Command Palette
Search for a command to run...
Überwinden Sie Die Schwierigkeiten Der OCR-Handschrifterkennung! Das InkSight-Tutorial Wird Gestartet Und Ermöglicht Eine Hochpräzise Transkription. Der iNatSounds-Datensatz Mit 230.000 Audiodaten Natürlicher Arten Wird Veröffentlicht

Handschriftliche Notizen sind für viele Menschen die Art und Weise, wie sie im Alltag Inspirationen festhalten. Die effiziente Umwandlung handschriftlicher Inhalte in elektronischen Text war jedoch schon immer eine große Herausforderung. Bei der Verarbeitung komplexer Hintergründe oder unregelmäßiger Handschrift weist die herkömmliche OCR-Technologie (optische Zeichenerkennung) häufig eine eingeschränkte Genauigkeit auf.
Um dieses Problem zu lösen, hat Google Research vor Kurzem die InkSight-Technologie eingeführt, die den menschlichen Lesevorgang durch Deep Learning simuliert, handgeschriebenen Text präzise erkennt und seinen Stil perfekt wiederherstellt. Im Gegensatz zu herkömmlicher OCR kann InkSight auch bei schwachem Licht oder komplexen Hintergründen eine hohe Genauigkeit aufrechterhalten, unterstützt die Transkription auf Wortebene und ganzer Seiten und der Effekt ist fast derselbe wie bei der ursprünglichen Handschrift. Diese Technologie hat in Bereichen wie der Dokumentendigitalisierung und dem Schutz des kulturellen Erbes großes Potenzial gezeigt.
Um vielen Handschrift-Enthusiasten die einfache Digitalisierung ihrer Inspiration zu ermöglichen und die hochpräzise Transkription wertvoller Dokumente zu erleichtern,Das InkSight-Tutorial ist jetzt auf der offiziellen Website von hyper.ai verfügbar. Sie können es erleben, indem Sie es mit einem Klick klonen~
Online ausführen:https://go.hyper.ai/gVh8a

Vom 11. bis 15. November gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 6
* Community-Artikelauswahl: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im November: 2
Besuchen Sie die offizielle Website: hyper.ai
Ausgewählte öffentliche Datensätze
1. DrivingDojo-Datensatz für autonomes Fahren
Der Datensatz zum autonomen Fahren von DrivingDojo enthält etwa 18.000 Videoclips, die speziell für die Simulation visueller Interaktionen in der realen Welt entwickelt wurden und umfassende Fahraktionen, Interaktionen mehrerer Agenten und Wissen zum Fahren in einer offenen Welt abdecken. Dieser Datensatz zielt darauf ab, die Entwicklung interaktiver und wissensbasierter Modelle der Fahrwelt voranzutreiben.
Direkte Verwendung:https://go.hyper.ai/Y86yY

2. TuSimple US-Highway-Straßenbilddatensatz
Der TuSimple-Datensatz enthält 6.408 Bilder von US-Autobahnen, darunter 3.626 für das Training, 358 für die Validierung und 2.782 für Tests. Die Bildauflösung beträgt 1280×720 und alle Bilder werden unter unterschiedlichen Wetterbedingungen aufgenommen.
Direkte Verwendung:https://go.hyper.ai/Mo6bt

3. Sportklassifizierung: 100 Sportbilddatensätze
Dieser Datensatz umfasst eine Reihe von bewegten Bildern aus 100 verschiedenen Sportarten und alle Bilder liegen im JPG-Format 224 x 224 x 3 vor. Die Daten werden in Trainingsbilder, Testbilder und Validierungsbilder unterteilt. Darüber hinaus enthält der Datensatz eine CSV-Datei, um Forschern das Laden und Verarbeiten dieser Bilddaten zu erleichtern.
Direkte Verwendung:https://go.hyper.ai/715At

4. Zimmerpflanzenarten 47 Zimmerpflanzenarten Datensatz
Der Datensatz wurde von Bing Images gesammelt und enthält 14.790 Bilder, die in 47 verschiedene Pflanzenartenkategorien eingeteilt sind.
Direkte Verwendung:https://go.hyper.ai/v7wTX

5.BIOSCAN-5M Multimodaler Insektenbiodiversitätsdatensatz
BIOSCAN-5M ist ein umfassender, multimodaler Datensatz zur Insektenbiodiversität, der zum Verständnis und zur Überwachung der globalen Insektenbiodiversität entwickelt wurde. Der Datensatz enthält detaillierte Informationen zu mehr als 5 Millionen Insektenexemplaren und erweitert damit bestehende bildbasierte biologische Datensätze erheblich.
Direkte Verwendung:https://go.hyper.ai/YDeuN

6. iNaturalist Sounds Dataset Datensatz natürlicher Artengeräusche
Der Datensatz ist eine Sammlung von Audiodateien natürlicher Arten, die 230.000 Audiodateien umfasst, die Geräusche von mehr als 5.500 Arten erfassen und von mehr als 27.000 Recordern weltweit beigesteuert wurden.
Direkte Verwendung:https://go.hyper.ai/S0lg6
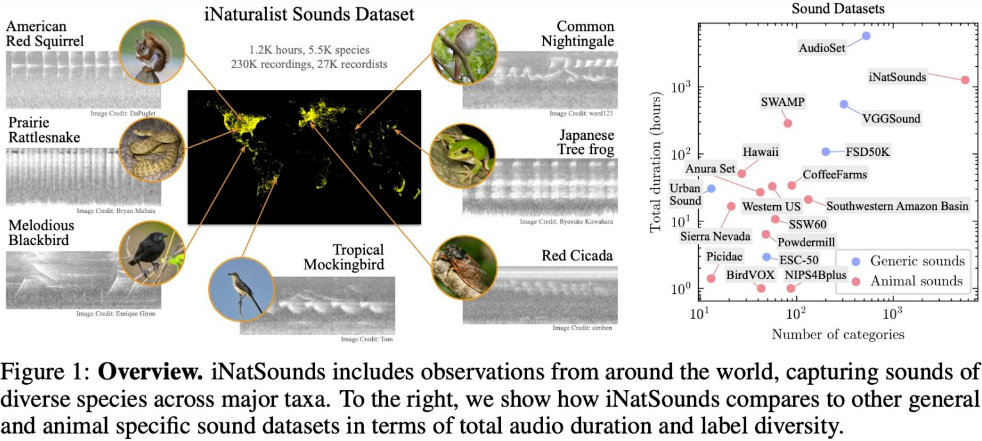
7. OpenSatMap hochauflösender Satellitendatensatz
OpenSatMap ist ein hochauflösender Satellitendatensatz, der für die Erstellung großflächiger Karten entwickelt wurde. Es enthält Bilder nicht nur von vielen Städten in China, sondern auch von mehr als 50 Städten und 18 Ländern auf der ganzen Welt. Diese Bilder haben eine Auflösung von 20 Stufen, die höchste aller vorhandenen Satellitendatensätze.
Direkte Verwendung:https://go.hyper.ai/PtbCB
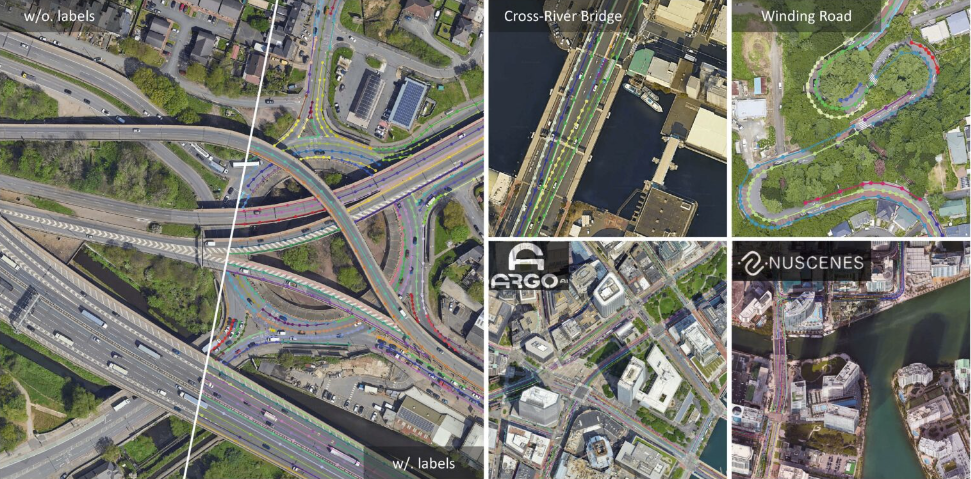
8. Kartenbild Kartenbild-Datensatz
„Cards Image“ ist ein Datensatz mit Spielkartenbildern. Der Datensatz enthält 7.624 Trainingsbilder, 265 Testbilder und 265 Validierungsbilder. Alle Bilder sind im JPG-Format 224 x 224 x 3. Jedes Bild wurde sorgfältig zugeschnitten, um nur eine Spielkarte anzuzeigen, die mehr als 50% Pixel des Bildes einnimmt.
Direkte Verwendung:https://go.hyper.ai/DuOJb
9. PD12M Großer Bild-Text-Paar-Datensatz
PD12M ist der größte gemeinfreie Datensatz mit Bild-Text-Paaren. Er enthält 12,4 Millionen hochwertige gemeinfreie und CCO-lizenzierte Bilder mit synthetischen Bildunterschriften und wird hauptsächlich zum Trainieren von Text-Bild-Modellen verwendet.
Direkte Verwendung:https://go.hyper.ai/xyjrD

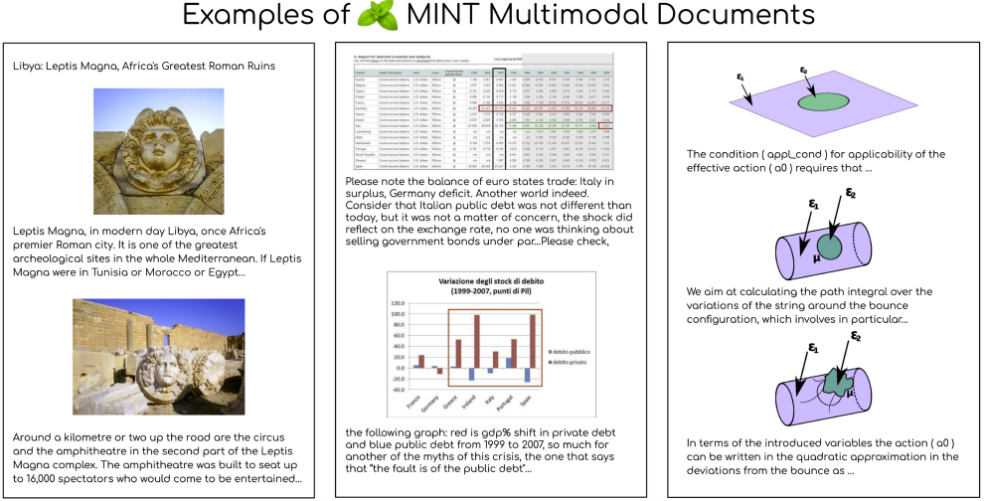
10. MINT-1T Text-Bild Multimodaler Datensatz
Der MINT-1T-Datensatz ist ein multimodaler Datensatz mit einer Billion Text-Tags und 3,4 Milliarden Bildern und ist damit zehnmal so groß wie der bisher größte Open-Source-Datensatz. Der Datensatz umfasst nicht nur HTML-Dokumente, sondern auch PDF-Dokumente und ArXiv-Papiere, wodurch die Abdeckung wissenschaftlicher Dokumente erheblich verbessert wird.
Direkte Verwendung:https://go.hyper.ai/Vf3mq
Ausgewählte öffentliche Tutorials
1. InkSight-Demo zum Digitalisieren handgeschriebenen Textes
InkSight ist eine Technologie zur Erkennung und Digitalisierung handschriftlicher Texte. Die Technologie ahmt den menschlichen Lese- und Lernprozess nach, indem sie handgeschriebenen Text kontinuierlich neu schreibt und daraus lernt und so ein Verständnis für das Aussehen und die Bedeutung des Textes entwickelt. Im Vergleich zur herkömmlichen optischen Zeichenerkennungstechnologie (OCR) weist InkSight eine höhere Erkennungsgenauigkeit bei der Verarbeitung von handgeschriebenem Text vor komplexen Hintergründen, verschwommenem Text oder bei schlechten Lichtverhältnissen auf.
Dieses Projekt kann über die Gradio-Schnittstelle eine interaktive Front-End-Schnittstelle generieren. Die relevanten Modelle und Abhängigkeiten wurden bereitgestellt. Sie können die Handschriftkonvertierung mit einem Klick starten.
Online ausführen:https://go.hyper.ai/gVh8a

2. CharacterGen generiert hochwertige 3D-Charaktere aus einem einzigen Bild
CharacterGen verwendet ein einzelnes Eingabebild und generiert ein einheitliches 3D-Charakternetz mit hoher Qualität und konsistentem Erscheinungsbild, das für die Verwendung in nachgelagerten Rigging- und Animations-Workflows bereit ist.
Dieses Tutorial ist eine Demo von CharacterGen, die mit einem Klick ausgeführt werden kann. Die relevante Umgebung und die Abhängigkeiten wurden installiert. Sie können klonen und mit der Erstellung hochwertiger 3D-Charaktere beginnen.
Online ausführen:https://go.hyper.ai/jtVAF

3. Bereitstellung von Ministerial-8B-Instruct-2410 mit einem Klick
Ministral-8B ist ein vom Mistral-KI-Team speziell für Edge-Geräte und Edge-Computing-Szenarien entwickeltes Sprachmodell. Es kann mehrere Aufgaben ausführen, darunter das Beantworten von Fragen, das Übersetzen von Texten in verschiedene Sprachen, das Erstellen von Dokumentzusammenfassungen und die Unterstützung beim Verfassen von Artikeln und Berichten. Es verwendet einen verschachtelten Sliding-Window-Aufmerksamkeitsmodus, der nicht nur die Inferenzgeschwindigkeit des Modells verbessert, sondern auch den Speicherverbrauch erheblich reduziert, sodass es sich sehr gut für die Ausführung auf Edge-Geräten mit eingeschränkten Ressourcen eignet.
Gehen Sie zur offiziellen Website, um den Container zu klonen und zu starten, kopieren Sie die API-Adresse direkt und Sie können mit dem Modell kommunizieren.
Online ausführen:https://go.hyper.ai/wMQWN
4. VASP-Tutorial: 1-1. DFT-Berechnung eines isolierten Sauerstoffatoms
VASP ist ein Softwarepaket zur Durchführung von Berechnungen elektronischer Strukturen und Simulationen der Quantenmechanik und Molekulardynamik. Es handelt sich um eine der beliebtesten kommerziellen Softwareprogramme für Materialsimulation und computergestützte Materialforschung. Seine hohe Genauigkeit und leistungsstarken Funktionen machen es zu einem wichtigen Werkzeug für Forscher zur Vorhersage und Entwicklung von Materialeigenschaften. Es wird häufig in der Festkörperphysik, den Materialwissenschaften, der Chemie, der Molekulardynamik und anderen Bereichen verwendet.
Dieses Tutorial ist der erste Teil des offiziellen VASP-Tutorials: DFT-Berechnungen isolierter Sauerstoffatome. Klicken Sie auf den Link unten und folgen Sie dem Tutorial, um DFT-Hochleistungsberechnungen von Grund auf zu starten.
Online ausführen:https://go.hyper.ai/pa2NX
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Community-Artikel
Da es bei der Arzneimittelentwicklung kein einheitliches Standardparadigma gibt, ist der Entwicklungsprozess komplex und erfordert eine präzise Datenkennzeichnung, was die Anwendung großer Sprachmodelle im Bereich der Arzneimittelentwicklung einschränkt. Als Reaktion darauf schlugen Forschungsteams von vier großen Universitäten gemeinsam ein großes Sprachmodell Y-Mol vor, das auf multiskaligem biomedizinischem Wissen basiert. Es kann auf verschiedene Textkorpora und Anweisungen abgestimmt werden, wodurch die Leistung und das Potenzial des Modells bei der Arzneimittelentwicklung verbessert werden. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Forschungspapiers.
Den vollständigen Bericht ansehen:https://go.hyper.ai/14X5I
Als Weltklasse-Meister auf dem Gebiet des Proteindesigns hat David Baker viele Deep-Learning-Tools als Open Source zur Verfügung gestellt. Darüber hinaus ist er der „akademische König“ und hat mehr als 700 Forschungsarbeiten im Bereich Proteine veröffentlicht, die insgesamt 177.000 Mal zitiert wurden. David Baker war als Gründer direkt an der Entwicklung von 21 Unternehmen in Bereichen wie Krankheitsbehandlung, Lebensmittelproduktion und Materialwissenschaft beteiligt. Klicken Sie hier, um mehr über David Bakers legendäres Erlebnis zu erfahren.
Den vollständigen Bericht ansehen:https://go.hyper.ai/ItxvG
Auf dem von HyperAI koproduzierten COSCon‘24 AI for Science-Forum hielt Jingtao Ding, ein Postdoktorand vom Center for Urban Science and Computational Research, Abteilung für Elektrotechnik, Tsinghua-Universität, eine Rede mit dem Titel „KI-gesteuerte Modellierung und Mustererkennung komplexer urbaner Systeme“. Er gab eine ausführliche Erläuterung der raumzeitlichen generativen Modellierungsmethode komplexer urbaner Systeme und der neuesten Forschungsfortschritte des Teams. Voller nützlicher Informationen, klicken Sie hier, um es zu lesen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/qaDYE
Am 13. November führten Huang Renxun und Son Masayoshi in Japan ein Offline-Gespräch, in dem sie die früheren Investitionen des Letzteren in Nvidia überprüften und die Entwicklung der KI in Japan diskutierten. Huang Renxun erklärte unverblümt, dass Masayoshi Son „der einzige Unternehmer und Innovator der Welt ist, der in jeder Generation des technologischen Wandels Gewinner ausgewählt und mit Gewinnern zusammengearbeitet hat.“ Dieser Artikel klärt die vergangenen Streitigkeiten zwischen den beiden und die aktuelle Entwicklungsrichtung. Klicken Sie hier, um weitere Einzelheiten zu erfahren.
Den vollständigen Bericht ansehen:https://go.hyper.ai/hLKbG
Beliebte Enzyklopädieartikel
1. UNA-Ausrichtungsrahmen
2. Digitaler Cousin
3. Modellkollaps
4. Gradientenverstärkung
5. Frequenzprinzip
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
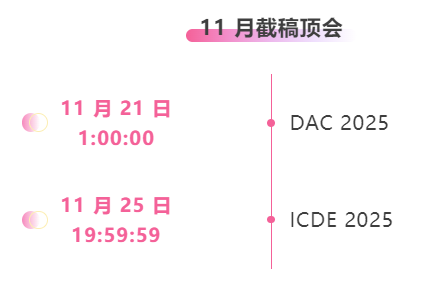
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung inländischer beschleunigter Download-Knoten für über 1300 öffentliche Datensätze
* Enthält über 400 klassische und beliebte Online-Tutorials
* Interpretation von über 100 AI4Science-Papierfällen
* Unterstützt die Suche nach über 500 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:
Abschließend empfehle ich ein „Creator Incentive Program“. Interessierte Freunde können den QR-Code scannen, um teilzunehmen!









