weniger als drei Jahre alte Startup einen vielversprechenden Weg eingeschlagen hat.
Den vollständigen Bericht ansehen:https://go.hyper.ai/iYHbK
3. AlphaGenome ziert das Cover von Nature! Es prognostiziert Variationseffekte über alle Modalitäten und Zelltypen hinweg in weniger als einer Sekunde.
Im Juni 2025 veröffentlichte Google DeepMind AlphaGenome. Das AlphaGenome-Modell verarbeitet DNA-Sequenzen mit bis zu einer Million Basenpaaren und sagt Tausende molekularer Eigenschaften voraus, die mit deren regulatorischen Aktivitäten zusammenhängen. Es kann auch die Auswirkungen von Genvarianten oder Mutationen bewerten, indem es Vorhersagen für mutierte und unmutierte Sequenzen vergleicht. Einer der wichtigsten Durchbrüche von AlphaGenome ist die Fähigkeit, „Spleißstellen direkt aus Sequenzen vorherzusagen und diese zur Vorhersage der Auswirkungen von Varianten zu nutzen“. Dr. Caleb Lareau vom Memorial Sloan Kettering Cancer Center kommentierte: „Dies ist ein Meilenstein auf diesem Gebiet. Erstmals verfügen wir über ein Modell, das gleichzeitig einen langen Kontext, Einzelbasengenauigkeit und Spitzenleistung bietet und ein breites Spektrum genomischer Aufgaben abdeckt.“
Den vollständigen Bericht ansehen:https://go.hyper.ai/jgO8K
4. Auf der Grundlage von Milliarden von Genen aus einer Million Arten haben NVIDIA und andere die EDEN-Modellreihe entwickelt und damit modernste (SOTA) Fähigkeiten zur Genom- und Proteinvorhersage erreicht.
Das grundlegende Ziel der programmierbaren Biologie ist die rationale Entwicklung und präzise Steuerung lebender Systeme, um so revolutionäre Therapien für komplexe Erkrankungen zu ermöglichen. Dieser Prozess wurde jedoch lange durch die inhärente Komplexität biologischer Systeme eingeschränkt. Seine Generalisierbarkeit ist bei multimodalen, skalenübergreifenden innovativen Therapieansätzen stark unzureichend. Um diese grundlegende Einschränkung zu überwinden, haben Basecamp Research, NVIDIA und mehrere führende akademische Einrichtungen gemeinsam die EDEN-Serie metagenomischer Basismodelle entwickelt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/jPS42
5. Die University of California hat ein On-Chip-Spektrometer auf Basis eines vollständig vernetzten neuronalen Netzes entwickelt, das eine spektrale Auflösung von 8 Nanometern auf Chip-Ebene erreicht.
Heutzutage erreichen Smartphone-Kameras das Megapixel-Zeitalter, können aber die chemische Zusammensetzung von Substanzen noch immer nicht so präzise analysieren wie professionelle Spektrometer. Der Grund dafür liegt im Fehlen einer zentralen Komponente in Smartphones und anderen Geräten – einem Spektrometer –, das den einzigartigen „spektralen Fingerabdruck“ einer Substanz genau erfassen kann. Traditionelle Spektrometer, wichtige Werkzeuge der Substanzanalyse, zerlegen zusammengesetztes Licht in Spektren unterschiedlicher Wellenlängen und identifizieren anschließend die Zusammensetzung der Substanz anhand charakteristischer Spektrallinien. Sie stehen jedoch vor einer großen Herausforderung: Die Miniaturisierung erfordert den Verzicht auf herkömmliche dispersive Strukturen. Doch wie lassen sich ohne diese Strukturen spektrale Informationen gewinnen? Um diese Herausforderung zu meistern, schlug ein Forschungsteam der University of California eine innovative Lösung vor: die Entwicklung einer speziellen Photonenfallen-Texturstruktur (PTST) auf der Oberfläche einer Standard-Silizium-Photodiode und die Integration eines hochgradig rauschunempfindlichen, vollständig vernetzten neuronalen Netzes.
Den vollständigen Bericht ansehen:https://go.hyper.ai/bYwq8
Beliebte Enzyklopädieartikel
1. Bilder pro Sekunde (FPS)
2. Reverse Sort Fusion RRF
3. Visuelles Sprachmodell (VLM)
4. Hypernetzwerke
5. Gesteuerte Aufmerksamkeit
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
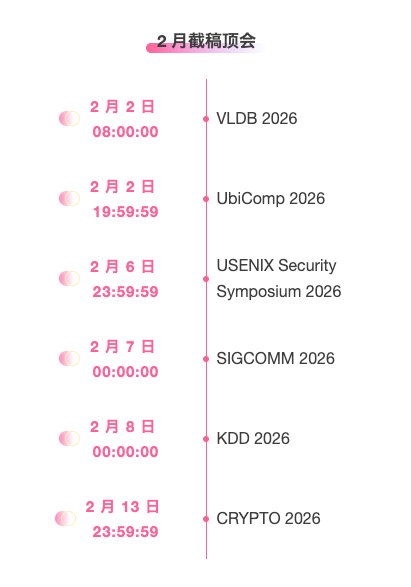
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








