Command Palette
Search for a command to run...
تقنية إدخال وإخراج مبتكرة! أطلقت تينسنت هونيوان مرآة هونيوان وورلد، التي تُعيد بناء المحتوى ثلاثي الأبعاد بتقنيات متطورة؛ تُحلل الصورة الكاملة لمحتوى نتفليكس! تُساعد مجموعة بيانات كتالوج أفلام وبرامج نتفليكس في فهم اتجاهات الترفيه.

يُعدّ تعلّم الهندسة البصرية موضوعًا أساسيًا في مجال الرؤية الحاسوبية، ويُستخدم على نطاق واسع في الواقع المعزز، والتحكم بالروبوتات، والملاحة الذاتية. تعتمد الطرق التقليدية، مثل تقنية بنية الحركة (SfM) وتقنيات الاستريو متعددة المشاهد، عادةً على التحسين التكراري، مما يؤدي إلى تكاليف حسابية عالية.في السنوات الأخيرة، تحول المجال تدريجيًا نحو نماذج إعادة بناء الهندسة الشاملة القائمة على الشبكات العصبية التغذية الأمامية.
وعلى الرغم من الإنجازات الكبيرة، فإن الأساليب الحالية لا تزال تعاني من قيود واضحة في أبعاد المدخلات والمخرجات.من ناحية الإدخال، يفشل النموذج الحالي في الاستفادة من المعلومات المسبقة المتاحة بسهولة مثل بيانات الكاميرا، والوضع الأولي، وعمق المستشعر لأنه يعالج الصورة الخام فقط.يؤدي هذا إلى ضعف الأداء عند التعامل مع مشكلات مثل غموض المقياس، وعدم الاتساق بين وجهات النظر المتعددة، والمناطق التي تفتقر إلى الملمس. أما من ناحية المخرجات، فتقتصر الطرق الحالية في الغالب على مهمة هندسية واحدة أو عدد قليل من المهام (مثل تقدير العمق أو الوضع)، مما يُظهر تخصصًا عاليًا ونقصًا في التكامل. على الرغم من أن أبحاثًا مثل VGGT قد عززت توحيد المهام، إلا أن المهام الأساسية مثل تقدير الخط العمودي السطحي وتوليف وجهات النظر الجديدة لم تُدمج بعد في إطار عمل موحد.
وتثير القيود المذكورة أعلاه سؤالاً رئيسياً: هل من الممكن معالجة تحديات الإدخال والإخراج في وقت واحد ضمن إطار إعادة بناء ثلاثي الأبعاد عام من خلال دمج المعلومات السابقة المتنوعة بشكل فعال؟
وبناء على هذا،أطلق فريق Hunyuan التابع لشركة Tencent تطبيق HunyuanWorld-Mirror، وهو نموذج تغذية أمامية متكامل بالكامل لمهام التنبؤ بالهندسة ثلاثية الأبعاد المتنوعة، وهو مصمم للاستفادة من أي معرفة هندسية مسبقة متاحة لأداء مهام إعادة بناء ثلاثية الأبعاد العامة.يعتمد هذا النموذج على آلية جديدة متعددة الوسائط للإشارة المسبقة، تدمج بمرونة عدة مقدمات هندسية، بما في ذلك وضعية الكاميرا، والمعلمات الجوهرية، وخرائط العمق، مع توليد تمثيلات ثلاثية الأبعاد متعددة في آنٍ واحد: سحب نقاط كثيفة، وخرائط عمق متعددة المشاهد، ومعلمات الكاميرا، وخطوط عمودية على السطح، وتوزيعات غاوسية ثلاثية الأبعاد. تستفيد هذه البنية الموحدة من المعلومات المسبقة المتاحة لحل الغموض الهيكلي، وتوفر مخرجات ثلاثية الأبعاد متسقة هندسيًا في عملية تغذية أمامية واحدة.
يستفيد HunyuanWorld-Mirror من المسبقات المتاحة لتمكين إعادة البناء القوية في السيناريوهات الصعبة، ويضمن تصميمه متعدد المهام الاتساق الهندسي عبر المخرجات المختلفة.تم تحقيق أداء متطور عبر مجموعة واسعة من المعايير، بدءًا من الكاميرا وخريطة النقاط وتقدير العمق والسطح الطبيعي إلى توليف المنظور الجديد.
يضم موقع HyperAI الآن "HunyuanWorld-Mirror: نموذج جيل العالم ثلاثي الأبعاد"، لذا تعال وجربه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/Ptv69
نظرة عامة سريعة على تحديثات الموقع الرسمي لـ hyper.ai من 24 نوفمبر إلى 28 نوفمبر:
* مجموعات البيانات العامة عالية الجودة: 7
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 6
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
أهم المؤتمرات التي لها مواعيد نهائية في ديسمبر: 2
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
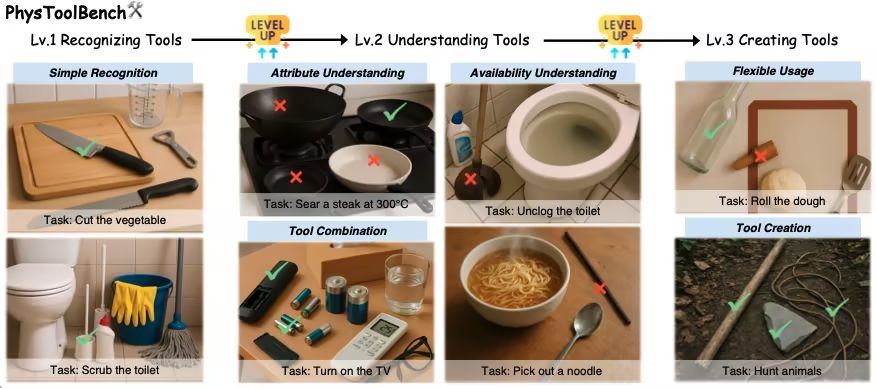
1. مجموعة بيانات مهام أداة الفيزياء PhysToolBench
PhysToolBench هي مجموعة بيانات للإجابة على الأسئلة اللغوية المرئية (VQA)، أصدرتها جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو) بالتعاون مع جامعة هونغ كونغ للعلوم والتكنولوجيا، وجامعة بكين للملاحة الجوية والفضائية، ومؤسسات أخرى. تهدف إلى تقييم قدرة نماذج اللغة الكبيرة متعددة الوسائط (MLLMs) على التعرف على الأدوات المادية وفهمها وإنشائها. تحتوي مجموعة البيانات على أكثر من 1000 زوج من الصور والنصوص، تغطي سيناريوهات متنوعة، بما في ذلك الحياة اليومية، والصناعة، والأنشطة الخارجية، والبيئات المهنية.
الاستخدام المباشر:https://go.hyper.ai/bP9Ad
2. مجموعة بيانات صور خلايا الدم من CytoData
مجموعة بيانات صور خلايا الدم "سايتوداتا" هي مجموعة بيانات لخلايا الدم مجهولة المصدر، نُشرت في مجلة "نيتشر" بواسطة فريق بحثي من جامعة كامبريدج، المملكة المتحدة. تحتوي المجموعة على 2904 مسحة دم من مستشفى أدينبروك في كامبريدج، بإجمالي 559,808 صورة لخلية واحدة. من بين هذه الصور، 4,996 صورة مُصنّفة بعشرة أنواع من خلايا الدم، بما في ذلك خلايا الدم الحمراء والحمضات.
الاستخدام المباشر:https://go.hyper.ai/uLXKt
3. MeshCoder: مجموعة بيانات الكود الثلاثي الأبعاد المنظمة
MeshCoder هي مجموعة بيانات متعددة الوسائط لتوليد أكواد قابلة للتعديل من سحابات النقاط ثلاثية الأبعاد، أصدرها مختبر الذكاء الاصطناعي في شنغهاي بالتعاون مع جامعة تسينغهوا ومعهد هاربين للتكنولوجيا (شنتشن) ومؤسسات أخرى. تهدف إلى تعزيز تطوير نماذج لغوية واسعة النطاق في تحليل المشاهد ثلاثية الأبعاد، وفهم الهياكل، وإعادة بناء الأشكال الهندسية القابلة للبرمجة.
الاستخدام المباشر:https://go.hyper.ai/x3zvv
4. مجموعة بيانات كتالوج الأفلام والبرامج التلفزيونية على Netflix
مجموعة بيانات كتالوج الأفلام والبرامج التلفزيونية من نتفليكس هي مجموعة بيانات شاملة تغطي أنواعًا مختلفة من محتوى الأفلام والبرامج التلفزيونية من دول متعددة حول العالم. تهدف هذه المجموعة إلى عرض التوزيع العام للمحتوى على منصة نتفليكس، وتوفير بيانات تدعم البحث في اتجاهات الترفيه، وتفضيلات الجمهور، واستراتيجيات المحتوى. تتضمن هذه المجموعة بيانات عن الأفلام والمسلسلات التلفزيونية المتوفرة حاليًا على نتفليكس. يمثل كل رقم عنوانًا، ويتضمن معلومات رئيسية مثل العنوان، ونوع المحتوى (فيلم أو مسلسل)، والمخرج.
الاستخدام المباشر:https://go.hyper.ai/8gzcZ
5. مجموعة بيانات تفاعل الإنسان مع الكائن في المشهد ثلاثي الأبعاد InteractMove
InteractMove هي مجموعة بيانات لتوليد تفاعلات بين الإنسان والأشياء في مشاهد ثلاثية الأبعاد، أصدرها معهد علوم وتكنولوجيا الحاسوب بجامعة بكين ومعهد بكين للعلوم والتكنولوجيا الإلكترونية. تهدف هذه المجموعة إلى دعم وتعزيز البحث في مجال النمذجة التفاعلية النصية القائمة على التحكم للأشياء المتحركة. تغطي مجموعة البيانات أنواعًا متعددة من الأشياء المتحركة ومشاهد ممسوحة ضوئيًا من العالم الحقيقي، وتوفر تسلسلات تفاعل بين الإنسان والأشياء تتوافق تمامًا مع المشهد.
الاستخدام المباشر:https://go.hyper.ai/uFrPd
6. مجموعة بيانات تدريب تشغيل واجهة GroundCUA
GroundCUA هي مجموعة بيانات لواجهات المستخدم (UI) في العالم الحقيقي، أصدرها معهد ميلا كيبيك للذكاء الاصطناعي بالتعاون مع جامعة ماكجيل وجامعة مونتريال ومؤسسات أخرى. تهدف هذه المجموعة إلى دعم الأبحاث المتعلقة بالعوامل الذكية متعددة الوسائط القادرة على التفاعل مع أجهزة الكمبيوتر. تعتمد مجموعة البيانات على عروض توضيحية بشرية على مستوى الخبراء، وتوفر أكثر من 3.56 مليون تعليق توضيحي على مستوى العناصر، مُتحقق منها يدويًا.
الاستخدام المباشر:https://go.hyper.ai/5bDrX
7. مجموعة بيانات استنساخ الكاميرا متعددة العرض
"استنساخ الكاميرا"، الذي أصدرته جامعة هونغ كونغ بالتعاون مع جامعة تشجيانغ، وشركة كوايشو للتكنولوجيا، ومؤسسات أخرى، هو مجموعة بيانات فيديو تركيبية واسعة النطاق تعتمد على معالجة الصور باستخدام محرك Unreal Engine 5. يهدف إلى دعم تعلم استنساخ الكاميرا، الذي يكرر حركة كاميرا فيديو مرجعي مع الحفاظ على محتوى المشهد دون تغيير، محققًا "إعادة إنتاج المحتوى + مطابقة حركة الكاميرا".
الاستخدام المباشر:https://go.hyper.ai/US4nY
دروس تعليمية عامة مختارة
1. البرنامج التعليمي الرسمي لـ PyTorch: تنفيذ التعلم العميق باستخدام PyTorch
الهدف من هذا البرنامج التعليمي هو فهم كيفية استخدام الموتر وبناء الشبكات العصبية في PyTorch، وتدريب شبكة عصبية صغيرة لتصنيف الصور.
تشغيل عبر الإنترنت:https://go.hyper.ai/Fb2c6
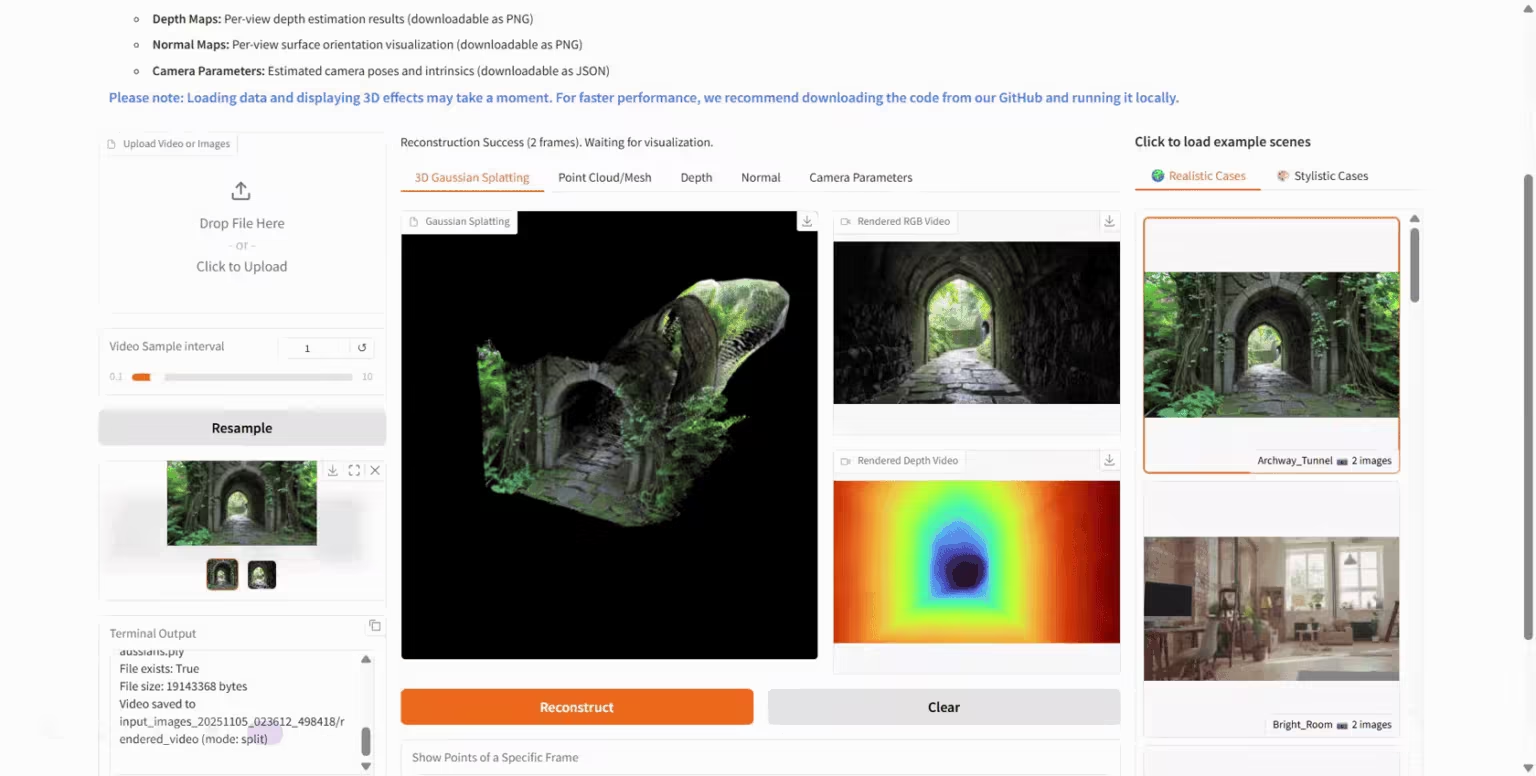
٢. مرآة هونيوان العالمية: نموذج جيل العالم ثلاثي الأبعاد
مرآة هونيوان العالمية (HunyuanWorld-Mirror) هي نموذج مفتوح المصدر لتوليد العالم ثلاثي الأبعاد، أصدره فريق هونيوان التابع لشركة تينسنت. يدعم هذا النموذج طرق إدخال متعددة، بما في ذلك الصور ومقاطع الفيديو متعددة المشاهد، ويُمكنه إخراج نتائج تنبؤ هندسية ثلاثية الأبعاد متنوعة، مثل السحب النقطية وخرائط العمق ومعلمات الكاميرا. يعتمد النموذج على بنية تغذية أمامية خالصة، ويمكن نشره على بطاقة رسومات واحدة، ويعالج من 8 إلى 32 مدخل عرض محليًا في ثانية واحدة فقط، محققًا بذلك استدلالًا من المستوى الثاني.
تشغيل عبر الإنترنت:https://go.hyper.ai/Ptv69
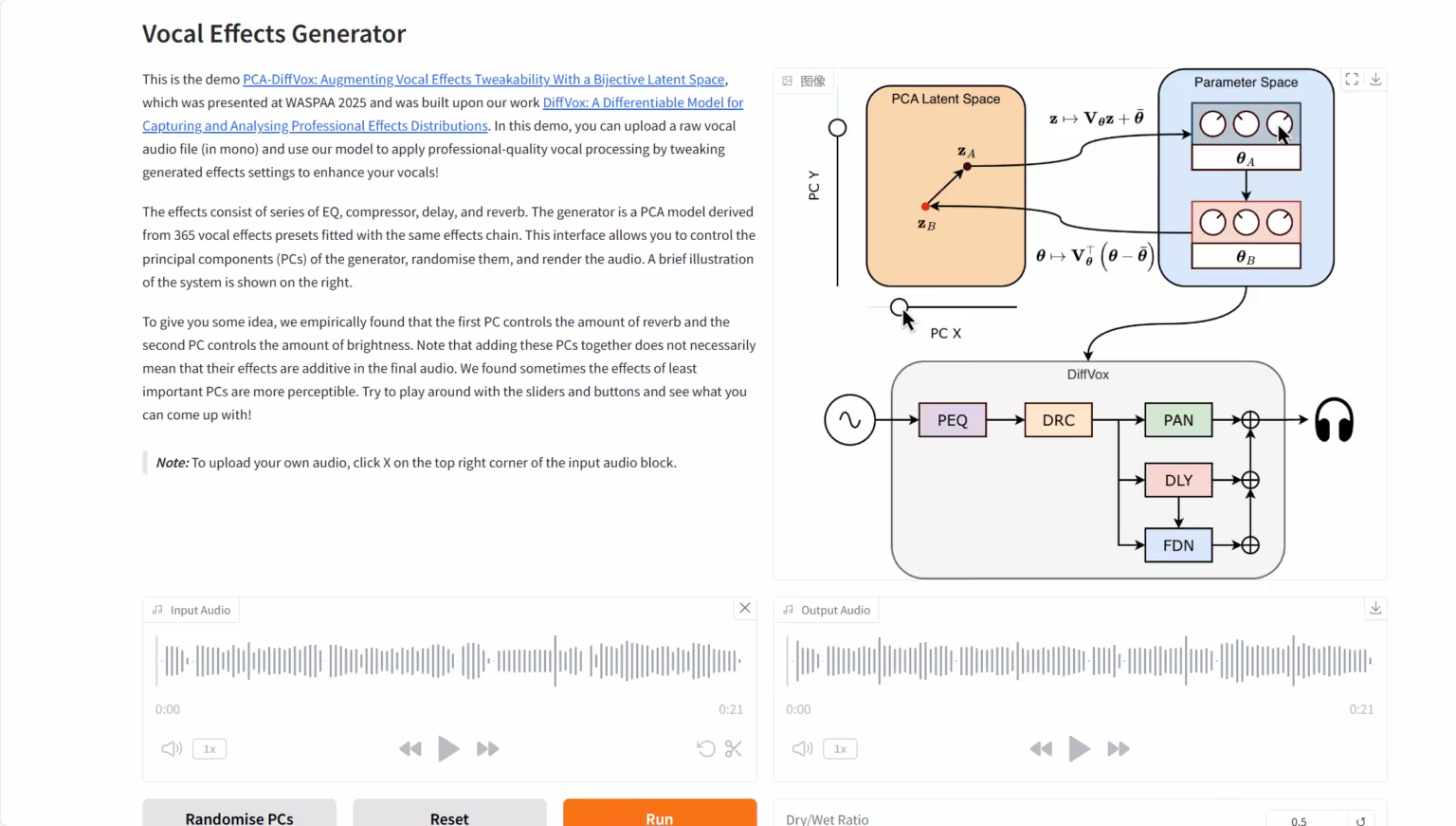
3. DiffVox: نموذج التمييز الصوتي
أُطلق مشروع DiffVox بالتعاون بين سوني للذكاء الاصطناعي ومجموعة سوني وفريق بحثي من جامعة كوين ماري في لندن. تكمن الميزة الأساسية لهذا النموذج في استخدامه أساليب متقدمة لتحسين زمن الاستدلال، وإدخاله المبتكر لقيود غاوسية مسبقة، مما يُمكّنه من تحويل تسجيل صوتي بشري خام بذكاء إلى صوت عالي الجودة، قريب من مستوى الصوت المرجعي المستهدف، ويُلبي معايير المزج الاحترافية من حيث المعلمات.
تشغيل عبر الإنترنت:https://go.hyper.ai/Y19Wv
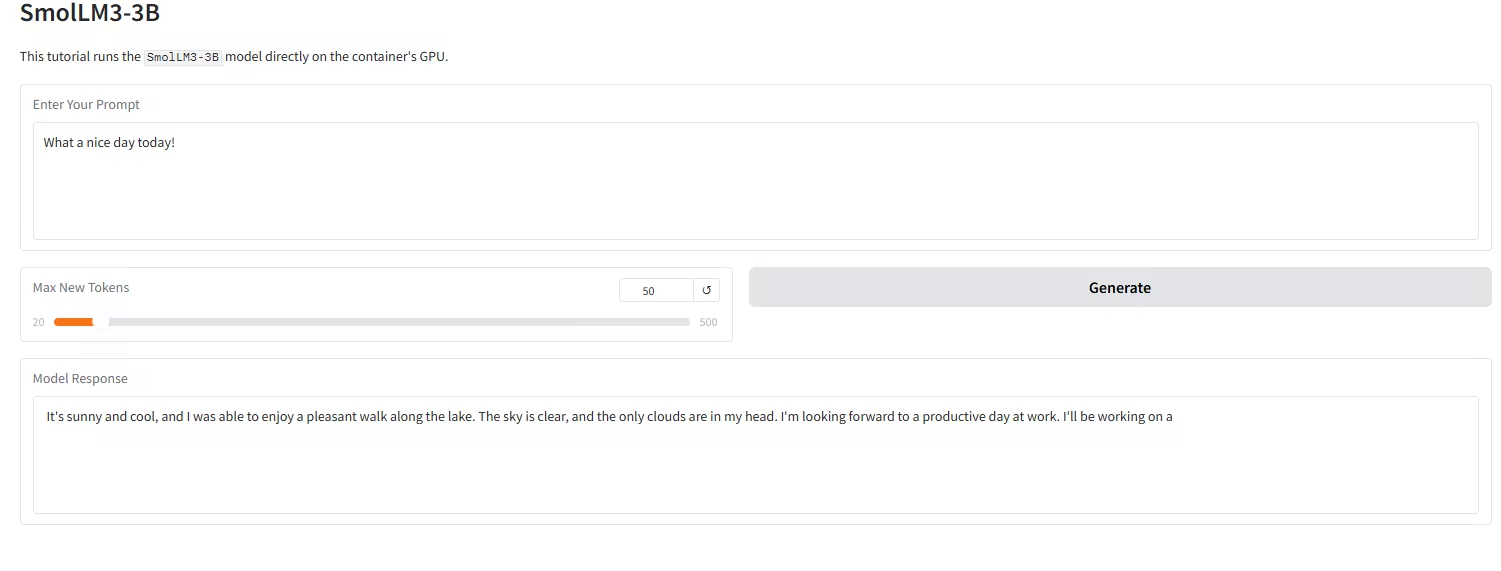
4. نشر نموذج SmolLM3-3B بنقرة واحدة
SmolLM3-3B، الذي أصدره فريق Hugging Face TB (Transformer Big)، يُعَدّ "سقف الأداء المتميز". إنه نموذج لغوي ثوري مفتوح المصدر، يضم 3 مليارات معلمة، ويهدف إلى تجاوز حدود أداء النماذج الصغيرة في حجم 3B صغير.
تشغيل عبر الإنترنت:https://go.hyper.ai/wZ48d
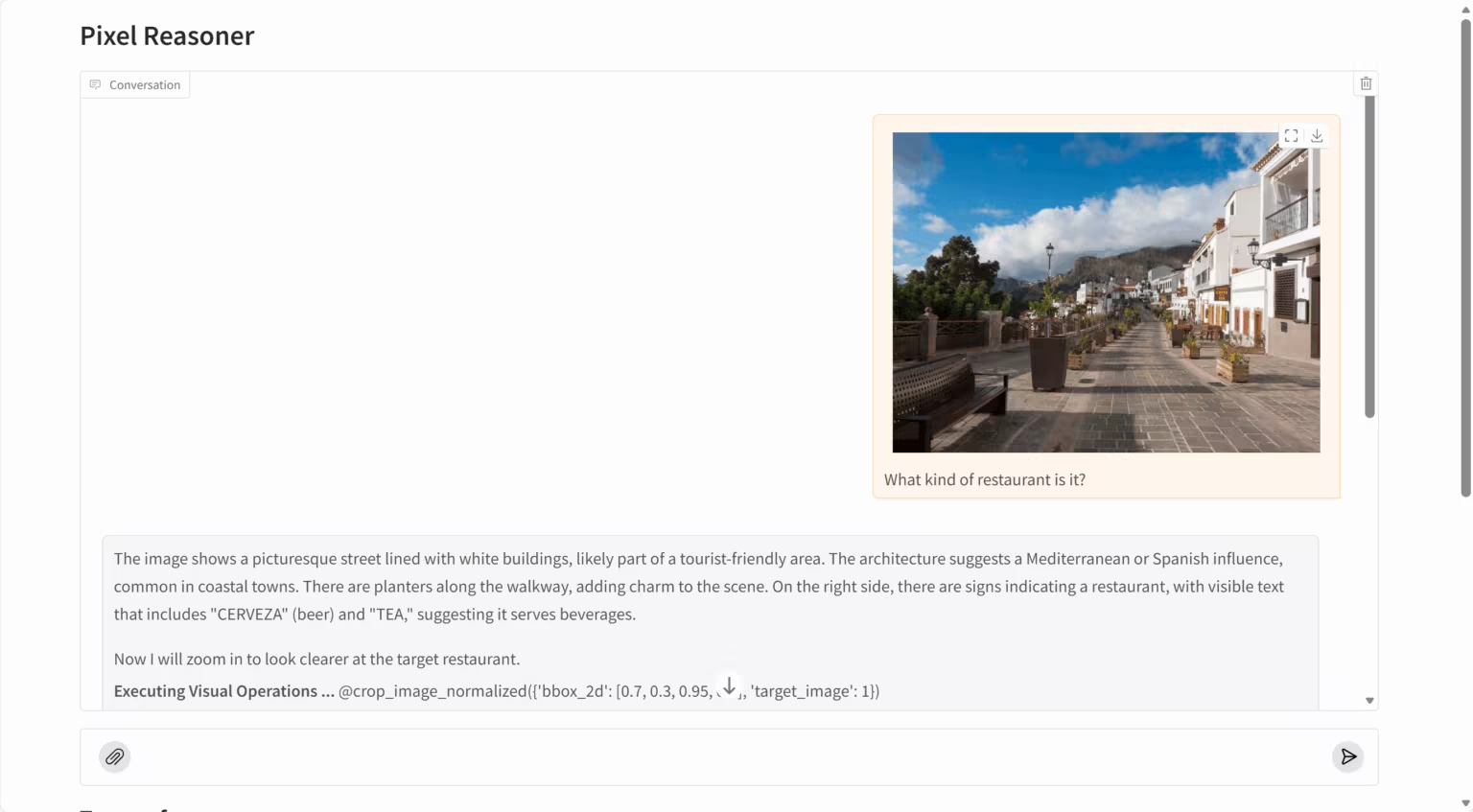
5. PixelReasoner-RL: نموذج الاستدلال البصري على مستوى البكسل
PixelReasoner-RL-v1 هو نموذج لغة بصرية رائد، أصدره مختبر TIGER للذكاء الاصطناعي. يعتمد المشروع على بنية Qwen2.5-VL، ويستخدم أسلوبًا مبتكرًا لتدريب التعلم التعزيزي قائمًا على الفضول، وذلك للتغلب على قيود نماذج اللغة البصرية التقليدية التي تعتمد كليًا على التفكير النصي. يستطيع النموذج إجراء التفكير مباشرةً في مساحة البكسل، داعمًا العمليات البصرية مثل التدرج واختيار الإطارات، مما يُحسّن بشكل كبير قدرته على فهم تفاصيل الصورة والعلاقات المكانية ومحتوى الفيديو.
تشغيل عبر الإنترنت:https://go.hyper.ai/t1rdr
6. Krea-realtime-video: نموذج توليد الفيديو في الوقت الفعلي
Krea Realtime 14B هو نموذج لتوليد الفيديو في الوقت الفعلي، يحتوي على 14 مليار معلمة، أصدره فريق Krea. يتيح هذا النموذج توليد مقاطع فيديو طويلة في الوقت الفعلي، وهو أحد أكبر نماذج توليد الفيديو في الوقت الفعلي المتاحة للجمهور. يعتمد هذا النموذج على نموذج Wan 2.1 14B لتحويل النص إلى فيديو، ويستخدم تدريب التقطير القسري لتحويل نموذج انتشار الفيديو التقليدي إلى بنية انحدار ذاتي، مما يحقق تجربة توليد فيديو حقيقية في الوقت الفعلي.
تشغيل عبر الإنترنت:https://go.hyper.ai/GS7oW

توصيات الورقة البحثية لهذا الأسبوع
1. الذاكرة الوكيلية العامة من خلال البحث العميق
تقترح هذه الورقة إطار عمل مبتكرًا يُسمى ذاكرة الوكالة العامة (GAM). يتبع هذا الإطار مبدأ "التشغيل الفوري" (JIT): فهو يحتفظ فقط بذاكرات بسيطة وعملية دون اتصال بالإنترنت، مع التركيز على بناء سياقات مُحسّنة لعملائه أثناء التشغيل. تُظهر الدراسات التجريبية أن ذاكرة الوكالة العامة تُحقق تحسينات كبيرة في الأداء في مختلف سيناريوهات إكمال المهام القائمة على الذاكرة مقارنةً بأنظمة الذاكرة الحالية.
رابط الورقة:https://go.hyper.ai/sA1RN
2. ROOT: مُحسِّن متعامد قوي لتدريب الشبكات العصبية
تقترح هذه الورقة البحثية مُحسِّن ROOT، وهو مُحسِّن متعامد قوي، يُعزز استقرار التدريب بشكل كبير من خلال آلية متانة مزدوجة. تُظهر نتائج التجارب الشاملة أن ROOT يُظهر متانة مُحسّنة بشكل كبير في البيئات الصاخبة وسيناريوهات التحسين غير المحدبة. وبالمقارنة مع المُحسِّنات القائمة على Muon وAdam، فهو لا يتقارب بشكل أسرع فحسب، بل يُحقق أيضًا أداءً نهائيًا مُتفوقًا.
رابط الورقة:https://go.hyper.ai/gv0x2
3. GigaEvo: إطار عمل مفتوح المصدر لتحسين الأداء، مدعوم بـ LLMs وخوارزميات التطور
تقترح هذه الورقة البحثية GigaEvo، وهو إطار عمل مفتوح المصدر وقابل للتطوير، مصمم لدعم الباحثين في إجراء البحوث والتجارب على أساليب الحوسبة التطورية الهجينة LLM المستوحاة من AlphaEvolve. يوفر نظام GigaEvo تطبيقات معيارية لعدة مكونات أساسية: خوارزمية MAP-Elites للتنوع النوعي، وخط أنابيب تقييم غير متزامن قائم على الرسوم البيانية اللادورية الموجهة (DAGs)، ومشغل طفرة مدفوع بـ LLM مع قدرات توليدية ثاقبة، وآلية تتبع نسب ثنائية الاتجاه، مع دعم استراتيجيات تطورية مرنة متعددة الجزر.
رابط الورقة:https://go.hyper.ai/jN3Q1
4. سام 3: تقسيم أي شيء إلى مفاهيم
تقترح هذه الورقة البحثية نموذج SAM 3 (Segment Anything Model) وهو نموذج موحد قادر على اكتشاف الكائنات وتقسيمها وتتبعها في الصور والفيديوهات بناءً على توجيهات مفاهيمية. يحقق SAM 3 ضعف دقة الأنظمة الحالية في مهام PCS للصور والفيديو، ويحسّن أداء الجيل السابق من نماذج SAM في مهام التجزئة المرئية. SAM 3 الآن مفتوح المصدر، كما تم إصدار معيار جديد لتجزئة المفاهيم القابلة للتوجيه، وهو Segment Anything with Concepts (SA-Co).
رابط الورقة:https://go.hyper.ai/KN3g7
5. OpenMMReasoner: توسيع آفاق التفكير المتعدد الوسائط من خلال وصفة عامة ومفتوحة
تُقدّم هذه الورقة البحثية OpenMMReasoner، وهو نظام تدريب استدلالي متعدد الوسائط شفاف بالكامل من مرحلتين، يشمل الضبط الدقيق المُشرف (SFT) والتعلم التعزيزي (RL). في مرحلة الضبط الدقيق المُشرف (SFT)، أنشأ الباحثون مجموعة بيانات بداية باردة تحتوي على 874,000 عينة، واستخدموا آلية تحقق دقيقة خطوة بخطوة لإرساء أساس متين لقدرات الاستدلال. أما مرحلة التعلم التعزيزي اللاحقة، فتستخدم مجموعة بيانات من 74,000 عينة تغطي مجالات متعددة لتعزيز هذه القدرات وتثبيتها، مما يحقق عملية تعلم أكثر متانة وكفاءة.
رابط الورقة:https://go.hyper.ai/OfXKY
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
١. طُوِّر بنجاح أول نموذج فلكي متعدد الوسائط، AION-1! نجحت جامعة كاليفورنيا، بيركلي، وباحثون آخرون في بناء إطار عمل معمم للذكاء الاصطناعي الفلكي متعدد الوسائط، يعتمد على التدريب المسبق على ٢٠٠ مليون هدف فلكي.
تعاونت فرق من أكثر من عشر مؤسسات بحثية حول العالم، منها جامعة كاليفورنيا، بيركلي، وجامعة كامبريدج، وجامعة أكسفورد، لإطلاق AION-1، أول عائلة نماذج أساسية متعددة الوسائط واسعة النطاق في علم الفلك. من خلال شبكة أساسية موحدة للاندماج المبكر، يدمج هذا النموذج وينمذجة معلومات رصدية غير متجانسة، مثل الصور والأطياف وبيانات كتالوج النجوم. لا يقتصر أداء هذا النموذج على الأداء الجيد في سيناريوهات الإطلاق، بل إن دقته في الكشف الخطي قادرة على منافسة، بل وتجاوز، النماذج المُدربة خصيصًا لمهام محددة.
شاهد التقرير الكامل:https://go.hyper.ai/2zA0f
2. يتمتع نموذج توليد الفيديو مفتوح المصدر من Meituan، LongCat-Video، بثلاث قدرات رئيسية: توليد الفيديو المستند إلى النص، وتوليد الفيديو المستند إلى الصور، واستمرار الفيديو، وهو مماثل للنماذج مفتوحة المصدر ومغلقة المصدر من الدرجة الأولى.
أطلقت شركة ميتوان أحدث نماذجها لتوليد الفيديو، LongCat-Video، مفتوح المصدر. يهدف هذا النموذج إلى التعامل مع مهام توليد فيديو متنوعة من خلال بنية موحدة، بما في ذلك تحويل النص إلى فيديو، وتحويل الصورة إلى فيديو، واستمرارية الفيديو. واستنادًا إلى أدائه المتميز في مهام توليد الفيديو بشكل عام، يعتبر فريق البحث LongCat-Video خطوةً فعّالة نحو بناء "نموذج عالمي" حقيقي.
شاهد التقرير الكامل:https://go.hyper.ai/b6pzF
3. استخدام مجاني لوحدة المعالجة المركزية / 30 ساعة من رصيد استخدام وحدة معالجة الرسومات / 70 جيجابايت من مساحة التخزين الضخمة، تم إطلاق HyperAI Pro رسميًا!
قامت HyperAI بتنسيق مئات من دروس تعلم الآلة وجمعها في Jupyter Notebooks، مما يتيح للمهندسين المبتدئين والخبراء على حد سواء الوصول بسهولة إلى مشاريع مفتوحة المصدر عالية الجودة أو إنشاء نماذج جديدة كليًا ونشرها. توفر HyperAI قوة حوسبة مستقرة لمساعدة مشاريع الذكاء الاصطناعي على الانتقال من الإلهام الأولي إلى النشر السريع. ولتلبية احتياجات مستخدميها بشكل أفضل وتوفير خيارات فوترة أكثر مرونة وبأسعار معقولة لقوة الحوسبة، أطلقت HyperAI رسميًا نظام عضوية HyperAI Pro.
شاهد التقرير الكامل:https://go.hyper.ai/Oi7d3
4. طورت جامعة كامبريدج تصنيفًا لصور خلايا الدم؛ ويساعد نموذج الانتشار في الكشف عن سرطان الدم، متجاوزًا قدرات الخبراء السريريين.
اقترح فريق بحثي من جامعة كامبريدج بالمملكة المتحدة تقنية CytoDiffusion، وهي طريقة لتصنيف صور خلايا الدم تعتمد على نموذج الانتشار. تُحاكي هذه الطريقة بدقة التوزيع المورفولوجي لخلايا الدم لضمان تصنيف دقيق، مع امتلاكها قدرات قوية على كشف الشذوذ، ومقاومة لتغيرات التوزيع، وسهولة في التفسير، وكفاءة عالية في البيانات، وقدرة على تحديد كمية عدم اليقين تفوق قدرات الخبراء السريريين.
شاهد التقرير الكامل:https://go.hyper.ai/QSCmq
5. مدد الرئيس التنفيذي لشركة Broadcom البالغ من العمر 72 عامًا، والذي بنى شركته على عمليات الاستحواذ، عقده حتى عام 2030، بهدف زيادة إيرادات الشركة من الذكاء الاصطناعي إلى 120 مليار دولار.
بالنظر إلى سيرة هوك تان الذاتية، يبدو أن "عمليات الدمج والاستحواذ" موضوعٌ لا مفر منه. إلا أن النظر إليه من منظور استثماري تجاري حصرًا يُعدّ ضيقًا وتبسيطيًا للغاية. فكل خطوة من خطواته، تتجاوز حسابات الأرباح والإيرادات، تُسهم تدريجيًا في رفع مكانة شركته إلى مركزٍ أساسي؛ كما أن توقعات الاتجاهات الأساسية أكثر أهمية.
شاهد التقرير الكامل:https://go.hyper.ai/6lPG5
مقالات موسوعية شعبية
1. دال-إي
2. الشبكات الفائقة
3. جبهة باريتو
4. الذاكرة طويلة المدى ثنائية الاتجاه (Bi-LSTM)
5. اندماج الرتب المتبادلة
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
أفضل مؤتمر مع الموعد النهائي في ديسمبر

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1800 مجموعة بيانات عامة
* يتضمن أكثر من 600 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* يدعم البحث عن أكثر من 600 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








