Command Palette
Search for a command to run...
Diffusionsmodell × Musikgenerierung, DiffRhythm Erledigt Die Songerstellung in Minuten! Der MiniMind-Datensatz Ist Open Source, Um Große Sprachmodelle Mit Geringen Implementierungshürden Zu Ermöglichen

Im Bereich der Musikgenerierung wurden in den letzten Jahren erhebliche Fortschritte erzielt, bestehende Modelle weisen jedoch in der praktischen Anwendung noch immer viele Einschränkungen auf. Die meisten Modelle können Gesangs- oder Begleitspuren nur unabhängig voneinander erzeugen, was zu einem unzusammenhängenden Musikerlebnis führt. Um diese Herausforderungen zu bewältigen, haben das Audio Speech and Language Processing Laboratory der Northwestern Polytechnical University und die Chinese University of Hong Kong gemeinsam ein Modell namens DiffRhythm entwickelt.
Als erstes Open Source-Modell zur vollständigen Songgenerierung basierend auf DiffusionstechnologieDiffRhythm sorgt nicht nur für ein hohes Maß an Musikgenerierung und Verständlichkeit, sondern gewährleistet auch seine Skalierbarkeit durch ein prägnantes und effektives Modell, eine Architektur und eine Datenverarbeitungspipeline. Im Hinblick auf die Benutzererfahrung gewährleistet die nicht-autoregressive Struktur eine schnelle Generierungsgeschwindigkeit.Erstellen Sie in nur 1 Minute komplette Musik.
Derzeit hat HyperAI das Tutorial „DiffRhythm: Erstellen Sie in 1 Minute eine vollständige Musikdemo“ veröffentlicht. Kommen Sie und probieren Sie es aus~
Online-Nutzung:https://go.hyper.ai/sHdPu
Vom 17. bis 21. März gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Ausgewählte hochwertige Tutorials: 2
* Community-Artikelauswahl: 6 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im März: 1
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
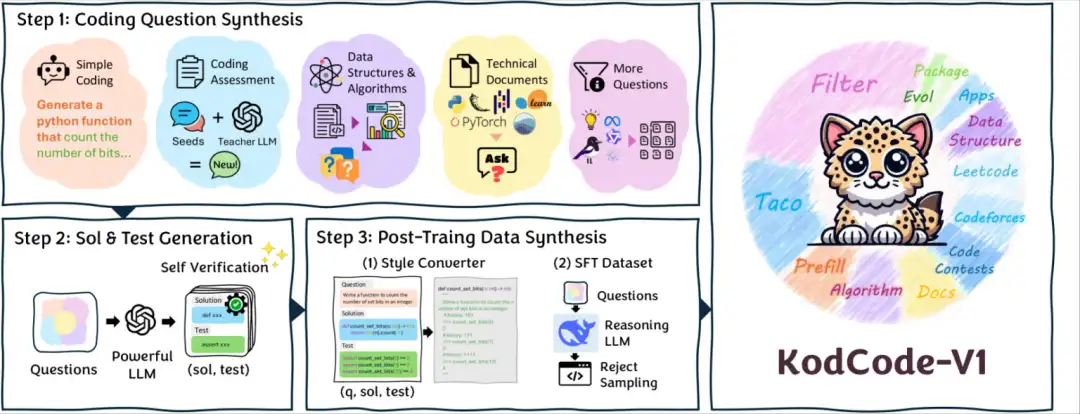
1. KodCode-V1-Codierungssynthese-Datensatz
Dieser Datensatz ist derzeit der größte vollständig synthetische Open-Source-Datensatz und bietet überprüfbare Lösungen und Tests für Codierungsaufgaben. Es enthält 12 verschiedene Teilmengen, die verschiedene Bereiche (von Algorithmen bis hin zu softwarepaketspezifischem Wissen) und Schwierigkeitsgrade (von grundlegenden Codierungsübungen bis hin zu Interviews und wettbewerbsorientierten Programmierherausforderungen) abdecken und ist für überwachtes Feintuning (SFT) und RL-Tuning konzipiert.
Direkte Verwendung:https://go.hyper.ai/CfZCm
2. Straßengefahren Datensatz zu Straßengefahren
Dieser Datensatz enthält 2,7.000 Bilder und wird hauptsächlich zum Erkennen von Schlaglöchern, Rissen und offenen Gullydeckeln auf der Straße verwendet.
Direkte Verwendung:https://go.hyper.ai/XPJNQ

3. DexGraspVLA Roboter-Greifdatensatz
Dies ist ein kleiner Datensatz mit 51 Beispielen menschlicher Demonstrationsdaten, der zum Verständnis der Daten und des Formats sowie zum Ausführen des Codes zum Erleben des Trainingsprozesses nützlich ist. Der Forschungshintergrund ergibt sich aus der Notwendigkeit einer hohen Erfolgsrate beim geschickten Greifen in unübersichtlichen Szenen, insbesondere dem Erreichen einer Erfolgsrate von über 90% bei beispiellosen Kombinationen von Objekten, Beleuchtung und Hintergründen.
Direkte Verwendung:https://go.hyper.ai/pJ44Y

4. IllusionAnimals Visual Illusion VQA-Datensatz
Der IllusionAnimals-Datensatz ist ein FiftyOne-Datensatz mit 2.000 Beispielen. Der Datensatz enthält 10 Tierkategorien und eine Kategorie ohne Illusion mit einer Bildauflösung von 512 × 512 Pixeln. Es wird verwendet, um die Fähigkeit multimodaler Modelle zur Identifizierung und Erklärung tierbasierter optischer Täuschungen zu bewerten.
Direkte Verwendung:https://go.hyper.ai/Ebl40

5. m-WildVision Mehrsprachiger, multimodaler Datensatz zur Evaluierung großer Modelle
Der Datensatz enthält 500 anspruchsvolle Benutzerabfragebeispiele in 23 Sprachen, die alle von der WildVision-Arena-Plattform stammen. Die Struktur des Datensatzes umfasst Frage-ID, Sprachtyp, Anweisungstext und Bilddaten, um die Generalisierung und Robustheit des Modells in verschiedenen Sprachen zu bewerten.
Direkte Verwendung:https://go.hyper.ai/Im6mN

6. MiniMind-Training und Feinabstimmung des Datensatzes für große Modelle
MiniMind ist ein Open-Source-Projekt für leichtgewichtige große Sprachmodelle, das darauf abzielt, die Hemmschwelle für die Verwendung großer Sprachmodelle (LLM) zu senken und einzelnen Benutzern schnelles Trainieren und Schlussfolgerungen auf gewöhnlichen Geräten zu ermöglichen.
Direkte Verwendung:https://go.hyper.ai/gCz2y
7. Seaclear-Datensatz zur Erkennung und Segmentierung von Meeresmüll
Der Datensatz enthält 8.610 Bilder von Meeresmüll, die für Aufgaben zur Objekterkennung und Instanzsegmentierung annotiert sind und 40 Objektkategorien abdecken, darunter nicht nur Müll, sondern auch beobachtete Tiere, Pflanzen und Roboterteile. Die Anmerkungen werden als Dateien im COCO-Format (.json) bereitgestellt und die Bilder sind in Ordnern angeordnet, wobei jeder Ordner einem eindeutigen Standort-Kamera-Paar zugeordnet ist. Alle Bilder haben eine Auflösung von 1920 x 1080.
Direkte Verwendung:https://go.hyper.ai/JFofd
8. Text- und Audio-Captchas Text- und Audio-Captchas-Datensatz
Der Datensatz enthält 100.000 CAPTCHA-Beispiele, die jeweils mit der entsprechenden alphanumerischen Zeichenfolge gekennzeichnet sind. Dadurch eignet er sich ideal zum Trainieren von OCR-Modellen, Spracherkennung und KI-basierten CAPTCHA-Lösern.
Direkte Verwendung:https://go.hyper.ai/vFmTJ
9. Datensatz zur Müllklassifizierung
Der Datensatz enthält Bilder und Anmerkungen im YOLO-Format zur Klassifizierung und Erkennung verschiedener Abfallarten: Kunststoff, Papier und Pappe, Glas/Metall, organischer Abfall, Textilien und Elektronik (Elektroschrott).
Direkte Verwendung:https://go.hyper.ai/NwEF7
10. Bild der Marsoberfläche (Curiosity Rover) Datensatz mit Bildern der Marsoberfläche
Der Datensatz besteht aus 6.691 Bildern, die von drei Instrumenten des Mars Science Laboratory (MSL) gesammelt wurden: Right-Eye Mastcam, Left-Eye Mastcam und MAHLI und deckt 24 Kategorien ab. Bei diesen Bildern handelt es sich um „Durchsuchungsversionen“ der einzelnen Rohdatenprodukte und sie haben nicht die volle Auflösung, sondern etwa 256 × 256 Pixel pro Bild.
Direkte Verwendung:https://go.hyper.ai/B1T0l
Ausgewählte öffentliche Tutorials
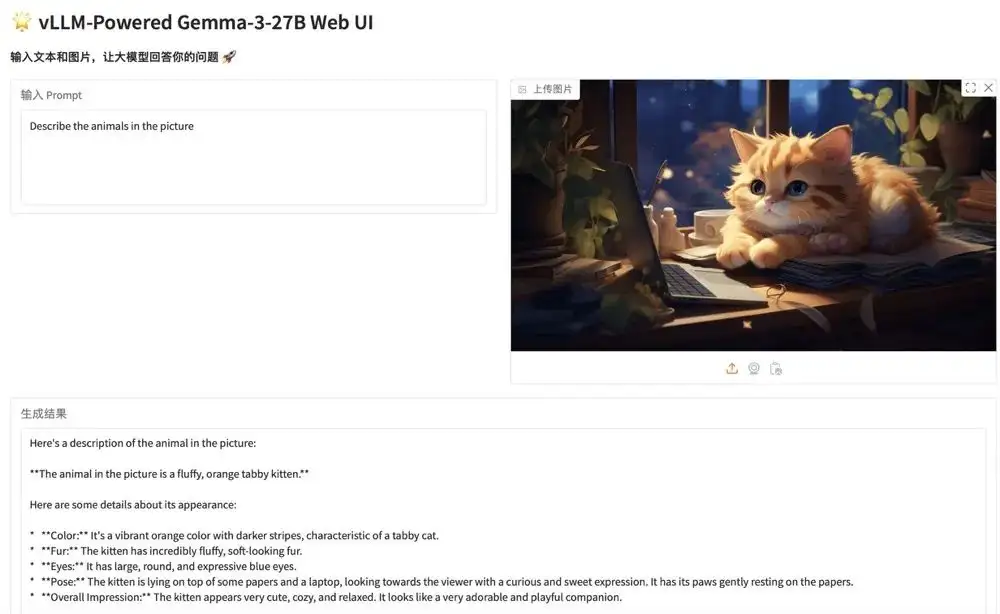
1. Stellen Sie Gemma-3-27B-IT mit vLLM bereit
Die Gemma-Serie ist eine Reihe großer, von Google als Open Source bereitgestellter Modelle, die auf derselben Forschung und Technologie basieren wie das Gemini-Modell. Gemma 3 ist ein großes multimodales Modell, das Text- und Bildeingaben verarbeiten und Textausgaben generieren kann. Das Modell eignet sich für eine Vielzahl von Aufgaben zur Textgenerierung und zum Bildverständnis, einschließlich der Beantwortung von Fragen, Zusammenfassungen und Schlussfolgerungen. Aufgrund ihrer relativ geringen Größe können sie in Umgebungen mit begrenzten Ressourcen eingesetzt werden, beispielsweise auf Laptops, Desktops oder in Cloud-Infrastrukturen.
Die relevanten Modelle und Abhängigkeiten dieses Projekts wurden bereitgestellt. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/JxVbA
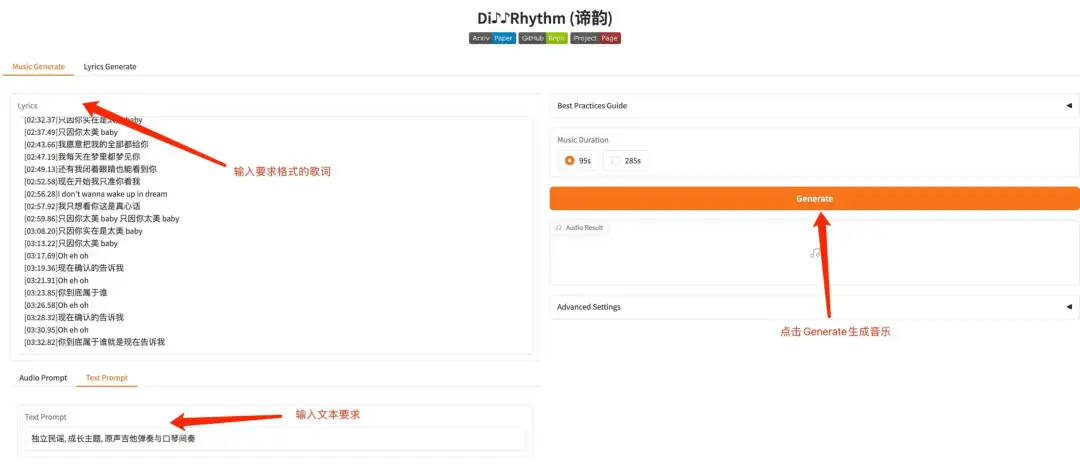
2. DiffRhythm: Erstellen Sie in 1 Minute eine komplette Musikdemo
DiffRhythm ist das erste diffusionsbasierte Songgenerierungsmodell, mit dem ganze Songs komponiert werden können. Es kann in kurzer Zeit ein komplettes Lied mit einer Länge von bis zu 4 Minuten und 45 Sekunden generieren, einschließlich Gesang und Begleitung. Benutzer müssen lediglich Liedtexte und Stilhinweise angeben, und DiffRhythm kann automatisch Melodien und Begleitungen generieren, die zu den Liedtexten passen und die Eingabe in mehreren Sprachen unterstützen.
Die relevanten Modelle und Abhängigkeiten dieses Projekts wurden bereitgestellt. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/sHdPu
Community-Artikel
Das Team des Akademikers Wu Lixin hat die physikalische Ozeanographie tief mit der KI integriert, die Theorie der Ozeandynamik zur Steuerung der neuronalen Netzwerkarchitektur verwendet und ein großes, globales, hochauflösendes, intelligentes Vorhersagemodell für die Ozeanumwelt namens „Wenhai“ erstellt, um den Zustand des realen Ozeans besser widerzuspiegeln und erheblich Rechenzeit und Energieverbrauch zu sparen. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/s7YMj
Ein Forschungsteam der Universität Cambridge hat ein virtuelles Gewebemodell namens Celcomen vorgeschlagen, das nicht nur die Auswirkungen der Umwelt auf einzelne Zellen abschätzen, sondern auch auf die Auswirkungen einzelner Zellen auf ihre Umgebung und das Gesamtgewebe schließen lässt. Die Forscher überprüften die Identifizierbarkeit des Celcomen-Modells beim Lernen kausaler Strukturen und beim Aufdecken kausaler Beziehungen durch selbstkonsistente synthetische Daten und Experimente mit realen Daten sowie seine Fähigkeit, Gen-Gen-Interaktionen in realen und selbstsimulierten räumlichen Transkriptomikdaten aufzudecken und wiederherzustellen. Für ICLR 2025 wurden entsprechende Ergebnisse ausgewählt. Dieser Artikel enthält eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/ylKOr
Zur siebten Live-Übertragung von Meet AI4S lud HyperAI Associate Professor Huang Hong von der Huazhong University of Science and Technology, Dr. Zhou Dongzhan vom Shanghai AI Lab und Dr. Zhou Bingxin vom Shanghai Jiao Tong University Research Institute ein, um mit drei Wissenschaftlern die neuesten Entwicklungen der KI in den Sozialwissenschaften, der physikalischen Chemie, den Biowissenschaften und anderen Bereichen zu diskutieren. Sie teilten außerdem ihre Erkenntnisse zur Auswahl von Forschungsrichtungen und ihre Erfahrungen mit der Einreichung von Beiträgen bei führenden KI-Konferenzen. Dieser Artikel ist eine Zusammenfassung der Aussagen der drei Lehrer.
Den vollständigen Bericht ansehen:https://go.hyper.ai/klU6m
NVIDIA-CEO Jensen Huang hielt auf der GTC 2025-Konferenz, dem jährlichen globalen KI-Event, eine Grundsatzrede, bei der er sich auf die neuesten Entwicklungen im hochmodernen Bereich der KI konzentrierte. Dabei wurde nicht nur Blackwells neue Generation nukleartauglicher KI-Chips präsentiert, sondern auch eine Reihe neuer Errungenschaften vorgestellt, darunter der Physical AI-Datensatz, das GR00T N1-Modell, die Newton-Physik-Engine und das Cosmos-Weltmodell. Dieser Artikel ist eine Zusammenfassung des Redeinhalts und der neuen Erfolge von Huang Renxun.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Q6wdO
NVIDIA hat in Zusammenarbeit mit dem MIT und anderen einen neuen Typ eines groß angelegten Protein-Backbone-Generators namens Proteina entwickelt. Proteina verfügt über die fünffache Anzahl an Parametern des RFdiffusion-Modells und hat seine Trainingsdaten auf 21 Millionen synthetische Proteinstrukturen erweitert. Es hat eine SOTA-Leistung beim De-novo-Design des Protein-Rückgrats erreicht und vielfältige und gestaltbare Proteine mit einer beispiellosen Länge von bis zu 800 Resten erzeugt. Die Ergebnisse wurden für die mündliche Prüfung ICLR 2025 ausgewählt. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/w7jlU
Die Shanghai Jiao Tong University hat sich mit einer Reihe führender Institutionen zusammengeschlossen, um ein maßgebliches Bewertungssystem aufzubauen und systematische Tests von 10 gängigen LLMs im In- und Ausland durchzuführen, darunter ChatGPT und DeepSeek. Dies stellt den ersten Praxisbeweis für eine KI-gestützte Ausbildung von Hausärzten dar und leistet eine wichtige Unterstützung für die KI-gestützte medizinische Grundversorgung. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/DH8hf
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1700 öffentliche Datensätze
* Enthält über 500 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 600 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








