Command Palette
Search for a command to run...
نموذج الانتشار × توليد الموسيقى، DiffRhythm يكمل إنشاء الأغنية في دقائق! مجموعة بيانات MiniMind مفتوحة المصدر لتمكين نماذج اللغة الكبيرة ذات الحواجز المنخفضة للنشر

لقد حقق مجال توليد الموسيقى تقدمًا كبيرًا في السنوات الأخيرة، ولكن النماذج الحالية لا تزال تعاني من العديد من القيود في التطبيقات العملية. لا يمكن لمعظم النماذج سوى إنشاء مسارات صوتية أو مصاحبة بشكل مستقل، مما يؤدي إلى تجربة موسيقية غير متماسكة. ولمعالجة هذه التحديات، قام مختبر معالجة الصوت واللغة في جامعة نورث وسترن بوليتكنيك وجامعة هونج كونج الصينية بتطوير نموذج مشترك يسمى DiffRhythm.
باعتباره أول نموذج مفتوح المصدر لتوليد الأغاني بالكامل يعتمد على تقنية الانتشارلا يحافظ DiffRhythm على مستوى عالٍ من توليد الموسيقى وفهمها فحسب، بل يضمن أيضًا قابلية التوسع من خلال نموذج موجز وفعال وهندسة معمارية وخط أنابيب معالجة البيانات. من حيث تجربة المستخدم، يضمن هيكلها غير المتراجع سرعة إنشاء سريعة.إنشاء موسيقى كاملة في دقيقة واحدة فقط.
في الوقت الحاضر، أطلقت HyperAI البرنامج التعليمي "DiffRhythm: إنشاء عرض توضيحي كامل للموسيقى في دقيقة واحدة". تعال وجربها~
الاستخدام عبر الإنترنت:https://go.hyper.ai/sHdPu
من 17 مارس إلى 21 مارس، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* دروس تعليمية مختارة عالية الجودة: 2
* اختيار المقالات المجتمعية: 6 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في مارس: 1
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
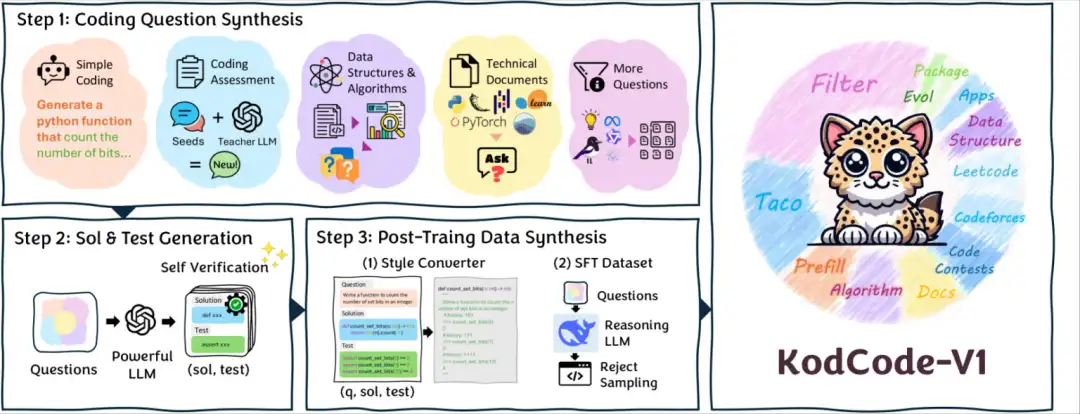
1. مجموعة بيانات تجميع ترميز KodCode-V1
تُعد مجموعة البيانات هذه حاليًا أكبر مجموعة بيانات مفتوحة المصدر مصنعة بالكامل، وتوفر حلولاً واختبارات قابلة للتحقق لمهام الترميز. يحتوي هذا الكتاب على 12 مجموعة فرعية مختلفة، تغطي مجالات مختلفة (من الخوارزميات إلى المعرفة الخاصة بحزمة البرامج) ومستويات الصعوبة (من تمارين الترميز الأساسية إلى المقابلات وتحديات البرمجة التنافسية)، وهو مصمم للضبط الدقيق الخاضع للإشراف (SFT) والضبط التعزيزي.
الاستخدام المباشر:https://go.hyper.ai/CfZCm
2. مخاطر الطرق مجموعة بيانات مخاطر الطرق
تحتوي مجموعة البيانات هذه على 2.7 ألف صورة ويتم استخدامها بشكل أساسي للكشف عن الحفر والشقوق وفتحات الصرف الصحي المفتوحة على الطريق.
الاستخدام المباشر:https://go.hyper.ai/XPJNQ

3. مجموعة بيانات DexGraspVLA Robot Grasping
هذه مجموعة بيانات صغيرة تحتوي على 51 عينة من بيانات العرض التوضيحي البشري، وهي مفيدة لفهم البيانات والتنسيق، وتشغيل التعليمات البرمجية لتجربة عملية التدريب. تنبع الخلفية البحثية من الحاجة إلى معدل نجاح مرتفع للإمساك الماهر في المشاهد المزدحمة، وخاصة تحقيق معدل نجاح يزيد عن 90% في ظل مجموعات غير مسبوقة من الأشياء والإضاءة والخلفيات.
الاستخدام المباشر:https://go.hyper.ai/pJ44Y

4. مجموعة بيانات الخداع البصري VQA من IllusionAnimals
مجموعة بيانات IllusionAnimals عبارة عن مجموعة بيانات FiftyOne تحتوي على 2000 عينة. تحتوي مجموعة البيانات على 10 فئات حيوانية وفئة واحدة خالية من الوهم، بدقة صورة تبلغ 512×512 بكسل. يتم استخدامه لتقييم قدرة النماذج متعددة الوسائط في تحديد وتفسير الأوهام البصرية المستندة إلى الحيوانات.
الاستخدام المباشر:https://go.hyper.ai/Ebl40

5. مجموعة بيانات تقييم النموذج الكبير متعدد اللغات ومتعدد الوسائط m-WildVision
تحتوي مجموعة البيانات على 500 مثال لاستعلامات المستخدم الصعبة بـ 23 لغة، كل منها مشتق من منصة WildVision-Arena. يتضمن هيكل مجموعة البيانات معرف السؤال ونوع اللغة ونص التعليمات وبيانات الصورة، بهدف تقييم تعميم النموذج ومتانته في لغات مختلفة.
الاستخدام المباشر:https://go.hyper.ai/Im6mN

6. مجموعة بيانات MiniMind للتدريب والضبط الدقيق للنماذج الكبيرة
MiniMind هو مشروع نموذج لغة كبير خفيف الوزن مفتوح المصدر يهدف إلى خفض عتبة استخدام نماذج اللغة الكبيرة (LLM) وتمكين المستخدمين الفرديين من التدريب والاستنتاج بسرعة على الأجهزة العادية.
الاستخدام المباشر:https://go.hyper.ai/gCz2y
7. مجموعة بيانات سي كلير للكشف عن الحطام البحري وتقسيمه
تحتوي مجموعة البيانات على 8610 صورة للحطام البحري موضحة لمهام اكتشاف الكائنات وتجزئة الحالات، وتغطي 40 فئة من الكائنات بما في ذلك ليس فقط الحطام ولكن أيضًا الحيوانات والنباتات وأجزاء الروبوت التي تمت ملاحظتها. يتم توفير التعليقات التوضيحية كملفات بتنسيق COCO (.json)، ويتم ترتيب الصور في مجلدات، حيث يتم تخصيص كل مجلد لزوج فريد من الكاميرات الخاصة بالموقع. جميع الصور بدقة 1920×1080.
الاستخدام المباشر:https://go.hyper.ai/JFofd
8. مجموعة بيانات رموز التحقق النصية والصوتية
تحتوي مجموعة البيانات على 100 ألف عينة CAPTCHA، كل منها مُسمَّى بسلسلة أبجدية رقمية مقابلة لها، مما يجعلها مثالية لتدريب نماذج OCR والتعرف على الكلام ومُحَلِّلات CAPTCHA المستندة إلى الذكاء الاصطناعي.
الاستخدام المباشر:https://go.hyper.ai/vFmTJ
9. مجموعة بيانات تصنيف القمامة
تحتوي مجموعة البيانات على صور وتعليقات بتنسيق YOLO لتصنيف واكتشاف أنواع مختلفة من النفايات: البلاستيك والورق والكرتون والزجاج / المعادن والنفايات العضوية والمنسوجات والإلكترونيات (النفايات الإلكترونية).
الاستخدام المباشر:https://go.hyper.ai/NwEF7
١٠. صورة سطح المريخ (مركبة كيوريوسيتي) مجموعة بيانات صور سطح المريخ
تتكون مجموعة البيانات من 6691 صورة تم جمعها بواسطة ثلاثة أجهزة تابعة لمختبر علوم المريخ (MSL): Mastcam للعين اليمنى، وMastcam للعين اليسرى، وMAHLI، وتغطي 24 فئة. هذه الصور عبارة عن إصدارات "تصفح" لكل منتج بيانات خام وليست بدقة كاملة، حيث يبلغ حجم كل صورة تقريبًا 256 × 256 بكسل.
الاستخدام المباشر:https://go.hyper.ai/B1T0l
دروس تعليمية عامة مختارة
1. نشر Gemma-3-27B-IT باستخدام vLLM
سلسلة Gemma هي سلسلة من النماذج الكبيرة مفتوحة المصدر من Google، والتي تم بناؤها على نفس الأبحاث والتكنولوجيا مثل نموذج Gemini. Gemma 3 هو نموذج متعدد الوسائط كبير الحجم يمكنه معالجة مدخلات النصوص والصور وإنشاء مخرجات نصية. النموذج مناسب لمجموعة متنوعة من مهام توليد النصوص وفهم الصور، بما في ذلك الإجابة على الأسئلة، والتلخيص، والاستدلال. إن حجمها الصغير نسبيًا يمكّنها من الانتشار في بيئات ذات موارد محدودة، مثل أجهزة الكمبيوتر المحمولة أو أجهزة الكمبيوتر المكتبية أو البنى التحتية السحابية.
لقد تم نشر النماذج والتبعيات ذات الصلة بهذا المشروع. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب.
تشغيل عبر الإنترنت:https://go.hyper.ai/JxVbA
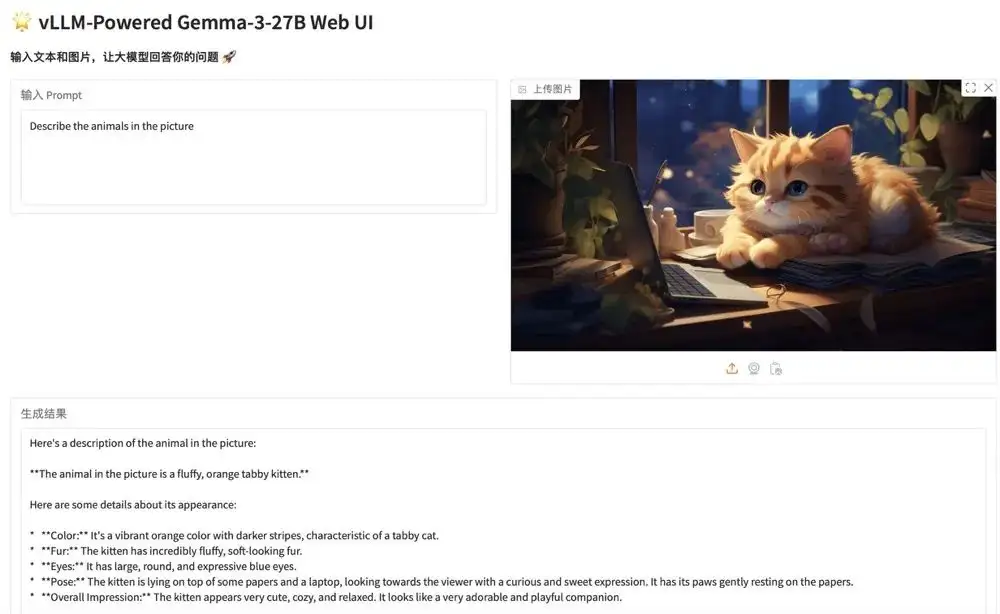
2. DiffRhythm: إنشاء عرض توضيحي كامل للموسيقى في دقيقة واحدة
DiffRhythm هو أول نموذج لتوليد الأغاني يعتمد على الانتشار وقادر على تأليف أغانٍ كاملة. يمكنه إنشاء أغنية كاملة تصل مدتها إلى 4 دقائق و45 ثانية، بما في ذلك الغناء والمرافقة، في وقت قصير. كل ما يحتاجه المستخدمون هو تقديم كلمات الأغاني وتلميحات الأسلوب، ويمكن لـ DiffRhythm إنشاء الألحان والموسيقى المرافقة تلقائيًا والتي تتوافق مع كلمات الأغاني، مع دعم الإدخال متعدد اللغات.
لقد تم نشر النماذج والتبعيات ذات الصلة بهذا المشروع. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب.
تشغيل عبر الإنترنت:https://go.hyper.ai/sHdPu
مقالات المجتمع
قام فريق الأكاديمي وو ليكسين بدمج علم المحيطات الفيزيائية بشكل عميق مع الذكاء الاصطناعي، واستخدم نظرية ديناميكيات المحيطات لتحريك بنية الشبكة العصبية، وبنى نموذجًا ذكيًا للتنبؤ ببيئة المحيطات العالمية عالية الدقة "وينهاي" ليعكس بشكل أفضل حالة المحيط الحقيقي ويوفر بشكل كبير وقت الحوسبة واستهلاك الطاقة. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/s7YMj
اقترح فريق بحثي من جامعة كامبريدج نموذجًا افتراضيًا للأنسجة يسمى Celcomen، والذي لا يمكنه تقدير تأثير البيئة على الخلايا الفردية فحسب، بل يمكنه أيضًا استنتاج تأثير الخلايا الفردية على البيئة المحيطة بها والأنسجة بشكل عام. وقد تحقق الباحثون من إمكانية التعرف على نموذج Celcomen في التعلم الهيكلي السببي وكشف العلاقات السببية من خلال البيانات الاصطناعية المتسقة ذاتيًا وتجارب البيانات في العالم الحقيقي، فضلاً عن قدرته على كشف واستعادة التفاعلات الجينية في البيانات النسخية المكانية الحقيقية والمحاكاة ذاتيًا. وقد تم اختيار النتائج ذات الصلة لـ ICLR 2025. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/ylKOr
في البث المباشر السابع لـ Meet AI4S، دعت HyperAI الأستاذ المشارك هوانغ هونغ من جامعة هواتشونغ للعلوم والتكنولوجيا، والدكتور تشو دونغزان من مختبر شنغهاي للذكاء الاصطناعي، والدكتور تشو بينجكسين من معهد أبحاث جامعة شنغهاي جياو تونغ لمناقشة التطور المتطور للذكاء الاصطناعي في العلوم الاجتماعية والكيمياء الفيزيائية وعلوم الحياة وغيرها من المجالات مع ثلاثة علماء. كما شاركوا رؤاهم حول اختيار اتجاهات البحث وخبرتهم في تقديم الأوراق إلى مؤتمرات الذكاء الاصطناعي الرائدة. هذه المقالة عبارة عن ملخص لمشاركة المعلمين الثلاثة.
شاهد التقرير الكامل:https://go.hyper.ai/klU6m
ألقى الرئيس التنفيذي لشركة NVIDIA جينسن هوانج خطابًا رئيسيًا في مؤتمر GTC 2025، الحدث العالمي السنوي للذكاء الاصطناعي، والذي يركز على أحدث التطورات في مجال الذكاء الاصطناعي المتطور. ولم يقتصر الأمر على عرض الجيل الجديد من رقائق الذكاء الاصطناعي المخصصة للاستخدامات النووية من بلاكويل فحسب، بل أطلق أيضًا سلسلة من الإنجازات الجديدة بما في ذلك مجموعة بيانات الذكاء الاصطناعي الفيزيائي، ونموذج GR00T N1، ومحرك نيوتن الفيزيائي، ونموذج العالم كوزموس. تلخص هذه المقالة محتوى خطاب هوانغ رينكسون وإنجازاته الجديدة.
شاهد التقرير الكامل:https://go.hyper.ai/Q6wdO
قامت شركة NVIDIA، بالتعاون مع معهد ماساتشوستس للتكنولوجيا وشركات أخرى، بتطوير نوع جديد من مولدات العمود الفقري للبروتين المتدفق على نطاق واسع، Proteina. تحتوي شركة Proteina على خمسة أضعاف عدد معلمات نموذج RFdiffusion، كما قامت بتوسيع بيانات التدريب الخاصة بها إلى 21 مليون بنية بروتينية اصطناعية. وقد حققت أداء SOTA في تصميم العمود الفقري للبروتين الجديد وأنشأت بروتينات متنوعة وقابلة للتصميم بطول غير مسبوق يصل إلى 800 بقايا. وقد تم اختيار نتائجها لـ ICLR 2025 الشفوي. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/w7jlU
تعاونت جامعة شنغهاي جياو تونغ مع عدد من المؤسسات الكبرى لبناء نظام تقييم موثوق وإجراء اختبارات منهجية لعشرة برامج ماجستير في القانون في الداخل والخارج، بما في ذلك ChatGPT و DeepSeek. يقدم هذا أول دليل واقعي على تدريب أطباء الرعاية الأولية بمساعدة الذكاء الاصطناعي ويوفر دعماً رئيسياً للرعاية الصحية الأولية المدعومة بالذكاء الاصطناعي. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/DH8hf
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1700 مجموعة بيانات عامة
* يتضمن أكثر من 500 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* يدعم البحث عن أكثر من 600 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








