Command Palette
Search for a command to run...
نموذج جديد لتقييم جماليات الصوت! أوديو بوكس-إيستيتكس رائدة في مجال القياس الكمي الصوتي رباعي الأبعاد؛ 6.7 مليون قضية! قانون القضايا يُمهد الطريق للامتثال للمرجع القانوني.

يعتمد تقييم الصوت التقليدي عادةً على الاستماع اليدوي، وتحيزه الذاتي يُصعّب توحيد معايير التقييم. على الرغم من أن أساليب وأدوات التقييم الحالية تُعطي نتائج تقييمية مُحددة، إلا أن مُعظمها يُركز فقط على جودة الصوت العامة، ويفتقر إلى تحليل مُستهدف للتفاصيل المحلية.
تحقيقا لهذه الغاية،أطلقت شركة Meta AI تطبيق Audiobox-Aesthetics، وهو أداة لتقييم جودة الصوت.تحقيق تحليل تلقائي متعدد الأبعاد للكلام والموسيقى والأصوات البيئية.قم بتقييم جودة الصوت بشكل شامل من خلال أربعة أبعاد أساسية: جودة الإنتاج، وتعقيد الإنتاج، ومتعة المحتوى، وفائدة المحتوى.إنه لا يعوض فقط العيوب المتأصلة في الاستماع اليدوي والأدوات الموجودة، بل يوفر أيضًا تحليلًا كميًا على المستوى الاحترافي لمنشئي الصوت والمهندسين والباحثين، ويقدم إرشادات دقيقة لتحسين الصوت.
في الوقت الحاضر، أطلق الموقع الرسمي لشركة HyperAI "عرضًا توضيحيًا لتقييم جماليات الصوت AudioBox-Aesthetics"، تعال وجربه~
الاستخدام عبر الإنترنت:https://go.hyper.ai/FNpIQ
من 21 يوليو إلى 25 يوليو، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 8
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في أغسطس: 9
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات معلومات الأدوية الطبية
مجموعة بيانات المعلومات الطبية (MID) هي حاليًا أكبر وأكثر مجموعات بيانات الأدوية تمثيلًا. تحتوي المجموعة على بيانات من 44 فئة علاجية مختلفة، تغطي أكثر من 192,000 دواء. وتهدف إلى توفير معلومات دقيقة وموثوقة عن الأدوية، ودعم تصنيف الأدوية ووضع الملصقات العلاجية، وتحسين التنبؤ بنتائج التجارب السريرية وكفاءتها.
الاستخدام المباشر:https://go.hyper.ai/qmGCW
2. مجموعة بيانات الاستدلال الرياضي Nemotron-Math-HumanReasoning
Nemotron-Math-HumanReasoning هي مجموعة بيانات استدلال رياضي أصدرتها NVIDIA، وتهدف إلى محاكاة أسلوب الاستدلال الموسّع لنماذج مثل DeepSeek-R1. تحتوي مجموعة البيانات على 50 مسألة رياضية من مجموعة بيانات OpenMathReasoning، و200 إجابة مكتوبة يدويًا، و50 إجابة إضافية مُولّدة بواسطة QwQ-32B-Preview.
الاستخدام المباشر:https://go.hyper.ai/udrjz
3. مجموعة بيانات النصوص الاصطناعية الهندية Updesh
Updesh هي مجموعة بيانات نصية اصطناعية باللغة الهندية، أصدرتها مايكروسوفت، وتهدف إلى تعزيز التدريب اللاحق لنماذج اللغات الكبيرة (LLMs) للغات الهندية. تحتوي مجموعة البيانات على 6,800,000 بيانات استدلالية و2,100,000 بيانات مُولّدة، تغطي لغات مثل الآسامية والبنغالية.
الاستخدام المباشر:https://go.hyper.ai/wMWci
4. مجموعة بيانات الكيمياء الكمومية QMOF150
QMOF150 هي مجموعة بيانات كيمياء كمومية أصدرتها ميتا وجامعة كامبريدج لتسريع اكتشاف المواد الكمومية. تحتوي مجموعة البيانات على حوالي 14,000 إطار عضوي معدني (MOFs) وبوليمرات تنسيق. من بينها، تم تضمين الخصائص المحسوبة للأطر العضوية المعدنية المُوَصَّفة تجريبيًا بعد الاسترخاء الهيكلي باستخدام نظرية التدفق المنفصل (DFT)، بما في ذلك على سبيل المثال لا الحصر: الهندسة المُحسَّنة، والطاقة، وفجوة النطاق، وكثافة الشحنة، وكثافة الحالة، والشحنة الجزئية، وكثافة الدوران، وترتيب الرابطة.
الاستخدام المباشر:https://go.hyper.ai/2rxVD
5. مجموعة بيانات الكشف عن سترات السلامة
"كشف سترات السلامة" هي مجموعة بيانات للكشف عن سترات السلامة، مصممة لتقييم هياكل الكشف عن الأجسام الجديدة (YOLOv8، Faster-RCNN، SSD، إلخ)، ونقل التعلم من مهام الكشف عن معدات الوقاية الشخصية (الخوذ، القفازات، النظارات الواقية)، وتطوير نماذج أولية لأجهزة مراقبة السلامة المثبتة على الحافة، مما يساعد على تطوير وتدريب نماذج لتحديد واكتشاف الأشخاص الذين يرتدون سترات السلامة تلقائيًا، وتحسين سلامة مكان العمل. تتضمن مجموعة البيانات 3897 صورة عالية الدقة، وتعليقات توضيحية على الإطار المحيط، وسياق الصورة.
الاستخدام المباشر:https://go.hyper.ai/q0aEL

6. مجموعة بيانات التفكير الرياضي والعلمي Open-Omega-Atom-1.5M
Open-Omega-Atom-1.5M هي مجموعة بيانات رياضية وعلمية مصممة لتعزيز قدرات التفكير المنطقي في مجالات الرياضيات والعلوم. تحتوي مجموعة البيانات على حوالي 1.5 مليون قطعة بيانات، وهي مصممة لتطبيقات الرياضيات والعلوم والبرمجة، حيث تلعب البيانات الرياضية دورًا مهمًا في تكوينها.
الاستخدام المباشر:https://go.hyper.ai/ctAbA
7. مجموعة بيانات نص المحادثة الصوتية AF-Chat
AF-Chat هي مجموعة بيانات نصية للمحادثات الصوتية، أصدرتها NVIDIA لتدريب وتقييم نماذج توليد المحادثات. تحتوي مجموعة البيانات على حوالي 75,000 محادثة متعددة الأدوار والصوت (بمتوسط 4.6 مقطع و6.2 جولة؛ تتراوح من 2 إلى 8 مقاطع ومن 2 إلى 10 جولات)، تغطي الكلام والأصوات البيئية والموسيقى.
الاستخدام المباشر:https://go.hyper.ai/mx6G0
8. مجموعة بيانات مشكلة الترميز على مستوى المنافسة rStar Coder
rStar Coder هي مجموعة بيانات واسعة النطاق لمسائل البرمجة على مستوى المنافسة، أصدرتها مايكروسوفت، وتهدف إلى تحسين قدرة نماذج اللغات الكبيرة على تحليل الشفرة، وخاصةً في التعامل مع مسائل البرمجة على مستوى المنافسة. تحتوي مجموعة البيانات على 418,000 مسألة برمجة على مستوى المنافسة، و580,000 حل منطقي مطول، ومجموعة غنية من حالات الاختبار (بمستويات صعوبة مختلفة). تم التحقق من كل حل من خلال محاكاة حالات اختبار مختلفة بمستويات صعوبة مختلفة.
الاستخدام المباشر:https://go.hyper.ai/uJXHe
9. مجموعة بيانات الأدبيات القانونية للسوابق القضائية
"سوابق القضاء" هي مجموعة بيانات للأدبيات القانونية تنشرها جامعة تورنتو، وتضم 6.7 مليون قضية من مشروع الوصول إلى السوابق القضائية وقاعدة بيانات المحكمة. يحصل مشروعا الوصول إلى السوابق القضائية وقاعدة بيانات المحكمة على البيانات القانونية من مصادر متنوعة، بما في ذلك الوثائق المتاحة للعامة فقط، مثل مكتبة هارفارد القانونية، ومكتبة الكونجرس القانونية، وقاعدة بيانات المحكمة العليا.
الاستخدام المباشر:https://go.hyper.ai/a1bET
10. مجموعة بيانات توليد البروتين APM
APM هي مجموعة بيانات لتوليد البروتين، أصدرتها جامعة هونان، وجامعة الأكاديمية الصينية للعلوم، وفريق بايت دانس سيد عام ٢٠٢٥. تتكون من مجموعات بيانات بروتينية أحادية السلسلة وأخرى متعددة السلاسل.
الاستخدام المباشر:https://go.hyper.ai/p4qgN
دروس تعليمية عامة مختارة
1. عرض توضيحي لتقييم جماليات الصوت في AudioBox-Aesthetics
Audiobox-Aesthetics هي أداة لتقييم جودة الصوت من Meta AI. تعتمد هذه الأداة على تقنية التعلم العميق، وتُجري تحليلًا تلقائيًا متعدد الأبعاد للكلام والموسيقى والأصوات البيئية، وتُقيّم جودة الصوت بشكل شامل من خلال أربعة أبعاد أساسية، وتُقدم تحليلًا كميًا احترافيًا لمُنشئي الصوت والمهندسين والباحثين.
تشغيل عبر الإنترنت:https://go.hyper.ai/FNpIQ
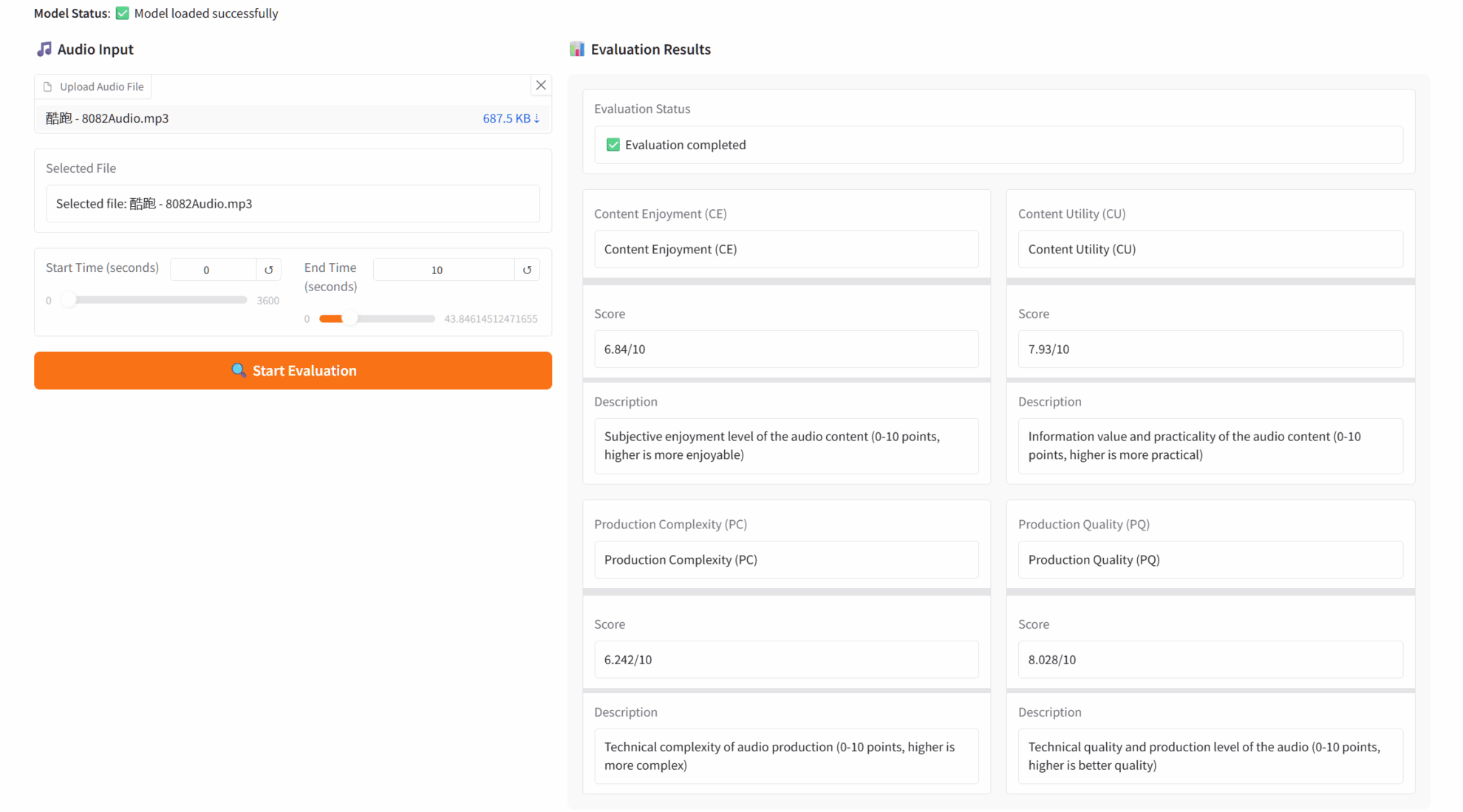
2. LFM2-1.2B: نموذج توليد نص فعال مُنشر على الحافة
LFM2-1.2B هو الجيل الثاني من نماذج Liquid Foundation (LFMs) التي أطلقتها Liquid AI. وهو نموذج ذكاء اصطناعي توليدي قائم على بنية هجينة. يهدف إلى توفير أسرع تجربة ذكاء اصطناعي توليدي على الجهاز في هذا المجال، وهو مصمم لأحمال عمل نماذج اللغة على الجهاز ذات زمن الوصول المنخفض.
تشغيل عبر الإنترنت:https://go.hyper.ai/fEtm9
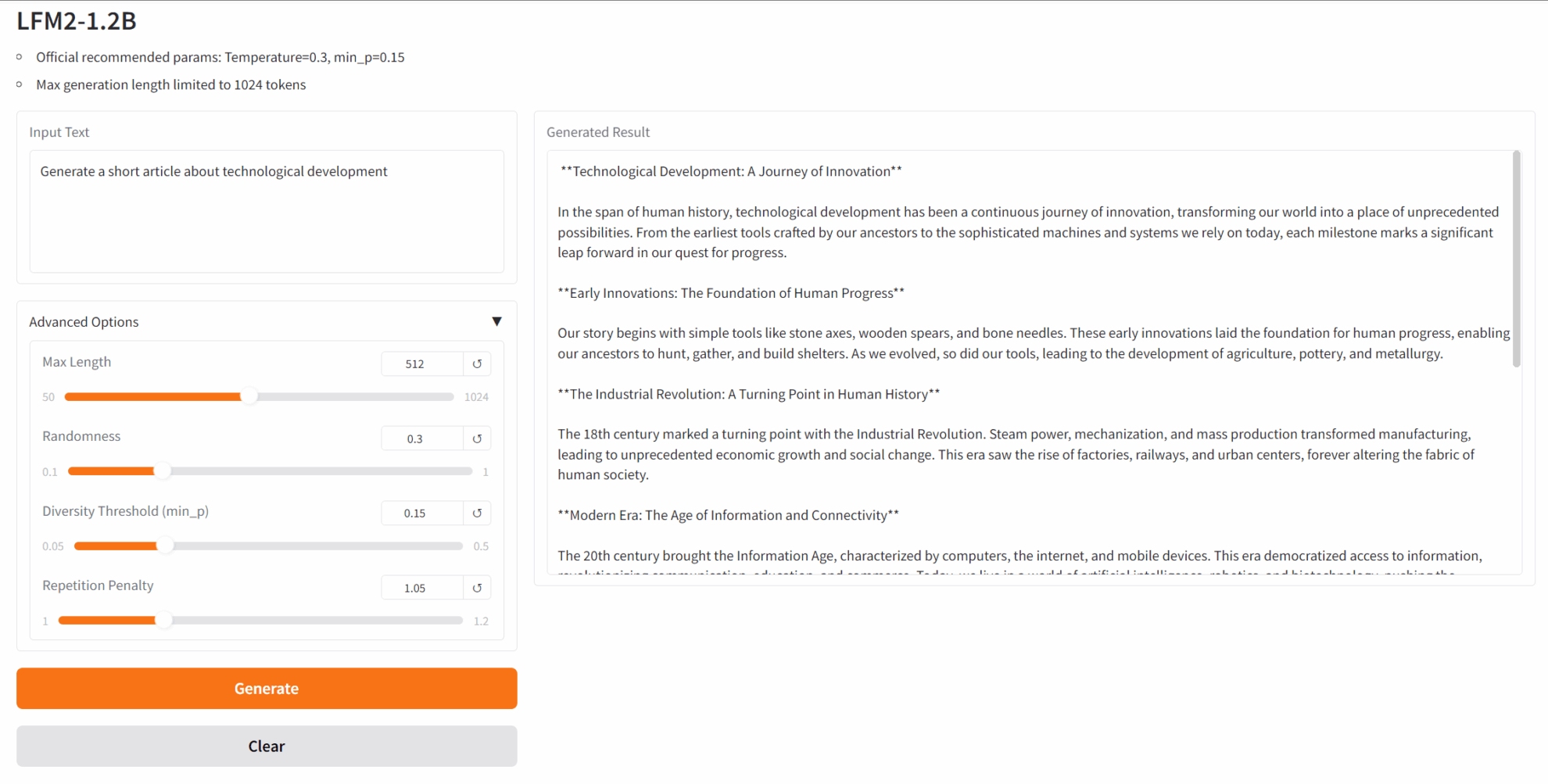
3. Osmosis-Structure-0.6B: نموذج لغوي صغير ذو مخرجات منظمة
Osmosis-Structure-0.6B هو نموذج لغة صغير متخصص (SLM) أطلقته Osmosis، مصمم لإكمال مهام توليد المخرجات المنظمة. على الرغم من أن حجم معاملاته يبلغ 0.6B فقط، إلا أن النموذج يُظهر أداءً ممتازًا في استخراج المعلومات المنظمة عند استخدامه مع الأطر المدعومة.
تشغيل عبر الإنترنت:https://go.hyper.ai/ayrhc
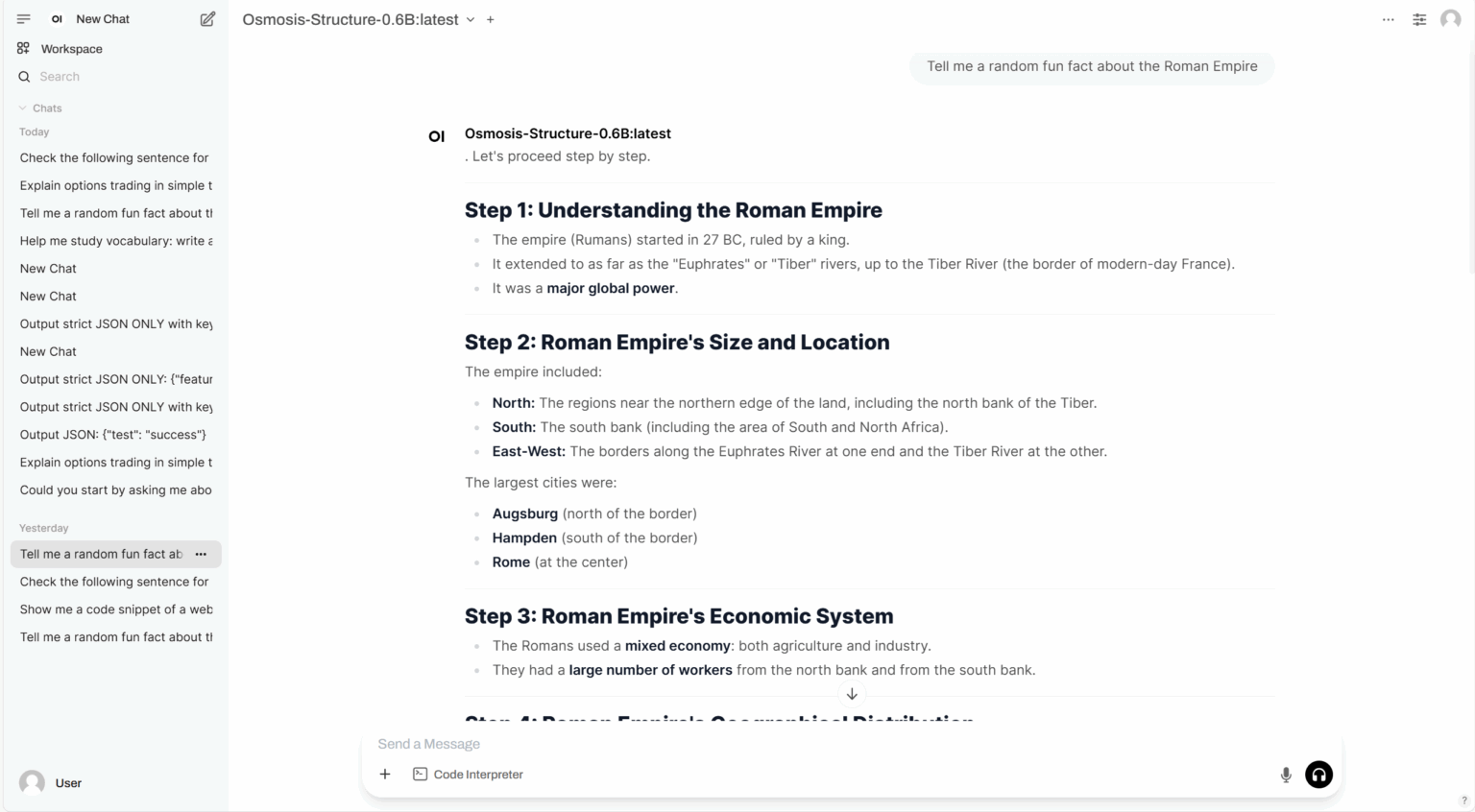
4. MOSS: توليد الحوار من النص إلى الكلام
MOSS-TTSD هو نموذج مفتوح المصدر لتوليف الحوار المنطوق ثنائي اللغة، أصدره فريق OpenMOSS، ويدعم اللغتين الصينية والإنجليزية. يحوّل MOSS-TTSD نص المحادثة بين متحدثين إلى كلام حواري طبيعي ومعبر. يدعم MOSS-TTSD استنساخ الصوت وتوليد كلام طويل من مقطع واحد، مما يجعله خيارًا مثاليًا لإنتاج بودكاست الذكاء الاصطناعي.
تشغيل عبر الإنترنت:https://go.hyper.ai/FOpMa
5. isometric-skeumorphic-3d-bnb: إنشاء أيقونات ثلاثية الأبعاد متساوية القياس
isometric-skeumorphic-3d-bnb هو نموذج LoRA أصدرته مجموعة multimodalart، ويركز على إنشاء أيقونات ثلاثية الأبعاد متساوية القياس تجمع بين جماليات التصميم المجسم وخصائص الأسلوب. يُظهر النموذج أداءً ممتازًا عند التعامل مع الكائنات الواقعية والمعالم المعمارية، ويمكنه تحويلها إلى رسومات توضيحية سهلة التمييز بأسلوب الأيقونات.
تشغيل عبر الإنترنت:https://go.hyper.ai/3BnDy

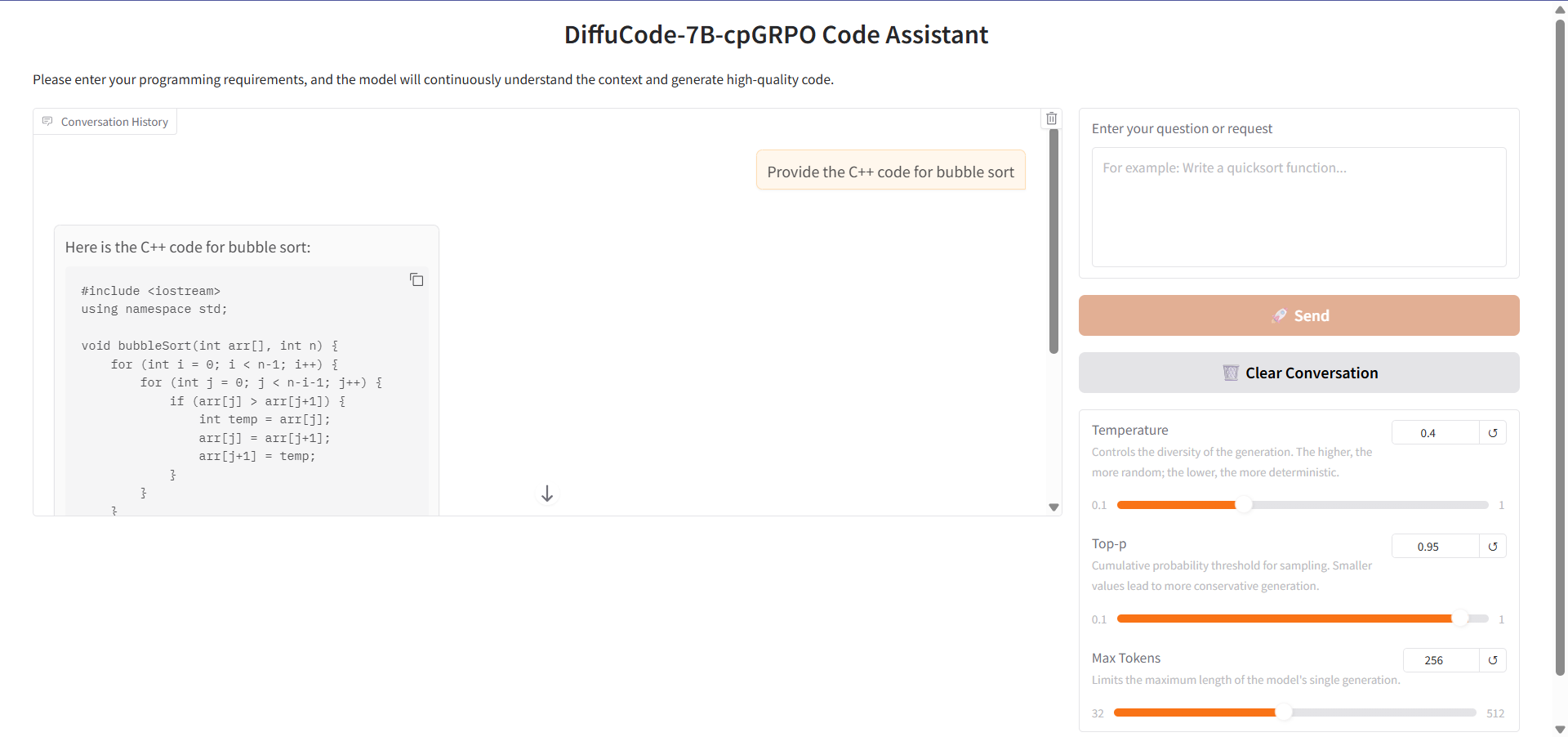
6. DiffuCode-7B-cpGRPO: نموذج توليد الكود يعتمد على تقنية انتشار القناع
DiffuCoder-7B-cpGRPO هو نموذج توليد شيفرة قائم على الانتشار المقنع (dLLM) اقترحه فريق Apple. يهدف النموذج إلى توليد الشيفرة وتحريرها من خلال تقليل الضوضاء التكرارية بدلاً من التوليد الانحداري التلقائي التقليدي من اليسار إلى اليمين.
تشغيل عبر الإنترنت:https://go.hyper.ai/CMfWm
7. LAMMPS: باستخدام الألومنيوم أحادي البلورة كمثال، يتم محاكاة التوتر أحادي المحور للمواد
LAMMPS (محاكي ذري/جزيئي ضخم متوازي واسع النطاق) هو برنامج محاكاة ديناميكيات جزيئية كلاسيكي يركز على نمذجة المواد. في هذا البرنامج التعليمي، نقوم بمحاكاة حالة تطبيق إجهاد أحادي المحور على المادة عن طريق تغيير ثابت الشبكة، ثم نحسب ونرسم منحنى الإجهاد-الإجهاد للمادة.
تشغيل عبر الإنترنت:https://go.hyper.ai/LAqAs
8. نموذج توضيحي لفهم الكلام Voxtral-Mini-3B-2507
Voxtral هو نموذج صوتي متقدم أطلقته Mistral AI. بفضل قدرته الممتازة على نسخ الصوت وفهمه العميق، يُعزز هذا النموذج استخدام الصوت كوسيلة طبيعية للتفاعل بين الإنسان والحاسوب. يدعم النموذج لغات متعددة، ومعالجة سياقات النصوص الطويلة، ووظائف مدمجة للإجابة على الأسئلة والتلخيص، ويمكنه تشغيل استدعاءات وظائف الواجهة الخلفية مباشرةً. يتفوق أداء Voxtral على النماذج مفتوحة المصدر الحالية وواجهات برمجة التطبيقات الخاصة في العديد من المعايير، مع انخفاض تكلفته واستخدامه على نطاق واسع في سيناريوهات مختلفة، مما يُسهم في تعميم التفاعل الصوتي.
تشغيل عبر الإنترنت:https://go.hyper.ai/PpjOs
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

توصيات الورقة البحثية لهذا الأسبوع
1. GUI-G^2: نمذجة المكافأة الغوسية لتأريض واجهة المستخدم الرسومية
مستوحاة من حقيقة أن سلوك النقر البشري يُشكّل توزيعًا غاوسيًا طبيعيًا مُركّزًا على العنصر المُستهدف، تُقدّم هذه الورقة البحثية مكافأة التوطين الغاوسي لواجهة المستخدم الرسومية (GUI-G^2)، وهي إطار عمل قائم على مبادئ المكافآت، يُنمذج عناصر واجهة المستخدم الرسومية كتوزيعات غاوسية مُستمرة على الواجهة. يُظهر تحليل البحث أن النمذجة المُستمرة تُوفّر متانة أفضل لتغييرات الواجهة وتعميمًا أقوى للتخطيطات غير المرئية، مما يُرسي نموذجًا جديدًا للاستدلال المكاني في مهام تفاعل واجهة المستخدم الرسومية.
رابط الورقة:https://go.hyper.ai/wLUhD
٢. MiroMind-M1: تقدم مفتوح المصدر في التفكير الرياضي عبر تحسين السياسات متعدد المراحل المراعي للسياق
تطورت نماذج اللغات الكبيرة مؤخرًا من توليد نصوص سلسة إلى استدلال متقدم عبر مجالات متعددة، مما أدى إلى ظهور نماذج اللغة الاستدلالية (RLMs). ولتعزيز الشفافية في تطوير نماذج اللغة الاستدلالية، أطلق الباحثون سلسلة MiroMind-M1، وهي مجموعة من نماذج اللغة الاستدلالية مفتوحة المصدر بالكامل، مبنية على إطار عمل Qwen-2.5، بأداء يُضاهي أو يفوق نماذج اللغة الاستدلالية مفتوحة المصدر الحالية.
رابط الورقة:https://go.hyper.ai/EGWPq
٣. ما وراء حدود السياق: خيوط اللاوعي للتفكير بعيد المدى
يحدّ محدودية طول سياق نماذج اللغات الكبيرة (LLMs) من دقة وكفاءة الاستدلال. وللتغلب على هذا القيد، تقترح هذه الورقة نموذج استنتاج الخيط (TIM)، وهو مجموعة من نماذج اللغات الكبيرة مُخصصة لحل المشكلات التكرارية والتحليلية. كما تقترح TIMRUN، وهي بيئة تشغيل استدلال تُمكّن الاستدلال الهيكلي طويل المدى بما يتجاوز حدود السياق.
رابط الورقة:https://go.hyper.ai/18j9w
4. المقود غير المرئي: لماذا قد لا ينجو RLVR من أصله
تُقدّم هذه الدراسة رؤى جديدة حول القيود المحتملة لـ RLVR من خلال التحليل النظري والتجريبي، كاشفةً عن القيود المحتملة لـ RLVR في توسيع حدود التفكير المنطقي. قد يتطلب كسر هذا القيد الخفي ابتكارات خوارزمية مستقبلية، مثل آليات الاستكشاف الصريحة أو الاستراتيجيات الهجينة لإدخال الكتلة الاحتمالية في المناطق غير الممثلة في فضاء الحل.
رابط الورقة:https://go.hyper.ai/kkRo2
5. الشيطان وراء القناع: ثغرة أمنية ناشئة في برامج الماجستير في القانون المتعلقة بالانتشار
برزت مؤخرًا نماذج اللغات واسعة النطاق القائمة على الانتشار (dLLMs) كبديل فعال لنماذج اللغات واسعة النطاق ذاتية الانحدار، حيث توفر سرعة استدلال أعلى وتفاعلية أعلى من خلال فك التشفير المتوازي والنمذجة ثنائية الاتجاه. ومع ذلك، تفشل آليات المحاذاة الحالية في حماية نماذج اللغات واسعة النطاق من هجمات الاستجابة الفورية المعادية للسياق باستخدام مدخلات مُقنّعة، مما يكشف عن ثغرات أمنية جديدة. ولتحقيق هذه الغاية، تقترح هذه الورقة البحثية DIJA، وهو أول إطار عمل لهجمات كسر الحماية يدرس ويبني بشكل منهجي نقطة ضعف أمنية فريدة لنماذج اللغات واسعة النطاق، مما يُبرز الحاجة المُلحة لإعادة النظر في آليات المحاذاة الآمنة لهذه الفئة الناشئة من نماذج اللغات.
رابط الورقة:https://go.hyper.ai/dyDhr
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
في الخطاب الرئيسي "Triton-distributed: Native Python Programming for High Performance Communications"، قام Zheng Size، عالم أبحاث Seed من ByteDance، بتحليل مفصل للاختراق في كفاءة الاتصالات لـ Triton-distributed في تدريب النماذج الكبيرة، والقدرة على التكيف عبر الأنظمة الأساسية، وكيفية تحقيق التكامل العميق للاتصالات والحوسبة من خلال برمجة Python.
شاهد التقرير الكامل:https://go.hyper.ai/L2rfl
اقترحت مجموعة البروفيسور تشنغ ينكيانغ من جامعة طوكيو ومجموعة البروفيسور دينغ جون من جامعة ماكجيل طريقةً مشتركةً لنمذجة بيانات النسخ المكاني، تُعرف باسم SUICA، وهي نموذج تعلّم عميق يعتمد على التمثيل العصبي الضمني وترميز الرسوم البيانية التلقائي. تُظهر النتائج أن بيانات النسخ المكاني التي تُعالجها SUICA تتميز بجودة أعلى، وضوضاء أقل، وإشارات بيولوجية أقوى. وقد تم اختيار نتائج البحث ذات الصلة لمؤتمر ICML 2025.
شاهد التقرير الكامل:https://go.hyper.ai/5esoL
ألقى الدكتور وانج لي، مؤسس مجتمع TileAI، خطابًا بعنوان "ربط قابلية البرمجة والأداء في أحمال عمل الذكاء الاصطناعي الحديثة"، حيث قدم لغة برمجة المشغل المبتكرة TileLang بطريقة سهلة الفهم وشارك مفاهيم التصميم الأساسية والمزايا التقنية.
شاهد التقرير الكامل:https://go.hyper.ai/AkeOJ
اقترحت جامعة هونان، بالتعاون مع جامعة الأكاديمية الصينية للعلوم وفريق بايت دانس سيد، نموذجًا جديدًا لتوليد البروتينات الذرية بالكامل (APM). يدمج هذا النموذج معلومات على المستوى الذري، ويدعم توليد البروتينات متعددة السلاسل، وطيّها، وطيّها العكسي دون الاعتماد على اتصالات شبه التسلسل. ويمكنه تحقيق أداء يفوق أداء نموذج SOTA الحالي في المهام اللاحقة، مثل تصميم الأجسام المضادة وتصميم ربط الببتيد.
شاهد التقرير الكامل:https://go.hyper.ai/fJvpi
نشر باحثون من Google DeepMind، بالتعاون مع جامعة نوتنغهام وجامعة وارويك وجامعات أخرى، ورقة بحثية بعنوان "وضع النصوص القديمة في سياقها باستخدام الشبكات العصبية التوليدية" في المجلة الأكاديمية الرائدة في العالم Nature، معلنين أن Aeneas حقق أول عملية ترميم ذات طول تعسفي للنقوش الرومانية القديمة.
شاهد التقرير الكامل:https://b23.moe/cYtSI
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
الموعد النهائي للقمة في أغسطس
1 أغسطس 7:59:59 إنفوكوم 2026
1 أغسطس 7:59:59 كيه دي دي 2026
2 أغسطس 7:59:59 HPCA 2026
2 أغسطس 7:59:59 UbiComp 2025
2 أغسطس 11:59:59 قاعدة بيانات VLDB 2026
2 أغسطس 19:59:59 AAAI 2026
7 أغسطس 7:59:59 الاستراتيجية الوطنية للأمن الغذائي 2026
21 أغسطس 11:59:59 أسبلوس 2026
27 أغسطس 7:59:59 ندوة أمن USENIX 2025
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








