Command Palette
Search for a command to run...
LightOnOCR-2-1B: تقنية التعرف الضوئي على الأحرف عالية الدقة من البداية إلى النهاية تعتمد على تدريب RLVR؛ صور Google Streetview الوطنية للشوارع: مكتبة صور بانورامية مفتوحة المصدر تعتمد على تقنية رسم الخرائط الجغرافية ذات المستوى العالمي.

تعتمد تقنية التعرف الضوئي على الأحرف حاليًا على مسار معقد ومتسلسل: أولاً، يتم اكتشاف مناطق النص، ثم يتم إجراء التعرف، وأخيرًا، يتم تنفيذ المعالجة اللاحقة.يُعدّ هذا النموذج معقداً وهشاً عند التعامل مع المستندات ذات التنسيقات المعقدة والمتنوعة. فأي خطأ في أي خطوة قد يؤدي إلى نتائج سيئة، ويصعب تحسينه من البداية إلى النهاية، مما ينتج عنه تكاليف صيانة وتعديل مرتفعة.
وفي هذا السياق،أصدرت شركة LightOn طراز LightOnOCR-2-1B كمصدر مفتوح.يحقق هذا النموذج المتكامل للرؤية واللغة، الذي لا يتجاوز عدد معلماته مليارًا، أداءً متميزًا على معيار OlmOCR-Bench المرجعي، متجاوزًا بذلك أفضل نموذج سابق ذي تسعة مليارات معلمة، مع تقليل حجمه تسعة أضعاف وزيادة سرعة الاستدلال عدة أضعاف. يستخدم LightOnOCR-2-1B نموذجًا موحدًا لإنشاء مربعات إحاطة للنصوص والصور بشكل منظم ومرتب مباشرةً من وحدات البكسل. ومن خلال دمج مكونات مُدرَّبة مسبقًا، وبيانات مُستخلصة عالية الجودة، واستراتيجيات مثل RLVR، يُبسِّط هذا النموذج العملية ويُحسِّن بشكل كبير كفاءة معالجة المستندات المعقدة.
يتوفر الآن نموذج التعرف الضوئي على الأحرف "LightOnOCR-2-1B خفيف الوزن وعالي الأداء" على موقع HyperAI الإلكتروني. جرّبه الآن!
الاستخدام عبر الإنترنت:https://go.hyper.ai/8zlVw
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 2 فبراير إلى 6 فبراير:
* مجموعات البيانات العامة عالية الجودة: 6
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 9
* الأوراق البحثية الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 4 مقالات
* إدخالات الموسوعة الشعبية: 5
أهم المؤتمرات التي تنتهي مواعيدها في فبراير: 4
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات RubricHub متعددة المجالات للمهام التوليدية
RubricHub عبارة عن مجموعة بيانات واسعة النطاق ومتعددة المجالات لمهام توليدية، تم إصدارها بالاشتراك بين شركة Li Auto وجامعة تشجيانغ. توفر هذه المجموعة إشرافًا عالي الجودة قائمًا على معايير التقييم للمهام التوليدية المفتوحة. تم بناء مجموعة البيانات باستخدام إطار عمل آلي لتوليد معايير التقييم من العام إلى الخاص، يدمج استراتيجيات مثل التركيب الموجه بالمبادئ، وتجميع النماذج المتعددة، وتطوير الصعوبة لإنتاج معايير تقييم شاملة ودقيقة للغاية.
الاستخدام المباشر:https://go.hyper.ai/g3Htm
2. مجموعة بيانات الشخصيات الاصطناعية البرازيلية Nemotron-Personas-Brazil
Nemotron-Personas-Brazil هي مجموعة بيانات للشخصيات الاصطناعية خاصة بالبرازيل، أصدرتها شركة NVIDIA بالتعاون مع WideLabs. وتهدف إلى إبراز تنوع وثراء سكان البرازيل، لتعكس بشكل أكثر شمولاً التوزيع السكاني المحتمل متعدد الأبعاد، بما في ذلك التنوع الإقليمي، والخلفية العرقية، ومستوى التعليم، والتوزيع المهني.
الاستخدام المباشر:https://go.hyper.ai/7xKKH
3. معيار تقييم التعلم السياقي CL-bench
تُعدّ CL-bench مجموعة بيانات مرجعية لتقييم قدرات نماذج اللغة الكبيرة على تعلّم السياق، وقد أُصدرت بالاشتراك بين فريق Tencent Hunyuan وجامعة فودان. وتهدف إلى اختبار ما إذا كان النموذج قادرًا على تعلّم قواعد أو مفاهيم أو معارف جديدة من سياق مُحدد دون الاعتماد على معارف مُدرّبة مسبقًا، وتطبيقها على مهام لاحقة.
الاستخدام المباشر:https://go.hyper.ai/w2MG3
4. مجموعة بيانات إنشاء فيديو RoVid-X Robot
RoVid-X هي مجموعة بيانات لتوليد فيديوهات الروبوتات، أصدرتها جامعة بكين بالتعاون مع شركة ByteDance Seed. وتهدف إلى معالجة التحديات الفيزيائية التي تواجهها نماذج توليد الفيديوهات عند إنتاج فيديوهات الروبوتات.
الاستخدام المباشر:https://go.hyper.ai/4P9hI
5. مجموعة بيانات صور جوجل ستريت فيو الوطنية
جوجل ستريت فيو عبارة عن مجموعة بيانات لصور الشوارع تغطي عدة دول. تتضمن أسماء ملفات الصور تاريخ الإنشاء واسم الخريطة، ويتم وضع صور كل دولة في مجلداتها الخاصة.
الاستخدام المباشر:https://go.hyper.ai/tZRlI

6. مجموعة بيانات تقييم قدرات التخطيط طويل الأجل من DeepPlanning
DeepPlanning هي مجموعة بيانات أصدرها فريق Qwen لتقييم قدرات التخطيط لدى الوكلاء الأذكياء، بهدف تقييم قدراتهم على التفكير واتخاذ القرارات في مهام التخطيط المعقدة وطويلة الأجل.
الاستخدام المباشر:https://go.hyper.ai/yywsb
دروس تعليمية عامة مختارة
1. نشر Qwen-Image-Edit باستخدام vLLM-Omni
Qwen-Image-Edit هو برنامج متعدد الوظائف لتحرير الصور، طوّره فريق تونغي تشيان وين التابع لشركة علي بابا. يتميز هذا البرنامج بقدرات تحرير دلالية وبصرية، مما يتيح إجراء تعديلات بصرية بسيطة كإضافة العناصر أو إزالتها أو تعديلها، بالإضافة إلى تعديلات دلالية بصرية متقدمة كإنشاء عناوين IP وتدوير العناصر ونقل الأنماط. يدعم البرنامج التحرير الدقيق للنصوص الصينية والإنجليزية، مما يسمح بتعديل محتوى النصوص داخل الصور مباشرةً مع الحفاظ على الخط والحجم والنمط الأصليين.
تشغيل عبر الإنترنت:https://go.hyper.ai/DowYs
2. نشر Qwen-Image-2512 باستخدام vLLM-Omni
يُعدّ Qwen-Image-2512 النموذج الأساسي لتحويل النصوص إلى صور ضمن سلسلة Qwen-Image. وبالمقارنة مع الإصدارات السابقة، خضع Qwen-Image-2512 لتحسينات منهجية في عدة جوانب رئيسية، مع التركيز على تعزيز واقعية الصور المُولّدة وسهولة استخدامها. وقد تحسّنت بشكل ملحوظ طبيعية توليد الصور الشخصية، حيث باتت بنية الوجه وملمس البشرة وعلاقات الإضاءة تُحاكي تأثيرات التصوير الفوتوغرافي الواقعية بشكل أدق. وفي المشاهد الطبيعية، يُمكن للنموذج توليد تفاصيل أكثر دقة لتضاريس الأرض، وتفاصيل الغطاء النباتي، ومعلومات عالية التردد مثل فراء الحيوانات. وفي الوقت نفسه، تم تحسين قدراته في توليد النصوص والطباعة، مما يُتيح عرضًا أكثر استقرارًا للنصوص المقروءة والتصاميم المعقدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/Xk93p
3. الخطوة 3-VL-10B: الفهم البصري متعدد الوسائط والحوار الرسومي
STEP3-VL-10B هو نموذج لغة بصرية مفتوح المصدر، طوّره فريق Stepping Star، وهو مصمم خصيصًا لفهم الوسائط المتعددة ومهام الاستدلال المعقدة. يهدف هذا النموذج إلى إعادة تعريف التوازن بين الكفاءة، والقدرة على الاستدلال، وجودة الفهم البصري ضمن نطاق محدود من المعلمات يبلغ 10 مليارات (10B). وقد أظهر أداءً فائقًا في الإدراك البصري، والاستدلال المعقد، ومواءمة التعليمات البشرية، متفوقًا باستمرار على نماذج ذات نطاق مماثل في العديد من الاختبارات المعيارية، ومقاربًا لنماذج ذات نطاقات معلمات أكبر بعشرة إلى عشرين ضعفًا في بعض المهام.
تشغيل عبر الإنترنت:https://go.hyper.ai/ZvOV0
4.vLLM+Open WebUI نشر GLM-4.7-Flash
GLM-4.7-Flash هو نموذج استدلال MoE خفيف الوزن أطلقته شركة Zhipu AI، مصمم لتحقيق التوازن بين الأداء العالي والإنتاجية العالية. يدعم النموذج سلاسل التفكير، واستدعاءات الأدوات، وقدرات الوكلاء بشكل أصلي. يعتمد النموذج بنية خبير هجينة ويستخدم آليات التنشيط المتفرقة لتقليل العبء الحسابي للاستدلال الواحد بشكل كبير مع الحفاظ على أداء النماذج الكبيرة.
تشغيل عبر الإنترنت:https://go.hyper.ai/bIopo

5. جهاز LightOnOCR-2-1B خفيف الوزن وعالي الأداء، نموذج OCR شامل
يُعدّ LightOnOCR-2-1B أحدث جيل من نماذج التعرّف البصري على اللغة (OCR) الشاملة التي أطلقتها شركة LightOn AI. وباعتباره الإصدار الرائد في سلسلة LightOnOCR، فهو يوحّد فهم المستندات وتوليد النصوص في بنية مدمجة، ويضم مليار مُعامل، ويمكن تشغيله على وحدات معالجة الرسومات (GPU) المُخصصة للمستهلكين (يتطلب حوالي 6 جيجابايت من ذاكرة الوصول العشوائي للفيديو VRAM). يستخدم هذا النموذج بنية Transformer للغة المرئية، ويُدمج تقنية تدريب RLVR، مما يُحقق دقة تعرّف عالية للغاية وسرعة استدلال فائقة. وهو مُصمم خصيصًا للتطبيقات التي تتطلب معالجة المستندات المُعقدة، والنصوص المكتوبة بخط اليد، وصيغ LaTeX.
تشغيل عبر الإنترنت:https://go.hyper.ai/8zlVw
6. نشر vLLM+Open WebUI لـ LFM2.5-1.2B-Thinking
يُعدّ LFM2.5-1.2B-Thinking أحدث نموذج معماري هجين مُحسّن للحوسبة الطرفية، أطلقته شركة Liquid AI. وباعتباره إصدارًا من سلسلة LFM2.5 مُحسّنًا خصيصًا للاستدلال المنطقي، فهو يجمع بين معالجة التسلسلات الطويلة وقدرات الاستدلال الفعّالة في بنية مُدمجة. يحتوي النموذج على 1.2 مليار مُعامل، ويمكن تشغيله بسلاسة على وحدات معالجة الرسومات (GPUs) المُخصصة للمستهلكين، وحتى على أجهزة الحوسبة الطرفية. يستخدم النموذج بنية هجينة مبتكرة، مما يُحقق كفاءة عالية في استخدام الذاكرة وإنتاجية فائقة، وهو مُصمم للسيناريوهات التي تتطلب استدلالًا فوريًا على الأجهزة دون المساس بالذكاء.
تشغيل عبر الإنترنت:https://go.hyper.ai/PACIr
7. نظام TurboDiffusion: نظام توليد الفيديو المعتمد على الصور والنصوص
TurboDiffusion هو نظام عالي الكفاءة لتوليد انتشار الفيديو، طوّره فريق من جامعة تسينغهوا. يعتمد هذا المشروع على بنية 2.1، ويستخدم تقنية التقطير عالي الرتبة لمعالجة مشكلات بطء سرعة الاستدلال واستهلاك موارد الحوسبة العالية في نماذج الفيديو واسعة النطاق، مما يحقق توليد فيديو عالي الجودة بأقل عدد من الخطوات.
تشغيل عبر الإنترنت:https://go.hyper.ai/YjCht
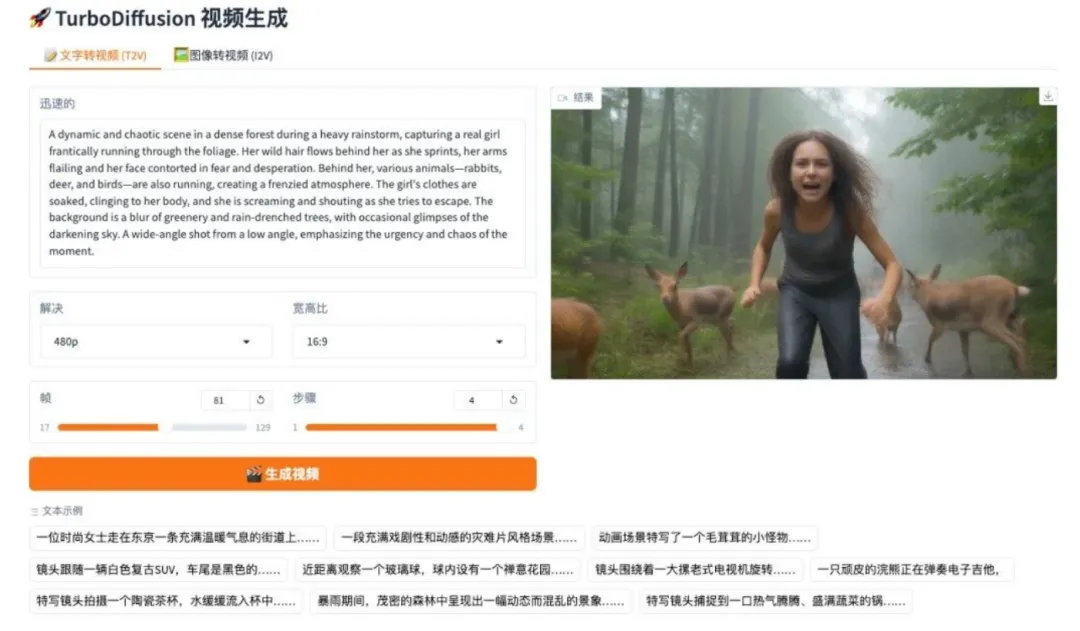
8. DeepSeek-OCR 2 التدفق السببي المرئي
يُعدّ DeepSeek-OCR 2 الجيل الثاني من نماذج التعرّف الضوئي على الأحرف (OCR) التي أصدرها فريق DeepSeek. وبفضل بنية DeepEncoder V2، يُحقق هذا النموذج نقلة نوعية من المسح الثابت إلى الاستدلال الدلالي. يستخدم النموذج استعلام التدفق السببي وآلية انتباه ثنائية التدفق لإعادة ترتيب الرموز المرئية ديناميكيًا، ما يُتيح إعادة بناء منطق القراءة الطبيعي للوثائق المعقدة بدقة أكبر. في تقييم OmniDocBench v1.5، حقق النموذج درجة شاملة بلغت 91.09%، وهو تحسن ملحوظ مقارنةً بسابقه، مع تقليل كبير في معدل تكرار نتائج التعرّف الضوئي على الأحرف، ما يُمهد الطريق لبناء مُشفّر متعدد الوسائط في المستقبل.
تشغيل عبر الإنترنت:https://go.hyper.ai/ITInm
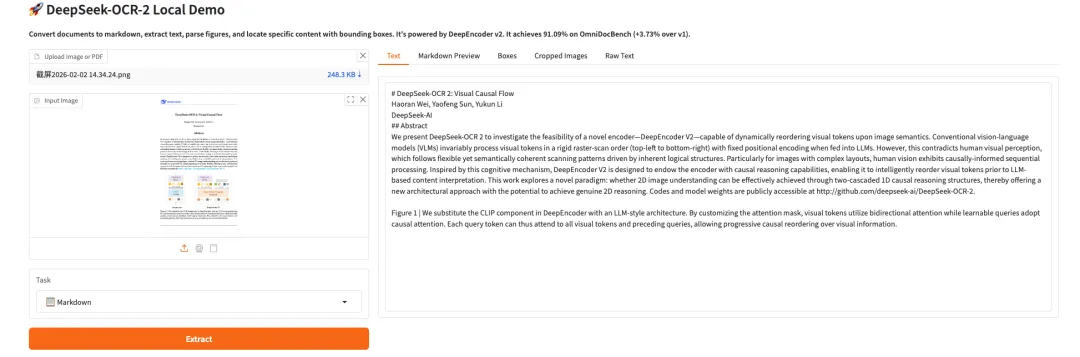
9. بيرسونابلكس-7ب-الإصدار 1: حوار فوري وواجهة صوتية مخصصة للشخصية
PersonaPlex-7B-v1 هو نموذج حوار شخصي متعدد الوسائط يتكون من 7 مليارات مُعامل، وقد أصدرته شركة NVIDIA. صُمم هذا النموذج للتفاعل الصوتي/النصي في الوقت الفعلي، ومحاكاة اتساق الشخصية على المدى الطويل، ومهام الإدراك متعدد الوسائط، بهدف توفير نظام عرض تفاعلي غامر متعدد الوسائط ولعب الأدوار بسرعة استجابة تصل إلى مستوى أجزاء من الثانية.
تشغيل عبر الإنترنت:https://go.hyper.ai/ndoj0
توصيات الورقة البحثية لهذا الأسبوع
1. التعلم المعزز التعاوني متعدد العوامل في وقت الاختبار لأغراض الاستدلال
تقترح هذه الورقة البحثية MATTRL، وهو إطار عمل للتعلم المعزز أثناء الاختبار، يُحسّن من قدرة الاستدلال متعدد العوامل عن طريق إدخال خبرة نصية منظمة في عملية الاستدلال. ويحقق هذا الإطار توافقًا في الآراء من خلال تعاون فرق متعددة الخبراء وتوزيع النقاط جولةً تلو الأخرى، كما يحقق تحسينات قوية في الأداء على المعايير الطبية والرياضية والتعليمية دون الحاجة إلى إعادة التدريب.
رابط الورقة:https://go.hyper.ai/ENmkT
2. A^3-Bench: قياس أداء التفكير العلمي القائم على الذاكرة من خلال تفعيل المرساة والمُستَقبِل
تقترح هذه الورقة البحثية A³-Bench، وهو معيار قياس ثنائي النطاق للاستدلال العلمي يعتمد على الذاكرة. يقيّم هذا المعيار تفعيل نقاط الارتكاز ونقاط الجذب باستخدام إطار عمل SAPM للتعليقات التوضيحية ومقياس AAUI، كاشفاً كيف يمكن لاستخدام الذاكرة أن يعزز اتساق الاستدلال بما يتجاوز التماسك القياسي أو دقة الإجابة.
رابط الورقة:https://go.hyper.ai/Ao5t9
3. PaCoRe: التعلم لتوسيع نطاق الحوسبة أثناء الاختبار باستخدام الاستدلال المنسق المتوازي
تقترح هذه الورقة البحثية PaCoRe، وهو إطار عمل للاستدلال التعاوني المتوازي يحقق توسعًا هائلاً في حسابات وقت الاختبار (TTC) من خلال تبادل الرسائل بين جولات متعددة من مسارات الاستدلال المتوازية. يتفوق PaCoRe على GPT-5 (93.2%) بدقة 94.5% على مجموعة بيانات HMMT 2025. يدمج PaCoRe بكفاءة عملية الاستدلال لملايين الرموز ضمن قيد سياق ثابت، مع إتاحة النموذج والبيانات كمصدر مفتوح لتعزيز تطوير أنظمة استدلال قابلة للتوسع.
رابط الورقة:https://go.hyper.ai/fQrnt
4. إسناد الحركة لإنشاء الفيديو
تقترح هذه الورقة البحثية "موتيف"، وهو إطار عمل لتصنيف البيانات يعتمد على الحركة وتدرج الألوان، ويفصل الديناميكيات الزمنية عن المظهر الثابت من خلال قناع خسارة مُرجّح بالحركة. يُمكّن هذا من التعرف على المقاطع التي تؤثر على الضبط الدقيق، مما يُحسّن سلاسة الحركة والمصداقية الفيزيائية في توليد الفيديو من النصوص. وقد حقق معدل تفضيل بشري بلغ 74.11 نقطة في اختبار VPench.
رابط الورقة:https://go.hyper.ai/2pU21
5. VIBE: محرر قائم على التعليمات المرئية
تقترح هذه الورقة البحثية VIBE، وهي سير عمل مُدمج لتحرير الصور يعتمد على التعليمات، ويستخدم نموذج Qwen3-VL ذو ملياري مُعامل للتوجيه، ونموذج Sana1.5 للانتشار ذو 1.6 مليار مُعامل للتوليد. يُحقق VIBE تحريرًا عالي الجودة يحافظ بدقة على اتساق الصورة الأصلية بتكلفة حسابية منخفضة للغاية. يعمل بكفاءة على ذاكرة GPU بسعة 24 جيجابايت، ويُولد صورة بدقة 2K على جهاز H100 في غضون 4 ثوانٍ فقط، مُحققًا أداءً يُضاهي أو يتجاوز أداء النماذج الأساسية الأكبر حجمًا.
رابط الورقة:https://go.hyper.ai/8YMEO
تفسير مقالة المجتمع
1. بعد اجتياز 100 مليون نقطة بيانات من تلسكوب هابل الفضائي في 3 أيام، اقترحت وكالة الفضاء الأوروبية مشروع AnomalyMatch، الذي اكتشف أكثر من ألف جسم سماوي شاذ.
تُسهم المسوحات السماوية واسعة النطاق، متعددة النطاقات وذات مجال رؤية واسع وعمق عالٍ، حاليًا في دفع علم الفلك نحو عصر غير مسبوق من البيانات الضخمة. ويكمن أحد أهم إمكاناته العلمية في الاكتشاف المنهجي للأجرام السماوية النادرة ذات القيمة الفيزيائية الفلكية الخاصة وتحديدها. إلا أن اكتشافها لطالما اعتمد بشكل كبير على التحديد البصري العرضي للباحثين أو الفرز اليدوي من خلال مشاريع العلوم التشاركية. ولا تقتصر هذه الأساليب على كونها ذاتية وغير فعالة فحسب، بل إنها غير ملائمة أيضًا للكم الهائل من البيانات المتوقعة. ولمعالجة هذا القصور، اقترح فريق بحثي في المركز الأوروبي لعلم الفلك الفضائي (ESAC)، التابع لوكالة الفضاء الأوروبية (ESA)، وطبّق طريقة جديدة تُسمى AnomalyMatch.
شاهد التقرير الكامل:https://go.hyper.ai/Jm3aq
2. ملخص مجموعة البيانات | 16 مجموعة بيانات للذكاء المجسد تغطي مجالات الفهم، والإجابة على الأسئلة، والاستدلال المنطقي، والاستدلال على المسار، وغيرها.
إذا كان محور الصراع الرئيسي للذكاء الاصطناعي خلال العقد الماضي هو "فهم العالم" و"إنتاج المحتوى"، فإن القضية الأساسية للمرحلة التالية تتجه نحو تحدٍ أكبر: كيف يمكن للذكاء الاصطناعي أن يدخل العالم المادي فعلاً ويتفاعل ويتعلم ويتطور ضمنه؟ في الأبحاث والمناقشات ذات الصلة، يتردد مصطلح "الذكاء المتجسد" بكثرة. وكما يوحي الاسم، فإن الذكاء المتجسد ليس روبوتًا تقليديًا، بل يركز على الذكاء الناتج عن التفاعل بين الكائن الحي والبيئة المحيطة ضمن حلقة مغلقة من الإدراك واتخاذ القرار والفعل. ستنظم هذه المقالة بشكل منهجي جميع مجموعات البيانات عالية الجودة المتاحة حاليًا والمتعلقة بالذكاء المتجسد، وستوصي بها، لتكون مرجعًا لمزيد من التعلم والبحث.
شاهد التقرير الكامل:https://go.hyper.ai/lsCyF
3. برنامج تعليمي عبر الإنترنت | تحسينات تحليل الصيغ/الجداول في DeepSeek-OCR 2: تحقيق قفزة في الأداء تقارب 4% بتكلفة رمزية مرئية منخفضة
في تطوير نماذج اللغة المرئية (VLMs)، لطالما واجهت تقنية التعرف الضوئي على الأحرف (OCR) للمستندات تحديات جوهرية، مثل تحليل التخطيطات المعقدة ومواءمة المنطق الدلالي. وقد شكّل تمكين النماذج من "فهم" المنطق المرئي كما يفهمه البشر إنجازًا هامًا في تحسين قدرات فهم المستندات. ومؤخرًا، قدّمت DeepSeek-OCR 2 من DeepSeek-AI حلًا جديدًا. يتمحور هذا الحل حول اعتماد بنية DeepEncoder V2 الجديدة: حيث يتخلى النموذج عن مُشفّر CLIP المرئي التقليدي، ويُقدّم نموذجًا للترميز المرئي على غرار نماذج اللغة المرئية (LLM). ومن خلال دمج الانتباه ثنائي الاتجاه والانتباه السببي، يُحقق النموذج إعادة ترتيب الرموز المرئية بناءً على الدلالة، مما يُنشئ مسارًا جديدًا لـ"الاستدلال السببي أحادي البعد على مرحلتين" لفهم الصور ثنائية الأبعاد.
شاهد التقرير الكامل:https://go.hyper.ai/nMH13
4. تغطي Polymathic AI 19 سيناريو بما في ذلك الفيزياء الفلكية وعلوم الأرض وعلم الريولوجيا وعلم الصوتيات، وتقوم بإنشاء 1.3 مليار نموذج لتحقيق محاكاة دقيقة للوسط المستمر.
في مجالي الحوسبة العلمية ومحاكاة الهندسة، لطالما شكّلت كيفية التنبؤ بكفاءة ودقة بتطور الأنظمة الفيزيائية المعقدة تحديًا أساسيًا للأوساط الأكاديمية والصناعية على حد سواء. وفي الوقت نفسه، دفعت الإنجازات في مجال التعلم العميق، لا سيما في معالجة اللغات الطبيعية ورؤية الحاسوب، الباحثين إلى استكشاف التطبيقات المحتملة لـ"النماذج الأساسية" في المحاكاة الفيزيائية. مع ذلك، غالبًا ما تتطور الأنظمة الفيزيائية عبر نطاقات زمنية ومكانية متعددة، بينما تُدرَّب معظم نماذج التعلم عادةً على ديناميكيات قصيرة المدى فقط. وعند استخدامها للتنبؤات طويلة المدى، تتراكم الأخطاء في الأنظمة المعقدة، مما يؤدي إلى عدم استقرار النموذج. وانطلاقًا من هذا، اقترح فريق بحثي من تعاونية Polymathic AI نموذج Walrus، وهو نموذج أساسي يحتوي على 1.3 مليار مُعامل، ويعتمد على بنية Transformer، ومصمم خصيصًا لديناميكيات الموائع المتصلة.
شاهد التقرير الكامل:https://go.hyper.ai/MJrny
مقالات موسوعية شعبية
1. الفرز العكسي مع RRF
2. نظرية تمثيل كولموغوروف-أرنولد
3. فهم اللغة متعدد المهام على نطاق واسع MMLU
4. مُحسِّنات الصندوق الأسود
5. الاحتمالية الشرطية للفئة
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








