Command Palette
Search for a command to run...
مجموعة من الموارد حول الذكاء المجسد: مجموعات بيانات تعلم الروبوتات، والتجربة عبر الإنترنت لنماذج نمذجة العالم، وأحدث الأوراق البحثية من NVIDIA وByteDance وXiaomi وغيرها.

إذا كانت ساحة المعركة الرئيسية للذكاء الاصطناعي على مدى العقد الماضي هي "فهم العالم" و"توليد المحتوى"، فإن القضية الأساسية للمرحلة التالية تتحول إلى اقتراح أكثر تحديًا:كيف يمكن للذكاء الاصطناعي أن يدخل العالم المادي حقاً ويتصرف ويتعلم ويتطور داخله؟وقد ظهر مصطلح "الذكاء المتجسد" بشكل متكرر في الأبحاث والمناقشات ذات الصلة.
كما يوحي الاسم، فإن الذكاء المجسد ليس روبوتًا تقليديًا.بدلاً من ذلك، يؤكد هذا المفهوم على أن الذكاء يتشكل من خلال التفاعل بين الكائن الحي والبيئة في حلقة مغلقة من الإدراك واتخاذ القرار والفعل.من هذا المنظور، لم يعد الذكاء يقتصر على معايير النموذج أو قدرات الاستدلال، بل أصبح متأصلاً بعمق في أجهزة الاستشعار، والمحركات، والتغذية الراجعة البيئية، والتعلم طويل الأمد. وتشمل هذه الإطار مناقشات حول الروبوتات، والقيادة الذاتية، والوكلاء، وحتى الذكاء الاصطناعي العام.
لهذا السبب، أصبح الذكاء المجسد محور اهتمام عمالقة التكنولوجيا العالميين وأبرز المؤسسات البحثية خلال العامين الماضيين. وقد أكد إيلون ماسك، الرئيس التنفيذي لشركة تسلا، مرارًا وتكرارًا على أن الروبوت البشري أوبتيموس لا يقل أهمية عن القيادة الذاتية؛ ويعتبر جنسن هوانغ، مؤسس شركة إنفيديا، الذكاء الاصطناعي الفيزيائي الموجة التالية للذكاء الاصطناعي التوليدي، ويواصل استثماره بكثافة في منصات محاكاة وتدريب الروبوتات؛ ويواصل كل من فاي فاي لي، ويان ليكان، وغيرهما، إنتاج تحليلات ونتائج متطورة وعالية الجودة في مجالات فرعية مثل الذكاء المكاني ونماذج العالم؛ كما تستكشف شركات OpenAI وGoogle DeepMind وMeta قدرات التعلم لدى الأنظمة الذكية في بيئات حقيقية أو شبه حقيقية، بالاعتماد على تقنيات مثل النماذج متعددة الوسائط والتعلم المعزز.
في هذا السياق، لم يعد الذكاء المتجسد مجرد مشكلة تتعلق بنماذج أو خوارزميات منفردة، بل تطور تدريجياً ليصبح منظومة بحثية متكاملة تضم مجموعات بيانات، وبيئات محاكاة، ومهام قياس الأداء، وأساليب منهجية. ولمساعدة المزيد من القراء على فهم المحاور الرئيسية لهذا المجال بسرعة،ستقوم هذه المقالة بتنظيم وتوصية مجموعة من مجموعات البيانات عالية الجودة، والدروس التعليمية عبر الإنترنت، والأوراق البحثية المتعلقة بالذكاء المجسد، مما يوفر مرجعًا لمزيد من التعلم والبحث.
توصية بمجموعة البيانات
1. مجموعة بيانات تعلم الروبوت BC-Z
الحجم المقدر:32.28 جيجابايت
عنوان التنزيل:https://go.hyper.ai/vkRel

هذه مجموعة بيانات واسعة النطاق لتعلم الروبوتات، طُوّرت بالتعاون بين جوجل، وإيفري داي روبوتس، وجامعة كاليفورنيا في بيركلي، وجامعة ستانفورد. تحتوي على أكثر من 25,877 سيناريو تشغيل مختلف، تغطي 100 مهمة تشغيلية متنوعة. جُمعت هذه المهام من خلال عمليات تشغيل عن بُعد على مستوى الخبراء وعمليات تشغيل ذاتية مشتركة، بمشاركة 12 روبوتًا و7 مشغلين مختلفين، بإجمالي 125 ساعة تشغيل للروبوتات. تدعم مجموعة البيانات تدريب سياسة متعددة المهام بسبع درجات حرية، قابلة للتعديل بناءً على الوصف اللفظي للمهمة أو مقاطع فيديو لتشغيلها من قِبل البشر، وذلك لأداء مهام تشغيلية محددة.
2.مجموعة بيانات DexGraspVLA Robot Grasping
الحجم المقدر:7.29 جيجابايت
عنوان التنزيل:https://go.hyper.ai/G37zQ

تحتوي مجموعة البيانات هذه، التي أنشأها فريق Psi-Robot، على 51 عينة بيانات توضيحية بشرية لفهم البيانات وتنسيقها، ولتشغيل الكود وتجربة عملية التدريب. ينبع هذا البحث من الحاجة إلى معدلات نجاح عالية في الإمساك السريع في المشاهد المزدحمة، ولا سيما تحقيق معدل نجاح يتجاوز 901 TP3T في ظل وجود مزيج من الأشياء غير المرئية والإضاءة والخلفيات. يستخدم هذا الإطار نموذجًا مُدرَّبًا مسبقًا للغة المرئية كمخطط مهام عالي المستوى، ويتعلم سياسة قائمة على الانتشار كوحدة تحكم في الحركة منخفضة المستوى. تكمن ابتكاراته في الاستفادة من النموذج الأساسي لتحقيق قدرات تعميم قوية، واستخدام التعلم بالتقليد القائم على الانتشار لاكتساب حركات سريعة.
3.EgoThink: مجموعة بيانات مرجعية للإجابة على الأسئلة المرئية من منظور الشخص الأول
الحجم المقدر:865.29 ميجابايت
عنوان التنزيل:https://go.hyper.ai/5PsDP

تُعدّ مجموعة البيانات هذه، التي اقترحتها جامعة تسينغهوا، معيارًا مرجعيًا للإجابة على الأسئلة المرئية من منظور الشخص الأول، وتحتوي على 700 صورة تغطي 6 قدرات أساسية، مُقسّمة إلى 12 بُعدًا. وقد جُمعت الصور من مجموعة بيانات الفيديو Ego4D من منظور الشخص الأول؛ ولضمان تنوّع البيانات، تمّ اختيار صورتين كحد أقصى من كل فيديو. وخلال عملية بناء مجموعة البيانات، تمّ اختيار الصور عالية الجودة فقط التي تُظهر بوضوح التفكير من منظور الشخص الأول. تتمتع EgoThink بتطبيقات واسعة، لا سيما في تقييم وتحسين أداء نماذج التعلّم المرئي (VLMs) في مهام منظور الشخص الأول، مما يُوفّر موارد قيّمة لأبحاث الذكاء الاصطناعي والروبوتات المُجسّدة في المستقبل.
4.مجموعة بيانات الإجابة على أسئلة EQA
الحجم المقدر:839.6 كيلوبايت
عنوان التنزيل:https://go.hyper.ai/8Uv1o
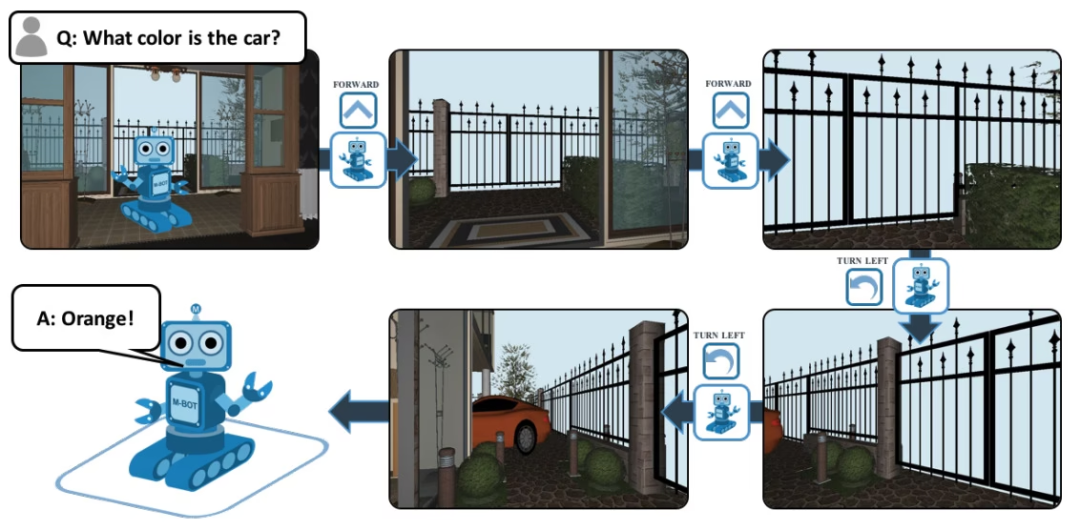
EQA، واسمها الكامل هو Embodied Question Answering، وهي عبارة عن مجموعة بيانات للإجابة على الأسئلة المرئية تعتمد على House3D. بعد تلقي سؤال، يمكن للوكيل في أي مكان في البيئة العثور على معلومات مفيدة في البيئة والإجابة على السؤال. على سبيل المثال: س: ما لون السيارة؟ للإجابة على هذا السؤال، يجب على العميل أولاً استكشاف البيئة من خلال الملاحة الذكية، وجمع المعلومات البصرية اللازمة من منظور الشخص الأول، ثم الإجابة على السؤال: البرتقالي.
5. أومني ريتارجت جلوبال روبوت
مجموعة بيانات إعادة رسم الحركة
الحجم المقدر:349.61 ميجابايت
عنوان التنزيل:https://go.hyper.ai/IloBI

هذه مجموعة بيانات عالية الجودة لتتبع مسارات حركة الروبوتات الشبيهة بالبشر، تم إصدارها من قبل أمازون بالتعاون مع معهد ماساتشوستس للتكنولوجيا وجامعة كاليفورنيا في بيركلي ومؤسسات أخرى. تحتوي على مسارات حركة الروبوت الشبيه بالبشر G1 أثناء تفاعله مع الأجسام والتضاريس المعقدة، وتغطي ثلاثة سيناريوهات: حمل الروبوت للأجسام، والمشي على التضاريس، والتفاعل الهجين بين الأجسام والتضاريس. نظرًا لقيود الترخيص، لا تتضمن مجموعة البيانات المتاحة للجمهور نسخة مُعاد رسم مساراتها من LAFAN1. وهي مقسمة إلى ثلاث مجموعات فرعية، يبلغ مجموعها حوالي 4 ساعات من بيانات مسارات الحركة، كما يلي:
* الروبوت-الكائن: مسار الكائن الذي يحمله الروبوت، مستمد من بيانات OMOMO 3.0؛
* تضاريس الروبوت: مسار حركة الروبوت على التضاريس المعقدة، والذي تم إنشاؤه بواسطة جمع بيانات MoCap الداخلية، ويستغرق حوالي 0.5 ساعة؛
* الروبوت-الجسم-التضاريس: يتضمن هذا مسار حركة جسم يتفاعل مع التضاريس، ويستمر لمدة 0.5 ساعة تقريبًا.
بالإضافة إلى ذلك، تحتوي مجموعة البيانات أيضًا على دليل نماذج، والذي يوفر ملفات نماذج مرئية بتنسيقات URDF وSDF وOBJ للعرض بدلاً من التدريب.
عرض المزيد من مجموعات البيانات عالية الجودة:https://hyper.ai/datasets
توصيات الدروس التعليمية
غالبًا ما تتضمن الأبحاث في مجال الذكاء الاصطناعي المجسد دمج نماذج ووحدات متعددة لتحقيق الإدراك والفهم والتخطيط والتصرف في العالم المادي. وتشمل هذه النماذج نماذج العالم ونماذج الاستدلال. وتوصي هذه المقالة بشكل أساسي بأحدث نموذجين مفتوحي المصدر.
شاهد المزيد من الدروس التعليمية عالية الجودة:https://hyper.ai/notebooks
1.HY-World 1.5: إطار عمل لنظام نمذجة العالم التفاعلي
يُعدّ HY-World 1.5 (WorldPlay) أول نموذج تفاعلي مفتوح المصدر للعالم في الوقت الفعلي، يتميز بتناسق هندسي طويل الأمد، وقد أصدره فريق Hunyuan التابع لشركة Tencent. يحقق هذا النموذج نمذجة تفاعلية للعالم في الوقت الفعلي من خلال تقنية بث الفيديو، ما يحل المفاضلة بين السرعة والذاكرة في الطرق الحالية.
تشغيل عبر الإنترنت:https://go.hyper.ai/qsJVe
2.نشر vLLM+Open WebUI نيموترون-3 نانو
يُعدّ Nemotron-3-Nano-30B-A3B-BF16 نموذجًا لغويًا واسع النطاق (LLM) تم تدريبه من الصفر بواسطة NVIDIA. وهو مصمم كنموذج موحد قابل للتطبيق على كل من مهام الاستدلال والمهام غير الاستدلالية، ويُستخدم بشكل أساسي لبناء أنظمة وكلاء الذكاء الاصطناعي، وبرامج الدردشة الآلية، وأنظمة RAG (التوليد المعزز بالاسترجاع)، وغيرها من تطبيقات الذكاء الاصطناعي المتنوعة.
تشغيل عبر الإنترنت:https://go.hyper.ai/6SK6n
توصية الورقة
- RBench
عنوان الأطروحة:إعادة التفكير في نموذج إنتاج الفيديو للعالم المجسد
فريق البحث:جامعة بكين، بايت دانس سيد
عرض الورقة:https://go.hyper.ai/k1oMT
ملخص البحث:
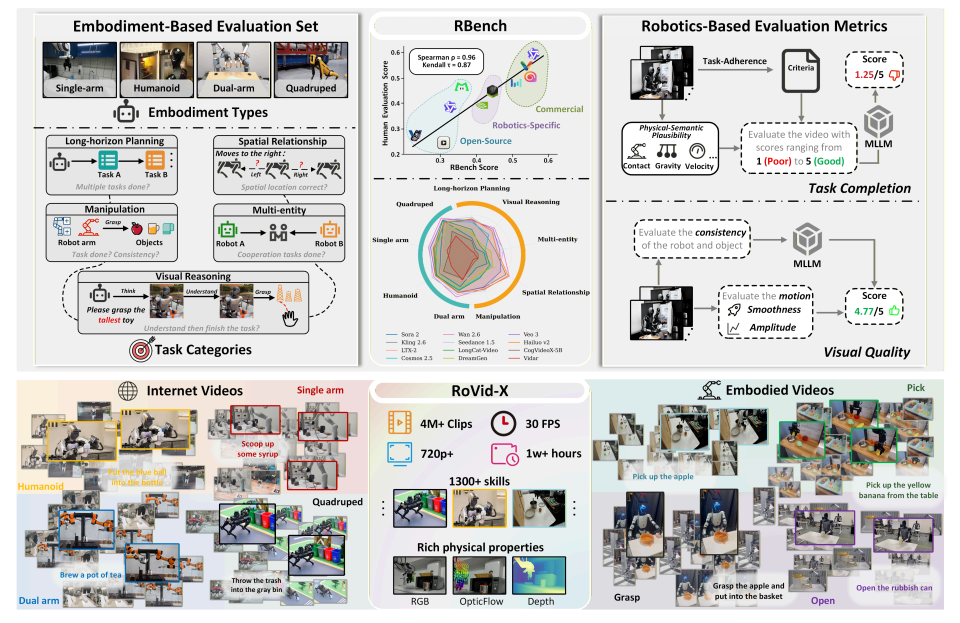
اقترح الفريق معيارًا شاملًا لتوليد فيديوهات الروبوتات، أطلق عليه اسم RBench، يغطي خمسة مجالات مهام وأربعة أشكال مختلفة للروبوتات. يقيم المعيار توليد فيديوهات الروبوتات من بُعدين: دقة المهمة ووضوح الصورة، باستخدام سلسلة من المؤشرات الفرعية القابلة للتكرار، وتحديدًا التناسق الهيكلي، والمعقولية الفيزيائية، واكتمال الحركة. تُظهر نتائج التقييم على 25 نموذجًا تمثيليًا لتوليد الفيديوهات أن الطرق الحالية لا تزال تعاني من قصور كبير في توليد سلوكيات روبوتية واقعية فيزيائيًا. علاوة على ذلك، بلغ معامل ارتباط سبيرمان بين RBench والتقييم البشري 0.96، مما يؤكد فعالية المعيار في قياس جودة النموذج.
بالإضافة إلى ذلك، قامت الدراسة أيضًا ببناء RoVid-X - وهي أكبر مجموعة بيانات مفتوحة المصدر لتوليد فيديوهات الروبوت حتى الآن، وتحتوي على 4 ملايين مقطع فيديو مشروح تغطي آلاف المهام، بالإضافة إلى شروح شاملة للسمات الفيزيائية.
2. الفصل H0.5
عنوان الورقة:Being-H0.5: توسيع نطاق تعلم الروبوت المتمحور حول الإنسان من أجل التعميم عبر التجسيدات
فريق البحث:الوجود ما وراء
عرض الورقة:https://go.hyper.ai/pW24B
ملخص البحث:
اقترح الفريق نموذجًا أساسيًا للرؤية واللغة والحركة (VLA)، أطلق عليه اسم Being-H0.5، مصممًا لتحقيق قدرات تعميم وتجسيد قوية عبر منصات روبوتية متعددة. غالبًا ما تعاني نماذج VLA الحالية من قيودٍ مثل الاختلافات الكبيرة في شكل الروبوتات وندرة البيانات المتاحة. ولمعالجة هذا التحدي، اقترح الفريق نموذجًا تعليميًا يتمحور حول الإنسان، حيث تُعامل مسارات التفاعل البشري كلغةٍ أم عالمية في مجال التفاعل الجسدي.
في الوقت نفسه، أصدر الفريق أيضًا UniHand-2.0، وهو أحد أكبر حلول التدريب المسبق المجسد حتى الآن، ويشمل أكثر من 35000 ساعة من البيانات متعددة الوسائط عبر 30 شكلًا مختلفًا من الروبوتات. وعلى المستوى المنهجي، اقترحوا فضاء عمل موحدًا، يربط أساليب التحكم غير المتجانسة للروبوتات المختلفة بفتحات عمل متوافقة دلاليًا، مما يُمكّن الروبوتات ذات الموارد المحدودة من نقل المهارات وتعلمها بسرعة من البيانات البشرية والمنصات ذات الموارد العالية.

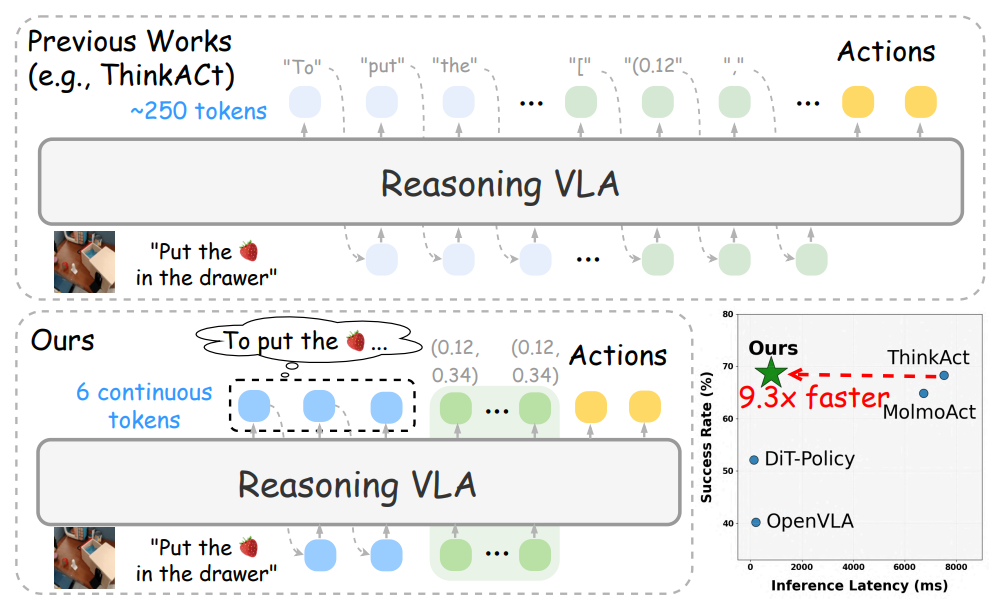
3. التفكير السريع والتصرف
عنوان الورقة:التفكير السريع والتصرف: استدلال فعال قائم على الرؤية واللغة والفعل من خلال التخطيط الكامن القابل للتعبير عنه لفظيًا
فريق البحث:نفيديا
عرض الورقة:https://go.hyper.ai/q1h7j
ملخص البحث:
اقترح الفريق إطار عمل استدلالي فعال، يُدعى "التفكير السريع والتنفيذ"، يحقق عملية تخطيط أكثر إيجازًا مع الحفاظ على الأداء من خلال آلية استدلال لغوية كامنة. يتعلم "التفكير السريع والتنفيذ" قدرات استدلالية فعالة من خلال استخلاص أنماط التفكير الكامنة من نماذج المعلم، ويُنسق مسارات العمليات وفقًا لدالة هدف موجهة بالتفضيلات، وبالتالي ينقل قدرات التخطيط اللغوية والبصرية إلى التحكم المجسد.
تُظهر النتائج التجريبية الواسعة التي تغطي مختلف العمليات المجسدة ومهام الاستدلال أن Fast-ThinkAct، مع الحفاظ على قدرات التخطيط على المدى الطويل، والقدرة على التكيف مع عدد قليل من العينات، وقدرات استعادة الفشل، يحقق تحسنًا كبيرًا في الأداء عن طريق تقليل زمن استجابة الاستدلال بما يصل إلى 89.31 TP3T مقارنة بأحدث نماذج VLA القائمة على الاستدلال.
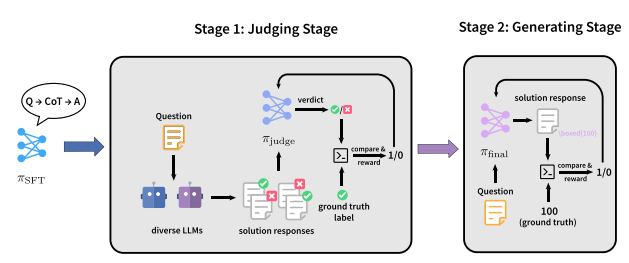
4. JudgeRLVR
عنوان الورقة:JudgeRLVR: قيّم أولاً، ثم أنشئ ثانياً من أجل استدلال فعال
فريق البحث:جامعة بكين، شركة شاومي
عرض الورقة:https://go.hyper.ai/2yCxp
ملخص البحث:
اقترح الفريق نموذج تدريب ثنائي المراحل، يُسمى JudgeRLVR، يتضمن "التمييز أولاً ثم التوليد". في المرحلة الأولى، يُدرّب الفريق نموذجًا للتمييز بين استجابات حل المشكلات وتقييمها بإجابات قابلة للتحقق. في المرحلة الثانية، يُضبط النموذج نفسه بدقة باستخدام RLVR التوليدي القياسي، مع استخدام نموذج التمييز كنموذج أولي.
بالمقارنة مع Vanilla RLVR، الذي يستخدم على بيانات التدريب في نفس المجال الرياضي، يحقق JudgeRLVR توازنًا أفضل بين الجودة والكفاءة على Qwen3-30B-A3B: في المهام الرياضية داخل المجال، تم تحسين متوسط الدقة بحوالي 3.7 نقطة مئوية بينما تم تقليل متوسط طول التوليد بمقدار 42%؛ في المعايير خارج المجال، تم تحسين متوسط الدقة بحوالي 4.5 نقطة مئوية، مما يدل على قدرة تعميم أقوى.
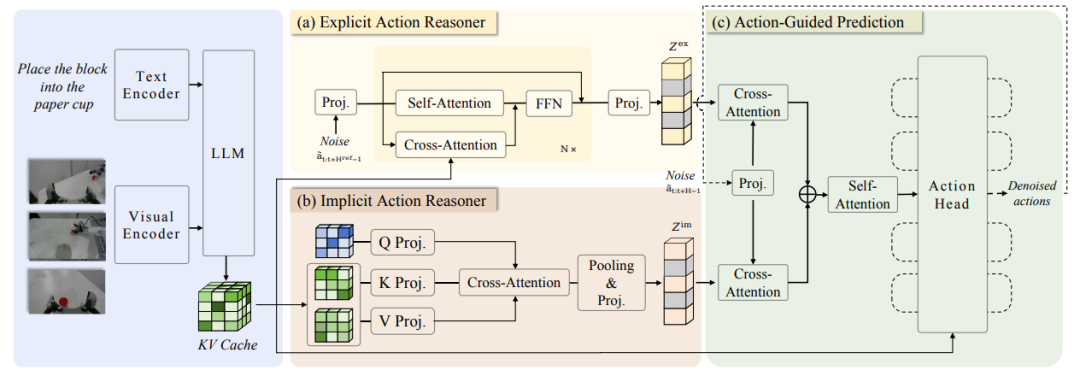
5. ACoT-VLA
عنوان الورقة:ACoT-VLA: سلسلة أفكار العمل لنماذج الرؤية واللغة والعمل
فريق البحث:جامعة بكين للملاحة الجوية والفضائية، أجيبوت
عرض الورقة:https://go.hyper.ai/2jMmY
ملخص البحث:
اقترح الفريق في البداية نموذج سلسلة الأفكار الإجرائية (ACoT)، الذي يُصوّر عملية التفكير نفسها كسلسلة من نوايا العمل المنظمة والواسعة النطاق لتوجيه عملية توليد السياسة النهائية. ثم اقترحوا لاحقًا نموذج ACoT-VLA، وهو نموذج معماري جديد يُجسّد نموذج ACoT.
يُقدّم هذا النظام، بتصميمه الخاص، مُكوّنين أساسيين مُتكاملين: مُستدلّ الفعل الصريح (EAR) ومُستدلّ الفعل الضمني (IAR). يقترح مُستدلّ الفعل الصريح مسارًا مرجعيًا عامًا على شكل خطوات استدلال صريحة على مستوى الفعل، بينما يستخلص مُستدلّ الفعل الضمني معلومات مسبقة كامنة عن الفعل من التمثيلات الداخلية للمدخلات متعددة الوسائط. يُشكّل هذان المُكوّنان معًا نموذج ACoT، ويعملان كمدخلات شرطية لرأس الفعل اللاحق، مما يُحقق تعلّم السياسة مع مراعاة قيود التنفيذ.
تُظهر النتائج التجريبية الواسعة في كل من بيئات العالم الحقيقي والمحاكاة المزايا الكبيرة لهذه الطريقة، حيث حققت درجات 98.51 TP3T و 84.11 TP3T و 47.41 TP3T على معايير LIBERO و LIBEROPlus و VLABench على التوالي.
اطلع على أحدث الأوراق البحثية:https://hyper.ai/papers








