Command Palette
Search for a command to run...
OmniGen2، استدلال متعدد الوسائط × محرك تصحيح ذاتي مزدوج، يُرسي نموذجًا جديدًا لتوليد الصور؛ 950,000 تصنيف! TreeOfLife-200M يفتح آفاقًا جديدة في إدراك الأنواع.

في السنوات الأخيرة، حققت تقنية الذكاء الاصطناعي التوليدي تقدمًا ملحوظًا في مجال الصور. وقد حققت نماذج مثل سلسلة الانتشار المستقر وDALL-E3 توليدًا عالي الجودة للنصوص إلى الصور من خلال نماذج الانتشار. ومع ذلك، تفتقر هذه النماذج إلى الفهم الإدراكي الشامل وقدرات التوليد اللازمة للنماذج العامة لتوليد الصور. وُلد OmniGen لتوفير حل موحد لمهام التوليد المختلفة استنادًا إلى بنية نموذج الانتشار. يتميز بقدرات معالجة متعددة المهام، ويمكنه توليد صور عالية الجودة دون الحاجة إلى مكونات إضافية. ولا شك أن هذا النموذج لا يزال يعاني من قيود في الفصل متعدد الوسائط وتنوع البيانات.
وللتغلب على هذه الصعوبات وتحسين مرونة النظام وقدرته على التعبير بشكل أكبر، حقق OmniGen2 تقدمًا كبيرًا.يحتوي على مسارين مستقلين لفك التشفير للنصوص والصور.يستخدم معلمات غير مشتركة ووسم صور منفصل. يُمكّن هذا التصميم OmniGen2 من البناء على نماذج الفهم متعدد الوسائط الحالية دون الحاجة إلى تعديل مدخلات مُرمِّز التباين التلقائي، مما يُحافظ على إمكانيات توليد النص الأصلية.
في الوقت الحاضر، أطلق الموقع الرسمي لشركة HyperAI البرنامج التعليمي "OmniGen2: استكشاف الجيل المتعدد الوسائط المتقدم"، تعال وجربه~
OmniGen2: استكشاف الجيل المتعدد الوسائط المتقدم
الاستخدام عبر الإنترنت:https://go.hyper.ai/fKbUP
من 30 يونيو إلى 4 يوليو، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 7
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في يوليو: 4
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات إنشاء الصور ShareGPT-4o-Image
ShareGPT-4o-Image هي مجموعة بيانات واسعة النطاق وعالية الجودة لتوليد الصور، تهدف إلى نقل قدرات توليد الصور بمستوى GPT-4o إلى نماذج متعددة الوسائط مفتوحة المصدر. جميع الصور في هذه المجموعة مُولّدة بواسطة دالة توليد الصور في GPT-4o، وتحتوي البيانات على ما مجموعه 92,256 عينة توليد صور من GPT-4o.
الاستخدام المباشر:https://go.hyper.ai/5G48Y

2. مجموعة بيانات فيديو السيارات متعددة المشاهد من MAD-Cars
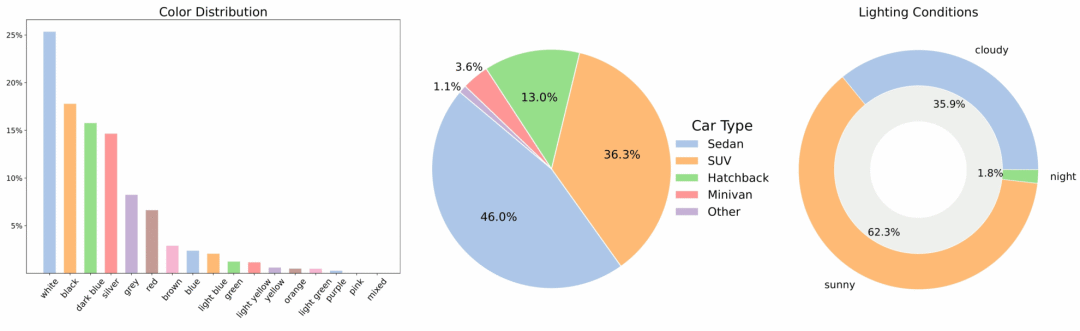
MAD-Cars هي مجموعة بيانات واسعة النطاق لفيديوهات السيارات متعددة المشاهد، تُوسّع نطاق مجموعات بيانات السيارات العامة متعددة المشاهد الحالية بشكل كبير. تحتوي مجموعة البيانات على حوالي 70,000 مقطع فيديو لسيارات، بمتوسط 85 إطارًا لكل مقطع. تتميز معظم مقاطع الفيديو بدقة 1920×1080، وتغطي حوالي 150 علامة تجارية للسيارات، بما في ذلك طُرز وألوان متعددة وثلاثة أوضاع إضاءة.
الاستخدام المباشر:https://go.hyper.ai/xuB9I
3. مجموعة بيانات صور المحاصيل والنباتات
مجموعة بيانات النباتات والمحاصيل هي مجموعة بيانات شاملة لصور المحاصيل في مجال الذكاء الاصطناعي الزراعي، تحتوي على 100,000 صورة موحدة، تغطي 139 محصولًا مزروعًا على نطاق واسع حول العالم. تغطي مجموعة البيانات مراحل نمو متعددة للمحاصيل، من الشتلات إلى الإزهار والإثمار، ويغطي محتوى الصور أجزاءً هيكلية متعددة، مثل الأوراق والسيقان والثمار، مع معلومات تمثيلية غنية. جميع الصور موحدة بدقة 224×224 بكسل لتقليل تأثير اختلافات الحجم على تدريب النموذج.
الاستخدام المباشر:https://go.hyper.ai/PLVJp

4. مجموعة بيانات الكتب المدرسية متعددة الوسائط - 6.5 مليون
يهدف كتاب Multimodal-Textbook-6.5M إلى تحسين التدريب المسبق متعدد الوسائط، وزيادة قدرة النموذج على التعامل مع المدخلات البصرية والنصية المتداخلة. تحتوي مجموعة البيانات على 6.5 مليون صورة و800 مليون بيانات نصية من فيديوهات تعليمية. جميع الصور والنصوص مُستخرجة من فيديوهات تعليمية عبر الإنترنت، تغطي ستة مواد أساسية، مثل الرياضيات والفيزياء والكيمياء.
الاستخدام المباشر:https://go.hyper.ai/q8Iin
5. مجموعة بيانات أزواج الأسئلة والأجوبة الهندية من IndicVault
Indic Vault هي مجموعة بيانات أسئلة وأجوبة باللغة الهندية اليومية، مناسبة لضبط روبوتات الدردشة والمساعدين الصوتيين. تحتوي مجموعة البيانات على أزواج أسئلة وأجوبة مكتوبة باللغة الهندية اليومية المعاصرة المستخدمة في جميع أنحاء الهند بحلول عام ٢٠٢٥، ملتقطةً التعبيرات العامية الحقيقية المستخدمة في المحادثات اليومية، وتغطي ٢٠ فئة أساسية.
الاستخدام المباشر:https://go.hyper.ai/JhEUR
6. مجموعة بيانات معيارية لوصف الفيديو DREAM-1K
تحتوي مجموعة البيانات على 1000 مقطع فيديو مُعلّق بدرجات متفاوتة من التعقيد، من خمس فئات مختلفة، يحتوي كل منها على حدث ديناميكي واحد على الأقل، لا يمكن تحديده بدقة من إطار واحد. يُزوَّد كل مقطع فيديو بتعليقات يدوية دقيقة تُغطي جميع الأحداث والحركات.
الاستخدام المباشر:https://go.hyper.ai/AgOm0
7. مجموعة بيانات تحليل الكشف عن أورام الدماغ باستخدام التصوير بالرنين المغناطيسي للدماغ
يحتوي تصوير الدماغ بالرنين المغناطيسي على فحوصات رنين مغناطيسي عالية الجودة ومتعددة التسلسلات من مرضى مختلفين. تتضمن هذه المسوحات تسلسلات تصوير مرجحة بـ T1، وT2، وFLAIR، ومرجحة بالانتشار. تغطي هذه المجموعة أنواعًا متعددة من أورام الدماغ، وتُقارن مع ضوابط سليمة، مما يجعلها مناسبة لتطوير واعتماد أي نماذج متقدمة للتعلم الآلي وتطبيقات الأبحاث السريرية.
الاستخدام المباشر:https://go.hyper.ai/oZWNu
8. مجموعة بيانات الاستدلال الرياضي AceReason-1.1-SFT
تُستخدم مجموعة البيانات هذه كبيانات تدريب SFT لنموذج الرياضيات والاستدلال البرمجي AceReason-Nemotron-1.1-7B. جميع الإجابات في مجموعة البيانات مُولّدة بواسطة DeepSeek-R1. تحتوي مجموعة بيانات AceReason-1.1-SFT على 2,668,741 عينة رياضية و1,301,591 عينة برمجية، تغطي بيانات من مصادر بيانات متعددة. تم تنظيف مجموعة البيانات وتصفية العينات التي تتداخل مع أي عينات اختبار في معايير الرياضيات والترميز.
الاستخدام المباشر:https://go.hyper.ai/WGl1k
9. مجموعة بيانات الرؤية البيولوجية TreeOfLife-200M
TreeOfLife-200M هي أكبر وأكثر مجموعات البيانات العامة تنوعًا، جاهزة للتعلم الآلي، لنماذج الرؤية الحاسوبية البيولوجية. تحتوي مجموعة البيانات على ما يقرب من 214 مليون صورة، تغطي 952,000 فئة من الأنواع، وتدمج الصور والبيانات الوصفية من أربعة مزودي بيانات رئيسيين للتنوع البيولوجي.
الاستخدام المباشر:https://go.hyper.ai/UKC0H
10. مجموعة بيانات توليد التفكير الطبي من VL-Health
VL-Health هي أول مجموعة بيانات شاملة لفهم وتوليد البيانات الطبية متعددة الوسائط. تدمج مجموعة البيانات 765,000 عينة مهام فهم و783,000 عينة مهام توليد، تغطي 11 نموذجًا طبيًا وسيناريوهات أمراض متعددة.
الاستخدام المباشر:https://go.hyper.ai/GvKlu
دروس تعليمية عامة مختارة
هذا الأسبوع، قمنا بتجميع 3 أنواع من الدروس التعليمية العامة عالية الجودة:
*دروس إنشاء الصور وتحريرها: 3
*دروس تعليمية حول إنشاء ثلاثي الأبعاد: 2
* دروس توليد الصوت: 2
برنامج تعليمي لإنشاء الصور وتحريرها
1. OmniGen2: استكشاف الجيل المتعدد الوسائط المتقدم
يهدف OmniGen2 إلى توفير حل موحد لمهام توليد متعددة، بما في ذلك توليد النصوص إلى صور، وتحرير الصور، وتوليد السياقات. يُمكّن تصميم المعلمات غير المشتركة ومُجزّئات الصور المنفصلة OmniGen2 من البناء على نماذج الفهم متعددة الوسائط الحالية دون الحاجة إلى إعادة تكييف مُدخلات VAE، مع الحفاظ على إمكانيات توليد النصوص الأصلية.
تشغيل عبر الإنترنت:https://go.hyper.ai/fKbUP

2. FLUX.1-Kontext-dev: تحرير الصور بنقرة واحدة باستخدام النصوص
تحرير الصور في FLUX.1 Kontext هو تحرير الصور بالمعنى الواسع، والذي لا يدعم تحرير الصور المحلي فقط (التعديل المستهدف لعناصر محددة في الصورة دون التأثير على الباقي)، ولكنه يحقق أيضًا اتساق الأحرف (الاحتفاظ بالعناصر الفريدة في الصورة مثل الأحرف المرجعية أو الكائنات للحفاظ عليها متسقة في مشاهد وبيئات متعددة).
تشغيل عبر الإنترنت:https://go.hyper.ai/PqRGn

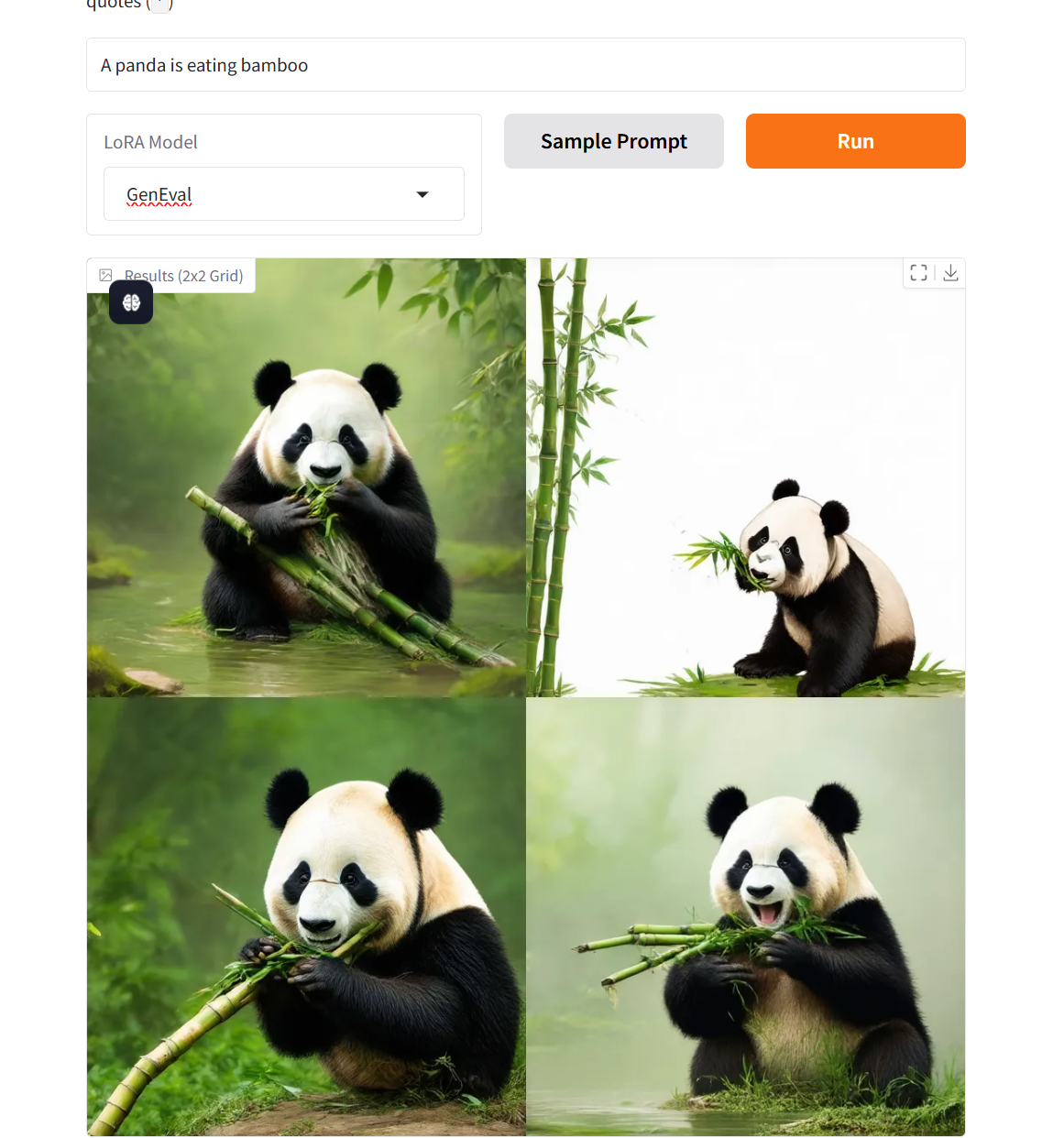
3. عرض توضيحي لنموذج الرسم البياني لمطابقة تدفق Flow-GRPO
كان هذا النموذج رائداً في دمج إطار التعلم التعزيزي عبر الإنترنت ونظرية مطابقة التدفق، وحقق تقدماً هائلاً في اختبار معيار GenEval 2025: حيث ارتفعت دقة التوليد المجمعة لنموذج SD 3.5 Medium من القيمة المعيارية 63% إلى 95%، وتجاوز مؤشر تقييم جودة التوليد GPT-4o لأول مرة.
تشغيل عبر الإنترنت:https://go.hyper.ai/v7xkq
برنامج تعليمي لإنشاء ثلاثي الأبعاد
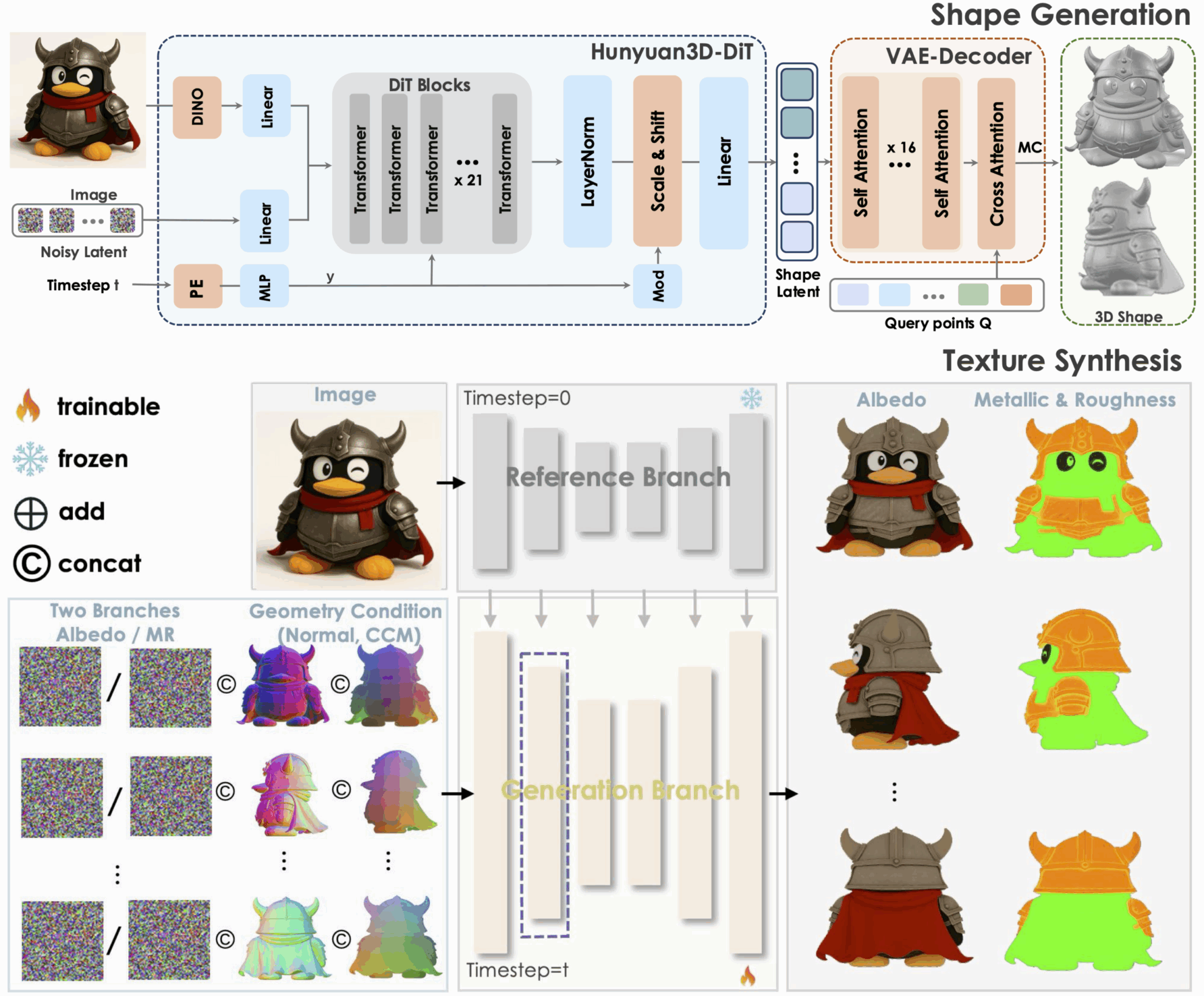
1. Hunyuan3D-2.1: نموذج توليدي ثلاثي الأبعاد يدعم القوام المادية
Tencent Hunyuan3D-2.1 هو نموذج توليد ثلاثي الأبعاد مفتوح المصدر، مُصمم للاستخدام الصناعي، ونظام إنشاء أصول ثلاثية الأبعاد قابل للتطوير. يُعزز هذا النموذج تطوير أحدث تقنيات توليد ثلاثي الأبعاد من خلال ابتكارين رئيسيين: إطار عمل مفتوح المصدر بالكامل، وتوليف نسيجي قائم على العرض المادي. وفي الوقت نفسه، يُتيح هذا النموذج إمكانية الوصول الكامل إلى معالجة البيانات، والتدريب، ورموز الاستدلال، وغيرها، مما يوفر قاعدة أساسية قابلة للتكرار للبحث الأكاديمي، ويُقلل من تكاليف التطوير المتكررة للتطبيق الصناعي.
تشغيل عبر الإنترنت:https://go.hyper.ai/0H91Z
2. Direct3D‑S2: إطار عمل للعرض ثلاثي الأبعاد عالي الدقة
Direct3D‑S2 هو إطار عمل لتوليد الصور ثلاثية الأبعاد عالي الدقة، يُحسّن بشكل كبير الكفاءة الحسابية لمحوّل الانتشار، ويُخفّض تكلفة التدريب بشكل ملحوظ، استنادًا إلى تمثيل الحجم المتناثر وآلية الانتباه المكاني المتناثر المبتكرة. يتفوق هذا الإطار على الطرق الحالية من حيث جودة وكفاءة توليد الصور، مُوفّرًا دعمًا فنيًا قويًا لإنشاء محتوى ثلاثي الأبعاد عالي الدقة.
تشغيل عبر الإنترنت:https://go.hyper.ai/67LQM

برنامج تعليمي لإنشاء الصوت
1. PlayDiffusion: نموذج تحرير الصوت المحلي مفتوح المصدر
يُشفِّر PlayDiffusion الصوت إلى تسلسلات رمزية منفصلة، ويُخفي الأجزاء التي تحتاج إلى تعديل، ويستخدم نموذج انتشار لإزالة الضوضاء من المناطق المُخفَّفة بناءً على النص المُحدَّث، لتحقيق تحرير صوتي عالي الجودة. يُحافظ هذا النظام على السياق بسلاسة، ويضمن تماسك الكلام وطبيعيته، ويدعم توليفًا فعالًا للنص إلى كلام، مما يوفر اتساقًا زمنيًا عاليًا وقابلية للتوسع.
تشغيل عبر الإنترنت:https://go.hyper.ai/WTlI4
2. OuteTTS: محرك توليد الكلام
OuteTTS هو مشروع مفتوح المصدر لتحويل النص إلى كلام. يكمن ابتكاره الأساسي في استخدام أساليب نمذجة اللغة البحتة لتوليد كلام عالي الجودة دون الاعتماد على محولات معقدة أو وحدات خارجية في أنظمة تحويل النص إلى كلام التقليدية. تشمل وظائفه الرئيسية تحويل النص إلى كلام واستنساخ الصوت.
تشغيل عبر الإنترنت:https://go.hyper.ai/eQVHL
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

توصيات الورقة البحثية لهذا الأسبوع
1. GLM-4.1V-التفكير: نحو تفكير متعدد الوسائط متعدد الاستخدامات مع التعلم التعزيزي القابل للتطوير
تقدم هذه الورقة البحثية نموذج التفكير البصري GLM-4.1V-Thinking، وهو نموذج لغوي بصري (VLM) مُصمم لتعزيز الفهم والاستدلال متعدد الوسائط. نقترح طريقة تجمع بين التعلم المعزز وأخذ العينات من المناهج الدراسية للاستفادة الكاملة من إمكانات النموذج، وبالتالي تحقيق قدرات شاملة في مهام متنوعة مثل حل مشكلات العلوم والتكنولوجيا والهندسة والرياضيات (STEM)، وفهم الفيديو، والتعرف على المحتوى، والبرمجة، وحل الإحالة المرجعية، والوكلاء المعتمدين على واجهة المستخدم الرسومية (GUI)، وفهم المستندات الطويلة. يحقق نموذج التفكير البصري GLM-4.1V-9B-Thinking أداءً متطورًا مقارنةً بنماذج مفتوحة المصدر من نفس الحجم، كما يُظهر أداءً مماثلاً أو أفضل من نماذج مغلقة المصدر مثل GPT-4o في المهام الصعبة مثل فهم المستندات الطويلة والاستدلال في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM).
رابط الورقة:https://go.hyper.ai/5UuYG
2. التقرير الفني لـ Ovis-U1
تُقدّم هذه الورقة البحثية نموذج Ovis-U1، وهو نموذج موحّد يضم 3 مليارات مُعامل، ويدمج الفهم متعدد الوسائط، وتوليد النص إلى صورة، وتحرير الصور. بناءً على أسس عائلة Ovis، يجمع Ovis-U1 بين مُفكّك تشفير بصري مُنتشر ومُحسّن وسم ثنائي الاتجاه، مما يجعله مُنافسًا للنماذج الرائدة مثل GPT-4o في مهام توليد الصور. حصل Ovis-U1 على 69.6 نقطة في معيار OpenCompass الأكاديمي متعدد الوسائط، مُتجاوزًا بذلك النماذج الحديثة المُتطورة مثل Ristretto-3B وSAIL-VL-1.5-2B.
رابط الورقة:https://go.hyper.ai/7Q8JV
3. BlenderFusion: تحرير مرئي ثلاثي الأبعاد وتركيب توليدي
تقترح هذه الورقة البحثية BlenderFusion، وهو إطار عمل لتوليف الصور المرئية التوليدية، يُولّد مشاهد جديدة عن طريق إعادة دمج الكائنات والكاميرات والخلفيات. يتبع الإطار عملية تحرير الطبقات وتوليفها: تُجزّأ المُدخلات المرئية وتُحوّل إلى كيانات ثلاثية الأبعاد قابلة للتحرير؛ وتُحرّر باستخدام عناصر تحكم ثلاثية الأبعاد في Blender؛ وتُدمج في مشهد متماسك باستخدام مُركّب توليدي. تُظهر النتائج التجريبية أن BlenderFusion يتفوق بشكل ملحوظ على الطرق السابقة في مهام تحرير المشاهد المركبة المعقدة.
رابط الورقة:https://go.hyper.ai/YoirX
4. SciArena: منصة تقييم مفتوحة لنماذج الأساس في مهام الأدبيات العلمية
تُقدّم هذه الورقة البحثية منصة SciArena، وهي منصة مفتوحة وتعاونية لتقييم النماذج الأساسية في مهام الأدبيات العلمية. بخلاف معايير فهم الأدبيات العلمية التقليدية وتوليفها، تُشرك SciArena مجتمع البحث مباشرةً، وتعتمد أسلوب تقييم مُشابهًا لمنصة Chatbot Arena، حيث تُقارن النماذج من خلال تصويت المجتمع. تدعم المنصة حاليًا 23 نموذجًا أساسيًا مفتوح المصدر ومُسجّل الملكية، وقد جمعت أكثر من 13,000 صوت من باحثين موثوقين في مجالات علمية مُتعددة.
رابط الورقة:https://go.hyper.ai/oPbpP
5. SPIRAL: اللعب الذاتي في ألعاب المجموع الصفري يحفز التفكير من خلال التعلم التعزيزي متعدد الأدوار متعدد العوامل
تُقدّم هذه الورقة البحثية إطار عمل SPIRAL، وهو إطار عمل قائم على اللعب الذاتي، حيث تتعلم النماذج من خلال لعب ألعاب متعددة الجولات، محصلتها صفر، ضد نسخ مُحسّنة باستمرار من نفسها، مما يُلغي الحاجة إلى الإشراف البشري. ولتمكين تدريب اللعب الذاتي على نطاق واسع، طبّق الباحثون نظامًا كاملًا عبر الإنترنت، متعدد الجولات، ومتعدد الوكلاء، واقترحوا تقديرًا للمزايا مُشروطًا بالأدوار لتحقيق الاستقرار في تدريب الوكلاء المتعددين. يُمكن للتدريب الذاتي على الألعاب ذات المحصلة الصفرية باستخدام SPIRAL أن يُنتج قدرات استدلال قابلة للنقل على نطاق واسع.
رابط الورقة:https://go.hyper.ai/n7J4m
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
اقترح فريق بحثي من جامعة فرجينيا للتكنولوجيا وشركة ميتا للذكاء الاصطناعي نموذجًا موحدًا يُسمى UNIMATE، والذي يُعالج أهم العوائق في تصميم الذكاء الاصطناعي الحالي للمواد الخارقة من خلال بنية نموذجية مبتكرة. كما يُحقق هذا النموذج، ولأول مرة، النمذجة الموحدة والمعالجة التعاونية للعناصر الأساسية الثلاثة لتصميم المواد الخارقة، وهي البنية الطوبولوجية ثلاثية الأبعاد، وظروف الكثافة، والخصائص الميكانيكية.
شاهد التقرير الكامل:https://go.hyper.ai/1x8iJ
اقترحت جامعة تشجيانغ، بالتعاون مع فرق من جامعة العلوم والتكنولوجيا الإلكترونية الصينية ومؤسسات أخرى، نموذج HealthGPT. ومن خلال إطار عمل مبتكر لتكييف المعرفة المتنوعة، نجحوا في بناء أول نموذج لغة بصرية واسع النطاق يوحد الفهم والتوليد الطبي متعدد الوسائط، مما يفتح آفاقًا جديدة لتطوير الذكاء الاصطناعي الطبي. وقد تم اختيار النتائج ذات الصلة لمؤتمر ICML 2025.
شاهد التقرير الكامل:https://go.hyper.ai/F7W6a
في كلمته المعنونة "بناء وتطبيق نظام حوسبة بروتينية ذكية"، استعرض الأستاذ المشارك تشانغ شوغانغ من كلية علوم الحاسوب بجامعة المحيط الصينية، بإسهاب، الإنجازات المبتكرة التي حققتها تقنية الحوسبة الذكية، مركزًا على التحديات التقليدية في مجال أبحاث البروتينات، ومُركزًا على نتائج أبحاث الفريق في مجالات الشرح الوظيفي، وتحديد التفاعلات، وتحسين التصميم. هذه المقالة هي نص كلمة الأستاذ المشارك تشانغ شوغانغ.
شاهد التقرير الكامل:https://go.hyper.ai/rTgSi
اقترح فريق من جامعة ميونيخ التقنية في ألمانيا وجامعة زيورخ في سويسرا طريقة جديدة لتوليد صور الأقمار الصناعية باستخدام نموذج الانتشار المستقر 3 (SD3) المشروط بمؤشرات المناخ الجغرافية، وأنشأوا أكبر وأشمل مجموعة بيانات للاستشعار عن بُعد حتى الآن، EcoMapper. تجمع هذه المجموعة أكثر من 2.9 مليون صورة أقمار صناعية بألوان RGB من 104,424 موقعًا حول العالم من Sentinel-2، تغطي 15 نوعًا من الغطاء الأرضي وسجلات المناخ المقابلة، مما يضع الأساس لطريقتين لتوليد صور الأقمار الصناعية باستخدام نموذج SD3 مُحسّن.
شاهد التقرير الكامل:https://go.hyper.ai/1zpeD
أصدرت مجلة ساينس تقريرا حصريا يقول إن التمويل المخصص لمشروع CASP من المعاهد الوطنية للصحة (NIH) قد استنفد، وعلى الرغم من أن جامعة كاليفورنيا، ديفيس (UC Davis)، المسؤولة عن إدارة أموال المشروع، قدمت الدعم الطارئ، إلا أنه سيتم استنفاده أيضًا في 8 أغسطس، ويواجه CASP أزمة التعليق.
شاهد التقرير الكامل:https://go.hyper.ai/3kTMU
مقالات موسوعية شعبية
1. كان
2. وظيفة السيني
3. حلقة الإنسان والآلة HITL
4. تعزيز الاسترجاع يولد RAG
5. ضبط التعزيزات بدقة
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
الموعد النهائي للقمة في يوليو
11 يوليو 7:59:59 بوبل 2026
15 يوليو 7:59:59 صودا 2026
18 يوليو 7:59:59 سيجمود 2026
19 يوليو 7:59:59 اي سي اس اي 2026
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








