Command Palette
Search for a command to run...
وداعًا لمشاكل البرمجة! يُطلق Seed-Coder العنان لبرمجة فعّالة؛ ويغطي Mixture-of-Thoughts بيانات متعددة المجالات لتحقيق تفكير عالي الجودة.

مع تزايد حدة المنافسة على النماذج الكبيرة واستمرار التوجه نحو "تكنولوجيا الحجم والنطاق"، أصبحت كيفية تحسين قابلية الاستخدام الفعلية للنموذج وأدائه في المهام مسألةً أكثر أهمية. ومن بين هذه القضايا، تُعد القدرة على البرمجة مؤشرًا مهمًا لقياس قابلية الاستخدام وأداء المهام في النماذج الكبيرة. بناءً على ذلك، أصدر فريق ByteDance Seed نموذجًا مفتوح المصدر خفيف الوزن ولكنه قوي للغة البرمجة الكبيرة - Seed-Coder-8B-Instruct.
هذا النموذج هو نسخة معدلة من سلسلة Seed-Coder، مبنية على بنية Llama 3، مع 8.2B معلمات وتدعم معالجة السياق بحد أقصى يبلغ 32 ألف رمز.بتدخل بشري بسيط، يستطيع برنامج LLM إدارة بيانات تدريب الكود بكفاءة عالية، مما يُحسّن قدرات البرمجة بشكل كبير. ومن خلال توليد بيانات تدريب عالية الجودة وفحصها ذاتيًا، يُمكن تحسين قدرة إنشاء كود النموذج بشكل كبير.
حاليًا، HyperAI Super Neural متصل بالإنترنت "vLLM+مبرمج نشر واجهة المستخدم على الويب المفتوح - 8B-Instruct"، تعال وجربها~
الاستخدام عبر الإنترنت:https://go.hyper.ai/BnO32
موعد البث المباشر
سيُعقد مؤتمر آبل العالمي WWDC25 في تمام الساعة الواحدة صباحًا بتوقيت بكين يوم 10 يونيو. سيبث حساب HyperAI Super Neural Video الاجتماع الرئيسي مباشرةً. لا تفوتوا الفرصة، احجزوا موعدًا الآن!

من 3 يونيو إلى 6 يونيو، تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* دروس تعليمية عالية الجودة: 13
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 4 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في يونيو: 2
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
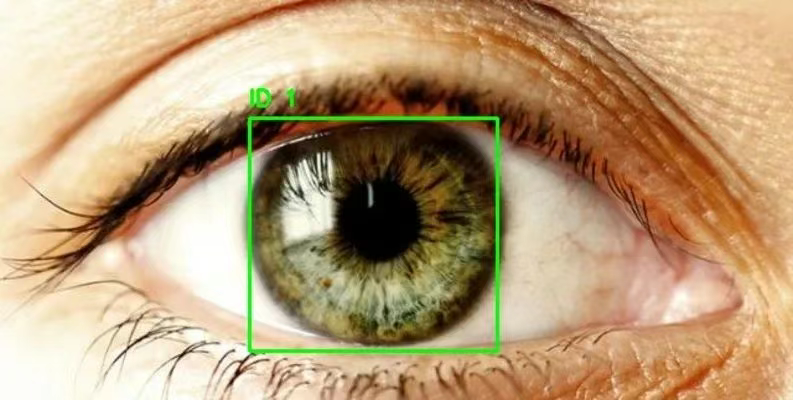
1. مجموعة بيانات الكشف عن نظارات العين
"كشف العين" هي مجموعة بيانات لكشف العين تحتوي على ما يقرب من 2000 صورة واضحة المعالم لمناطق العين، ويمكن استخدامها لتدريب نماذج كشف الأهداف مثل RCNN وYOLO لتتبع مناطق العين وكشفها. كما يمكن استخدام هذه المجموعة لبناء نماذج كشف إعتام عدسة العين، ونماذج تتبع العين، وغيرها.
الاستخدام المباشر:https://go.hyper.ai/5IUPr
2. مجموعة بيانات توصيات الموسيقى Yambda
Yambda-5B هي مجموعة بيانات واسعة النطاق لتحليل الموسيقى متعدد الوسائط، تهدف إلى توفير موارد تدريب وتقييم لنماذج اللغة الكبيرة (LLMs)، مثل التوصية بالموسيقى، واسترجاع المعلومات، والفرز. تحتوي مجموعة البيانات على 4.79 مليار تفاعل (بما في ذلك الاستماع والإعجاب وعدم الإعجاب)، تغطي مليون مستخدم و9.39 مليون مقطوعة موسيقية. وهي حاليًا واحدة من أكبر مجموعات بيانات التوصية بالموسيقى العامة.
الاستخدام المباشر:https://go.hyper.ai/VSL3J
3. مجموعة بيانات صور الأقمار الصناعية 4x
هذه المجموعة من البيانات عبارة عن مجموعة بيانات صور أقمار صناعية عالية الدقة تحتوي على أزواج من صور الأقمار الصناعية عالية الدقة (HR) ومنخفضة الدقة (LR)، وهي مصممة لمهمة الدقة الفائقة 4x.
الاستخدام المباشر:https://go.hyper.ai/TyCeW
4. مجموعة بيانات الاستدلال الطبي MedXpertQA
تحتوي مجموعة البيانات على 4460 عينة بيانات، تدمج بيانات النصوص والصور، وتغطي مهام مثل الإجابة على الأسئلة الطبية، والتشخيص السريري، وتوصية خطة العلاج، وفهم المعرفة الطبية الأساسية. ويدعم البحث والتطوير في قدرات اتخاذ القرارات الطبية المعقدة وهو مناسب للضبط الدقيق وتقييم النماذج متوسطة الحجم في المجال الطبي.
الاستخدام المباشر:https://go.hyper.ai/YGW7J
5. مجموعة بيانات أصوات الحيوانات
تحتوي مجموعة البيانات على حوالي 10800 عينة، تغطي الصوت لسبعة أنواع، بما في ذلك الطيور (مثل العصافير طويلة الذيل والعصافير الوحشية)، والكلاب، وخفافيش الفاكهة المصرية، وثعالب الماء العملاقة، والقرود، والحيتان القاتلة. يبلغ طول كل مقطع صوتي من 1 إلى 5 ثوانٍ، وهو مناسب لتدريب النماذج خفيفة الوزن والتجارب السريعة.
الاستخدام المباشر:https://go.hyper.ai/asUR4
6. مجموعة بيانات مطياف الكتلة الكيميائية من GeMS
تحتوي مجموعة البيانات على مئات الملايين من أطياف الكتلة (مثل ملياري طيف في المجموعة الفرعية GeMS-C1)، بما في ذلك بيانات رقمية منظمة (أزواج أطياف الكتلة التي تقيس نسبة الكتلة إلى الشحنة وشدتها) وبيانات وصفية (مثل المصادر الطيفية، والظروف التجريبية، وغيرها). تُعد هذه المجموعة من أكبر مجموعات بيانات مطياف الكتلة العامة المتاحة حاليًا، ويمكنها دعم تدريب النماذج فائقة الحجم.
الاستخدام المباشر:https://go.hyper.ai/yXI9M
7. مجموعة بيانات إثبات نظرية DeepTheorem
DeepTheorem هي مجموعة بيانات استدلال رياضي تهدف إلى تعزيز قدرات الاستدلال الرياضي لنماذج اللغات الكبيرة (LLMs) من خلال إثباتات نظرية غير رسمية مبنية على اللغة الطبيعية. تحتوي مجموعة البيانات على 121,000 نظرية غير رسمية وبرهان على مستوى IMO، تغطي مجالات رياضية متعددة. كل زوج من إثباتات النظرية مُعلّق عليه بدقة.
الاستخدام المباشر:https://go.hyper.ai/fjnad
8. مجموعة بيانات الاستدلال SynLogic
تهدف SynLogic إلى تعزيز قدرات الاستدلال المنطقي لنماذج اللغات الكبيرة (LLMs) من خلال التعلم التعزيزي بمكافآت قابلة للتحقق. تحتوي مجموعة البيانات على 35 مهمة استدلال منطقي متنوعة مع إمكانية التحقق التلقائي، مما يجعلها مناسبة تمامًا لتدريب التعلم التعزيزي.
الاستخدام المباشر:https://go.hyper.ai/iF5f2
9. مجموعة بيانات التفكير المختلط
"مزيج الأفكار" هي مجموعة بيانات استدلالية متعددة المجالات، تدمج مسارات استدلالية عالية الجودة في ثلاثة مجالات رئيسية: الرياضيات، والبرمجة، والعلوم. تهدف إلى تدريب نماذج اللغات الكبيرة (LLMs) على إجراء الاستدلال خطوة بخطوة. تحتوي كل عينة في هذه المجموعة على حقل رسائل يخزن عملية الاستدلال على شكل جولات حوار متعددة، مما يدعم النموذج لتعلم قدرات الاستنتاج خطوة بخطوة.
الاستخدام المباشر:https://go.hyper.ai/7Qo2l
10. مجموعة بيانات استدلال اللاما-نيموترون
تحتوي مجموعة البيانات على ما يقارب 22.06 مليون بيانات رياضية، وحوالي 10.10 مليون بيانات برمجية، أما الباقي فهو بيانات في مجالات مثل العلوم ومتابعة التعليم. تُولّد البيانات بشكل تعاوني من خلال نماذج متعددة مثل Llama-3.3-70B-Instruct وDeepSeek-R1 وQwen-2.5، والتي تغطي أساليب تفكير متنوعة ومسارات حل مشكلات لتلبية الاحتياجات المتنوعة لتدريب النماذج واسعة النطاق.
الاستخدام المباشر:https://go.hyper.ai/4V52g
دروس تعليمية عامة مختارة
هذا الأسبوع، قمنا بتلخيص 4 فئات من الدروس التعليمية العامة عالية الجودة:
*دروس الذكاء الاصطناعي في العلوم: 4
* دروس معالجة الصور: 4
*دروس إنشاء الكود: 3
*دروس التفاعل الصوتي: 2
دروس الذكاء الاصطناعي للعلوم
1. عرض توضيحي لنموذج أورورا الأساسي للغلاف الجوي واسع النطاق
يُخفّض نظام أورورا التكاليف الحسابية بشكل ملحوظ، متفوقًا في أدائه على أنظمة التنبؤ التشغيلية الحالية، مما يُعزز الوصول الواسع النطاق إلى معلومات عالية الجودة عن المناخ والطقس. وقد ثبت أن أورورا أسرع بنحو 5000 مرة من نظام التنبؤ العددي الأكثر تطورًا، IFS.
يستخدم هذا البرنامج التعليمي بطاقة A6000 أحادية البطاقة كمورد. بعد تشغيل الحاوية، انقر على عنوان API للدخول إلى واجهة الويب.
تشغيل عبر الإنترنت:https://go.hyper.ai/416Xs
2. نشر نموذج الذكاء الاصطناعي الطبي متعدد الوسائط MedGemma-4b-it بنقرة واحدة
MedGemma-4b-it هو نموذج ذكاء اصطناعي طبي متعدد الوسائط، مصمم خصيصًا للمجال الطبي. وهو نسخة مُعدّلة التعليمات من حزمة MedGemma. يستخدم مُشفّر الصور SigLIP، المُدرّب مسبقًا خصيصًا، والذي يستخدم بيانات تغطي صورًا طبية مجهولة الهوية، بما في ذلك صور الأشعة السينية للصدر، وصور الأمراض الجلدية، وصور طب العيون، ومقاطع الأنسجة المرضية.
يستخدم هذا البرنامج التعليمي بطاقة RTX 4090 واحدة كمورد. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب.
تشغيل عبر الإنترنت:https://go.hyper.ai/31RKp
3. نشر نموذج الاستدلال الطبي MedGemma-27b-text-it بنقرة واحدة
يركز هذا النموذج على معالجة النصوص السريرية، وهو جيد بشكل خاص في فرز المرضى ومساعدة اتخاذ القرار، مما يوفر للأطباء معلومات سريعة وقيمة عن حالة المريض لتسهيل صياغة خطط العلاج الفعالة.
يستخدم هذا البرنامج التعليمي موارد هاتف A6000 ثنائي الشريحة. افتح الرابط أدناه لنشره بنقرة واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/2mDmF
4. نشر vLLM+Open WebUI II-Medical-8B نموذج التفكير الطبي
يعتمد النموذج على نموذج Qwen/Qwen3-8B ويحسن أداء النموذج باستخدام SFT (الضبط الدقيق الخاضع للإشراف) باستخدام مجموعة بيانات استدلال طبية محددة وتدريب DAPO (طريقة تحسين محتملة) على مجموعة بيانات استدلال صعبة.
موارد الحوسبة المستخدمة في هذا البرنامج التعليمي هي بطاقة RTX 4090 واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/1Qvwo
برنامج تعليمي لمعالجة الصور
1. DreamO: إطار عمل موحد لتخصيص الصور
استنادًا إلى بنية DiT (محول الانتشار)، يدمج DreamO مجموعة متنوعة من مهام إنشاء الصور، ويدعم وظائف معقدة مثل تغيير الأزياء (IP)، وتغيير الوجه (ID)، ونقل الأسلوب (Style)، والجمع بين العديد من الموضوعات، ويحقق التحكم في العديد من الحالات من خلال نموذج واحد.
يستخدم هذا البرنامج التعليمي الموارد لبطاقة واحدة A6000.
تشغيل عبر الإنترنت:https://go.hyper.ai/zGGbh
2. BAGEL: نموذج موحد للفهم والتوليد متعدد الوسائط
صُمم BAGEL-7B-MoT للتعامل بشكل موحد مع مهام فهم وتوليد البيانات متعددة الوسائط، مثل النصوص والصور والفيديو. وقد أثبت BAGEL قدرات شاملة في مهام متعددة الوسائط، مثل فهم وتوليد البيانات متعددة الوسائط، والاستدلال والتحرير المعقد، ونمذجة العالم، والملاحة. وتتمثل وظائفه الرئيسية في الفهم البصري، وتحويل النص إلى صورة، وتحرير الصور، وغيرها.
يستخدم هذا البرنامج التعليمي موارد الحوسبة A6000 ثنائية البطاقة ويوفر إنشاء الصور، وتوليد الصور باستخدام Think، وتحرير الصور، وتحرير الصور باستخدام Think، وفهم الصور للاختبار.
تشغيل عبر الإنترنت:https://go.hyper.ai/76cEZ

3. برنامج تعليمي عبر الإنترنت لسير عمل ComfyUI Flex.2-معاينة
يُمكّن Flex.2-preview من إنشاء صور عالية الجودة بناءً على أوصاف النصوص المُدخلة، ويدعم إدخال ما يصل إلى 512 رمزًا نصيًا، ويدعم فهم الأوصاف المُعقدة لإنشاء محتوى الصورة المُطابق. كما يدعم إصلاح أو استبدال مناطق مُحددة من الصورة. يُوفر المستخدم صورة الإصلاح وقناع الإصلاح، ويُنشئ النموذج محتوى صورة جديدًا في المنطقة المُحددة.
يستخدم هذا البرنامج التعليمي بطاقة RTX 4090 واحدة كمورد ويدعم فقط المطالبات باللغة الإنجليزية.
تشغيل عبر الإنترنت:https://go.hyper.ai/MH5qY
4. برنامج تعليمي لاستعادة الصور باستخدام ComfyUI LanPaint
LanPaint أداة مفتوحة المصدر لاستعادة الصور محليًا، تستخدم أسلوبًا استدلاليًا مبتكرًا للتكيف مع مجموعة متنوعة من نماذج الانتشار المستقرة (بما في ذلك النماذج المخصصة) دون الحاجة إلى تدريب إضافي، مما يحقق استعادة عالية الجودة للصور. مقارنةً بالطرق التقليدية، يوفر LanPaint حلاً أخف وزنًا يقلل بشكل كبير من الحاجة إلى بيانات التدريب وموارد الحوسبة.
يستخدم هذا البرنامج التعليمي بطاقة RTX 4090 واحدة. يمكنك استنساخ النموذج بسرعة بفتح الرابط أدناه.
تشغيل عبر الإنترنت:https://go.hyper.ai/QAuag
برنامج تعليمي لإنشاء الكود
1. vLLM+مبرمج نشر واجهة المستخدم على الويب المفتوح - 8B-Instruct
Seed-Coder-8B-Instruct هو نموذج لغة برمجة مفتوح المصدر خفيف الوزن وقوي. وهو نسخة مُحسّنة من سلسلة تعليمات Seed-Coder. باستخدام أقل قدر من الموارد البشرية، يُمكن لـ LLM إدارة بيانات تدريب البرمجة بكفاءة عالية، مما يُحسّن قدرات البرمجة بشكل كبير. يعتمد النموذج على بنية Llama 3، ويحتوي على 8.2 مليار معلمة، ويدعم سياقًا بطول 32 ألف رمز.
موارد الحوسبة المستخدمة في هذا البرنامج التعليمي هي بطاقة RTX 4090 واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/BnO32
2. Mellum-4b-base هو نموذج مصمم لاستكمال التعليمات البرمجية
صُمم نموذج Mellum-4b-base لمهام فهم الأكواد البرمجية وتوليدها وتحسينها. يُظهر النموذج قدرات ممتازة في عملية تطوير البرمجيات بأكملها، وهو مناسب لسيناريوهات مثل البرمجة المُحسّنة بالذكاء الاصطناعي، وتكامل بيئات التطوير المتكاملة الذكية، وتطوير الأدوات التعليمية، وأبحاث الأكواد البرمجية.
يستخدم هذا البرنامج التعليمي بطاقة RTX 4090 واحدة كمورد، ويُستخدم النموذج فقط لتحسين الكود.
تشغيل عبر الإنترنت:https://go.hyper.ai/2iEWz
3. نشر OpenCodeReasoning-Nemotron-32B بنقرة واحدة
هذا النموذج هو نموذج لغوي كبير عالي الأداء، مصمم لاستنتاج وتوليد الأكواد البرمجية. وهو الإصدار الرائد من مجموعة نماذج OpenCodeReasoning (OCR)، ويدعم طول سياق يبلغ 32 ألف رمز.
الموارد الحاسوبية المستخدمة في هذا البرنامج التعليمي هي البطاقة المزدوجة A6000.
تشغيل عبر الإنترنت:https://go.hyper.ai/jhwYd
برنامج تعليمي للتفاعل الصوتي
1. VITA-1.5: عرض توضيحي لنموذج التفاعل متعدد الوسائط
ITA-1.5 هو نموذج لغوي متعدد الوسائط واسع النطاق، يدمج الرؤية واللغة والكلام، وهو مصمم لتحقيق تفاعل بصري وكلامي آني بمستوى مماثل لـ GPT-4o. يُقلل VITA-1.5 زمن استجابة التفاعل بشكل ملحوظ من 4 ثوانٍ إلى 1.5 ثانية، مما يُحسّن تجربة المستخدم بشكل كبير.
يستخدم هذا البرنامج التعليمي بطاقة A6000 واحدة كمورد. في الوقت الحالي، يدعم التفاعل بالذكاء الاصطناعي اللغتين الصينية والإنجليزية فقط.
تشغيل عبر الإنترنت:https://go.hyper.ai/WTcdM
2. كيمي أوديو: دع الذكاء الاصطناعي يفهم البشر
Kimi-Audio-7B-Instruct هو نموذج بنية تحتية صوتية مفتوح المصدر، قادر على التعامل مع مهام معالجة صوتية متنوعة ضمن إطار عمل موحد. يمكنه التعامل مع مهام متنوعة، مثل التعرف التلقائي على الكلام (ASR)، والإجابة على الأسئلة الصوتية (AQA)، والترجمة الصوتية التلقائية (AAC)، والتعرف على انفعالات الكلام (SER)، وتصنيف الأحداث/المشاهد الصوتية (SEC/ASC)، والحوار الصوتي الشامل.
يستخدم هذا البرنامج التعليمي الموارد لبطاقة واحدة A6000.
تشغيل عبر الإنترنت:https://go.hyper.ai/UBRBP
توصيات الورقة البحثية لهذا الأسبوع
1. نموذج أساسي لنظام الأرض
تقترح هذه الورقة نموذج أورورا، وهو نموذج أساسي واسع النطاق تم تدريبه على أكثر من مليون ساعة من البيانات الجيوفيزيائية المتنوعة، والذي يتفوق على أنظمة التنبؤ التشغيلية الحالية في جودة الهواء، وأمواج المحيط، ومسارات الأعاصير المدارية، والتنبؤ بالطقس عالي الدقة.
رابط الورقة:https://go.hyper.ai/ibyij
2. Paper2Poster: نحو أتمتة الملصقات متعددة الوسائط من الأوراق العلمية
يُعدّ إنشاء ملصقات الأوراق الأكاديمية مهمةً بالغة الأهمية وصعبةً في التواصل العلمي، إذ يتطلب ضغط المستندات الطويلة المتداخلة في صفحة واحدة ذات محتوى مترابط بصريًا. ولمعالجة هذا التحدي، تُقدّم هذه الورقة أول مجموعة معايير ومقاييس لإنشاء ملصقات الأوراق الأكاديمية، والتي تُمكّن من تحويل ورقة من 22 صفحة إلى ملصق نهائي قابل للتعديل بصيغة pptx.
رابط الورقة:https://go.hyper.ai/Q4cQG
3. ProRL: التعلم التعزيزي المطول يوسع حدود التفكير في نماذج اللغة الكبيرة
لا يزال الجدل قائمًا حول ما إذا كان التعلم المعزز يُوسّع بالفعل قدرة النموذج على التفكير المنطقي. تقترح هذه الورقة البحثية أسلوب تدريب جديد، ProRL، يجمع بين التحكم في تباعد KL، وإعادة ضبط سياسة المرجع، ومجموعة مهام متنوعة، مما يُقدّم رؤى جديدة لفهم أفضل للظروف التي يُوسّع فيها التعلم المعزز حدود التفكير المنطقي لنماذج اللغة بشكل هادف.
رابط الورقة:https://go.hyper.ai/62DUb
4. تدريب لاحق غير خاضع للإشراف على التفكير متعدد الوسائط في برنامج الماجستير في القانون عبر GRPO
تستخدم هذه الدراسة خوارزمية GRPO، وهي خوارزمية تعلّم تعزيزي عبر الإنترنت مستقرة وقابلة للتطوير، لتحقيق تحسين ذاتي مستمر دون إشراف خارجي، وتقترح MM-UPT، وهو إطار عمل بسيط وفعال للتدريب اللاحق غير الخاضع للإشراف لنماذج اللغات الكبيرة متعددة الوسائط. تُظهر النتائج التجريبية أن MM-UPT يُحسّن بشكل ملحوظ قدرة Qwen2.5-VL-7B على الاستدلال.
رابط الورقة:https://go.hyper.ai/W5nO5
5. آلية الإنتروبيا في التعلم التعزيزي لنماذج اللغة المنطقية
تهدف هذه الورقة البحثية إلى التغلب على عقبة رئيسية عند استخدام نماذج اللغات الكبيرة (LLMs) في الاستدلال في التعلم التعزيزي واسع النطاق، ألا وهي انهيار إنتروبيا السياسات. ولتحقيق ذلك، اقترح الباحثون طريقتين بسيطتين وفعالتين: Clip-Cov وKL-Cov. الأولى تقص رموز التباين العالي، بينما تفرض الثانية عقوبة KL على هذه الرموز. تُظهر النتائج التجريبية أن هاتين الطريقتين يمكنهما تعزيز سلوك الاستكشاف، مما يساعد السياسات على تجنب انهيار إنتروبيا وتحقيق أداء أفضل في المراحل اللاحقة.
رابط الورقة:https://go.hyper.ai/rFSoq
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/UuE1o
تفسير مقالة المجتمع
استناداً إلى الإنجازات التي حققتها سلسلة GPT في مجال اللغة، قام فريق بحثي من معهد الكيمياء العضوية والكيمياء الحيوية التابع للأكاديمية التشيكية للعلوم باستخراج 700 مليون طيف MS/MS من الشبكة الجزيئية الاجتماعية العالمية للمنتجات الطبيعية (GNPS)، ونجحوا في بناء أكبر مجموعة بيانات مطيافية كتلة في التاريخ، GeMS، وتدريب نموذج Transformer DreaMS مع 116 مليون معلمة.
شاهد التقرير الكامل:https://go.hyper.ai/P9qvl
من أجل ربط الأبحاث المتطورة بشكل أفضل بسيناريوهات التطبيق، ستعقد HyperAI الدورة السابعة من معرض Meet AI Compiler Technology Salon في بكين في 5 يوليو. ويسعدنا أن ندعو العديد من كبار الخبراء من AMD وجامعة بكين وMuxi Integrated Circuit وغيرها لمشاركة أفضل ممارساتهم وتحليلاتهم للاتجاهات لمُجمّعي الذكاء الاصطناعي.
شاهد التقرير الكامل:https://go.hyper.ai/FPxw2
ألقى الدكتور ليانغ هاوجيان، من معهد ابتكار معلومات الفضاء التابع للأكاديمية الصينية للعلوم، كلمة بعنوان "بحث في أساليب تحسين تصميم مرافق إطفاء الحرائق في حالات الطوارئ الحضرية القائمة على التعلم التعزيزي العميق الهرمي" خلال الاجتماع السنوي الأكاديمي لعام ٢٠٢٥ للجنة المهنية للنماذج الجغرافية وتحليل المعلومات الجغرافية التابعة للجمعية الجغرافية الصينية. انطلاقًا من تحسين تصميم مرافق إطفاء الحرائق في المناطق الحضرية، خضعت أساليب التحسين التقليدية في مجال التحسين الجغرافي المكاني لمراجعة منهجية، وقُدّمت بالتفصيل مزايا وإمكانيات أساليب التحسين القائمة على التعلم التعزيزي العميق (DRL). هذه المقالة هي نسخة من أبرز ما جاء في مداخلة الدكتور ليانغ هاوجيان.
شاهد التقرير الكامل:https://go.hyper.ai/xvnAI
أصدر مختبر العرض التابع للجامعة الوطنية في سنغافورة مكونًا إضافيًا للاتساق العالمي، OmniConsistency، والذي يستخدم محول انتشار واسع النطاق (DiT) في 28 مايو 2025. وهو تصميم توصيل وتشغيل كامل، متوافق مع LoRA من أي نمط ضمن إطار Flux، ويستند إلى آلية تعلم الاتساق لأزواج الصور المنمقة لتحقيق تعميم قوي.
شاهد التقرير الكامل:https://go.hyper.ai/etmWQ
مقالات موسوعية شعبية
1. دال-إي
2. حلقة الإنسان والآلة
3. دمج الفرز العكسي
4. الذاكرة طويلة المدى ثنائية الاتجاه
5. فهم اللغة متعدد المهام على نطاق واسع
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
الموعد النهائي للقمة في يونيو
مؤشر ستاندرد آند بورز 2026 6 يونيو 7:59:59
اي سي دي 2026 19 يونيو 7:59:59
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كنت تريد تضمين هايبر.اي بالنسبة للموارد الموجودة على الموقع الرسمي، نرحب بك أيضًا لترك رسالة أو المساهمة في إخبارنا!
نراكم في الاسبوع القادم!








