Command Palette
Search for a command to run...
مفتوح المصدر، أفضل قيمة! أطلقت Mistral AI سلسلة نماذج Ministral 3، التي تجمع بين الفهم متعدد الوسائط وقدرات التنفيذ الذكي؛ من الرقص عالي الديناميكية إلى السلوك اليومي، تُتيح مجموعة بيانات X-Dance اختبارًا متعدد الأبعاد لتوليد الرسوم المتحركة البشرية.

حديثاً،أطلق فريق Mistral AI سلسلة النماذج عالية الكفاءة، Ministral 3، مفتوحة المصدر، وتقدم ثلاثة خيارات لمعلمات النموذج: 3B، و8B، و14B.يأتي كل معلمة في ثلاثة إصدارات: Basic وCommand وInference، وكلها مرخصة بموجب ترخيص Apache 2.0.
يُقدم Ministral-3-14B، باعتباره الطراز ذو أكبر معايير في السلسلة، الأداء الأكثر تطورًا في فئته، مُقارنًا بطراز Mistral Small 3.2-24B الأكبر حجمًا. وهو مُحسّن للنشر المحلي، مُحافظًا على أداء عالٍ على الأجهزة الصغيرة محدودة الموارد.
يدمج Ministral-3-14B بين الفهم المتعدد الوسائط وقدرات التنفيذ الذكية:من حيث الرؤية، يُمكنه تحليل محتوى الصور مباشرةً وإنشاء محتوى نصي بناءً على المعلومات المرئية؛ وفي الوقت نفسه، يُغطي دعمه متعدد اللغات عشرات اللغات السائدة، بما في ذلك الإنجليزية والصينية واليابانية، وغيرها. يعتمد النموذج على نافذة سياق قوية بحجم 256 كيلوبايت، مما يُوفر دعمًا قويًا للتعامل مع المهام المعقدة والطويلة.
يُتيح موقع HyperAI الآن نشر تعليمات Ministral-3-14B بنقرة واحدة. جرّبها!
الاستخدام عبر الإنترنت:https://go.hyper.ai/EGIY2
نظرة عامة سريعة على تحديثات الموقع الرسمي لـ hyper.ai من 1 ديسمبر إلى 5 ديسمبر:
* مجموعات البيانات العامة عالية الجودة: 5
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 5
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
أهم المؤتمرات التي لها مواعيد نهائية في ديسمبر: 1
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات توليد المشكلات باستخدام خوارزمية UniCode التطورية
UniCode هي مجموعة بيانات آلية لمسائل الخوارزميات وحالات الاختبار، مبنية باستخدام استراتيجية توليد متطورة. تهدف هذه المجموعة إلى استبدال مجموعات المسائل التقليدية الثابتة المُولّدة يدويًا، موفرةً موارد أكثر تنوعًا وتحديًا وقوة لمسائل البرمجة. من خلال مسار توليد وتحقق منهجي للمسائل، تُنشئ هذه المجموعة بيانات مسائل واختبارات منظمة وتحديًا وخالية من أي شوائب، مناسبة لأبحاث الخوارزميات، وتقييم نماذج توليد الأكواد، والتدريب على المسابقات.
الاستخدام المباشر:https://go.hyper.ai/YBBcI
2. مجموعة بيانات أداء الحركة المرئية VAP-Data
VAP-Data، التي أصدرتها بايت دانس بالتعاون مع الجامعة الصينية في هونغ كونغ، تُعد حاليًا أكبر مجموعة بيانات لتوليد الفيديو المُتحكّم دلاليًا. تهدف إلى توفير معايير تدريب وتقييم عالية الجودة لتوليد الفيديو المُتحكّم فيه، وتوليف الحركة المُتحكّم فيه، ونماذج الفيديو متعددة الوسائط. تحتوي مجموعة البيانات على أكثر من 90,000 عينة مُقترنة مُختارة بعناية، تُغطي 100 شرط دلالي دقيق عبر أربع فئات دلالية: المفهوم، والأسلوب، والحركة، واللقطة. تتضمن كل فئة دلالية مجموعات متعددة من حالات الفيديو المُتراصفة بشكل مُتبادل.
الاستخدام المباشر:https://go.hyper.ai/wUrHs

3. مجموعة بيانات صور مجهرية للفطريات متعددة الفئات
Fungi MultiClass Microscopic هي مجموعة بيانات صور مجهرية عالية الجودة لتصنيف الصور وأبحاث التعلم العميق، وهي مصممة لتوفير موارد بيانات موثوقة للتدريب والتقييم لمجالات مثل تشخيص الفطريات الطبية وأمراض الزراعة.
الاستخدام المباشر:https://go.hyper.ai/ZHUaY
4. مجموعة بيانات حركات الرقص المعتمدة على الصور X-Dance
X-Dance هي مجموعة بيانات اختبارية أصدرتها جامعة نانجينغ بالتعاون مع تينسنت ومختبر الذكاء الاصطناعي في شنغهاي. صُممت خصيصًا لتوليد الرسوم المتحركة من الصور إلى الفيديو، وتهدف إلى تقييم متانة النماذج وقدرتها على التعميم في سيناريوهات واقعية عند مواجهة تحديات مثل الحفاظ على الهوية، والتماسك الزمني، وعدم التوافق الزماني المكاني.
الاستخدام المباشر:https://go.hyper.ai/QXsNo

5. مجموعة بيانات الفهم ثلاثي الأبعاد المعتمدة على اللغة 3EED
3EED هي مجموعة بيانات تأريض بصري ثلاثي الأبعاد متعددة المنصات والوسائط، أصدرتها جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو) بالتعاون مع جامعة نانيانغ التكنولوجية وجامعة هونغ كونغ للعلوم والتكنولوجيا ومؤسسات أخرى. وقد تم اعتمادها من قِبل NeurIPS 2025، وتهدف إلى دعم النماذج في إنجاز مهام تحديد مواقع الأهداف ثلاثية الأبعاد المعتمدة على اللغة في المشاهد الخارجية الواقعية، وإجراء تقييم شامل لمتانة النماذج عبر المنصات وقدراتها على الفهم المكاني.
استخدمه مباشرة: https://go.hyper.ai/gC8Fq
دروس تعليمية عامة مختارة
1. شجرة عيد الميلاد ثلاثية الأبعاد تعتمد على التعرف على الإيماءات
شجرة عيد الميلاد ثلاثية الأبعاد هو مشروع مبتكر من قِبَل Molecularmmeng020425. يُقدّم المشروع تجربة بصرية غامرة وسينمائية. بُني المشروع على React وThree.js (R3F)، ويستخدم تقنية متقدمة للذكاء الاصطناعي للتعرف على الإيماءات، مما يُتيح للمستخدمين التحكم بسهولة في شكل شجرة عيد الميلاد (تجميعًا وتوزيعًا) وتدوير زاوية المشاهدة بحرية باستخدام الإيماءات.
تشغيل عبر الإنترنت:https://go.hyper.ai/LpApP
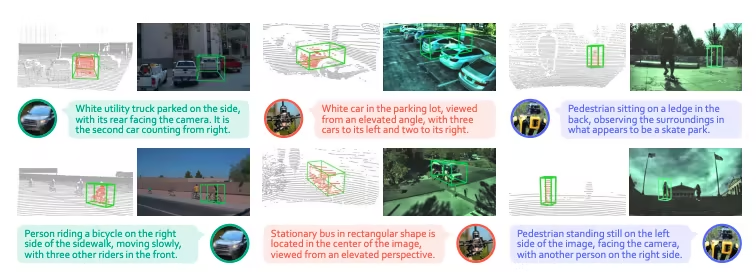
2. نشر Ministry-3-14B-Instruct بنقرة واحدة
Ministral-3-14B-Instruct-2512 هو نموذج متعدد الوسائط أصدرته Mistral AI. يدعم هذا النموذج الوسائط المتعددة (النص والصورة) واللغات المتعددة، مما يوفر أداءً عاليًا وفعالية من حيث التكلفة. بفضل تقنيات التحسين من شركاء مثل NVIDIA، يمكن لهذا النموذج العمل بكفاءة على مختلف الأجهزة، وهو مناسب للحوسبة الطرفية، وعمليات النشر المؤسسية، وغيرها من السيناريوهات، مما يوفر للمطورين أدوات قوية لبناء تطبيقات الذكاء الاصطناعي ونشرها.
تشغيل عبر الإنترنت:https://go.hyper.ai/EGIY2
3. SAM3: نموذج التجزئة المرئية
SAM3 هو نموذج متقدم للرؤية الحاسوبية، طورته شركة Meta AI. يستطيع هذا النموذج اكتشاف الكائنات في الصور والفيديوهات وتجزئتها وتتبعها باستخدام النصوص والأمثلة والإشارات البصرية. يدعم هذا النموذج إدخال عبارات مفتوحة المصدر، ويتمتع بقدرات تفاعلية قوية عبر الوسائط، ويمكنه تصحيح نتائج التجزئة آنيًا. يقدم SAM3 أداءً فائقًا في مهام تجزئة الصور والفيديوهات، متفوقًا على الأنظمة الحالية بضعف الأداء، كما يدعم التعلم الآلي.
تشغيل عبر الإنترنت:https://go.hyper.ai/PEaVo

4. FLUX.2-dev: نموذج إنشاء الصور وتحريرها
FLUX.2 هو نموذج صور ذكاء اصطناعي طورته مختبرات بلاك فورست. صُمم خصيصًا لسير العمل الإبداعي في العالم الواقعي. يدعم النموذج مراجع متعددة للصور تصل إلى 10 صور، مما يُنتج صورًا عالية الجودة بدقة تصل إلى 4 ميجابكسل مع إمكانيات استثنائية في عرض التفاصيل والنصوص. بدمجه نموذج لغة بصرية مع بنية محول التدفق، يُحسّن النموذج بشكل كبير فهم المعرفة العملية وجودة إنتاج الصور، مما يُعزز الابتكار المفتوح والتطبيق الواسع لتقنيات الذكاء البصري.
تشغيل عبر الإنترنت:https://go.hyper.ai/4abhg
5. يمكن لجهاز F5-E2 TTS استنساخ أي نغمة في 3 ثوانٍ فقط.
F5-TTS هو نظام تحويل نص إلى كلام (TTS) عالي الأداء، مفتوح المصدر، مشترك بين جامعة شنغهاي جياو تونغ وجامعة كامبريدج وشركة جيلي لأبحاث السيارات (نينغبو) المحدودة. يعتمد النظام على طريقة توليد غير انحدارية باستخدام مطابقة التدفق، مقترنة بتقنية محول الانتشار (DiT). يُمكّن هذا النظام من توليد كلام طبيعي وسلس ودقيق من النص الأصلي بسرعة، من خلال التعلم التلقائي دون إشراف إضافي. يدعم النظام التوليف متعدد اللغات، بما في ذلك الصينية والإنجليزية، ويمكنه توليف الكلام من النصوص الطويلة بفعالية.
تشغيل عبر الإنترنت:https://go.hyper.ai/8YCMD
توصيات الورقة البحثية لهذا الأسبوع
1. من نماذج أساسيات الكود إلى الوكلاء والتطبيقات: دراسة شاملة ودليل عملي لذكاء الكود
تدمج هذه الدراسة بشكل منهجي وتوفر مجموعة شاملة من المبادئ التوجيهية للتحليل والممارسة المتكاملة (بما في ذلك سلسلة من التجارب التحليلية والاستكشافية) لاستكشاف دورة حياة كاملة لمعلمي التعلم القائم على التعليمات البرمجية، والتي تغطي بناء البيانات، والتدريب المسبق، وأنماط المطالبة، والتدريب المسبق للتعليمات البرمجية، والضبط الدقيق الخاضع للإشراف، والتعلم التعزيزي، وبناء وكلاء البرمجة المستقلة.
رابط الورقة:https://go.hyper.ai/xvPZN
2. DeepSeek-V3.2: توسيع آفاق نماذج اللغات الكبيرة المفتوحة
تُقدّم هذه الورقة البحثية نموذج DeepSeek-V3.2، وهو نموذج يُحقق قدرات استدلالية فائقة وأداءً مُتميّزًا للوكلاء مع الحفاظ على كفاءة حسابية عالية. تشمل الإنجازات التكنولوجية الرئيسية لـ DeepSeek-V3.2 الجوانب الثلاثة التالية: آلية الانتباه المُتفرّق DeepSeek Sparse Attention (DSA)، وإطار عمل تعلّم مُعزّز قابل للتوسّع، وخط أنابيب واسع النطاق لتوليف مهام الوكلاء.
رابط الورقة:https://go.hyper.ai/pVyE9
3. LongVT: تحفيز "التفكير باستخدام مقاطع فيديو طويلة" عبر استدعاء الأدوات الأصلية
تقترح هذه الورقة البحثية LongVT، وهو إطار عمل ذكي متكامل يُمكّن من "التفكير العميق في مقاطع الفيديو الطويلة" من خلال سلسلة متداخلة متعددة الوسائط من التفكير في الأدوات. ويستفيد هذا الإطار من قدرات تحديد المواقع الزمنية الكامنة في أجهزة LMM كأداة أصلية لقص الفيديو، مع التركيز بدقة على مقاطع فيديو محددة وإجراء إعادة أخذ عينات أكثر دقة لإطارات الفيديو.
رابط الورقة:https://go.hyper.ai/ho70t
4. Z-Image: نموذج أساسي لتوليد الصور بكفاءة باستخدام محول انتشار أحادي التدفق
تقترح هذه الورقة البحثية نموذج Z-Image، وهو نموذج توليدي عالي الكفاءة بستة مليارات معلمة، يعتمد على بنية محول الانتشار أحادي التدفق القابل للتطوير (S3-DiT)، متحديًا بذلك نموذج "التوسع فقط". بناءً على ذلك، طوّر الباحثون نموذج Z-Image-Turbo باستخدام نظام تقطير من بضع خطوات مع مكافأة ما بعد التدريب. يحقق هذا النموذج زمن انتقال استدلالي أقل من ثانية على وحدات معالجة الرسومات H800 المخصصة للمؤسسات، مع الحفاظ على توافقه مع الأجهزة المخصصة للمستهلكين (أقل من 16 جيجابايت من ذاكرة الوصول العشوائي للفيديو)، مما يُخفّض بشكل كبير من عتبة النشر.
رابط الورقة:https://go.hyper.ai/qqSwp
5. تقرير فني عن Qwen3-VL
تُقدّم هذه المقالة Qwen3-VL، أقوى نموذج لغة بصرية في سلسلة Qwen حتى الآن، مُظهرةً أداءً مُتميزًا عبر مجموعة واسعة من معايير الأداء مُتعددة الوسائط. يدعم هذا النموذج بشكل أصلي سياقات مُتداخلة تصل إلى 256 ألف رمز، مُدمجًا بسلاسة معلومات النصوص والصور والفيديو. تتضمن عائلة النموذج هياكل كثيفة (2B/4B/8B/32B) وهياكل مُتخصصة هجينة (30B-A3B/235B-A22B) لمُراعاة مُقارنات زمن الوصول والجودة في سيناريوهات مُختلفة.
رابط الورقة:https://go.hyper.ai/8HkMJ
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
1. إعادة تشكيل القدرة التنبؤية لتجمعات البروتين غير المنظمة: أصدرت NVIDIA وMIT وجامعة أكسفورد وجامعة كوبنهاجن وPeptone وغيرها نماذج توليدية ومعايير جديدة.
حقق فريق مشترك يضم شركة Peptone، وهي شركة بريطانية متخصصة في تطوير تقنيات تحليل البروتينات، وشركة NVIDIA، ومعهد ماساتشوستس للتكنولوجيا (MIT)، إنجازين هامين. الأول هو إطار عمل التقييم المنهجي PeptoneBench: يدمج هذا الإطار بيانات تجريبية متعددة المصادر من SAXS، والرنين المغناطيسي النووي، وRDC، وPRE، ويجمع بين أساليب إحصائية مثل إعادة ترجيح الإنتروبيا القصوى لتحقيق مقارنة كمية دقيقة بين الملاحظات التجريبية والتنبؤات النظرية. أما الثاني فهو النموذج التوليدي PepTron: المدرب على مجموعة بيانات IDR اصطناعية موسعة، فهو يعزز تحديدًا قدرة النمذجة للمناطق غير المنظمة، مما يُمكّنه من رصد التنوع التكويني للبروتينات غير المنظمة بشكل أفضل.
شاهد التقرير الكامل:https://go.hyper.ai/YBd9t
2. البرنامج التعليمي عبر الإنترنت | FLUX.2، أحدث التقنيات في مجال توليد الصور، يمكنه الإشارة إلى ما يصل إلى 10 صور في وقت واحد، مما يحقق اتساقًا عاليًا للغاية في الشخصية/الأسلوب.
بعد فترة انقطاع طويلة، عادت مختبرات الغابة السوداء (Black Forest Labs) إلى الواجهة من خلال إتاحة نموذجها الجديد لتوليد وتحرير الصور، FLUX.2، مفتوح المصدر. حقق FLUX.1، الذي صدر عام 2024، نتائج شبه واقعية عند توليد صور للأشخاص، وخاصةً الأشخاص الحقيقيين. والآن، ترتقي ترقية FLUX.2 إلى آفاق جديدة من حيث جودة الصورة والمرونة الإبداعية، محققةً مستويات متقدمة من حيث فهم التعليمات، وجودة الصورة، وتقديم التفاصيل، وتنوع المخرجات.
شاهد التقرير الكامل:https://go.hyper.ai/wLDRW
3. معاينة الحدث | يجتمع مختبر شنغهاي للابتكار، وTileAI، وHuawei، وAdvanced Compiler Lab في شنغهاي؛ حيث تعرض TVM، وTileRT، وPyPTO، وTriton نقاط قوتها الفريدة.
سيُعقد الملتقى التقني الثامن لمترجمي الذكاء الاصطناعي (Meet AI Compiler) في 27 ديسمبر في أكاديمية شنغهاي للابتكار. يشارك في هذه الجلسة خبراء من أكاديمية شنغهاي للابتكار، ومجتمع TileAI، وHuawei HiSilicon، ومختبر المترجمات المتقدمة. سيتبادلون رؤاهم حول سلسلة التكنولوجيا بأكملها، بدءًا من تصميم حزمة البرامج وتطوير المشغلات وصولًا إلى تحسين الأداء. ستشمل المواضيع قابلية التشغيل البيني عبر الأنظمة البيئية لـ TVM، وتحسين مشغلي دمج PyPTO، والأنظمة منخفضة الكمون باستخدام TileRT، وتسريع متعدد البنى باستخدام Triton، مقدمين بذلك مسارًا تقنيًا شاملًا من النظرية إلى التنفيذ.
شاهد التقرير الكامل:https://go.hyper.ai/x6po9
4. تعاونت جامعة ستانفورد وجامعة بكين وجامعة كلية لندن وجامعة كاليفورنيا في بيركلي لاستخدام CNN لتحديد سبع عينات عدسية نادرة من 810 ألف نجم شبه نجمي بدقة.
قام فريق مكون من العديد من مؤسسات البحث، بما في ذلك جامعة ستانفورد، ومختبر تسريع SLAC الوطني، وجامعة بكين، ومرصد بريرا التابع للمعهد الوطني الإيطالي للفيزياء الفلكية، وجامعة كلية لندن، وجامعة كاليفورنيا، بيركلي، بتطوير سير عمل قائم على البيانات لتحديد الكوازارات التي تعمل كعدسات جاذبية قوية في البيانات الطيفية لـ DESI DR1، مما أدى إلى توسيع حجم العينة الصغيرة من الكوازارات بشكل كبير.
شاهد التقرير الكامل:https://go.hyper.ai/6s2FB
5. مع الوصول إلى 2% فقط، يواجه رهان سام ألتمان على البنية التحتية للتحقق من الهوية البشرية معضلة تنظيمية عالمية.
في عصرٍ يصعب فيه تمييز مصداقية الذكاء الاصطناعي، يعمل سام ألتمان وأليكس بلانيا على بناء نظام عالمي للتحقق من الهوية البشرية باستخدام تقنية التعرف على قزحية العين، إلا أن توسع "أدوات من أجل الإنسانية" يواجه ضغوطًا هائلة. علّقت الفلبين خدمات البيانات لديها بدعوى انتهاك الخصوصية والتأثير غير المبرر، وبدأت عدة دول أخرى في إجراء مراجعات. وتزداد الفجوة بين رؤية "مليار مستخدم" وعدد مستخدميها الحالي البالغ 17.5 مليون مستخدم فقط. ورغم التمويل الوفير وفريق العمل المتميز، ستظل مخاوف الخصوصية والتنظيم مصدر قلق طويل الأمد لمستقبل "أدوات من أجل الإنسانية".
شاهد التقرير الكامل: https://go.hyper.ai/KL1Dq
مقالات موسوعية شعبية
1. دال-إي
2. الشبكات الفائقة
3. جبهة باريتو
4. الذاكرة طويلة المدى ثنائية الاتجاه (Bi-LSTM)
5. اندماج الرتب المتبادلة
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
أفضل مؤتمر مع الموعد النهائي في ديسمبر

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1800 مجموعة بيانات عامة
* يتضمن أكثر من 600 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* يدعم البحث عن أكثر من 600 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








