Command Palette
Search for a command to run...
تحقيق توصيف دقيق لتسلسلات مستقبلات الخلايا التائية (TCR)! يُوسّع إطار التعلم العميق DeepTCR أساليب البحث في علم المناعة؛ مدعومًا ببيانات 50,000 مريض بسرطان الرئة! يُفصّل موقع "خطر الإصابة بسرطان الرئة" عوامل خطر الإصابة بسرطان الرئة.

يُعد تسلسل مستقبلات الخلايا التائية (TCR-Seq) تطبيقًا هامًا لتقنية تسلسل الجيل التالي (NGS)، إذ يُمكّن الباحثين من توصيف تنوع الاستجابات المناعية التكيفية بشكل منهجي. عند تحليل بيانات تسلسل مستقبلات الخلايا التائية، حققت الطرق التقليدية (مثل البحث عن النمط أو محاذاة التسلسل) نتائج جيدة، إلا أنها كشفت تدريجيًا عن محدوديتها.عند تحديد استجابات الخلايا التائية النوعية للمستضد منخفضة التردد في الجسم، غالبًا ما تطغى على إشاراتها عدد كبير من الخلفيات غير النوعية للخلايا التائية.ويعكس هذا التحديات التي تواجهها الطرق التقليدية في تحديد الإشارات من الضوضاء.
مع استمرار نمو الطلب على توصيف أكثر دقة لتسلسلات TCR، حوّل الباحثون انتباههم إلى تقنيات التعلم العميق التي تمثلها الشبكات العصبية التلافيفية (CNNs).ظهرت تقنية DeepTCR كإطار عمل لتحليل تسلسل المستقبلات المناعية يعتمد على التعلم العميق.يمكن للإطار أن يتعلم تسلسلات CDR3، واستخدام جين V/D/J، وخصائص نوع جزيء MHC من بيانات ذخيرة المناعة لتسلسل TCR وإنشاء تمثيل مشترك لنمذجة بيانات تسلسل TCR المعقدة للغاية.
تطبق DeepTCR بشكل منهجي إطار التعلم العميق لتحليل تسلسل TCR، والذي لا يوسع الأساليب التحليلية للبحث المناعي فحسب، بل يوضح أيضًا التطبيق الواسع لتكنولوجيا التعلم العميق في مجالات مختلفة.
أطلق الموقع الرسمي لشركة HyperAI برنامج "DeepTCR: التنبؤ بتقارب TCR مع الببتيد باستخدام التعلم العميق". تعالوا وجرّبوه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/gKmgi
من 8 سبتمبر إلى 12 سبتمبر، إليك نظرة عامة سريعة على تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* دروس تعليمية مختارة عالية الجودة: 2
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في سبتمبر: 5
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات صور أمراض النبات الجديدة
أمراض النبات الجديدة هي مجموعة بيانات صور تُستخدم لتحديد أمراض النبات وتصنيف الأوراق. تغطي هذه المجموعة الأوراق السليمة وأنواعًا مختلفة من الأمراض. وهي مناسبة على نطاق واسع لتطوير وتقييم نماذج التعلم الآلي والتعلم العميق، لا سيما في مراقبة صحة المحاصيل، وتحديد الأمراض، ونماذج الزراعة الدقيقة، والبحث الأكاديمي، ولها قيمة مرجعية مهمة.
الاستخدام المباشر: https://go.hyper.ai/RKYtW

2. مجموعة بيانات تصنيف صور المشهد الطبيعي من Intel Image Classification
تصنيف الصور من إنتل هو مجموعة بيانات لتصنيف الصور أصدرتها إنتل، تهدف إلى تصنيف صور المشاهد الطبيعية والاصطناعية. تحتوي مجموعة البيانات على حوالي 25,000 صورة ملونة موزعة على ست فئات، بما في ذلك المباني والغابات.
الاستخدام المباشر: https://go.hyper.ai/qgbeX

3. مجموعة بيانات التفكير الروائي LongPage
LongPage هي أول مجموعة بيانات شاملة لتدريب نماذج الذكاء الاصطناعي على كتابة روايات كاملة ذات قدرات استدلال معقدة. تدعم هذه المجموعة الضبط الدقيق المُشرف عليه من البداية لعمليات تدريب التعلم التعزيزي، وهي مناسبة لتدريب نماذج لغوية واسعة النطاق ذات قدرات استدلال هرمية، وتحسين تماسك وتخطيط الكتابة الطويلة.
الاستخدام المباشر: https://go.hyper.ai/odoKA
4. مجموعة بيانات مخاطر الإصابة بسرطان الرئة
مخاطر سرطان الرئة هي مجموعة بيانات جدولية للتنبؤ بمخاطر سرطان الرئة وتحليل العوامل الصحية. تهدف إلى استكشاف العلاقة بين عادات التدخين ونمط الحياة وخطر الإصابة بسرطان الرئة من خلال خصائص متعددة الأبعاد. وهي مناسبة لنمذجة مخاطر سرطان الرئة، وأبحاث التعلم الآلي الطبي، وتطوير أنظمة التنبؤ بالصحة، والتجارب التعليمية. كما أنها قيّمة بشكل خاص في نمذجة التصنيف وسيناريوهات تقييم المخاطر.
الاستخدام المباشر:https://go.hyper.ai/YGFzG
5. مجموعة بيانات تقييم التعليمات العكسية IFEval-Inverse
IFEval-Inverse هي مجموعة بيانات لتقييم التعليمات التنافسية لنماذج اللغات الكبيرة، أصدرتها شركة ByteDance Seed بالتعاون مع جامعة نانجينغ وجامعة تسينغهوا ومؤسسات أخرى. تهدف هذه المجموعة إلى اختبار قدرة النموذج على كسر جمود التدريب وتحقيق توافق حقيقي مع التعليمات عند مواجهة تعليمات معاكسة أو غير طبيعية.
الاستخدام المباشر: https://go.hyper.ai/IcTqj
6. مجموعة بيانات الرسم البياني للمعرفة المالية FinReflectKG
FinReflectKG هي مجموعة بيانات واسعة النطاق للرسوم البيانية المعرفية للقطاع المالي. تهدف إلى استخلاص علاقات دلالية منظمة من الوثائق التنظيمية للشركات، وتعزيز تطوير أبحاث الرسوم البيانية المعرفية في المجال المالي. وهي مناسبة للتعرف على الكيانات، واستخلاص العلاقات، وبناء الرسوم البيانية المعرفية، وتحليل السلاسل الزمنية، وتقييم استخلاص المعلومات واسع النطاق القائم على نموذج لغوي، وتطوير تطبيقات مالية ذكية لاحقة في المجال المالي.
الاستخدام المباشر: https://go.hyper.ai/EB5em
7. مجموعة بيانات لغة يوي الكانتونية من WenetSpeech
WenetSpeech Yue هو مجموعة بيانات كلامية واسعة ومتعددة الأبعاد ومُعلّقة، مُخصصة للتعرف على الكلام الكانتوني (ASR) وتوليف النص إلى كلام (TTS). يهدف إلى سد النقص في الموارد في مجال اللغة الكانتونية، وتعزيز تدريب وتقييم نماذج كانتونية عالية الجودة.
الوصول المباشر: https://go.hyper.ai/cICOv
8. مجموعة بيانات ضبط التعليمات المستمرة UCIT
UCIT هي مجموعة بيانات مرجعية لضبط التعليمات المستمر لنماذج اللغات متعددة الوسائط الكبيرة. تتكون كل عينة في هذه المجموعة من وصف للمهمة (مطالبة/تعليمات) وتوقع التنفيذ الصحيح المقابل (استجابة حقيقية)، ويُستخدم هذا الوصف لقياس أداء النموذج في ظروف التشغيل الصفري.
الاستخدام المباشر: https://go.hyper.ai/TZPwY
9. مجموعة بيانات معيارية للاستدلال متعدد المجالات من لونغ بينش
لونغ بينش هي مجموعة بيانات لتقييم الاستدلال متعدد المجالات، مصممة لتزويد برنامج ماجستير القانون بمورد تدريب وتقييم متعدد المجالات وقابل للتحقق. تحتوي مجموعة البيانات على 8729 سؤالاً باللغة الطبيعية، تغطي 12 مجالاً مكثفاً للاستدلال، بما في ذلك الرياضيات المتقدمة والفيزياء المتقدمة.
الاستخدام المباشر: https://go.hyper.ai/AcFOZ
10. مجموعة بيانات محاذاة التفضيلات البشرية CA‑1
تُركز CA-1 على أحكام القيم البشرية وتفضيلاتها للسلوكيات الافتراضية لنماذج الذكاء الاصطناعي. وهي عبارة عن مجموعة بيانات سلوكية تعتمد على التغذية الراجعة البشرية، تجمع بين المحتوى المُولّد من النموذج وتقييمات المُعلّق. وهي مناسبة لدراسة اختلافات توافق المجموعات، وتوجيه معايير سلوك النموذج، وتطوير آليات مكافأة مُراعية للقيم.
الاستخدام المباشر: https://go.hyper.ai/mXznO
دروس تعليمية عامة مختارة
1. Wan2.2-S2V-14B: إنشاء فيديو صوتي بجودة الأفلام
Wan2.2-S2V-14B هو نموذج مفتوح المصدر لتوليد الفيديو بالصوت، طوّره فريق Alibaba Tongyi Wanxiang. باستخدام صورة ثابتة واحدة وصوت واحد فقط، يُمكنه توليد مقاطع فيديو رقمية بجودة سينمائية، تصل مدتها إلى دقائق، ويدعم أنواعًا وأحجامًا متنوعة من الصور. يدمج النموذج تقنيات مبتكرة متعددة لتمكين توليد الفيديو بالصوت للمشاهد المعقدة، ودعم توليد مقاطع فيديو طويلة، والتدريب والاستدلال متعدد الدقة.
تشغيل عبر الإنترنت: https://go.hyper.ai/TlSai
2. DeepTCR: التعلم العميق للتنبؤ بتقارب TCR مع الببتيد
DeepTCR هو إطار عمل لتحليل تسلسلات مستقبلات المناعة قائم على التعلم العميق، ويُمكّنه من التنبؤ بالألفة من بيانات ذخيرة المناعة لتسلسلات مستقبلات المناعة، واستخراج وتعلم تسلسلات CDR3 لمستقبلات المناعة، واستخدام جينات V/D/J، أو خصائص نوع جزيء معقد التوافق النسيجي الكبير (MHC)، وتمثيل مستقبلات المناعة بشكل مشترك لنمذجة بيانات تسلسلات مستقبلات المناعة شديدة التعقيد. كما يُمكنه استخراج مستقبلات المناعة الخاصة بالمستضد من تسلسلات RNA-Seq أحادية الخلية باستخدام فحوصات تعتمد على تشويش الخلفية وزراعة الخلايا التائية.
تشغيل عبر الإنترنت: https://go.hyper.ai/gKmgi
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

توصيات الورقة البحثية لهذا الأسبوع
1. المشاركة تعني الاهتمام: تدريب فعّال بعد التعلم القيادي مع مشاركة جماعية لخبرات التعلم التحفيزي
تقترح هذه الورقة البحثية خوارزمية تحسين سياسة أخذ العينات السربية (SAPO)، وهي خوارزمية تعلّم معزز لامركزية وغير متزامنة بالكامل لما بعد التدريب. صُممت SAPO لشبكات لامركزية من عُقد حوسبة غير متجانسة. تُدير كل عُقدة نموذج سياستها بشكل مستقل، بينما تُشارك مسارها مع العُقد الأخرى. لا تعتمد الخوارزمية على افتراضات صريحة حول زمن الوصول، أو تجانس النموذج، أو تكوين الأجهزة، ويمكن للعُقد العمل بشكل مستقل عند الطلب.
رابط الورقة: https://go.hyper.ai/MWeWF
2. لماذا تُسبب نماذج اللغة الهلوسة؟
تقترح هذه الورقة البحثية أن السبب الرئيسي وراء تعرض نماذج اللغة للهلوسة هو أن آليات تدريبها وتقييمها تميل إلى مكافأة التخمين بدلاً من الاعتراف بعدم اليقين. كما تُحلل الجذور الإحصائية للهلوسة في عمليات التدريب الحديثة. وتشير العقوبة المنهجية التي تفرضها النماذج الكبيرة على الاستجابات غير المؤكدة إلى ضرورة مراجعة أساليب التقييم المعيارية السائدة حاليًا، وإن كانت متحيزة، بدلاً من إدخال مقاييس إضافية لتقييم الهلوسة.
رابط الورقة: https://go.hyper.ai/eXoOR
3. التفكير الهندسي العكسي للجيل المفتوح
تقترح هذه الورقة نموذجًا جديدًا - التفكير الهندسي العكسي (REER) - يُغيّر جذريًا طريقة بناء التفكير. فخلافًا للطرق التقليدية التي تُبنى عمليات التفكير من الصفر عبر التجربة والخطأ أو التقليد، يتبنى REER استراتيجيةً عكسية. انطلاقًا من حلول معروفة عالية الجودة، يكتشف حاسوبيًا مسارات التفكير العميق المحتملة، خطوةً بخطوة، والتي يُمكن أن تُولّد هذه الحلول.
رابط الورقة: https://go.hyper.ai/xFygJ
4. Parallel-R1: نحو التفكير المتوازي من خلال التعلم التعزيزي
تقدم هذه الورقة البحثية Parallel-R1، أول إطار عمل للتعلم التعزيزي (RL) لمهام التفكير الواقعي المعقدة، والذي يُمكّن من سلوكيات التفكير المتوازي. يستخدم هذا الإطار تصميمًا منهجيًا متدرجًا لمعالجة مشكلة البداية الباردة لتدريب التفكير المتوازي في التعلم التعزيزي.
رابط الورقة: https://go.hyper.ai/s2OlH
5. WebExplorer: استكشاف وتطوير لتدريب وكلاء الويب على المدى الطويل
بالاستفادة من مجموعة بيانات عالية الجودة ومُصممة بعناية، نجحت هذه الورقة البحثية في تدريب نموذج وكيل ويب متطور، WebExplorer-8B، من خلال الضبط الدقيق المُشرف عليه مع التعلم التعزيزي. يدعم هذا النموذج سياقات تصل إلى 128 كيلوبايت، ويمكنه تنفيذ ما يصل إلى 100 استدعاء للأدوات، مما يُمكّن من حل المشكلات طويلة الأمد. وفي العديد من معايير استرجاع المعلومات، حقق WebExplorer-8B أداءً متطورًا مقارنةً بالنماذج المتشابهة في الحجم.
رابط الورقة: https://go.hyper.ai/NusbG
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
اقترح باحثون من الجامعة الصينية في هونغ كونغ، وجامعة محمد بن زايد للذكاء الاصطناعي، ومؤسسات أخرى، نموذج انتشار موجه بالنسخ الجيني، قابل للتطوير، يُعرف باسم MorphDiff، وهو مصمم خصيصًا لمحاكاة استجابة مورفولوجيا الخلية للاضطرابات بدقة عالية. يعتمد هذا النموذج على بنية نموذج الانتشار الكامن (LDM)، ويستخدم أنماط التعبير الجيني L1000 كمدخلات شرطية لتدريب إزالة الضوضاء.
شاهد التقرير الكامل: https://go.hyper.ai/f7WeP
قام فريق بحثي مشترك من جامعة الصين للبترول وجامعة يونسي بدمج تقنيات متقدمة متعددة لتطوير إطار عمل جديد يُسمى AlphaPPIMI. يجمع هذا الإطار بين نموذج مُدرّب مسبقًا واسع النطاق وآلية تعلم تكيفية، ويهدف إلى مواجهة التحدي الرئيسي المتمثل في اكتشاف مُعدّلات تستهدف واجهة مُثبطات مضخة البروتون (PPI) تحديدًا، مما يوفر دعمًا قويًا للتطوير المستقبلي للأدوية التي تستهدف مُثبطات مضخة البروتون.
شاهد التقرير الكامل: https://go.hyper.ai/4tp0M
في تمام الساعة الواحدة صباحًا بتوقيت بكين يوم 10 سبتمبر، ركز مؤتمر آبل لخريف 2025 كليًا على الذكاء الاصطناعي، معلنًا عن ترقيات الذكاء الاصطناعي لثلاثة منتجات رئيسية: آيفون 17، وساعة آبل سيريس 11، وسماعات إيربودز برو 3. تطورت تقنية الذكاء الاصطناعي من مجرد عرض مفاهيمي العام الماضي إلى تطبيق شامل، يغطي مجالات مثل الترجمة الفورية، ومراقبة الصحة، والذكاء البصري. وتُشكل شرائح A19 وM19 Pro من الجيل التالي حجر الأساس لقوتها الحاسوبية.
شاهد التقرير الكامل: https://go.hyper.ai/IimjS
أطلق فريقان بحثيان من جامعة ووهان وجامعة نانيانغ التكنولوجية برنامجًا مشتركًا لوكيل رعاية صحية يتكون من ثلاثة مكونات: الحوار، والذاكرة، والمعالجة. يستطيع هذا البرنامج تحديد الأغراض الطبية للمرضى، والكشف تلقائيًا عن مشكلات الأخلاقيات الطبية والسلامة.
شاهد التقرير الكامل: https://go.hyper.ai/AdG2j
في أوائل سبتمبر، أفادت التقارير أن شركة آبل أبدت اهتمامها بالاستحواذ على شركة ميسترال للذكاء الاصطناعي الفرنسية الناشئة. وتبعتها شركة ASML، عملاق أشباه الموصلات، في جولتها التمويلية الثالثة بقيمة 1.3 مليار يورو. وارتفعت قيمة الشركة الآن إلى 14 مليار دولار، مما يجعلها قوة رائدة في مجال الذكاء الاصطناعي الأوروبي.
شاهد التقرير الكامل: https://go.hyper.ai/zsQBu
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
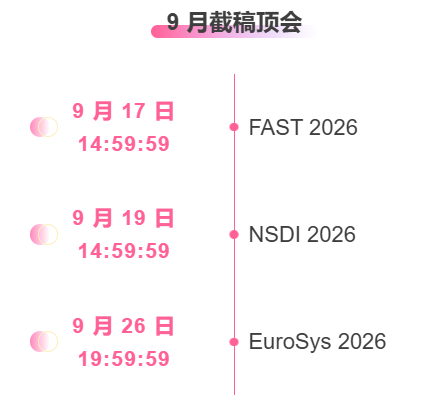
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1800 مجموعة بيانات عامة
* يتضمن أكثر من 600 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* يدعم البحث عن أكثر من 600 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








