Command Palette
Search for a command to run...
الكشف عن استدلال الذكاء الاصطناعي: نموذج OpenAI المتفرق يجعل الشبكات العصبية شفافة لأول مرة؛ التنبؤ بالسعرات الحرارية المحروقة: إدخال بيانات الطاقة الدقيقة في نماذج اللياقة البدنية

المقال الأصلي بقلم لين جيامين هايبر ايه اي14 يناير 2026، الساعة 17:06بكين
شهدت نماذج اللغة الكبيرة في السنوات الأخيرة تقدماً سريعاً في قدراتها، إلا أن عمليات اتخاذ القرار الداخلية فيها لا تزال أشبه بصندوق أسود معقد يصعب تتبعه وفهمه. هذه المشكلة الجوهرية تعيق بشكل خطير التطبيق الموثوق للذكاء الاصطناعي في مجالات عالية المخاطر كالرعاية الصحية والتمويل.كيفية جعل عملية التفكير في النموذج شفافة وقابلة للتتبع لا تزال قضية رئيسية لم يتم حلها.
وبناء على هذا،أصدرت OpenAI نموذج Circuit Sparsity، وهو نموذج لغة كبير يحتوي على 0.4 مليار معلمة، في ديسمبر 2025. ويستخدم تقنية Circuit Sparsity لإعادة ضبط 99.9% وزنًا إلى الصفر، مما يؤدي إلى إنشاء بنية حسابية متفرقة قابلة للتفسير.بفضل تجاوزها لقيود اتخاذ القرار "المبهمة" في نماذج Transformers التقليدية، تُمكّن هذه النماذج من تحليل عملية الاستدلال في الذكاء الاصطناعي طبقةً تلو الأخرى. وتقوم في جوهرها بتحويل الشبكات العصبية الكثيفة التقليدية إلى "دوائر" متفرقة ومنظمة من خلال أسلوب تدريب فريد.
*التباعد القسري الديناميكيبخلاف الطرق التقليدية، يقوم هذا الأسلوب بـ "التقليم الديناميكي" في كل خطوة من خطوات التدريب، حيث يحتفظ فقط بعدد قليل جدًا من الأوزان ذات القيمة المطلقة الأكبر (مثل 0.1%) في كل جولة، ويجبر الباقي على أن يكون صفرًا، مما يجبر النموذج على التعلم للعمل في ظل الحد الأدنى من الاتصال منذ البداية.
*تفعيل خاصية التباعدمن خلال إدخال وظائف التنشيط في مواقع رئيسية مثل آليات الانتباه، يميل ناتج الخلايا العصبية إلى حالة منفصلة من "إما/أو"، وبالتالي يشكل قنوات معلومات واضحة في الشبكات المتفرقة.
*مكونات مخصصةيتم استخدام RMSnorm بدلاً من LayerNorm لمنع تدمير التباعد؛ ويتم إدخال جدول بحث ثنائي الكلمات للتعامل مع التنبؤ البسيط بالكلمات، مما يسمح للشبكة الرئيسية بالتركيز بشكل أكبر على المنطق المعقد.
يشكّل النموذج المُدرَّب باستخدام الطريقة المذكورة أعلاه تلقائيًا "دوائر" وظيفية محددة وقابلة للحل. كل دائرة مسؤولة عن مهمة فرعية محددة. يستطيع الباحثون تحديد أن بعض الخلايا العصبية تُستخدم تحديدًا لاكتشاف "علامات الاقتباس المفردة"، بينما تعمل خلايا أخرى كـ"عدادات" منطقية. بالمقارنة مع النماذج الكثيفة التقليدية، ينخفض عدد العقد النشطة المطلوبة لإنجاز المهمة نفسها بشكل ملحوظ.تحاول تقنية "شبكة الجسر" المصاحبة لها رسم خرائط التفسيرات التي تم الحصول عليها من الدوائر المتفرقة إلى نماذج كثيفة عالية الأداء مثل GPT-4، كما أنها توفر أداة محتملة لتحليل النماذج الكبيرة الموجودة.
يعرض موقع HyperAI الإلكتروني الآن "Circuit Sparsity: نموذج OpenAI الجديد مفتوح المصدر للخوارزميات المتفرقة"، لذا تفضلوا بتجربته!
الاستخدام عبر الإنترنت:https://go.hyper.ai/WgLQc
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 5 يناير إلى 9 يناير:
* مجموعات البيانات العامة عالية الجودة: 8
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 4
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات التي لها مواعيد نهائية في يناير: 9
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات MCIF متعددة الوسائط لتتبع التعليمات عبر اللغات
MCIF هي مجموعة بيانات تقييم متعددة اللغات والوسائط، مُعَلَّمة يدويًا، تعتمد على الخطابات العلمية، وقد أصدرتها مؤسسة برونو كيسلر بالتعاون مع معهد كارلسروه للتكنولوجيا وشركة Translated في عام 2025. وتهدف إلى تقييم قدرة نماذج اللغة الكبيرة متعددة الوسائط على فهم التعليمات وتنفيذها في سيناريوهات متعددة اللغات، بالإضافة إلى قدرتها على دمج المعلومات الصوتية والمرئية والنصية لأغراض الاستدلال.
الاستخدام المباشر:https://go.hyper.ai/SyUiL
2. مجموعة بيانات الاستدلال متعدد المهام TxT360-3efforts
TxT360-3efforts عبارة عن مجموعة بيانات تدريب نموذج اللغة واسعة النطاق للغاية لضبطها الدقيق الخاضع للإشراف (SFT)، وقد تم إصدارها من قبل جامعة محمد بن زايد للذكاء الاصطناعي في عام 2025. وهي مصممة للتحكم في ثلاث قوى استدلال للنموذج من خلال قوالب الدردشة.
الاستخدام المباشر:https://go.hyper.ai/fMEbf
3. مجموعة بيانات الكشف عن الممنوعات بالأشعة السينية
مجموعة بيانات الكشف عن الممنوعات بالأشعة السينية هي مجموعة بيانات أصدرتها جامعة جنوب الصين للمعلمين عام 2025 بالتعاون مع جامعة هونغ كونغ للفنون التطبيقية وجامعة ساسكاتشوان. صُممت هذه المجموعة لتحسين قدرات نماذج الكشف في الصور الأمنية المعقدة والمزدحمة، مع التركيز بشكل خاص على معالجة المشكلات الواقعية مثل عدم توازن الفئات وندرة العينات.
الاستخدام المباشر:https://go.hyper.ai/ppXub
4. مجموعة بيانات قياس حجم الدم عن بعد متعدد الكاميرات MCD-rPPG
MCD-rPPG عبارة عن مجموعة بيانات فيديو متعددة الكاميرات تم إصدارها بواسطة Sber AI Lab في عام 2025. تتكون مجموعة البيانات من مقاطع فيديو متزامنة وبيانات الإشارات الحيوية التي تم التقاطها بواسطة 600 شخص في حالات مختلفة، وهي مصممة لإجراء قياس حجم الدم عن بعد (rPPG) وتقدير المؤشرات الحيوية الصحية.
الاستخدام المباشر:https://go.hyper.ai/6KY40
5. مجموعة بيانات التقييم الشامل للسياق الطويل لبرنامج LongBench-Pro
LongBench-Pro عبارة عن مجموعة بيانات لتقييم نماذج اللغة ذات السياق الطويل، وهي مصممة لتقييم قدرة النموذج بشكل منهجي على فهم ومعالجة النصوص الطويلة في ظل أطوال سياق مختلفة وأنواع مهام وظروف وقت التشغيل.
الاستخدام المباشر:https://go.hyper.ai/7esQI
6. مجموعة بيانات الوجوه البشرية
مجموعة بيانات "وجوه بشرية" هي مجموعة بيانات صدرت عام 2025 لمهام رؤية الحاسوب المتعلقة بالوجوه. وتهدف إلى توفير بيانات صور عالية الجودة ومنظمة بشكل جيد لدعم تطبيقات مثل التعرف على الوجوه، والكشف عنها، وتحليل تعابير الوجه، والنمذجة التوليدية.
الاستخدام المباشر:https://go.hyper.ai/9WlDl

7. مجموعة بيانات التنبؤ بالسعرات الحرارية المحروقة
تُعدّ مجموعة بيانات التنبؤ بالسعرات الحرارية المحروقة مجموعة بيانات للتعلم الخاضع للإشراف تُستخدم للتنبؤ باستهلاك الطاقة أثناء التمرين. وتهدف إلى استخدام الخصائص الفسيولوجية للفرد ومعلومات حالته البدنية للتنبؤ بعدد السعرات الحرارية المحروقة خلال التمرين.
الاستخدام المباشر:https://go.hyper.ai/o6X59
8. مجموعة بيانات تتبع المسار MapTrace
MapTrace هي مجموعة بيانات ضخمة لتتبع مسارات الخرائط الاصطناعية، أطلقتها جوجل بالتعاون مع جامعة بنسلفانيا عام 2025. تهدف هذه المجموعة إلى تحسين قدرات نماذج اللغة متعددة الوسائط (MLLMs) على الاستدلال المكاني الدقيق وتخطيط المسارات في مشاهد الخرائط. يتمثل الهدف الرئيسي في تدريب النماذج على توليد مسارات دقيقة على مستوى البكسل، متصلة، وقابلة للمشي من نقطة البداية إلى الوجهة.
الاستخدام المباشر:https://go.hyper.ai/BGHUu
دروس تعليمية عامة مختارة
1. تباعد الدوائر: نموذج OpenAI الجديد مفتوح المصدر للتباعد
يُعدّ Circuit-sparsity نموذجًا لغويًا ضخمًا بحجم 0.4 مليار مُعامل، أصدرته OpenAI. يعتمد هذا النموذج على تقنية Circuit-sparsity، حيث يُعيد ضبط 99.9% وزنًا إلى الصفر لبناء بنية حسابية متفرقة قابلة للتفسير. يُتيح هذا تجاوز قيود اتخاذ القرار "المبهم" في نماذج Transformers التقليدية، مما يسمح بتحليل استدلال الذكاء الاصطناعي طبقةً تلو الأخرى. توفر مجموعة أدوات Streamlit، المُرفقة مع النموذج، تقنية "جسر التنشيط"، مما يُمكّن الباحثين من تتبع مسارات الإشارة الداخلية، وتحليل الدوائر المُقابلة، ومقارنة اختلافات الأداء بين النماذج المتفرقة والكثيفة.
تشغيل عبر الإنترنت:https://go.hyper.ai/zui8w
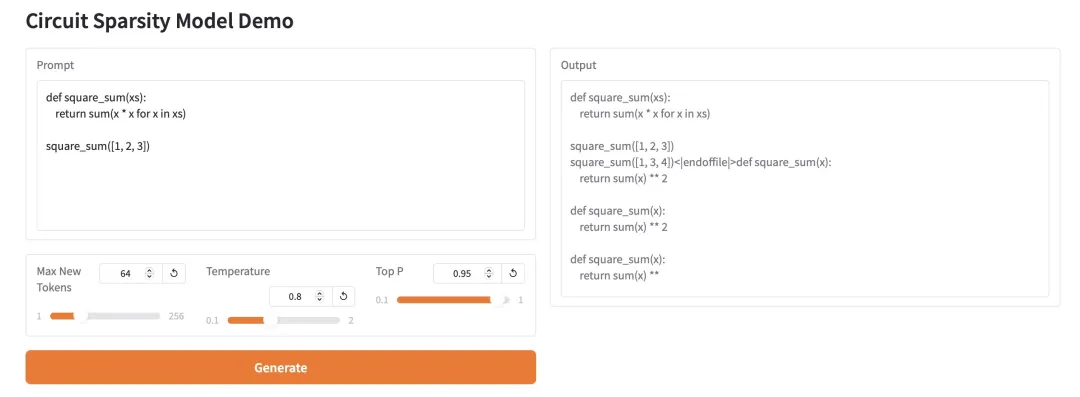
2. HY-MT1.5-1.8B: نموذج الترجمة الآلية العصبية متعددة اللغات
يُعدّ HY-MT1.5-1.8B نموذجًا للترجمة الآلية متعددة اللغات، يضم 1.8 مليار مُعامل، وقد طوّره فريق Hunyuan التابع لشركة Tencent. يعتمد هذا النموذج على بنية Transformer الموحدة، ويدعم الترجمة المتبادلة بين 33 لغة و5 لغات/لهجات عرقية، وهو مُحسّن خصيصًا لسيناريوهات العالم الحقيقي، مثل اللغات المختلطة والتحكم في المصطلحات. مع تحقيق جودة ترجمة تُقارب جودة نموذج 7B، يحتوي هذا النموذج على ثلث عدد المُعاملات فقط، ويدعم النشر الكمي والتكامل مع نظام HuggingFace البيئي، مما يجعله مناسبًا لخدمات الترجمة متعددة اللغات عبر الإنترنت بكفاءة عالية وتكلفة منخفضة.
تشغيل عبر الإنترنت:https://go.hyper.ai/I0pdR
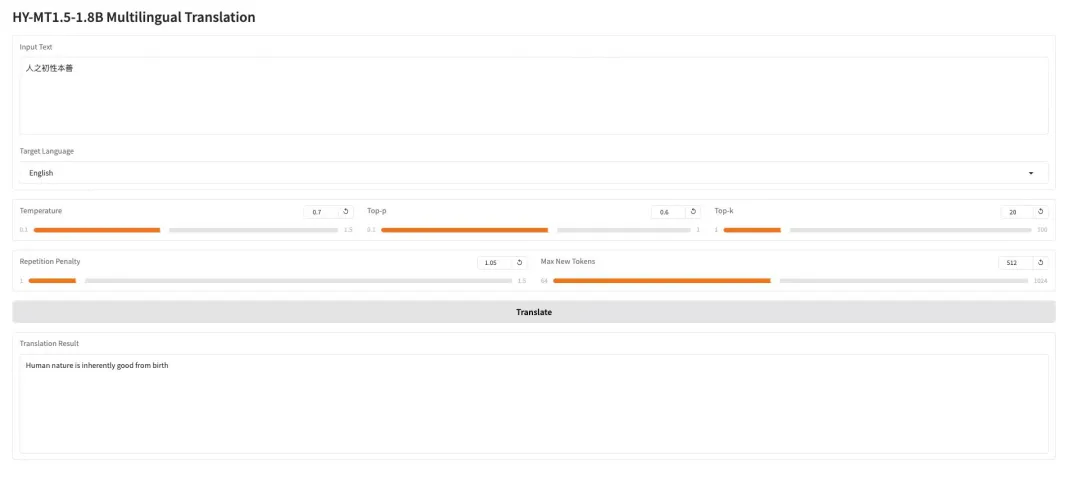
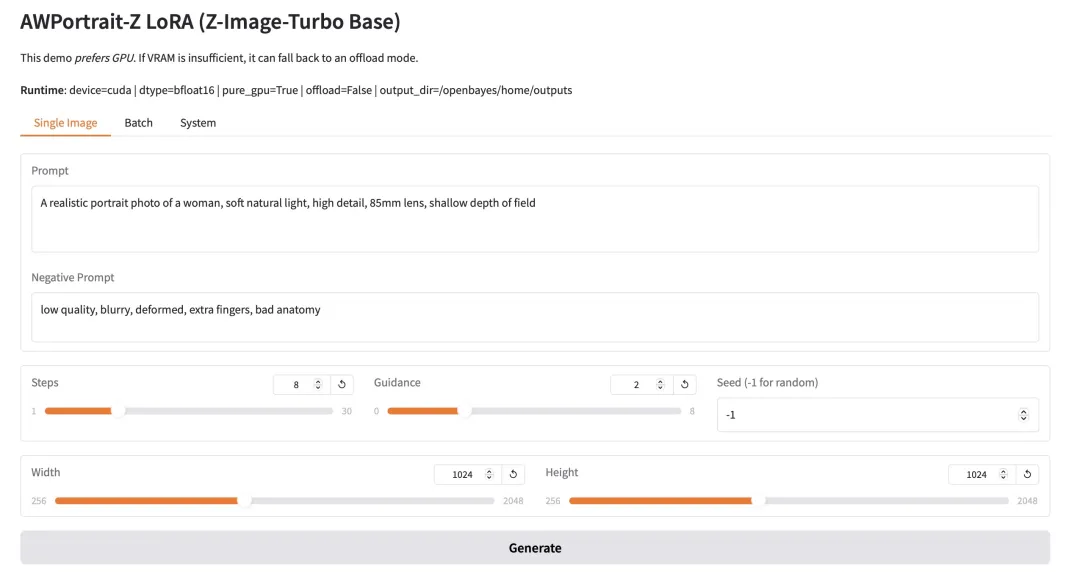
3. AWPortrait-Z Portrait Art LoRA
AWPortrait-Z هو نموذج لتحسين الصور الشخصية يعتمد على تقنية LoRA. يعمل كإضافة، ويتكامل مع نماذج نشر الصور النصية الشائعة، مما يُحسّن بشكل ملحوظ واقعية وجودة الصور الشخصية المُنشأة دون الحاجة إلى إعادة تدريب النموذج الأساسي. يُحسّن هذا النموذج تحديدًا عرض بنية الوجه وملمس البشرة والإضاءة، مما ينتج عنه تأثيرات أكثر طبيعية ودقة، مناسبة لإنشاء الصور الشخصية وتركيب الصور التي تتطلب واقعية فوتوغرافية.
تشغيل عبر الإنترنت:https://go.hyper.ai/wRjIp
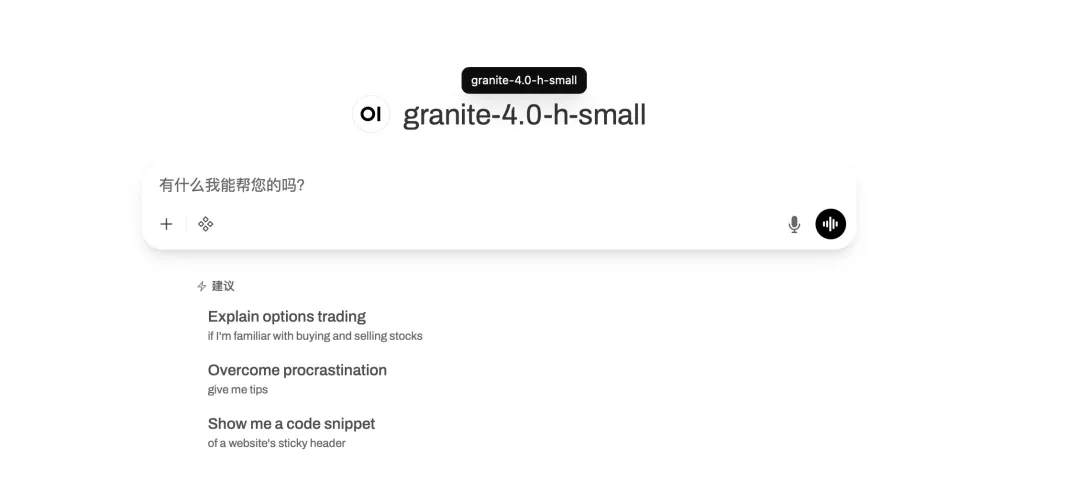
4. Granite-4.0-h-small: منصة شاملة للحوار متعدد اللغات ومهام البرمجة.
Granite-4.0-h-small هو نموذج ضبط دقيق لتعليمات السياق الطويل، يحتوي على 3.2 مليار مُعامل، وقد أصدرته شركة IBM. يعتمد هذا النموذج على نموذج أساسي، ويُدمج بيانات مفتوحة المصدر وبيانات اصطناعية، ويستخدم تقنيات الضبط الدقيق الخاضع للإشراف، ومواءمة التعلم المعزز، ودمج النماذج. يتميز هذا النموذج بتوافقه الممتاز مع التعليمات وقدراته الفائقة في استدعاء الأدوات، ويستخدم تنسيق حوار مُهيكل، وهو مُحسَّن لتطبيقات المؤسسات عالية الكفاءة.
تشغيل عبر الإنترنت:https://go.hyper.ai/1HhB9
توصيات الورقة البحثية لهذا الأسبوع
1. mHC: الاتصال الفائق المقيد بالتعددية
تقترح هذه الورقة البحثية "الوصلات الفائقة المقيدة بالمتشعبات" (mHC)، وهو إطار عمل عام يستعيد خاصية مطابقة الهوية للوصلات الفائقة (HC) من خلال إسقاط فضاء الوصلات المتبقية للوصلات الفائقة على متشعب محدد، مع ضمان كفاءة حسابية عالية عبر تحسين دقيق للبنية التحتية. تُظهر النتائج التجريبية أن mHC يحقق أداءً استثنائيًا في التدريب واسع النطاق، إذ لا يُحسّن الأداء بشكل ملموس فحسب، بل يُظهر أيضًا قابلية توسع ملحوظة. نتوقع أن يُسهم mHC، بوصفه امتدادًا مرنًا وعمليًا للوصلات الفائقة، في فهم أعمق لتصميم الطوبولوجيا، وأن يُوفر توجهات جديدة واعدة لتطوير النماذج الأساسية.
رابط الورقة:https://go.hyper.ai/ZePnH
2. Youtu-LLM: إطلاق العنان لإمكانات الوكلاء الأذكياء الأصليين في نماذج اللغة الكبيرة خفيفة الوزن
يقترح المؤلفون نموذج Youtu-LLM، وهو نموذج لغوي خفيف الوزن يحتوي على 1.96 مليار مُعامل، طوّره فريق Youtu-LLM. من خلال التدريب المسبق من الصفر باستخدام منهج قائم على مبدأ "الفطرة السليمة - العلوم والتكنولوجيا والهندسة والرياضيات - الوكيل"، يحقق هذا النموذج أداءً متميزًا بين النماذج التي يقل عدد مُعاملاتها عن ملياري مُعامل. يدمج هذا النموذج بنية انتباه مُدمجة متعددة زمن الاستجابة، ومُجزئًا للكلمات مُوجّهًا نحو مجالات العلوم والتكنولوجيا والهندسة والرياضيات، وخط أنابيب قابل للتوسع لتوليد بيانات مسار وكيل عالية الجودة في مجالات مثل الرياضيات والبرمجة والبحث المُعمّق واستخدام الأدوات. يُمكّن هذا النموذج من استيعاب قدرات التخطيط والتفكير والتنفيذ الأصلية، متفوقًا بشكل ملحوظ على النماذج الأكبر حجمًا في معايير الوكلاء، مع الحفاظ على قدرات استدلال عامة قوية وقدرات سياقية طويلة المدى.
رابط الورقة:https://go.hyper.ai/gitUc
3. Youtu-LLM: إطلاق العنان لإمكانات الوكلاء الأذكياء الأصليين في نماذج اللغة الكبيرة خفيفة الوزن
تُوضّح هذه الورقة البحثية تعريف الذاكرة ووظيفتها من خلال تتبّع تطوّرها من علم الأعصاب الإدراكي إلى نماذج اللغة الضخمة، ثم إلى الأنظمة الذكية. بعد ذلك، تُقارن الورقة وتحلل نظام تصنيف الذاكرة وآلية تخزينها ودورة إدارتها الكاملة من منظورين بيولوجي وصناعي. وبناءً على ذلك، تُراجع الورقة بشكل منهجي معايير تقييم ذاكرة الأنظمة الذكية السائدة حاليًا. علاوة على ذلك، تستكشف هذه الورقة قضايا أمن أنظمة الذاكرة من منظورَي الهجوم والدفاع. وأخيرًا، تستشرف الورقة اتجاهات البحث المستقبلية، مع التركيز على بناء أنظمة ذاكرة متعددة الوسائط وآليات اكتساب المهارات.
رابط الورقة:https://go.hyper.ai/01H6H
4. دع الأفكار تتدفق: بناء وكلاء أذكياء في سياق موسيقى الروك، وإنشاء نموذج روما ضمن نظام بيئي مفتوح لتعلم الوكلاء الأذكياء.
يقترح المؤلفون ROME، وهو نموذج وكيل مفتوح المصدر قائم على نظام التعلم الجيني (ALE). يدمج هذا الإطار تنظيم بيئة الاختبار المعزولة (Sandbox) الخاص بـ ROCK، وتحسين ما بعد التدريب الخاص بـ ROLL، وتنفيذ الوكيل المُراعي للسياق الخاص بـ iFlow CLI. يحقق أداءً متميزًا على منصتي Terminal-Bench 2.0 وSWE-bench Verified من خلال تخصيص نقاط لكتل التفاعل الدلالي عبر خوارزمية مبتكرة لتحسين السياسات (IPA)، ويدعم النشر في بيئات واقعية، مما يُتيح بناء سير عمل وكيل قابل للتوسع وآمن وجاهز للإنتاج.
رابط الورقة:https://go.hyper.ai/UaAXZ
5. تقرير فني عن برنامج IQuest-Coder-V1
تقترح هذه الورقة البحثية عائلة جديدة من نماذج اللغة الكبيرة (LLMs)، وهي سلسلة IQuest-Coder-V1 (7B/14B/40B/40B-Loop). على عكس تمثيلات الشفرة الثابتة التقليدية، يقترح الباحثون نموذج تدريب متعدد المراحل قائم على تدفق الشفرة، يرصد ديناميكيًا تطور منطق البرمجيات في مختلف مراحل خط الأنابيب. يُبنى النموذج من خلال خط أنابيب تدريب تطوري. سيساهم إصدار سلسلة IQuest-Coder-V1 بشكل كبير في تطوير الأبحاث في مجال ذكاء الشفرة المستقل وأنظمة الوكلاء الأذكياء في العالم الحقيقي.
رابط الورقة:https://go.hyper.ai/DBYN7
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
1. من خلال توليد بيانات مناخية لمدة 18000 عام، اقترحت NVIDIA وغيرها تقنية التقطير لمسافات طويلة، مما يتيح التنبؤ بالطقس على المدى الطويل من خلال عملية حسابية واحدة فقط.
قدّم فريق بحثي من شركة NVIDIA Research، بالتعاون مع جامعة واشنطن، طريقةً جديدةً للتقطير بعيد المدى. وتتلخص الفكرة الأساسية في استخدام نموذج الانحدار الذاتي، القادر على توليد تقلبات جوية واقعية، كـ"معلم" لتوليد كميات هائلة من البيانات المناخية الاصطناعية من خلال محاكاة سريعة ومنخفضة التكلفة. تُستخدم هذه البيانات بعد ذلك لتدريب نموذج "طالب" احتمالي. يُولّد نموذج الطالب تنبؤات طويلة المدى بحساب أحادي الخطوة، متجنبًا تراكم الأخطاء التكرارية ومتجاوزًا تحديات معايرة البيانات المعقدة. تُظهر التجارب الأولية أن أداء نموذج الطالب المُدرّب بهذه الطريقة يُضاهي أداء نظام التنبؤ المتكامل ECMWF في التنبؤات من فصل إلى فصل، ويستمر أداؤه في التحسن مع زيادة حجم البيانات الاصطناعية، مما يبشر بتنبؤات مناخية أكثر موثوقية واقتصادية في المستقبل.
شاهد التقرير الكامل:https://go.hyper.ai/Ljebq
2. أحدث خطاب لجنسن هوانغ: 5 ابتكارات، والكشف عن بيانات أداء روبين لأول مرة؛ ومصادر مفتوحة متنوعة، تغطي الوكلاء/الروبوتات/القيادة الذاتية/الذكاء الاصطناعي للأنظمة الذكية
مع بداية العام الجديد، انطلقت فعاليات معرض الإلكترونيات الاستهلاكية CES 2026، الذي يُعرف غالبًا باسم "مهرجان الربيع التقني"، في لاس فيغاس، الولايات المتحدة الأمريكية. ورغم أن جنسن هوانغ لم يكن ضمن قائمة المتحدثين الرئيسيين الرسمية في المعرض، إلا أنه شارك في العديد من الفعاليات. وكان من أبرزها عرضه التقديمي في مؤتمر NVIDIA LIVE. في عرضه الذي اختتمه مؤخرًا، قدّم هوانغ، مرتديًا سترته الجلدية السوداء المميزة، منصة Rubin التي تضم خمسة ابتكارات، وكشف عن العديد من الإنجازات مفتوحة المصدر. وتحديدًا: سلسلة NVIDIA Nemotron للذكاء الاصطناعي الوكيل؛ ومنصة NVIDIA Cosmos للذكاء الاصطناعي الفيزيائي؛ وسلسلة NVIDIA Alpamayo لأبحاث القيادة الذاتية؛ ومنصة NVIDIA Isaac GR00T للروبوتات؛ ومنصة NVIDIA Clara للمجال الطبي الحيوي.
شاهد التقرير الكامل:https://go.hyper.ai/YMK1J
3. قام بيزوس وبيل غيتس وشركة إنفيديا وشركة إنتل وغيرهم بالمراهنة؛ ويقود مهندسو ناسا فريقًا لإنشاء دماغ روبوتي للأغراض العامة، وتبلغ قيمة الشركة ملياري دولار.
بينما يمكن للنماذج الضخمة أن تنمو بلا حدود بفضل الإنترنت ومكتبات الصور والكميات الهائلة من النصوص، فإن الروبوتات محصورة في عالم آخر، حيث البيانات الواقعية نادرة للغاية ومكلفة وغير قابلة لإعادة الاستخدام. ولمعالجة قيود عدم كفاية حجم البيانات ومحدودية البنية في العالم المادي، اختارت FieldAI نهجًا مختلفًا عن استراتيجية التركيز على الإدراك السائدة. فهي تبني نظام ذكاء آلي متعدد الأغراض يرتكز على القيود الفيزيائية منذ البداية، بهدف تعزيز قدرة الروبوتات على التعميم والاستقلالية في بيئات العالم الحقيقي.
شاهد التقرير الكامل:https://go.hyper.ai/9T1rE
٤. إعادة كاملة | شانغهاي تشوانغتشي/تايل إيه آي/هواوي/مختبر المترجمات المتقدمة/إيه آي ٩ ستارز: غوص عميق في ممارسة تكنولوجيا مترجمات الذكاء الاصطناعي
في خضم التطور المتسارع لتقنية مُترجمات الذكاء الاصطناعي، تتواصل العديد من الدراسات والاستكشافات، مُراكمةً رؤىً ثاقبةً ومتكاملة. وفي هذا السياق، عُقدت الجلسة الثامنة من مؤتمر "لقاء مُترجمات الذكاء الاصطناعي" في 27 ديسمبر. استضافت هذه الجلسة خمسة خبراء من أكاديمية شنغهاي للابتكار، ومجتمع TileAI، وشركة Huawei HiSilicon، ومختبر Advanced Compiler Lab، وAI9Stars، لمشاركة خبراتهم في مختلف مراحل سلسلة التكنولوجيا، بدءًا من تصميم بنية البرمجيات وتطوير المُشغلات وصولًا إلى تحسين الأداء. وقدّم المتحدثون، مستندين إلى أبحاث فرقهم طويلة الأمد، عرضًا توضيحيًا لأساليب التنفيذ والمفاضلات بين مختلف المناهج التقنية في سيناريوهات واقعية، مما أضفى على المفاهيم المجردة أساسًا ملموسًا.
شاهد التقرير الكامل:https://go.hyper.ai/8ytqF
5. تحقيق تصميم ركيزة انتقائي للغاية: اكتشف معهد ماساتشوستس للتكنولوجيا وجامعة هارفارد أنماط انقسام البروتياز الجديدة باستخدام الذكاء الاصطناعي التوليدي.
اقترح معهد ماساتشوستس للتكنولوجيا وجامعة هارفارد بشكل مشترك CleaveNet، وهي عملية تصميم شاملة قائمة على الذكاء الاصطناعي تهدف إلى إحداث ثورة في النموذج الحالي لتصميم ركائز البروتياز من خلال العمل جنبًا إلى جنب مع النماذج التنبؤية والتوليدية، مما يوفر حلولًا جديدة تمامًا للبحوث الأساسية ذات الصلة والتطوير الطبي الحيوي.
شاهد التقرير الكامل:https://go.hyper.ai/tcYYZ
مقالات موسوعية شعبية
1. حلقة التفاعل بين الإنسان والآلة (HITL)
2. دمج الفرز التبادلي الفائق RRF
3. الملاحة المجسدة
4. الشبكة العصبية متعددة الطبقات
5. ضبط التعزيزات بدقة
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
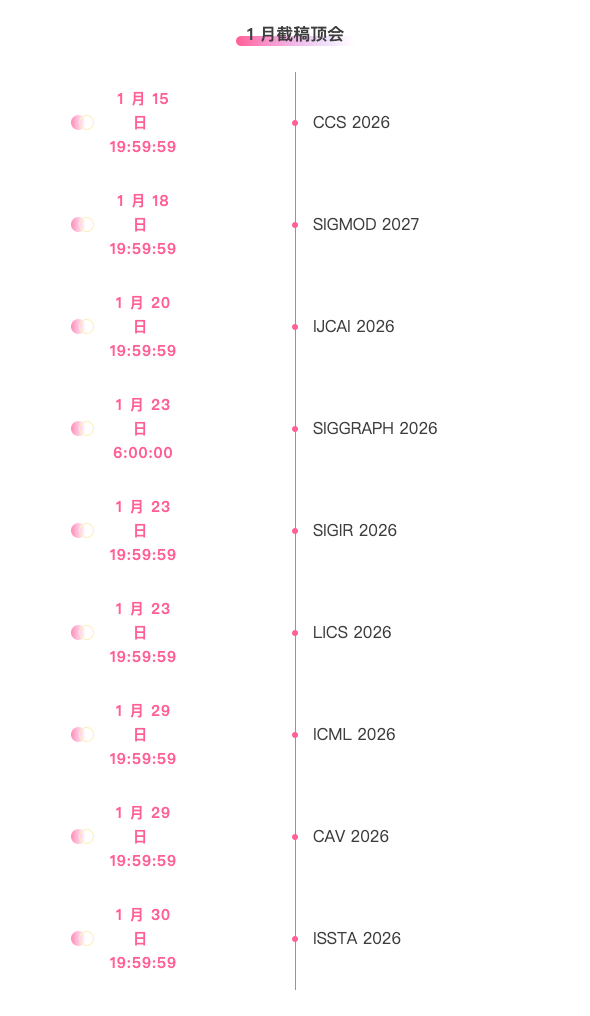
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








