Command Palette
Search for a command to run...
٢٥٠٠ سؤال! حققت HLE تقدمًا كبيرًا في بناء نظام تقييم دقيق لنماذج اللغات الكبيرة؛ جان نانو، وهو نموذج لغوي كبير خفيف الوزن يحتوي على ٤ مليارات معلمة، مصمم لمهام بحثية متعمقة.

في السنوات الأخيرة، حققت نماذج اللغات الكبيرة (LLMs) تقدمًا هائلًا، وأصبحت قادرة على التعامل مع مهام متنوعة، مثل الإجابة على الأسئلة وإنشاء المحتوى، مما يُظهر قدراتها القوية. تُعدّ معايير التقييم أدوات مهمة لتقييم قدرات تطوير نماذج اللغات الكبيرة، كما أنها مرجعية مهمة لتحسينها وتعزيزها. مع ذلك، تفتقر معايير التقييم الشائعة حاليًا إلى تصميم الصعوبة، حيث حققت نماذج اللغات الكبيرة المتطورة درجات عالية ومماثلة في العديد من التقييمات الحالية، مما يحد من دقة قياس قدرات نماذج اللغات الكبيرة، ويحجب إمكانية تحسين قدرات النماذج الكبيرة.
وبناءً على ذلك، أصدر مركز سلامة الذكاء الاصطناعي وScimble AI بشكل مشترك مجموعة بيانات معيارية للمشاكل البشرية متعددة الوسائط تسمى Humanity's Last Exam (HLE).يهدف إلى بناء الختم النهائي الذي يغطي حدود المعرفة الإنسانيةمغلقيقيمنظام.تتكون مجموعة البيانات هذه من 2500 سؤال من عشرات المجالات الدراسية، وهي ملتزمة بتوفير معيار دقيق وفعال لقياس قدرة LLM، وتوضيح الفجوة بين قدرات LLM الحالية والأكاديميين المحترفين، وتحقيق التحسين السريع لقدرات LLM في مجالات المعرفة الرائدة.
في الوقت الحاضر، أطلق الموقع الرسمي لشبكة HyperAI Super Neural Network "مجموعة بيانات معيارية لحل المشكلات البشرية HLE"، تعال وجربها~
تنزيل مجموعة البيانات:
من 14 يوليو إلى 18 يوليو، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 5
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في يوليو: 4
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات الاستدلال الرياضي GSM8K
GSM8K هي مجموعة بيانات استدلال رياضي أصدرتها OpenAI عام ٢٠٢٢، وتهدف إلى تحسين أداء نماذج التعلم الآلي في فهم وحل المسائل الرياضية المعقدة. تحتوي مجموعة البيانات على ٨.٥ ألف مسألة رياضية لفظية عالية الجودة ومتنوعة اللغات، مخصصة للمرحلة الابتدائية، تغطي الجبر والحساب والهندسة ومجالات أخرى. تتراوح خطوات حل الأسئلة بين خطوتين وثماني خطوات. يتضمن الحل بشكل أساسي سلسلة من العمليات الحسابية البسيطة باستخدام العمليات الحسابية الأساسية (الجمع والطرح والضرب والقسمة) للحصول على الإجابة النهائية.
الاستخدام المباشر:https://go.hyper.ai/ZqNLt
2. مجموعة بيانات أمراض المحاصيل
أمراض المحاصيل هي مجموعة بيانات لصور أمراض المحاصيل الزراعية، مصممة للمساعدة في تطوير نماذج رؤية حاسوبية للكشف عن أمراض المحاصيل المختلفة وتصنيفها تلقائيًا. تحتوي مجموعة البيانات على حوالي 1300 صورة لأمراض المحاصيل، تغطي الأمراض الشائعة لمجموعة متنوعة من المحاصيل (مثل الذرة والطماطم والبطاطس، إلخ)، وكل صورة مُعلقة بفئة مرضية محددة.
الاستخدام المباشر:https://go.hyper.ai/GEDTA

3. مجموعات البيانات الاصطناعية متعددة المجالات من OpenScience
OpenScience هي مجموعة بيانات تركيبية متعددة المجالات، أصدرتها NVIDIA عام ٢٠٢٣، وتهدف إلى تحسين دقة معايير التقييم المتقدمة مثل GPQA-Diamond وMMLU-Pro من خلال الضبط الدقيق المُشرف أو التعلم التعزيزي. تحتوي مجموعة البيانات على ستة ملايين زوج من أسئلة الاختيار من متعدد مع تتبعات منطقية مفصلة، تغطي مجالات علمية متعددة مثل العلوم والتكنولوجيا والهندسة والرياضيات (STEM) والقانون والاقتصاد والعلوم الإنسانية.
الاستخدام المباشر:https://go.hyper.ai/YvAo7
4. مجموعة بيانات استدلال مسائل البرمجة الرياضية Skywork-OR1-RL
Skywork-OR1-RL هي مجموعة بيانات لحل مسائل البرمجة الرياضية، مصممة لتدريب نموذج Skywork-OR1 (Open Reasoner 1). تحتوي مجموعة البيانات على 105 آلاف مسألة رياضية و14 ألف مسألة برمجة، وهي قابلة للتحقق، وصعبة، ومتنوعة.
الاستخدام المباشر:https://go.hyper.ai/mxoAv
5. مجموعة بيانات صور تصنيف أنواع الطيور
أنواع الطيور هي مجموعة بيانات لتصنيف صور الطيور، مناسبة لتدريب نماذج الرؤية الحاسوبية على تحديد أنواع الطيور وتصنيفها. تحتوي مجموعة البيانات على 7 أنواع مختلفة، لكل منها 1200 صورة. تحتوي صور كل نوع على نمط ريشه ولونه وتركيب جسمه. بعض الصور مشوشة أو مائلة عمدًا، أو تحتوي على طائرين من نوعين مختلفين، مما يزيد من تعقيد العالم الواقعي ويعزز قدرة النموذج على التصنيف الدقيق في البيئات الطبيعية.
الاستخدام المباشر:https://go.hyper.ai/X2X2M

6. مجموعة بيانات تحرير الكود NextCoder
NextCoder هي مجموعة بيانات لتحرير ترميز الحوار الاصطناعي، أصدرتها مايكروسوفت عام ٢٠٢٥. تُستخدم هذه المجموعة لضبط نماذج اللغات الكبيرة بدقة، مما يُحسّن أداء النموذج في إصلاح الأكواد البرمجية وإعادة هيكلتها وتحسينها. وهي مناسبة جدًا لتدريب مساعدي برمجة الذكاء الاصطناعي، وتحسين قراءة الأكواد البرمجية وقدرات التفاعل متعدد الجولات. تحتوي مجموعة البيانات على حوالي ٣٨١ ألف عينة تعليمات أحادية الجولة (NextCoderDataset) و٥٧٠٠٠ عينة حوار متعددة الجولات (Conversational version)، وتغطي ٨ لغات مثل بايثون وجافا.
الاستخدام المباشر:https://go.hyper.ai/e4MIs
7. مجموعة بيانات أسئلة المعرفة في علم النفس Psych-101 للإجابة عليها
Psych-101 هي مجموعة بيانات للإجابة على أسئلة المعرفة النفسية، مصممة للمساعدة في تطوير نماذج معالجة اللغة الطبيعية لمهام الإجابة على أسئلة المعرفة النفسية، وتعزيز أبحاث الذكاء الاصطناعي المتعلقة بعلم النفس، وخاصةً في مجالات تعليم علم النفس، وتحليل المشاعر، وتطبيقات الصحة النفسية. تحتوي مجموعة البيانات على بيانات مُفصلة من 160 تجربة نفسية شارك فيها 60,092 مشاركًا، بإجمالي 10,681,650 خيارًا.
الاستخدام المباشر:https://go.hyper.ai/NUshw
8. مجموعة بيانات صور سرطان الدم
اللوكيميا (اللوكيميا) هي مجموعة بيانات لصور خلايا اللوكيميا، مصممة لتدريب نماذج الرؤية الحاسوبية على اكتشاف خلايا اللوكيميا وتصنيفها تلقائيًا. تحتوي مجموعة البيانات على 6778 صورة خلوية، بما في ذلك خلايا طبيعية (3389) وخلايا اللوكيميا (3389).
الاستخدام المباشر:https://go.hyper.ai/Lwxwj
9. مجموعة بيانات صور الأشعة السينية للالتهاب الرئوي الصدري
صور الأشعة السينية للصدر للالتهاب الرئوي هي مجموعة بيانات لصور الأشعة السينية للصدر، مصممة لتدريب وتقييم نماذج الرؤية الحاسوبية لمساعدة أنظمة التشخيص الآلية على اكتشاف أمراض الجهاز التنفسي، مثل الالتهاب الرئوي. تحتوي مجموعة البيانات على ما يقارب 5800 صورة أشعة سينية للصدر، مقسمة إلى فئتين: طبيعية وأخرى للالتهاب الرئوي (بكتيري وفيروسي).
الاستخدام المباشر:https://go.hyper.ai/Pgra4
10. رطوبة التربة مجموعة بيانات صور رطوبة التربة
رطوبة التربة هي مجموعة بيانات قياسية لرطوبة التربة، تهدف إلى دراسة تأثير رطوبة التربة على نمو المحاصيل، وتحسين أنظمة الري، ورفع كفاءة الإنتاج الزراعي. كما أن لها تطبيقات مهمة في مجالات مثل تغير المناخ وإدارة موارد المياه. تحتوي مجموعة البيانات على 200 صورة لسطح التربة من منطقة بوندووسو الزراعية البعلية في إندونيسيا.
الاستخدام المباشر:https://go.hyper.ai/TtpgP

دروس تعليمية عامة مختارة
هذا الأسبوع، قمنا بتلخيص 4 فئات من الدروس التعليمية العامة عالية الجودة:
*دروس الذكاء الاصطناعي للعلوم: 2
*دورة التعرف على النص: 1
*دورة تعليمية متعددة الوسائط: 1
*نموذج تعليمي كبير: 1
دروس الذكاء الاصطناعي للعلوم
1. انتشار الترددات الراديوية: نموذج تصميم بروتين الانتشار
انتشار الترددات الراديوية (RFdiffusion) هو إطار عمل لتوليد هياكل البروتين: يستخدم شبكة RoseTTAFold كشبكة أساسية، ويُقدم نموذج احتمالية الانتشار الخالي من الضوضاء (DDPM) لتصميم هياكل بروتينية جديدة من الصفر. يتميز هذا الإطار بقدرته على تصميم بروتينات ذات أشكال معقدة (مثل حلزونات ألفا وطيات بيتا)، والتنبؤ بدقة بهيكل الموقع التحفيزي للإنزيمات.
تشغيل عبر الإنترنت:https://go.hyper.ai/q7Ajs
2. بيومني: أول عامل طبي حيوي عام
Biomni هو وكيل الذكاء الاصطناعي الطبي متعدد الأغراض الذي يمكنه إكمال مهام البحث المعقدة بشكل مستقل عبر فروع طبية حيوية متعددة مثل علم الوراثة وعلم الجينوم وعلم الأحياء الدقيقة وعلم الأدوية والطب السريري، مما يمثل مرحلة جديدة في تطوير الاكتشاف العلمي القائم على الذكاء الاصطناعي.
تشغيل عبر الإنترنت:https://go.hyper.ai/aameS
برنامج تعليمي للتعرف على النص
1. OCRFlux-3B: مجموعة أدوات التعرف على النصوص الذكية
OCRFlux-3B هي مجموعة أدوات تعتمد على نموذج متعدد الوسائط لغوي كبير لتحويل ملفات PDF والصور إلى نصوص Markdown واضحة وسهلة القراءة. لا توفر الأداة إمكانيات تحويل النصوص على مستوى الصفحة فحسب، بل تدعم أيضًا دمج الجداول والفقرات عبر الصفحات، مما يوفر دعمًا قويًا لمعالجة هياكل المستندات المعقدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/BGqmR
برنامج تعليمي متعدد الوسائط
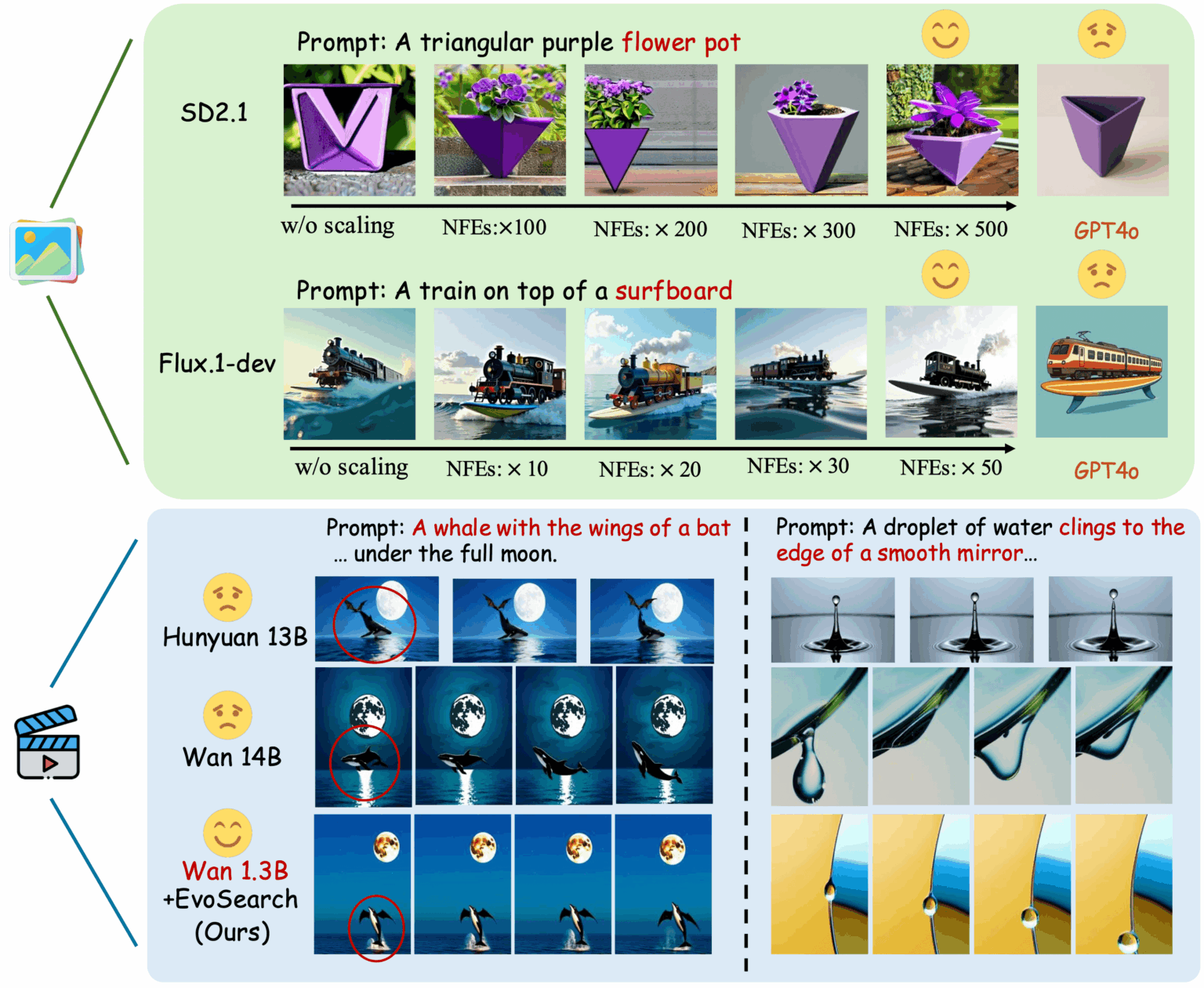
1. EvoSearch-codes: إطار عمل الخوارزمية التطورية
EvoSearch-codes هي طريقة بحث تطورية أطلقتها جامعة هونغ كونغ للعلوم والتكنولوجيا وفريق كوايشو كيلينغ. تُحسّن هذه الطريقة جودة توليد النموذج بشكل ملحوظ من خلال زيادة حجم العمليات الحسابية أثناء الاستدلال، وتدعم توليد الصور والفيديو، وتدعم أحدث النماذج القائمة على الانتشار والتدفق. يمكن للنموذج تحقيق نتائج مثالية ملحوظة في سلسلة من المهام دون الحاجة إلى تدريب أو تحديثات التدرج، كما يتميز بقدرات ممتازة على التوسع، ومتانة، وتعميم.
تشغيل عبر الإنترنت:https://go.hyper.ai/zjzrE
برنامج تعليمي للنماذج الكبيرة
1. جان نانو: نموذج لغوي مُدمج مُخصص للبحث
Jan-Nano هو نموذج لغوي كبير وخفيف الوزن يحتوي على 4 مليارات معلمة أصدره فريق Menlo Research في 1 يوليو 2025. وهو مصمم لمهام البحث العميقة ومُحسَّن لخادم بروتوكول سياق النموذج (MCP) لتسهيل التكامل الفعال مع مجموعة متنوعة من أدوات البحث ومصادر البيانات.
تشغيل عبر الإنترنت:https://go.hyper.ai/mC8gx
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

توصيات الورقة البحثية لهذا الأسبوع
1. قياس وقت الاختبار باستخدام النموذج التوليدي الانعكاسي
تُقدّم هذه الورقة البحثية نموذج MetaStone-S1، وهو أول نموذج توليدي عاكس، يُحقق مستوى أداء OpenAI o3 من خلال نموذج مكافأة العملية ذاتية الإشراف (SPRM). من خلال مشاركة الشبكة الأساسية واستخدام رؤوس خاصة بالمهام للتنبؤ بالرمز التالي وتسجيل نقاط العملية، يُدمج SPRM بنجاح نموذج السياسة ونموذج مكافأة العملية (PRM) في واجهة موحدة دون الحاجة إلى تعليقات توضيحية إضافية للعملية، مما يُقلل من معلمات PRM بأكثر من 99%، وبالتالي يُحقق استدلالًا فعالًا.
رابط الورقة:https://go.hyper.ai/zFLhf
2. Open Vision Reasoner: نقل السلوك المعرفي اللغوي إلى التفكير البصري
تقترح هذه الورقة نموذجًا من مرحلتين يعتمد على Qwen2.5-VL-7B: أولًا، ضبط دقيق للغة على نطاق واسع، يتبعه ما يقرب من 1000 خطوة من التعلم التعزيزي متعدد الوسائط (RL)، وهو ما يفوق جميع محاولات التعلم مفتوحة المصدر السابقة. يحقق النموذج النهائي، Open-Vision-Reasoner (OVR)، أداءً متطورًا على مجموعة من معايير الاستدلال، بما في ذلك 95.3% على MATH500، و51.8% على MathVision، و54.6% على MathVerse.
رابط الورقة:https://go.hyper.ai/WucU8
٣. الاستدلال أم الحفظ؟ نتائج غير موثوقة للتعلم التعزيزي بسبب تلوث البيانات
وجد الباحثون أنه على الرغم من أداء Qwen2.5 الجيد في التفكير الرياضي، إلا أن تدريبه المسبق على مجموعة بيانات ويب واسعة النطاق يجعله عرضة لتلوث البيانات في معايير الأداء الشائعة، مما يؤثر بدوره على موثوقية النتائج المُحصل عليها من هذه المعايير. لمعالجة هذه المشكلة، قدّم الباحثون مُولّدًا قادرًا على توليد مسائل حسابية تركيبية بالكامل ذات طول ودرجة صعوبة عشوائية، مما ينتج عنه مجموعة بيانات نظيفة تُسمى "الحساب العشوائي". باستخدام هذه المجموعات الخالية من التسريبات، ثَبُتَ أن إشارات المكافأة الدقيقة فقط هي القادرة على تحسين الأداء باستمرار، بينما لا تستطيع الإشارات المشوشة أو الخاطئة ذلك.
رابط الورقة:https://go.hyper.ai/WZp4V
4. NeuralOS: نحو محاكاة أنظمة التشغيل عبر النماذج التوليدية العصبية
تُقدّم هذه الورقة البحثية نظام NeuralOS، وهو إطار عمل عصبي يُحاكي واجهة المستخدم الرسومية (GUI) لنظام التشغيل من خلال التنبؤ المباشر بإطارات الشاشة استجابةً لمدخلات المستخدم، مثل حركات الماوس والنقرات وأحداث لوحة المفاتيح. يجمع NeuralOS بين شبكة عصبية متكررة (RNN) لتتبع حالة الحاسوب، وعارض عصبي قائم على الانتشار لتوليد صور الشاشة. يُتيح هذا النظام مسارًا لإنشاء واجهات عصبية توليدية ومتكيّفة بالكامل لأنظمة التفاعل بين الإنسان والحاسوب المستقبلية.
رابط الورقة:https://go.hyper.ai/hceCb
5. CLiFT: رموز حقل الضوء المضغوطة للعرض العصبي التكيفي والفعال للحوسبة
في هذه الورقة، نقترح طريقة عرض عصبية تُمثِّل المشاهد كـ "رموز حقل الضوء المضغوط (CLiFTs)"، مما يحافظ على المظهر الغني للمشهد وهندسته. تُحقق CLiFT عرضًا حاسوبيًا فعالًا باستخدام الرموز المضغوطة، مع إمكانية تغيير عدد الرموز في شبكة مُدرَّبة واحدة لتمثيل المشهد أو عرض منظورات جديدة.
رابط الورقة:https://go.hyper.ai/aqzHX
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
اقترح فريق بحثي مشترك من ميتا فير وجامعة كامبريدج ومعهد ماساتشوستس للتكنولوجيا (MIT) محول الانتشار الذري الكامل (ADiT)، الذي كسر حواجز النمذجة بين الأنظمة الدورية وغير الدورية. ومن خلال ابتكارين رئيسيين، هما التمثيل الكامن الموحد للذرات بالكامل ومحول الانتشار الكامن، حقق الفريق تقدمًا كبيرًا في توليد الجزيئات والبلورات باستخدام نموذج واحد.
شاهد التقرير الكامل:https://go.hyper.ai/Dnw5r
اقترح فريق جامعة ستانفورد ومعهد آرك في بالو ألتو، كاليفورنيا، بشكل مشترك طريقة جديدة لتصميم تسلسلات البروتين تُسمى FAMPNN (Full-Atom MPNN)، والتي تُمكّن من نمذجة هوية التسلسل وبنية السلسلة الجانبية لكل بقايا حمض أميني بشكل واضح. يستخدم النموذج بنية تمرير رسائل تعتمد على الشبكات العصبية البيانية، بالإضافة إلى وحدات MPNN وGVP مُحسّنة للترميز الذري الكامل، والتي تُعالج معلومات السلسلة الرئيسية والسلسلة الجانبية للبروتينات في آنٍ واحد.
شاهد التقرير الكامل:https://go.hyper.ai/x04Am
طورت جامعة ستانفورد، بالتعاون مع جينينتك ومعهد آرك وجامعة كاليفورنيا في سان فرانسيسكو ومؤسسات أخرى، أول برنامج ذكاء اصطناعي عام في مجال الطب الحيوي، وهو Biomni. هذا البرنامج قادر على إجراء مجموعة واسعة من المهام البحثية بشكل مستقل في مختلف التخصصات الطبية الحيوية، وإنشاء أول برنامج بيئي موحد، مستخرجًا الأدوات وقواعد البيانات والحلول اللازمة من عشرات الآلاف من المنشورات في 25 مجالًا طبيًا حيويًا. تُظهر معايير النظام أن Biomni يحقق تعميمًا قويًا في المهام الطبية الحيوية غير المتجانسة دون أي ضبط فوري خاص بكل مهمة.
شاهد التقرير الكامل:https://go.hyper.ai/VHpMD
في الخامس من يوليو، اختُتم بنجاح مؤتمر "لقاء تكنولوجيا مُجمِّعات الذكاء الاصطناعي" السابع الذي استضافته شركة HyperAI. وقد قدّم دونغ تشاو هوا، المدير الأول لشركة Muxi Integrated Circuit، شرحًا مُفصّلًا لكيفية تطبيق TVM على وحدات معالجة الرسومات من Muxi، وعرض الخصائص التقنية لمنتجاتها من وحدات معالجة الرسومات، وحلول تكييف مُجمِّعات TVM، وحالات تطبيقية عملية، ورؤية بناء بيئية، كما بيّن الإنجازات التكنولوجية وإمكانات تطبيق وحدات معالجة الرسومات المحلية في مجالات الحوسبة عالية الأداء والذكاء الاصطناعي.
شاهد التقرير الكامل:https://go.hyper.ai/rxxX3
اقترح فريق بحث NVIDIA، بالتعاون مع ميلا من معهد كيبيك للذكاء الاصطناعي في كندا، طريقة La-Proteina، وهي طريقة لتصميم البروتينات على المستوى الذري تعتمد على مطابقة التدفق الكامن الجزئي. وتعالج هذه الطريقة التحدي الرئيسي المتمثل في التباين البعدي لتمثيلات السلسلة الجانبية الصريحة أثناء توليد البروتينات، مما يُحدث نقلة نوعية في مجال تصميم البروتينات.
شاهد التقرير الكامل:https://go.hyper.ai/0Sw8R
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
الموعد النهائي للقمة في يوليو
11 يوليو 7:59:59 بوبل 2026
15 يوليو 7:59:59 صودا 2026
18 يوليو 7:59:59 سيجمود 2026
19 يوليو 7:59:59 اي سي اس اي 2026
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








