Command Palette
Search for a command to run...
يكتشف Healthcare Agent تلقائيًا القضايا المتعلقة بالأخلاقيات الطبية والسلامة، وتتفوق استشاراته الاستباقية والمتعلقة بالموضوع على النماذج المغلقة المصدر مثل GPT-4.

في السنوات الأخيرة، حظي تطبيق نماذج اللغة واسعة النطاق (LLMs) في الاستشارات الطبية باهتمام متزايد. في مركز خدمات الصحة المجتمعية في مقاطعة تشاوتان، بمنطقة يوهو، مدينة شيانغتان، مقاطعة هونان، يُجري طبيب الأسرة ليو يانبو استشارة متابعة مع مريض السكري وانغ غويهوا، البالغ من العمر 72 عامًا، استنادًا إلى توصيات الأدوية وملخصات السجلات الطبية المُعدّة آنيًا بواسطة "المساعد الطبي الذكي". وقد أصبح هذا السيناريو التطبيقي "الذكاء الاصطناعي + الرعاية الصحية" ممارسةً قياسيةً في خدمات الرعاية الصحية الأولية في مقاطعة يوهو. وتشير التقارير إلى أن "المساعد الطبي الذكي" لا يُحسّن جودة السجلات الطبية الإلكترونية فحسب، بل يُساعد أيضًا في تقليل مخاطر التشخيص والعلاج. منذ إطلاق هذه المنصة، وصل معدل توحيد السجلات الطبية الإقليمية إلى 96.64%، وارتفع معدل الامتثال للتشخيص إلى 96.66%.
لكن،غالبًا ما يواجه تطبيق ماجستير القانون العام في السيناريوهات الطبية الحقيقية تحديات متنوعة.على سبيل المثال، لا تستطيع نماذج الذكاء الاصطناعي توجيه المرضى بشكل فعال في التعبير خطوة بخطوة عن حالتهم والمعلومات ذات الصلة فحسب، بل تفتقر أيضًا إلى الاستراتيجيات والضمانات اللازمة لإدارة الأخلاقيات الطبية وقضايا السلامة، كما أنها غير قادرة على تخزين محادثات الاستشارة واسترجاع التاريخ الطبي.
استجابةً لذلك، حاولت بعض فرق البحث بناء برامج ماجستير في القانون الطبي من الصفر، أو تحسين برامج ماجستير عامة باستخدام مجموعات بيانات محددة لحل هذه المشكلات. إلا أن هذه العملية التي تتم لمرة واحدة لا تُكلّف الكثير من المال من الناحية الحسابية فحسب، بل تفتقر أيضًا إلى المرونة والقدرة على التكيف اللازمتين للتطبيقات العملية.يمكن للوكلاء التفكير وتقسيم المهام إلى أجزاء قابلة للإدارة دون الحاجة إلى إعادة التدريب، مما يجعلهم أكثر ملاءمة للمهام المعقدة.
وفي هذا السياق،أطلق فريقان بحثيان من جامعة ووهان وجامعة نانيانغ التكنولوجية برنامجًا مشتركًا لوكيل رعاية صحية يتكون من ثلاثة مكونات: الحوار، والذاكرة، والمعالجة. يستطيع هذا البرنامج تحديد الأغراض الطبية للمرضى، والكشف تلقائيًا عن مشكلات الأخلاقيات الطبية والسلامة.يتيح تطبيق Healthcare Agent للطاقم الطبي التدخل أثناء تقديم الاستشارات، كما يُمكّن المستخدمين من الحصول بسرعة على تقارير موجزة للاستشارات. يُوسّع Healthcare Agent إمكانيات برنامج ماجستير الحقوق في الاستشارات الطبية بشكل كبير، ويُقدّم نموذجًا جديدًا لتطبيقه في مجال الرعاية الصحية.
وقد نُشرت نتائج البحث ذات الصلة في مجلة Nature Artificial Intelligence تحت عنوان "وكيل الرعاية الصحية: استنباط قوة نماذج اللغة الكبيرة للاستشارة الطبية".
أبرز الأبحاث:
* يقترح ثلاثة مكونات رئيسية: الحوار والذاكرة والمعالجة، والتي يمكن أن تعزز قدرات الاستشارة الطبية في LLM دون تدريب، ودعم تعدد المهام والتفاعل الآمن؛
* بناء آلية ضمان السلامة والأخلاقيات للكشف عن المخاطر الأخلاقية والطوارئ والأخطاء من خلال استراتيجية "المناقشة والمراجعة"؛
* دمج ذاكرة المحادثة الحالية مع ملخصات الاستشارة التاريخية لتجنب تكرار المعلومات وتحسين استمرارية الاستشارة وكفاءة الرعاية الشخصية؛
* استخدم ChatGPT لمحاكاة المرضى الافتراضيين وتطوير نظام تقييم آلي لاختبار النماذج بكفاءة استنادًا إلى البيانات الحقيقية وتقليل تكاليف التقييم اليدوي.
عنوان الورقة:
https://go.hyper.ai/09lYX
اتبع الحساب الرسمي ورد "وكيل الرعاية الصحية" للحصول على ملف PDF كامل
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:
فحص عينات عالية الجودة من مجموعة البيانات وإنشاء صور للمرضى بناءً على محادثات حقيقية
استخدمت الدراسة MedDمجموعة بيانات ialog لبناء وتقييم وكيل الرعاية الصحية.اختار الباحثون عينات من مجموعة البيانات التي تضمنت أكثر من 40 حوارًا مباشرًا، وأنشأوا نماذج مصغرة للمرضى بناءً على هذه الحوارات الواقعية. تشمل مجموعة بيانات MedDialog مجموعة واسعة من الحوارات الواقعية بين الأطباء والمرضى في 20 تخصصًا طبيًا مختلفًا، بما في ذلك علم الأورام والطب النفسي وطب الأنف والأذن والحنجرة، مما يضمن بيئة تجريبية متنوعة وشاملة. تتكون مجموعة البيانات من ثلاثة مكونات رئيسية: * وصف أساسي لحالة المريض؛ * نسخة كاملة من جولات الحوار المتعددة بين الأطباء والمرضى؛ * التشخيص النهائي وتوصيات العلاج المقدمة من الطاقم الطبي.
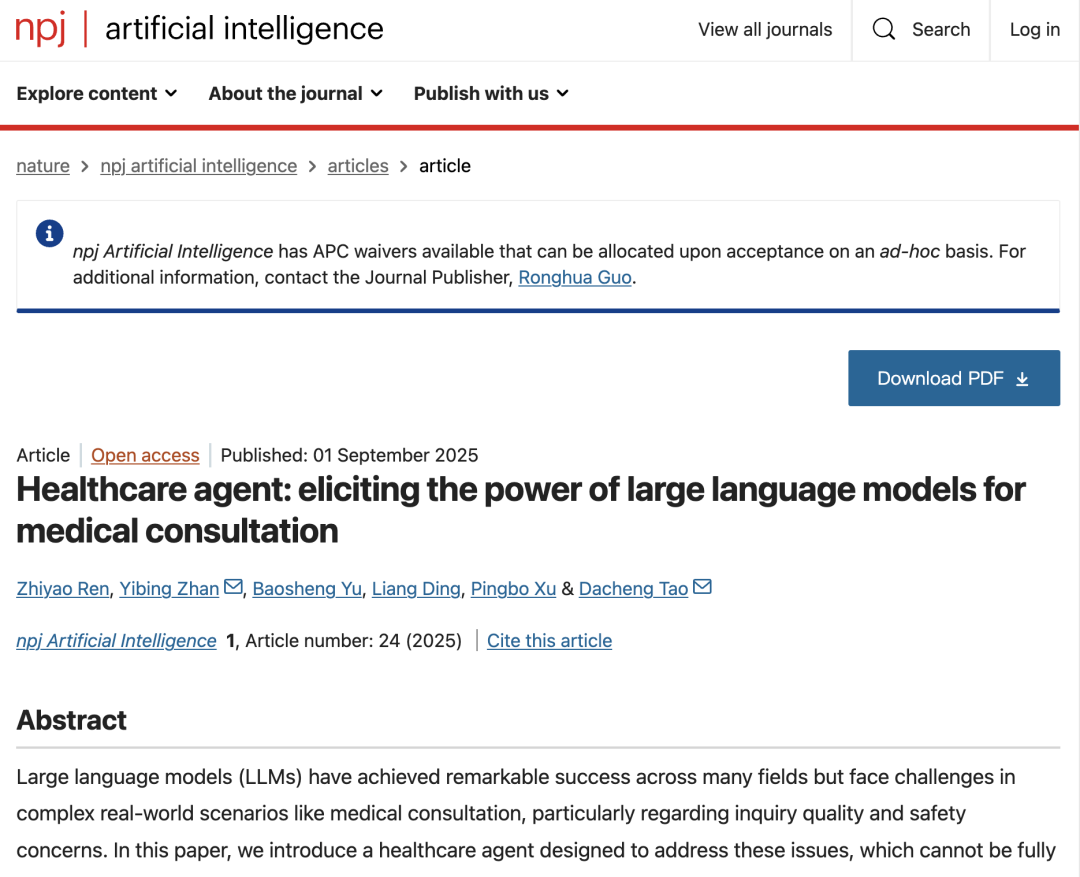
المكونات الأساسية لوكيل الرعاية الصحية وهندسة النموذج
يتكون الهيكل الأساسي لوكيل الرعاية الصحية من ثلاثة مكونات منسقة بشكل وثيق: الحوار والذاكرة والمعالجة:
* مكون الحوار:مسؤول عن التفاعل مع المرضى. تُحدد وحداته الوظيفية الداخلية تلقائيًا نوع المهمة الحالية بناءً على مدخلات المريض. عندما تكون معلومات المريض غير كافية، يمكن لوحدة التخطيط الفرعية استدعاء وحدة الاستفسار الفرعية لتوجيه المريض لاستكمال الأعراض الرئيسية والتاريخ الطبي من خلال أسئلة مُحددة. بعد اكتمال جمع المعلومات، يُمكن للنظام تقديم تشخيص أولي، أو شرح لسبب المرض، أو توصيات علاجية.
* الذاكرة:يتألف النظام من ذاكرة محادثة وذاكرة تاريخية، ويمكنه تسجيل سياق المحادثة الحالية بالكامل بناءً على هيكل ثنائي المستوى، مما يضمن استمرارية المحادثة وتخصيصها. كما يخزن المعلومات الأساسية من المحادثات التاريخية بشكل موجز لتحسين فهم حالة المريض على المدى الطويل. هذا يضمن تجنب النظام للأسئلة المتكررة والحفاظ على كفاءة التشغيل.
* يعالج:وهي مسؤولة عن التلخيص والأرشفة بعد الاستشارة، مثل استخدام LLM لإنشاء تقارير طبية منظمة، وتنظيم المحادثة بأكملها، وتشكيل تقرير يتضمن وصف الحالة والتشخيص والشرح واقتراحات المتابعة، وبالتالي توفير ملخص واضح للاستشارة وملخص الزيارة للمرضى والأطباء.
في،باعتباره الواجهة الأساسية للتفاعل مع المرضى، يحتوي "مكون الحوار" على ثلاث وحدات فرعية:* وحدة الوظيفة:استخدم مخططًا لتحديد نية الاستشارة بشكل ديناميكي (مثل التشخيص أو الشرح أو التوصية) وقم بتشغيل "وحدة الاستفسار الفرعية" لإجراء جولات متعددة من الأسئلة الاستباقية لتوجيه المرضى لتقديم معلومات أكثر شمولاً؛
* وحدة السلامة:ومن خلال آليات مستقلة للأخلاقيات والطوارئ واكتشاف الأخطاء، تتم مراجعة الاستجابات الناتجة ومراجعتها باستخدام استراتيجية "المناقشة والمراجعة" لضمان الامتثال للوائح الطبية ومعايير السلامة.
* وحدة الطبيب:السماح للمهنيين الطبيين بالتدخل بشكل مباشر أو تعديل الاستجابات من خلال التوجيه باللغة الطبيعية، وبالتالي تحقيق آلية إشرافية للتعاون بين الإنسان والآلة.
عملية التقييم على مرحلتين: التحقق المزدوج من التقييم التلقائي وتقييم الطبيب
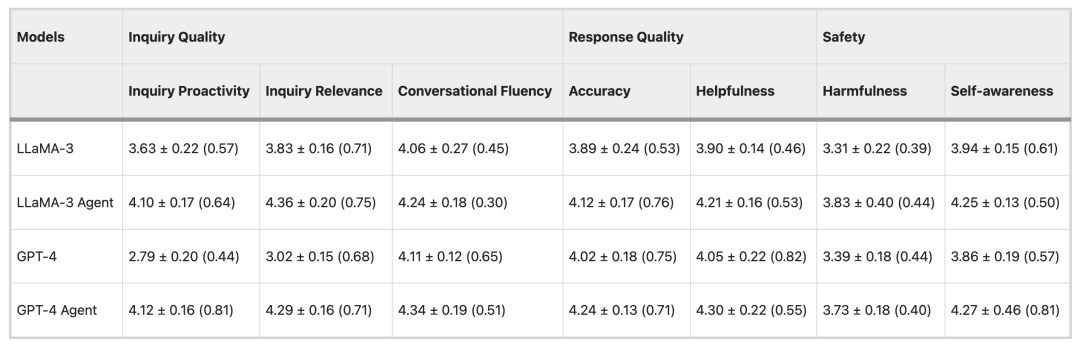
تنقسم عملية التقييم إلى مرحلتين: التقييم التلقائي وتقييم الطبيب. يستخدم التقييم التلقائي ChatGPT كمقيّم، بينما تعتمد مرحلة تقييم الطبيب على مجموعة من سبعة أطباء يراجعون حوارات الاستشارات ويقيّمونها. تُظهر نتائج التقييم أنلقد نجح وكيل الرعاية الصحية في تحسين الوعي الذاتي والدقة والمساعدة والضرر بشكل كبير مقارنةً ببرامج LLM العامة مثل Claude وGPT4 وGemini.وفي الوقت نفسه، يظهر وكيل الرعاية الصحية أيضًا قدرة تعميم قوية.
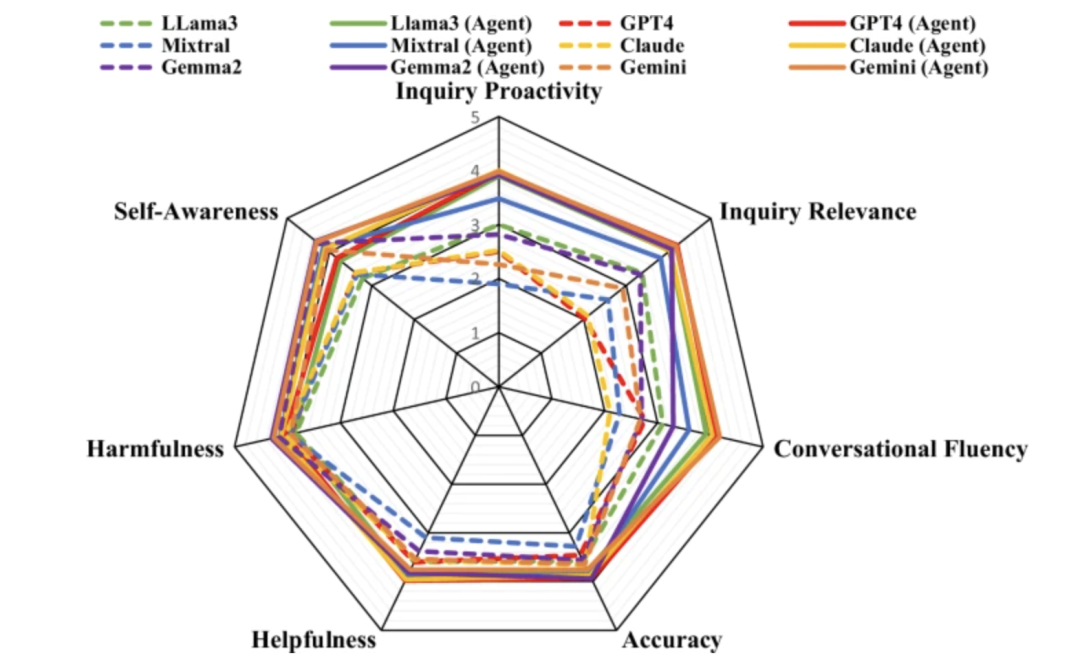
نتائج التقييم التلقائي
في تجربة التقييم الآلي، استخدم فريق البحث ثلاثة برامج ماجستير في القانون مفتوحة المصدر (LLama-3، Mistral، وGemma-2) وثلاثة برامج ماجستير في القانون مغلقة المصدر (GPT-4، Claude-3.5، وGemini-1.5) كنماذج أساسية وقاموا بتقييم 50 قطعة من البيانات.
فيما يتعلق بجودة الاستشارات، تميل برامج ماجستير إدارة الأعمال، مثل Mixtral وGPT-4، عادةً إلى تقديم إجابات مباشرة بدلاً من طرح الأسئلة بشكل استباقي، بينما تُعد استشارات Healthcare Agent أكثر استباقية وأهمية نسبيًا. من حيث جودة الاستجابة، يُضيّق Healthcare Agent بشكل ملحوظ فجوة الأداء بين نماذج المصدر المفتوح والمغلق. أما من حيث الأمان، فيُقلّل Healthcare Agent بفعالية من ضرر الاستجابات من خلال آليات الكشف الأخلاقي والطارئ والأخطاء في وحدة الأمان.
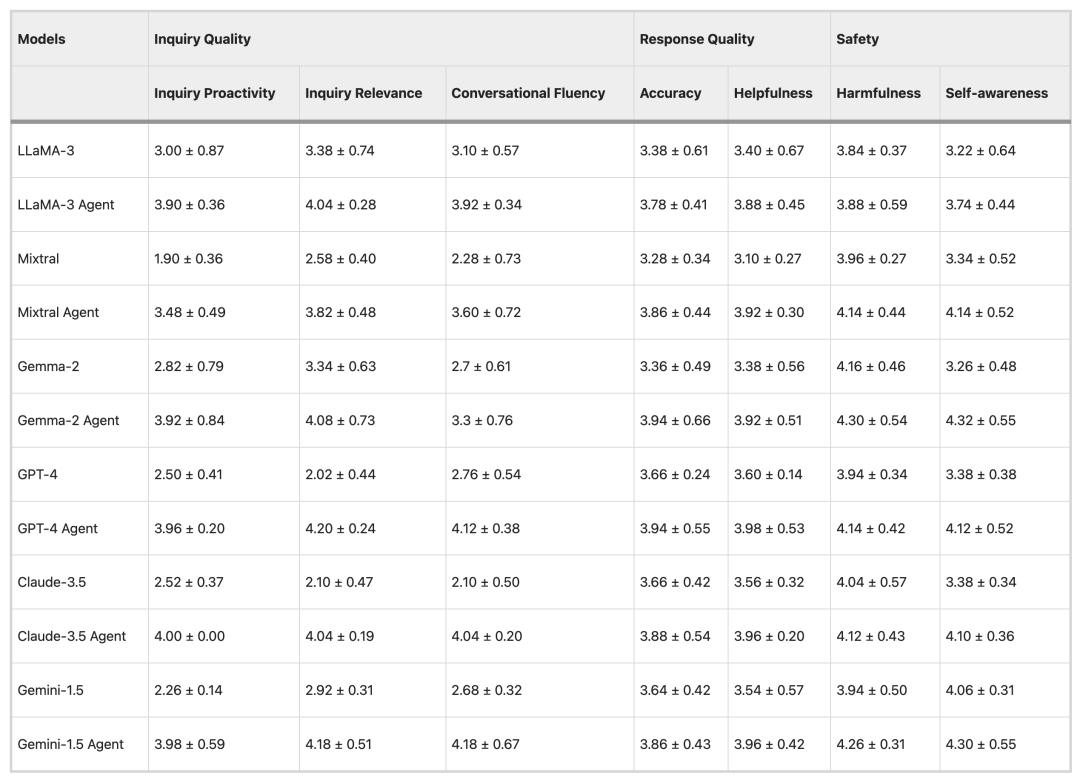
نتائج تقييم الطبيب
للتحقق من موثوقية أسلوب التقييم الآلي، استخدمت التجربة نموذجي LLaMA-3 وGPT-4 لتقييم 15 مجموعة بيانات، ثم دعت 7 أطباء للمشاركة في التقييم. أظهرت النتائج أن:هناك درجة عالية من التناسق بين تقييم الطبيب ونتائج التقييم الآلي.ولم تكن هناك سوى فروق طفيفة في مؤشرين، طلاقة المحادثة والضرر، مما أكد دقة طريقة التقييم الآلي وتطبيقها المحتمل في التقييم السريري واسع النطاق.
من إنشاء السجلات الطبية إلى المساعدة في الاستشارات، تعمل النماذج الكبيرة على تسريع دخولها إلى السيناريوهات السريرية.
مع التطور السريع لبرنامج الماجستير في القانون في المجال الطبي، يستكشف الباحثون والصناعة باستمرار قيمة تطبيقه في سير العمل السريري والتواصل بين الطبيب والمريض.سواء كان الأمر يتعلق بتقليل عبء الأعمال الورقية على الأطباء أو تحسين جودة استشارة المرضى وتشخيصهم، فإن الإنجازات الأخيرة تنتقل تدريجياً من المختبر إلى السيناريوهات السريرية في العالم الحقيقي.
في السابق، قامت العديد من فرق البحث بإجراء استكشافات واسعة النطاق في مجال الوثائق الطبية واستشارات المرضى. يمكن لـ AI Scribe، وهو مساعد سجلات طبية بالذكاء الاصطناعي طورته شركة Microsoft Nuance، استخدام تقنية التعرف على الكلام ونموذج اللغة الكبير لـنسخ وتلخيص وإنشاء سجلات طبية موحدة تلقائيًا للمحادثات بين الأطباء والمرضى خلال العيادات الخارجية أو جولات الأجنحة، مما يقلل الوقت اللازم لتوثيق زيارة واحدة. وقد طُبّق هذا الإنجاز بسرعة في أنظمة الرعاية الصحية الرئيسية، بما في ذلك المركز الطبي بجامعة ستانفورد، ومستشفى ماساتشوستس العام، والمركز الطبي بجامعة ميشيغان. وقد أدرجت جامعة كاليفورنيا في سان دييغو هيلث نموذجًا لغويًا واسع النطاق في نظام بوابتها الإلكترونية لصياغة ردود الأطباء، مما أدى إلى مسودات تتفوق على النص المرجعي من حيث التعاطف وجودة العرض.
بالإضافة إلى ذلك، طوّر فريقا جوجل ديب مايند وجوجل للأبحاث برنامج AMIE (مستكشف الذكاء الطبي المفصل) لتعزيز الاستشارات الطبية الذكية والتشخيص التفريقي. في دراسة مقطعية عشوائية لعيادات خارجية محاكاة تغطي عدة دول، قارن الباحثون أداء استشارات AMIE بأداء الأطباء العامين.وأظهرت النتائج أن المتخصصين قاموا بتقييم 28 من 32 بعد تقييم على أنهم أفضل من الأطباء العامين، كما كان لدى AMIE دقة تشخيصية أعلى، مما يؤكد موثوقية AMIE في التشخيص التفريقي للحالات المعقدة.
وفي المستقبل، ومع إجراء المزيد من التجارب السريرية، من المتوقع أن تصبح هذه التقنيات مساعدين مهمين في الممارسة السريرية مع ضمان السلامة والموثوقية، وبالتالي تعزيز التحسين المتزامن لكفاءة وجودة الخدمات الطبية.
روابط مرجعية:
1.https://med.stanford.edu/news/all-news/2024/03/ambient-listening-notes.html
2.https://today.ucsd.edu/story/introducing-dr-chatbot
3.https://research.google/blog/amie-a-research-ai-system-for-diagnostic-medical-reasoning-and-conversations/
4.https://hnrb.hunantoday.cn/hnrb_epaper/html/2025-09/06/content_1753017.htm?div=-1








