Command Palette
Search for a command to run...
AI Paper Weekly Report | Modernste OCR-Technologie: DeepSeek, Tencent Und Baidu Konkurrieren Auf Derselben Bühne – Von Der Zeichenerkennung Bis Zur Analyse Strukturierter Dokumente

In den letzten Jahren hat sich die OCR (optische Zeichenerkennung) rasant von einem „Zeichenerkennungswerkzeug“ zu... entwickelt.Ein allgemeines Dokumentenverständnissystem basierend auf einem Bild-Sprach-ModellWährend globale Unternehmen wie Microsoft und Google weiterhin investieren, nehmen auch führende chinesische Anbieter wie Baidu, Tencent und Alibaba Cloud intensive Implementierungen vor und treiben den Markt dazu voran, schnell von regelbasierter OCR auf intelligente Dokumentenverarbeitung (IDP) umzusteigen, die künstliche Intelligenz und Verarbeitung natürlicher Sprache integriert, und ihre Anwendung in realen Geschäftsszenarien wie Finanzen, Regierungsangelegenheiten und Gesundheitswesen kontinuierlich zu vertiefen.
Angetrieben von der anhaltenden Nachfrage der Industrie hat sich auch der Fokus der OCR-Forschung deutlich verändert:Das Modell verfolgt nicht mehr nur die "Erkennungsgenauigkeit", sondern hat begonnen, systematisch anspruchsvollere Probleme wie komplexe Layouts, multimodale Symbole, die Modellierung langer Kontexte und das durchgängige semantische Verständnis zu lösen.Wie man zweidimensionale visuelle Informationen effizient kodiert, Textinformationen effizienter analysiert und die Lesereihenfolge des Modells der menschlichen kognitiven Logik annähert, werden zu zentralen Themen, die Wissenschaft und Industrie gleichermaßen beschäftigen.
Vor diesem Hintergrund intensiver Interaktion ist die kontinuierliche Verfolgung und Analyse der neuesten wissenschaftlichen Arbeiten zum Thema OCR von besonderer Bedeutung, um die neuesten technologischen Entwicklungen zu erfassen, die realen Herausforderungen der Branche zu verstehen und sogar die nächste Stufe paradigmatischer Durchbrüche zu finden.
Diese Woche empfehlen wir 5 populäre KI-Artikel zum Thema OCR.Es sind Teams von DeepSeek, Tencent, der Tsinghua-Universität und anderen beteiligt. Lasst uns gemeinsam lernen! ⬇️
Um außerdem mehr Nutzern die neuesten Entwicklungen auf dem Gebiet der künstlichen Intelligenz in der Wissenschaft näherzubringen, hat die Website HyperAI (hyper.ai) eine Rubrik „Neueste Veröffentlichungen“ eingerichtet, die täglich mit hochaktuellen KI-Forschungsarbeiten aktualisiert wird.
Neueste KI-Artikel:https://go.hyper.ai/hzChC
Die Zeitungsempfehlung dieser Woche
- DeepSeek-OCR 2: Visueller Kausalfluss
Aufbauend auf DeepSeek-OCR haben die Forscher von DeepSeek-AI DeepSeek-OCR 2 entwickelt. Während DeepSeek-OCR die Machbarkeit der Komprimierung langer Kontexte mittels zweidimensionaler optischer Kartierung untersuchte, zielt DeepSeek-OCR 2 darauf ab, die Machbarkeit eines neuartigen Encoders – DeepEncoderV2 – zu erforschen, der visuelle Token dynamisch anhand der Bildsemantik neu anordnet. DeepEncoderV2 stattet den Encoder mit kausalem Denken aus und ermöglicht so die intelligente Neuanordnung visueller Token vor der LLM-basierten Inhaltsanalyse. Dadurch wird die starre Rasterscan-Verarbeitung ersetzt. Dies führt zu einer menschenähnlicheren, semantisch kohärenteren Bildanalyse und verbessert die OCR- und Dokumentenanalysefunktionen.
Papier und detaillierte Interpretation:https://go.hyper.ai/ChW45
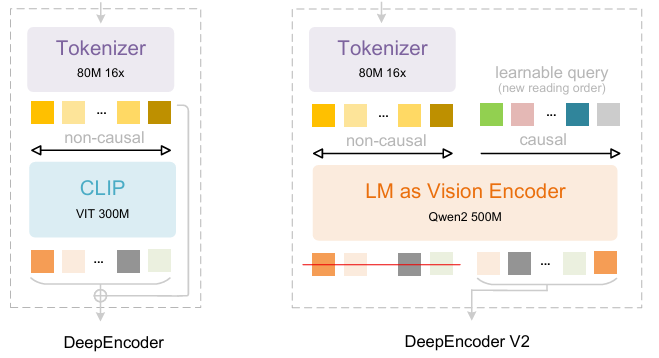
Der Trainingsdatensatz besteht aus OCR 1.0-, OCR 2.0- und allgemeinen Bildverarbeitungsdaten, wobei die OCR-Daten 80% der gemischten Trainingsdaten ausmachen. Zur Evaluierung wurde OmniDocBench v1.5 verwendet, ein Benchmark mit 1.355 Seiten chinesischer und englischer Dokumente aus Zeitschriften, wissenschaftlichen Artikeln und Forschungsberichten in neun Kategorien.
2. LightOnOCR: Ein 1B-End-to-End-Mehrsprachigkeits-Bildverarbeitungsmodell für modernste OCR
Die Forscher von LightOn haben LightOnOCR-2-1B veröffentlicht, ein kompaktes, mehrsprachiges visuelles Sprachmodell mit einer Milliarde Parametern, das sauberen, geordneten Text direkt aus Dokumentenbildern extrahiert und dabei größere Modelle übertrifft. Es verbessert zudem die Bildlokalisierungsfähigkeiten durch RLVR und erhöht die Robustheit durch Checkpoint-Merging. Das Modell und die Benchmarks sind Open Source.
Papier und detaillierte Interpretation:https://go.hyper.ai/zXFQs
Link zum Ein-Klick-Bereitstellungstutorial:https://go.hyper.ai/vXC4o
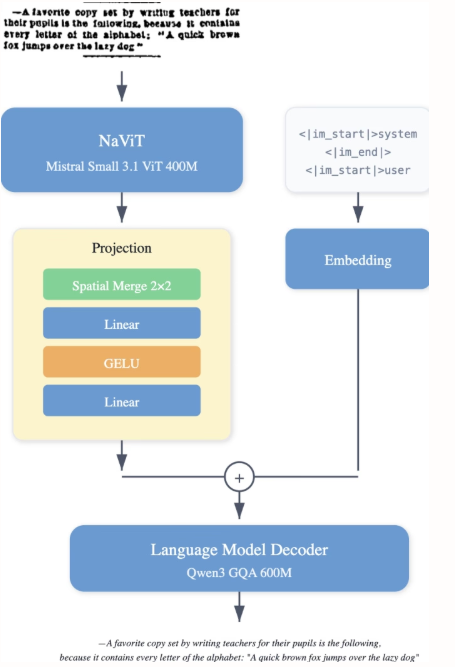
Der Datensatz LightOnOCR-2-1B kombiniert von Lehrkräften annotierte Seiten aus verschiedenen Quellen, darunter gescannte Dokumente zur Verbesserung der Robustheit und ergänzende Daten zur Layoutvielfalt. Er enthält mit GPT-4o annotierte Ausschnitte (Absätze, Überschriften, Abstracts), Beispiele leerer Seiten zur Vermeidung von optischen Täuschungen sowie TeX-basierte Supervision, die über die nvpdftex-Pipeline von arXiv bezogen wurde. Öffentliche OCR-Datensätze wurden hinzugefügt, um die Diversität zu erhöhen.
3. Technischer Bericht zu HunyuanOCR
Dieser Artikel stellt HunyuanOCR vor, ein Open-Source-Bildverarbeitungsmodell mit einer Milliarde Parametern, entwickelt von Tencent und seinen Kooperationspartnern. Durch datengetriebenes Training und eine neuartige Reinforcement-Learning-Strategie vereint es mit einer schlanken Architektur (ViT-LLM MLP-Adapter) umfassende OCR-Funktionen, darunter Textlokalisierung, Dokumentenanalyse, Informationsextraktion und Übersetzung. Seine Leistung übertrifft die größerer Modelle und kommerzieller APIs und ermöglicht so einen effizienten Einsatz in industriellen und wissenschaftlichen Forschungsanwendungen.
Papier und detaillierte Interpretation:https://go.hyper.ai/F9fni
Link zum Ein-Klick-Bereitstellungstutorial:https://go.hyper.ai/C4srs

In dieser Arbeit wird HunyuanOCR zur Bewertung der Dokumentenanalyseleistung auf OmniDocBench verwendet. Es erzielt die höchste Gesamtpunktzahl von 94,10 und übertrifft damit alle anderen Modelle (einschließlich größerer).
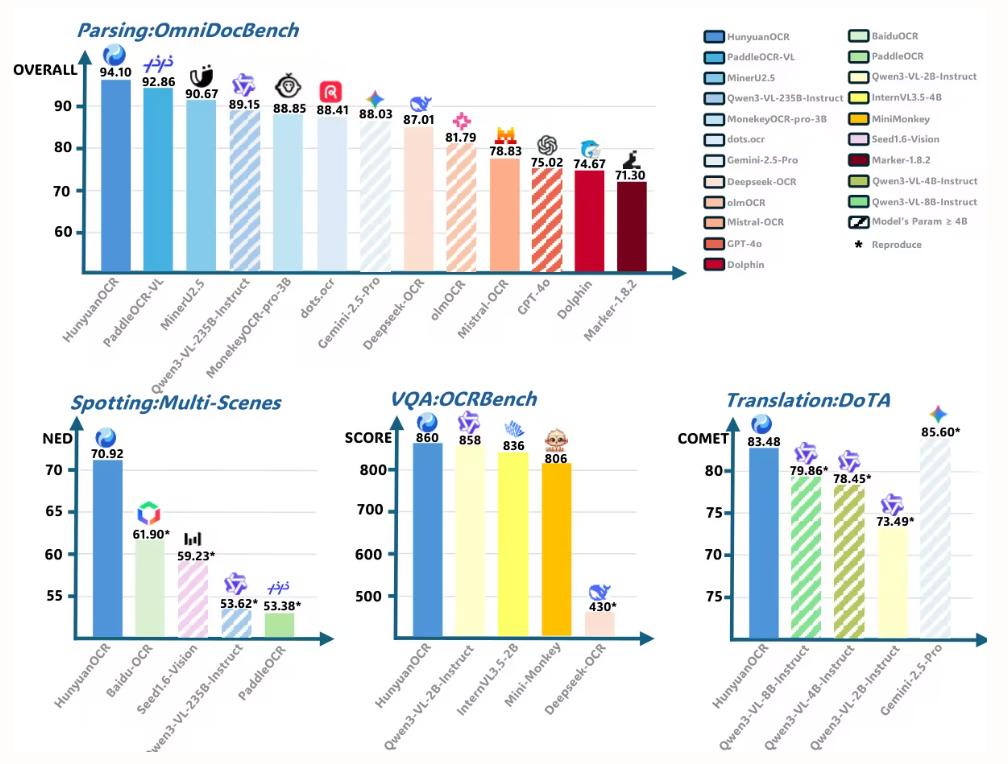
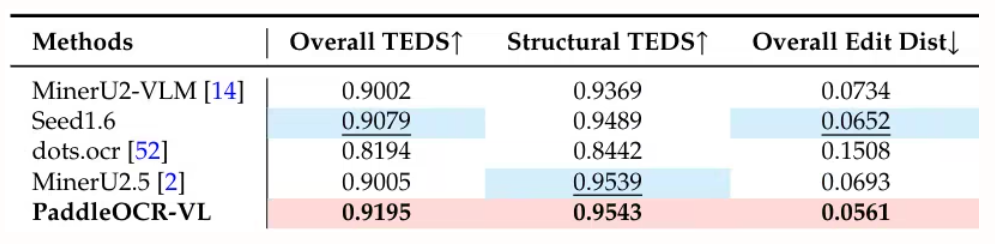
4 .PaddleOCR-VL: Steigerung der mehrsprachigen Dokumentenanalyse durch ein 0,9-B-Ultrakompaktes Bildverarbeitungs- und Sprachmodell
Das Team von Baidu hat PaddleOCR-VL entwickelt, ein ressourcenschonendes Bildverarbeitungsmodell, das einen dynamischen Auflösungs-Encoder im NaViT-Stil mit dem ERNIE-4.5-0.3B-Modell kombiniert. Es erzielt Spitzenleistungen beim Parsen mehrsprachiger Dokumente und erkennt komplexe Elemente wie Tabellen und Formeln präzise. Dabei bietet es schnelle Schlussfolgerungsfähigkeiten, übertrifft bestehende Lösungen und eignet sich für den Einsatz in realen Anwendungsszenarien.
Papier und detaillierte Interpretation:https://go.hyper.ai/Rw3ur
Link zum Ein-Klick-Bereitstellungstutorial:https://go.hyper.ai/5D8oo
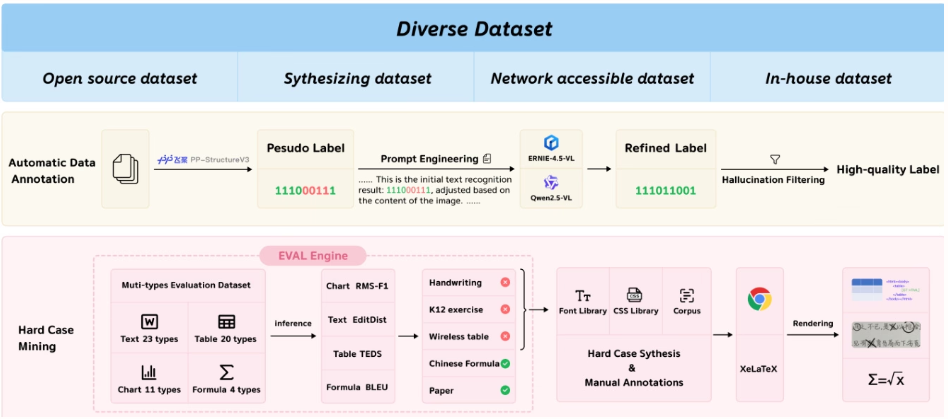
Diese Studie evaluierte die seitenweise Dokumentenanalyse mit OmniDocBench v1.5, olmOCR-Bench und OmniDocBench v1.0. Sie erzielte mit OmniDocBench v1.5 einen hervorragenden Gesamtscore von 92,86, der besser ist als der von MinerU2.5-1.2B (90,67). Auch bei Texten (Editierdistanz 0,035), Formeln (CDM 91,22), Tabellen (TEDS 90,89 und TEDS-S 94,76) und der Lesereihenfolge (0,043) erreichte sie Spitzenwerte.
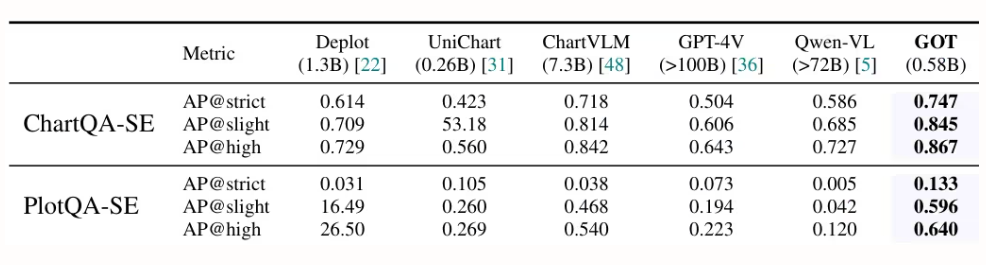
5. Allgemeine OCR-Theorie: Auf dem Weg zu OCR-2.0 durch ein einheitliches End-to-End-Modell
Forscher von StepFun, Megvii Technology, der Universität der Chinesischen Akademie der Wissenschaften und der Tsinghua-Universität haben GOT entwickelt, ein einheitliches End-to-End-OCR-2.0-Modell mit 580 Millionen Parametern. Durch einen hochkomprimierenden Encoder und einen Decoder mit langem Kontext erweitert es die Erkennungsfähigkeiten von Text auf eine Vielzahl künstlicher optischer Signale – wie mathematische Formeln, Tabellen, Diagramme und geometrische Figuren. Es unterstützt die Eingabe von Abschnitten/ganzen Seiten, formatierte Ausgabe (Markdown/TikZ/SMILES), interaktive Bereichserkennung, dynamische Auflösung und die Verarbeitung mehrseitiger Daten und leistet damit einen bedeutenden Beitrag zur Entwicklung intelligenter Dokumentenanalyse.
Papier und detaillierte Interpretation:https://go.hyper.ai/9E6Ra
Link zum Ein-Klick-Bereitstellungstutorial:https://go.hyper.ai/HInRr
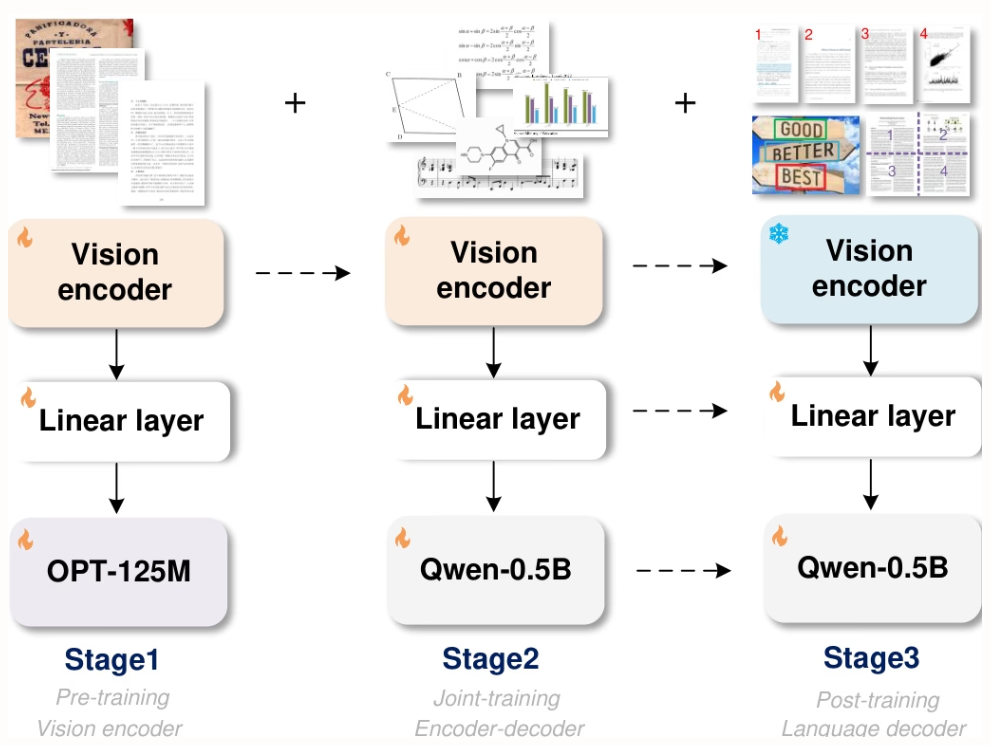
Die in dieser Arbeit beschriebenen Experimente wurden auf einer 8×8 L40s GPU durchgeführt. Das Training umfasste drei Phasen: Vortraining (3 Runden, Batchgröße 128, Lernrate 1e-4), gemeinsames Training (1 Runde, maximale Tokenlänge 6000) und Nachtraining (1 Runde, maximale Tokenlänge 8192, Lernrate 2e-5). In der ersten Phase wurden 80% Daten beibehalten, um die Leistung aufrechtzuerhalten.
Dies ist der gesamte Inhalt der Papierempfehlung dieser Woche. Weitere aktuelle KI-Forschungsarbeiten finden Sie im Bereich „Neueste Arbeiten“ auf der offiziellen Website von hyper.ai.
Wir freuen uns auch über die Einreichung hochwertiger Ergebnisse und Veröffentlichungen durch Forschungsteams. Interessierte können sich im NeuroStar WeChat anmelden (WeChat-ID: Hyperai01).
Bis nächste Woche!








