HyperAI
Command Palette
Search for a command to run...
Ovis-Image: 高品質画像生成モデル
1. チュートリアルの概要

Ovis-Imageは、AIDC-AIチームが2025年11月にリリースした高忠実度テキスト画像生成モデルOvis-Image-7Bをベースに構築された、高品質なテキスト画像生成(T2I)モデルシステムです。このシステムは、マルチスケールTransformerエンコーダーと自己回帰生成アーキテクチャを採用し、高解像度画像生成、詳細表現、マルチスタイル適応において卓越した性能を発揮します。最適化されたノイズサンプリングと分類器フリーのガイダンス技術により、Ovis-Imageは1024×1024の解像度で自然で一貫性のある詳細な画像を生成し、写実画、サイバーパンク、アニメ、SFなど、様々なスタイルに対応します。関連研究論文も入手可能です。 Ovis-Image 7B: マルチスケールトランスフォーマーによるテキストから画像への生成 。
コア機能:
- 高解像度のネイティブ生成: 最大 1024×1024 解像度のネイティブ生成をサポートし、追加の超解像度モデルを必要とせずに鮮明で詳細な結果を実現します。
- マルチスケール セマンティック モデリング: マルチスケール Transformer エンコーディング構造に基づいて、全体的な構成とローカル テクスチャの詳細の両方を考慮します。
- 高品質なディテール再現: キャラクター、マテリアル、照明、環境の複雑さに関して安定したパフォーマンス。
- 複数のスタイルにわたる強力な汎用性: リアリズム、サイバーパンク、アニメ、SF、イラストなど、さまざまな主流のスタイルをネイティブにサポートします。
- 高度に制御可能な生成機能: ガイダンス スケール、サンプリング ステップ、解像度、ランダム シードにより、細かく制御可能な生成が実現されます。
- 推論の精度と効率のバランス: BF16 低メモリ推論をサポートし、FP32 デコードを利用して最終的な画像の精度を向上させます。
このチュートリアルでは、Grado を使用して、ビデオ メモリやメモリのボトルネックなしで 1024×1024 の高解像度テキスト生成を実現できる「RTX_5090」コンピューティング リソースを備えた Ovis-Image 7B コア モデルを展開します。
2. エフェクト表示

Ovis-Image 7B は、コアタスクにおいて非常に優れたパフォーマンスを発揮します。
- 複雑なシーン生成: 詳細なテキスト プロンプトから自然で論理的に健全な画像を生成します。
- 複数のスタイルのサポート: リアル、サイバーパンク、アニメ、SF などのさまざまなビジュアル スタイルを生成できます。
- 高解像度の詳細: 豊かなテクスチャ、影、照明。
- 制御性: ステップ数、ガイダンススケール、解像度を変更することで、生成される効果を調整できます。
3. 操作手順
1. コンテナを起動します
コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
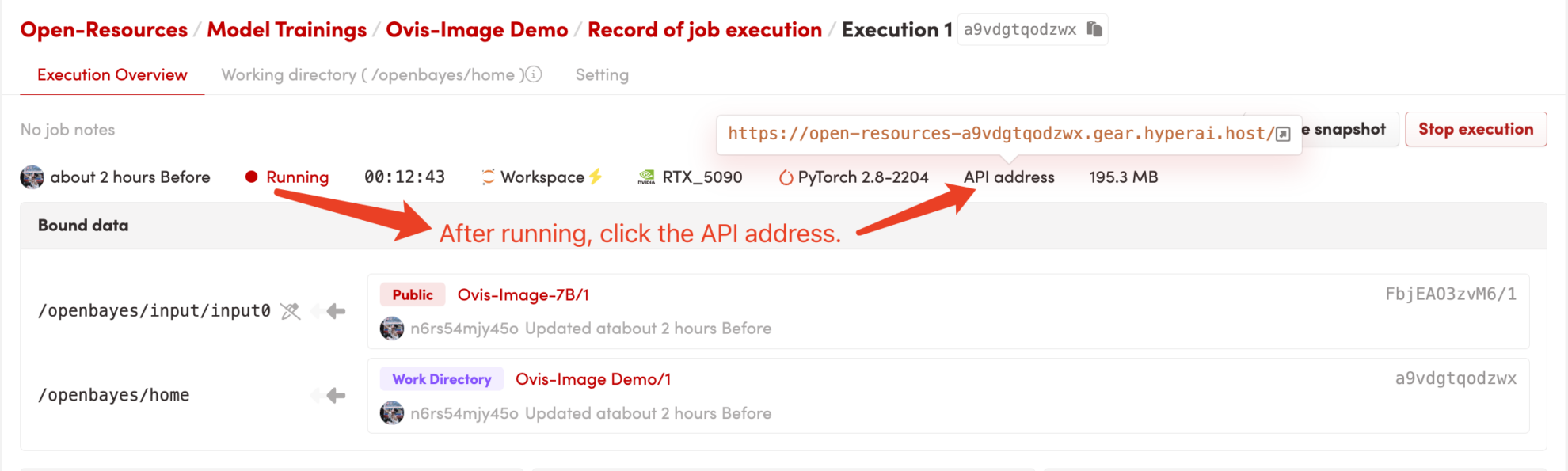
2. はじめに
「Bad Gateway」と表示される場合は、モデルが初期化中であることを意味します。モデルのサイズが大きいため、2~3分待ってからページを更新してください。
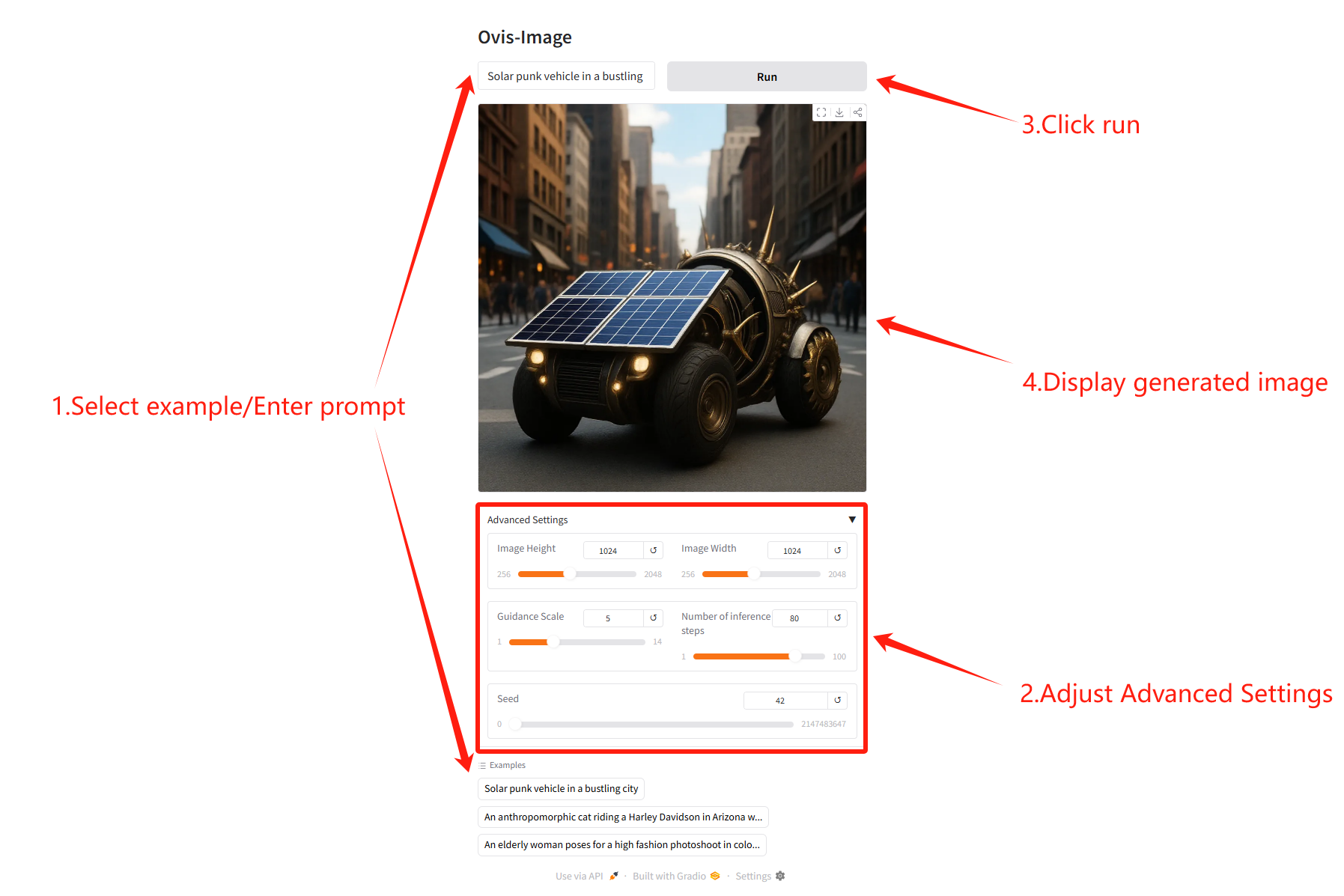
パラメータの説明
- 画像の高さ/幅: ステップ サイズ 32 で画像の高さと幅を生成します。
- 推論ステップ数生成されるステップ数が増えるほど、画像の詳細が豊かになります。
- ガイダンススケールテキスト プロンプトの強度。値が高いほど、画像がプロンプトに近くなります。
- シードランダムシードにより再現可能な生成が保証されます。
引用情報
このプロジェクトの引用情報は次のとおりです。
@article{ovisimage7b,
title={Ovis-Image 7B: Text-to-Image Generation with Multi-Scale Transformer},
author={AIDC-AI Team},
journal={arXiv preprint arXiv:2511.22982},
year={2025}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。
Notebook の概要
レベル
入門
トピック
HyperAI Newsletters
最新情報を購読する
北京時間 毎週月曜日の午前9時 に、その週の最新情報をメールでお届けします
メール配信サービスは MailChimp によって提供されています