Command Palette
Search for a command to run...
6 مجموعات بيانات كلاسيكية للتعلم الآلي، تم التصويت عليها من قبل أكثر من 3 مستخدمين، يوصى بجمعها

نظرة عامة على المحتوى: يلخص هذا العدد 6 مجموعات بيانات تحتوي على أكبر عدد من التنزيلات العصبية الفائقة، والتي تغطي مجالات مثل التعرف على الصور، والترجمة الآلية، والتصوير الاستشعاري عن بعد. تتمتع هذه المجموعات من البيانات بجودة عالية وحجم كبير، وهي تستحق التجميع والاحتفاظ بها نظرًا لشهادة شعبيتها. الكلمات المفتاحية: مجموعة البيانات، الترجمة الآلية، الرؤية الآلية
تشكل مجموعات البيانات الأساس لتدريب نموذج التعلم الآلي. تتمتع مجموعات البيانات العامة عالية الجودة بأهمية كبيرة في نمذجة تأثيرات التدريب وموثوقية نتائج البحث.
منذ إطلاقه، قدم HyperAI عددًا كبيرًا من مجموعات البيانات العامة عالية الجودة لممارسي علوم البيانات.في هذا العدد، قمنا باختيار 6 مجموعات بيانات شائعة.لقد تم تنزيله 32,569 مرة في المجموع.آمل أن تتمكن مجموعات البيانات هذه من خدمة المطورين بشكل أكبر~
ملحوظة: مجموعات البيانات الموضحة في هذه المقالة كلها من الموقع الإلكتروني:
رقم 6: مجموعة بيانات إعادة بناء معبد الدبابات ثلاثية الأبعاد
وكالة النشر:مختبرات إنتل
الكمية المتضمنة:فيديو عالي الدقة لـ 21 نوعًا من الكائنات
نوع البيانات:فيديو
الحجم المقدر:52.53 جيجابايت
وقت الإصدار:2017
عنوان التنزيل:hyper.ai/datasets/5148

توفر مجموعة بيانات صور معبد الدبابات مقاطع فيديو عالية الدقة يمكن للباحثين جمع الصور منها.قم بإجراء إعادة بناء ثلاثية الأبعاد بناءً على الصورة.تتضمن مجموعة البيانات فئتين: بيانات التدريب وبيانات الاختبار، حيث يتم تقسيم بيانات الاختبار إلى مجموعة متوسطة ومجموعة متقدمة.
رقم 5: مجموعة بيانات الصور الجوية للعبة DOTA
وكالة النشر:جامعة ووهان
الكمية المتضمنة:2,806 صورة جوية
نوع البيانات:الصور
الحجم المقدر:35.38 جيجابايت
وقت الإصدار:2017
عنوان التنزيل:hyper.ai/datasets/4920

DOTA تعني مجموعة بيانات واسعة النطاق لاكتشاف الكائنات في الصور الجوية. إنها مجموعة بيانات صور تحتوي على 2,806 صورة جوية.يتم استخدامه لاكتشاف الهدف في الصور الجوية للعثور على الكائنات في الصورة وتقييمها.
تتضمن مصادر الصور هذه أجهزة استشعار ومنصات مختلفة. يتراوح حجم البكسل لكل صورة من 800*800 إلى 4000*4000، وتحتوي على كائنات بمقاييس واتجاهات وأشكال مختلفة.
للاطلاع على الإصدارات السابقة، يرجى زيارة:
مجموعة بيانات DOTA: 2,806 صورة استشعار عن بعد، وما يقرب من 190,000 حالة مُعلّق عليها
رقم 4: مجموعة بيانات التعرف على الوجه VGG-Face2
وكالة النشر:جامعة أكسفورد
الكمية المتضمنة:3.31 مليون صورة
نوع البيانات:الصور
الحجم المقدر:37.49 جيجابايت
وقت الإصدار:2015
عنوان التنزيل:hyper.ai/datasets/5711

VGG-Face2 هي مجموعة بيانات لصور الوجه تحتوي على بيانات وجوه 9131 شخصًا في المجموع. الصور كلها من بحث الصور في جوجل.يختلف الأشخاص في مجموعة البيانات بشكل كبير من حيث الوضعية والعمر والعرق والمهنة.تم إصدار هذه المجموعة من البيانات من قبل مجموعة الهندسة البصرية التابعة لقسم علوم الهندسة في جامعة أكسفورد في عام 2015، والورقة ذات الصلة هي "التعرف العميق على الوجوه".
رقم 3: مجموعة بيانات صور الاستشعار عن بُعد UCAS-AOD
وكالة النشر:جامعة الأكاديمية الصينية للعلوم
الكمية المتضمنة:910 صورة
نوع البيانات:الصور
الحجم المقدر:3.24 جيجابايت
وقت الإصدار:2014
عنوان التنزيل:hyper.ai/datasets/5419

UCAS-AOD هي مجموعة بيانات صور الاستشعار عن بعد.لفحص الطائرات والمركبات.صدرت هذه المجموعة من البيانات لأول مرة عن جامعة العلوم والتكنولوجيا الصينية عام ٢٠١٤، وأُضيفت إليها إضافات عام ٢٠١٥. تتضمن الأوراق البحثية ذات الصلة "الكشف الدقيق عن الأجسام بالاتجاه في الصور الجوية باستخدام الشبكة العصبية التلافيفية العميقة".
رقم 2: مجموعة بيانات الترجمة الآلية للقصص المصورة OpenMantra
وكالة النشر:جامعة طوكيو
الكمية المتضمنة:214 صفحة من القصص المصورة
نوع البيانات:ملفات JSON والصور
الحجم المقدر:32.46 ميجابايت
وقت الإصدار:2020
عنوان التنزيل:hyper.ai/datasets/14137
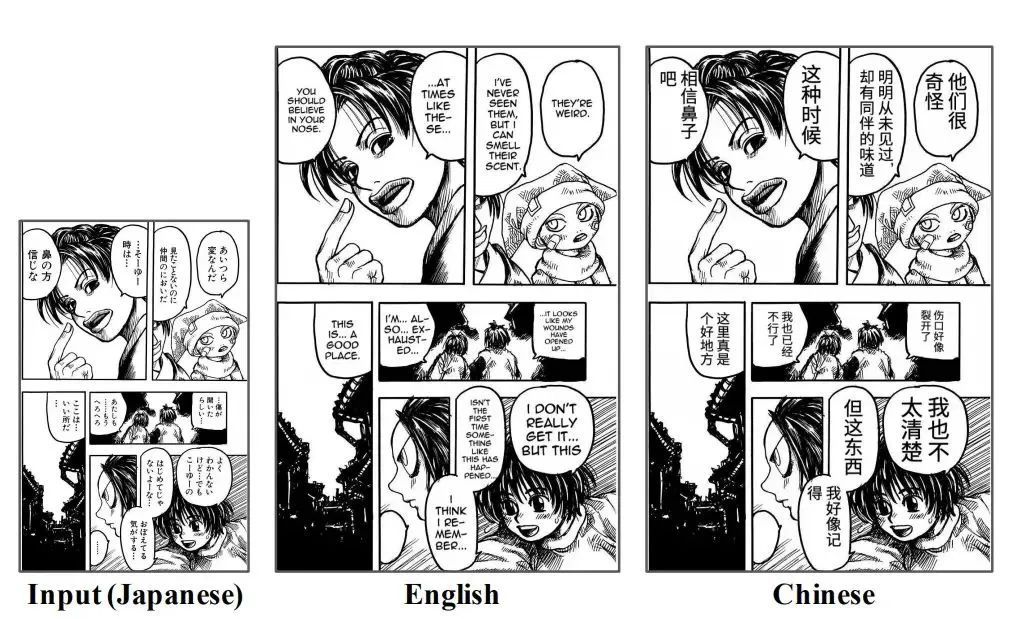
OpenMantra هي مجموعة بيانات لتقييم الترجمة الآلية للقصص المصورة اليابانية، تحتوي على قصص مصورة بخمسة أنماط مختلفة (خيالية، رومانسية، قتالية، غامضة، شريحة من الحياة).تحتوي مجموعة البيانات على 1593 جملة و 848 مشهدًا و 214 صفحة من القصص المصورة.تم نشره بواسطة فريق مانترا، جامعة طوكيو.
بالنسبة للدفعات السابقة، يرجى الاطلاع على:
HyperAI: ترجمة القصص المصورة، الذكاء الاصطناعي المُضمّن للكلمات، ورقة بحثية من جامعة طوكيو مُدرجة في AAAI'21 (٣ إعجابات · تعليق واحد)
رقم 1: مجموعة بيانات التعرف على الصور ImageNet 10
وكالة النشر:جامعة برينستون
الكمية المتضمنة:15 مليون صورة
نوع البيانات:الصور
الحجم المقدر:860.55 جيجابايت
وقت الإصدار:2009
عنوان التنزيل:hyper.ai/datasets/4889

ImageNet هي حاليًا أكبر قاعدة بيانات للتعرف على الصور في العالم، تم إنشاؤها على يد أستاذ جامعة ستانفورد Fei-Fei Li وآخرين.يتم استخدامه بشكل أساسي لتصنيف الصور واكتشاف الهدف في مجال الرؤية الآلية.
يتم تنظيم مجموعة البيانات وفقًا لتسلسل WordNet، حيث تتكون كل عقدة (وتسمى أيضًا الفئة) من مئات أو حتى آلاف الصور. تحتوي مجموعة البيانات على إجمالي 22000 فئة صورة وحوالي 15 مليون صورة.
للاطلاع على الإصدارات السابقة، يرجى زيارة:
جعل هذا القرار من في في لي ملكة صناعة الذكاء الاصطناعيmp.weixin.qq.com/s/VyKUmG512pFJ3XTgVf4Qjg
ما ورد أعلاه هو مجموعات البيانات الستة التي يتم تنزيلها بشكل متكرر من hyper.ai والتي يوصى بها في هذا العدد. لمزيد من مجموعات البيانات العامة عالية الجودة لعلم البيانات، انقر في نهاية المقالة.اقرأ المقال الأصلي،أو قم بزيارة الرابط التالي للتحميل:
نُشرت هذه المقالة لأول مرة على حساب WeChat العام "HyperAI Super Neural Network"6 مجموعات بيانات كلاسيكية للتعلم الآلي، تم التصويت عليها من قبل أكثر من 3 مستخدمين، يوصى بجمعها』
-- زيادة--








