Command Palette
Search for a command to run...
يتصدر GPT-5 جميع المجالات؛ وتطلق OpenAI برنامج FrontierScience، باستخدام نهج مزدوج من "الاستدلال + البحث" لاختبار قدرات النماذج واسعة النطاق.
مع استمرار تحسن قدرات الاستدلال والمعرفة للنماذج، تصبح اختبارات المعايير الأكثر تحديًا ضرورية لقياس قدرة النموذج على تسريع البحث العلمي والتنبؤ بها. في 16 ديسمبر 2025، أطلقت OpenAI برنامج FrontierScience، وهو معيار مصمم لقياس القدرات العلمية على مستوى الخبراء.وفقًا للتقييمات الأولية، حقق GPT-5.2 درجة 25% و 77% في مهام FrontierScience-Olympiad و Research على التوالي، متفوقًا على النماذج المتطورة الأخرى.
صرحت شركة OpenAI في بيان رسمي قائلة: "إن تسريع التقدم العلمي هو أحد أكثر الفرص الواعدة للذكاء الاصطناعي لإفادة البشرية، لذلك نعمل على تحسين نماذجنا للمهام الرياضية والعلمية المعقدة ونعمل على تطوير أدوات يمكن أن تساعد العلماء على تحقيق أقصى استفادة من هذه النماذج".
ركزت معايير العلوم السابقة في الغالب على أسئلة الاختيار من متعدد، إما بصيغة أسئلة معقدة للغاية أو بافتقارها إلى التركيز العلمي. على النقيض من ذلك، فإن FrontierScience مكتوب ومُدقّق من قبل خبراء في الفيزياء والكيمياء والأحياء، على عكس المعايير السابقة.يتضمن هذا الاختبار أنواعًا من الأسئلة على غرار الأسئلة الأولمبية وأخرى قائمة على البحث العلمي، مما يُمكّنه من قياس كل من التفكير العلمي وقدرات البحث العلمي.بالإضافة إلى ذلك، يتضمن برنامج FrontierScience-Research 60 مهمة بحثية فرعية أصلية صممها علماء حاصلون على درجة الدكتوراه، بمستوى صعوبة مماثل لما قد يواجهه علماء الدكتوراه أثناء أبحاثهم.
فيما يتعلق بمستقبل وقيود قياس الأداء، ذكرت OpenAI في تقريرها الرسمي: "يُعاني FrontierScience من محدودية النطاق ولا يُمكنه تغطية جميع جوانب العمل اليومي للعلماء. ومع ذلك، يحتاج هذا المجال إلى معايير علمية أكثر تحديًا وأصالةً وأهمية، ويُعد FrontierScience خطوة في هذا الاتجاه."
تم نشر نتائج البحث الخاصة بالمشروع تحت عنوان "FrontierScience: تقييم قدرة الذكاء الاصطناعي على أداء المهام العلمية على مستوى الخبراء".
عنوان الورقة:
https://hyper.ai/papers/7a783933efcc
المزيد من الأوراق البحثية:
عرض المزيد من المعايير:

تتيح مجموعة بيانات FrontierScience اتباع نهج مزدوج المسار يتمثل في "الاستدلال + البحث".
في هذا المشروع، قام فريق البحث بإنشاء مجموعة بيانات تقييم FrontierScience لتقييم قدرات النماذج الكبيرة بشكل منهجي في التفكير العلمي على مستوى الخبراء والمهام الفرعية البحثية.تعتمد مجموعة البيانات آلية تصميم "إنشاء الخبراء + هيكل مهمة من مستويين + آلية تسجيل تلقائية" لتشكيل معيار تقييم التفكير العلمي الذي يتسم بالتحدي وقابلية التوسع والتكرار.
عنوان مجموعة البيانات:
https://hyper.ai/datasets/47732
استنادًا إلى تنسيقات المهام المختلفة وأهداف التقييم، يتم تقسيم مجموعة بيانات FrontierScience إلى مجموعتين فرعيتين، تتوافقان مع نوعين من القدرات: التفكير الدقيق ذو النهاية المغلقة والتفكير العلمي ذو النهاية المفتوحة.
* مجموعة بيانات الأولمبياد: صُممت في الأصل من قبل الفائزين بالميداليات ومدربي المنتخبات الوطنية في الأولمبياد الدولية للفيزياء والكيمياء والأحياء، وتتميز بصعوبة مسائل مماثلة للمسابقات الدولية الكبرى مثل IPhO وIChO وIBO؛ وتركز على مهام الاستدلال ذات الإجابات القصيرة، وتتطلب من النماذج إخراج قيمة عددية واحدة أو تعبير جبري أو مصطلحات بيولوجية يمكن مطابقتها بشكل تقريبي، وذلك لضمان إمكانية التحقق من النتائج واستقرار التقييم التلقائي.
* مجموعة بيانات بحثية: صُممت هذه المجموعة من قِبل طلاب الدكتوراه، وزملاء ما بعد الدكتوراه، والأساتذة، وغيرهم من الباحثين النشطين، وتُحاكي الأسئلة مشاكل فرعية قد تُصادف في البحث العلمي الحقيقي، وتغطي المجالات الرئيسية الثلاثة: الفيزياء، والكيمياء، وعلم الأحياء. يُرفق كل سؤال بدرجة تفصيلية من 10 نقاط لتقييم أداء النموذج في عدة جوانب رئيسية، تتجاوز مجرد صحة الإجابة، بما في ذلك استكمال افتراضات النمذجة، ومسارات الاستدلال، والاستنتاجات الوسيطة.
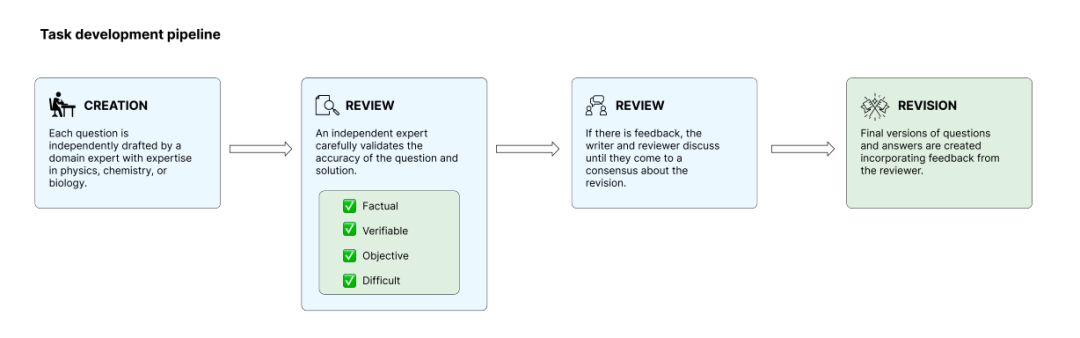
لضمان أصالة الأسئلة ودقتها، قام فريق البحث بفحصها خلال مرحلة اختبار النموذج الداخلي، واستبعد الأسئلة التي يمكن حلها بسهولة باستخدام النماذج الحالية للحد من خطر تشبع التقييم. تمر مهام التدريب بأربع مراحل: الإنشاء، والمراجعة، والحل، والتنقيح. ويراجع خبراء مستقلون مهام بعضهم البعض للتأكد من استيفائها للمعايير.في النهاية، اختار الفريق 160 سؤالاً مفتوح المصدر من بين مئات الأسئلة المرشحة، بينما تم الاحتفاظ بالأسئلة المتبقية كاحتياطي للكشف اللاحق عن التلوث والتقييم طويل الأجل.
حققت نماذج أخذ العينات الفرعية المستقلة ونماذج أخرى مثل GPT-5.2 نتائج مبهرة.
لتقييم قدرة النماذج الكبيرة على التفكير العلمي بشكل مستقر وقابل للتكرار دون الاعتماد على الاسترجاع الخارجي، قام فريق البحث بتصميم عملية تقييم صارمة وآلية تسجيل النقاط.
اختارت هذه الدراسة العديد من النماذج الكبيرة الرائدة كأهداف للتقييم، والتي تغطي مؤسسات وأساليب تقنية مختلفة، وذلك من أجل عكس مستوى القدرة الإجمالية للنماذج الكبيرة ذات الأغراض العامة الحالية في مجال التفكير العلمي قدر الإمكان.تم تعطيل جميع النماذج من الإنترنت أثناء عملية التقييم لضمان أن مخرجاتها تستند فقط إلى معرفتها الداخلية وقدراتها على التفكير، ولا تتأثر باسترجاع المعلومات في الوقت الفعلي أو الأدوات الخارجية.يقلل هذا من تأثير الاختلافات في قدرات الحصول على المعلومات بين النماذج المختلفة على النتائج.
وبالنظر إلى العشوائية المتأصلة في النماذج الكبيرة في الاستجابات التوليدية، أجرى فريق البحث تحليلاً إحصائياً من خلال أخذ عينات مستقلة متعددة وحساب متوسط النتائج من المجموعتين الفرعيتين، الأولمبياد والبحث، لتجنب التقلبات العشوائية.فيما يتعلق بطريقة التقييم، تصمم الورقة استراتيجيات تقييم آلية لنوعي المهام، مع مراعاة خصائصهما المختلفة:
* مجموعة فرعية من FrontierScience-Olympiad: تؤكد على التفكير المغلق، مع اعتماد التقييم بشكل أساسي على تحديد تكافؤ الإجابة، مما يسمح بالتقريبات العددية ضمن نطاق خطأ معقول، والتحويلات المكافئة للتعبيرات الجبرية، والمطابقة التقريبية للمصطلحات أو الأسماء في الأسئلة البيولوجية، مع تجنب الحساسية المفرطة لشكل التعبير؛
* مجموعة فرعية من FrontierScience-Research: تحاكي هذه المجموعة مهام البحث في العالم الحقيقي بدقة، حيث يقسم كل سؤال عملية التفكير البحثي إلى عدة خطوات رئيسية مستقلة وقابلة للتحقق. ويتم تقييم إجابات النموذج بندًا بندًا وفقًا لمعايير محددة، بدلاً من الاعتماد فقط على صحة الاستنتاج النهائي.
بشكل عام، يُظهر معيار FrontierScience اتجاهًا واضحًا لاختلاف الأداء في نوعي المهام.
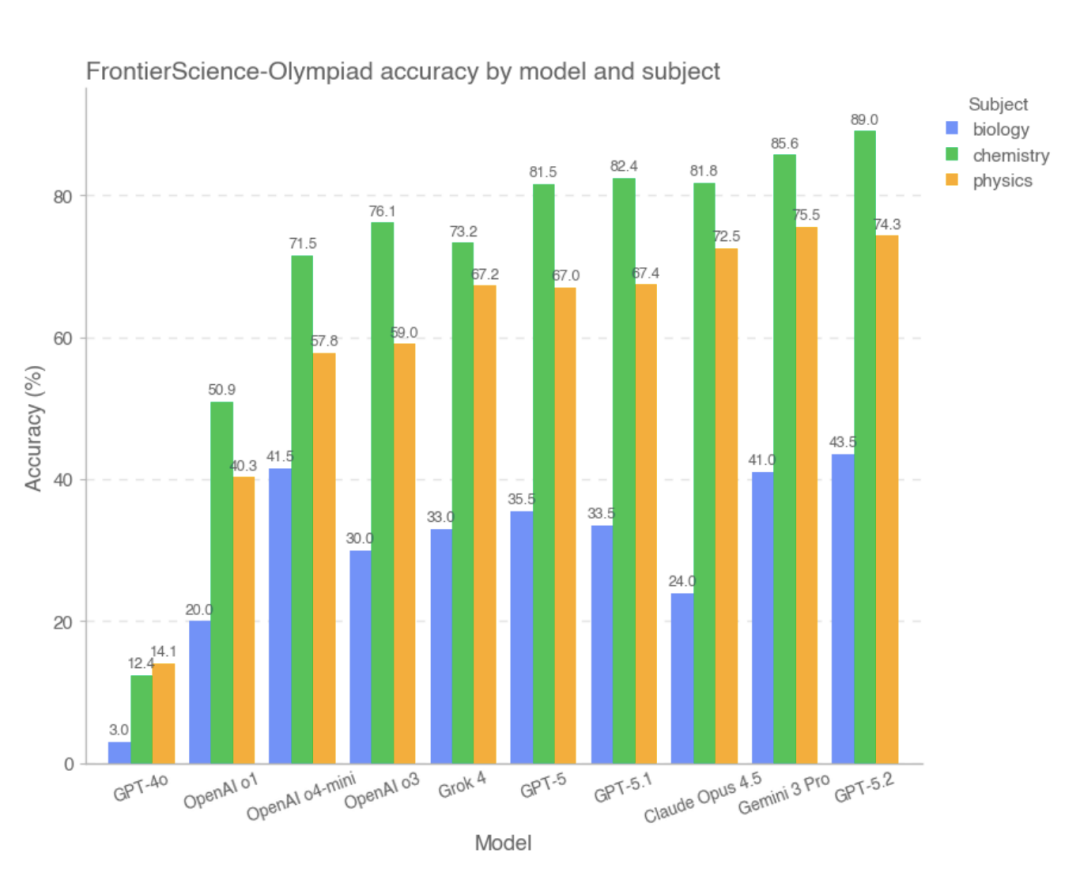
في مجموعة الأولمبياد الفرعية، حققت معظم النماذج المتطورة درجات عالية. من بينها،أفضل ثلاثة نماذج ذات أفضل النتائج الإجمالية هي GPT-5.2 و Gemini 3 Pro و Claude Opus 4.5، بينما كان أداء GPT-4o و OpenAI-o1 ضعيفًا نسبيًا.تشير الدراسة إلى أنه في هذا النوع من المشاكل ذات الشروط الواضحة، ومسارات الاستدلال المغلقة نسبياً، والإجابات القابلة للتحقق، تمكنت معظم النماذج من إكمال العمليات الحسابية المعقدة والاستنتاجات المنطقية بشكل مستقر، وكان أداؤها العام قريباً من أداء حل المشكلات البشرية عالية المستوى.
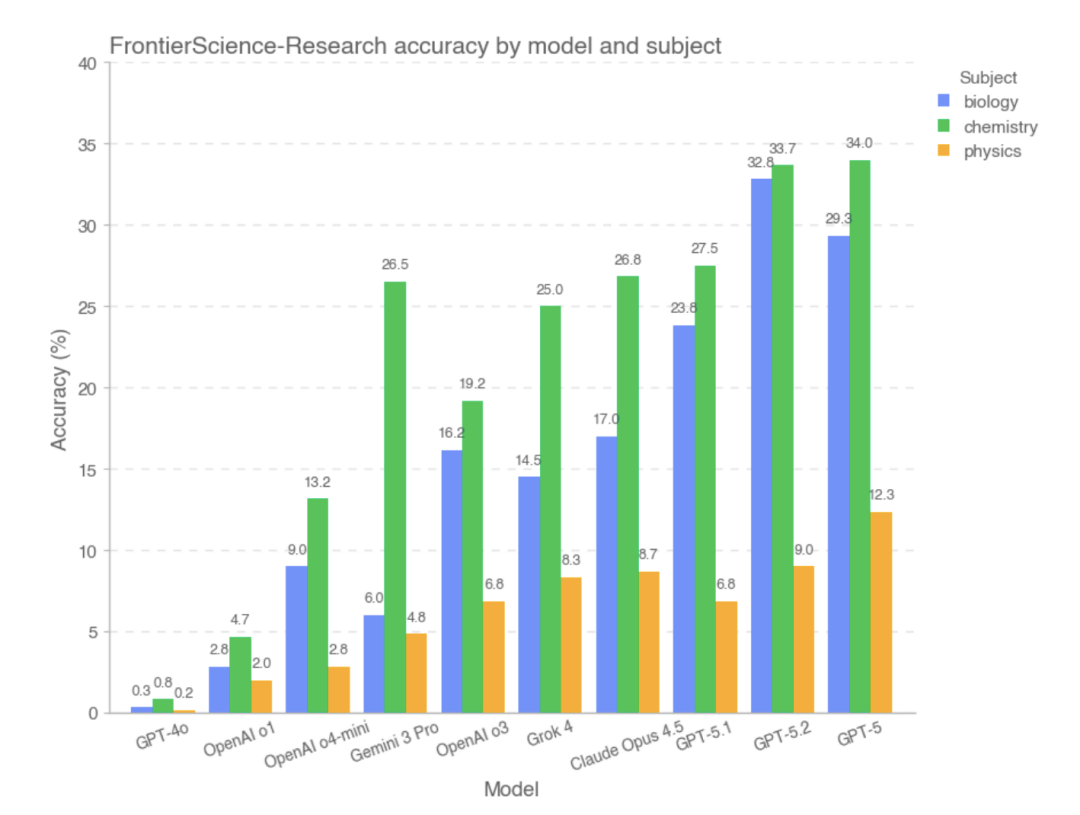
ومع ذلك، في المجموعة الفرعية FrontierScience-Research، كانت النتيجة الإجمالية للنموذج أقل بكثير..في مجموعة البحث الفرعية، يكون النموذج أكثر عرضة للتحيز أثناء تفكيك مشاكل البحث المعقدة.على سبيل المثال، قد يكون هناك فهم غير مكتمل لهدف المشكلة، أو معالجة غير سليمة للمتغيرات أو الافتراضات الرئيسية، أو تراكم تدريجي للأخطاء المنطقية ضمن سلسلة طويلة من الاستدلال. بالمقارنة مع مسائل الأولمبياد، لا تزال النماذج واسعة النطاق تُظهر فجوة كبيرة في القدرات عند مواجهة مهام أكثر انفتاحًا وأقرب إلى عمليات البحث في العالم الحقيقي. استنادًا إلى البيانات التجريبية،كانت النماذج التي حققت أداءً جيدًا في قسم البحث هي GPT-5 و GPT-5.2 و GPT-5.1.
قارنت هذه الدراسة أيضًا دقة أداء GPT-5.2 وOpenAI-o3 على مجموعتي اختبار FrontierScience-Olympiad وFrontierScience-Research في ظل مستويات استدلال مختلفة. وتُظهر النتائج أن...مع زيادة عدد الرموز المستخدمة في الاختبار، تحسنت دقة GPT-5.2 من 67.51 TP3T إلى 77.11 TP3T على مجموعة بيانات الأولمبياد، ومن 181 TP3T إلى 251 TP3T على مجموعة بيانات البحث.تجدر الإشارة إلى أنه في مجموعة بيانات البحث، فإن نموذج o3 يؤدي أداءً أسوأ قليلاً في ظل كثافة الاستدلال العالية مقارنة بكثافة الاستدلال المتوسطة.
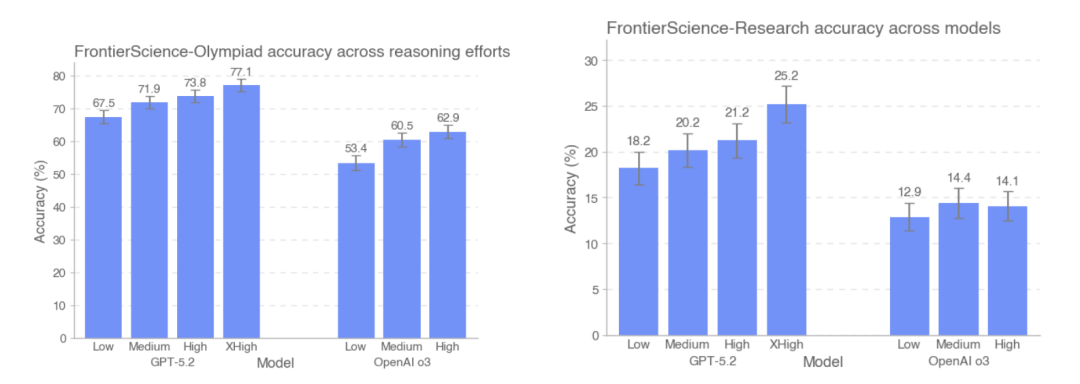
استناداً إلى التصميم العام والنتائج التجريبية لشركة FrontierScience،لقد تمكن النموذج الكبير من الأداء بثبات في المشكلات العلمية ذات الهياكل الواضحة والشروط المغلقة، وقد اقترب أداؤه في بعض المهام من مستوى الخبراء البشريين.ومع ذلك، تظل قدراتها محدودة بشكل كبير بمجرد دخولها في مهام البحث الفرعية التي تتطلب نمذجة مستمرة، وتجزئة المشكلة، والحفاظ على الاتساق في الاستدلال طويل السلسلة.
بغض النظر عن صحة الإجابة، فإن النماذج واسعة النطاق تُبشر بمعيار جديد للقدرات.
في شرحها الرسمي، تُشير OpenAI صراحةً إلى أن FrontierScience لا تُغطي جميع جوانب العمل اليومي للعلماء؛ فمهامها لا تزال في الأساس تعتمد على الاستدلال النصي، ولا تشمل بعدُ العمليات التجريبية، أو المعلومات متعددة الوسائط، أو عمليات التعاون البحثي في العالم الحقيقي. مع ذلك، ونظرًا للتشبع العام لأساليب التقييم العلمي الحالية، تُقدم FrontierScience مسار تقييم أكثر تحديًا وقيمة تشخيصية: فهي لا تُركز فقط على صحة إجابات النموذج، بل تبدأ أيضًا في قياس قدرة النموذج على إنجاز المهام الفرعية البحثية بشكل منهجي. من هذا المنظور، لا تكمن قيمة FrontierScience في لوحة الصدارة فحسب، بل أيضًا في توفير معيار جديد لتحسين النموذج لاحقًا ولأبحاث الذكاء العلمي. ومع استمرار تطور قدرات الاستدلال في النماذج، قد يُصبح هذا النوع من المعايير، الذي يُؤكد على الأصالة ومشاركة الخبراء وتقييم العملية، نافذةً مهمةً لمعرفة ما إذا كان الذكاء الاصطناعي يتجه حقًا نحو مرحلة التعاون البحثي.
روابط مرجعية:
1.https://cdn.openai.com/pdf/2fcd284c-b468-4c21-8ee0-7a783933efcc/frontierscience-paper.pdf
2.https://openai.com/index/frontierscience/
3.https://huggingface.co/datasets/openai/frontierscience








