Command Palette
Search for a command to run...
Meituans Open-Source-Videogenerierungsmodell LongCat-Video Kombiniert Textbasierte Videogenerierung, Bildbasierte Videogenerierung Und Videofortsetzungsfunktionen Und Konkurriert Damit Mit Erstklassigen Open-Source- Und Closed-Source-Modellen.

Weltmodelle dienen dem Verständnis, der Simulation und der Vorhersage komplexer realer Umgebungen und bilden somit eine entscheidende Grundlage für den effektiven Einsatz künstlicher Intelligenz in realen Szenarien. In diesem Kontext komprimieren und erlernen Videogenerierungsmodelle im Laufe ihres Generierungsprozesses schrittweise verschiedene Wissensformen, darunter geometrische, semantische und physikalische Elemente.Daher wird es als ein wichtiger Weg zum Aufbau eines Weltmodells angesehen und soll letztendlich eine effektive Simulation und Vorhersage der Dynamik der realen physikalischen Welt ermöglichen.Im Bereich der Videogenerierung ist die Erzielung effizienter Fähigkeiten zur Generierung langer Videos von besonderer Bedeutung.
Auf dieser GrundlageMeituan hat sein neuestes Videogenerierungsmodell LongCat-Video als Open Source veröffentlicht. Ziel des Modells ist es, verschiedene Videogenerierungsaufgaben über eine einheitliche Architektur zu bewältigen, darunter Text-zu-Video, Bild-zu-Video und Videofortsetzung.Aufgrund seiner herausragenden Leistung bei allgemeinen Videogenerierungsaufgaben wird LongCat-Video vom Forschungsteam als ein solider Schritt hin zum Aufbau eines echten „Weltmodells“ angesehen.
Zu den Hauptmerkmalen von LongCat-Video gehören:
* Einheitliche Architektur für vielfältige Aufgaben. LongCat-Video vereint textbasiertes Video, bildbasiertes Video und Videofortsetzungsaufgaben in einem einzigen Videogenerierungs-Framework und unterscheidet sie durch die Anzahl der bedingten Frames.
* Fähigkeit zur Generierung langer Videos. LongCat-Video ist auf Basis von Videofortsetzungsaufgaben vortrainiert, wodurch es Videos von mehreren Minuten Länge generieren und Farbverzerrungen oder andere Formen der Bildqualitätsminderung während des Generierungsprozesses effektiv vermeiden kann.
* Effizientes Denken. LongCat-Video verwendet eine „Grob-zu-Fein“-Strategie, um in nur wenigen Minuten 720p-Videos mit 30 Bildern pro Sekunde zu erzeugen und so die Genauigkeit und Effizienz der Videogenerierung effektiv zu verbessern.
* Die überragende Leistungsfähigkeit des Multi-Reward Reinforcement Learning Frameworks (RLHF). LongCat-Video verwendet Group Relative Policy Optimization (GRPO), wodurch die Modellleistung durch die Verwendung mehrerer Belohnungen weiter verbessert wird und eine Leistung erreicht wird, die mit führenden Open-Source-Videogenerierungsmodellen und den neuesten kommerziellen Lösungen vergleichbar ist.
Basierend auf internen Benchmark-Leistungsbewertungen schneidet LongCat-Video bei texturierten Videoaufgaben gut ab.Es schneidet sowohl in der Bild- als auch in der Bewegungsqualität außergewöhnlich gut ab und erreicht fast das Niveau des Spitzenmodells Wan2.2.Das Modell erzielte auch robuste Ergebnisse bei der Textausrichtung und der Gesamtqualität und bot den Nutzern ein durchgängig hochwertiges Erlebnis in mehreren Dimensionen.
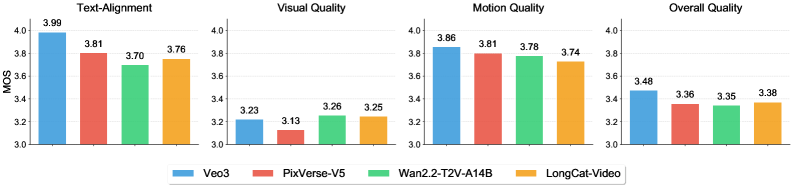
Bei der Bild-zu-Video-Konvertierung zeichnet sich LongCat-Video durch seine Bildqualität aus und übertrifft andere Modelle wie Wan2.2. Es beweist damit seinen deutlichen Vorteil bei der Erzeugung hochwertiger Bilder. Allerdings besteht in Bereichen wie Bildausrichtung und Gesamtqualität noch Verbesserungspotenzial.

Vor Kurzem kam es bei Cloudflare zu einer Störung, die Verbindungsabbrüche bei zahlreichen Internetanwendungen, darunter X, ChatGPT und Canva, verursachte. Schauen wir uns an, wie LongCat-Video die Reaktion auf diese Störung simuliert hat 👇
Aktuell ist „LongCat-Video: Meituans Open-Source-KI-Videogenerierungsmodell“ im Bereich „Tutorials“ auf der HyperAI-Website verfügbar. Klicken Sie auf den unten stehenden Link, um die Anleitung zur Ein-Klick-Bereitstellung zu starten ⬇️
Link zum Tutorial:
Demolauf
1. Nachdem Sie die Homepage von hyper.ai aufgerufen haben, wählen Sie „LongCat-Video: Meituans Open-Source-KI-Videogenerierungsmodell“ aus oder gehen Sie zur Seite „Tutorials“, wählen Sie es aus und klicken Sie dann auf „Dieses Tutorial online ausführen“.


2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.

3. Wählen Sie die Images „NVIDIA RTX PRO 6000 Blackwell“ und „PyTorch“ aus und wählen Sie je nach Bedarf „Pay As You Go“ oder „Tagesplan/Wochenplan/Monatsplan“. Klicken Sie anschließend auf „Auftragsausführung fortsetzen“.


4. Warten Sie auf die Ressourcenzuweisung. Der erste Klonvorgang dauert etwa 3 Minuten. Sobald der Status auf „Wird ausgeführt“ wechselt, klicken Sie auf den Pfeil neben „API-Adresse“, um zur Demoseite zu gelangen.

Effektdemonstration
Nach dem Aufrufen der Demo-Oberfläche können Sie aus vier Beispielen zum Testen auswählen: Bild-zu-Video, Text-zu-Video, Langes Video und Video-Fortsetzung. In diesem Artikel wird die Bild-zu-Video-Konvertierung als Beispiel verwendet.
Nach dem Hochladen des Beispielbildes geben Sie „Prompt“ ein. Unter „Erweiterte Optionen“ können Sie weitere Einstellungen für Parameter wie negative Prompts, Auflösung und den Startpunkt der Zufälligkeit im Generierungsprozess vornehmen, um einen idealeren Generierungseffekt zu erzielen.


Vor Kurzem kam es bei Cloudflare zu einer Störung, die Verbindungsabbrüche bei zahlreichen Internetanwendungen, darunter X, ChatGPT und Canva, verursachte. Sehen wir uns die Simulation von LongCat-Video an, die zeigt, wie die Nutzer auf die Störung reagierten 👇
Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!
Link zum Tutorial:








