Command Palette
Search for a command to run...
أفضل ورقة بحثية في ACL 25! جامعة ستانفورد تُصدر مجموعة بيانات معيارية تُراعي الفروقات لبناء عدالة مُراعية للفروقات؛ تقنية Self-Forcing تُحقق إنتاج فيديو مُتدفق في الوقت الفعلي مع زمن انتقال أقل من الثانية

غالبًا ما تساوي نماذج الذكاء الاصطناعي بين "المعاملة المتساوية" التقليدية والعدالة.وفي السياقات القانونية وسيناريوهات تقييم الأضرار، فإن تطبيق مبدأ "المعاملة غير التمييزية" ميكانيكياً لتحقيق العدالة ليس حلاً عالمياً.إن بعدًا واحدًا للعدالة قد يؤدي بسهولة إلى نتائج متحيزة، وهو ما يشير إلى أنه ينبغي أخذ الاختلافات الجماعية في الاعتبار.ومن ثم، فقد أصبح من الأهمية بمكان تعزيز النماذج الكبيرة لتحقيق تحول تدريجي في النموذج من "العدالة دون تمييز" إلى "العدالة القائمة على الاختلافات المتصورة".
وبناء على هذا،أصدرت جامعة ستانفورد مجموعة بيانات معيارية للعدالة المدركة للاختلاف، والتي تهدف إلى قياس أداء النماذج في إدراك الاختلاف والوعي بالسياق.تم اختيار نتائج البحث ذات الصلة ضمن أفضل 25 ورقة بحثية من قِبل ACL. تحتوي مجموعة البيانات على ثمانية معايير تقييم، مقسمة إلى نوعين: مهام وصفية ومعيارية، تغطي مجموعة متنوعة من السيناريوهات الواقعية، بما في ذلك المجالات القانونية والمهنية والثقافية. يحتوي كل معيار تقييم على 2000 سؤال، يتطلب 1000 منها التمييز بين فئات مختلفة، ليصل المجموع إلى 16000 سؤال. يُحسّن إصدار هذا المعيار التقييمي بُعد العدالة في النماذج واسعة النطاق، مما يُوفر إضافة قيّمة لسد الفجوة بين التطور التكنولوجي والقيمة المجتمعية، ويعزز بقوة التطور العميق لمنظومة الذكاء الاصطناعي نحو اتجاه أكثر تنوعًا ودقة.
مجموعة بيانات معيار العدالة والوعي بالاختلاف متاحة الآن على الموقع الرسمي لشركة HyperAI. حمّلها الآن وجرّبها!
الاستخدام عبر الإنترنت:https://go.hyper.ai/XOx97
من 28 يوليو إلى 1 أغسطس، إليك نظرة عامة سريعة على تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 5
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في أغسطس: 9
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات المعايير البيولوجية B3DB
B3DB هي مجموعة بيانات مرجعية بيولوجية واسعة النطاق أصدرتها جامعة ماكماستر في كندا. تهدف إلى توفير معيار مرجعي لنمذجة نفاذية الحاجز الدموي الدماغي للجزيئات الصغيرة. جُمعت مجموعة البيانات من 50 مصدرًا منشورًا، وتوفر مجموعة فرعية من الخصائص الفيزيائية والكيميائية لهذه الجزيئات. وتُقدم قيم logBB الرقمية لبعض هذه الجزيئات، بينما تحتوي مجموعة البيانات بأكملها على بيانات رقمية وفئوية.
الاستخدام المباشر:https://go.hyper.ai/0mPpP
الأنمي عبارة عن مجموعة بيانات أنمي من http://MyAnimeList.net تهدف قاعدة البيانات إلى توفير مورد غنيّ وواضح وسهل الوصول لعلماء البيانات ومهندسي التعلم الآلي وعشاق الأنمي. تغطي قاعدة البيانات معلومات عن أكثر من 28,000 عمل أنمي فريد، مما يوفر رؤى ثاقبة حول اتجاهات عالم الأنمي.
الاستخدام المباشر:https://go.hyper.ai/MxrqC
3. مجموعة بيانات الاستدلال العلمي من ميجا ساينس
ميجا ساينس هي مجموعة بيانات علمية استدلالية أصدرتها جامعة شنغهاي جياو تونغ. تحتوي هذه المجموعة على 1.25 مليون نموذج، وهي مصممة لدعم معالجة اللغة الطبيعية (NLP) ونماذج التعلم الآلي، لا سيما في مهام مثل استرجاع المراجع، واستخراج المعلومات، والتلخيص التلقائي، وتحليل الاستشهادات في مجال البحث العلمي.
الاستخدام المباشر:https://go.hyper.ai/694qh
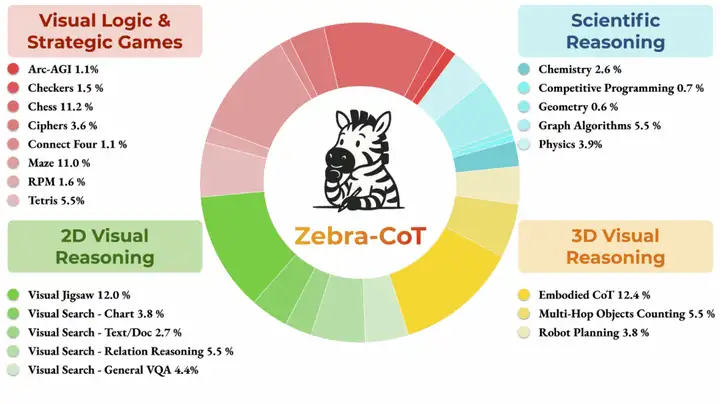
4. مجموعة بيانات استدلال النص إلى صورة Zebra-CoT
Zebra-CoT هي مجموعة بيانات للتفكير اللغوي البصري، أصدرتها جامعة كولومبيا، وجامعة ماريلاند، وجامعة جنوب كاليفورنيا، وجامعة نيويورك. تهدف هذه المجموعة إلى مساعدة النماذج على فهم العلاقات المنطقية بين الصور والنصوص بشكل أفضل. تُستخدم على نطاق واسع في مجالات مثل الإجابة على الأسئلة بصريًا وتوليد أوصاف الصور، مما يُحسّن قدرات التفكير ودقته. تحتوي مجموعة البيانات على 182,384 عينة تغطي أربع فئات رئيسية: التفكير العلمي، والتفكير البصري ثنائي الأبعاد، والتفكير البصري ثلاثي الأبعاد، وألعاب المنطق والاستراتيجية البصرية.
الاستخدام المباشر:https://go.hyper.ai/y2a1e
5. مجموعة بيانات التفكير الرياضي PolyMath
بولي ماث (PolyMath) هي مجموعة بيانات رياضية تعاونت علي بابا وجامعة شنغهاي جياو تونغ في إصدارها، وتهدف إلى تعزيز البحث في الرياضيات. تحتوي المجموعة على 500 سؤال رياضي عالي الجودة، بواقع 125 سؤالاً لكل مستوى لغوي.
الاستخدام المباشر:https://go.hyper.ai/yRVfY
6. مجموعة بيانات تقييم الموسيقى SongEval
SongEval هي مجموعة بيانات لتقييم الموسيقى، أصدرها معهد شنغهاي للموسيقى، وجامعة نورث وسترن بوليتكنيك، وجامعة سري، وجامعة هونغ كونغ للعلوم والتكنولوجيا. تهدف هذه المجموعة إلى إجراء تقييمات جمالية لأغانٍ كاملة. تحتوي المجموعة على أكثر من 2399 أغنية (بما في ذلك الغناء والعزف)، قيّمها 16 خبيرًا عبر خمسة أبعاد إدراكية: التماسك العام، وسهولة التذكر، وطبيعية التنفس الصوتي والتعبير، ووضوح بنية الأغنية، والطابع الموسيقي العام. تشمل المجموعة حوالي 140 ساعة من التسجيلات الصوتية عالية الجودة، تشمل أغاني صينية وإنجليزية وتسعة أنواع موسيقية رئيسية.
الاستخدام المباشر:https://go.hyper.ai/ohp0k
7. مجموعة بيانات توليد الفيديو Vchitect T2V
Vchitect T2V هي مجموعة بيانات لتوليد الفيديو أصدرها مختبر الذكاء الاصطناعي في شنغهاي. تهدف إلى تحسين قدرة النماذج على ترجمة المحتوى النصي إلى محتوى مرئي، مما يساعد الباحثين والمطورين على إحراز تقدم في توليد الصور، والفهم الدلالي، والمهام متعددة الوسائط. تحتوي مجموعة البيانات على 14 مليون فيديو عالي الجودة، كل منها مزود بتعليقات نصية مفصلة.
الاستخدام المباشر:https://go.hyper.ai/vLs9z
8. مجموعة بيانات النقش اللاتيني LED
تُعد قاعدة بيانات LED أكبر قاعدة بيانات للنقوش اللاتينية القابلة للقراءة آليًا حتى الآن، حيث تضم 176,861 نقشًا. ومع ذلك، فإن معظم هذه النقوش تالفة جزئيًا، مع وجود 51 نقشًا فقط من نوع TP3T تُنتج صورًا قابلة للاستخدام. تُستمد البيانات من ثلاث من أشمل قواعد بيانات النقوش اللاتينية: قاعدة بيانات النقوش الرومانية (EDR)، وقاعدة بيانات نقوش هايدلبرغ (EDH)، وقاعدة بيانات كلاوس-سلابي.
الاستخدام المباشر:https://go.hyper.ai/O8noU
9. مجموعة بيانات معيارية لترجمة الفيديو التلقائية
مجموعة بيانات AutoCaption هي مجموعة بيانات مرجعية لترجمة الفيديوهات، أصدرتها مختبرات Tjunlp. تهدف هذه المجموعة إلى تعزيز البحث في مجال نماذج اللغات الكبيرة متعددة الوسائط لتوليد ترجمة الفيديوهات. تحتوي مجموعة البيانات على مجموعتين فرعيتين، بإجمالي 11,184 عينة.
الاستخدام المباشر:https://go.hyper.ai/pgOCw
10. مجموعة بيانات الصور التفاعلية لآلة ArtVIP
ArtVIP هي مجموعة بيانات صور تفاعلية آلية أصدرها مركز بكين لابتكار الروبوتات البشرية. تحتوي هذه المجموعة على 206 كائنات مفصلية موزعة على 26 فئة. تضمن واقعية بصرية من خلال شبكات هندسية دقيقة وقوام عالي الدقة، وتحقق دقة فيزيائية من خلال معلمات ديناميكية مضبوطة بدقة، وهي الأولى من نوعها التي تُدمج سلوكيات تفاعلية معيارية ضمن الأصول، مع تمكين الشرح التوضيحي على مستوى البكسل.
الاستخدام المباشر:https://go.hyper.ai/vGYek

دروس تعليمية عامة مختارة
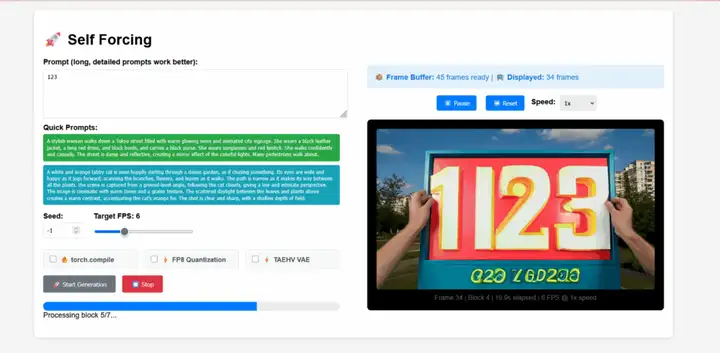
1. إنشاء فيديو ذاتي الإجبار في الوقت الفعلي
الإجبار الذاتي هو نموذج تدريبي جديد لنماذج انتشار الفيديو ذاتية الانحدار، اقترحه فريق شون هوانغ. يعالج هذا النموذج مشكلة تحيز التعريض القديمة، حيث يتعين على النموذج المُدرَّب على سياق حقيقي توليد تسلسلات بناءً على مخرجاته غير الكاملة أثناء الاستدلال. يحقق هذا النموذج توليد فيديو متدفق في الوقت الفعلي بزمن انتقال أقل من ثانية على وحدة معالجة رسومية واحدة، مع مطابقة جودة التوليد، بل وتجاوزها، لنماذج الانتشار غير السببية الأبطأ بكثير.
تشغيل عبر الإنترنت:https://go.hyper.ai/j19Hx
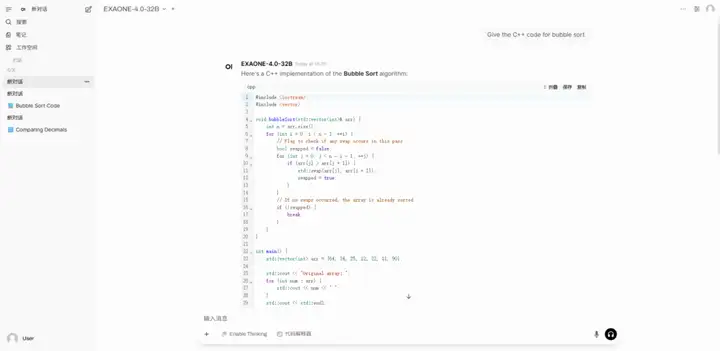
2. نشر EXAONE-4.0-32B باستخدام vLLM + Open WebUI
EXAONE-4.0 هو نموذج ذكاء اصطناعي هجين من الجيل التالي، أطلقته شركة LG AI Research في كوريا الجنوبية. وهو أيضًا أول نموذج ذكاء اصطناعي هجين في كوريا الجنوبية. يجمع هذا النموذج بين قدرات معالجة اللغة الطبيعية العامة وقدرات التفكير المتقدمة التي أثبتتها EXAONE Deep، محققًا إنجازاتٍ رائدة في مجالاتٍ صعبة كالرياضيات والعلوم والبرمجة.
تشغيل عبر الإنترنت:https://go.hyper.ai/7XiZM
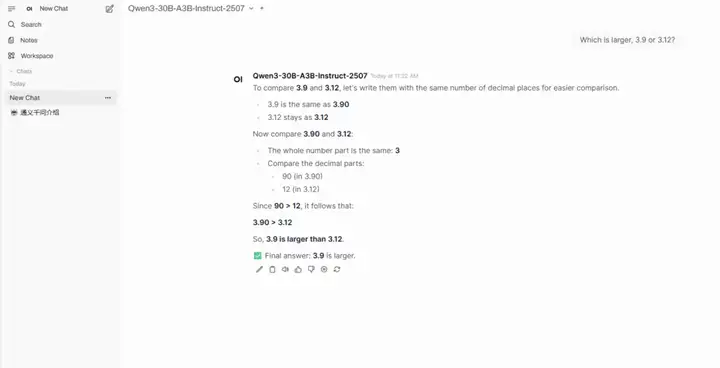
3. نشر Qwen3-30B-A3B-Instruct-2507 بنقرة واحدة
Qwen3-30B-A3B-Instruct-2507 هو نموذج لغوي ضخم طوّره مختبر تونغي وانكسيانغ التابع لشركة علي بابا. هذا النموذج هو نسخة مُحدّثة من وضع عدم التفكير في Qwen3-30B-A3B. ومن أبرز ما يميزه أنه، مع تفعيل 3 مليارات معلمة فقط (3B)، يُظهر أداءً مُبهرًا يُضاهي أداء Gemini 2.5-Flash من جوجل (وضع عدم التفكير) وGPT-4o من OpenAI. ويُمثل هذا إنجازًا كبيرًا في كفاءة النموذج وتحسين أدائه.
تشغيل عبر الإنترنت:https://go.hyper.ai/hr1o6
4. Wan2.2: نموذج مفتوح ومتقدم لتوليد الفيديو واسع النطاق
Wan-2.2 هو نموذج متقدم مفتوح المصدر لتوليد الفيديو بالذكاء الاصطناعي، طوره مختبر تونغيي وانكسيانغ التابع لشركة علي بابا. يقدم هذا النموذج بنية "مزيج الخبراء" (MoE)، مما يُحسّن جودة الإنتاج وكفاءة الحوسبة بشكل فعال. كما يُقدم نظام تحكم سينمائيًا رائدًا، يتيح التحكم الدقيق في الإضاءة والألوان والتركيب والمؤثرات الجمالية الأخرى.
تشغيل عبر الإنترنت:https://go.hyper.ai/AG6CE
5. PE3R: إطار عمل للإدراك الفعال وإعادة البناء ثلاثي الأبعاد
PE3R (إعادة بناء ثلاثية الأبعاد بكفاءة الإدراك) هو إطار عمل مبتكر مفتوح المصدر لإعادة بناء ثلاثية الأبعاد، أصدره مختبر XML في الجامعة الوطنية في سنغافورة. يدمج هذا الإطار تقنيات الإدراك متعددة الوسائط لتحقيق نمذجة مشاهد فعّالة وذكية. طُوّر هذا الإطار بناءً على العديد من نتائج أبحاث الرؤية الحاسوبية المتطورة، ويُعيد بناء المشاهد ثلاثية الأبعاد بسرعة من صور ثنائية الأبعاد فقط. على بطاقة رسومات RTX 3090، يبلغ متوسط وقت إعادة بناء مشهد واحد 2.3 دقيقة فقط، وهو تحسن يزيد عن 65% مقارنةً بالطرق التقليدية.
تشغيل عبر الإنترنت:https://go.hyper.ai/3BnDy

توصيات الورقة البحثية لهذا الأسبوع
1. تحسين السياسات المعززة بالوكالة
في سيناريوهات التفكير الواقعي، غالبًا ما تستفيد نماذج اللغات الكبيرة (LLMs) من أدوات خارجية للمساعدة في حل المهام. ومع ذلك، تواجه خوارزميات التعلم التعزيزي الحالية صعوبة في موازنة قدرات التفكير بعيد المدى الكامنة في النموذج مع كفاءتها في التفاعلات متعددة الجولات مع الأدوات. لسد هذه الفجوة، تقترح هذه الورقة البحثية خوارزمية تحسين سياسة تعزيز الوكلاء (ARPO)، وهي خوارزمية جديدة للتعلم التعزيزي مصممة خصيصًا لتدريب الوكلاء متعددي الجولات المعتمدين على نماذج اللغات الكبيرة. تحقق هذه الخوارزمية تحسينات في الأداء بنصف ميزانية استخدام الأدوات المستخدمة في الطرق الحالية فقط، مما يوفر حلاً قابلاً للتطوير لمواءمة الوكلاء المعتمدين على نماذج اللغات الكبيرة مع البيئات الديناميكية في الوقت الفعلي.
رابط الورقة:https://go.hyper.ai/lPyT2
لا يزال إنشاء عوالم ثلاثية الأبعاد غامرة وتفاعلية من النصوص والصور يُمثل تحديًا أساسيًا في مجال الرؤية الحاسوبية والرسومات. تعاني أساليب إنشاء العوالم الحالية من بعض القيود، مثل ضعف اتساق الصورة ثلاثية الأبعاد وانخفاض كفاءة العرض. ولمعالجة هذه المشكلة، تقترح هذه الورقة إطار عمل مبتكرًا، هونيوان وورلد 1.0، لإنشاء مشاهد ثلاثية الأبعاد غامرة وقابلة للاستكشاف وتفاعلية من النصوص والصور.
رابط الورقة:https://go.hyper.ai/aMbdz
على الرغم من التقدم المُحرز مؤخرًا في توليد النصوص إلى أكواد باستخدام نماذج اللغة الكبيرة (LLMs)، إلا أن العديد من الطرق الحالية تعتمد كليًا على إشارات اللغة الطبيعية، مما يُصعّب عليها استيعاب البنية المكانية للتخطيطات وهدف التصميم المرئي بفعالية. في المقابل، يُعد تطوير واجهات المستخدم في العالم الحقيقي متعدد الوسائط بطبيعته، وغالبًا ما يبدأ برسومات أو نماذج أولية مرئية. ولسد هذه الفجوة، تقترح هذه الورقة البحثية ScreenCoder، وهو إطار عمل معياري متعدد الوكلاء يُمكّن توليد واجهات المستخدم إلى أكواد من خلال ثلاث مراحل قابلة للتفسير: التوطين، والتخطيط، والتوليد.
رابط الورقة:https://go.hyper.ai/k4p58
4. ARC-Hunyuan-Video-7B: فهم منظم للفيديوهات القصيرة من العالم الحقيقي
تفتقر نماذج الوسائط المتعددة واسعة النطاق الحالية إلى القدرات اللازمة لفهم الفيديو، المُهيكل زمنيًا والمُفصل والمتعمق، والتي تُعدّ أساسيةً للبحث والتوصية بالفيديو بفعالية، بالإضافة إلى تطبيقات الفيديو الناشئة. تقترح هذه الدراسة نموذج ARC-Hunyuan-Video، وهو نموذج متعدد الوسائط يُعالج الإشارات المرئية والصوتية والنصية من البداية إلى النهاية من مُدخلات الفيديو الخام لتحقيق فهم مُهيكل. يتميز النموذج بوصف وتلخيص فيديو مُتعدد التفاصيل مُؤرخ زمنيًا، وإجابة مفتوحة على أسئلة الفيديو، وتحديد موقع الفيديو زمنيًا، والتفكير المنطقي.
رابط الورقة:https://go.hyper.ai/ogYbH
5. باحث عميق مع انتشار وقت الاختبار
عند استخدام خوارزميات قياس زمن الاختبار الشائعة لإنشاء تقارير بحثية معقدة وطويلة، غالبًا ما يواجه أداؤها عوائق. مستوحاة من الطبيعة التكرارية لعملية البحث البشري، تقترح هذه الورقة البحثية الباحث العميق للانتشار في زمن الاختبار (TTD-DR). يبدأ TTD-DR العملية بمسودة أولية (إطار عمل قابل للتحديث) تُشكل أساسًا متطورًا لتوجيه مسار البحث. هذا التصميم المُركّز على المسودة يجعل عملية كتابة التقارير أكثر توقيتًا وتماسكًا، مع تقليل فقدان المعلومات أثناء البحث التكراري.
رابط الورقة:https://go.hyper.ai/D4gUK
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
أطلق فريق بقيادة شي بوكسين من جامعة بكين، بالتعاون مع OpenBayes Bayes للحوسبة البايزية، إطار عمل PanoWan لتوليد مقاطع فيديو بانورامية موجهة بالنص. بفضل بنيته المعيارية البسيطة والفعّالة، ينقل هذا النهج بسلاسة البيانات الأولية التوليدية لنماذج تحويل النص إلى فيديو المُدرّبة مسبقًا إلى المجال البانورامي.
شاهد التقرير الكامل:https://go.hyper.ai/9UWXl
قام فريق بحثي من جامعة بوترا ماليزيا (UPM) وجامعة نيو ساوث ويلز (UNSW) في سيدني بتطوير إطار عمل ذكي للتصنيف التلقائي وتقدير القيمة السوقية للقطع الأثرية الخزفية، بالاعتماد على نموذج YOLOv11. يُمكّن نموذج YOLOv11 المُحسّن من تحديد السمات الخزفية الرئيسية، مثل الأنماط الزخرفية والأشكال والحرفية، والتنبؤ بأسعار السوق بناءً على الخصائص المرئية المُستخرجة وبيانات المزادات متعددة المصادر. يوفر هذا حلاً قابلاً للتطوير لمصادقة الخزف الذكية والمعالجة الرقمية للقطع الأثرية.
شاهد التقرير الكامل:https://go.hyper.ai/XcuLz
قام فريق بحثي من جامعة بنسلفانيا بالولايات المتحدة الأمريكية بدمج أربع قواعد بيانات رئيسية للسموم لبناء قاعدة بيانات عالمية للسموم، وطبق نموذج APEX للتعلم العميق القائم على تحليل التسلسل الوظيفي، والذي يُستخدم خصيصًا للبحث المنهجي عن مضادات البكتيريا المحتملة في بروتيوم السم. وفي النهاية، نجحوا في فرز 386 ببتيدًا مرشحًا يتمتع بإمكانات مضادة للبكتيريا وتشابه تسلسلي منخفض مع AMPs المعروفة.
شاهد التقرير الكامل:https://go.hyper.ai/u067l
أطلق فريق بحثي مشترك من شركة NVIDIA، ومختبر لورانس بيركلي الوطني، وجامعة كاليفورنيا، بيركلي، ومعهد كاليفورنيا للتكنولوجيا، نظام FourCastNet 3 (FCN3)، وهو نظام تنبؤ بالطقس قائم على التعلم الآلي الاحتمالي، يجمع بين معالجة الإشارات الكروية وإطار عمل مجموعة ماركوف المخفية. يستطيع النظام إنتاج توقعات جوية لمدة 15 يومًا في 60 ثانية باستخدام وحدة معالجة رسومية واحدة من طراز NVIDIA H100.
شاهد التقرير الكامل:https://go.hyper.ai/JQh25
أطلق مختبر تونغيي وانكسيانغ التابع لشركة علي بابا مؤخرًا نموذجه المتطور لتوليد الفيديو بالذكاء الاصطناعي، Wan2.2. يُحسّن هذا النموذج، الذي يعتمد على بنية مزيج الخبراء (MoE)، جودة التوليد وكفاءة الحوسبة بشكل كبير، مما يُمكّن من التشغيل بكفاءة على بطاقات الرسومات الاستهلاكية مثل NVIDIA RTX 4090. كما أنه رائد في نظام تحكم سينمائي، يُتيح التحكم الدقيق في الإضاءة والألوان والتركيب والمؤثرات الجمالية الأخرى.
شاهد التقرير الكامل:https://go.hyper.ai/RgFmY
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








