Command Palette
Search for a command to run...
TRELLIS.2: يستخدم تقنية O-Voxel لتوليد هندسة ومواد ثلاثية الأبعاد معقدة بكفاءة؛ مجموعة بيانات التنبؤ بتسرب المرضى: تساعد في تحديد المرضى المعرضين لخطر التسرب.

حالياً، لا يزال إنشاء نماذج ثلاثية الأبعاد قابلة للاستخدام من الصور عملية تستغرق وقتاً طويلاً وتتطلب جهداً كبيراً، حيث تعتمد العمليات التقليدية بشكل كبير على التشغيل اليدوي من قبل مصممي النماذج المحترفين. حتى مع مساعدة الذكاء الاصطناعي،عند التعامل مع الأشكال المعقدة أو المواد الشفافة أو الأسطح المفتوحة، غالباً ما تنتج النماذج نتائج سيئة أو هياكل غير طبيعية، ومن الصعب إنتاج منتجات نهائية بمواد واقعية يمكن استخدامها مباشرة في الألعاب والتجارة الإلكترونية.
في هذا السياق، أصدر فريق مايكروسوفت مشروع TRELLIS.2، وهو مشروع مفتوح المصدر في ديسمبر 2025، لإنشاء أصول ثلاثية الأبعاد عالية الجودة ومهام التكسية من صور مفردة.يوفر المشروع عملية شاملة من الصور المدخلة إلى الأشكال والمواد ثلاثية الأبعاد، ويأتي مع عرض توضيحي تفاعلي على الويب لتجربة سريعة وتصدير الأصول. يركز برنامج TRELLIS.2 على تحسين التفاصيل الهندسية وتناسق النسيج، ويدعم دقة متعددة وتكوينات استدلال متتالية، ويوازن بين السرعة والجودة من خلال معلمات الاستدلال القابلة للتحكم، مما يجعله مناسبًا لسيناريوهات مثل إنتاج المحتوى ثلاثي الأبعاد، والنمذجة السريعة، والاستكشاف الإبداعي.
يعرض موقع HyperAI الإلكتروني الآن "عرضًا توضيحيًا للجيل ثلاثي الأبعاد TRELLIS.2"، لذا تفضلوا بتجربته!
الاستخدام عبر الإنترنت:https://go.hyper.ai/drI7I
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 19 يناير إلى 23 يناير:
* مجموعات البيانات العامة عالية الجودة: 5
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 9
* الأوراق البحثية الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 4 مقالات
* إدخالات الموسوعة الشعبية: 5
أهم المؤتمرات التي تنتهي مواعيدها في يناير: 3
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات تجزئة المرضى
تُعدّ تجزئة المرضى مجموعة بيانات لتصنيف المرضى تُستخدم في تحليلات الرعاية الصحية والتسويق. وتهدف إلى تقسيم المرضى إلى مجموعات ذات دلالة من خلال تحليل خصائصهم الديموغرافية، وحالتهم الصحية، ونوع التأمين الصحي، وأنماط استخدامهم للرعاية الصحية، وذلك لتحسين فعالية الرعاية والتسويق الشخصيين.
الاستخدام المباشر:https://go.hyper.ai/Wp8LS
2. مجموعة بيانات اكتشاف حوادث السقوط بواسطة كاميرات المراقبة
مجموعة بيانات CCTV Incident هي مجموعة بيانات اصطناعية مفتوحة مصممة خصيصًا لكشف السقوط، وتقدير الوضعية، ومراقبة الحوادث في مهام رؤية الحاسوب. وهي مصممة للتحليل من منظور علوي لكاميرات المراقبة، مما يُمكّن النماذج من فهم وضعيات الأشخاص والتمييز بدقة بين الأفراد الواقفين والساقطين.
الاستخدام المباشر:https://go.hyper.ai/q60Dm

3. مجموعة بيانات التنبؤ بانقطاع المرضى
مجموعة بيانات التنبؤ بانقطاع المرضى هي مجموعة بيانات تصنيفية لمجال الرعاية الصحية تحتوي على 2000 سجل مريض مصممة للمساعدة في تحديد المرضى المعرضين لخطر الانقطاع حتى يمكن اتخاذ تدابير الاحتفاظ بهم مسبقًا.
الاستخدام المباشر:https://go.hyper.ai/QAeYw
4. مجموعة بيانات RealTimeFaceSwap-10k لتزييف مكالمات الفيديو
مجموعة بيانات RealTimeFaceSwap-10k لكشف التزييف العميق في مكالمات الفيديو هي مجموعة بيانات تُستخدم لكشف مقاطع الفيديو المُزيّفة في سيناريوهات مؤتمرات الفيديو. تتضمن هذه المجموعة سيناريوهات تطبيقية وأنواع بيانات متنوعة، بهدف توفير دعم بيانات أساسي لكشف التزييف في الفيديو.
الاستخدام المباشر:https://go.hyper.ai/SGZRO
5. مجموعة بيانات فيديو TransPhy3D لتوليف الانعكاس الشفاف
TransPhy3D هي مجموعة بيانات فيديو اصطناعية طورتها أكاديمية بكين للذكاء الاصطناعي بالتعاون مع جامعة جنوب كاليفورنيا وجامعة تسينغهوا ومؤسسات أخرى، وتركز على المشاهد الشفافة والعاكسة. تتكون مجموعة البيانات من 11000 تسلسل تم عرضها باستخدام Blender/Cycles، مما يوفر إطارات RGB عالية الجودة بالإضافة إلى بيانات العمق والخرائط العادية المستندة إلى الفيزياء.
الاستخدام المباشر:https://go.hyper.ai/5ExjE
دروس تعليمية عامة مختارة
1.vLLM+Open WebUI ينشر Nemotron-3 Nano
Nemotron-3-Nano-30B-A3B-BF16 هو نموذج لغوي واسع النطاق (LLM) تم تدريبه من الصفر بواسطة NVIDIA، وهو مصمم كنموذج موحد قابل للتطبيق على مهام الاستدلال وغير الاستدلال. هذا النموذج مناسب للمطورين الذين يصممون أنظمة وكلاء الذكاء الاصطناعي، وبرامج الدردشة الآلية، وأنظمة RAG، وغيرها من تطبيقات الذكاء الاصطناعي.
تشغيل عبر الإنترنت:https://go.hyper.ai/VUuDA
2. نموذج MedGemma 1.5 الطبي متعدد الوسائط بتقنية الذكاء الاصطناعي
يُعدّ MedGemma 1.5 نموذجًا متميزًا في المهام الطبية متعددة الوسائط. فهو يُظهر قدرات فائقة في تصنيف الصور، والإجابة على الأسئلة المرئية، والاستدلال المعرفي الطبي، مما يجعله مناسبًا لمختلف السيناريوهات السريرية، ويدعم البحث والممارسة الطبية بفعالية. يعتمد هذا النموذج على مُشفّر الصور SigLIP ووحدة لغة عالية الأداء، وقد تم تدريبه مسبقًا على مجموعات بيانات متنوعة تشمل الصور الطبية والنصوص وتقارير المختبر. وهذا يُتيح معالجة فعّالة لمهام مثل الصور الطبية عالية الأبعاد، وصور علم الأمراض المقطعية الكاملة، وتحليل الصور الطولية، والتحديد التشريحي، وفهم الوثائق الطبية، وتحليل السجلات الصحية الإلكترونية.
تشغيل عبر الإنترنت:https://go.hyper.ai/dZRn9
3. نيموترون - بث الكلام - التعرف التلقائي على الكلام: عرض توضيحي
يُعدّ Nemotron Speech Streaming ASR نموذجًا للتعرف التلقائي على الكلام المتدفق، وقد طوّره فريق Nemotron Speech في NVIDIA. صُمّم هذا النموذج خصيصًا لسيناريوهات نسخ الكلام في الوقت الفعلي مع زمن استجابة منخفض، كما يتميّز بقدرات استدلالية عالية الإنتاجية، مما يجعله مناسبًا لتطبيقات مثل المساعدين الصوتيين، والترجمة الفورية، ونسخ المؤتمرات، والذكاء الاصطناعي التفاعلي. يستخدم النموذج مُشفّر FastConformer مُدركًا لذاكرة التخزين المؤقت، وبنية مُفكّك RNN-T، مما يُحقق معالجة فعّالة لتدفقات الصوت المتواصلة مع تقليل زمن الاستجابة بشكل ملحوظ، مع الحفاظ على دقة التعرّف.
تشغيل عبر الإنترنت:https://go.hyper.ai/SDEBI
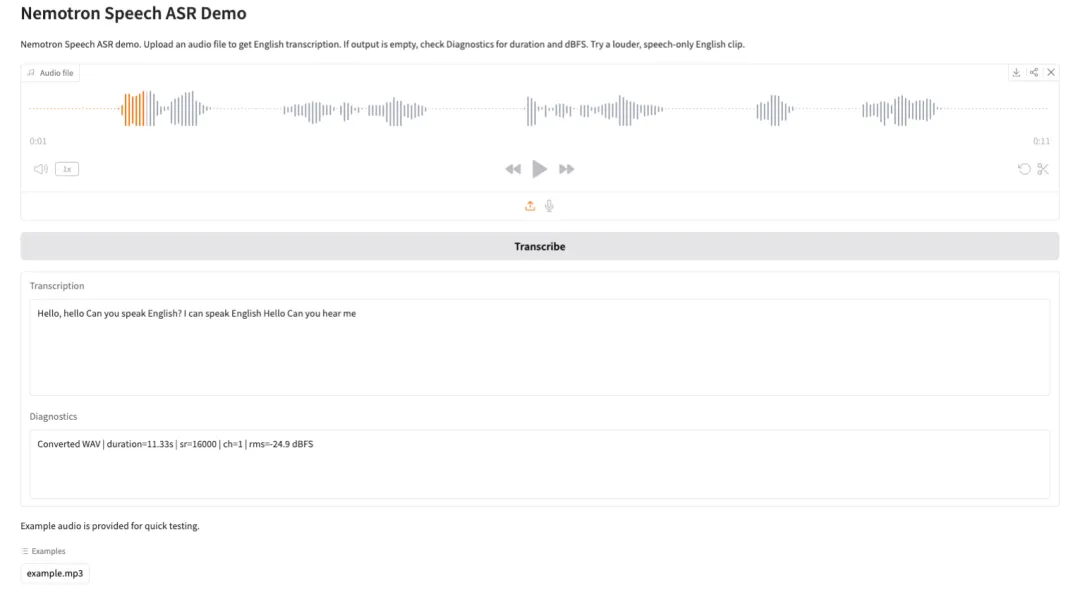
4. TranslateGemma-4B-IT: سلسلة من نماذج الترجمة مفتوحة المصدر من جوجل.
TranslateGemma هي عائلة نماذج ترجمة خفيفة الوزن ومفتوحة المصدر، طوّرها فريق ترجمة جوجل. بُنيت هذه العائلة على أساس عائلة نماذج Gemma 3، وهي مصممة خصيصًا لترجمة النصوص متعددة اللغات وتطبيقاتها العملية. توفر هذه العائلة إمكانيات ترجمة مستقرة وسهلة الاستخدام مع نطاق معلمات صغير، مما يجعلها مناسبة للتحميل والاستدلال في بيئات ذات ذاكرة GPU محدودة أو تتطلب نشرًا سريعًا.
تشغيل عبر الإنترنت:https://go.hyper.ai/FRy35
5. GLM-Image: نموذج لتوليد الصور عالي الدقة ذو دلالات دقيقة
GLM-Image هو نموذج مفتوح المصدر لتوليد الصور، طوّرته شركة Zhipu AI، ويجمع بين فك التشفير التلقائي وفك تشفير الانتشار. يدعم هذا النموذج توليد الصور من النصوص ومن الصور، وهو مبني على تمثيل موحد للغة المرئية. يُمكّن هذا النموذج من فهم كلٍّ من النصوص والصور المدخلة، بالإضافة إلى توليد صور دقيقة من خلال شبكة أساسية للانتشار على غرار DiT (محوّل الانتشار).
تشغيل عبر الإنترنت:https://go.hyper.ai/2bcfV

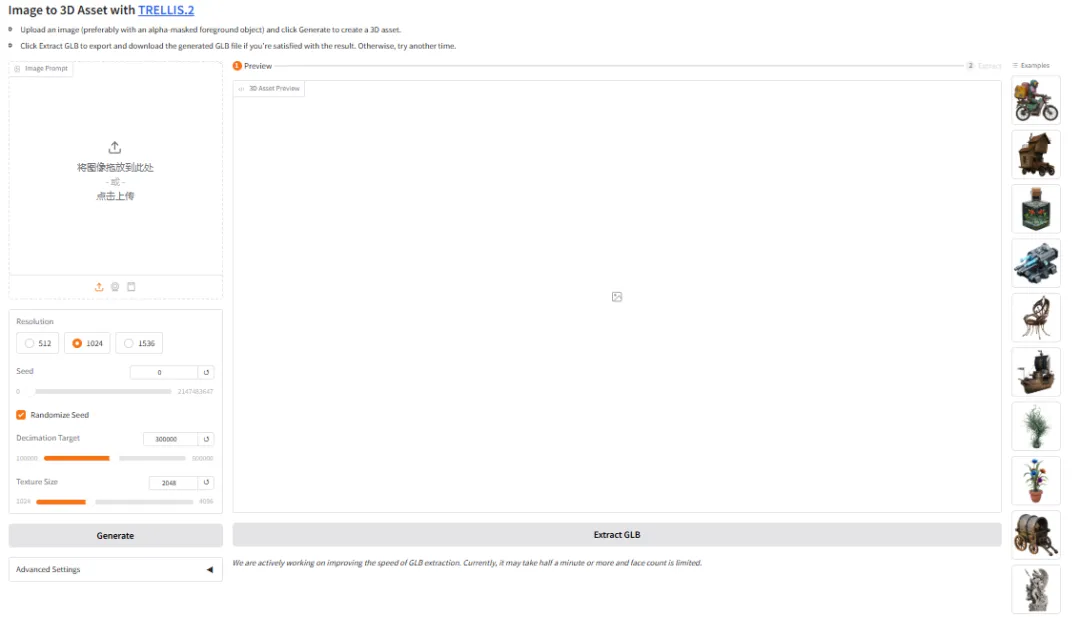
6. إنشاء عرض توضيحي ثلاثي الأبعاد لـ TRELLIS.2
TRELLIS.2 هو مشروع مفتوح المصدر أطلقته مايكروسوفت، وهو نموذج ضخم يحتوي على 4 مليارات مُعامل، ويركز على توليد أصول ثلاثية الأبعاد جاهزة للاستخدام ومُزوّدة بالكامل بالخامات، مباشرةً من صورة واحدة. يوحّد هذا النموذج هندسة عالية الجودة وتوليد المواد، مُنجزًا إعادة بناء هندسية عالية الدقة وتوليف مواد PBR كاملة الأبعاد ضمن سير عمل واحد.
تشغيل عبر الإنترنت:https://go.hyper.ai/drI7I
7.vLLM + وظيفة نشر WebUI المفتوحةGemma-270m-it
FunctionGemma-270m-it هو نموذج خفيف الوزن ومخصص لاستدعاء الدوال، أطلقته جوجل ديب مايند، ويحتوي على 270 مليون مُعامل. بُني هذا النموذج على بنية Gemma 3 270M، وتم تدريبه باستخدام نفس تقنيات البحث المستخدمة في سلسلة Gemini. صُمم هذا النموذج خصيصًا لسيناريوهات استدعاء الدوال، ويستخدم 6 تيرابايت من بيانات التدريب حتى أغسطس 2024، والتي تغطي تعريفات الأدوات العامة وبيانات تفاعل استخدام الأدوات. يدعم FunctionGemma طول سياق أقصى يبلغ 32 كيلوبايت، وقد خضع لعملية ترشيح صارمة لأمن المحتوى وعملية تطوير ذكاء اصطناعي مسؤولة.
تشغيل عبر الإنترنت:https://go.hyper.ai/pdN7q

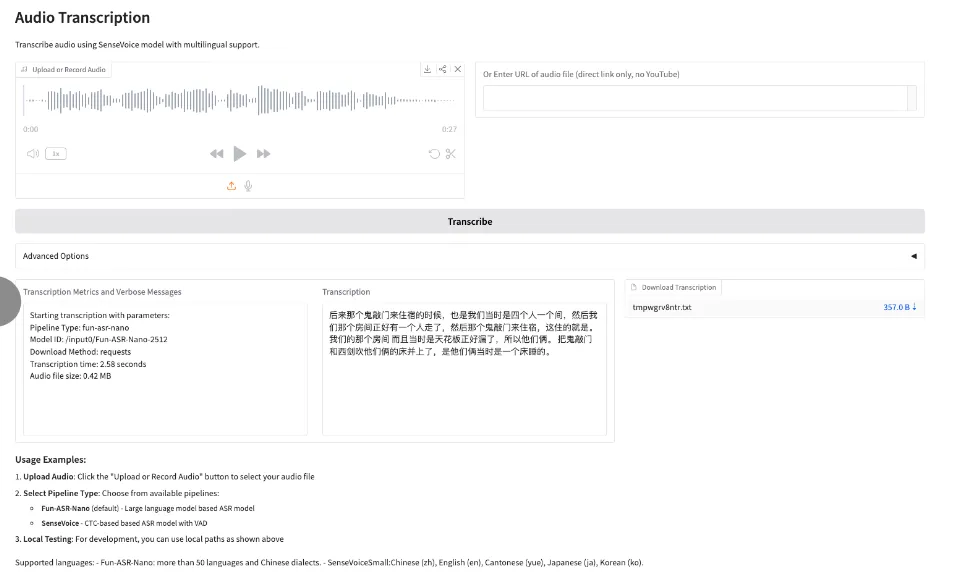
8. Fun-ASR-Nano: نموذج واسع النطاق للتعرف على الكلام من البداية إلى النهاية
Fun-ASR-Nano هو حل متكامل للتعرف على الكلام باستخدام نماذج كبيرة، أطلقته شركة Alibaba Tongyi Labs، وهو جزء من سلسلة Fun-ASR. صُمم هذا الحل خصيصًا للبيئات ذات القدرة الحاسوبية المنخفضة، بهدف تحقيق نسخ نصي سريع الاستجابة، مع التركيز على الأداء في مجموعات التقييم الواقعية. تشمل ميزاته التعرف الحر على الكلام متعدد اللغات (التبديل الحر بين اللغات)، والكلمات المفتاحية القابلة للتخصيص، وكبح التشويش.
تشغيل عبر الإنترنت:https://go.hyper.ai/j7OdD
9. فارا-7ب: نموذج وكيل ذكي فعال قائم على الويب
يُعدّ Fara-7B أول نموذج لغة صغير (SLM) مُصمّم للاستخدام الحاسوبي، وقد أصدرته شركة مايكروسوفت للأبحاث. وبفضل احتوائه على 7 مليارات مُعامل فقط، يُحقق أداءً استثنائيًا في مهام معالجة صفحات الويب الواقعية، مُحققًا أداءً مُتميزًا في العديد من معايير أداء وكلاء الويب، ومُقاربًا أو حتى مُتفوقًا على النماذج الأكبر حجمًا في بعض المهام.
تشغيل عبر الإنترنت:https://go.hyper.ai/2e5rp
توصيات الورقة البحثية لهذا الأسبوع
1. المشاهدة والاستدلال والبحث: معيار بحثي معمق للفيديو على الويب المفتوح للاستدلال الفعال للفيديو
تُقدّم هذه الورقة البحثية أول معيار للتعلم العميق للفيديوهات، وهو VideoDR، الذي يتطلب من النماذج استخراج نقاط مرجعية بصرية من الفيديوهات، وإجراء استرجاع تفاعلي، واستخلاص استنتاجات متعددة المراحل بناءً على أدلة من مصادر متعددة. ويُظهر تقييم نماذج كبيرة مختلفة أن نموذج الوكيل ليس دائمًا أفضل من نموذج سير العمل؛ إذ تعتمد فعاليته على قدرة النموذج على الحفاظ على النقاط المرجعية البصرية الأولية في سلاسل الاسترجاع الطويلة. وتُحدد الدراسة انحراف الهدف والاتساق طويل الأمد كعقبات رئيسية.
رابط الورقة:https://go.hyper.ai/uB9jE
2. بيبي فيجن: التفكير البصري يتجاوز اللغة
خلصت هذه الدراسة إلى أن نماذج التعلم الآلي متعددة اللغات الحالية تعتمد بشكل مفرط على المعارف اللغوية المسبقة، وتفتقر إلى القدرات البصرية الأساسية التي يمتلكها الأطفال الصغار. وأظهر اختبار BabyVision المعياري الذي أجراه فريق البحث أن النماذج ذات الأداء المتميز (مثل Gemini الذي حصل على 49.7) سجلت درجات أقل بكثير من مستويات البالغين (94.1)، بل إنها لم تصل حتى إلى مستوى الأطفال في سن السادسة، مما يدل على قصور جوهري في الفهم البصري الأساسي. ويهدف هذا البحث إلى تطوير نماذج التعلم الآلي متعددة اللغات لتصل إلى مستوى الإدراك البصري والاستدلال البشري.
رابط الورقة:https://go.hyper.ai/cjtcE
3. التقرير الفني STEP3-VL-10B
تقترح هذه الورقة البحثية نموذج STEP3-VL-10B كنموذج أساسي متعدد الوسائط عالي الأداء ومفتوح المصدر. من خلال التدريب المسبق الموحد، والتعلم المعزز، وآلية استدلال متوازية منسقة مبتكرة، يحقق هذا النموذج أداءً متميزًا باستخدام 10 مليارات مُعامل فقط. ويُنافس أو يتفوق على نماذج ضخمة أكبر منه بعشرة إلى عشرين ضعفًا، وعلى أفضل النماذج المغلقة المصدر في العديد من اختبارات القياس المعيارية، مما يوفر للمجتمع معيارًا قويًا وفعالًا لذكاء اللغة المرئية.
رابط الورقة:https://go.hyper.ai/q6kmv
4. التفكير باستخدام الخريطة: وكيل معزز بالخريطة المتوازية لتحديد الموقع الجغرافي
تقترح هذه الورقة البحثية تمكين النموذج من "التفكير باستخدام الخريطة". من خلال حلقات الربط بين الوكيل والخريطة والتحسين على مرحلتين، يتم توظيف التعلم المعزز وتوسيع نطاق وقت الاختبار المتوازي، مما يحسن بشكل كبير دقة تحديد الموقع الجغرافي للصور. على معيار الصور الواقعية المُنشأ حديثًا MAPBench، يتفوق هذا الأسلوب على النماذج مفتوحة المصدر ومغلقة المصدر الحالية، حيث يزيد الدقة بشكل كبير ضمن نطاق 500 متر من 8.01 TP3T إلى 22.11 TP3T.
رابط الورقة:https://go.hyper.ai/Fn9XT
5. التجزئة الاجتماعية الدلالية الحضرية باستخدام الاستدلال البصري اللغوي
تقترح هذه الدراسة مجموعة بيانات SocioSeg وإطار عمل SocioReasoner، مستخدمةً نموذجًا لغويًا بصريًا للاستدلال بهدف معالجة تحدي تجزئة الكيانات الدلالية الاجتماعية في صور الأقمار الصناعية. تحاكي هذه الطريقة عملية التعليق البشري من خلال التعرف متعدد الوسائط والاستدلال متعدد المراحل، وقد تم تحسينها باستخدام التعلم المعزز. تجريبيًا، تتفوق هذه الطريقة على أحدث النماذج المتاحة، مُظهرةً قدرات تعميم قوية دون الحاجة إلى تدريب مسبق.
رابط الورقة:https://go.hyper.ai/PW7g4
تفسير مقالة المجتمع
1. من خلال دمج بيانات تسلسل البروتين والبنية ثلاثية الأبعاد والخصائص الوظيفية، قام فريق ألماني ببناء "نظرة بانورامية" لإنزيم E3 ubiquitin ligase البشري بناءً على التعلم المتري.
في الكائنات الحية، يُعدّ التحلل والتجديد السريع للبروتينات الخلوية أمرًا بالغ الأهمية للحفاظ على توازن البروتينات. ويُعتبر نظام اليوبيكويتين-بروتيازوم (UPS) آلية أساسية لتنظيم نقل الإشارات وتحلل البروتينات. ضمن هذا النظام، تعمل إنزيمات E3 يوبيكويتين ليغاز كوحدات تحفيزية رئيسية، وقد أظهرت إنزيمات E3 ليغاز التي دُرست حتى الآن تباينًا كبيرًا. في هذا السياق، قام فريق بحثي من جامعة غوته في ألمانيا بتصنيف "مجموعة إنزيمات E3 ليغاز البشرية". تعتمد طريقة التصنيف التي اتبعوها على نموذج تعلم المقاييس، باستخدام إطار هرمي ذي إشراف ضعيف لفهم العلاقات الحقيقية بين عائلة E3 وفروعها.
شاهد التقرير الكامل:https://go.hyper.ai/zyM1F
2. اقترحت جامعة ييل مشروع MOSAIC، الذي يقوم ببناء فريق يضم أكثر من 2000 خبير في الكيمياء باستخدام الذكاء الاصطناعي، مما يتيح التخصص الفعال وتحديد المسارات التركيبية المثلى.
يواجه علم الكيمياء التركيبية الحديث تناقضًا بارزًا بين التراكم السريع للمعرفة وكفاءة تطبيقها وتحويلها. حاليًا، يحدّ من تطور هذا المجال عاملان رئيسيان: أولهما، صعوبة تغطية الخبرة المتخصصة لنطاق التفاعلات المتسع باستمرار، مما يؤدي غالبًا إلى تكاليف باهظة من التجربة والخطأ في المهام التركيبية متعددة التخصصات؛ وثانيهما، على الرغم من التطور السريع لتقنية الذكاء الاصطناعي، لا تزال موثوقية النماذج العامة في الكيمياء غير كافية. في هذا السياق، اقترح فريق بحثي في جامعة ييل مؤخرًا نموذج MOSAIC، الذي يحوّل نموذجًا عامًا للغة واسعة النطاق إلى نظام تعاوني يتألف من العديد من خبراء الكيمياء المتخصصين.
شاهد التقرير الكامل:https://go.hyper.ai/oatBT
3. برنامج تعليمي عبر الإنترنت | GLM-Image: فهم التعليمات بدقة وكتابة نص صحيح باستخدام بنية هجينة من مُفكِّك الانحدار الذاتي + مُفكِّك الانتشار
في مجال توليد الصور، أصبحت نماذج الانتشار شائعة الاستخدام تدريجيًا نظرًا لثبات تدريبها وقدراتها العالية على التعميم. مع ذلك، عند التعامل مع سيناريوهات تتطلب معرفة مكثفة، تعاني النماذج التقليدية من قصور في الجمع بين فهم التعليمات والوصف التفصيلي. ولمعالجة هذه المشكلة، قامت شركة Zhipu، بالتعاون مع هواوي، بنشر نموذج GLM-Image، وهو نموذج مفتوح المصدر لتوليد الصور من الجيل الجديد. تم تدريب هذا النموذج بالكامل على جهاز Ascend Atlas 800T A2 وإطار عمل MindSpore للذكاء الاصطناعي. وتتمثل ميزته الأساسية في اعتماد بنية هجينة مبتكرة تجمع بين "النموذج التراجعي الذاتي وفك تشفير الانتشار" (نموذج تراجعي ذاتي 9 بايت + فك تشفير DiT 7 بايت)، ما يجمع بين قدرات الفهم العميق لنماذج اللغة وقدرات التوليد عالية الجودة لنماذج الانتشار.
شاهد التقرير الكامل:https://go.hyper.ai/LTojo
٤. أحدث نتائج بحثية منشورة في مجلة Nature من جامعة تسينغهوا وجامعة شيكاغو! يُمكّن الذكاء الاصطناعي العلماء من الترقية قبل ١٫٣٧ سنة ويُقلل نطاق البحث العلمي بمقدار ٤٫٦٣١ TP3T
في الآونة الأخيرة، نشر فريق بحثي من جامعة تسينغهوا وجامعة شيكاغو أحدث نتائج أبحاثهم في مجلة Nature بعنوان "أدوات الذكاء الاصطناعي توسع نطاق تأثير العلماء ولكنها تقلص تركيز العلوم"، مما يوفر دليلاً منهجياً غير مسبوق للصناعة لفهم التأثير الأساسي للذكاء الاصطناعي على العلوم.
شاهد التقرير الكامل:https://go.hyper.ai/0NhLI
مقالات موسوعية شعبية
1. معدل الإطارات في الثانية (FPS)
2. دمج الفرز العكسي RRF
3. نموذج اللغة المرئي (VLM)
4. الشبكات الفائقة
5. الانتباه المُوجَّه
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
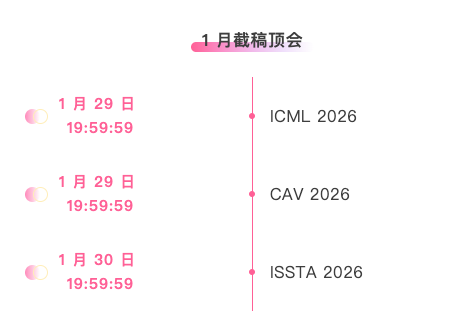
منصة شاملة لتتبع أهم المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








