Command Palette
Search for a command to run...
تقرير أسبوعي عن أبحاث الذكاء الاصطناعي | تفسير تقنية التعرف الضوئي على الأحرف المتطورة: تتنافس شركات DeepSeek وTencent وBaidu على نفس الساحة، من التعرف على الأحرف إلى تحليل المستندات المهيكلة

على مدى السنوات القليلة الماضية، تطورت تقنية التعرف الضوئي على الأحرف (OCR) بسرعة من "أداة للتعرف على الأحرف" إلى...نظام عام لفهم المستندات يعتمد على نموذج الرؤية واللغةبينما تواصل الشركات العالمية مثل مايكروسوفت وجوجل الاستثمار، يقوم البائعون الصينيون الرائدون مثل بايدو وتينسنت وعلي بابا كلاود أيضًا بعمليات نشر مكثفة، مما يدفع السوق إلى الترقية بسرعة من تقنية التعرف الضوئي على الأحرف (OCR) القائمة على القواعد إلى معالجة المستندات الذكية (IDP) التي تدمج الذكاء الاصطناعي ومعالجة اللغة الطبيعية، وتعميق تطبيقها باستمرار في سيناريوهات الأعمال الحقيقية مثل التمويل والشؤون الحكومية والرعاية الصحية.
نتيجةً للطلب المستمر من الصناعة، تغير تركيز أبحاث التعرف الضوئي على الأحرف بشكل كبير أيضًا:لم يعد النموذج يسعى فقط إلى "دقة التعرف"، بل بدأ في حل المشكلات الأكثر صعوبة بشكل منهجي مثل التخطيطات المعقدة والرموز متعددة الوسائط ونمذجة السياق الطويل والفهم الدلالي من البداية إلى النهاية.أصبحت كيفية ترميز المعلومات المرئية ثنائية الأبعاد بكفاءة، وتحليل المعلومات النصية بكفاءة أكبر، وكيفية جعل ترتيب قراءة النموذج أقرب إلى المنطق الإدراكي البشري، قضايا أساسية ذات أهمية مشتركة للأوساط الأكاديمية والصناعية.
في ظل هذا التفاعل العالي، يعد التتبع والتحليل المستمر لأحدث الأوراق الأكاديمية بتقنية التعرف الضوئي على الحروف (OCR) أمرًا بالغ الأهمية لفهم التوجهات التكنولوجية المتطورة، وفهم التحديات الحقيقية للصناعة، وحتى إيجاد المرحلة التالية من الاختراقات النموذجية.
نوصي هذا الأسبوع بخمس أوراق بحثية شائعة حول الذكاء الاصطناعي في مجال التعرف الضوئي على الأحرف (OCR).يضم هذا الفريق فرقًا من DeepSeek وTencent وجامعة تسينغهوا وغيرها. هيا نتعلم معًا! ⬇️
بالإضافة إلى ذلك، ولتمكين المزيد من المستخدمين من فهم أحدث التطورات في مجال الذكاء الاصطناعي في الأوساط الأكاديمية، أطلق موقع HyperAI الإلكتروني (hyper.ai) قسم "أحدث الأوراق البحثية"، والذي يتم تحديثه يوميًا بأحدث أوراق البحث في مجال الذكاء الاصطناعي.
أحدث أبحاث الذكاء الاصطناعي:https://go.hyper.ai/hzChC
توصيات الورقة البحثية لهذا الأسبوع
- DeepSeek-OCR 2: التدفق السببي المرئي
استنادًا إلى تقنية DeepSeek-OCR، اقترح باحثو DeepSeek-AI تقنية DeepSeek-OCR 2. فإذا كانت DeepSeek-OCR بمثابة استكشاف أولي لجدوى ضغط النصوص الطويلة عبر رسم الخرائط البصرية ثنائية الأبعاد، فإن DeepSeek-OCR 2 تهدف إلى استكشاف جدوى استخدام مُشفِّر جديد - DeepEncoderV2 - يُعيد ترتيب الرموز المرئية ديناميكيًا بناءً على دلالات الصورة. صُمِّم DeepEncoder V2 لتزويد المُشفِّر بقدرات الاستدلال السببي، مما يُمكِّنه من إعادة ترتيب الرموز المرئية بذكاء قبل فهم المحتوى القائم على نموذج اللغة واللغة (LLM)، ليحل محل معالجة المسح النقطي الجامدة. وهذا يُحقق فهمًا للصور أقرب إلى الفهم البشري وأكثر تماسكًا دلاليًا، مما يُحسِّن قدرات التعرف الضوئي على الأحرف (OCR) وتحليل المستندات.
ورقة وتفسير مفصل:https://go.hyper.ai/ChW45
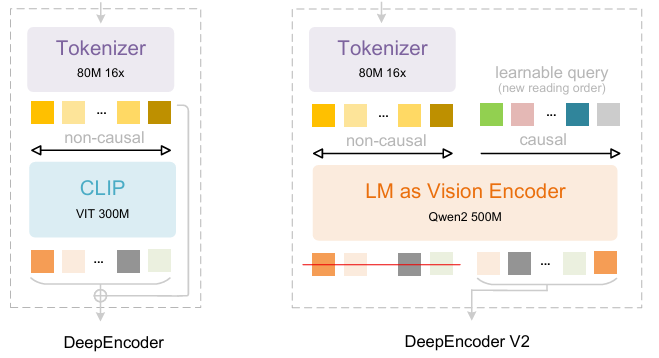
تتألف مجموعة بيانات التدريب من بيانات التعرف الضوئي على الحروف (OCR) الإصدار 1.0، والإصدار 2.0، وبيانات الرؤية العامة، حيث تمثل بيانات التعرف الضوئي على الحروف 80% من بيانات التدريب المختلطة. وللتقييم، استُخدم برنامج OmniDocBench الإصدار 1.5، وهو معيار مرجعي يحتوي على 1355 صفحة من الوثائق الصينية والإنجليزية، تشمل المجلات والأوراق الأكاديمية والتقارير البحثية ضمن تسع فئات.
2. LightOnOCR: نموذج رؤية-لغة متعدد اللغات شامل بقيمة مليار دولار أمريكي لتقنية التعرف الضوئي على الأحرف المتطورة
أصدر باحثو شركة LightOn نموذج LightOnOCR-2-1B، وهو نموذج لغوي مرئي متعدد اللغات صغير الحجم يحتوي على مليار مُعامل، ويستخرج نصوصًا واضحة ومنظمة مباشرةً من صور المستندات، متفوقًا بذلك على النماذج الأكبر حجمًا. كما يُحسّن النموذج قدرات تحديد مواقع الصور من خلال تقنية RLVR، ويعزز موثوقية النتائج عبر دمج نقاط التحقق. النموذج ومعاييره متاحة كمصدر مفتوح.
ورقة وتفسير مفصل:https://go.hyper.ai/zXFQs
رابط البرنامج التعليمي للنشر بنقرة واحدة:https://go.hyper.ai/vXC4o
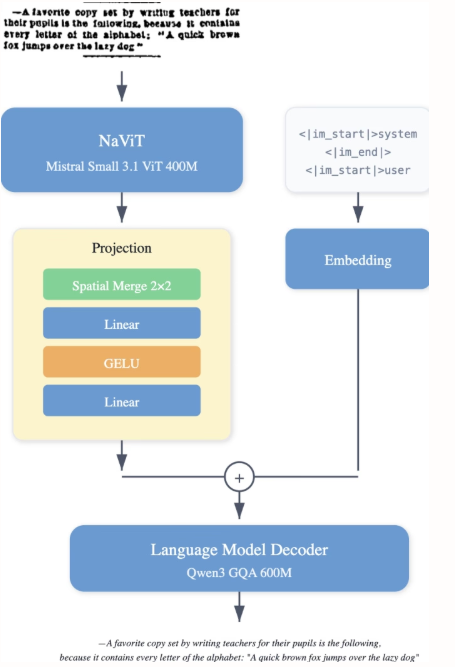
تجمع مجموعة بيانات LightOnOCR-2-1B صفحات مُعَلَّمة من قِبَل مُعلِّمين من مصادر مُتعددة، بما في ذلك مستندات ممسوحة ضوئيًا لتعزيز المتانة، وبيانات تكميلية لتنويع التنسيق. تتضمن المجموعة مناطق مُقتطعة (فقرات، عناوين، مُلخصات) مُعَلَّمة باستخدام GPT-4o، وأمثلة لصفحات فارغة لكبح التشويش، وإشرافًا مُستمدًا من TeX تم الحصول عليه من arXiv عبر مسار nvpdftex. أُضيفت مجموعات بيانات OCR عامة لزيادة التنوع.
3. تقرير فني HunyuanOCR
تقترح هذه الورقة البحثية نموذج HunyuanOCR، وهو نموذج مفتوح المصدر للرؤية واللغة، يضم مليار مُعامل، طُوّر بواسطة شركة Tencent وشركائها. يعتمد النموذج، من خلال التدريب القائم على البيانات واستراتيجية تعلّم معزز مبتكرة، على بنية خفيفة الوزن (مُهايئ ViT-LLM MLP) لتوحيد إمكانيات التعرّف الضوئي على الأحرف (OCR) الشاملة، بما في ذلك تحديد موقع النص، وتحليل المستندات، واستخراج المعلومات، والترجمة. يتفوق أداء النموذج على أداء النماذج الأكبر حجمًا وواجهات برمجة التطبيقات التجارية، مما يُتيح نشره بكفاءة في التطبيقات الصناعية والبحثية العلمية.
ورقة وتفسير مفصل:https://go.hyper.ai/F9fni
رابط البرنامج التعليمي للنشر بنقرة واحدة:https://go.hyper.ai/C4srs

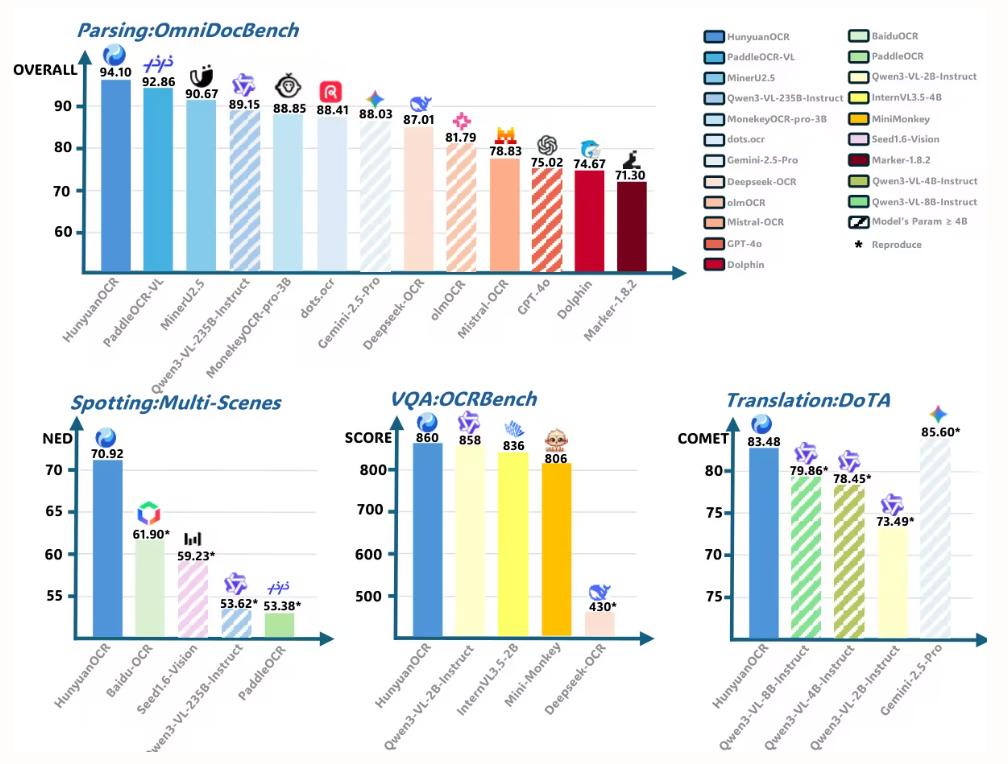
تستخدم هذه الورقة البحثية برنامج HunyuanOCR لتقييم أداء تحليل المستندات على منصة OmniDocBench. وقد حقق البرنامج أعلى مجموع نقاط بلغ 94.10، متفوقًا على جميع النماذج الأخرى (بما في ذلك النماذج الأكبر حجمًا).
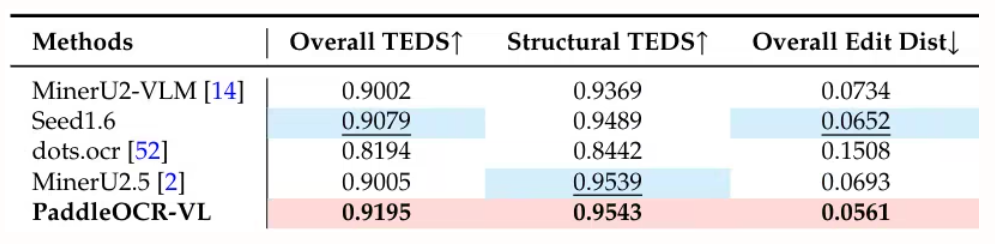
4 .PaddleOCR-VL: تعزيز تحليل المستندات متعددة اللغات عبر نموذج رؤية-لغة فائق الصغر بحجم 0.9 بايت
اقترح فريق بايدو نموذج PaddleOCR-VL، وهو نموذج رؤية لغوية فعال من حيث الموارد، يدمج مُشفِّر دقة ديناميكية على غرار NaViT مع نموذج ERNIE-4.5-0.3B. يحقق هذا النموذج أداءً متميزًا في تحليل المستندات متعددة اللغات، حيث يتعرف بدقة على العناصر المعقدة مثل الجداول والصيغ. مع الحفاظ على قدرات استدلال سريعة، يتفوق على الحلول الحالية، وهو مناسب للتطبيق في سيناريوهات واقعية.
ورقة وتفسير مفصل:https://go.hyper.ai/Rw3ur
رابط البرنامج التعليمي للنشر بنقرة واحدة:https://go.hyper.ai/5D8oo
قامت هذه الدراسة بتقييم تحليل المستندات على مستوى الصفحة باستخدام OmniDocBench v1.5 وolmOCR-Bench وOmniDocBench v1.0. وقد حققت الدراسة نتيجة إجمالية متميزة بلغت 92.86 على OmniDocBench v1.5، متفوقةً بذلك على MinerU2.5-1.2B (90.67). كما تفوقت الدراسة في تحليل النصوص (مسافة التحرير 0.035)، والصيغ (CDM 91.22)، والجداول (TEDS 90.89 وTEDS-S 94.76)، وترتيب القراءة (0.043).
5. نظرية التعرف الضوئي على الأحرف العامة: نحو التعرف الضوئي على الأحرف 2.0 من خلال نموذج موحد شامل
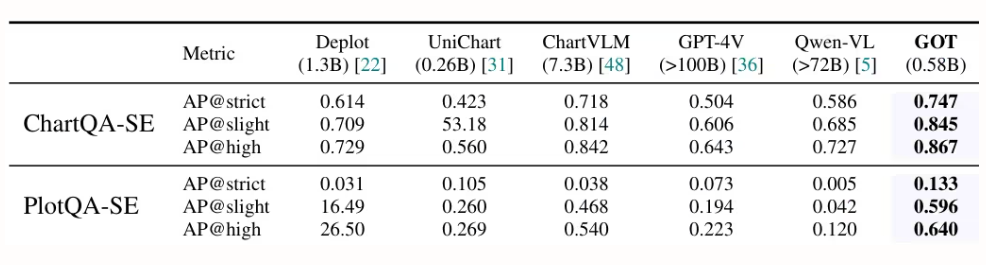
اقترح باحثون من شركات StepFun وMegvii Technology وجامعة الأكاديمية الصينية للعلوم وجامعة تسينغهوا نموذج GOT، وهو نموذج OCR-2.0 موحد وشامل، يضم 580 مليون مُعامل. وبفضل مُشفّر عالي الضغط ومُفكّك سياق طويل، يُوسّع هذا النموذج قدرات التعرّف من النصوص إلى مجموعة متنوعة من الإشارات البصرية الاصطناعية، مثل الصيغ الرياضية والجداول والرسوم البيانية والأشكال الهندسية. ويدعم النموذج إدخال البيانات على شكل شرائح أو صفحات كاملة، وإخراجها بتنسيقات مُنسّقة (Markdown/TikZ/SMILES)، والتعرّف التفاعلي على مستوى المناطق، والدقة الديناميكية، ومعالجة صفحات متعددة، مما يُسهم بشكل كبير في تطوير فهم ذكي للوثائق.
ورقة وتفسير مفصل:https://go.hyper.ai/9E6Ra
رابط البرنامج التعليمي للنشر بنقرة واحدة:https://go.hyper.ai/HInRr
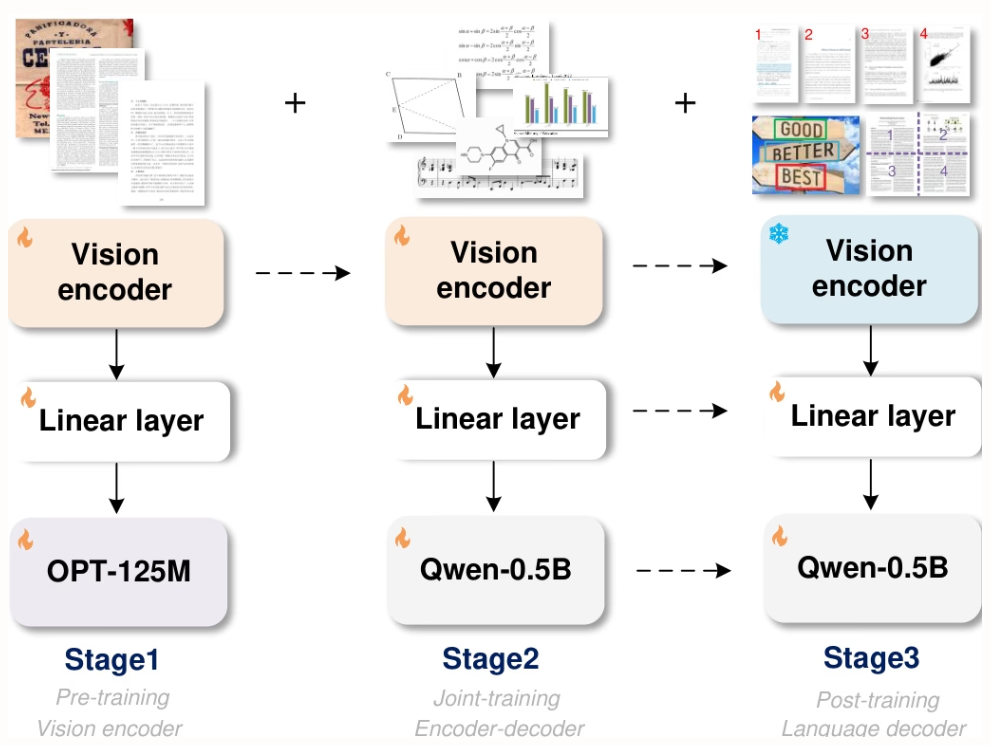
أُجريت التجارب المذكورة في هذه الورقة البحثية على وحدة معالجة رسومية (GPU) من نوع L40s بحجم 8×8، وتم تنفيذ ثلاث مراحل تدريب: التدريب المسبق (3 جولات، حجم الدفعة 128، معدل التعلم 1e-4)، والتدريب المشترك (جولة واحدة، أقصى طول للرمز المميز 6000)، والتدريب اللاحق (جولة واحدة، أقصى طول للرمز المميز 8192، معدل التعلم 2e-5). احتفظت المرحلة الأولى ببيانات بحجم 80% للحفاظ على الأداء.
هذا هو محتوى توصيات البحث لهذا الأسبوع. لمزيد من أبحاث الذكاء الاصطناعي المتطورة، يُرجى زيارة قسم "أحدث الأبحاث" على الموقع الرسمي لـ hyper.ai.
نرحب أيضًا بفرق البحث لتقديم نتائج وأوراق بحثية عالية الجودة إلينا. يمكن للمهتمين إضافة حساب نيوروستار على وي تشات (معرف وي تشات: Hyperai01).
نراكم في الاسبوع القادم!








