Command Palette
Search for a command to run...
Mit 2,6.000 Sternen Übertrifft MonkeyOCR-3B Das 72B-Modell Bei Der Analyse Englischer Dokumente Und Erreicht Die SOTA-Leistung

Heute beschränkt sich die OCR-Technologie (Optical Character Recognition) nicht mehr nur auf die Texterkennung, sondern entwickelt sich allmählich zu einem komplexeren System zur Dokumentenanalyse. Von der anfänglich einfachen Zeichenextraktion bis hin zum multimodalen Großmodell, das in den letzten Jahren entstanden ist,OCR wurde in Aufgaben wie Layoutverständnis, semantische Erkennung und Strukturwiederherstellung integriert und wird häufig in der Dokumenterkennung, Untertitelerkennung, Logistiksortierung, Literatursuche und anderen Bereichen eingesetzt.Die vielfältigen Anwendungsszenarien stellen zudem erhöhte Anforderungen an das Modell.
Beispielsweise verwenden die meisten herkömmlichen OCR-Modelle ein modulares Design, das eine Zerlegung der Dokumentenanalyse in mehrere feingranulare Teilaufgaben erfordert. Dies ist ineffizient und lässt sich nur schwer einheitlich optimieren. Obwohl das umfassende Modell leistungsstark ist, erfordert es extrem hohe Ressourcen und ist schwer universell zu implementieren. Komplexe Dokumente, die aus mehreren Elementen wie Text, Tabellen, mathematischen Ausdrücken und eingebetteten Grafiken bestehen, stellen immer noch eine erhebliche Beeinträchtigung der Genauigkeit dar.
In Anbetracht dessenDie Huazhong University of Science and Technology und Kingsoft Office haben gemeinsam ein Dokumentanalysemodell namens MonkeyOCR eingeführt.Es kann unstrukturierte Dokumentinhalte effizient in strukturierte Informationen umwandeln. Unter dem SRR-Paradigma wird die Dokumentenanalyse in drei grundlegende Fragen abstrahiert: Wo (Struktur), Was (Erkennung) und Wie (Relation), die jeweils der Layoutanalyse, der Inhaltserkennung und der logischen Sortierung entsprechen. Diese klare Aufgabenzerlegung erreicht ein Gleichgewicht zwischen Genauigkeit und Geschwindigkeit.Unterstützt effiziente und skalierbare Verarbeitung ohne Kompromisse bei der Genauigkeit.
Um das Modell ausreichend mit Daten zu unterstützen, erstellte das Forschungsteam einen Datensatz namens MonkeyDoc.Dies ist der bislang umfassendste Datensatz zur Dokumentanalyse. Er enthält 3,9 Millionen Instanzen und deckt eine Vielzahl von Dokumenttypen ab (z. B. Notizen, PPTs, Zeitschriften, Prüfungsunterlagen usw.).Gleichzeitig werden auch verschiedene Strukturblöcke (Tabellen, Bilder, Texte, Formeln etc.) detailliert gekennzeichnet.
Den experimentellen Ergebnissen des Forschungsteams zufolge schneidet MonkeyOCR bei der Verarbeitung komplexer Dokumente, beispielsweise solcher mit Formeln und Tabellen, gut ab.Die Leistung bei Formel- und Tabellenanalyseaufgaben verbesserte sich um 15,01 TP3T bzw. 8,61 TP3T.Auch hinsichtlich der Verarbeitungsgeschwindigkeit mehrseitiger Dokumente übertrifft es andere Modelle bei weitem und erreicht 0,84 Seiten pro Sekunde.
Es ist erwähnenswert, dass sein 3B-Parametermodell bei der Analyse englischer Dokumente das gängige 72B-Modell übertrifft und die durchschnittliche Leistung das SOTA-Niveau erreicht. Heute ist MonkeyOCR weniger als einen Monat alt und seine GitHub-Sterne haben 2,6.000 erreicht.
„MonkeyOCR: Dokumentenanalyse basierend auf dem Struktur-Erkennungs-Beziehungs-Dreifachparadigma“ wurde im Abschnitt „Tutorial“ der offiziellen Website von HyperAI Super Neural (hyper.ai) veröffentlicht. Kommen Sie vorbei und erleben Sie es ⬇️
Link zum Tutorial:
Demolauf
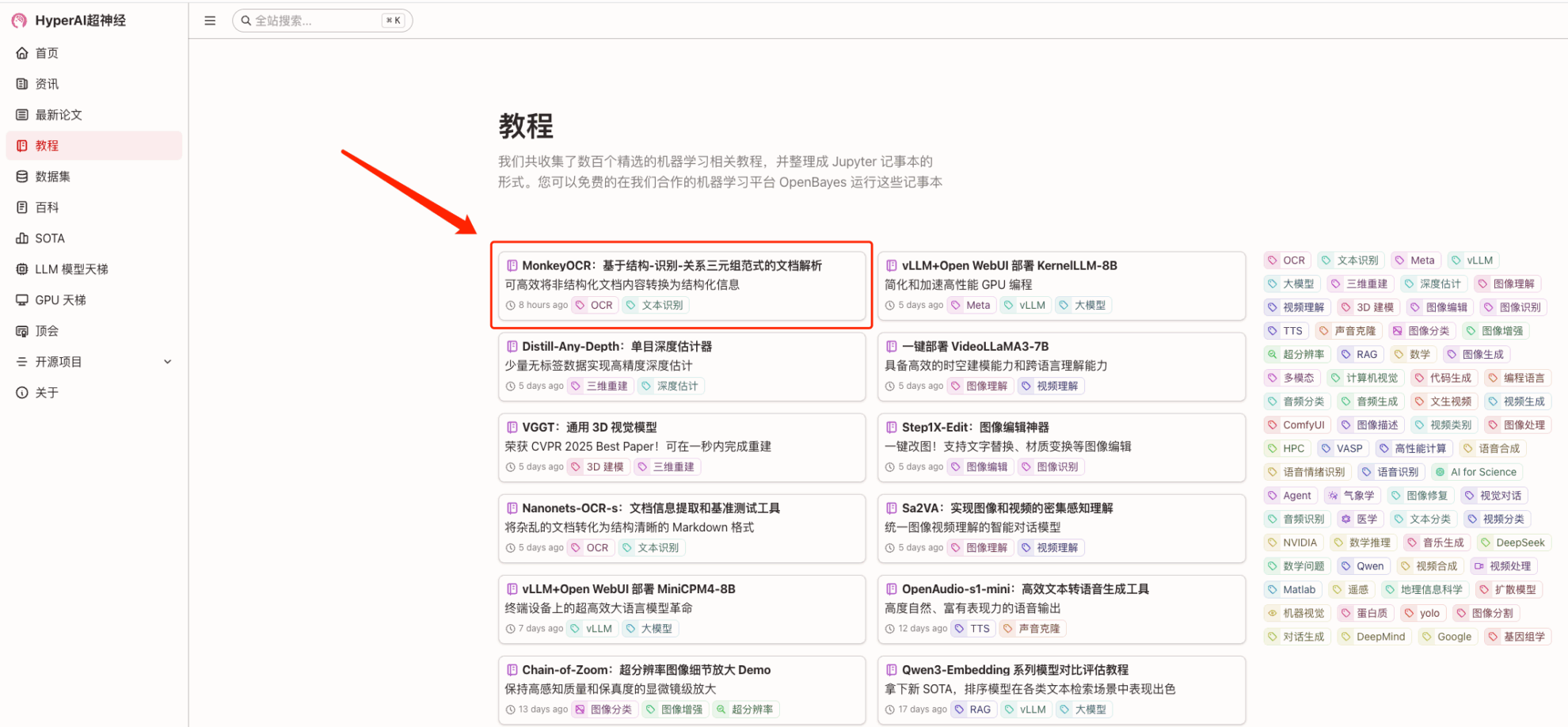
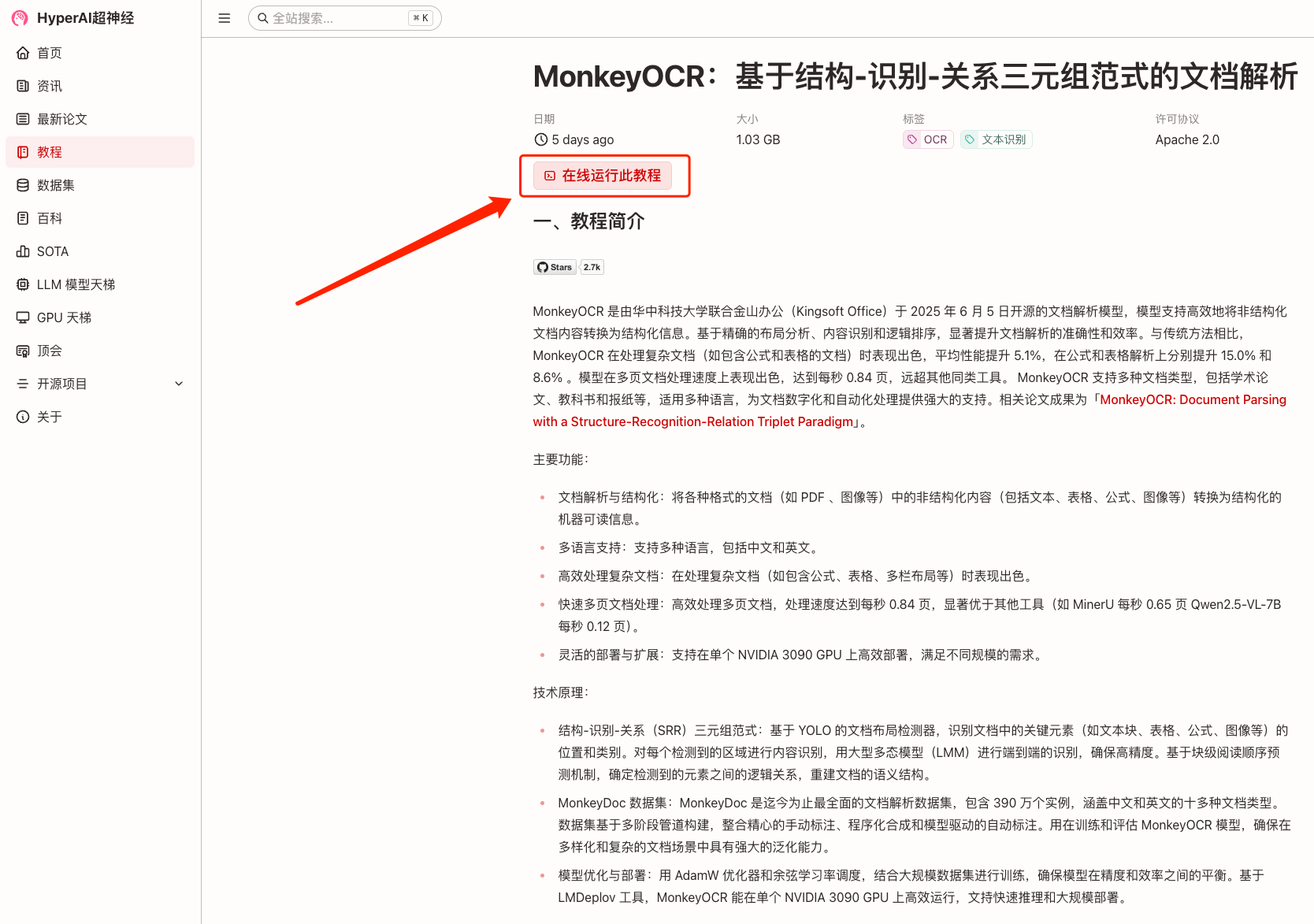
1. Nachdem Sie die Homepage von hyper.ai aufgerufen haben, wählen Sie die Seite „Tutorial“, wählen Sie „MonkeyOCR: Dokumentanalyse basierend auf dem dreifachen Struktur-Erkennungs-Beziehungs-Paradigma“ und klicken Sie auf „Dieses Tutorial online ausführen“.
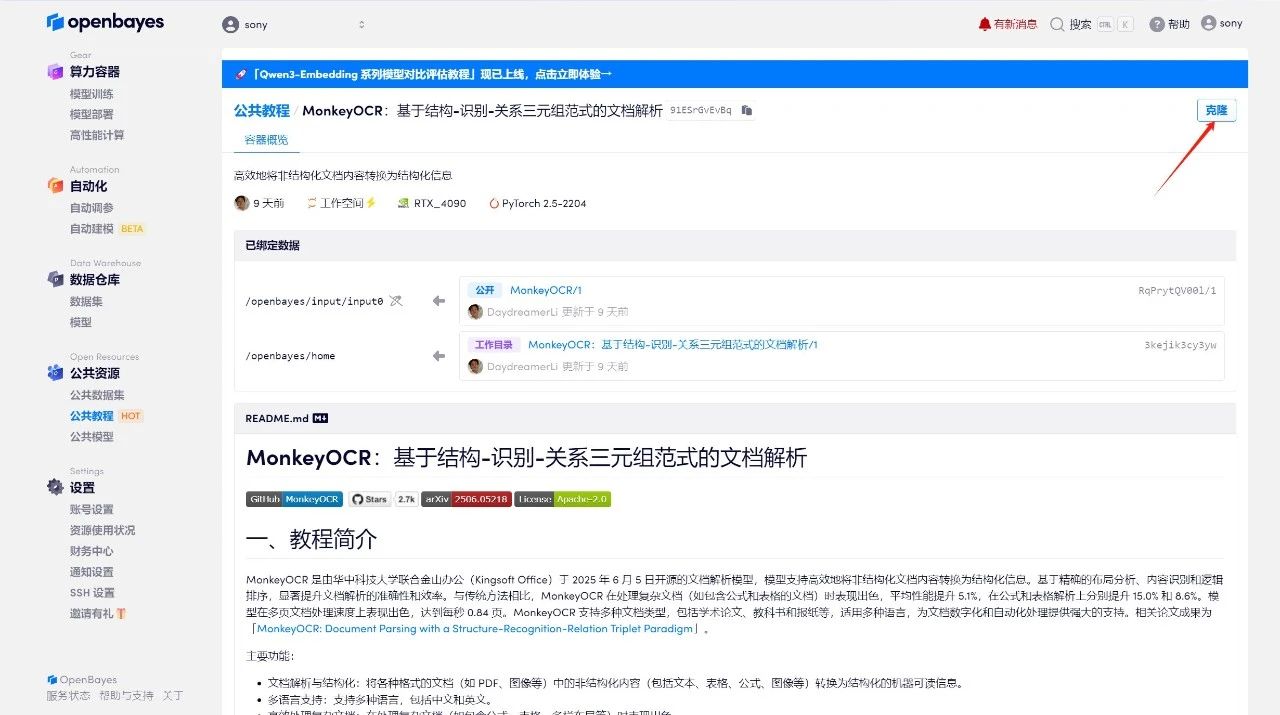
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
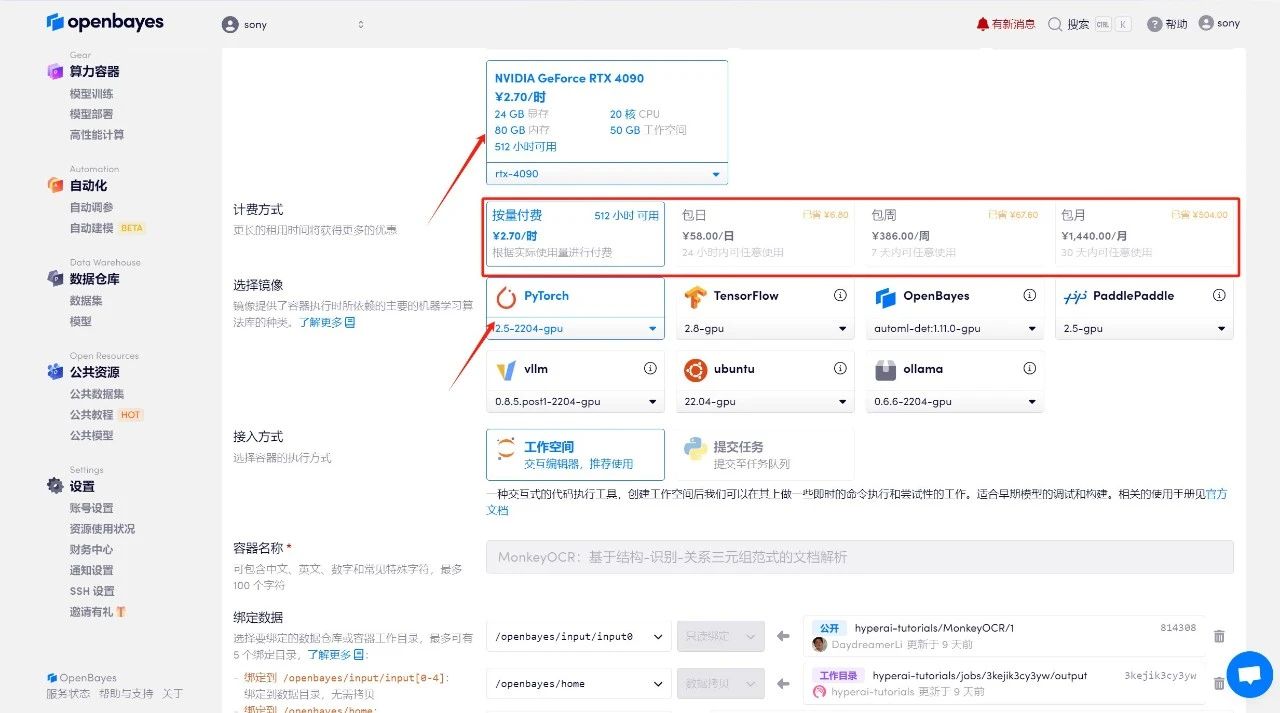
3. Wählen Sie die Bilder „NVIDIA GeForce RTX 4090“ und „PyTorch“ aus. Die OpenBayes-Plattform bietet vier Abrechnungsmethoden. Sie können je nach Bedarf zwischen „Pay as you go“ oder „Täglich/Wöchentlich/Monatlich“ wählen. Klicken Sie auf „Weiter“. Neue Benutzer können sich über den unten stehenden Einladungslink registrieren, um 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit zu erhalten!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_NR0n
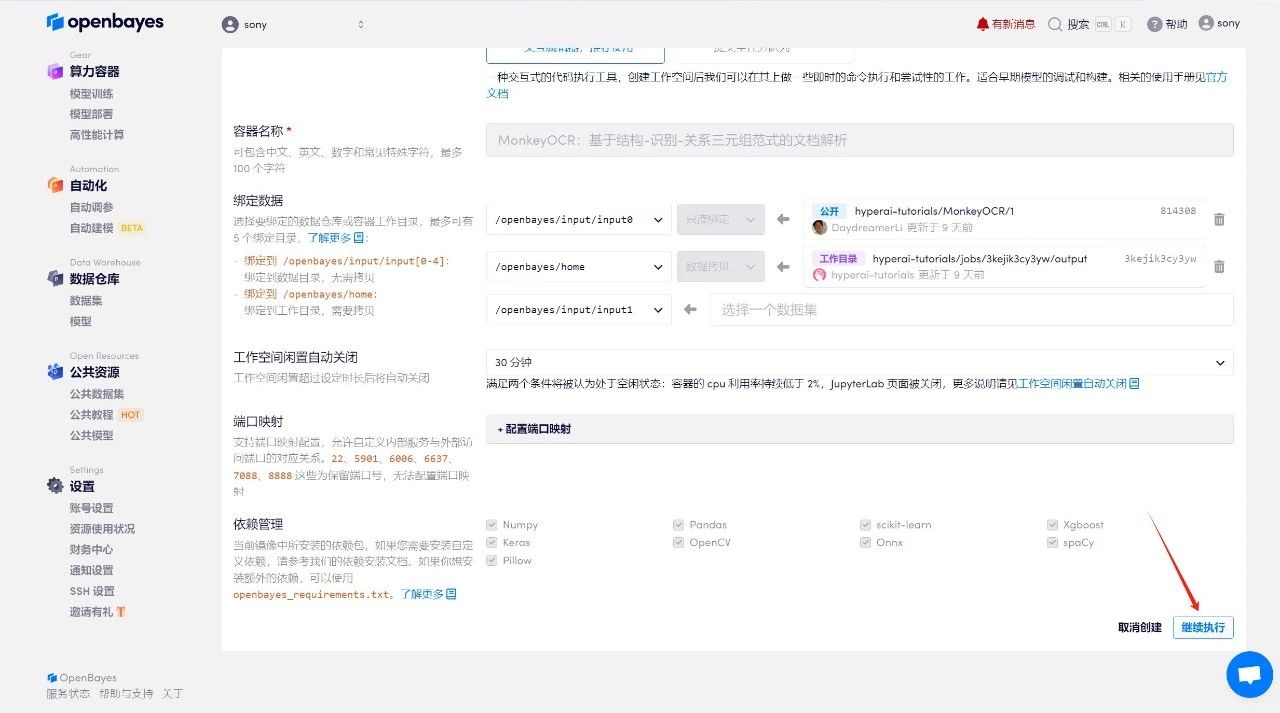
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 2 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen. Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.
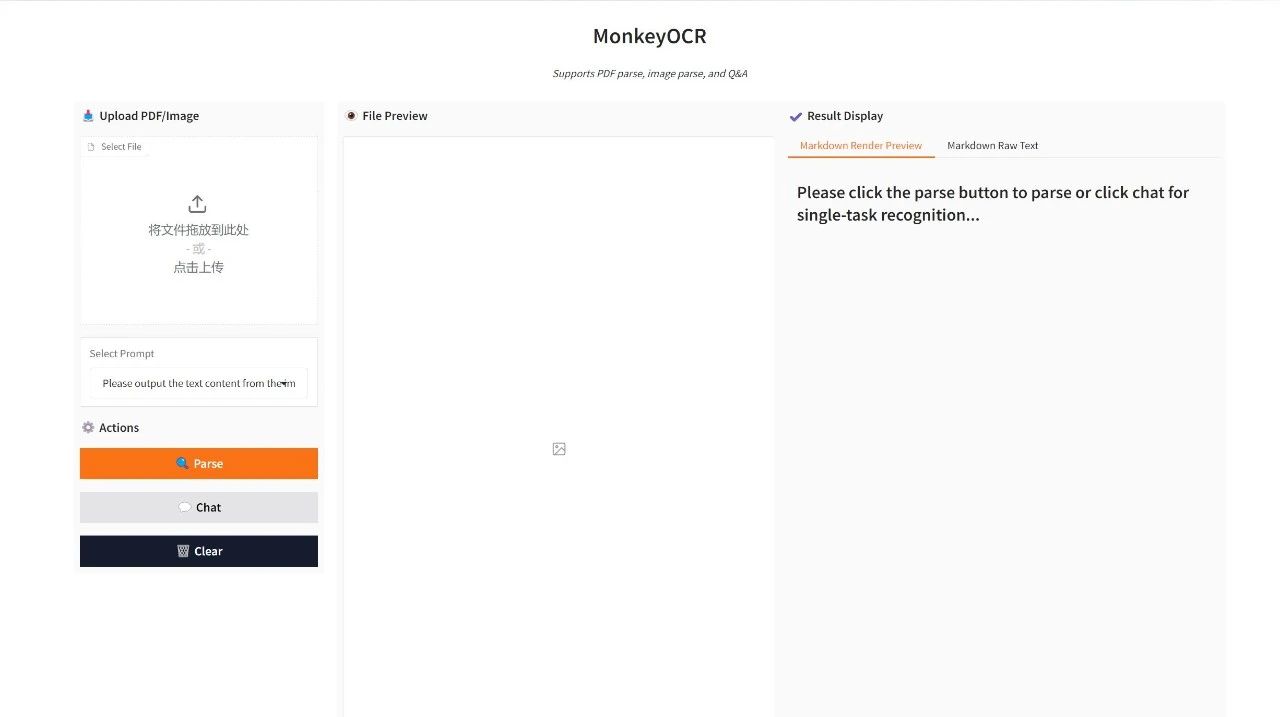
Effektdemonstration
Laden Sie eine PDF-Datei oder ein Bild hoch und klicken Sie auf „Analysieren“, um es zu analysieren. Wenn Sie den Chat-Modus wählen, müssen Sie unter „Eingabeaufforderung auswählen“ die Option „Eingabeaufforderung“ auswählen.
Die Ausgabeergebnisse werden unter „Ergebnisanzeige“ angezeigt. Klicken Sie auf „PDF-Layout herunterladen/Markdown herunterladen“, um das Dokument im PDF-/Markdown-Format auf Ihren lokalen Computer herunterzuladen.
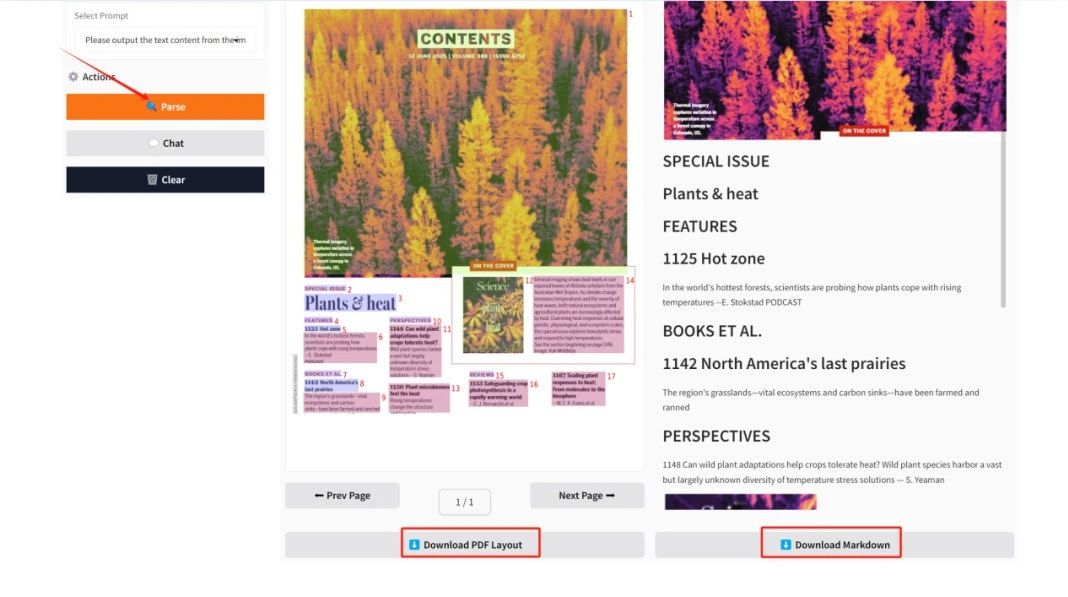

Das obige Tutorial ist die empfohlene Lösung für dieses Problem. Wir laden alle herzlich ein, es auszuprobieren ⬇️
Link zum Tutorial:








