Command Palette
Search for a command to run...
إنجازٌ رائد في مجال الرؤية ثلاثية الأبعاد: تُطلق ByteSeed برنامج DA3، الذي يُتيح إعادة بناء الفضاء المرئي من أي زاوية رؤية؛ أكثر من 70,000 بيانات من بيئات صناعية واقعية! يسد برنامج CHIP الفجوة في البيانات الصناعية لتقدير الوضعية سداسية الأبعاد.

تُعدّ القدرة على إدراك وفهم المعلومات المكانية ثلاثية الأبعاد من المدخلات البصرية حجر الزاوية في الذكاء المكاني، وشرطًا أساسيًا لتطبيقات مثل الروبوتات والواقع المختلط. وقد أدت هذه القدرة الجوهرية إلى ظهور مجموعة متنوعة من مهام الرؤية ثلاثية الأبعاد، مثل تقدير العمق أحادي الرؤية، واستخلاص البنية من الحركة، والرؤية المجسمة متعددة المشاهد، والتحديد والتخطيط المتزامنين للموقع.
غالبًا ما تختلف هذه المهام في عوامل قليلة فقط، مثل عدد طرق عرض المدخلات، ولذلك تتشابه مفاهيميًا إلى حد كبير. ومع ذلك، لا يزال النموذج السائد حاليًا يركز على تطوير نماذج متخصصة للغاية لكل مهمة. وقد أصبح بناء نموذج موحد لفهم الأبعاد الثلاثية، قادر على التعامل مع مهام متعددة، اتجاهًا بحثيًا هامًا.ومع ذلك، تعتمد الحلول الحالية عادةً على بنى شبكية معقدة ومصممة خصيصًا وتتطلب تدريبًا من الصفر من خلال التحسين المشترك متعدد المهام.لذلك، من الصعب استيعاب واستخدام المعرفة والمزايا الخاصة بالنماذج المدربة مسبقًا على نطاق واسع بشكل كامل.
وبناء على هذا،أطلق فريق Seed التابع لشركة ByteDance لعبة Depth Anything 3 (DA3).يمكن لنموذج Transformer واحد، مُدرَّب خصيصًا ومبني على تمثيلات شعاعية محددة، أن يُقدِّر العمق والوضع معًا من أي زاوية رؤية. وفي سعيها لتحقيق تبسيط النموذج إلى أقصى حد، توصلت DA3 إلى نتيجتين رئيسيتين:
*يمكن استخدام محول قياسي واحد (مثل مشفر DINO العادي) كشبكة أساسية.لا يتطلب الأمر تخصيصًا هيكليًا خاصًا بالمهمة؛
*التنبؤ بالأهداف باستخدام شعاع عمق واحد فقط.يمكن تحقيق أداء ممتاز دون الحاجة إلى آلية تعلم معقدة متعددة المهام.
كما وضع فريق البحث معيارًا جديدًا للهندسة البصرية يشمل تقدير وضعية الكاميرا، وهندسة وجهة النظر العشوائية، والعرض المرئي. في هذا الاختبار،يقوم DA3 بتحديث الحالة في جميع المهمات.تزيد دقة وضع الكاميرا بمعدل 35.71 نقطة في مقياس TP3T عن دقة VGGT، كما تحسّنت الدقة الهندسية بمقدار 23.61 نقطة في مقياس TP3T، ويتفوق تقدير العمق أحادي العدسة على النموذج السابق DA2. تُظهر التجارب أن هذه الطريقة البسيطة كافية لإعادة بناء الفضاء المرئي من أي عدد من الصور (بغض النظر عما إذا كان وضع الكاميرا معروفًا أم لا).
يعرض موقع HyperAI الإلكتروني الآن "Depth-Anything-3: استعادة المساحة المرئية من أي وجهة نظر"، لذا جربه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/MXyML
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 15 ديسمبر إلى 19 ديسمبر:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 3
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
أهم المؤتمرات التي تنتهي مواعيدها في يناير: 11
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات تقييم نموذج مكافآت الفيديو VideoRewardBench
يُعدّ VideoRewardBench، الذي أطلقته جامعة العلوم والتكنولوجيا الصينية بالتعاون مع مختبر هواوي نوح آرك، أول معيار تقييم شامل يغطي أربعة أبعاد أساسية لفهم الفيديو: الإدراك، والمعرفة، والاستدلال، والأمان. ويهدف إلى تقييم قدرة النماذج بشكل منهجي على إصدار أحكام تفضيلية وتقييم جودة النتائج المُولّدة في سيناريوهات فهم الفيديو المعقدة. تحتوي مجموعة البيانات على 1563 عينة مُصنّفة، تشمل 1482 مقطع فيديو مختلفًا و1559 سؤالًا مختلفًا. تتكون كل عينة من نص الفيديو، وإجابة مُفضّلة، وإجابة رفض.
الاستخدام المباشر:https://go.hyper.ai/JIB1B
2. مجموعة بيانات تقييم توليد الكتابة باستخدام برنامج Arena-Write
Arena-Write هي مجموعة بيانات لمهام الكتابة، أصدرتها جامعة سنغافورة للتكنولوجيا والتصميم بالتعاون مع مختبر هندسة المعرفة بجامعة تسينغهوا. صُممت هذه المجموعة لتقييم نماذج توليد النصوص الطويلة، ولتقييم القدرات الشاملة لنماذج اللغة الكبيرة في توليد محتوى طويل ومهام كتابة معقدة في ظل سيناريوهات استخدام واقعية. تحتوي مجموعة البيانات على 100 مهمة كتابة للمستخدم، تتكون كل منها من نص كتابة واقعي، ومصنفة حسب نوع سيناريو الكتابة المناسب.
الاستخدام المباشر:https://go.hyper.ai/4NQdD
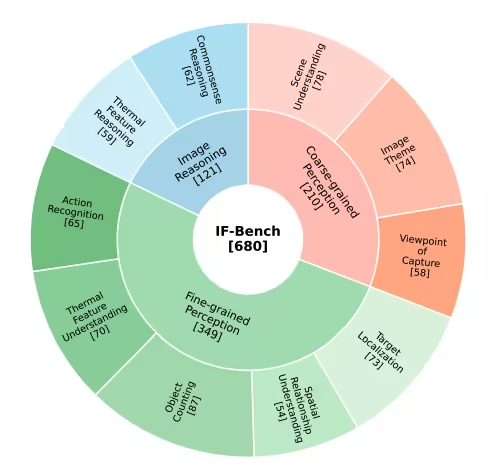
3. مجموعة بيانات IF-Bench المعيارية لفهم صور الأشعة تحت الحمراء
يُعدّ IF-Bench معيارًا عالي الجودة لفهم الصور بالأشعة تحت الحمراء متعددة الوسائط، وقد أُصدر بالاشتراك بين معهد الأتمتة التابع للأكاديمية الصينية للعلوم وكلية الذكاء الاصطناعي بجامعة الأكاديمية الصينية للعلوم. ويهدف إلى التقييم المنهجي لقدرات الفهم الدلالي لنماذج اللغة الكبيرة متعددة الوسائط (MLLMs) للصور بالأشعة تحت الحمراء. تحتوي مجموعة البيانات على 499 صورة بالأشعة تحت الحمراء و680 زوجًا من الأسئلة والأجوبة المرئية (VQA). وقد جُمعت الصور من 23 مجموعة بيانات مختلفة للصور بالأشعة تحت الحمراء، مما يحافظ على توزيع متوازن نسبيًا.
الاستخدام المباشر:https://go.hyper.ai/hty3u
4. مجموعة بيانات تقدير وضعية الكرسي الصناعي سداسي الأبعاد من CHIP
CHIP هي مجموعة بيانات لتقدير وضعية الروبوتات في سيناريوهات صناعية واقعية، تم إصدارها من قِبل FBK-TeV بالتعاون مع Ikerlan وAndreu World. تهدف هذه المجموعة إلى سدّ فجوة البيانات في المعايير الحالية، التي تركز بشكل أساسي على الأدوات المنزلية والإعدادات المختبرية، وتفتقر إلى بيانات حول الظروف الصناعية الواقعية. تحتوي مجموعة البيانات على 77,811 صورة RGB-D، تغطي نماذج كراسي بسبعة هياكل ومواد مختلفة.
الاستخدام المباشر:https://go.hyper.ai/AR5Xm
5. مجموعة بيانات الاستعلام باللغة الطبيعية للبيانات شبه المهيكلة SSRB
تُعدّ SSRB مجموعة بيانات مرجعية واسعة النطاق للاستعلام باللغة الطبيعية عن البيانات شبه المهيكلة، وقد تم إصدارها بالاشتراك بين معهد هاربين للتكنولوجيا (شنتشن)، وجامعة هونغ كونغ للفنون التطبيقية، وجامعة تسينغهوا، ومؤسسات أخرى. وقد تم اختيارها ضمن مجموعات بيانات ومعايير مؤتمر NeurIPS 2025، بهدف تقييم وتعزيز قدرة النماذج على استرجاع البيانات شبه المهيكلة في ظل ظروف استعلام معقدة باللغة الطبيعية.
الاستخدام المباشر:https://go.hyper.ai/szsqF
6. مجموعة بيانات INFINITY-CHAT للإجابة على الأسئلة المفتوحة في العالم الحقيقي
فازت مجموعة بيانات INFINITY-CHAT، وهي أول مجموعة بيانات واسعة النطاق لأسئلة المستخدمين المفتوحة في العالم الحقيقي، والتي أصدرتها جامعة واشنطن بالتعاون مع جامعة كارنيجي ميلون ومعهد ألين للذكاء الاصطناعي، بجائزة أفضل ورقة بحثية في مؤتمر NeurIPS 2025 (مسار قواعد البيانات). وتهدف هذه المجموعة إلى دراسة قضايا رئيسية بشكل منهجي، مثل تنوع نماذج اللغة في توليد الأسئلة المفتوحة، والاختلافات في تفضيلات المستخدمين، و"تأثير السرب الاصطناعي".
الاستخدام المباشر:https://go.hyper.ai/KmH1N
7. معيار MUVR لاسترجاع الفيديو متعدد الوسائط غير المقصوص
تُعدّ MUVR مجموعة بيانات مرجعية لمهام استرجاع مقاطع الفيديو غير المُحرّرة متعددة الوسائط، وقد أُصدرت بالاشتراك بين جامعة نانجينغ للملاحة الجوية والفضائية، وجامعة نانجينغ، وجامعة هونغ كونغ للفنون التطبيقية. وقد تم اختيارها ضمن مجموعات البيانات والمعايير المرجعية لمؤتمر NeurIPS 2025، وتهدف إلى تعزيز البحث في مجال استرجاع مقاطع الفيديو على منصات الفيديو الطويلة. تحتوي مجموعة البيانات على ما يقارب 53,000 مقطع فيديو غير مُحرّر من موقع Bilibili، و1,050 استعلامًا متعدد الوسائط، و84,000 علاقة مطابقة بين الاستعلامات ومقاطع الفيديو، وتغطي أنواعًا شائعة من مقاطع الفيديو مثل الأخبار والسفر والرقص.
الاستخدام المباشر:https://go.hyper.ai/NRaSw

8. مجموعة بيانات التقييم الشامل لنسيان الرسم البياني OpenGU
OpenGU هي مجموعة بيانات تقييم شاملة لتقنية إلغاء التعلم في الرسوم البيانية (GU)، وقد أصدرها معهد بكين للتكنولوجيا. تم اختيارها ضمن مجموعات بيانات ومعايير NeurIPS 2025، وتهدف إلى توفير إطار تقييم موحد، وموارد بيانات متعددة المجالات، وإعدادات تجريبية موحدة لأساليب النسيان في الشبكات العصبية الرسومية.
الاستخدام المباشر:https://go.hyper.ai/qqHct
9. مجموعة بيانات تقييم مهمة البحث الاستدلالي في FrontierScience
تُعدّ FrontierScience، التي أصدرتها OpenAI، مجموعة بيانات لتقييم مهام الاستدلال والبحث العلمي. وتهدف إلى تقييم قدرات النماذج الكبيرة بشكل منهجي في مهام الاستدلال العلمي والبحث على مستوى الخبراء. وتعتمد مجموعة البيانات على آلية تصميم تتألف من "محتوى أصلي من الخبراء + بنية مهام ثنائية الطبقات + آلية تسجيل تلقائية"، وهي مقسمة إلى مجموعتين فرعيتين: الأولمبياد والبحث.
الاستخدام المباشر:https://go.hyper.ai/fUUzF
10. مجموعة بيانات FirstAidQA للإجابة على أسئلة المعرفة في الإسعافات الأولية
FirstAidQA هي مجموعة بيانات متخصصة في مجال الإسعافات الأولية والاستجابة للطوارئ، أصدرتها الجامعة الإسلامية للعلوم والتكنولوجيا. تهدف هذه المجموعة إلى دعم تدريب النماذج وتطبيقها في بيئات الطوارئ ذات الموارد المحدودة. تحتوي مجموعة البيانات على 5500 زوج من الأسئلة والأجوبة عالية الجودة، تغطي مجموعة متنوعة من سيناريوهات الإسعافات الأولية والاستجابة للطوارئ الشائعة.
الاستخدام المباشر:https://go.hyper.ai/QQphC
دروس تعليمية عامة مختارة
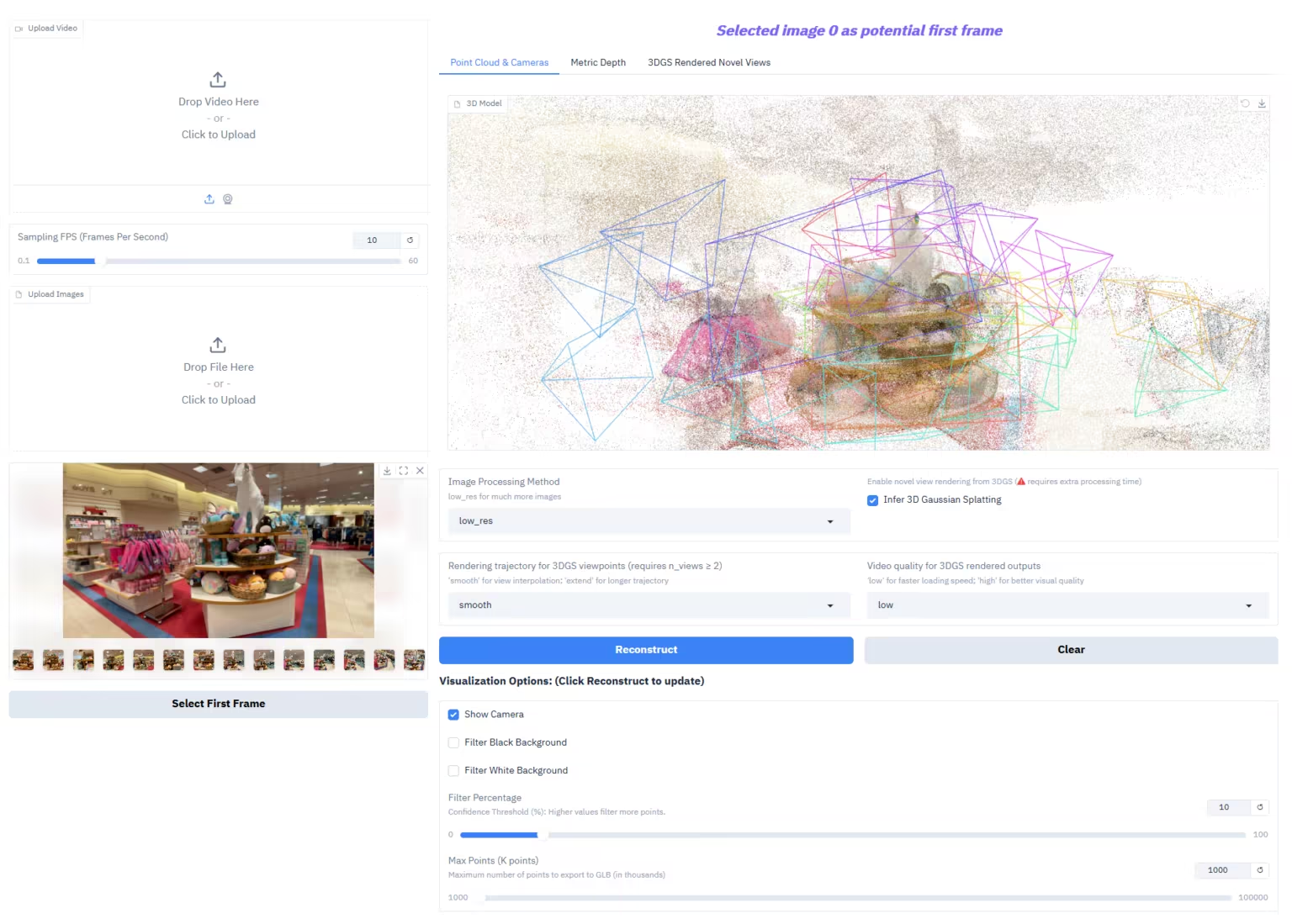
1. العمق-أي-3: استعادة المساحة البصرية من أي منظور
يُعدّ Depth-Anything-3 (DA3) نموذجًا رائدًا للهندسة البصرية، وقد أصدره فريق ByteDance-Seed. يُحدث هذا النموذج ثورة في مهام الهندسة البصرية من خلال مفهوم "النمذجة البسيطة": فهو يستخدم مُحوّلًا عاديًا واحدًا فقط (مثل مُشفّر DINO الأساسي) كشبكة أساسية، ويستبدل عملية التعلّم المعقدة متعددة المهام بـ "تمثيل شعاع العمق" للتنبؤ بالهياكل الهندسية المتسقة مكانيًا من أي مُدخلات بصرية (سواء كانت أوضاع الكاميرا معروفة أو غير معروفة).
تشغيل عبر الإنترنت:https://go.hyper.ai/MXyML
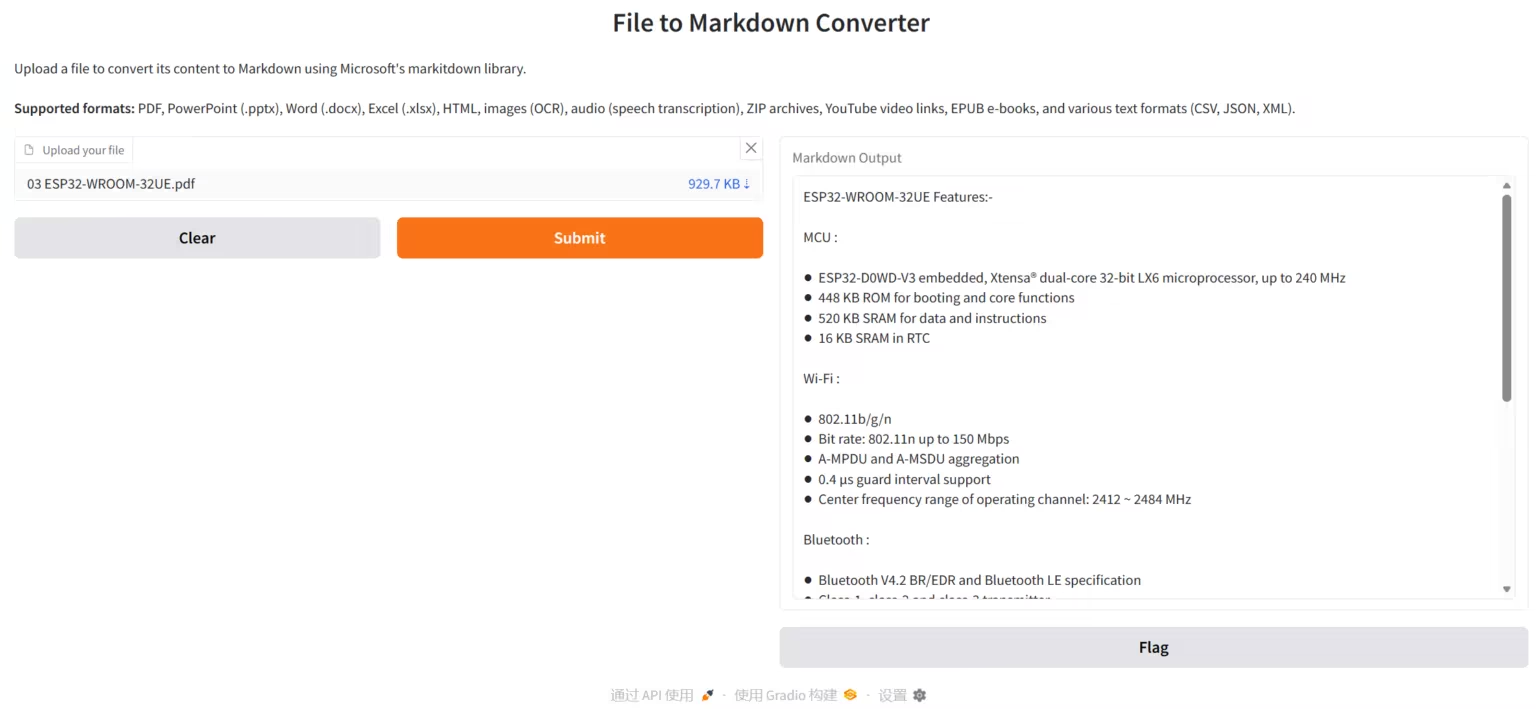
2. MarkItDown، أداة تحويل المستندات مفتوحة المصدر من مايكروسوفت
MarkItDown هي أداة تحويل مستندات بايثون خفيفة الوزن وسهلة الاستخدام، طورتها مايكروسوفت. تهدف إلى تحويل تنسيقات المستندات والوسائط المتعددة الشائعة بكفاءة وهيكلية إلى Markdown، مما يوفر تنسيق إدخال مُحسَّن خصيصًا لخطوط أنابيب فهم النصوص وتحليلها في نماذج اللغة الكبيرة (LLMs).
تشغيل عبر الإنترنت:https://go.hyper.ai/7WIGP
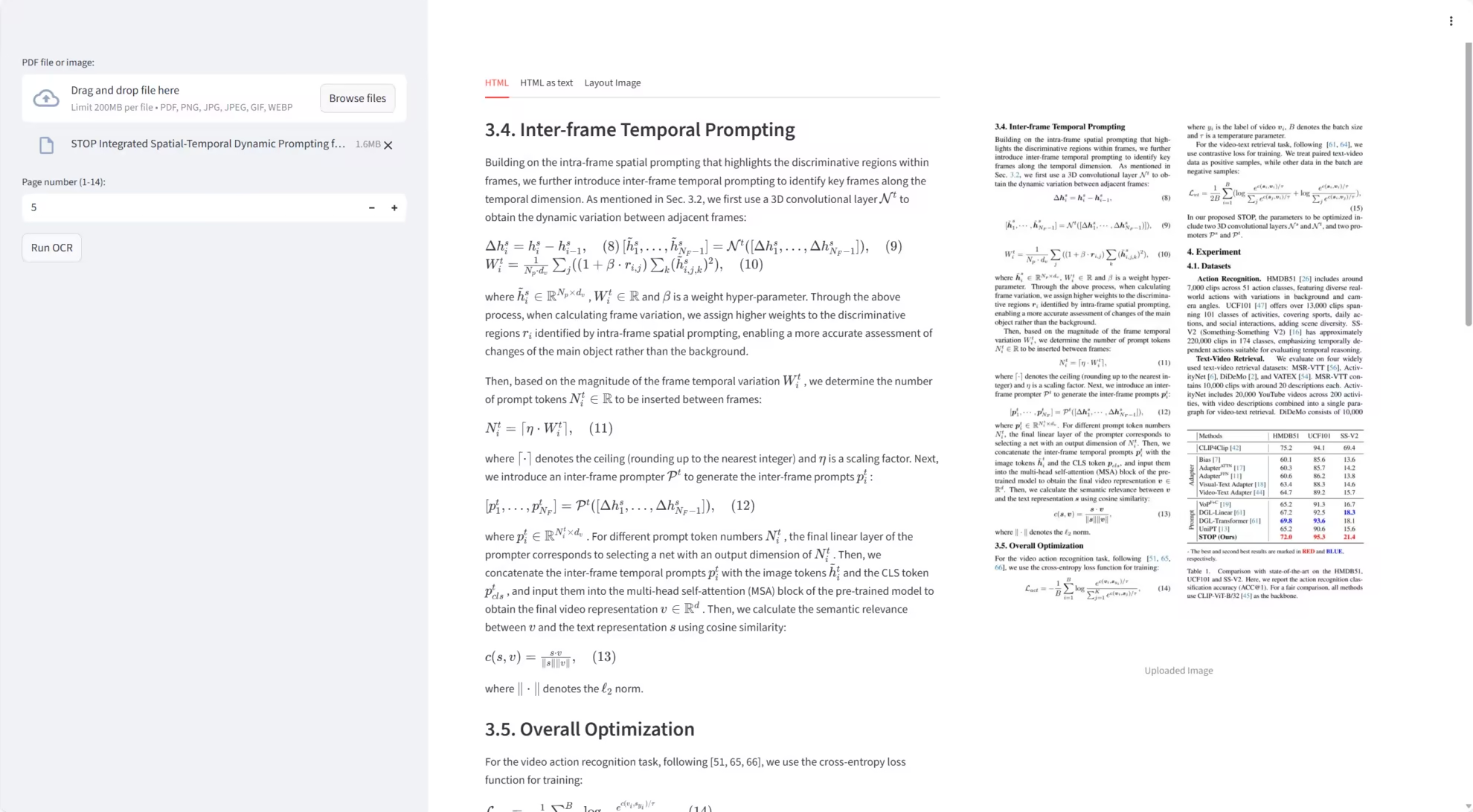
3. تشاندرا: تقنية التعرف الضوئي على الأحرف عالية الدقة للوثائق
شاندرا هو نظام عالي الدقة للتعرف الضوئي على الأحرف (OCR) للمستندات، طوّره فريق داتالاب-تو، ويركز على فهم تخطيط المستند واستخراج النصوص. يستطيع شاندرا معالجة ملفات PDF والصور مباشرةً، مُنتجًا نصوصًا مُهيكلة، ونصوص Markdown، ونصوص HTML، مع توفير مخططات تخطيط مرئية لتسهيل فحص نتائج التعرف الضوئي على الأحرف.
تشغيل عبر الإنترنت:https://go.hyper.ai/nZhF5
توصيات الورقة البحثية لهذا الأسبوع
1. لونغ في 2: نموذج فيديو عالمي فائق الطول قابل للتحكم متعدد الوسائط
تقترح هذه الورقة البحثية LongVie 2، وهو إطار عمل انحداري ذاتي شامل يحقق أداءً متطورًا في إمكانية التحكم بعيد المدى والتماسك الزمني والدقة البصرية، ويدعم إنشاء مقاطع فيديو متواصلة تصل مدتها إلى خمس دقائق، مما يمثل خطوة رئيسية نحو نمذجة عالم فيديو موحد.
رابط الورقة:https://go.hyper.ai/toK8K
2. MMGR: الاستدلال التوليدي متعدد الوسائط
تقترح هذه الورقة البحثية إطار عمل تقييم وقياس أداء الاستدلال التوليدي متعدد الوسائط (MMGR)، وهو نظام تقييم منهجي قائم على خمس قدرات استدلالية أساسية: الاستدلال الفيزيائي، والاستدلال المنطقي، والاستدلال المكاني ثلاثي الأبعاد، والاستدلال المكاني ثنائي الأبعاد، والاستدلال الزمني. يقيم MMGR قدرات الاستدلال للنماذج التوليدية في ثلاثة مجالات رئيسية: الاستدلال المجرد (مثل الذكاء الاصطناعي العام المتقدم، ولعبة سودوكو)، والملاحة المجسدة (الملاحة وتحديد المواقع ثلاثية الأبعاد في العالم الحقيقي)، والفهم الحسي الفيزيائي العام (مثل سيناريوهات رياضية وسلوكيات تفاعلية معقدة).
رابط الورقة:https://go.hyper.ai/Gxwuz
3. QwenLong-L1.5: وصفة ما بعد التدريب للاستدلال طويل السياق وإدارة الذاكرة
تقدم هذه الورقة البحثية نموذج QwenLong-L1.5، الذي يحقق قدرات فائقة في الاستدلال السياقي الطويل من خلال ابتكارات منهجية بعد التدريب. وبالاستناد إلى بنية Qwen3-30B-A3B-Thinking، يُظهر QwenLong-L1.5 أداءً قريبًا من GPT-5 وGemini-2.5-Pro في معايير الاستدلال السياقي الطويل، مع تحسن متوسط قدره 9.90 نقطة مقارنةً بالنماذج الأساسية. وفي المهام فائقة الطول (من مليون إلى 4 ملايين رمز)، يحقق إطار عمل وكيل الذاكرة تحسنًا ملحوظًا قدره 9.48 نقطة مقارنةً بالوكيل الأساسي.
رابط الورقة:https://go.hyper.ai/DxYGd
4. الذاكرة في عصر وكلاء الذكاء الاصطناعي
تهدف هذه الورقة إلى استعراض أحدث التطورات في أبحاث ذاكرة الوكلاء بشكل منهجي. في البداية، توضح نطاق ذاكرة الوكيل، وتميزها بوضوح عن المفاهيم ذات الصلة مثل ذاكرة نموذج اللغة الكبير (LLM)، والتوليد المعزز بالاسترجاع (RAG)، وهندسة السياق. ثم تحلل ذاكرة الوكيل من ثلاثة منظورات موحدة: الشكل، والوظيفة، والديناميكيات.
رابط الورقة:https://go.hyper.ai/zfHTr
5. ReFusion: نموذج لغة كبير الانتشار مع فك تشفير التراجع الذاتي المتوازي
تقترح هذه الورقة البحثية نموذج ReFusion، وهو نموذج جديد لنشر الأقنعة يحقق أداءً وكفاءةً فائقين من خلال رفع مستوى فك التشفير المتوازي من مستوى الرموز إلى مستوى "الفتحة" الأعلى. كل فتحة عبارة عن تسلسل فرعي متصل ثابت الطول. لا يحقق ReFusion تحسينًا في الأداء بمعدل 341 TP3T مقارنةً بنماذج نشر الأقنعة السابقة فحسب، بل يحقق أيضًا تحسينًا في سرعة الاستدلال بمعدل يزيد عن 18 ضعفًا، كما أنه يقلل بشكل كبير من فجوة الأداء مع نماذج الانحدار الذاتي القوية مع الحفاظ على ميزة تسريع متوسطة تبلغ 2.33 ضعفًا.
رابط الورقة:https://go.hyper.ai/YosaF
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
1. باستخدام أقل من 100000 نقطة بيانات منظمة للتدريب، اقترح المعهد الفدرالي السويسري للتكنولوجيا في لوزان (EPFL) تقنية PET-MAD، محققًا دقة محاكاة ذرية قابلة للمقارنة بالنماذج الاحترافية.
يحقق نموذج PET-MAD الذي اقترحه المعهد الفدرالي السويسري للتكنولوجيا في لوزان (EPFL) دقة مماثلة للنماذج المخصصة مع مجموعة بيانات تغطي نطاقًا واسعًا من التنوع الذري وباستخدام عدد أقل بكثير من عينات التدريب مقارنة بالنماذج التقليدية، مما يوفر دليلًا قويًا لتطوير المحاكاة الذرية نحو كفاءة وشمولية أكبر.
شاهد التقرير الكامل:https://go.hyper.ai/cpeR5
2. برنامج تعليمي عبر الإنترنت | مايكروسوفت تُتيح برنامج VibeVoice مفتوح المصدر، مما يُتيح 90 دقيقة من الحوار الطبيعي بين 4 أدوار
أتاحت مايكروسوفت برنامج VibeVoice مفتوح المصدر، المصمم لتمكين توليف الكلام متعدد المتحدثين ذي الصيغة الطويلة والقابل للتطوير. يستطيع هذا النموذج توليف ما يصل إلى 90 دقيقة من الكلام مع ما يصل إلى أربعة متحدثين ضمن نافذة سياقية بحجم 64 ألف كلمة، مما يوفر جودة صوتية أغنى، ونبرة طبيعية أكثر، وقدرة على التقاط أجواء محادثة واقعية. كما يُظهر البرنامج قابلية نقل أقوى في التطبيقات متعددة اللغات، ويتفوق أداؤه العام على نماذج الحوار الحالية مفتوحة المصدر والخاصة.
شاهد التقرير الكامل:https://go.hyper.ai/YfDjq
3. انتقد أعضاء الفريق الأولي لـ CUDA بشدة cuTile لاستهدافها "على وجه التحديد" Triton؛ هل يمكن لنموذج Tile إعادة تشكيل المشهد التنافسي لنظام برمجة GPU؟
في ديسمبر 2025، وبعد ما يقارب عقدين من إطلاق CUDA، أطلقت NVIDIA "cuTile"، وهي نقطة دخول جديدة لبرمجة وحدات معالجة الرسومات (GPU). تعيد cuTile هيكلة نواة وحدة معالجة الرسومات باستخدام نموذج برمجة قائم على الوحدات، مما يُمكّن المطورين من كتابة النوى بكفاءة دون الحاجة إلى معرفة متعمقة بلغة CUDA C++، الأمر الذي أثار نقاشًا واسعًا في أوساط مجتمع المطورين. ورغم أنها لا تزال في مراحلها الأولى، إلا أن المزايا النظرية لنهج الوحدات، واستكشاف المجتمع لأدوات الترحيل، والمحاولات العملية، تشير إلى أن cuTile لديها القدرة على أن تصبح نموذجًا جديدًا لبرمجة وحدات معالجة الرسومات. ويعتمد مستقبلها على نضج النظام البيئي، وتكاليف الترحيل، والأداء.
شاهد التقرير الكامل:https://go.hyper.ai/H1b0n
4. قام داريو أمودي، الذي يعطي الأولوية للإشراف الاستباقي، بدمج سلامة الذكاء الاصطناعي في مهمة الشركة بعد مغادرته OpenAI.
مع تسارع وتيرة سباق الذكاء الاصطناعي العالمي، أصبح داريو أمودي، بموقفه المخالف لرأي الأغلبية بشأن "التنظيم المبكر"، قوة لا يُستهان بها في وادي السيليكون. فهو يسعى، من خلال الترويج للذكاء الاصطناعي الدستوري والتأثير على الأطر التنظيمية في أوروبا والولايات المتحدة، إلى وضع "بروتوكول حوكمة" مماثل لبروتوكول TCP/IP لعصر الذكاء الاصطناعي. ولا يقتصر الأمر على الأمن فحسب، بل يتعداه إلى إمكانية انتقال الذكاء الاصطناعي من التطور التكنولوجي السريع إلى تطبيقات مستقرة خلال العقد القادم. وتُعيد استراتيجية أمودي تشكيل المنطق الأساسي لصناعة الذكاء الاصطناعي العالمية.
شاهد التقرير الكامل:https://go.hyper.ai/SwyNW
5. اقترح فريق بقيادة لي يونغ في جامعة تسينغهوا طريقة الانحدار الرمزي العصبي التي يمكنها تحسين دقة التنبؤ بواسطة 60%، واستخلاص صيغ ديناميكيات الشبكة عالية الدقة تلقائيًا.
اقترح البروفيسور يونغ لي وفريقه من قسم الهندسة الإلكترونية بجامعة تسينغهوا طريقةً للانحدار الرمزي العصبي، تُسمى ND²، تُحدد ديناميكيات النظام من خلال استخلاص الصيغ الرياضية تلقائيًا من البيانات. تُبسط هذه الطريقة مشكلة البحث في الشبكات عالية الأبعاد إلى نظام أحادي البعد، وتستخدم شبكة عصبية مُدرَّبة مسبقًا لتوجيه عملية اكتشاف الصيغ بدقة عالية.
شاهد التقرير الكامل:https://go.hyper.ai/wVktJ
مقالات موسوعية شعبية
1. القاعدة النووية
2. الذاكرة طويلة المدى ثنائية الاتجاه (Bi-LSTM)
3. الحقيقة على أرض الواقع
4. الملاحة المجسدة
5. معدل الإطارات في الثانية (FPS)
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
الموعد النهائي لشهر يناير للمؤتمر الأعلى

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1800 مجموعة بيانات عامة
* يتضمن أكثر من 600 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* يدعم البحث عن أكثر من 600 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








