Command Palette
Search for a command to run...
Kosten Werden Deutlich Reduziert! Distill-Any-Depth Ermöglicht Hochpräzise Tiefenschätzung; Ausgewählt Für CVPR 2025! Real-IADD Erschließt Neue Höhen in Der Industriellen Detektion

Die monokulare metrische Tiefenschätzung ist eine Computer-Vision-Technik, die darauf abzielt, die absolute Tiefe aus einem einzelnen RGB-Bild vorherzusagen. Diese Technik findet breite Anwendung in Bereichen wie autonomes Fahren, Augmented Reality, Robotik und 3D-Szenenverständnis.
Die monokulare Tiefenschätzung (MDE) mit Null-Schuss verbessert die Generalisierungsmöglichkeiten erheblich, indem sie die Tiefenverteilung vereinheitlicht und große Mengen unmarkierter Daten nutzt. Bestehende Methoden behandeln jedoch alle Tiefenwerte einheitlich, was das Rauschen in Pseudo-Labels verstärken und den Destillationseffekt verringern kann. Auf dieser Grundlage haben die Zhejiang University of Technology und mehrere andere Universitäten Distill-Any-Depth veröffentlicht.
Distill-Any-Depth integriert die Vorteile mehrerer Open-Source-Modelle durch den Destillationsalgorithmus und erreicht eine hochpräzise Tiefenschätzung mit nur einer kleinen Menge nicht gekennzeichneter Daten.Im Vergleich zu herkömmlichen Methoden, die Millionen von Anmerkungen erfordern, sind für dieses Projekt nur 20.000 unbeschriftete Bilder erforderlich, wodurch die Kosten für die Datenanmerkungen erheblich gesenkt werden.
HyperAI hat derzeit das Tutorial „Distill-Any-Depth: Monocular Depth Estimator“ veröffentlicht. Probieren Sie es aus!
Distill-Any-Depth: Monokularer Tiefenschätzer
Online-Nutzung:https://go.hyper.ai/DNSf5
Vom 16. bis 20. Juni gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorials: 14
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im Juli: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
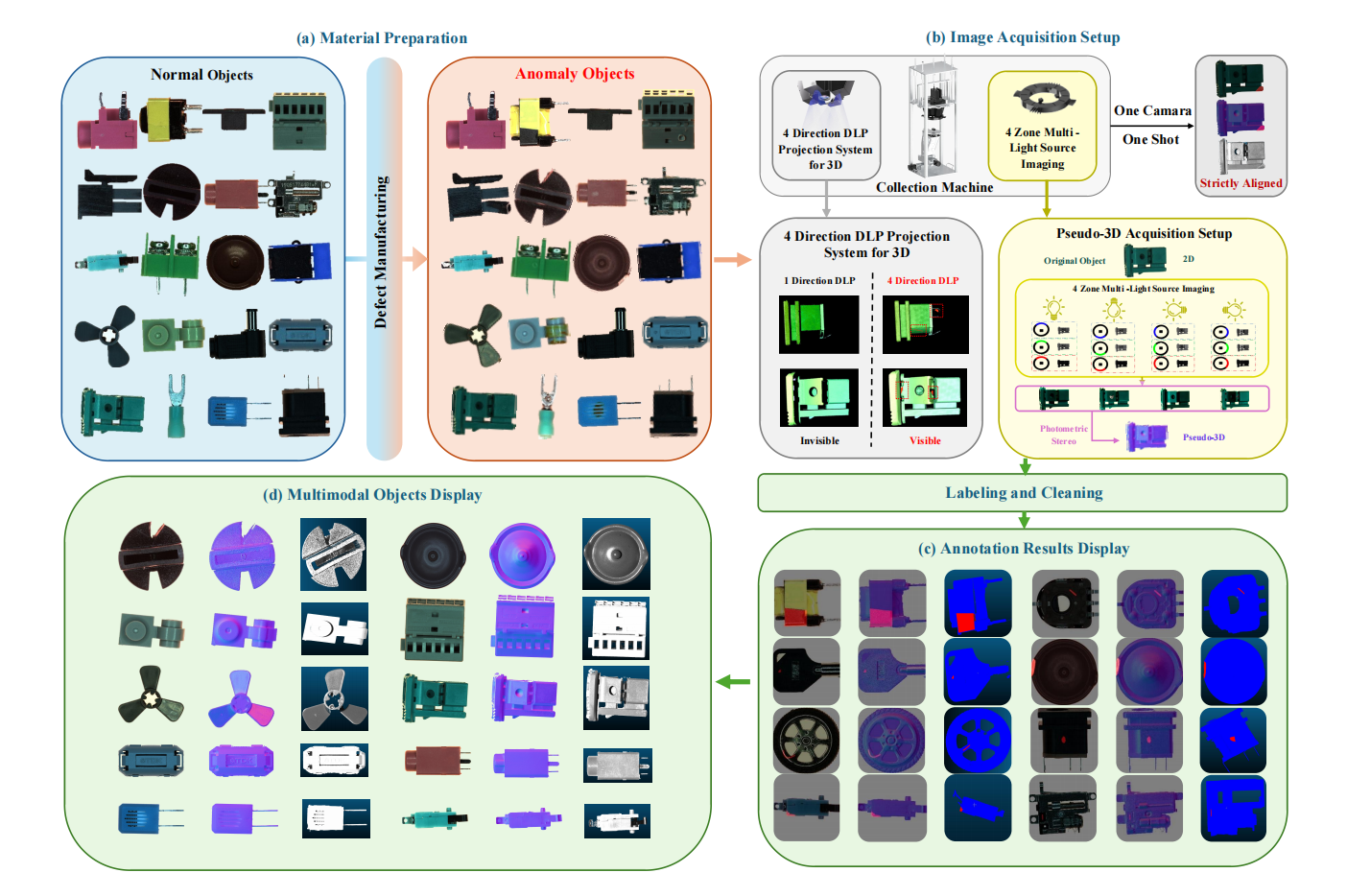
1. Real-IAD D³-Datensatz zur industriellen Anomalieerkennung
Real-IAD D³ ist ein hochpräziser multimodaler Datensatz, und zugehörige Beiträge wurden in die führende Computer Vision-Konferenz CVPR 2025 aufgenommen. Der Datensatz enthält 20 Industrieproduktkategorien, 69 Defekttypen und insgesamt 8.450 Proben, darunter 5.000 normale Proben und 3.450 abnormale Proben.
Direkte Verwendung:https://go.hyper.ai/i4T8m
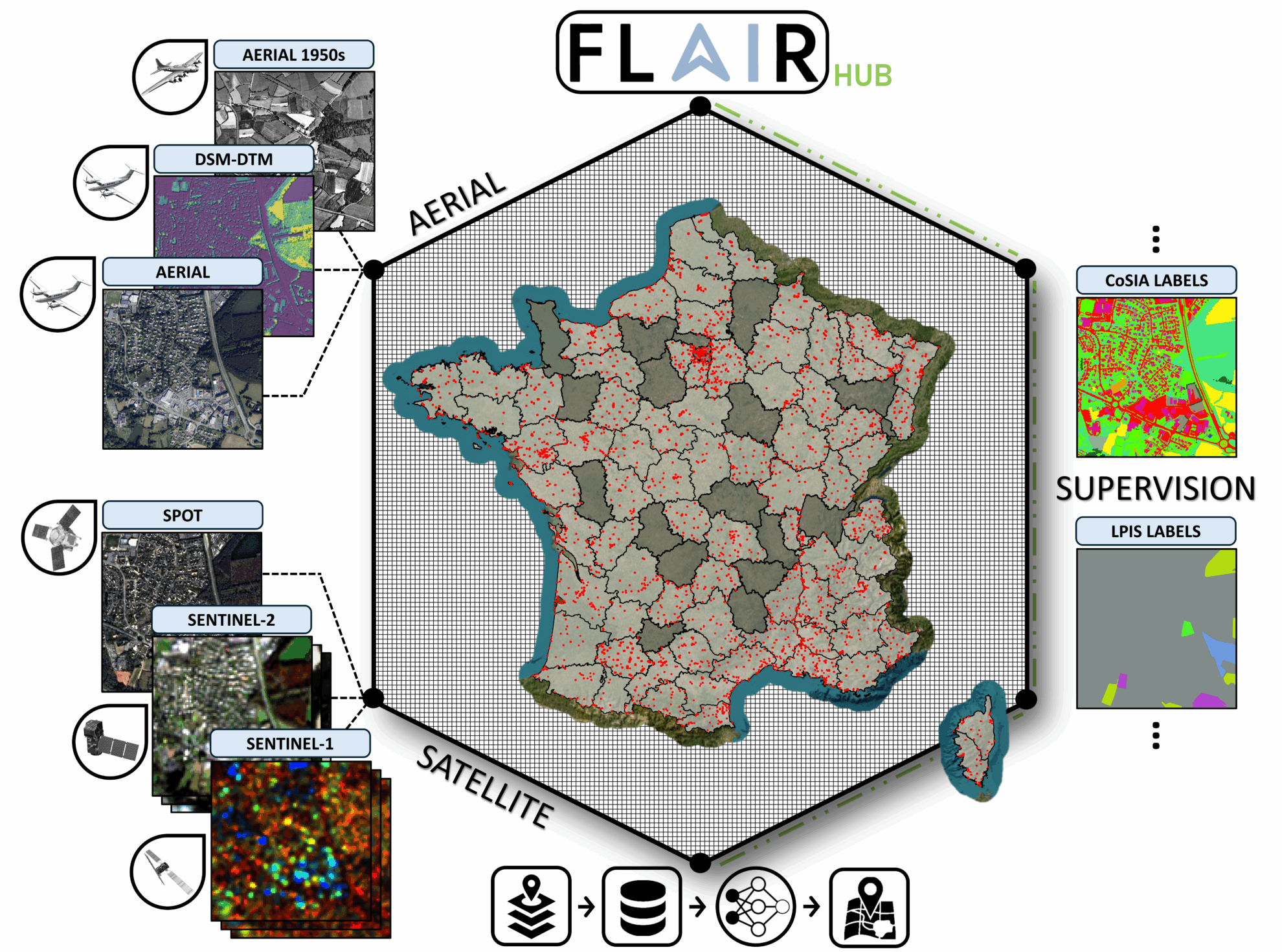
2. FLAIR HUB Multisensor-Datensatz für französisches Land
FLAIR-HUB deckt mehr als 2.500 km2 der vielfältigen Ökoklimata und Landschaften Frankreichs ab, umfasst 19 Bodenbedeckungsklassen und 23 Anbaukategorien und enthält 63 Milliarden manuell annotierte Pixel, wobei ergänzende Datenquellen integriert werden.
Direkte Verwendung:https://go.hyper.ai/4VvCI
3. MathFusionQA-Datensatz zum mathematischen Denken
MathFusionQA konzentriert sich auf mehrstufiges Denken und Lösen mathematischer Probleme. Der Datensatz enthält 59.000 hochwertige Beispiele für mathematische Frage- und Antwortfragen und deckt eine Vielzahl von Fragetypen ab, wie z. B. Rechenoperationen, algebraische Gleichungen, geometrische Anwendungen, logisches Denken usw. Die Frageszenarien sind vielfältig und decken Alltagsanwendungen, akademische Ausbildung usw. ab. Ziel ist es, die mathematische Problemlösungsfähigkeit des Large Language Model (LLM) zu verbessern.
Direkte Verwendung:https://go.hyper.ai/uGR9C
4. Institutional Books 1.0 Buchdatensatz
Institutional Books umfasst 983.004 gemeinfreie Bücher in 254 Sprachen, hauptsächlich aus dem 19. und 20. Jahrhundert. Der Datensatz umfasst 242 Milliarden Token, 386 Millionen Textseiten und ist sowohl im Roh- als auch im nachbearbeiteten OCR-Exportformat verfügbar.
Direkte Verwendung:https://go.hyper.ai/ZsSI7
5. ReasonMed-Datensatz für medizinisches Denken
ReasonMed ist der größte Open-Source-Datensatz für medizinisches Denken. Er wurde entwickelt, um Modelle für Aufgaben wie die Beantwortung medizinischer Fragen und die Textgenerierung zu trainieren und zu evaluieren. Der Datensatz enthält 370.000 hochwertige Frage-Antwort-Beispiele aus verschiedenen Bereichen wie Klinik, Anatomie und Genetik.
Direkte Verwendung:https://go.hyper.ai/DwGmH
6. Miriad-5.8M-Datensatz zur Beantwortung medizinischer Fragen
Der Datensatz enthält 5,82 Millionen medizinische Frage-Antwort-Paare und deckt alle Aspekte von der Grundlagenforschung bis zur klinischen Praxis ab. MIRIAD bietet strukturierte, hochwertige Frage-Antwort-Paare zur Unterstützung verschiedener nachgelagerter Aufgaben wie RAG, medizinischer Datenabfrage, Halluzinationserkennung und Anweisungsanpassung.
Direkte Verwendung:https://go.hyper.ai/Xw8Ph
7. Common Corpus Großer offener Textdatensatz
Dieser Datensatz ist derzeit der größte Textdatensatz mit offener Lizenz und enthält 2 Billionen Token. Er deckt Inhalte aus mehreren Bereichen ab, beispielsweise Bücher, wissenschaftliche Literatur, Codes, juristische Dokumente usw. Die Hauptsprachen sind Englisch und Französisch. Darüber hinaus umfasst er 8 Sprachen mit über 10 Milliarden Token (Deutsch/Spanisch/Italienisch usw.) und 33 Sprachen mit über 1 Milliarde Token.
Direkte Verwendung:https://go.hyper.ai/PnbfK
8. HLE-Benchmark-Datensatz zum menschlichen Fragendenken
HLE hat sich zum Ziel gesetzt, das ultimative geschlossene Bewertungssystem zu entwickeln, das die Grenzen des menschlichen Wissens abdeckt. Der Datensatz enthält 2.500 Fragen aus Dutzenden von Disziplinen wie Mathematik, Geisteswissenschaften und Naturwissenschaften, darunter Multiple-Choice-Fragen und Fragen mit Kurzantworten, die für die automatische Bewertung geeignet sind.
Direkte Verwendung:https://go.hyper.ai/Lq7mE
9. MedCaseReasoning-Datensatz zur medizinischen Fallbegründung
MedCaseReasoning umfasst 13.000 Fälle aus verschiedenen Fachbereichen wie Innere Medizin, Neurologie, Infektionskrankheiten und Kardiologie. Dieser Datensatz integriert den gesamten Diagnose- und Behandlungsprozess klinischer Fälle verschiedener Fachrichtungen und deckt Kernaufgaben wie Krankheitsdiagnose, Differenzialanalyse und Behandlungsentscheidungen ab. Ziel ist es, standardisierte Ressourcen für die Bewertung der Argumentationsfähigkeit medizinischer Großsprachenmodelle bereitzustellen.
Direkte Verwendung:https://go.hyper.ai/4vqwo
10. FineHARD-Datensatz zur Bild-Text-Ausrichtung
FineHARD ist ein Open-Source-Datensatz zur hochwertigen Bild-Text-Ausrichtung. Der Datensatz zeichnet sich durch Skalierung und Verfeinerung aus und enthält 12 Millionen Bilder sowie die dazugehörigen Lang- und Kurzbeschreibungstexte und deckt 40 Millionen Begrenzungsrahmen ab.
Direkte Verwendung:https://go.hyper.ai/L2TOZ
Ausgewählte öffentliche Tutorials
Diese Woche haben wir 4 Kategorien hochwertiger öffentlicher Tutorials zusammengefasst:
*Tutorials zur Bereitstellung großer Modelle: 5
*Tutorials zur multimodalen Verarbeitung: 4
*Tutorials zur 3D-Rekonstruktion: 3
*OCR-Erkennungs-Tutorial: 2
Große ModellbereitstellungLernprogramm
1. vLLM+Open WebUI-Bereitstellung KernelLLM-8B
KernelLLM zielt darauf ab, PyTorch-Module automatisch in effizienten Triton-Kernelcode zu übersetzen und so die Programmierung leistungsstarker GPUs zu vereinfachen und zu beschleunigen. Das Modell basiert auf der Llama 3.1 Instruct-Architektur, verfügt über 8 Milliarden Parameter und konzentriert sich auf die Generierung effizienter Triton-Kernelimplementierungen.
Online ausführen:https://go.hyper.ai/DfoWo
2. vLLM+Open WebUI-Bereitstellung MiniCPM4-8B
MiniCPM 4.0 erreicht leistungsstarkes Reasoning bei geringen Rechenkosten durch Technologien wie Sparse-Architektur, Quantisierungskompression und ein effizientes Reasoning-Framework. Es eignet sich besonders für die Verarbeitung langer Texte, datenschutzrelevante Szenarien und den Einsatz von Edge-Computing-Geräten. Bei der Verarbeitung langer Sequenzen zeigt das Modell eine deutlich höhere Verarbeitungsgeschwindigkeit als Qwen3-8B.
Online ausführen:https://go.hyper.ai/kcANp
3. vLLM+Open WebUI-Bereitstellung FairyR1-14B-Preview
FairyR1-14B-Preview konzentriert sich auf Mathematik- und Programmieraufgaben. Das Modell basiert auf der DeepSeek-R1-Distill-Qwen-32B-Basis und wird durch die Kombination von Feinabstimmungs- und Modellzusammenführungstechniken erstellt.
Online ausführen:https://go.hyper.ai/8jwGm
4. Tutorial zur Modellvergleichsbewertung der Qwen3-Embedding-Serie
Die Qwen3-Embedding-Familie stellt einen bedeutenden Fortschritt bei einer Vielzahl von Text-Embedding- und Ranking-Aufgaben dar, darunter Textabruf, Codeabruf, Textklassifizierung, Textclustering und Bitext-Mining.
Durch dieses Tutorial verstehen Sie systematisch die Kernkonzepte eingebetteter Modelle und Neuordnungsmodelle und lernen, wie Sie diese in praktischen Szenarien auswählen und anwenden.
Online ausführen:https://go.hyper.ai/YtMdH
5. vLLM+Open WebUI-Bereitstellung Devstral-Small-2505
Devstral zeichnet sich durch die Verwendung von Tools zur Code-Analyse, zur Bearbeitung mehrerer Dateien und zur Steuerung von Software-Engineering-Agenten aus. Das Modell schnitt im SWE-Benchmark gut ab und wurde zum führenden Open-Source-Modell im Benchmark.
Online ausführen:https://go.hyper.ai/mnGzy
Tutorial zur multimodalen Verarbeitung
1. Bereitstellung von VideoLLaMA3-7B mit einem Klick
VideoLLaMA3 ist ein multimodales Open-Source-Basismodell, das sich auf Bild- und Videoverständnisaufgaben konzentriert. Es verbessert die Genauigkeit und Effizienz des Videoverständnisses durch visionszentriertes Architekturdesign und hochwertige Datentechnik erheblich.
Dieses Tutorial verwendet eine einzelne RTX 4090-Rechenressource und stellt das Modell VideoLLaMA3-7B-Image bereit, wobei zwei Beispiele für Videoverständnis und Bildverständnis bereitgestellt werden.
Online ausführen:https://go.hyper.ai/t2z4d
2. Step1X-Edit: Bildbearbeitungstool
Step1X-Edit bietet drei Hauptfunktionen: präzise semantische Analyse, Aufrechterhaltung der Identitätskonsistenz und hochpräzise Steuerung auf Bereichsebene. Es unterstützt elf Arten hochfrequenter Bildbearbeitungsaufgaben, wie z. B. Textersetzung, Stilübertragung, Materialtransformation und Zeichenretusche.
Online ausführen:https://go.hyper.ai/MdDTI

3. Chain-of-Zoom: Demo zur Bilddetailvergrößerung mit Superauflösung
Chain-of-Zoom ist ein Chained-Zoom-Framework (COZ), das das Problem löst, dass moderne Einzelbild-Superauflösungsmodelle (SISR) versagen, wenn weit über diesen Bereich hinaus gezoomt werden soll. Das im COZ-Framework gekapselte Standard-4x-Diffusions-SR-Modell erreicht einen über 256-fachen Zoom bei gleichzeitig hoher Wahrnehmungsqualität und Wiedergabetreue.
Online ausführen:https://go.hyper.ai/7Lixx

4. Sa2VA: Auf dem Weg zum dichten perzeptuellen Verständnis von Bildern und Videos
Sa2VA ist das erste einheitliche Modell für dichtes perzeptuelles Verständnis von Bildern und Videos. Im Gegensatz zu bestehenden multimodalen Großsprachenmodellen, die oft auf bestimmte Modalitäten und Aufgaben beschränkt sind, unterstützt Sa2VA ein breites Spektrum an Bild- und Videoaufgaben, einschließlich Referenzsegmentierung und Konversation, mit minimaler Einzelpunkt-Feinabstimmung.
Online ausführen:https://go.hyper.ai/tj2bX
Tutorial zur 3D-Rekonstruktion
1. Distill-Any-Depth: Monokularer Tiefenschätzer
Das Projekt integriert die Vorteile mehrerer Open-Source-Modelle durch den Destillationsalgorithmus und erreicht so eine hochpräzise Tiefenschätzung mit nur einer kleinen Menge nicht gekennzeichneter Daten und aktualisiert die aktuelle SOTA-Leistung (State-of-the-Art).
Online ausführen:https://go.hyper.ai/DNSf5

2. VGGT: Ein allgemeines 3D-Vision-Modell
VGGT ist ein Feedforward-Neuralnetzwerk, das alle wichtigen 3D-Eigenschaften einer Szene, einschließlich extrinsischer und intrinsischer Kameraparameter, Punktkarten, Tiefenkarten und 3D-Punkttrajektorien, aus einer, wenigen oder Hunderten von Ansichten in Sekundenschnelle direkt ableitet. Es ist zudem einfach und effizient und ermöglicht die Rekonstruktion in weniger als einer Sekunde. Damit übertrifft es sogar alternative Methoden, die eine Nachbearbeitung mit Techniken zur visuellen Geometrieoptimierung erfordern.
Online ausführen:https://go.hyper.ai/e8xzG
3. UniDepthV2: Universelle monokulare metrische Tiefenschätzung
UniDepthV2 kann metrische 3D-Szenen domänenübergreifend aus nur einem einzigen Bild rekonstruieren. Im Gegensatz zum bestehenden MMDE-Paradigma prognostiziert UniDepthV2 metrische 3D-Punkte direkt aus dem Eingabebild zum Zeitpunkt der Inferenz ohne zusätzliche Informationen und strebt damit eine allgemeine und flexible MMDE-Lösung an.
Online ausführen:https://go.hyper.ai/JdgZC
OCR-Erkennungs-Tutorial
1. MonkeyOCR: Dokumentenanalyse basierend auf dem Struktur-Erkennungs-Relations-Dreifachparadigma
MonkeyOCR unterstützt die effiziente Konvertierung unstrukturierter Dokumentinhalte in strukturierte Informationen. Das Modell unterstützt eine Vielzahl von Dokumenttypen, darunter wissenschaftliche Arbeiten, Lehrbücher und Zeitungen, ist auf mehrere Sprachen anwendbar und bietet umfassende Unterstützung für die Digitalisierung und automatisierte Verarbeitung von Dokumenten.
Online ausführen:https://go.hyper.ai/s9GE2
2. Nanonets-OCR-s: Tool zur Extraktion von Dokumentinformationen und zum Benchmarking
Nanonets-OCR-s können verschiedene Elemente in Dokumenten erkennen, wie mathematische Formeln, Bilder, Signaturen, Wasserzeichen, Kontrollkästchen und Tabellen, und diese in ein strukturiertes Markdown-Format organisieren. Dadurch eignet es sich hervorragend für die Verarbeitung komplexer Dokumente wie akademischer Arbeiten, juristischer Dokumente oder Geschäftsberichte.
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource. Das Tutorial enthält zwei Funktionen: das Extrahieren von Informationen und Bildern aus Dokumenten und das Konvertieren von PDF in Markdown.
Online ausführen:https://go.hyper.ai/1uPym
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Freunde können Neural Star (WeChat-ID: Hyperai01) hinzufügen und [SD-Tutorial] kommentieren, um der Gruppe beizutreten, verschiedene technische Probleme zu diskutieren und Anwendungsergebnisse auszutauschen.
Die Zeitungsempfehlung dieser Woche
1.FocalAD: Lokale Bewegungsplanung für durchgängig autonomes Fahren
Dieses Dokument stellt FocalAD vor, ein neuartiges End-to-End-Framework für autonomes Fahren, das sich auf kritische lokale Nachbarn konzentriert und die Planung durch eine verbesserte lokale Bewegungsdarstellung optimiert. FocalAD enthält zwei Kernmodule: Autonomous-Local-Agent Interactor (ELAI) und Focal-Local-Agent Loss (FLA Loss).
Link zum Artikel:https://go.hyper.ai/vjBZy
2. Biomni: Ein universeller biomedizinischer Wirkstoff
Wir präsentieren Biomni: einen universellen biomedizinischen KI-Assistenten, der autonom eine Vielzahl von Forschungsaufgaben in verschiedenen biomedizinischen Teilbereichen durchführt. Um den biomedizinischen Aktionsraum systematisch abzubilden, nutzt Biomni Action Discovery Agents, um wichtige Tools, Datenbanken und Protokolle aus Zehntausenden von Arbeiten aus 25 biomedizinischen Bereichen zu extrahieren und so die erste einheitliche Agentenumgebung zu schaffen.
Link zum Artikel:https://go.hyper.ai/zTFzy
3.SeerAttention-R: Sparse Attention Adaptation für langes Denken
Dieses Dokument stellt SeerAttention-R vor, ein Framework für spärliche Aufmerksamkeit, das für die lange Dekodierung von Inferenzmodellen entwickelt wurde. Das Framework erweitert SeerAttention und behält das Design des Lernens von Aufmerksamkeitssparsität durch einen selbstdestillierenden Gating-Mechanismus bei, während das Abfragepooling entfernt wird, um an die autoregressive Dekodierung anzupassen. Dank des leichtgewichtigen Insertion-Gating-Mechanismus ist SeerAttention-R flexibel und lässt sich problemlos in bestehende vortrainierte Modelle integrieren, ohne die ursprünglichen Parameter zu ändern.
Link zum Artikel:https://go.hyper.ai/8XHpf
4.Textbasierte Bildwiederherstellung mit Diffusionsmodellen
In diesem Artikel schlagen wir das Multitasking-Diffusionsframework TeReDiff vor, das die internen Funktionen des Diffusionsmodells in ein Texterkennungsmodul integriert, sodass beide Komponenten vom gemeinsamen Training profitieren. Dadurch können umfangreiche Textdarstellungen extrahiert werden, die im nachfolgenden Denoising-Schritt als Hinweise dienen können.
Link zum Artikel:https://go.hyper.ai/3YDSf
5.Einheitliches differenzierbares Lernen der elektrischen Reaktion
Dieses Dokument implementiert ein äquivariantes maschinelles Lernmodell, bei dem die Reaktionseigenschaften aus der exakten differentiellen Beziehung zwischen der verallgemeinerten Potentialfunktion und dem angelegten externen Feld abgeleitet werden. Die Methode konzentriert sich auf die Reaktion auf das elektrische Feld und prognostiziert die elektrische Enthalpie, Kraft, Polarisation, Born'sche Ladung und Polarisierbarkeit in einem einheitlichen Modell, das einen vollständigen Satz präziser physikalischer Einschränkungen, Symmetrien und Erhaltungssätze durchsetzt.
Link zum Artikel:https://go.hyper.ai/AO8dM
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Ein gemeinsames Forschungsteam der Harvard University und Bosch schlug eine innovative Lösung vor und entwickelte ein einheitliches differenzierbares Lernmodell für elektrische Reaktionen. Dieses Modell kann die verallgemeinerte potentielle Energie und ihre Reaktionsfunktion auf externe Reize gleichzeitig in einem einzigen maschinellen Lernmodell erlernen. Dadurch werden die inhärenten Mängel herkömmlicher unabhängiger Modelle überwunden und ein neuer Weg für die hochpräzise Forschung zu den dielektrischen und ferroelektrischen Eigenschaften von Kristallen, ungeordneten und flüssigen Materialien eröffnet.
Den vollständigen Bericht ansehen:https://go.hyper.ai/d3cAc
HyperAI veranstaltet am 5. Juli in Zhongguancun, Peking, den 7. Meet AI Compiler Technology Salon. Zu dieser Veranstaltung waren vier erfahrene Experten von AMD, Muxi Integrated Circuit, ByteDance und der Peking-Universität eingeladen, um die neuesten Verfahren von KI-Compilern aus mehreren Perspektiven zu erkunden, von der Low-Level-Kompilierung bis hin zu Anwendungen auf höherer Ebene.
Den vollständigen Bericht ansehen:https://go.hyper.ai/elNCA
Die Shandong University of Technology hat gemeinsam mit Forschungsteams der Beijing Forestry University, der Guangdong Academy of Agricultural Sciences, der University of São Paulo in Brasilien, der Rosalind Franklin University of Medical Sciences in Großbritannien und der Umeå University in Schweden das PlantLncBoost-Modell entwickelt, das eine systematische Lösung für das Generalisierungsproblem der Identifizierung pflanzlicher lncRNA bietet.
Den vollständigen Bericht ansehen:https://go.hyper.ai/M88RZ
Die Abteilung für Materialwissenschaft und Werkstofftechnik am MIT hat in Zusammenarbeit mit einem Team aus mehreren Abteilungen einen neuen datengesteuerten Ansatz entwickelt, der auf einem großen Sprachmodell (LLM) und einer Architektur mit mehreren neuronalen Netzwerken basiert, um eine groß angelegte Vorhersage und Überprüfung der Reaktivität von Zementersatzmaterialien zu erreichen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/rtvf4
Um mehr Benutzer über die neuesten Entwicklungen im Bereich der künstlichen Intelligenz in der Wissenschaft zu informieren, wurde auf der offiziellen Website von HyperAI (hyper.ai) jetzt der Bereich „Neueste Artikel“ eingerichtet, in dem täglich topaktuelle KI-Forschungsartikel aktualisiert werden, die mehrere vertikale Felder abdecken, wie etwa maschinelles Lernen, Computersprachen, Computersehen und Mustererkennung sowie Mensch-Computer-Interaktion.
Den vollständigen Bericht ansehen: https://go.hyper.ai/ttAl7
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Juli-Frist für den Gipfel
2. Juli 7:59:59 VLDB 2026
11. Juli 7:59:59 POPL 2026
15. Juli 7:59:59 SODA 2026
18. Juli 7:59:59 SIGMOD 2026
19. Juli 7:59:59 ICSE 2026
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








