Command Palette
Search for a command to run...
تجربة ذات حاجز منخفض لـ Open-AutoGLM: تجربة وكيل ذكي تجمع بين فهم الشاشة والتنفيذ الآلي؛ Spatial-SSRL-81k: بناء مسار تحسين ذاتي الإشراف للوعي المكاني.

بينما كانت "Doubao Mobile" لا تزال في خضم النقاشات حول كونها موضة رائجة،أعلنت شركة Zhipu AI أنها جعلت إطار عمل مساعدها الذكي للهواتف المحمولة مفتوح المصدر، وهو Open-AutoGLM.فهو يتيح فهمًا متعدد الوسائط وتشغيلًا آليًا لمحتوى الشاشة.
على عكس أدوات أتمتة الأجهزة المحمولة التقليدية،يستخدم وكيل الهاتف نموذج لغة مرئي لتحقيق فهم دلالي عميق لمحتوى الشاشة، ويجمع بين قدرات التخطيط الذكية لإنشاء وتنفيذ عمليات التشغيل تلقائيًا.يتحكم النظام بالجهاز عبر ADB (جسر تصحيح أخطاء أندرويد). كل ما يحتاجه المستخدمون هو وصف احتياجاتهم بلغة طبيعية، مثل "افتح تطبيق Xiaohongshu للبحث عن الطعام"، ويمكن لوكيل الهاتف تحليل الغرض تلقائيًا، وفهم الواجهة الحالية، والتخطيط للخطوة التالية، وإتمام العملية بأكملها.
من حيث الأمان والتحكم، صُمم النظام بآلية تأكيد حساسة للعمليات، ويدعم استحواذ المستخدم على الحساب في الحالات التي تتطلب تدخلاً يدوياً، مثل تسجيل الدخول أو الدفع أو رموز التحقق، مما يضمن تجربة مستخدم آمنة وموثوقة. إضافةً إلى ذلك، يتمتع وكيل الهاتف بإمكانيات تصحيح أخطاء ADB عن بُعد، ويدعم اتصالات الأجهزة عبر شبكات الواي فاي أو شبكات الجوال، مما يوفر للمطورين والمستخدمين المتقدمين تحكماً مرناً عن بُعد ودعماً فورياً لتصحيح الأخطاء.
في الوقت الحالي،تم تطبيق Open-AutoGLM، الذي تم تنفيذه بناءً على هذا الإطار، على أكثر من 50 تطبيقًا صينيًا رئيسيًا، بما في ذلك WeChat و Taobao و Xiaohongshu.بفضل قدرته على التعامل مع مجموعة متنوعة من المهام اليومية، بدءًا من التفاعل الاجتماعي والتسوق الإلكتروني وصولاً إلى تصفح المحتوى، فإنه يتطور تدريجياً ليصبح مساعداً ذكياً يغطي جميع جوانب حياة المستخدمين، بما في ذلك الملابس والطعام والسكن والنقل.
يعرض موقع HyperAI الإلكتروني الآن "Open-AutoGLM: مساعد ذكي للأجهزة المحمولة"، لذا تفضلوا بتجربته!
الاستخدام عبر الإنترنت:https://go.hyper.ai/QwvOU
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 8 ديسمبر إلى 12 ديسمبر:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 5
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
أهم المؤتمرات التي تنتهي مواعيدها في يناير: 11
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات توليد الصور المرئية للأحداث متعددة المراحل من Envision
Envision هي مجموعة بيانات تضم صورًا متعددة وأزواجًا نصية، أصدرها مختبر شنغهاي للذكاء الاصطناعي، وهي مصممة لاختبار قدرة النموذج على فهم العلاقات السببية وتوليد سرديات متعددة المراحل في أحداث واقعية. تحتوي مجموعة البيانات على 1000 تسلسل أحداث و4000 نص توضيحي من أربع مراحل، تغطي ستة مجالات رئيسية: العلوم الطبيعية والعلوم الإنسانية/التاريخ. تُستقى مواد الأحداث من الكتب الدراسية والموارد الإلكترونية، ويختارها خبراء، ثم يُولّدها ويُحسّنها نموذج GPT-4o لتشكيل سرديات ذات سلاسل سببية واضحة ومراحل متدرجة.
الاستخدام المباشر:https://go.hyper.ai/xD4j6
2. مجموعة بيانات DetectiumFire متعددة الوسائط لفهم الحرائق
تم تصميم مجموعة بيانات DetectiumFire، التي أصدرتها جامعة تولين بالتعاون مع جامعة آلتو، خصيصًا لمهام الكشف عن اللهب، والاستدلال البصري، وتوليد الوسائط المتعددة. وقد أُدرجت ضمن مسار مجموعات البيانات والمعايير في مؤتمر NeurIPS 2025، بهدف توفير مورد موحد للتدريب والتقييم لمشاهد الحرائق في مجال رؤية الحاسوب ونماذج اللغة البصرية. تحتوي مجموعة البيانات على أكثر من 145,000 صورة عالية الجودة لحرائق حقيقية، بالإضافة إلى 25,000 مقطع فيديو متعلق بالحرائق.
الاستخدام المباشر:https://go.hyper.ai/7Z92Z

3. مجموعة بيانات تقييم المشي ثلاثي الأبعاد لمرضى باركنسون Care-PD
تُعدّ مجموعة بيانات CARE-PD، التي أصدرتها جامعة تورنتو بالتعاون مع معهد فيكتور ومعهد كايت للأبحاث التابع لشبكة جامعة تورنتو الصحية (UHN) ومؤسسات أخرى، أكبر مجموعة بيانات متاحة للعموم لشبكات المشي ثلاثية الأبعاد لمرض باركنسون. وقد تم اختيارها ضمن مجموعات بيانات ومعايير مؤتمر NeurIPS 2025، وتهدف إلى توفير قاعدة بيانات عالية الجودة للتنبؤ بالنتائج السريرية، وتعلم تمثيل مشية باركنسون، والتحليل الموحد عبر المؤسسات. تحتوي مجموعة البيانات على سجلات مشي لـ 362 شخصًا من 9 مجموعات مستقلة من 8 مؤسسات سريرية. وقد خضعت جميع مقاطع الفيديو الخاصة بالمشي وبيانات التقاط الحركة لمعالجة موحدة وتحويلها إلى شبكات SMPL ثلاثية الأبعاد مجهولة الهوية لمشي الإنسان.
الاستخدام المباشر:https://go.hyper.ai/CH7Oi
4. مجموعة بيانات PolyMath المعيارية للاستدلال الرياضي متعدد اللغات
PolyMath هي مجموعة بيانات تقييم الاستدلال الرياضي متعددة اللغات، أصدرها فريق Qianwen التابع لشركة Alibaba بالتعاون مع جامعة Shanghai Jiao Tong. وقد تم اختيارها ضمن مجموعات بيانات ومعايير NeurIPS 2025، وتهدف إلى التقييم المنهجي للفهم الرياضي وعمق الاستدلال وأداء الاتساق عبر اللغات لنماذج اللغة الكبيرة في ظل ظروف متعددة اللغات.
الاستخدام المباشر:https://go.hyper.ai/VM5XK
5. مجموعة بيانات فيديو VOccl3D ثلاثية الأبعاد لحجب الرؤية البشرية
VOccl3D هي مجموعة بيانات اصطناعية واسعة النطاق، أصدرتها جامعة كاليفورنيا، وتركز على فهم الإنسان ثلاثي الأبعاد في المشاهد المعقدة المحجوبة. تهدف هذه المجموعة إلى توفير معيار أكثر واقعية لتقدير وضعية الإنسان، وإعادة بنائه، ومهام الإدراك متعدد الوسائط. تحتوي مجموعة البيانات على أكثر من 250,000 صورة وحوالي 400 مقطع فيديو، تم إنشاؤها من مشاهد خلفية، وحركات بشرية، وقوام متنوع.
الاستخدام المباشر:https://go.hyper.ai/vBFc2

6. مجموعة بيانات Spatial-SSRL-81k ذاتية الإشراف الواعية بالمكان
Spatial-SSRL-81k هي مجموعة بيانات للتعلم الذاتي للرؤية واللغة، مصممة لفهم واستدلال المعلومات المكانية، وقد أصدرها مختبر شنغهاي للذكاء الاصطناعي بالتعاون مع جامعة شنغهاي جياو تونغ، والجامعة الصينية في هونغ كونغ، ومؤسسات أخرى. تهدف هذه المجموعة إلى تزويد النماذج الكبيرة بقدرات إدراك مكاني دون الحاجة إلى إضافة تعليقات توضيحية يدوية، مما يُحسّن أداءها في الاستدلال والتعميم في سيناريوهات متعددة الوسائط.
الاستخدام المباشر:https://go.hyper.ai/AfHSW

7. WenetSpeech-Chuan (مجموعة بيانات الكلام باللهجة السيشوانية-تشونغتشينغ)
WenetSpeech-Chuan هي مجموعة بيانات واسعة النطاق للهجات سيتشوان وتشونغتشينغ، أصدرتها جامعة نورث وسترن بوليتكنيكال بالتعاون مع شركة هيلبيك، ومعهد أبحاث الذكاء الاصطناعي التابع لشركة تشاينا تيليكوم، ومؤسسات أخرى. تغطي مجموعة البيانات 9 سيناريوهات واقعية، حيث تمثل مقاطع الفيديو القصيرة 52,831 نقطة زمنية. أما باقي المحتوى فيشمل الترفيه، والبث المباشر، والكتب الصوتية، والأفلام الوثائقية، والمقابلات، والأخبار، والقراءة، والمسلسلات، مما يوفر توزيعًا متنوعًا وواقعيًا للغاية للكلام.
الاستخدام المباشر:https://go.hyper.ai/dFlE2
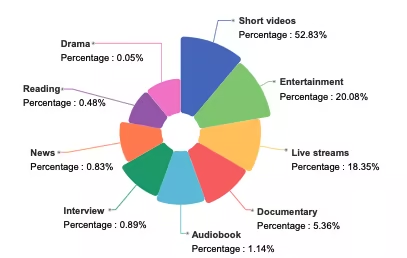
8. مجموعة بيانات اختبار فسيولوجي من PhysDriver
يُعدّ PhysDrive أول مجموعة بيانات متعددة الوسائط واسعة النطاق لقياسات فسيولوجية داخل المركبات دون تلامس في بيئة قيادة حقيقية، وقد أصدرتها مؤسسات مثل جامعة هونغ كونغ للعلوم والتكنولوجيا (غوانغتشو)، وجامعة هونغ كونغ للعلوم والتكنولوجيا، وجامعة تسينغهوا. وقد تم اختيارها ضمن مجموعات بيانات ومعايير NeurIPS 2025، وتهدف إلى دعم البحث والتقييم في مجال مراقبة حالة السائق، وأنظمة قمرة القيادة الذكية، وأساليب الإدراك الفسيولوجي متعددة الوسائط.
الاستخدام المباشر:https://go.hyper.ai/4qz9T
9. مجموعة بيانات MMSVGBench المعيارية لتوليد الرسومات المتجهة متعددة الوسائط
MMSVG-Bench هو معيار شامل مصمم لمهام توليد رسومات SVG متعددة الوسائط، تم إصداره بالاشتراك بين جامعة فودان وشركة StepFun. وقد تم اختياره ضمن مجموعات بيانات ومعايير NeurIPS 2025، ويهدف إلى سد الفجوة في مجال توليد الرسومات المتجهة الحالي، الذي يفتقر إلى مجموعة اختبار موحدة ومفتوحة ومعيارية.
الاستخدام المباشر:https://go.hyper.ai/WiZCR
10. مجموعة بيانات PolypSense3D المُراعية لحجم الزوائد اللحمية
PolypSense3D هي مجموعة بيانات مرجعية متعددة المصادر مصممة خصيصًا لمهام قياس حجم الزوائد اللحمية باستخدام استشعار العمق، وقد أصدرتها جامعة هانغتشو للمعلمين بالتعاون مع جامعة الدنمارك التقنية وجامعة هوهاي ومؤسسات أخرى. تم اختيارها للمشاركة في مؤتمر NeurIPS 2025، وتهدف إلى توفير موارد تدريب وتقييم عالية الجودة للكشف عن الزوائد اللحمية، وتقدير العمق، وقياس الحجم، ونقل التعلم من المحاكاة إلى الواقع.
الاستخدام المباشر:https://go.hyper.ai/SZnu6
دروس تعليمية عامة مختارة
1. Dia2-TTS: خدمة توليف الكلام في الوقت الحقيقي
Dia2-TTS هي خدمة توليف كلام فوري مبنية على نموذج Dia2 لتوليد الكلام واسع النطاق (Dia2-2B) الذي طوره فريق nari-labs. تدعم الخدمة إدخال نصوص حوارية متعددة الأدوار، وموجهات صوتية ثنائية الدور (Prefix Voice)، وأخذ عينات قابل للتحكم في عدة معايير. توفر واجهة تفاعلية كاملة عبر الإنترنت من خلال Grado لتوليف كلام محادثة عالي الجودة. يمكن للنموذج إدخال نصوص حوارية متتالية متعددة الأدوار مباشرةً لتوليد كلام طبيعي ومتماسك ومتسق وعالي الجودة، مما يجعله مناسبًا لتطبيقات مثل خدمة العملاء الافتراضية، والمساعدين الصوتيين، ودبلجة الذكاء الاصطناعي، وإنتاج المسلسلات القصيرة.
تشغيل عبر الإنترنت:https://go.hyper.ai/Qbfni
2. Open-AutoGLM: مساعد ذكي للأجهزة المحمولة
Open-AutoGLM هو إطار عمل مساعد ذكي للهواتف المحمولة، أطلقته شركة Zhipu AI، وهو مبني على AutoGLM. يستطيع هذا الإطار فهم محتوى شاشة الهاتف المحمول بطريقة متعددة الوسائط، ومساعدة المستخدمين على إنجاز المهام من خلال عمليات مؤتمتة. على عكس أدوات أتمتة الهواتف المحمولة التقليدية، يستخدم Phone Agent نموذج لغة مرئية لفهم الشاشة، بالإضافة إلى إمكانيات تخطيط ذكية لإنشاء وتنفيذ عمليات التشغيل تلقائيًا.
تشغيل عبر الإنترنت:https://go.hyper.ai/QwvOU
3. خدمة VibeVoice-Realtime TTS: خدمة توليف الكلام في الوقت الفعلي
يُعدّ نظام VibeVoice-Realtime TTS نظامًا عالي الجودة لتحويل النص إلى كلام في الوقت الفعلي، وهو مبنيّ على نموذج توليف الكلام المتدفق VibeVoice-Realtime-0.5B الذي أصدره فريق أبحاث مايكروسوفت. يدعم النظام توليد الكلام من متحدثين متعددين، والاستدلال في الوقت الفعلي بزمن استجابة منخفض، بالإضافة إلى عرض مرئي تفاعلي على منصة Grado الإلكترونية.
تشغيل عبر الإنترنت:https://go.hyper.ai/RviLs
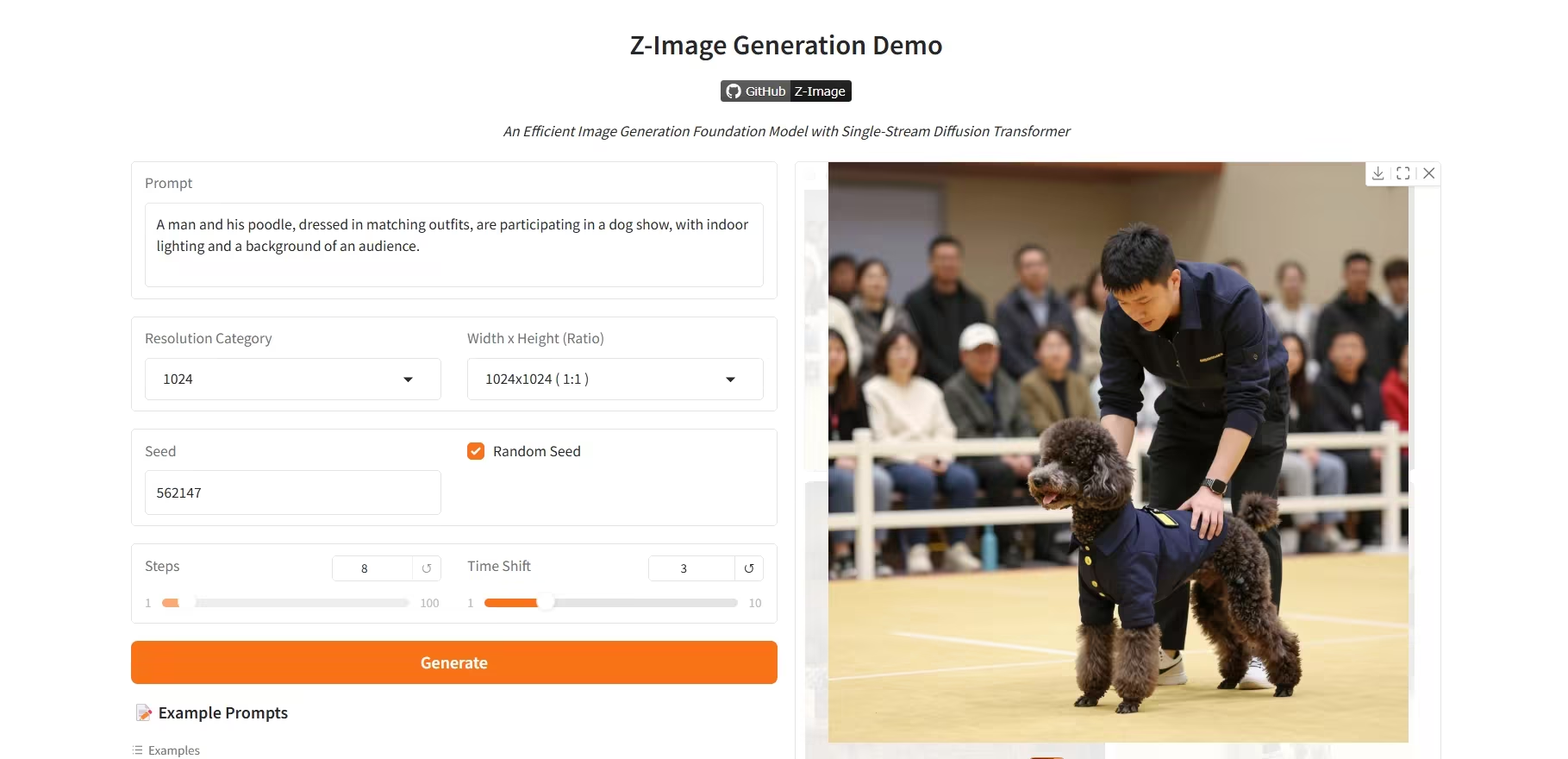
4. Z-Image-Turbo: نموذج عالي الكفاءة لتوليد الصور بستة معلمات
Z-Image-Turbo هو جيل جديد من نماذج توليد الصور عالية الكفاءة، أطلقه فريق تونغي تشيان وين التابع لشركة علي بابا. باستخدام 6 بايتات فقط من المعاملات، يحقق هذا النموذج أداءً يُضاهي النماذج الرائدة المغلقة المصدر التي تحتوي على أكثر من 20 بايتًا من المعاملات، وهو بارع بشكل خاص في توليد صور شخصية عالية الدقة وواقعية للغاية.
تشغيل عبر الإنترنت:https://go.hyper.ai/R8BJF
5. أوفيس-إيميج: نموذج عالي الجودة لتوليد الصور
يُعدّ Ovis-Image نظامًا عالي الجودة لتحويل النصوص إلى صور (T2I)، وهو مبنيّ على نموذج Ovis-Image-7B عالي الدقة لتحويل النصوص إلى صور، والذي أصدره فريق AIDC-AI. يستخدم هذا النظام مُشفّر Transformer متعدد المقاييس وبنية توليدية ذاتية التراجع، مما يُظهر أداءً استثنائيًا في توليد الصور عالية الدقة، وتمثيل التفاصيل، والتكيّف مع أنماط متعددة.
تشغيل عبر الإنترنت:https://go.hyper.ai/NoaDw

توصيات الورقة البحثية لهذا الأسبوع
1. وان-موف: توليد فيديو قابل للتحكم بالحركة عبر توجيه المسار الكامن
تقترح هذه الورقة البحثية Wan-Move، وهو إطار عمل بسيط وقابل للتطوير يُضيف إمكانيات التحكم في الحركة إلى نماذج توليد الفيديو. غالبًا ما تعاني الطرق الحالية للتحكم في الحركة من تحكم غير دقيق وقابلية محدودة للتطوير، مما ينتج عنه نتائج لا تفي بمتطلبات التطبيقات العملية. لسد هذه الفجوة، يُحقق Wan-Move تحكمًا عالي الدقة والجودة في الحركة. وتتمثل فكرته الأساسية في تزويد الميزات الشرطية الأصلية مباشرةً بإمكانيات إدراك الحركة لتوجيه عملية توليد الفيديو.
رابط الورقة:https://go.hyper.ai/h3uaG
2. فيجنري: حامل نموذج العالم المبني على منصة غاوسيان سبلاتينغ المدعومة بتقنية WebGPU
تقترح هذه الورقة البحثية منصة Visionary، وهي منصة مفتوحة المصدر، مصممة خصيصًا للعمل على الويب، لعرض الصور في الوقت الفعلي، وتدعم عرض أنواع مختلفة من الصور النقطية والشبكية باستخدام نموذج غاوسي. تعتمد المنصة على محرك عرض عالي الأداء بتقنية WebGPU، بالإضافة إلى آلية استدلال ONNX تُنفذ لكل إطار، مما يُمكّنها من تحقيق قدرات معالجة عصبية ديناميكية مع الحفاظ على تصميم خفيف الوزن وتجربة استخدام سلسة عبر المتصفح.
رابط الورقة:https://go.hyper.ai/NaBv3
3. مُستَخرِج التوازي الأصلي: الاستدلال بالتوازي عبر التعلم المعزز المُستخلص ذاتيًا
تقترح هذه الورقة البحثية نظام الاستدلال المتوازي الأصلي (NPR)، وهو إطار عمل لا يعتمد على مُعلِّم، يمكّن نماذج اللغة الكبيرة (LLMs) من تطوير قدرات استدلال متوازية حقيقية بشكل مستقل. في ثمانية اختبارات معيارية للاستدلال، حقق نظام NPR، المُدرَّب على نموذج Qwen3-4B، تحسنًا في الأداء يصل إلى 24.51 TP3T، وزيادة قصوى في سرعة الاستدلال بمقدار 4.6 أضعاف.
رابط الورقة:https://go.hyper.ai/KWiZQ
4. TwinFlow: تحقيق توليد بخطوة واحدة على نماذج كبيرة باستخدام تدفقات ذاتية العداء
تقترح هذه الورقة البحثية TwinFlow، وهو إطار عمل لتدريب النماذج التوليدية. لا تعتمد هذه الطريقة على نموذج مُدرِّب مُسبقًا ثابت، وتتجنب استخدام الشبكات التنافسية التقليدية أثناء التدريب، مما يجعلها مناسبة بشكل خاص لبناء نماذج توليدية واسعة النطاق وعالية الكفاءة. في مهام تحويل النصوص إلى صور، يحقق هذا الإطار درجة GenEval تبلغ 0.83 باستخدام تقييم دالة من الدرجة الأولى فقط (1-NFE)، متفوقًا بشكل ملحوظ على نماذج أساسية قوية مثل SANA-Sprint (إطار عمل يعتمد على خسارة GAN) وRCGM (إطار عمل يعتمد على آليات الاتساق).
رابط الورقة:https://go.hyper.ai/l1nUp
5. ما وراء الواقع: امتداد تخيلي لتضمينات الموضع الدوراني لنماذج اللغة ذات السياق الطويل
أصبح ترميز الموضع الدوراني (RoPE)، الذي يتضمن تدوير متجهي الاستعلام والمفتاح في المستوى المركب، أسلوبًا قياسيًا لترميز ترتيب التسلسل في نماذج اللغة الكبيرة (LLMs). مع ذلك، تستخدم التطبيقات القياسية الحالية الجزء الحقيقي فقط من حاصل الضرب النقطي المركب لحساب درجات الانتباه، متجاهلةً الجزء التخيلي الذي يحتوي على معلومات طورية مهمة. قد يؤدي هذا إلى فقدان تفاصيل العلاقات النسبية الحاسمة عند نمذجة التبعيات بعيدة المدى. تقترح هذه الورقة البحثية أسلوبًا موسعًا يُعيد إدخال معلومات الجزء التخيلي التي تم تجاهلها سابقًا. يستفيد هذا الأسلوب استفادةً كاملةً من التمثيل المركب الكامل لبناء درجة انتباه ثنائية المكونات.
رابط الورقة:https://go.hyper.ai/iGTw6
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
1. مقامرة بقيمة 20 مليار دولار! تراهن xAI بحصص ماسك الضخمة على OpenAI، مع بقاء جدواها التجارية المستقبلية هي أكبر علامة استفهام.
في عام 2025، اكتسبت xAI زخمًا رأسماليًا غير مسبوق بفضل الدعم القوي من إيلون ماسك، إلا أن تسويقها ظل يعتمد بشكل كبير على منظومتي X وTesla، مع تزايد التدفقات النقدية والضغوط التنظيمية في آن واحد. وأصبح نهج Grok القائم على "التوافق الضعيف" أكثر خطورة في ظل تزايد صرامة اللوائح العالمية، كما أن ارتباطاتها الوثيقة بـ X أضعفت من إمكانات نموها المستقل. وفي مواجهة اختلالات التكاليف، ومحدودية نماذج الأعمال، والتعقيدات التنظيمية، لا يزال مستقبل xAI يتأرجح بين سرديات الشركات العملاقة، والتغيرات السياسية، وإرادة ماسك الشخصية.
شاهد التقرير الكامل:https://go.hyper.ai/NmLi4
2. جدول الأعمال الكامل | يجتمع مختبر شنغهاي للابتكار، وشركة TileAI، وشركة Huawei، ومختبر Advanced Compiler، وشركة AI9Stars في شنغهاي لإجراء تحليل متعمق للعملية الكاملة لتحسين المشغل.
ستُعقد الجلسة التقنية الثامنة لفعالية "لقاء مع مُترجم الذكاء الاصطناعي" في 27 ديسمبر/كانون الأول في أكاديمية شنغهاي للابتكار. تضم هذه الجلسة خبراء من أكاديمية شنغهاي للابتكار، ومجتمع TileAI، وشركة Huawei HiSilicon، ومختبر Advanced Compiler Lab، ومجتمع AI9Stars. سيشاركون رؤاهم حول سلسلة التكنولوجيا بأكملها، بدءًا من تصميم حزمة البرمجيات وتطوير المُعاملات وصولًا إلى تحسين الأداء. تشمل المواضيع قابلية التشغيل البيني بين الأنظمة البيئية المختلفة لـ TVM، وتحسين مُعاملات الدمج في PyPTO، وأنظمة زمن الاستجابة المنخفض باستخدام TileRT، وتقنيات التحسين الرئيسية لـ Triton عبر بنى معمارية متعددة، وتحسين المُعاملات لـ AutoTriton، مما يُقدم مسارًا تقنيًا متكاملًا من النظرية إلى التطبيق.
شاهد التقرير الكامل:https://go.hyper.ai/xpwkk
3. برنامج تعليمي عبر الإنترنت | يحقق SAM 3 تجزئة المفاهيم المُلمّحة مع تحسين الأداء بمقدار الضعف، ومعالجة 100 كائن مُكتشف في 30 مللي ثانية
رغم التقدم الملحوظ الذي أحرزته نماذج SAM وSAM 2 في تجزئة الصور، إلا أنها لا تزال عاجزة عن تحديد جميع حالات المفهوم وتجزئة المحتوى المدخل تلقائيًا. لسد هذه الثغرة، أطلقت شركة Meta أحدث إصداراتها، SAM 3. لا يتفوق هذا الإصدار الجديد على أداء الإصدارات السابقة في تجزئة الصور المرئية القابلة للتوجيه (PVS) فحسب، بل يرسي أيضًا معيارًا جديدًا لمهام تجزئة المفاهيم القابلة للتوجيه (PCS).
شاهد التقرير الكامل:https://go.hyper.ai/YfmLc
4. نجح فريق متعدد التخصصات من كارنيجي في التقاط آثار الحياة من 3.3 مليار سنة مضت باستخدام نموذج الغابة العشوائية القائم على 406 عينة.
قامت مؤسسة كارنيجي للعلوم في الولايات المتحدة، بالتعاون مع العديد من الجامعات حول العالم، بتشكيل فريق متعدد التخصصات لتحسين حل "دمج التكنولوجيا" لتحليل الغازات بالتحلل الحراري وقياس الطيف الكتلي والتعلم الآلي الخاضع للإشراف، والذي يمكنه التقاط آثار الحياة القديمة في الشظايا الجزيئية الفوضوية.
شاهد التقرير الكامل:https://go.hyper.ai/CNPMQ
5. ملخص الفعالية | جامعة بكين، وجامعة تسينغهوا، وشركة زيليز، وشركة مونبيت يناقشون المصادر المفتوحة، ويغطون مواضيع توليد الفيديو، والفهم البصري، وقواعد البيانات المتجهة، ولغات البرمجة الأصلية للذكاء الاصطناعي.
استضافت HyperAI، بصفتها إحدى الجهات المنظمة لمؤتمر COSCon'25، "منتدى التعاون بين الصناعة والبحث العلمي في مجال البرمجيات مفتوحة المصدر" في السابع من ديسمبر. هذه المقالة هي ملخص لأهم النقاط الواردة في العروض التقديمية المتعمقة التي قدمها أربعة متحدثين. سنشارككم لاحقًا العروض التقديمية كاملةً بصيغة فيديو، فتابعونا!
شاهد التقرير الكامل:https://go.hyper.ai/XrCEl
مقالات موسوعية شعبية
1. الذاكرة طويلة المدى ثنائية الاتجاه (Bi-LSTM)
2. الحقيقة الأساسية
3. التحكم في التخطيط (تحويل التخطيط إلى صورة)
4. الملاحة المجسدة
5. معدل الإطارات في الثانية (FPS)
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
الموعد النهائي لشهر يناير للمؤتمر الأعلى

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1800 مجموعة بيانات عامة
* يتضمن أكثر من 600 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* يدعم البحث عن أكثر من 600 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








