HyperAI
Command Palette
Search for a command to run...
DeepSeek-R1-70Bのワンクリック展開
1. チュートリアルの概要

DeepSeek-R1-Distill-Llama-70Bは、DeepSeekが2025年にリリースしたオープンソースの大規模言語モデルで、700億のパラメータ規模を誇ります。Llama3.3-70B-Instructで学習され、強化学習と蒸留技術を採用することで推論性能を向上させています。Llamaシリーズモデルの利点を継承するだけでなく、推論機能をさらに最適化し、特に数学、コード、論理推論タスクに優れています。DeepSeekシリーズの高性能版として、複数のベンチマークテストで非常に優れたパフォーマンスを発揮しています。さらに、このモデルはDeepSeek AIが提供する推論強化モデルであり、モバイルデバイスやエッジコンピューティング、オンライン推論サービスなど、さまざまなアプリケーションシナリオをサポートし、応答速度を向上させ、運用コストを削減します。非常に強力な推論および意思決定能力を備えています。高度なAIアシスタントや科学研究分析などの分野において、非常に専門的で詳細な分析結果を提供できます。たとえば、医療研究では、バージョン 70B は大量の医療データを分析し、病気の研究に貴重な参考資料を提供できます。
本教程使用 Ollama + Open WebUI 部署 DeepSeek-R1-Distill-Qwen-70B 作为演示,算力资源采用「单卡 A6000」。
2. 操作手順
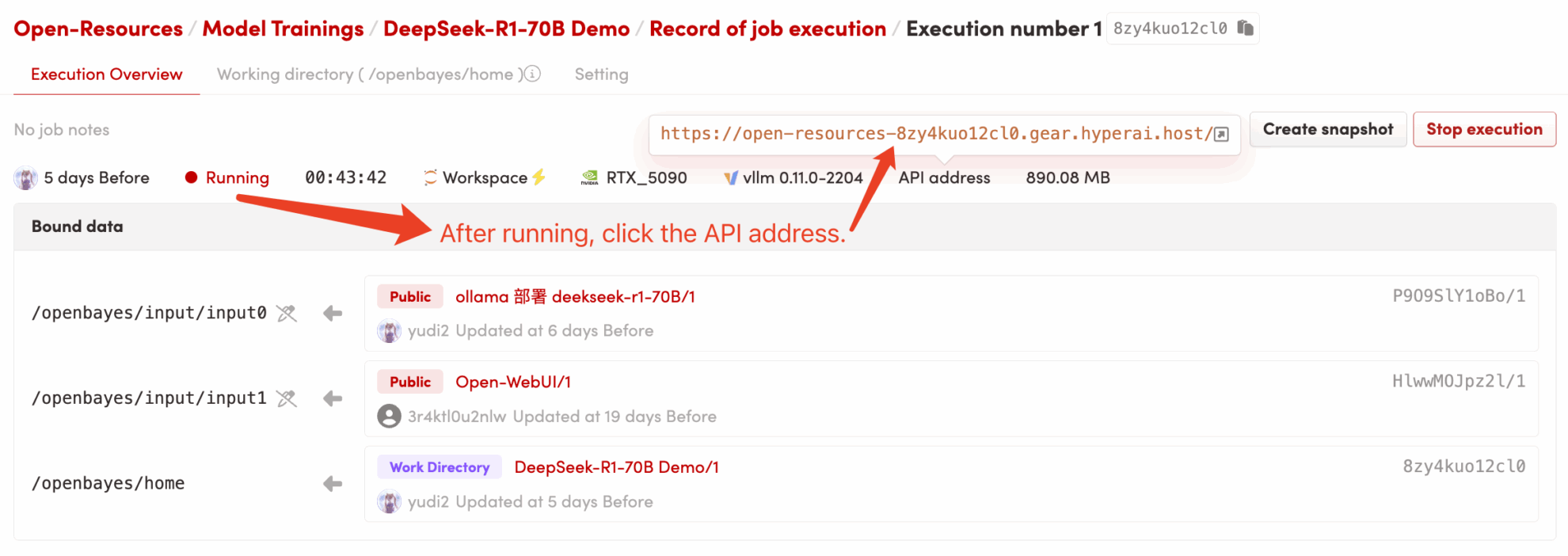
1. コンテナを起動した後、API アドレスをクリックして Web インターフェースに入ります (「Bad Gateway」と表示された場合は、モデルが初期化中であることを意味します。モデルが大きいため、5 分ほど待ってからもう一度お試しください。) 2. Web ページに入ったら、モデルとの会話を開始できます。
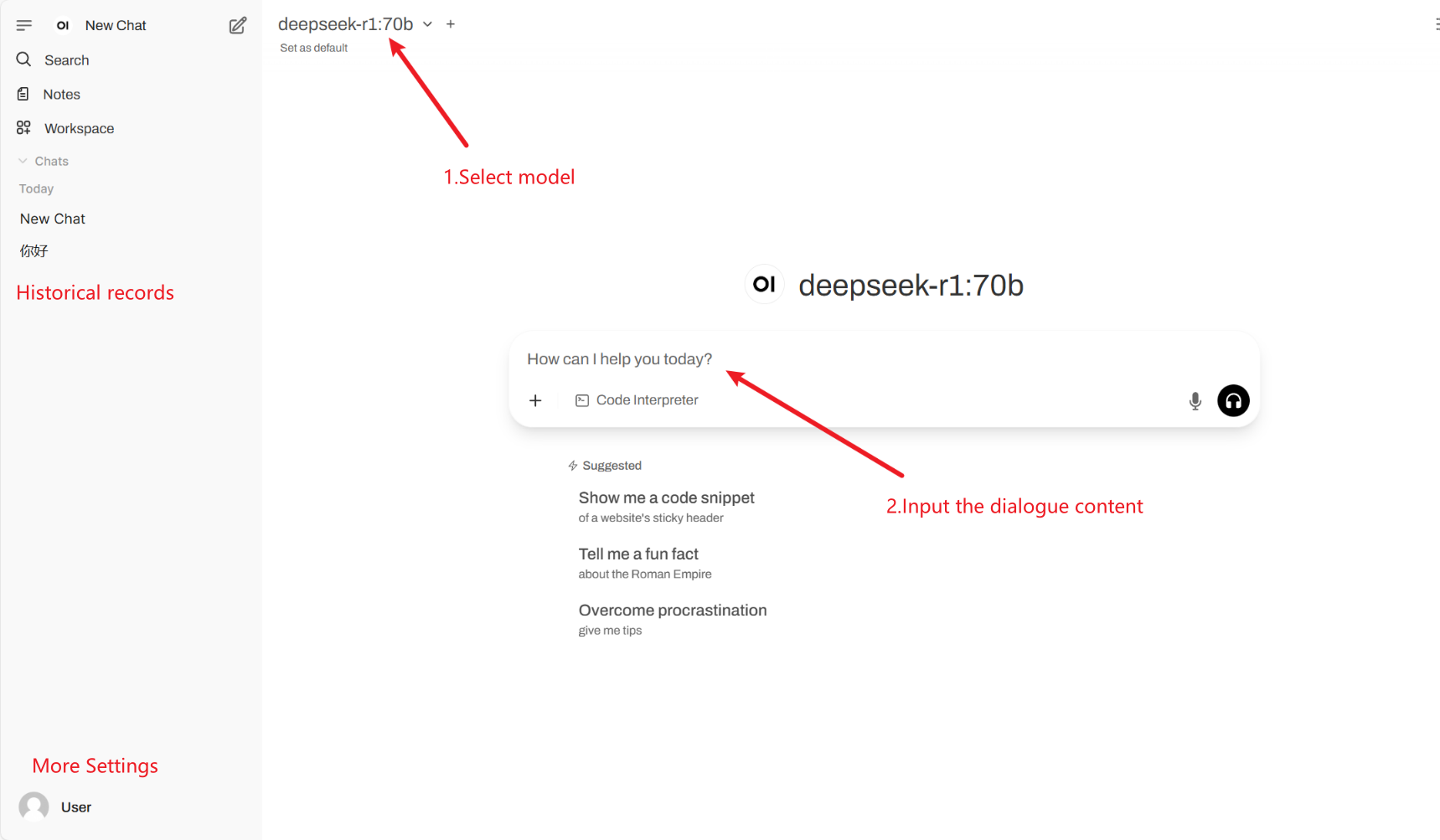
2. Web ページに入ると、モデルと会話を開始できます。
一般的な会話設定
1. 温度
- 出力のランダム性を、通常は 0.0 ~ 2.0 の範囲で制御します。
- 低い値(0.1など): より確実で、一般的な単語に偏っています。
- 高い値(1.5など): よりランダムで、潜在的にもっとクリエイティブだが不安定なコンテンツ。
2. トップkサンプリング
- 確率の低い単語を除外し、確率が最も高い k 個の単語のみをサンプリングします。
- k は小さい (例: 10): 確実性は高まり、ランダム性は減少します。
- k は大きい(例:50): 多様性が増すと、革新性も高まります。
3. Top-pサンプリング(核サンプリング、Top-pサンプリング)
- 累積確率が p に達する単語セットを選択し、k の値は固定しません。
- 低い値(0.3など): 確実性は高まり、ランダム性は減少します。
- 高い値(0.9など): 多様性が増し、流暢性が向上しました。
4. 繰り返しペナルティ
- テキストの繰り返し率を制御します。通常は 1.0 ~ 2.0 の範囲です。
- 高い値(1.5など): 繰り返しを減らして読みやすさを向上します。
- 低い値(1.0など): ペナルティはありませんが、モデルが単語や文を繰り返す可能性があります。
5. 最大トークン数(最大生成長)
- 出力が長くなりすぎないように、モデルによって生成されるトークンの最大数を制限します。
- 通常の範囲: 50 ~ 4096 (特定のモデルによって異なります)。
引用
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。
Notebook の概要
レベル
入門
トピック
HyperAI Newsletters
最新情報を購読する
北京時間 毎週月曜日の午前9時 に、その週の最新情報をメールでお届けします
メール配信サービスは MailChimp によって提供されています