HyperAI
Command Palette
Search for a command to run...
SAM3: 視覚セグメンテーションモデル
1. チュートリアルの概要

SAM3は、Meta AIが2025年11月に発表した高度なコンピュータビジョンモデルです。このモデルは、テキスト、例、視覚的な手がかりを用いて、画像や動画内のオブジェクトを検出、セグメント化、追跡できます。オープンボキャブラリーのフレーズ入力をサポートし、強力なクロスモーダルインタラクション機能を備え、セグメンテーション結果をリアルタイムで修正できます。SAM3は、画像および動画のセグメンテーションタスクにおいて優れたパフォーマンスを発揮し、既存システムの2倍の性能を発揮します。また、ゼロショット学習もサポートしています。このモデルは3D再構成にも対応しており、住宅内覧、クリエイティブな動画編集、科学研究など、様々なシナリオでの応用をサポートし、コンピュータビジョンの将来の発展に力強い推進力をもたらします。関連研究論文もご覧いただけます。 SAM 3: コンセプトを使ってあらゆるものをセグメント化する 。
このチュートリアルでは、デフォルトでRTX 5090グラフィックカードを1枚使用しますが、最低でもRTX 4090を1枚搭載していれば開始できます。テスト用に、画像セグメンテーション、ビデオテキストプロンプト、ビデオポイント/ボックスプロンプトの3つのサンプルが用意されています。モデルは英語入力のみをサポートしています。
2. エフェクト表示


3. 操作手順
1. コンテナを起動します
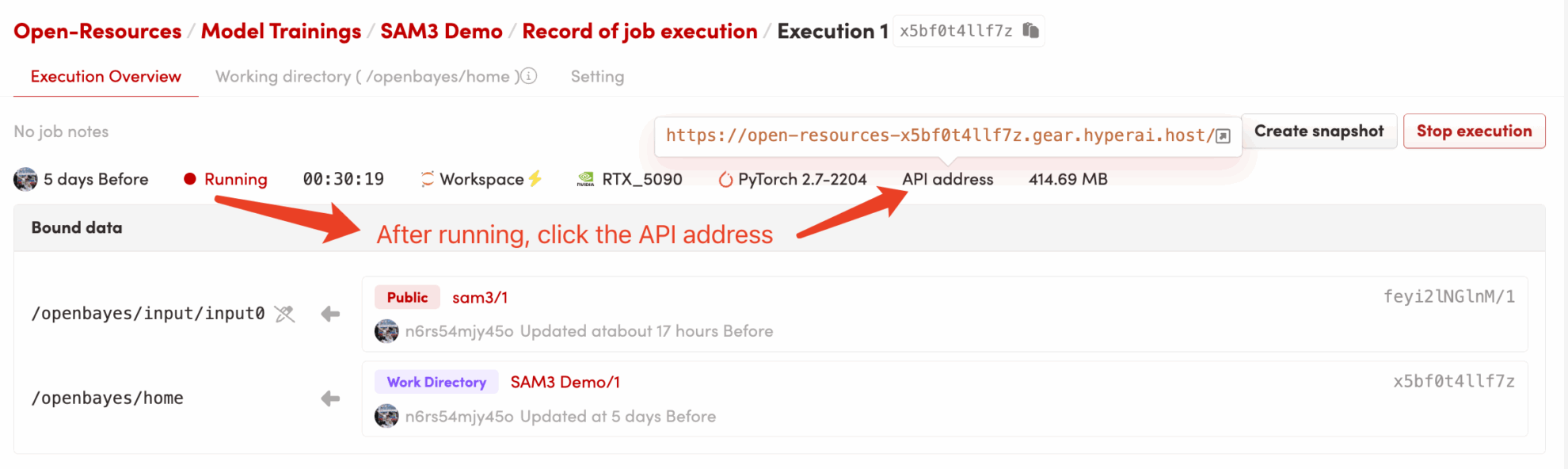
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
1. 画像セグメンテーション
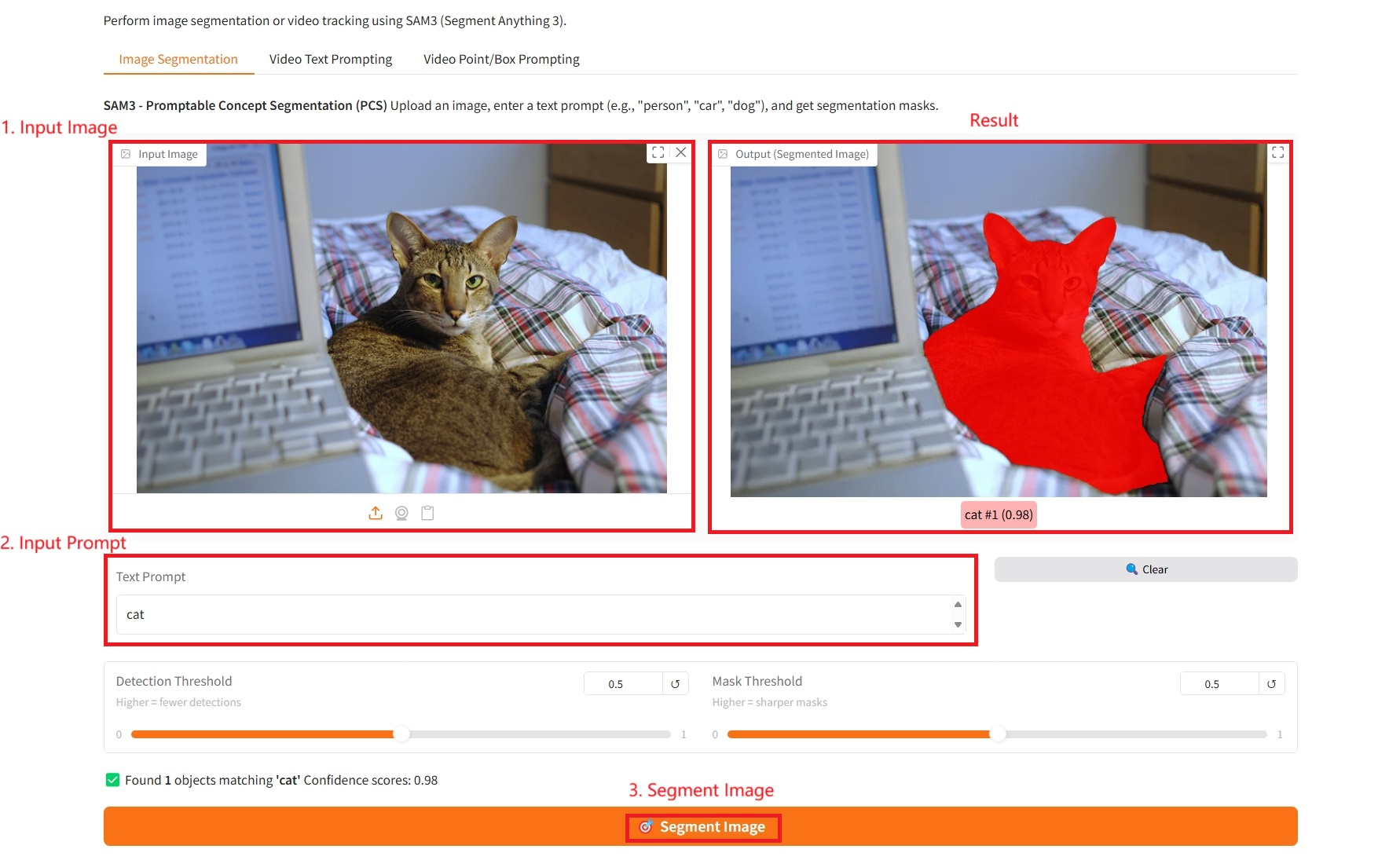
具体的なパラメータ:
- テキストプロンプト:ここにテキストを入力できます。
- 検出しきい値: しきい値が高いほど、検出されるターゲットの数は少なくなります。
- マスクしきい値: しきい値が高いほど、生成されるマスクの境界はより鮮明かつシャープになります。
2. ビデオテキストプロンプト
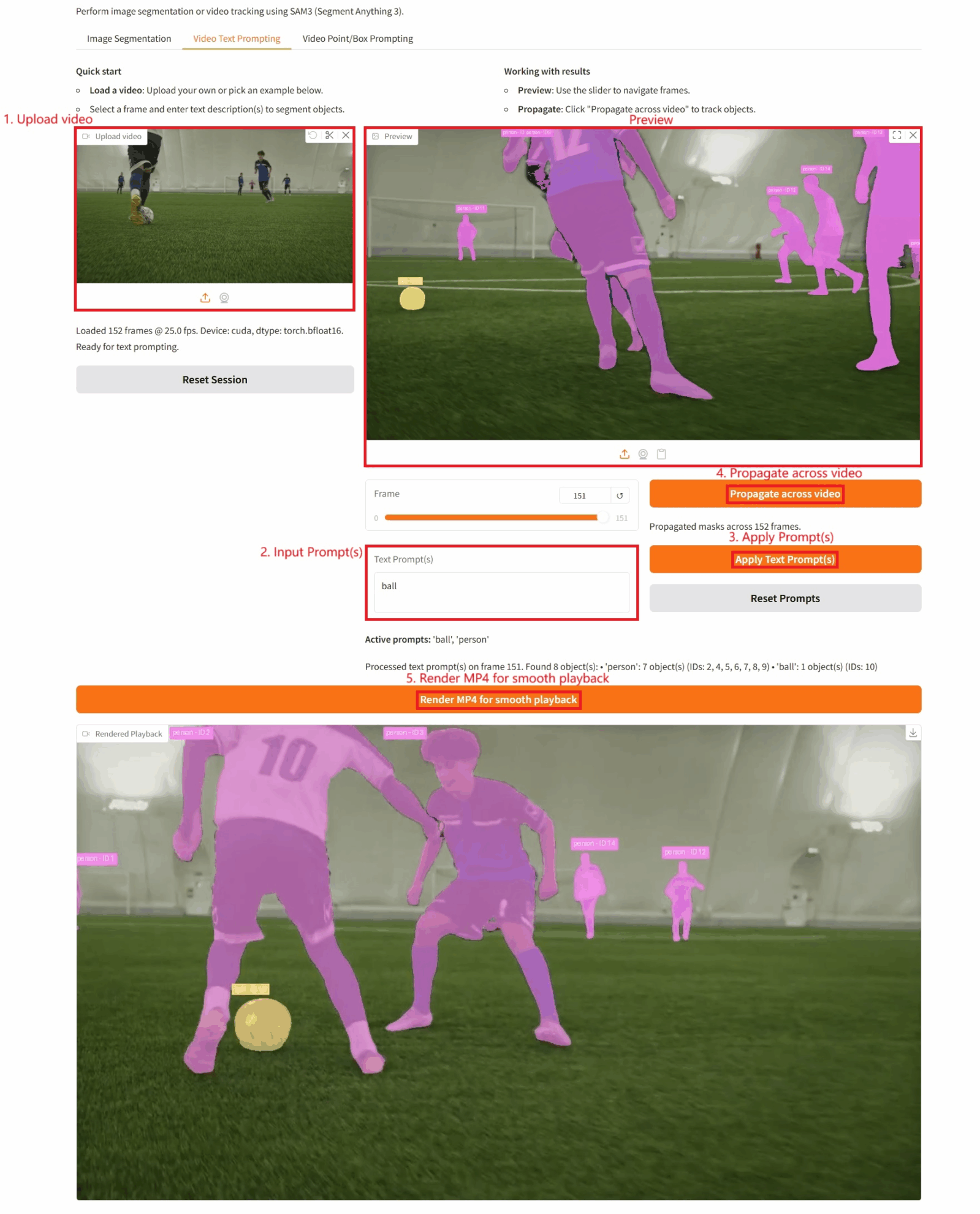
具体的なパラメータ:
- テキストプロンプト:ここにテキストを入力できます。
- ビデオ全体に伝播: このボタンをクリックすると、ターゲットのビデオ トラッキングが実行されます。
3. ビデオポイント/ボックスプロンプト
具体的なパラメータ:
- オブジェクト ID: 検出されたターゲット ID。
- ポイントラベル:
- positive: 画像上の位置をクリックした時に、それが positive であれば、その点はセグメント化する対象オブジェクトに属していることを意味するので、計算に含めてください。
- 負: 画像上の場所をクリックしたときに負になっている場合は、そのポイントがターゲット オブジェクトに属していない (背景など) ことを意味しますので、削除してください。
- このオブジェクトの古い入力をクリア: 以前に検出されたターゲットをクリアするかどうか。
- プロンプトの種類:
- ポイント: 視覚的なヒントをクリックします。
- ボックス: 項目を選択するための視覚的なヒント。

引用情報
このプロジェクトの引用情報は次のとおりです。
@misc{carion2025sam3segmentconcepts,
title={SAM 3: Segment Anything with Concepts},
author={Nicolas Carion and Laura Gustafson and Yuan-Ting Hu and Shoubhik Debnath and Ronghang Hu and Didac Suris and Chaitanya Ryali and Kalyan Vasudev Alwala and Haitham Khedr and Andrew Huang and Jie Lei and Tengyu Ma and Baishan Guo and Arpit Kalla and Markus Marks and Joseph Greer and Meng Wang and Peize Sun and Roman Rädle and Triantafyllos Afouras and Effrosyni Mavroudi and Katherine Xu and Tsung-Han Wu and Yu Zhou and Liliane Momeni and Rishi Hazra and Shuangrui Ding and Sagar Vaze and Francois Porcher and Feng Li and Siyuan Li and Aishwarya Kamath and Ho Kei Cheng and Piotr Dollár and Nikhila Ravi and Kate Saenko and Pengchuan Zhang and Christoph Feichtenhofer},
year={2025},
eprint={2511.16719},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.16719},
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。
Notebook の概要
レベル
入門
HyperAI Newsletters
最新情報を購読する
北京時間 毎週月曜日の午前9時 に、その週の最新情報をメールでお届けします
メール配信サービスは MailChimp によって提供されています