Command Palette
Search for a command to run...
منصة تحليل مستندات متطورة جديدة! يُبتكر الإصدار الجديد من MinerU استراتيجية تحليل من مرحلتين "من الخشن إلى الدقيق"؛ ويُطلق معيار نطاق S2S لأول مرة! تُقيّم أحدث مجموعة بيانات معيارية من Tencent قدرات نموذج الكلام.

في موجة التحول الرقمي، تراكمت لدى كافة مناحي الحياة كميات هائلة من بيانات المستندات غير المنظمة، وخاصة الأوراق الأكاديمية والتقارير والنماذج وما إلى ذلك، بشكل أساسي بتنسيق PDF.إن تحويل هذه المستندات بكفاءة ودقة إلى بيانات منظمة قابلة للقراءة آليًا يعد شرطًا أساسيًا مهمًا لتحقيق استخراج المعلومات تلقائيًا وإدارة المستندات والتحليل الذكي، كما يعد خطوة أساسية في اكتشاف قيمة البيانات.
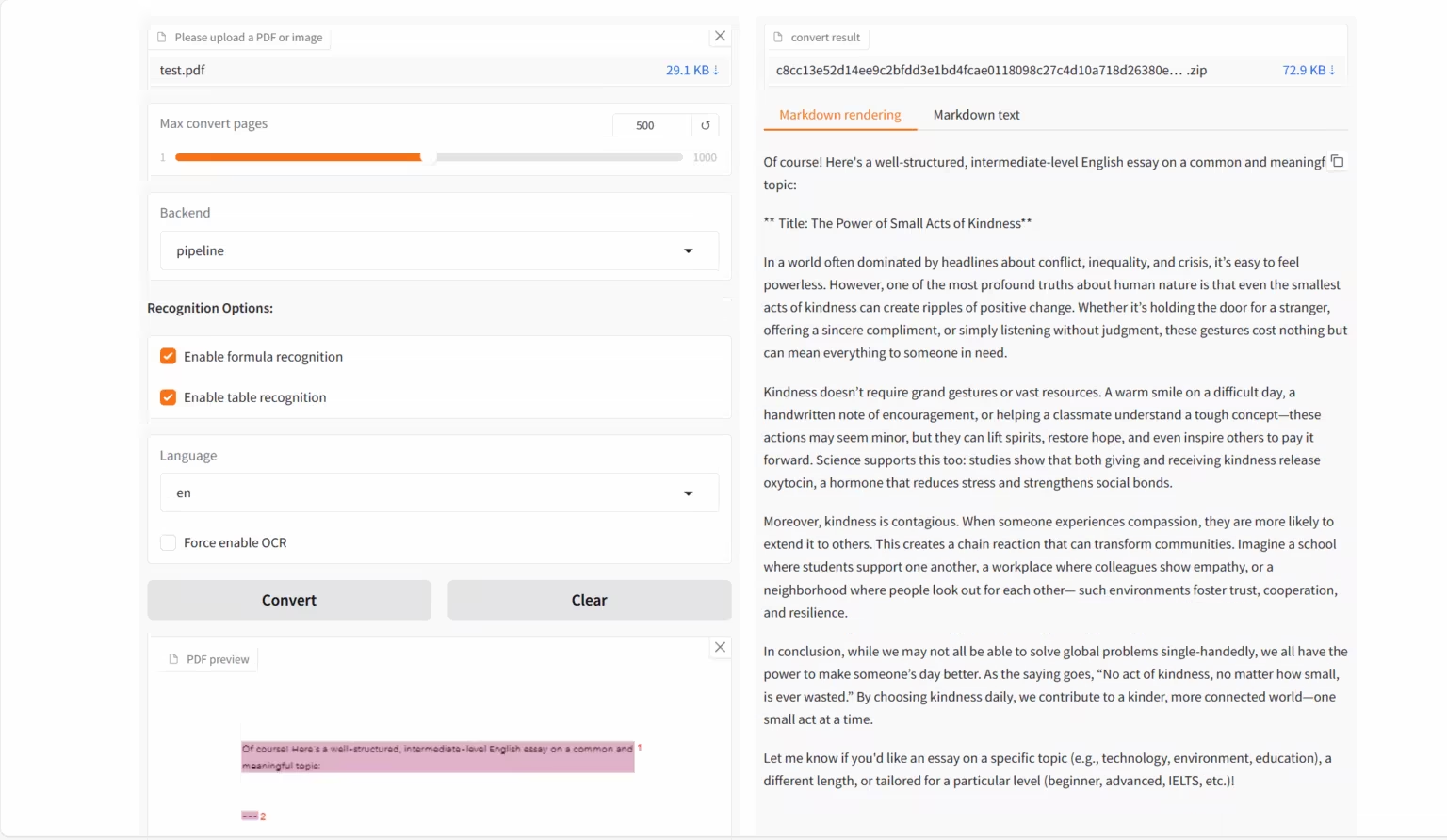
بناءً على الطلب المتزايد باستمرار على OCR،أطلق OpenDataLab ومختبر شنغهاي للذكاء الاصطناعي بشكل مشترك نموذج اللغة المرئية MinerU2.5-2509-1.2B.يركز على تحويل المستندات ذات التنسيقات المعقدة مثل PDF إلى بيانات منظمة قابلة للقراءة آليًا (مثل Markdown وJSON وما إلى ذلك)، وهو مصمم لمهام تحليل المستندات عالية الدقة وعالية الكفاءة.يحقق الإصدار الجديد من النموذج تحليلًا فعالًا من خلال استراتيجية مكونة من مرحلتين "من الخشن إلى الدقيق":تستخدم المرحلة الأولى تحليل تخطيط فعال لتحديد العناصر الهيكلية وتحديد إطار المستند؛ وتقوم المرحلة الثانية بإجراء التعرف الدقيق داخل المنطقة المقصوصة بالدقة الأصلية لضمان استعادة التفاصيل مثل النص والصيغ والجداول.
يقوم MinerU2.5-2509-1.2B بفصل تحليل التخطيط العالمي عن التعرف على المحتوى المحلي، مما يوضح إمكانيات تحليل المستندات القوية.إنه يتفوق على نماذج المجال العام والعمودي في مهام التعرف المتعددة.في الوقت نفسه، يُظهر هذا النظام مزايا كبيرة في تقليل التكاليف الحسابية. فهو ليس نموذجًا متفوقًا تقنيًا فحسب، بل أداة تُحسّن الكفاءة التقنية بشكل فعال، مُوفرةً دعمًا قويًا لاحتياجات المستخدمين النهائيين، مثل تحليل البيانات واسترجاع المعلومات وبناء نصوص البيانات.
أصدر الموقع الرسمي لـ HyperAI "MinerU2.5-2509-1.2B: عرض توضيحي لتحليل المستندات". جربه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/emEKs
من 13 أكتوبر إلى 17 أكتوبر، إليك نظرة عامة سريعة على تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة تعليمية عالية الجودة: 11
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* المؤتمر الأول مع الموعد النهائي في أكتوبر: 1
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. FDAbench - مجموعة بيانات معيارية لتحليل البيانات غير المتجانسة الكاملة
FDAbench-Full هو أول معيار مرجعي لتحليل البيانات غير المتجانسة لوكلاء البيانات، أصدرته جامعة نانيانغ التكنولوجية، والجامعة الوطنية في سنغافورة، وشركة هواوي تكنولوجيز المحدودة. ويهدف إلى تقييم قدرات النموذج في توليد استعلامات قاعدة البيانات، وفهم SQL، وتحليل البيانات المالية.
الاستخدام المباشر:https://go.hyper.ai/AUjv5
2. مجموعة بيانات التقييم الطبي متعدد الوسائط PubMedVision
PubMedVision هي مجموعة بيانات لتقييم القدرات الطبية متعددة الوسائط، تغطي مجموعة متنوعة من وسائل التصوير الطبي والمناطق التشريحية. تهدف إلى توفير موارد اختبار موحدة لنماذج اللغة الكبيرة متعددة الوسائط (MLLMs) في مهام فهم النصوص البصرية الطبية، لاختبار قدرتها على دمج المعرفة البصرية وأدائها الاستدلالي في المجال الطبي.
الاستخدام المباشر:https://go.hyper.ai/qdvVe
3. مجموعة بيانات تقييم توليد الوصلات السمعية والبصرية من Verse-Bench
Verse-Bench هي مجموعة بيانات مرجعية لتقييم التوليد المشترك للصوت والفيديو، أصدرتها StepFun بالتعاون مع جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو)، ومؤسسات أخرى. تهدف هذه المجموعة إلى تمكين النماذج التوليدية ليس فقط من توليد مقاطع الفيديو، بل أيضًا من الحفاظ على تناغم زمني دقيق مع محتوى الصوت (بما في ذلك الصوت المحيط والكلام).
الاستخدام المباشر:https://go.hyper.ai/mvau0

4. مجموعة بيانات معيارية لتوليد الفيديو التعليمي MMMC
MMMC هي مجموعة بيانات مرجعية واسعة النطاق ومتعددة التخصصات لتوليد مقاطع الفيديو التعليمية، أصدرها مختبر Show Lab التابع للجامعة الوطنية في سنغافورة. تهدف إلى توفير موارد تدريب وتقييم عالية الجودة لنماذج الذكاء الاصطناعي التعليمية، ودعم الأبحاث المتعلقة بالتوليد التلقائي لمقاطع فيديو تعليمية احترافية من برمجيات ومحتوى تعليمي مُهيكل.
الاستخدام المباشر:https://go.hyper.ai/AELav
5. مجموعة بيانات معيارية لتوليد الصور متعددة الوسائط T2I-CoReBench
T2I-CoReBench هو معيار تقييم شامل لنماذج توليد الصور النصية، اقترحته جامعة العلوم والتكنولوجيا الصينية، وفريق كلينج التابع لشركة كوايشو للتكنولوجيا، وجامعة هونغ كونغ. يهدف إلى قياس قدرات نماذج توليد الصور على الجمع والاستدلال في آنٍ واحد.
الاستخدام المباشر:https://go.hyper.ai/SLyED
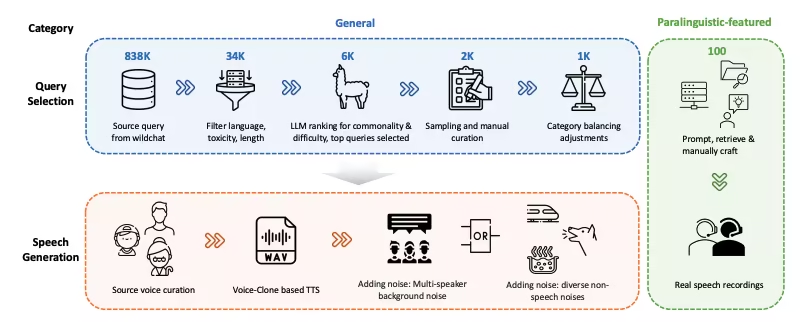
6. مجموعة بيانات WildSpeech-Bench لفهم الكلام وتوليده
WildSpeech-Bench هو أول معيار أصدرته Tencent لتقييم قدرات SpeechLLM في تحويل الكلام إلى كلام. يهدف إلى قياس قدرة النموذج على فهم وتوليد تحويل الكلام إلى كلام كامل (S2S) في سيناريوهات التفاعل الصوتي الحقيقي.
الاستخدام المباشر:https://go.hyper.ai/Cy63e
7. مجموعة بيانات إعادة رسم خريطة حركة الروبوت العالمية OmniRetarget
OmniRetarget هي مجموعة بيانات مسارات عالية الجودة لإعادة رسم خريطة حركة الجسم بالكامل للروبوتات البشرية، أصدرتها أمازون بالتعاون مع معهد ماساتشوستس للتكنولوجيا (MIT) وجامعة كاليفورنيا، بيركلي، ومؤسسات أخرى. تحتوي المجموعة على مسارات حركة الروبوت البشري G1 عند تفاعله مع الأجسام والتضاريس المعقدة، وتغطي ثلاثة سيناريوهات: حمل الروبوت للأجسام، والمشي على التضاريس، والتفاعل المختلط بين الأجسام والتضاريس.
الاستخدام المباشر:https://go.hyper.ai/xfZY4

8. بيانات معيارية لفيديو Paper2Video
Paper2Video هي أول مجموعة بيانات مرجعية لأزواج الأوراق والفيديوهات تُصدرها جامعة سنغافورة الوطنية. تهدف إلى توفير مرجع معياري للتقييم والقياس لمهمة إنشاء مقاطع فيديو للعروض التقديمية تلقائيًا (بما في ذلك الشرائح والترجمات والصوت وصور المتحدثين) من الأوراق الأكاديمية.
الاستخدام المباشر:https://go.hyper.ai/NeRuV
9. مجموعة بيانات التقييم متعدد الوسائط لـ FoMER Bench
FoMER Bench هو معيار أساسي لنموذج التفكير المجسد (FoMER) يغطي ثلاثة أنواع مختلفة من الروبوتات وأوضاع روبوت متعددة، وهو مصمم لتقييم قدرة التفكير لدى LMMs في سيناريوهات صنع القرار المجسدة المعقدة.
الاستخدام المباشر:https://go.hyper.ai/Tiy5w
١٠. مجموعة بيانات معيار التعرف على النصوص OCRBench-v2
OCRBench-v2 هو معيار معياري متعدد الوسائط للتعرف الضوئي على الحروف (OCR) واسع النطاق، أصدرته جامعة هواتشونغ للعلوم والتكنولوجيا بالتعاون مع جامعة جنوب الصين للتكنولوجيا، وشركة بايت دانس، ومؤسسات أخرى. يهدف إلى تقييم قدرات التعرف الضوئي على الحروف (OCR) لنماذج متعددة الوسائط كبيرة الحجم (LMMs) في مهام نصية مختلفة.
الاستخدام المباشر:https://go.hyper.ai/hhGFR
دروس تعليمية عامة مختارة
هذا الأسبوع، قمنا بتلخيص 4 فئات من الدروس التعليمية العامة عالية الجودة:
* دروس التعرف الضوئي على الحروف: 2
* دروس AI4S: 2
* نموذج تعليمي كبير: 1
* دروس تعليمية متعددة الوسائط: 6
برنامج تعليمي للتعرف الضوئي على الحروف (OCR)
1. MinerU2.5-2509-1.2B: عرض توضيحي لتحليل المستندات
MinerU 2.5-2509-1.2B هو نموذج لغوي بصري طورته OpenDataLab ومختبر شنغهاي للذكاء الاصطناعي، وهو مصمم خصيصًا لتحليل المستندات بدقة وكفاءة عالية. وهو أحدث إصدار من سلسلة MinerU، ويركز على تحويل صيغ المستندات المعقدة، مثل PDF، إلى بيانات منظمة وقابلة للقراءة آليًا (مثل Markdown وJSON).
تشغيل عبر الإنترنت:https://go.hyper.ai/emEKs
2. تحليل صور المستندات متعددة الوسائط باستخدام دولفين
دولفين هو نموذج تحليل مستندات متعدد الوسائط، طوّره فريق بايت دانس. يعتمد هذا النموذج على مرحلتين: تحليل البنية أولاً، ثم تحليل المحتوى. تُولّد المرحلة الأولى سلسلة من عناصر تخطيط المستند، بينما تستخدم المرحلة الثانية هذه العناصر كمرسيات لتحليل المحتوى بالتوازي. وقد أظهر دولفين أداءً متميزًا في مجموعة متنوعة من مهام تحليل المستندات، متجاوزًا نماذج مثل GPT-4.1 وMistral-OCR.
تشغيل عبر الإنترنت: https://go.hyper.ai/lLT6X

برنامج تعليمي AI4S
1. BindCraft: تصميم رابط البروتين
BindCraft، وهو خط أنابيب مفتوح المصدر لتصميم رابط بروتيني بنقرة واحدة، طوره مارتن باسيسا، يحقق معدل نجاح تجريبيًا يتراوح بين 10 و100%. يستخدم هذا الخط أوزان AlphaFold2 المُدربة مسبقًا لتوليد رابطات نانومولية جديدة بتقنية الحاسوب، مما يُغني عن الفحص عالي الإنتاجية، والتكرار التجريبي، أو حتى الحاجة إلى مواقع ربط معروفة.
تشغيل عبر الإنترنت:https://go.hyper.ai/eSoHk
2. Ml-simplefold: نموذج ذكاء اصطناعي خفيف الوزن للتنبؤ بطي البروتين
Ml-simplefold هو نموذج ذكاء اصطناعي خفيف الوزن للتنبؤ بطي البروتينات، أطلقته شركة Apple. يعتمد النموذج على تقنية مطابقة التدفق، ويتجاوز الوحدات المعقدة مثل محاذاة التسلسلات المتعددة (MSA)، ويُولّد مباشرةً البنية ثلاثية الأبعاد للبروتينات من الضوضاء العشوائية، مما يُخفّض تكاليف الحوسبة بشكل كبير.
تشغيل عبر الإنترنت: https://go.hyper.ai/Y0Us9
برنامج تعليمي للنماذج الكبيرة
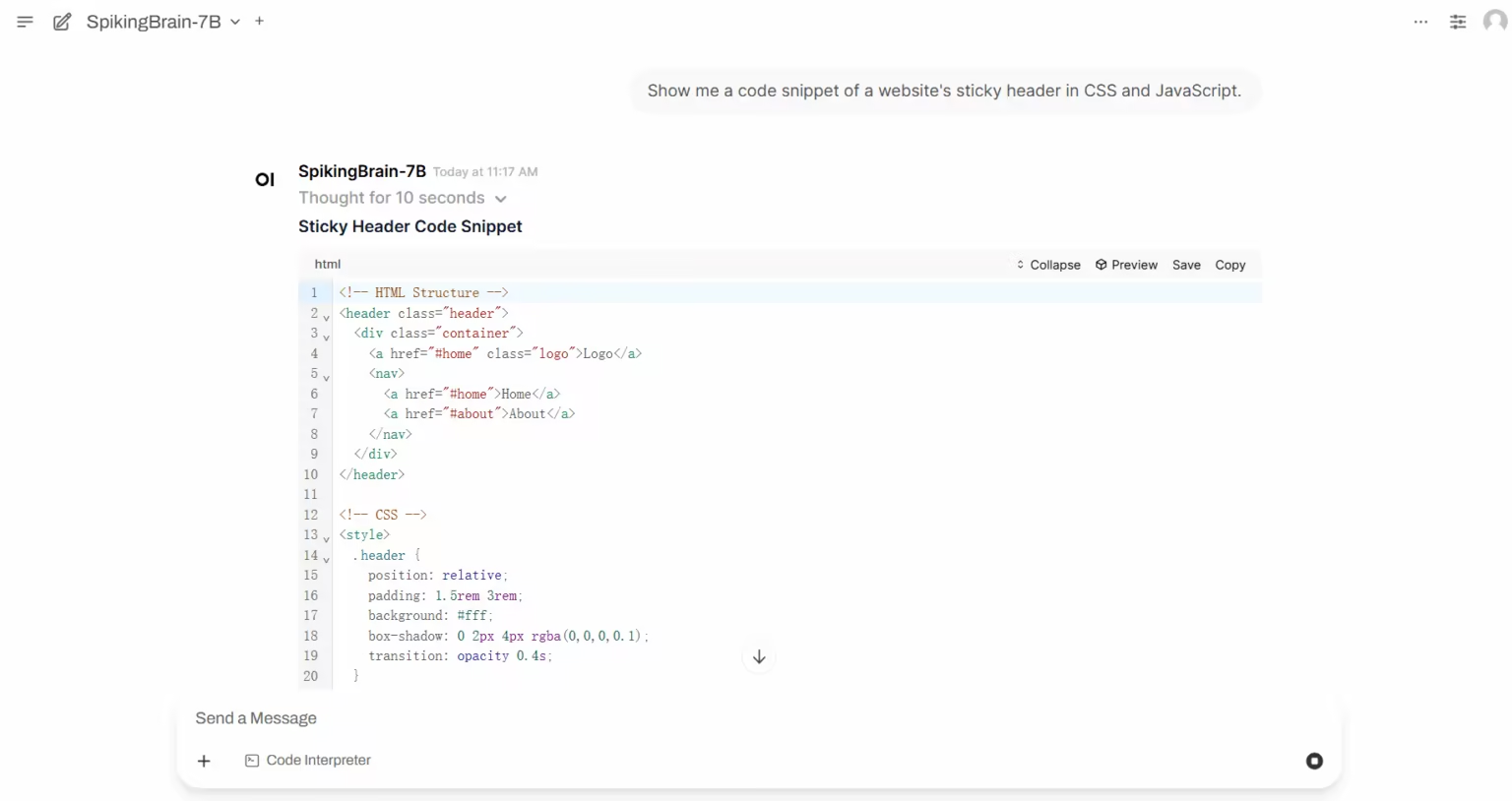
1. SpikingBrain-1.0: نموذج دماغي ضخم يشبه الأشواك، ويعتمد على التعقيد الجوهري
SpikingBrain-1.0 هو نموذجٌ ضخمٌ مُطوّرٌ محليًا للتحكم في الإشارات العصبية، مستوحىً من الدماغ، وأصدره معهد الأتمتة التابع للأكاديمية الصينية للعلوم، بالتعاون مع المختبر الوطني الرئيسي للإدراك الدماغي والذكاء المُستلهم من الدماغ، وشركة Muxi Integrated Circuit Co., Ltd.، ومؤسسات أخرى. هذا النموذج، المُستوحى من آليات الدماغ، يدمج آلية انتباه هجينة عالية الكفاءة، ووحدة MoE، وترميز الإشارات العصبية في بنيته، مدعومًا بخط أنابيب تحويل عالمي متوافق مع نظام النماذج مفتوح المصدر.
تشغيل عبر الإنترنت:https://go.hyper.ai/i3zHC
برنامج تعليمي متعدد الوسائط
1. HuMo-1.7B: إطار عمل لتوليد الفيديو متعدد الوسائط
HuMo هو إطار عمل متعدد الوسائط لتوليد الفيديو، طورته جامعة تسينغهوا ومختبر الإبداع الذكي التابع لشركة بايت دانس. يركز هذا الإطار على توليد فيديوهات تتمحور حول الإنسان، ويمكنه توليد فيديوهات عالية الجودة ومفصلة وقابلة للتحكم، تُشبه الفيديوهات البشرية، من خلال مدخلات متعددة الوسائط، بما في ذلك النصوص والصور والصوت.
تشغيل عبر الإنترنت:https://go.hyper.ai/Xe4dM
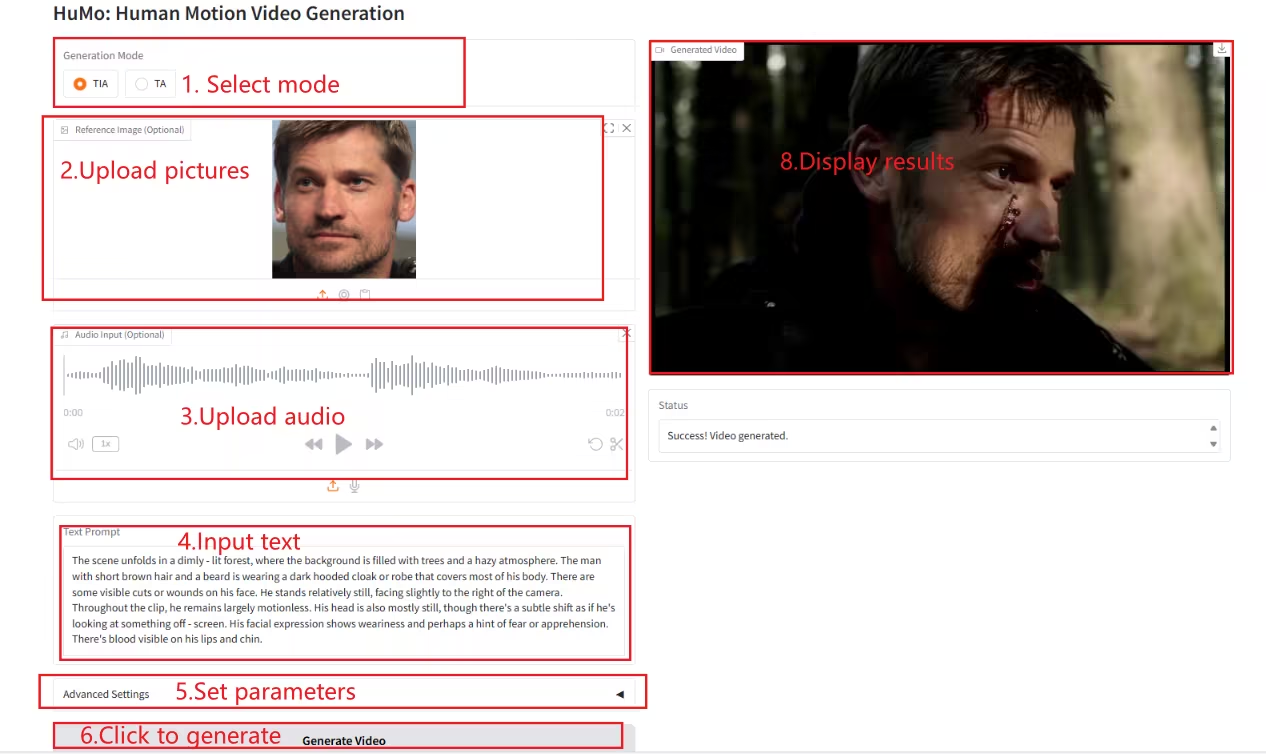
2. NeuTTS-Air: نموذج استنساخ صوتي خفيف الوزن وفعال
NeuTTS-Air هو نموذج تحويل نص إلى كلام (TTS) متكامل من شركة Neuphonic. يعتمد على بنية Qwen LLM الأساسية بسرعة 0.5B وترميز الصوت NeuCodec، ويُظهر قدرات تعلم سريعة في النشر على الجهاز واستنساخ الصوت الفوري. تُظهر تقييمات النظام أن NeuTTS Air يحقق أداءً متطورًا مقارنةً بالنماذج مفتوحة المصدر، وخاصةً في معايير التوليف فائقة الواقعية والاستدلال الفوري.
تشغيل عبر الإنترنت:https://go.hyper.ai/7ONYq
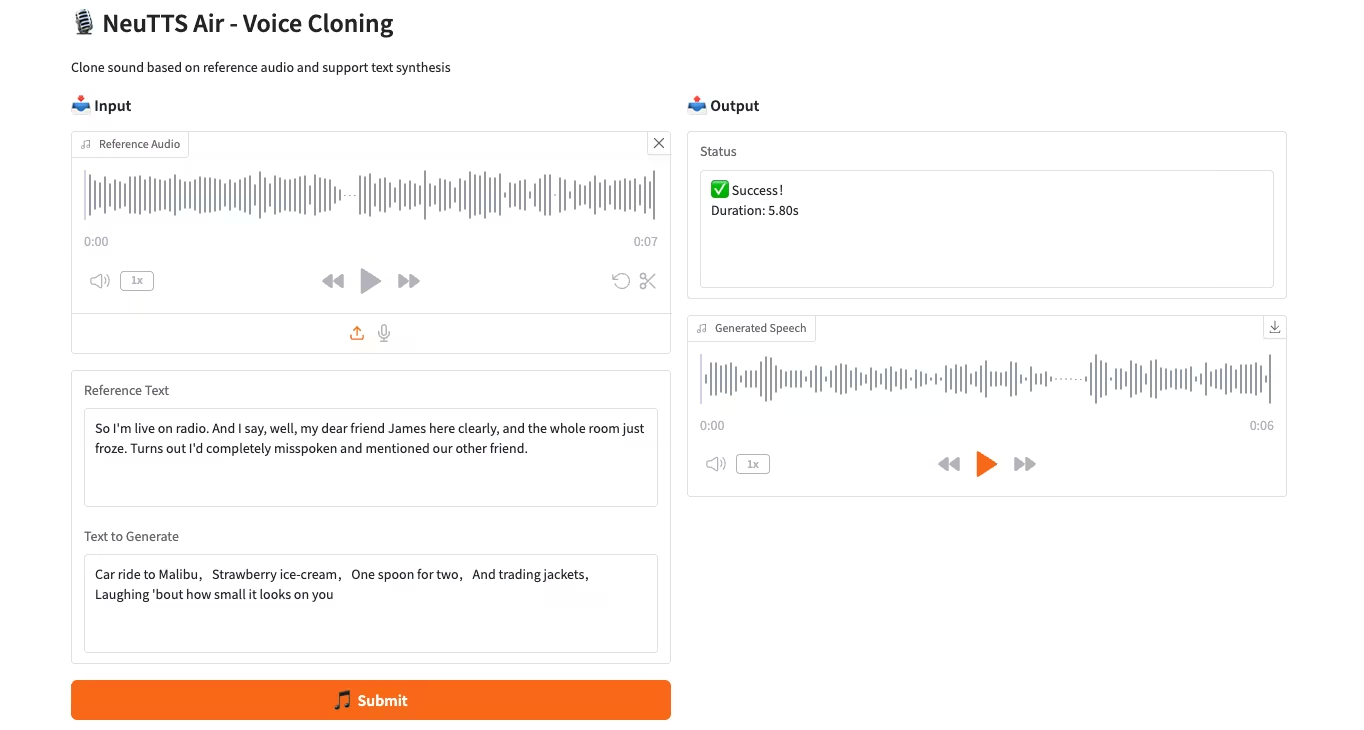
٣. معاينة Moondream3: نموذج فهم اللغة البصرية المعياري
Moondream3، وهو نموذج لغة بصرية قائم على بنية خبيرة هجينة اقترحها فريق Moondream، يضم 9 مليارات معلمة (ملياران منها معلمات تنشيط). يوفر هذا النموذج إمكانيات استدلال بصري متطورة، ويدعم طول سياق أقصى يبلغ 32 كيلوبايت، ويمكنه معالجة الصور عالية الدقة بكفاءة.
تشغيل عبر الإنترنت:https://go.hyper.ai/eKGcP
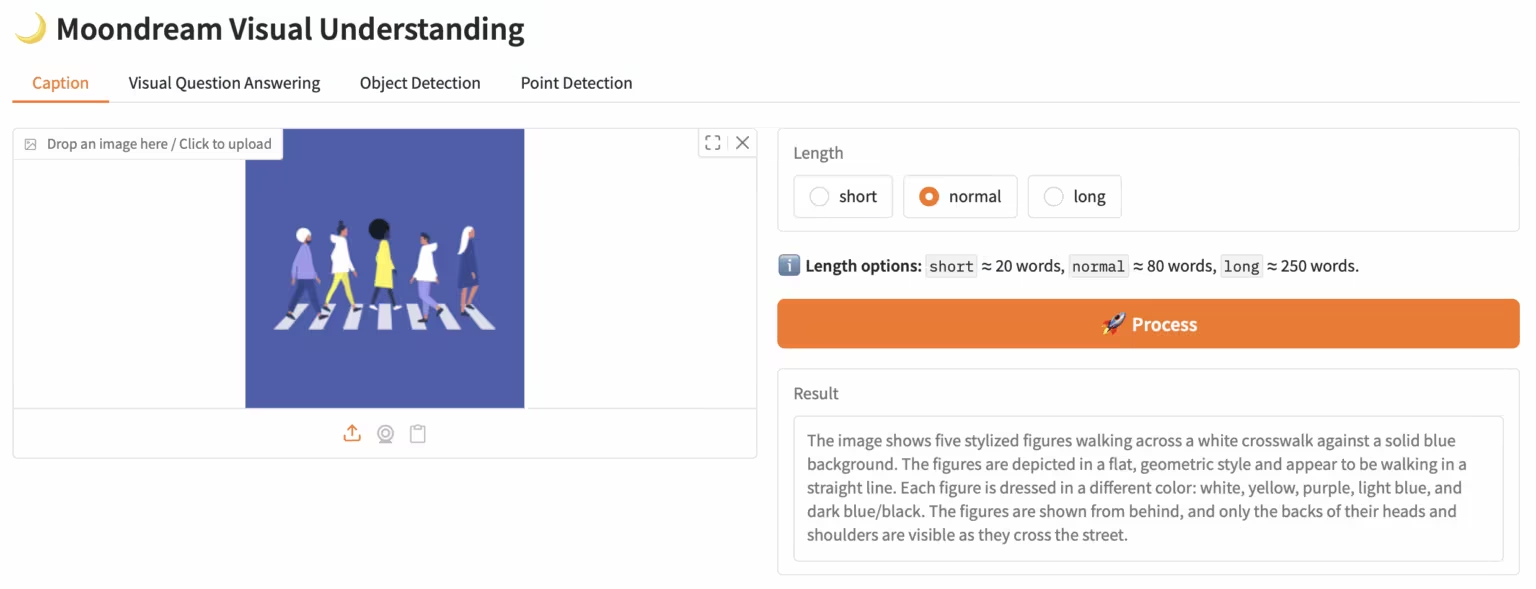
4. LiveCC: نموذج كبير للتعليق على الفيديو في الوقت الفعلي
LiveCC هو مشروع نموذج لغة فيديو يركز على نسخ الكلام عبر البث المباشر على نطاق واسع. يهدف المشروع إلى تدريب أول نموذج لغة فيديو مزود بإمكانيات التعليق الفوري من خلال طريقة بث مبتكرة للتعرف التلقائي على الكلام (ASR). وقد حقق المشروع أحدث التقنيات في كل من معايير البث المباشر وغير المباشر.
تشغيل عبر الإنترنت:https://go.hyper.ai/3Gdr2
5. Hunyuan3D-Part: نموذج توليدي ثلاثي الأبعاد قائم على المكونات
Hunyuan3D-Part، نموذج توليدي ثلاثي الأبعاد طوره فريق Tencent Hunyuan، يتكون من P3-SAM وX-Part. وقد كان رائدًا في توليد نماذج ثلاثية الأبعاد عالية الدقة وقابلة للتحكم، قائمة على المكونات، داعمًا التوليد التلقائي لأكثر من 50 مكونًا. له تطبيقات واسعة في مجالات مثل نمذجة الألعاب والطباعة ثلاثية الأبعاد، مثل فصل نموذج سيارة إلى هيكلها وعجلاتها لتسهيل منطق التمرير الخاص باللعبة أو الطباعة ثلاثية الأبعاد خطوة بخطوة.
تشغيل عبر الإنترنت:https://go.hyper.ai/1w1Jq

6. HunyuanImage-2.1: نموذج انتشار لصور Wensheng عالية الدقة (2K)
HunyuanImage-2.1 هو نموذج صور نصي مفتوح المصدر، طوّره فريق Tencent Hunyuan. يدعم دقة 2K الأصلية، ويتمتع بقدرات قوية لفهم الدلالات المعقدة، مما يُمكّن من توليد تفاصيل المشهد، وتعبيرات الشخصيات، والحركات بدقة. يدعم النموذج الإدخال باللغتين الصينية والإنجليزية، ويمكنه توليد صور بأنماط متنوعة، مثل القصص المصورة وشخصيات الحركة، مع الحفاظ على تحكم دقيق في النصوص والتفاصيل داخل الصور.
تشغيل عبر الإنترنت:https://go.hyper.ai/i96yp
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

توصيات الورقة البحثية لهذا الأسبوع
1. QeRL: ما وراء الكفاءة - التعلم التعزيزي المُعزز بالكمية لطلاب الماجستير في القانون
تقترح هذه الورقة البحثية إطار عمل للتعلم التعزيزي المُحسَّن بالكمية لنماذج اللغات الكبيرة. من خلال الجمع بين التكميم NVFP4 والتكيف منخفض الرتبة (LoRA)، يُسرِّع هذا النموذج مرحلة أخذ العينات من التعلم التعزيزي مع تقليل العبء على الذاكرة بشكل كبير. يُعد QeRL أول إطار عمل قادر على تدريب نماذج التعلم التعزيزي الكبيرة باستخدام 32 مليار معلمة (32B) على وحدة معالجة رسومية واحدة H100 بسعة 80 جيجابايت، مع تحسين سرعة التدريب الإجمالية.
رابط الورقة: https://go.hyper.ai/catLh
2. محولات الانتشار مع مشفرات التمثيل التلقائي
يستكشف هذا البحث استبدال نماذج VAEs بمشفرات تمثيل مُدرَّبة مسبقًا (مثل DINO وSigLIP وMAE) مع فك تشفير مُدرَّب مسبقًا لبناء بنية جديدة نُسمِّيها مُشفرات التمثيل التلقائي (RAEs). لا تُحقق هذه النماذج إعادة بناء عالية الجودة فحسب، بل تمتلك أيضًا مساحة كامنة غنية دلاليًا، وتدعم تصميم بنية قابلة للتطوير قائمة على المحول.
رابط الورقة: https://go.hyper.ai/fqVs4
3. D2E: توسيع نطاق التدريب المسبق للرؤية والفعل على بيانات سطح المكتب لنقلها إلى الذكاء الاصطناعي المتجسد
تقترح هذه الورقة إطار عمل D2E (الذكاء الاصطناعي من سطح المكتب إلى الذكاء الاصطناعي المُجسَّد)، مُبيِّنةً أن تفاعل سطح المكتب يُمكن أن يُشكِّل أساسًا فعّالًا للتدريب المسبق لمهام الذكاء الاصطناعي المُجسَّد الروبوتية. وخلافًا للمناهج السابقة التي تقتصر على مجالات مُحددة أو مُحاطة بالبيانات، يُرسي إطار D2E سلسلة تقنية كاملة، بدءًا من جمع بيانات سطح المكتب القابلة للتطوير، ووصولًا إلى التحقق من النطاق المُجسَّد ونقل البيانات.
رابط الورقة: https://go.hyper.ai/aNbE4
4. التفكير بالكاميرا: نموذج موحد متعدد الوسائط لفهم وتوليد المعلومات المرتكزة على الكاميرا
تقترح هذه الورقة Puffin، وهو نموذج موحد متعدد الوسائط يركز على الكاميرا ويمتد الإدراك المكاني على طول بُعد الكاميرا، ويدمج انحدار اللغة مع تقنيات التوليد القائمة على الانتشار، ويمكنه تحليل المشاهد وتوليدها من وجهات نظر عشوائية.
رابط الورقة: https://go.hyper.ai/9JBvw
5. DITING: إطار عمل تقييمي متعدد الوكلاء لقياس أداء ترجمة الروايات على شبكة الإنترنت
تقترح هذه الورقة البحثية نظام DITING، وهو أول إطار تقييم شامل لترجمة الروايات عبر الإنترنت. يُقيّم هذا الإطار منهجيًا الاتساق السردي والنزاهة الثقافية للترجمات وفق ستة أبعاد: ترجمة المصطلحات الاصطلاحية، ومعالجة الغموض المعجمي، وتوطين المصطلحات، واتساق الزمن، وحل الضمائر، والسلامة الثقافية. ويدعمه أكثر من 18,000 زوج من الجمل الصينية-الإنجليزية المُعلّق عليها من قِبل خبراء.
رابط الورقة:https://go.hyper.ai/KRUmn
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
1. اقترحت جامعة هونج كونج للعلوم والتكنولوجيا وآخرون نموذج التنبؤ بالطقس التدريجي VA-MoE، والذي يحتوي على 751 معلمة مبسطة ولا يزال يحقق أداءً متطورًا.
طورت فرق بحثية من جامعة هونغ كونغ للعلوم والتكنولوجيا وجامعة تشجيانغ نموذج "مزيج الخبراء المتكيف المتغير" (VA-MoE). يستخدم هذا النموذج التدريب التدريجي وتضمين مؤشر المتغير لتوجيه وحدات الخبراء المختلفة للتركيز على متغيرات جوية محددة. عند إضافة متغيرات أو محطات جديدة، يمكن توسيع النموذج دون الحاجة إلى إعادة تدريب كاملة، مما يقلل بشكل كبير من التكلفة الحسابية مع الحفاظ على الدقة.
شاهد التقرير الكامل:https://go.hyper.ai/nPWPN
٢. NeurIPS ٢٠٢٥ | أصدرت جامعة هواتشونغ للعلوم والتكنولوجيا وآخرون الإصدار الثاني من OCRBench. حلّ جيميني في المركز الأول في التصنيف الصيني، لكنه لم يحصل إلا على درجة النجاح.
أطلق فريق باي شيانغ من جامعة هواتشونغ للعلوم والتكنولوجيا، بالتعاون مع جامعة جنوب الصين للتكنولوجيا وجامعة أديلايد وبايت دانس، معيار تقييم OCR من الجيل التالي OCRBench v2، والذي قام بتقييم 58 نموذجًا متعدد الوسائط رئيسيًا في جميع أنحاء العالم من عام 2023 إلى عام 2025 باللغتين الصينية والإنجليزية.
شاهد التقرير الكامل:https://go.hyper.ai/AL1ZJ
3. تم اختيار إطار عمل Ctrl-DNA لمؤتمر NeurIPS 2025، واقترحته جامعة تورنتو وآخرون لتحقيق "التحكم المستهدف" في التعبير الجيني في خلايا محددة.
قام فريق من جامعة تورنتو، بالتعاون مع مختبر تشانجبينج، بتطوير إطار عمل للتعلم التعزيزي المقيد يسمى Ctrl-DNA، والذي يمكنه تعظيم النشاط التنظيمي لـ CRE في الخلايا المستهدفة مع الحد بشكل صارم من نشاطه في الخلايا غير المستهدفة.
شاهد التقرير الكامل:https://go.hyper.ai/eVORr
٤. يتنبأ الذكاء الاصطناعي بتسرب البلازما. يستخدم معهد ماساتشوستس للتكنولوجيا (MIT) وجهات أخرى تقنيات التعلم الآلي لتحقيق تنبؤات عالية الدقة لديناميكيات البلازما باستخدام عينات صغيرة الحجم.
استخدم فريق بحثي بقيادة معهد ماساتشوستس للتكنولوجيا (MIT) تقنيات التعلم الآلي العلمية لدمج قوانين الفيزياء بذكاء مع البيانات التجريبية. وطوّر الفريق نموذجًا عصبيًا للفضاء-الحالة، قادر على التنبؤ بديناميكيات البلازما وعدم الاستقرار المحتمل أثناء عملية تخفيض متغير تكوين توكاماك (TCV) باستخدام الحد الأدنى من البيانات.
شاهد التقرير الكامل:https://go.hyper.ai/HQgZx
5. هيكل MOF يفوز بجائزة نوبل بعد 36 عامًا: عندما تفهم الذكاء الاصطناعي الكيمياء، تتحرك الأطر المعدنية العضوية نحو عصر البحث التوليدي.
في 8 أكتوبر 2025، مُنح كلٌ من سوسومو كيتاغاوا وريتشارد روبسون وعمر ياغي جائزة نوبل في الكيمياء لمساهماتهم في مجال الأطر المعدنية العضوية (MOFs). على مدى العقود الثلاثة الماضية، تطور مجال الأطر المعدنية العضوية من التصميم الإنشائي إلى التصنيع، ممهدًا بذلك الطريق للكيمياء القابلة للحوسبة. واليوم، يُعيد الذكاء الاصطناعي صياغة أبحاث الأطر المعدنية العضوية من خلال النماذج التوليدية وخوارزميات الانتشار، مُبشرًا بعصر جديد من التصميم الكيميائي.
شاهد التقرير الكامل:https://go.hyper.ai/U5XgN
مقالات موسوعية شعبية
1. دال-إي
2. الشبكات الفائقة
3. جبهة باريتو
4. الذاكرة طويلة المدى ثنائية الاتجاه (Bi-LSTM)
5. اندماج الرتب المتبادلة
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
الموعد النهائي للمؤتمر هو شهر أكتوبر

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1800 مجموعة بيانات عامة
* يتضمن أكثر من 600 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* يدعم البحث عن أكثر من 600 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








