Command Palette
Search for a command to run...
F5-E2 TTS あらゆるサウンドをわずか 3 秒でクローン作成
1. チュートリアルの概要

このチュートリアルには、F5-TTS と E2 TTS という 2 つのモデルのデモ使用が含まれています。
F5-TTSは、上海交通大学、ケンブリッジ大学、吉利汽車研究所(寧波)有限公司が2024年に共同でオープンソース化した高性能テキスト読み上げ(TTS)システムです。ストリームマッチングを用いた非自己回帰生成法と拡散トランスフォーマー(DiT)技術を組み合わせています。関連研究論文も公開されています。 F5-TTS: フロー マッチングを使用して流暢で忠実なスピーチを偽装するおとぎ話者 このシステムは、追加の監督なしにゼロショット学習を通じて元のテキストから自然で流暢で忠実な音声を迅速に生成できます。 F5-TTSは、中国語や英語を含む多言語合成をサポートし、長いテキストで効果的に音声を合成できます。 さらに、F5-TTSは感情制御機能を備えており、テキストの内容に基づいて合成音声の感情表現を調整し、速度制御をサポートしているため、ユーザーは必要に応じて再生速度を調整できます。 このシステムは10万時間という大規模なデータセットでトレーニングされ、優れた性能と一般化能力を示しました。 F5-TTSの主な機能には、ゼロショット音声複製、速度制御、感情制御、長文合成、多言語サポートなどがあります。 その技術的原理には、ストリームマッチング、拡散トランスフォーマー(DiT)、ConvNeXt V2テキスト表現の改善、Swayサンプリング戦略、エンドツーエンドのシステム設計が含まれます。 F5-TTS は、オーディオブック、音声アシスタント、言語学習、ニュース放送、ゲームの吹き替えなど、幅広い用途があり、さまざまな商用および非商用の用途に強力な音声合成機能を提供します。
E2 TTS(「Embarrassingly Easy Text-to-Speech」の略)は、人間レベルの自然さと話者類似性を、簡素化されたプロセスで実現する高度なテキスト読み上げ(TTS)システムです。E2 TTSの核となるのは、完全に非自己回帰的な性質です。つまり、段階的な生成を必要とせず、音声シーケンス全体を一度に生成できるため、高品質の音声出力を維持しながら、生成速度を大幅に向上させることができます。関連研究論文には以下が含まれます… E2 TTS: 恥ずかしいほど簡単な完全非自己回帰ゼロショット TTSSLT 2024に採択されたE2 TTSは、テキスト入力をパディングマーカー付きの文字列に変換します。次に、ストリームマッチングに基づくメルスペクトログラム生成器をオーディオパディングタスク用に学習します。多くの先行研究とは異なり、E2 TTSは追加コンポーネント(例:持続時間モデル、文字から音素への変換)や複雑な技術(例:単調アライメント検索)を必要としません。そのシンプルさにもかかわらず、E2 TTSは最先端のゼロショットTTS機能を実現しており、VoiceboxやNaturalSpeech 3などの先行研究に匹敵、あるいは凌駕しています。E2 TTSのシンプルさは、入力表現の柔軟性も可能にします。
该教程支持如下模型和功能: 2 个模型检查点: F5-TTS E2 TTS 3 个功能:单人语音生成(Batched TTS): 根据上传的音频进行文本生成。 双人语音生成(Podcast Generation):根据双人音频模拟双人对话。多种语音类型生成(Multiple Speech-Type Generation):可根据同一讲话人不同情绪下的音频,生成不同情绪的音频。
このチュートリアルでは、リソースとして単一の RTX 5090 カードを使用します。
2. プロジェクト例
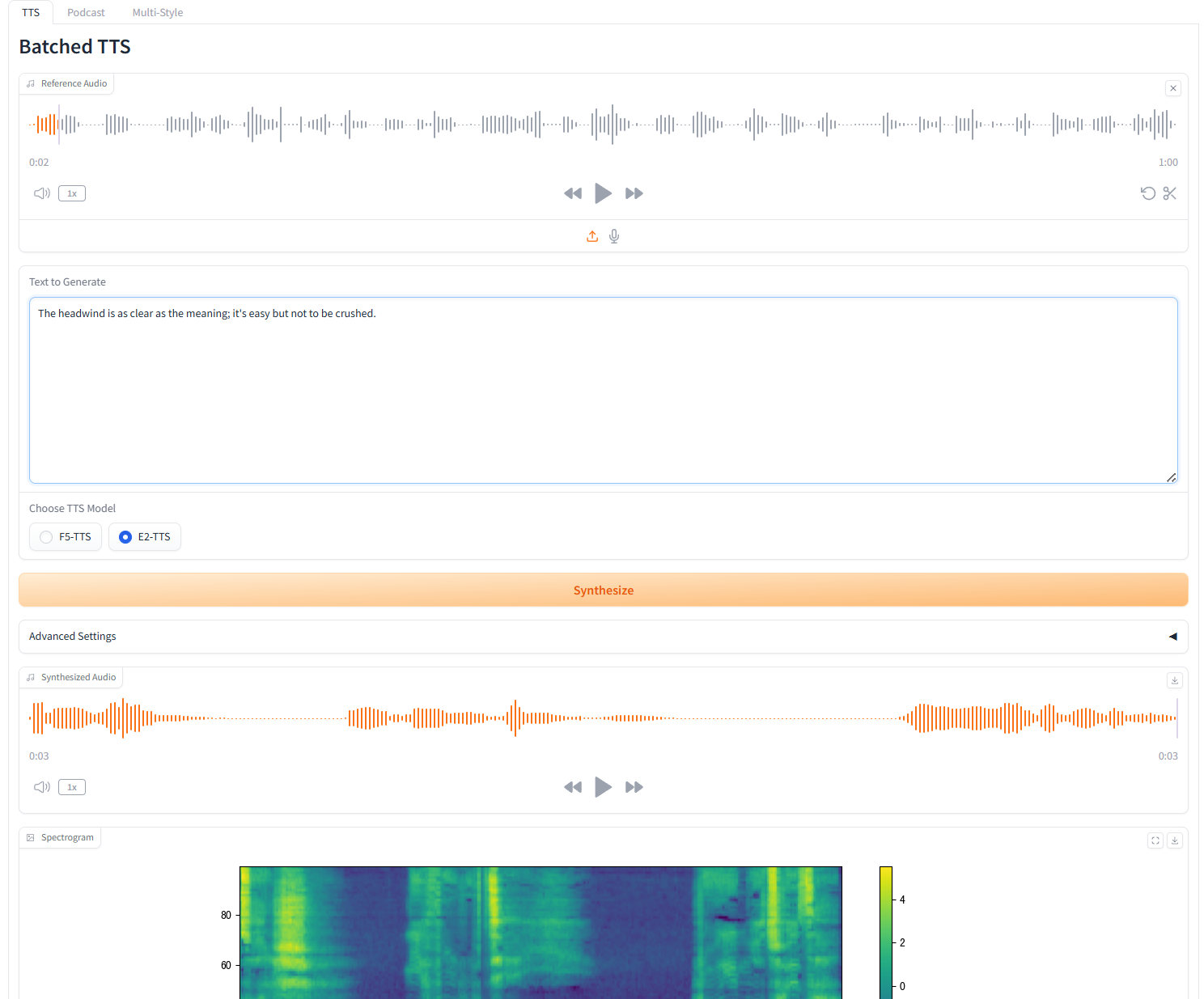
1. 一人音声生成(Batched TTS)
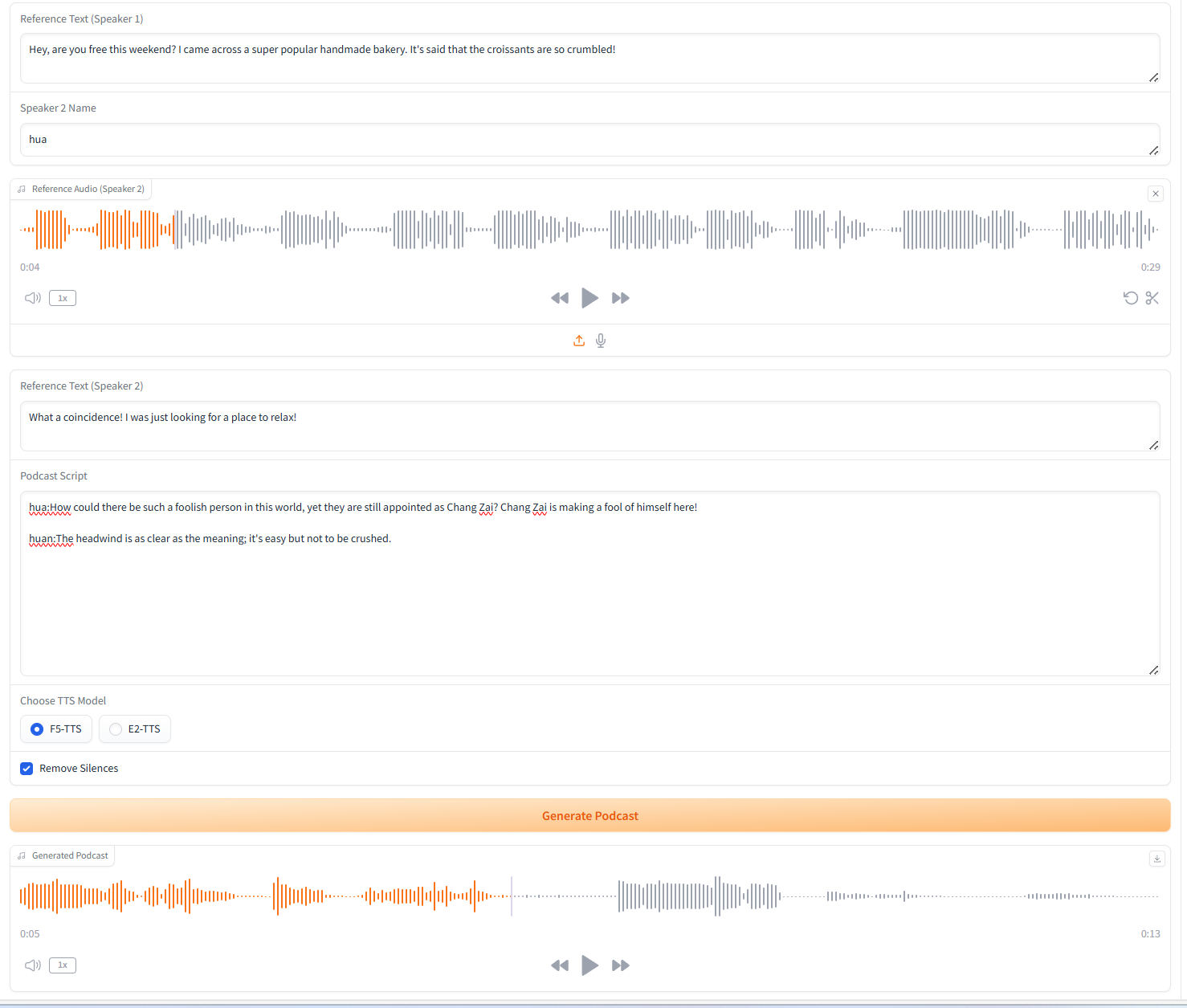
2. 複数人の音声生成(Podcast Generation)
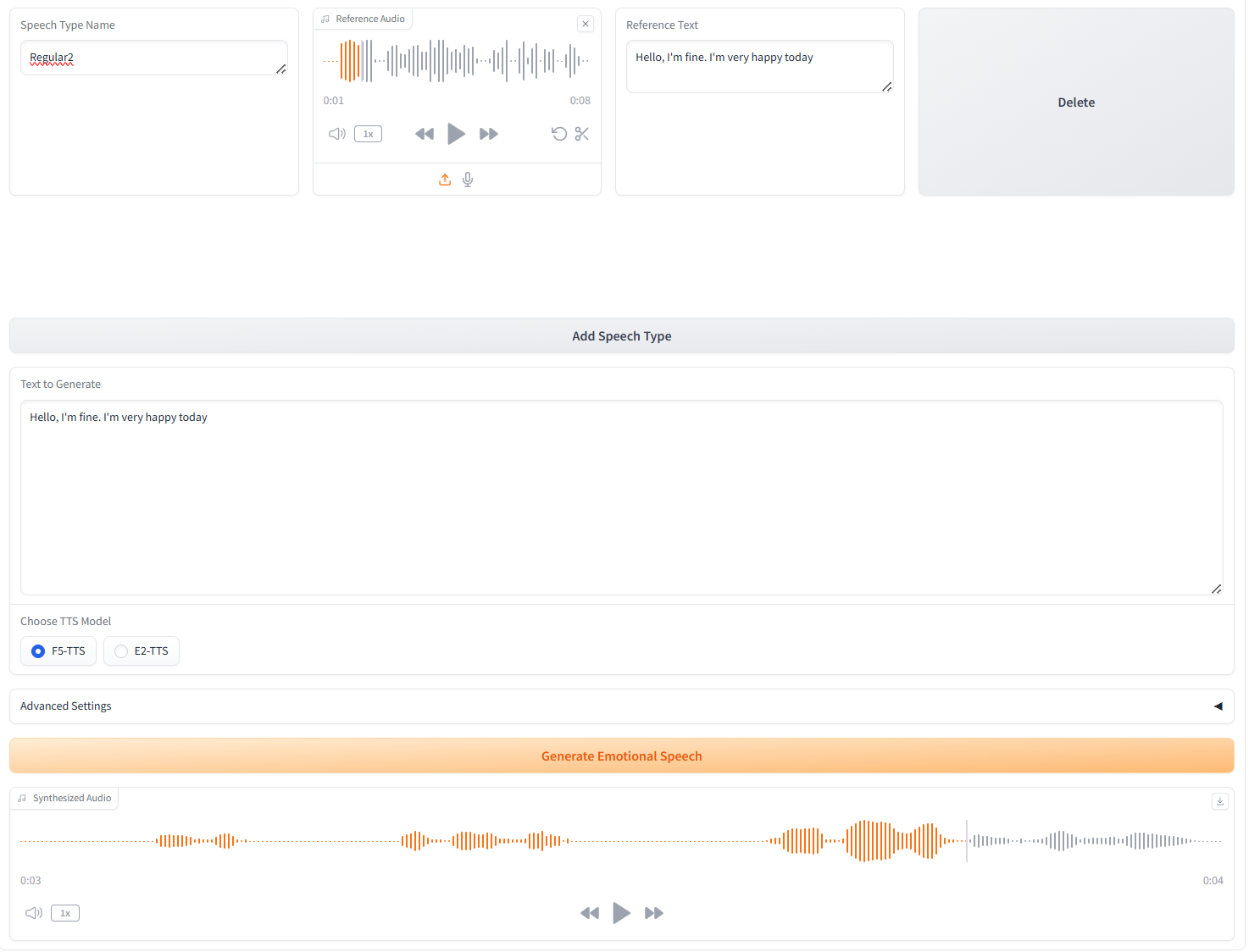
3. 複数の音声タイプの生成
3. 操作手順
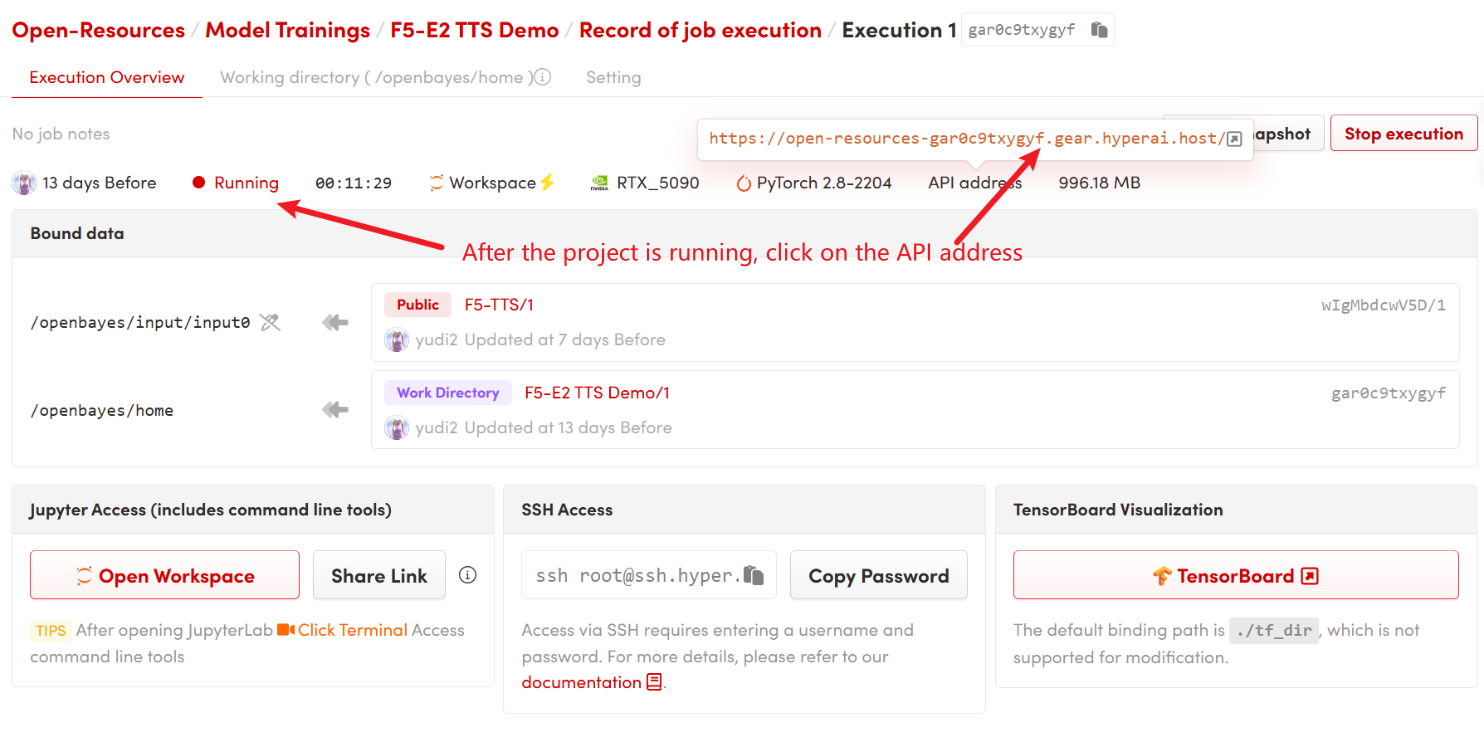
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. 使用手順
「Bad Gateway」と表示される場合は、モデルが初期化中であることを意味します。モデルのサイズが大きいため、約9分待ってからページを更新してください。
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
1. 一人音声生成(Batched TTS)
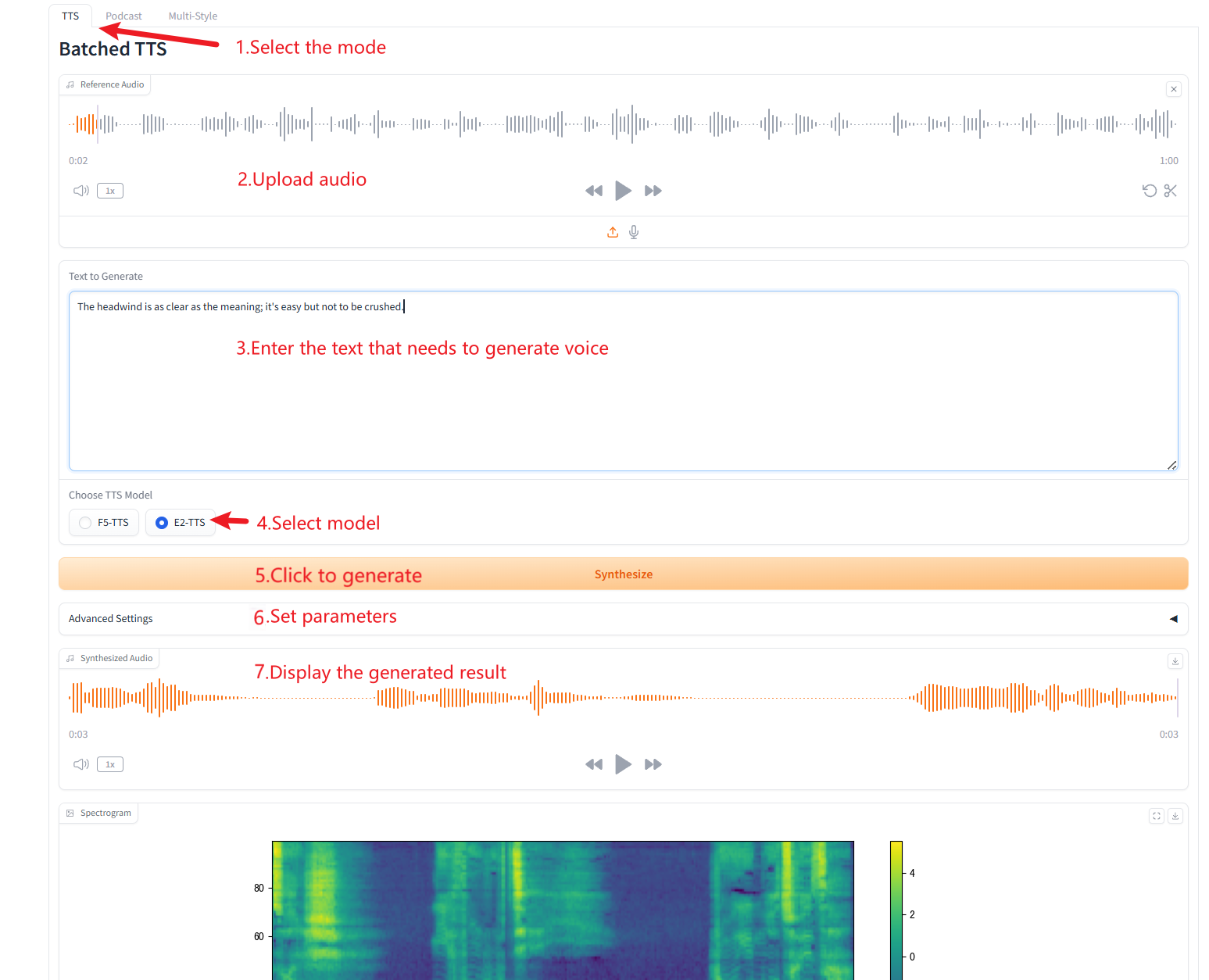
パラメータの説明
- 参考テキスト: 空白のままにすると、参照音声が自動的に文字起こしされます。テキストを入力すると、自動文字起こしが無効になります。
- 無音部分を削除する: このモデルは、特に長いオーディオの場合、無音になる傾向があります。必要に応じて、無音部分を手動で削除できます。これは実験的な機能であるため、奇妙な結果が生じる可能性があることに注意してください。これにより、ビルド時間も増加します。
- カスタム分割単語: 分割するカスタム単語をカンマで区切って入力します。デフォルトのリストを使用するには、空白のままにします。
- スピード: 生成される音声速度を制御します
2. 複数人の音声生成(Podcast Generation)
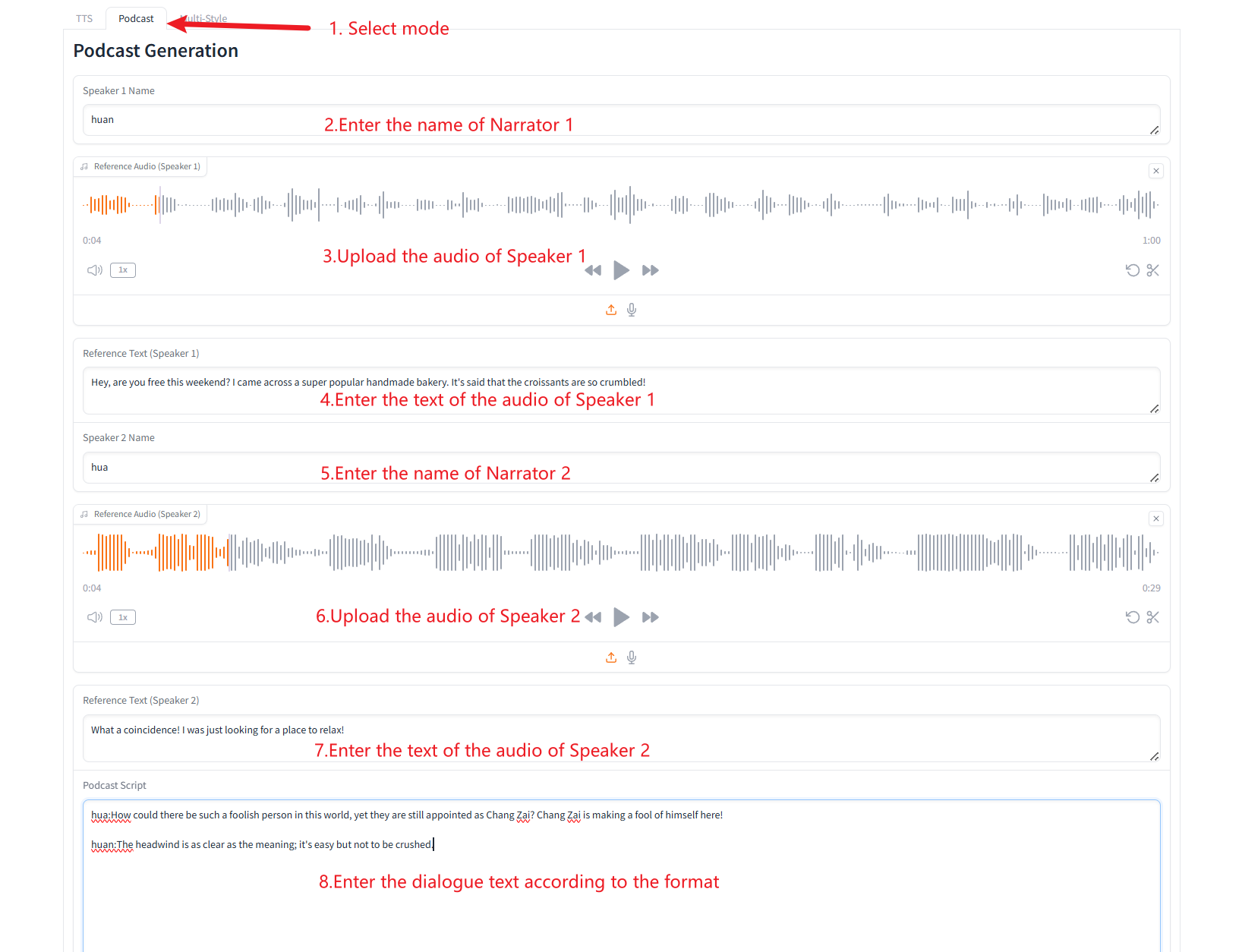
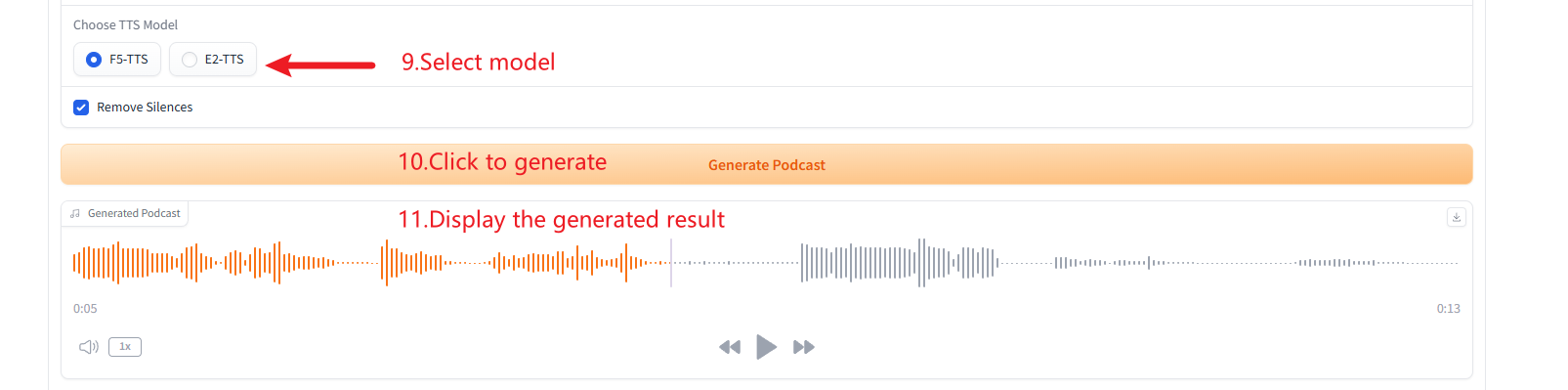
3. 複数の音声タイプの生成
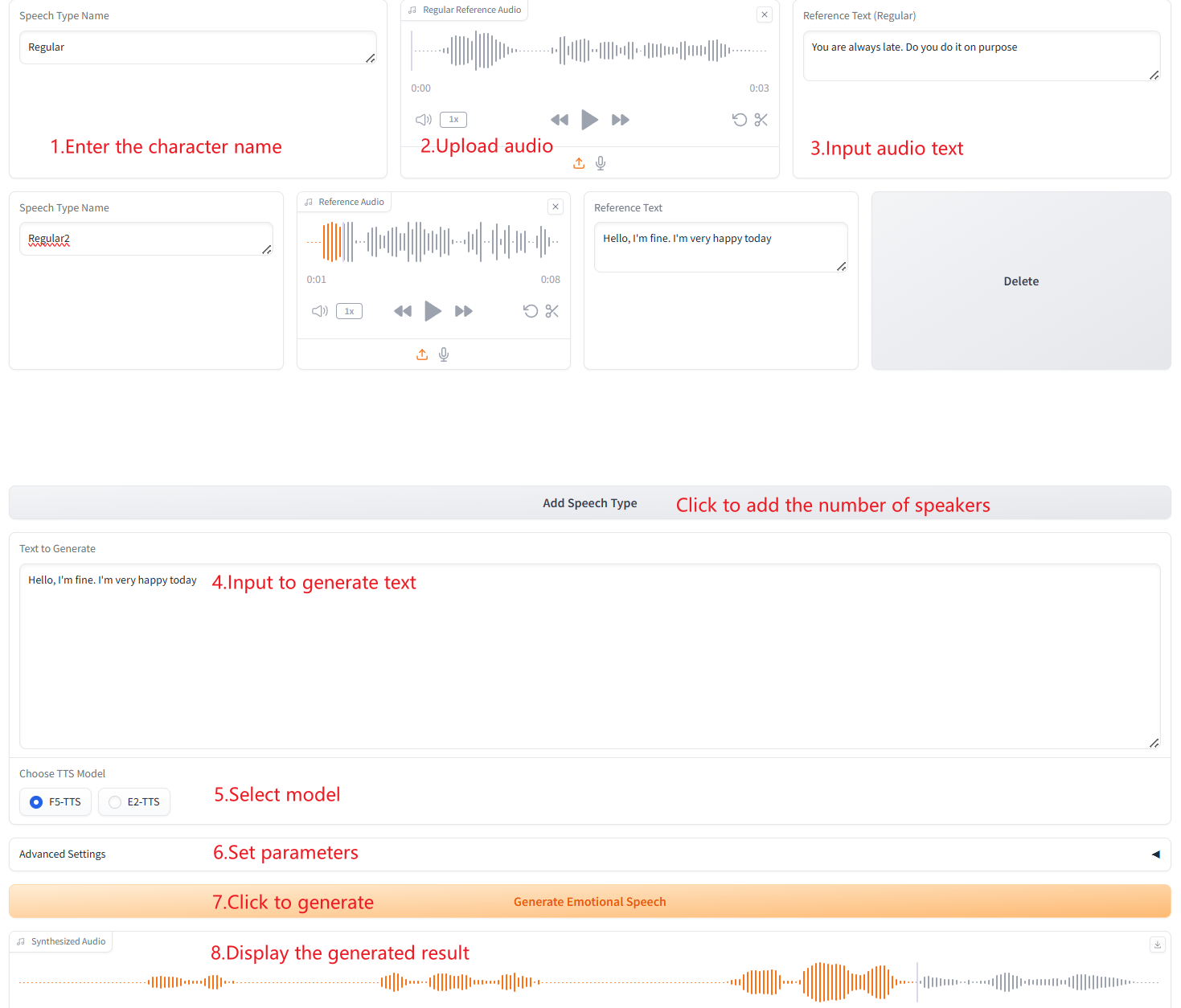
引用情報
@article{chen-etal-2024-f5tts,
title={F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching},
author={Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen},
journal={arXiv preprint arXiv:2410.06885},
year={2024},
}