HyperAI
Command Palette
Search for a command to run...
MMaDA: マルチモーダル大規模拡散言語モデル
1. チュートリアルの概要

MMaDA-8B-Baseは、プリンストン大学、ByteDanceシードチーム、北京大学、清華大学が共同で開発し、2025年5月23日にリリースされたマルチモーダル拡散ベースの大規模言語モデルです。このモデルは、マルチモーダル学習の基本パラダイムとして拡散アーキテクチャを体系的に探求した初の統合モデルであり、テキスト推論、マルチモーダル理解、画像生成の深い融合を通じて、モーダルタスク全体にわたる汎用的なインテリジェント機能の実現を目指しています。関連研究論文も公開されています。 MMaDA: マルチモーダル大規模拡散言語モデル 。
このチュートリアルのコンピューティングリソースには、A6000カード1枚を使用し、MMaDA-8B-Baseモデルをデプロイします。テスト用に、テキスト生成、マルチモーダル理解、テキスト画像生成の3つの例が用意されています。
2. 操作手順
1. コンテナを起動します
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
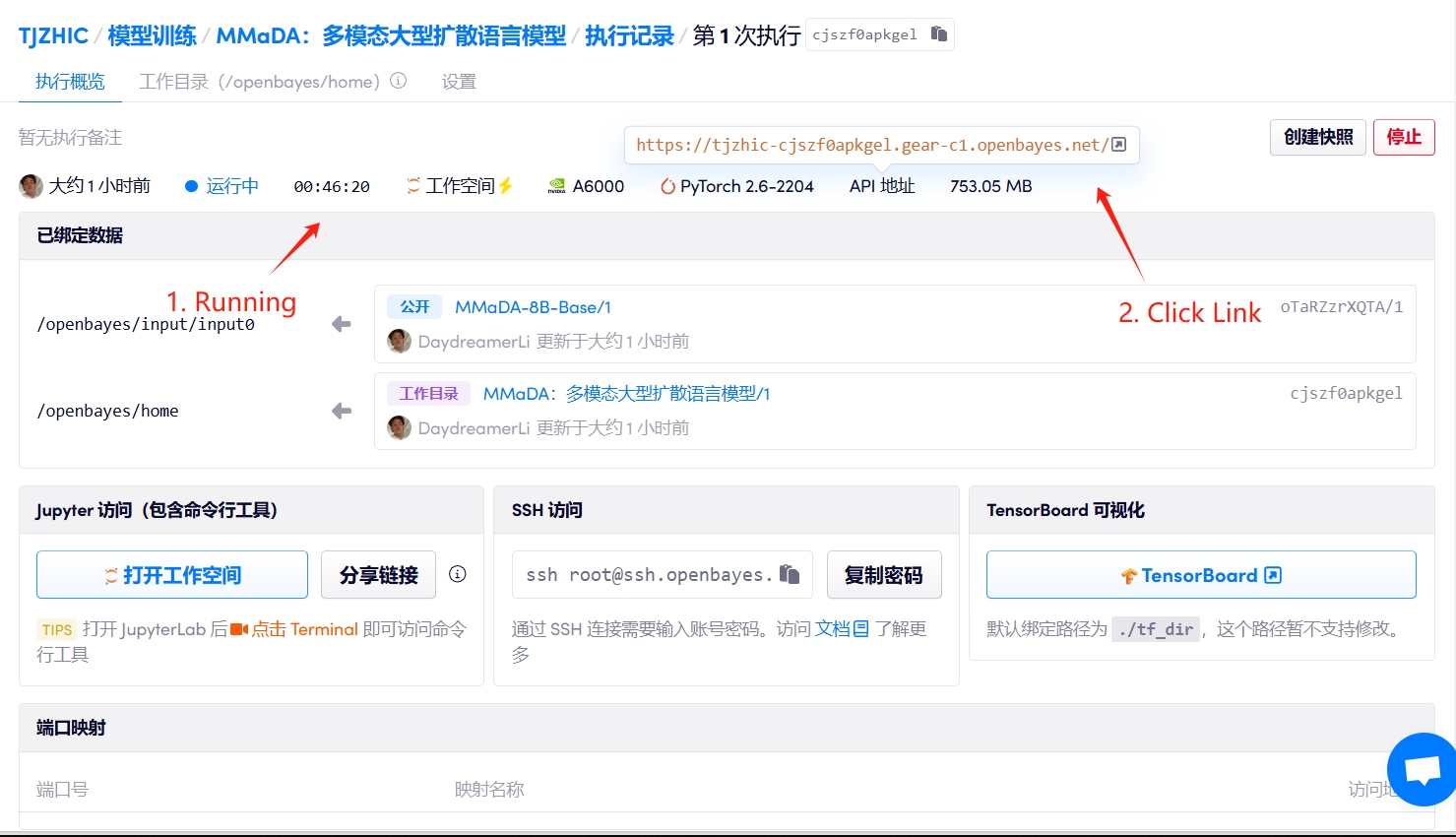
2. 使用手順
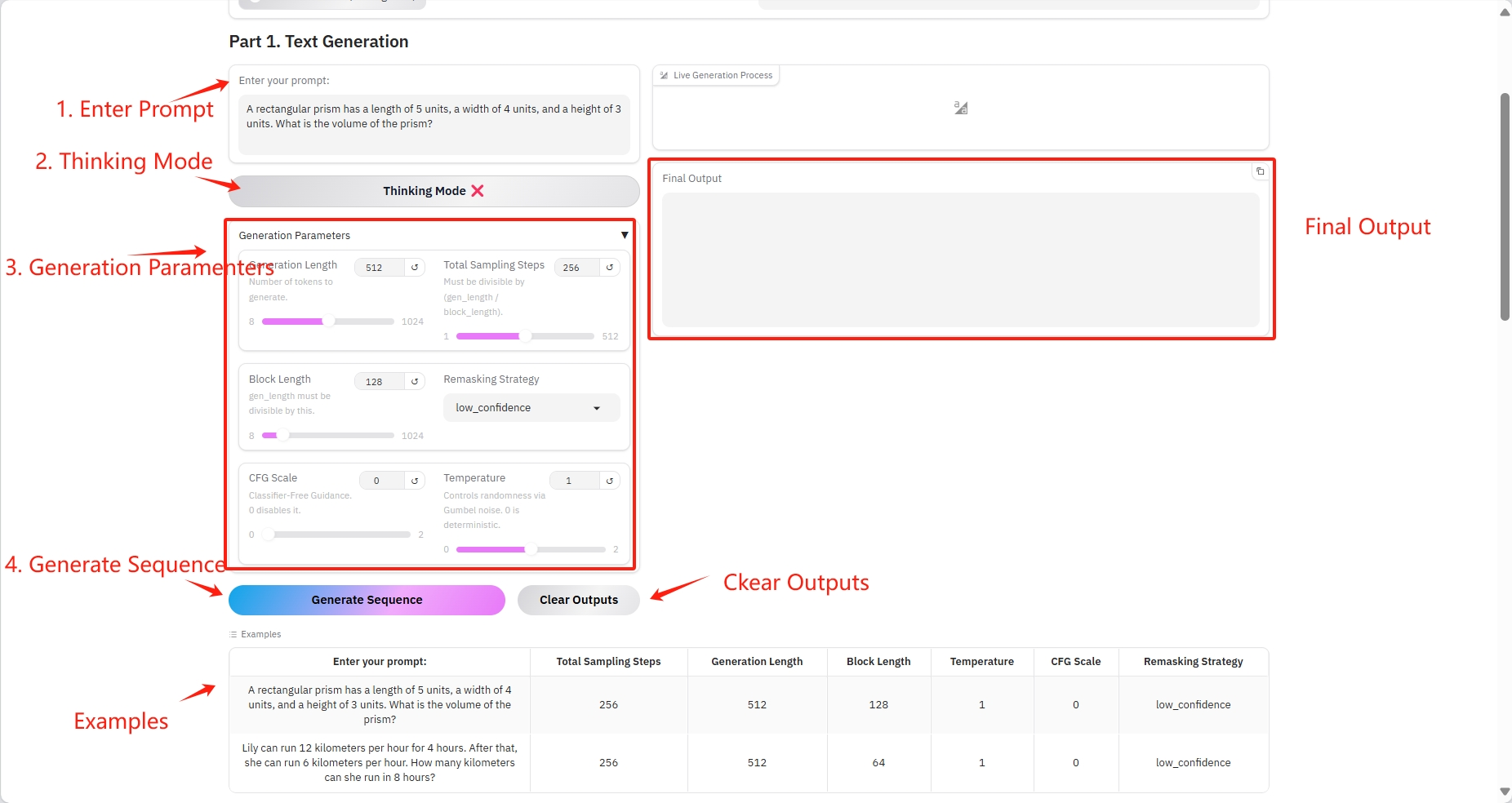
1. テキスト生成
具体的なパラメータ:
- プロンプト:ここにテキストを入力できます。
- 生成の長さ: 生成されるトークンの数。
- 合計サンプリング ステップ: (gen_length / block_length) で割り切れる必要があります。
- ブロック長: gen_length はこの数値で割り切れる必要があります。
- リマスキング戦略: リマスキング戦略。
- CFG スケール: 分類ガイドなし。0 は無効にします。
- 温度: Gumbel ノイズを介してランダム性を制御します。0 は決定論的です。
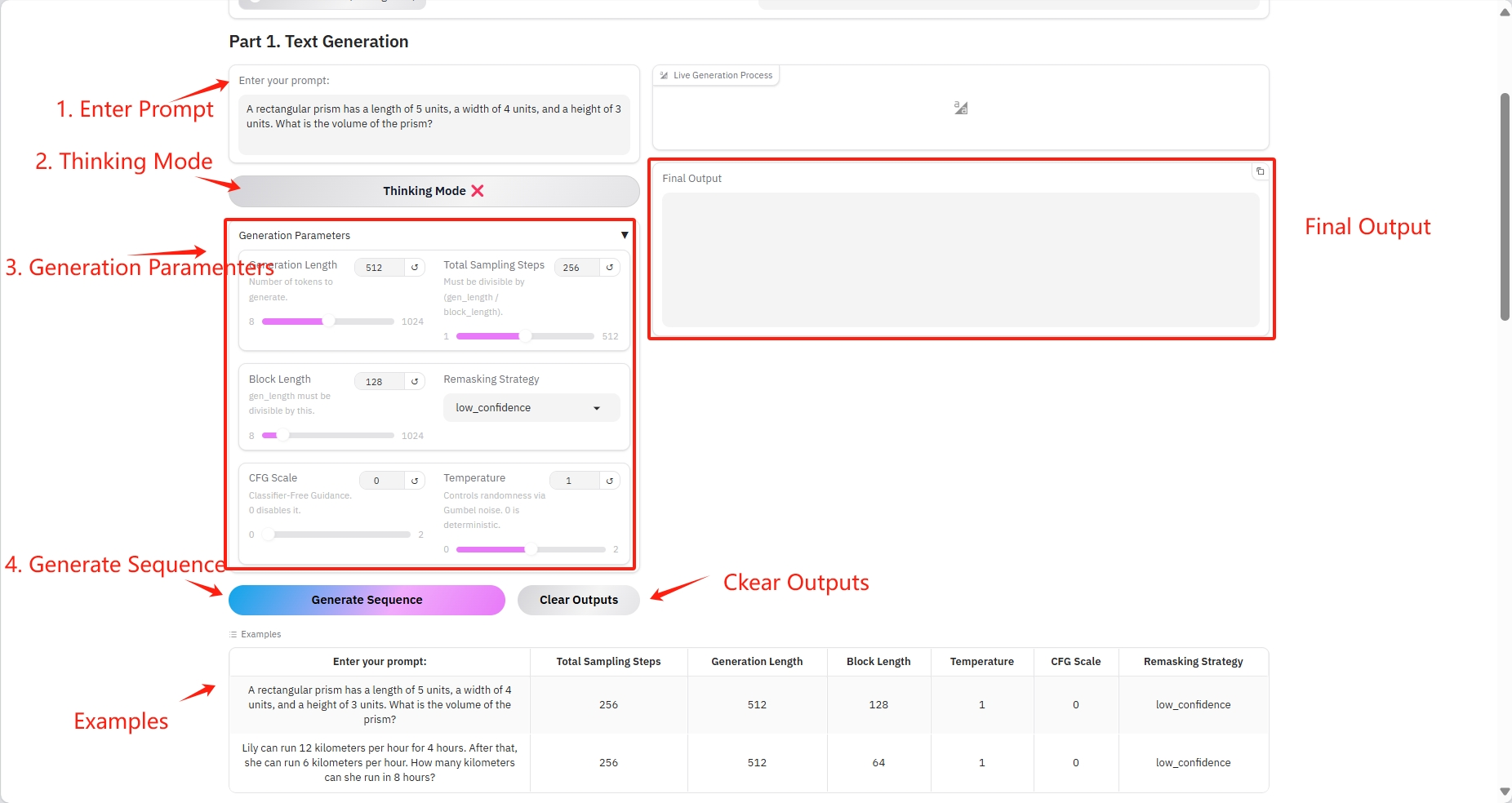
結果出力
2. マルチモーダル理解
具体的なパラメータ:
- プロンプト:ここにテキストを入力できます。
- 生成の長さ: 生成されるトークンの数。
- 合計サンプリング ステップ: (gen_length / block_length) で割り切れる必要があります。
- ブロック長: gen_length はこの数値で割り切れる必要があります。
- リマスキング戦略: リマスキング戦略。
- CFG スケール: 分類ガイドなし。0 は無効にします。
- 温度: Gumbel ノイズを介してランダム性を制御します。0 は決定論的です。
- 画像: 写真。
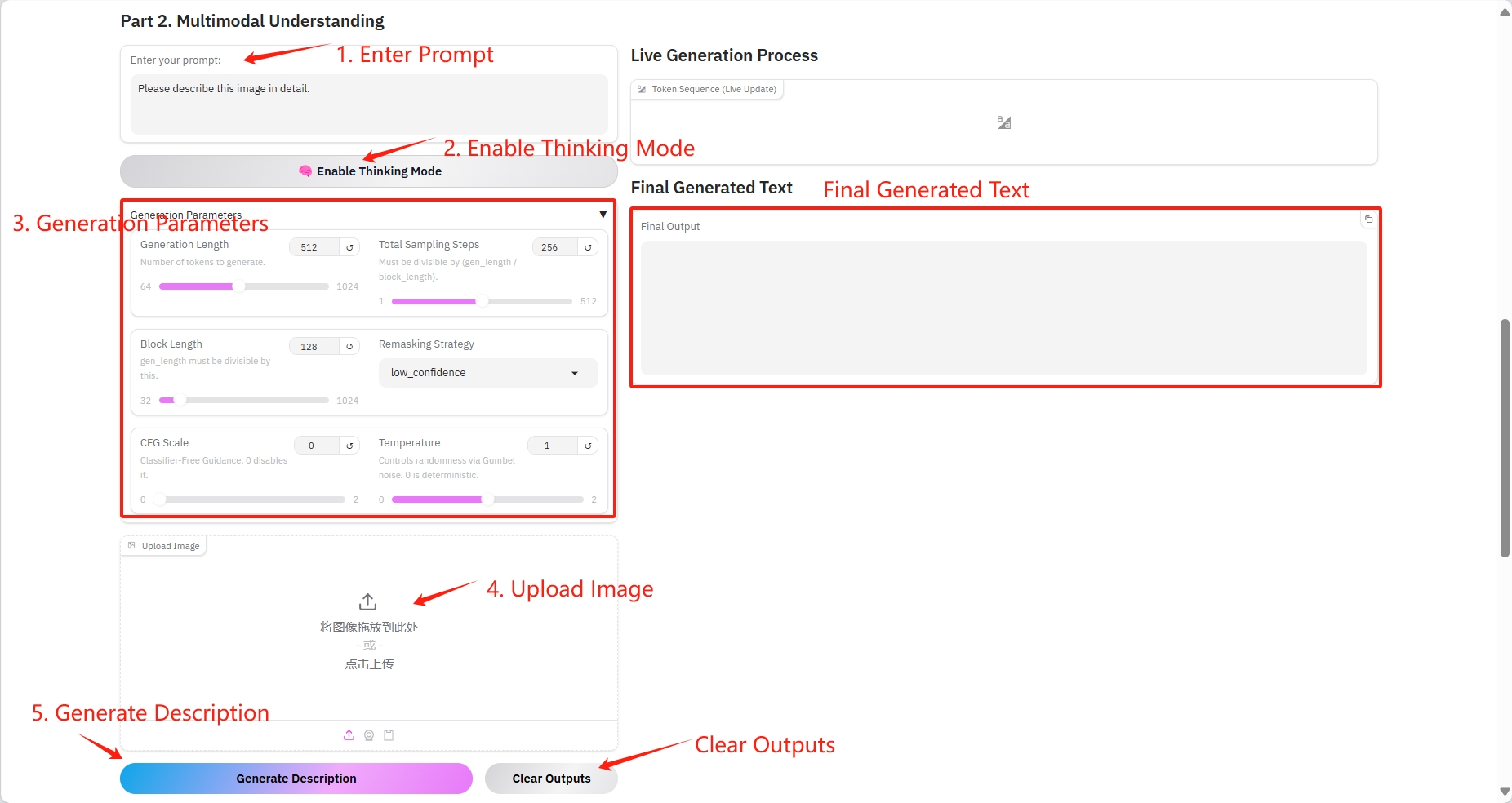
結果出力
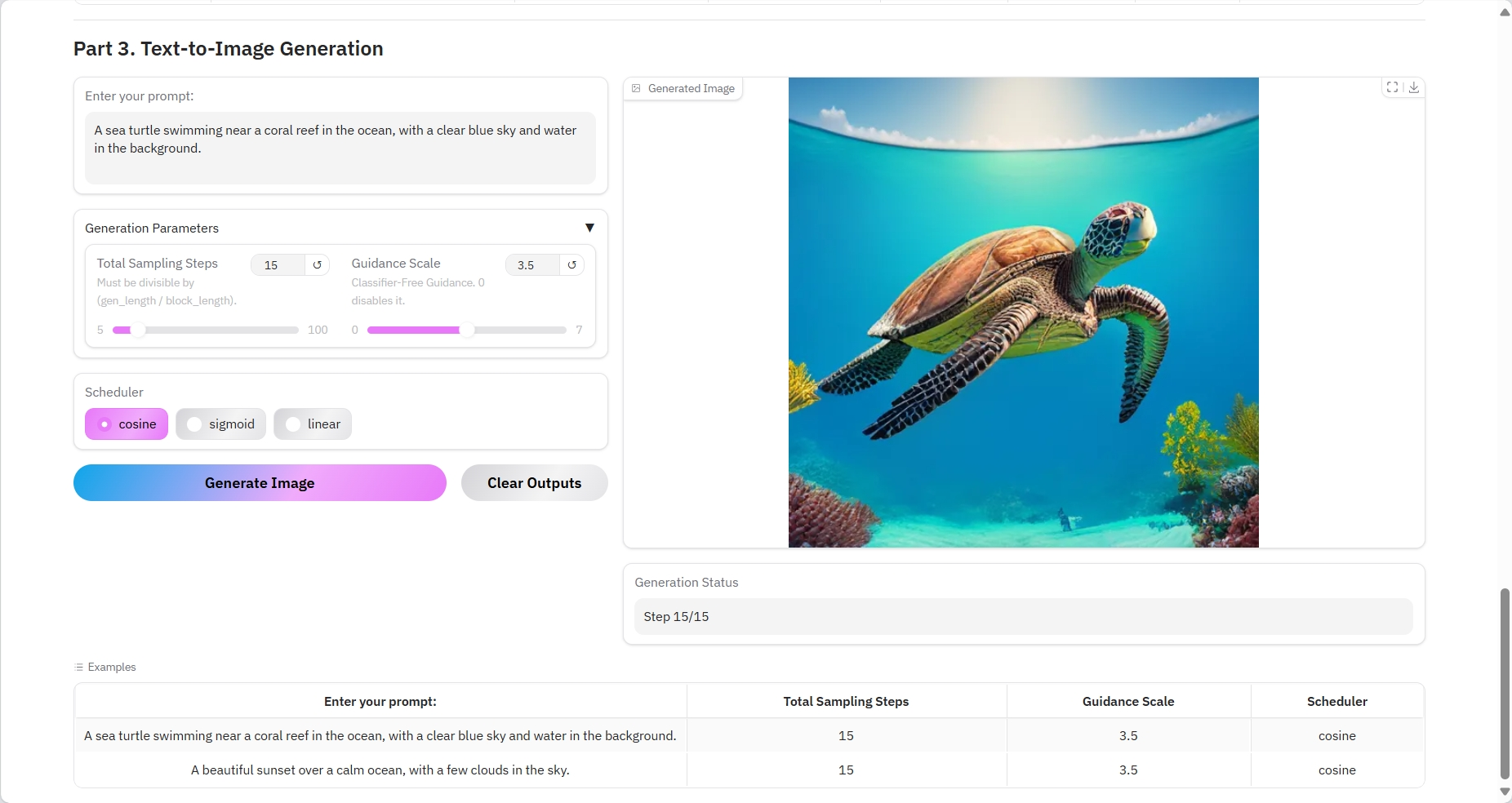
3. テキストから画像への生成
具体的なパラメータ:
- プロンプト:ここにテキストを入力できます。
- 合計サンプリング ステップ: (gen_length / block_length) で割り切れる必要があります。
- ガイダンス スケール: 分類器ガイダンスはありません。0 は無効にします。
- スケジューラ:
- コサイン: コサイン類似度は、文のペアの類似度を計算し、埋め込みベクトルを最適化します。
- シグモイド: マルチラベル分類。
- 線形: 線形レイヤーは、注目度の計算のために画像パッチ埋め込みベクトルをより高い次元にマッピングします。
結果出力
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
Githubユーザーに感謝 スーパーヤン このチュートリアルの展開。このプロジェクトの引用情報は次のとおりです。
@article{yang2025mmada,
title={MMaDA: Multimodal Large Diffusion Language Models},
author={Yang, Ling and Tian, Ye and Li, Bowen and Zhang, Xinchen and Shen, Ke and Tong, Yunhai and Wang, Mengdi},
journal={arXiv preprint arXiv:2505.15809},
year={2025}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。