Command Palette
Search for a command to run...
يحتوي على 284 مجموعة بيانات تغطي 18 مهمة سريرية، أصدر مختبر شنغهاي للذكاء الاصطناعي وآخرون معيارًا طبيًا متعدد الوسائط GMAI-MMBench

"بفضل هذا الجهاز الطبي الذكي، لا يحتاج المرضى إلا إلى الاستلقاء عليه لإكمال العملية برمتها من المسح والتشخيص والعلاج والإصلاح، وتحقيق بداية صحية جديدة." هذه قصة من فيلم الخيال العلمي "إليسيوم" لعام 2013.

في الوقت الحاضر، ومع التطور السريع لتكنولوجيا الذكاء الاصطناعي، نأمل أن تصبح المشاهد الطبية التي تظهر في أفلام الخيال العلمي حقيقة واقعة. في المجال الطبي، يمكن لنماذج اللغة البصرية واسعة النطاق (LVLMs) معالجة مجموعة متنوعة من أنواع البيانات مثل التصوير والنصوص وحتى الإشارات الفسيولوجية، مثل DeepSeek-VL، وGPT-4V، وClaude3-Opus، وLLaVA-Med، وMedDr، وDeepDR-LLM، وما إلى ذلك، مما يُظهر إمكانات تطوير كبيرة في تشخيص الأمراض وعلاجها.
ومع ذلك، قبل أن يتم وضع نماذج LVLM في الممارسة السريرية، يجب وضع اختبارات معيارية لتقييم فعالية النماذج. ومع ذلك، فإن المعايير الحالية تعتمد عادة على الأدبيات الأكاديمية المحددة وتركز بشكل أساسي على مجال واحد، وتفتقر إلى حبيبات إدراكية مختلفة، مما يجعل من الصعب تقييم فعالية وأداء LVLMs بشكل شامل في السيناريوهات السريرية الحقيقية.
ردًا على ذلك، اقترح مختبر الذكاء الاصطناعي في شنغهاي، بالتعاون مع العديد من مؤسسات البحث العلمي بما في ذلك جامعة واشنطن وجامعة موناش وجامعة شرق الصين العادية، معيار GMAI-MMBench. تم بناء GMAI-MMBench من 284 مجموعة بيانات مهام لاحقة من جميع أنحاء العالم، تغطي 38 نموذجًا للتصوير الطبي، و18 مهمة ذات صلة سريرية، و18 قسمًا، و4 حبيبات إدراكية بتنسيق الإجابة على الأسئلة المرئية (VQA)، مع تصنيف هيكل البيانات الكامل والحبيبات المتعددة الإدراكية.
تم اختيار البحث ذي الصلة، بعنوان "GMAI-MMBench: معيار تقييم متعدد الوسائط شامل نحو الذكاء الاصطناعي الطبي العام"، لمعيار بيانات NeurIPS 2024 وتم نشره كنسخة أولية على arXiv.

عنوان الورقة:
https://arxiv.org/abs/2408.03361v7
"مجموعة بيانات معيار التقييم الطبي المتعدد الوسائط GMAI-MMBench" متاحة الآن على الموقع الرسمي لشركة HyperAI ويمكن تنزيلها بنقرة واحدة!
عنوان تنزيل مجموعة البيانات:
https://go.hyper.ai/xxy3w
GMAI-MMBench: معيار الذكاء الاصطناعي الطبي العام الأكثر شمولاً ومفتوح المصدر حتى الآن
يمكن تقسيم عملية البناء الشاملة لـ GMAI-MMBench إلى 3 خطوات رئيسية:
أولاً، قام الباحثون بالبحث في مئات مجموعات البيانات من مجموعات البيانات العامة العالمية وبيانات المستشفيات. وبعد الفحص وتوحيد تنسيقات الصور وتوحيد تعبيرات العلامات، احتفظوا بـ 284 مجموعة بيانات تحتوي على علامات عالية الجودة.
ومن الجدير بالذكر أن هذه المجموعات الـ 284 من البيانات تغطي مجموعة متنوعة من مهام التصوير الطبي مثل الكشف ثنائي الأبعاد، والتصنيف ثنائي الأبعاد، والتجزئة ثنائية/ثلاثية الأبعاد، ويتم شرحها من قبل أطباء محترفين، مما يضمن تنوع مهام التصوير الطبي بالإضافة إلى الأهمية السريرية العالية والدقة.
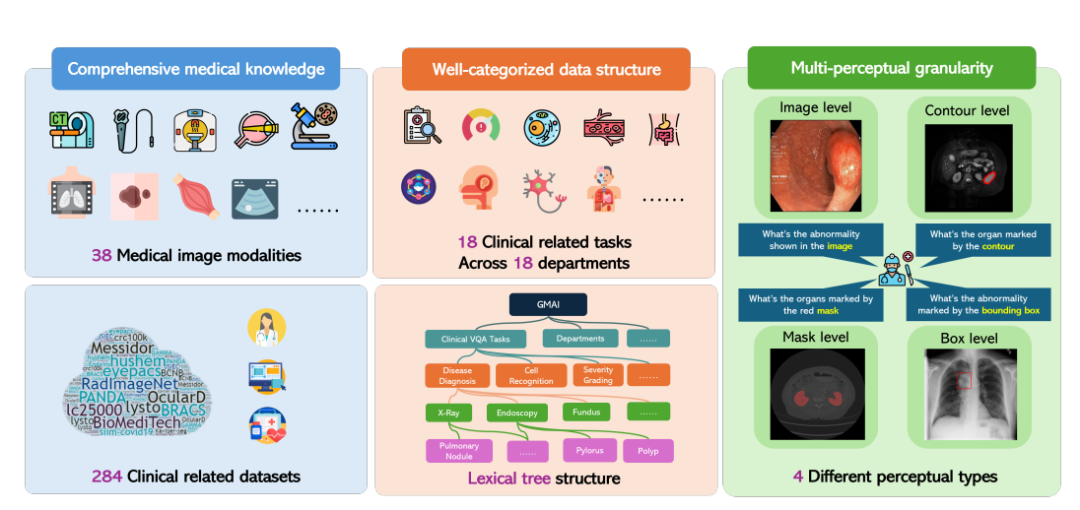
بعد ذلك، قام الباحثون بتصنيف جميع العلامات إلى 18 مهمة VQA سريرية و18 قسمًا سريريًا، مما يجعل من الممكن تقييم إيجابيات وسلبيات LVLMs بشكل شامل في جوانب مختلفة، وهو أمر مناسب لمطوري النماذج والمستخدمين ذوي الاحتياجات المحددة.
على وجه التحديد، صمم الباحثون نظام تصنيف يسمى هيكل الشجرة المعجمية، والذي قسم جميع الحالات إلى 18 مهمة سريرية لتقييم الجودة البصرية، و18 قسمًا، و38 نمطًا، وما إلى ذلك. "مهمة تقييم الجودة البصرية السريرية"، و"القسم"، و"النمط" هي مصطلحات يمكن استخدامها لاسترجاع حالات التقييم المطلوبة. على سبيل المثال، يمكن لأقسام الأورام اختيار الحالات المتعلقة بالأورام لتقييم أداء أجهزة LVLM في مهام الأورام، مما يحسن بشكل كبير المرونة وسهولة الاستخدام للاحتياجات المحددة.
وأخيرًا، قام الباحثون بإنشاء أزواج من الأسئلة والأجوبة استنادًا إلى مجموعة الأسئلة والخيارات المقابلة لكل تسمية.يجب أن يحتوي كل سؤال على نمط الصورة، ومطالبات المهام، ومعلومات حبيبات التعليق التوضيحي المقابلة. تم الحصول على المعيار النهائي من خلال التحقق الإضافي والفحص اليدوي.
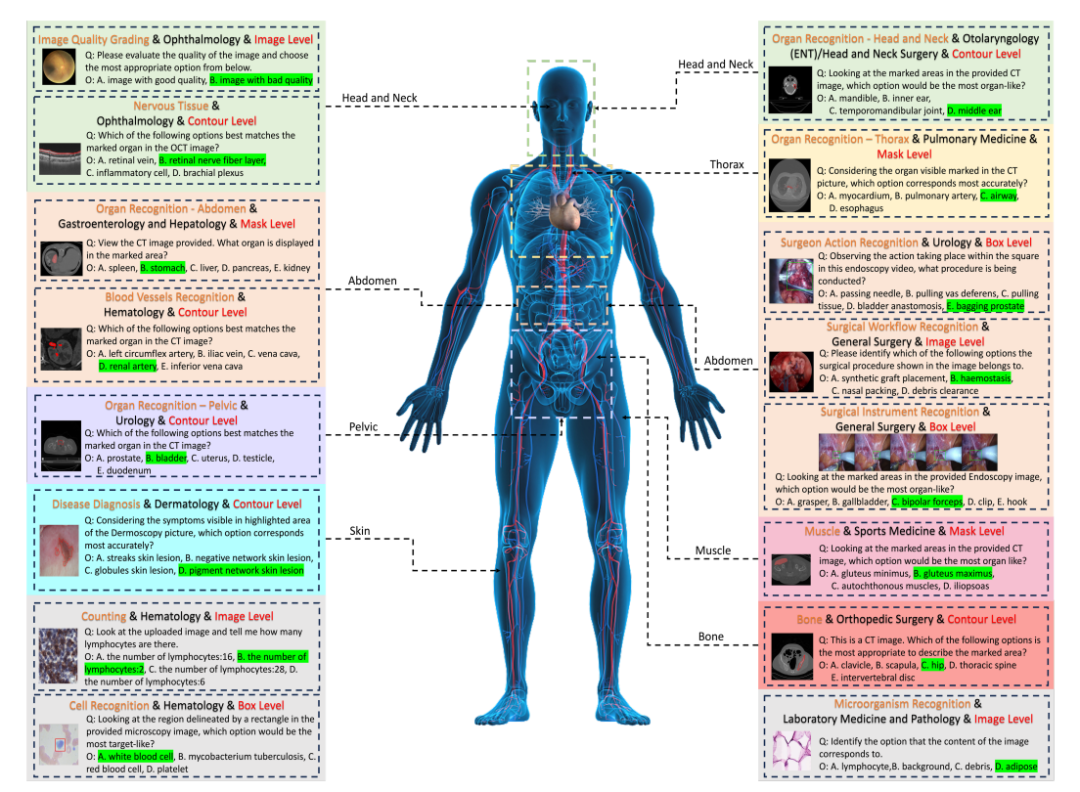
تم تقييم 50 نموذجًا، أي منها جاء في المقدمة في معيار GMAI-MMBench
من أجل تعزيز التطبيق السريري للذكاء الاصطناعي في المجال الطبي بشكل أكبر،قام الباحثون بتقييم 44 نموذجًا مفتوح المصدر من LVLM (بما في ذلك 38 نموذجًا عامًا و6 نماذج طبية محددة) ونماذج تجارية مغلقة المصدر من LVLM مثل GPT-4o وGPT-4V وClaude3-Opus وGemini 1.0 وGemini 1.5 وQwen-VL-Max على GMAI-MMBench.
وتظهر النتائج أنه لا تزال هناك خمسة نقائص رئيسية في LVLMs الحالية، على النحو التالي:
* لا يزال هناك مجال للتحسين في التطبيقات السريرية: حتى النموذج الأفضل أداءً، GPT-4o، قد استوفى متطلبات التطبيقات السريرية العملية، ولكن دقته تبلغ 53.96% فقط، مما يدل على أن أجهزة LVLM الحالية غير كافية للتعامل مع المشاكل المهنية الطبية ولا يزال هناك مجال كبير للتحسين.
* مقارنة النماذج مفتوحة المصدر مع النماذج التجارية: تتمتع نماذج LVLM مفتوحة المصدر مثل MedDr و DeepSeek-VL-7B بدقة تبلغ حوالي 44%، وهو ما يتفوق على النماذج التجارية Claude3-Opus و Qwen-VL-Max في بعض المهام، كما أن أدائها مماثل لأداء Gemini 1.5 و GPT-4V. ومع ذلك، لا تزال هناك فجوة كبيرة في الأداء مقارنةً بجهاز GPT-4o الأفضل أداءً.
* تواجه معظم النماذج الطبية المحددة صعوبة في الوصول إلى مستوى الأداء العام لـ LVLMs للأغراض العامة (دقة تبلغ حوالي 30%)، باستثناء MedDr، الذي يحقق دقة تبلغ 43.69%.
* يؤدي معظم LVLM أداءً غير متساوٍ عبر مهام VQA السريرية المختلفة والأقسام والحبيبات الإدراكية. على وجه الخصوص، في التجارب التي تحتوي على حبيبات إدراكية مختلفة، تكون دقة التعليقات التوضيحية على مستوى الصندوق دائمًا هي الأدنى، حتى أنها أقل من دقة التعليقات التوضيحية على مستوى الصورة.
* تشمل العوامل الرئيسية المؤدية إلى اختناقات الأداء أخطاء الإدراك (مثل تحديد محتوى الصورة بشكل خاطئ)، ونقص المعرفة بالمجال الطبي، ومحتوى الإجابة غير ذي الصلة، ورفض الإجابة على الأسئلة بسبب بروتوكولات الأمان.
باختصار، تشير نتائج التقييم هذه إلى أن أداء LVLMs الحالية في التطبيقات الطبية لا يزال لديه مجال كبير للتحسين ويحتاج إلى مزيد من التحسين لتلبية الاحتياجات السريرية الفعلية.
جمع مجموعات البيانات الطبية مفتوحة المصدر للمساعدة في تطوير الرعاية الصحية الذكية
في المجال الطبي، أصبحت مجموعات البيانات مفتوحة المصدر عالية الجودة قوة دافعة مهمة للتقدم في البحث الطبي والممارسة السريرية. ولتحقيق هذه الغاية، قامت HyperAI باختيار بعض مجموعات البيانات ذات الصلة بالطب لك، والتي نقدمها لك بإيجاز على النحو التالي:
مجموعة بيانات PubMedVision الطبية واسعة النطاق لتقييم جودة التعليم (VQA)
PubMedVision هي مجموعة بيانات طبية متعددة الوسائط عالية الجودة وواسعة النطاق تم إنشاؤها في عام 2024 بواسطة فريق بحثي من معهد أبحاث البيانات الضخمة في شنتشن، والجامعة الصينية في هونج كونج، والمعهد الوطني للبيانات الصحية، وتحتوي على 1.3 مليون عينة طبية من VQA.
ومن أجل تحسين محاذاة البيانات الرسومية والنصية، استخدم فريق البحث النموذج المرئي الكبير (GPT-4V) لإعادة وصف الصور وبناء الحوارات في 10 سيناريوهات، وإعادة كتابة البيانات الرسومية والنصية في شكل أسئلة وأجوبة، مما يعزز تعلم المعرفة البصرية الطبية.
الاستخدام المباشر:https://go.hyper.ai/ewHNg
مجموعة MMedC الطبية متعددة اللغات واسعة النطاق
MMedC هو مجموعة طبية متعددة اللغات تم إنشاؤها بواسطة فريق الرعاية الصحية الذكية في كلية الذكاء الاصطناعي بجامعة شنغهاي جياو تونغ في عام 2024. تحتوي على ما يقرب من 25.5 مليار رمز تغطي 6 لغات رئيسية: الإنجليزية والصينية واليابانية والفرنسية والروسية والإسبانية.
كما قام فريق البحث أيضًا بفتح المصدر للنموذج الطبي متعدد اللغات MMed-Llama 3، والذي أظهر أداءً استثنائيًا في العديد من المعايير، متفوقًا بشكل كبير على النماذج مفتوحة المصدر الحالية وهو مناسب بشكل خاص للضبط الدقيق المخصص في القطاع الطبي.
الاستخدام المباشر:https://go.hyper.ai/xpgdM
مجموعة بيانات الحوسبة الطبية MedCalc-Bench
MedCalc-Bench عبارة عن مجموعة بيانات مصممة خصيصًا لتقييم قدرات الحوسبة الطبية للنماذج اللغوية الكبيرة (LLMs). تم إصداره بشكل مشترك في عام 2024 من قبل تسع مؤسسات بما في ذلك المكتبة الوطنية للطب التابعة للمعاهد الوطنية للصحة وجامعة فيرجينيا. تحتوي مجموعة البيانات هذه على 10,055 حالة تدريب و1,047 حالة اختبار، تغطي 55 مهمة حوسبة مختلفة.
الاستخدام المباشر:https://go.hyper.ai/XHitC
مجموعة بيانات تقييم OmniMedVQA الطبية واسعة النطاق
OmniMedVQA هي مجموعة بيانات تقييمية واسعة النطاق للإجابة على الأسئلة المرئية (VQA) تركز على المجال الطبي. تم إطلاق هذه المجموعة من البيانات بشكل مشترك من قبل جامعة هونغ كونغ ومختبر الذكاء الاصطناعي في شنغهاي في عام 2024. تحتوي على 118010 صورة مختلفة، تغطي 12 طريقة مختلفة، وتشمل أكثر من 20 عضوًا وجزءًا مختلفًا من جسم الإنسان، وجميع الصور من مشاهد طبية حقيقية. ويهدف إلى توفير معيار تقييم لتطوير نماذج طبية متعددة الوسائط كبيرة الحجم.
الاستخدام المباشر:https://go.hyper.ai/1tvEH
مجموعة بيانات الصور الطبية MedMNIST
تم إصدار MedMNIST من قبل جامعة شنغهاي جياو تونغ في 28 أكتوبر 2020. وهي عبارة عن مجموعة من 10 مجموعات بيانات طبية عامة، تحتوي على ما مجموعه 450000 صورة طبية متعددة الوسائط 28 * 28، تغطي أوضاع بيانات مختلفة، والتي يمكن استخدامها لحل المشكلات المتعلقة بتحليل الصور الطبية.
الاستخدام المباشر:https://go.hyper.ai/aq7Lp
ما ورد أعلاه هو مجموعات البيانات التي أوصت بها HyperAI في هذا العدد. إذا رأيت مصادر بيانات عالية الجودة، فنحن نرحب بك لترك رسالة أو إرسال مقال لإخبارنا بذلك!
مزيد من مجموعات البيانات عالية الجودة للتنزيل:https://go.hyper.ai/jJTaU
مراجع:
https://mp.weixin.qq.com/s/vMWNQ-sIABocgScnrMW0GA









