HyperAI
HyperAI
メイン
ホーム
GPU
コンソール
ドキュメント
料金
パルス
ニュース
リソース
論文
ノートブック
データセット
Wiki
ベンチマーク
SOTA
LLMモデル
GPUランキング
コミュニティ
イベント
ユーティリティ
検索
概要
利用規約
プライバシーポリシー
日本語
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
サインイン
HyperAI
Papers
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
HyperAI
HyperAI
メイン
ホーム
GPU
コンソール
ドキュメント
料金
パルス
ニュース
リソース
論文
ノートブック
データセット
Wiki
ベンチマーク
SOTA
LLMモデル
GPUランキング
コミュニティ
イベント
ユーティリティ
検索
概要
利用規約
プライバシーポリシー
日本語
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
サインイン
HyperAI
Papers
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
GUI-Libra:アクション認識型の監督と部分検証可能なRLを用いたネイティブGUIエージェントの推論・実行訓練
監視付き微調整
エージェント
Rui Yang, Qianhui Wu, Zhaoyang Wang, et al.
SkyReels-V4:マルチモーダルな動画・音声生成、インペインティングおよび編集モデル
テキストから動画
拡散モデル
Guibin Chen, Dixuan Lin, Jiangping Yang, et al.
ARLArena:安定したエージェント強化学習を実現する包括的フレームワーク
強化学習
LLM
Xiaoxuan Wang, Han Zhang, Haixin Wang, et al.
DreamID-Omni:制御可能かつ人間中心型音声・映像生成のための統合枠組み
マルチモーダル
Any-to-Any
Xu Guo, Fulong Ye, Qichao Sun, et al.
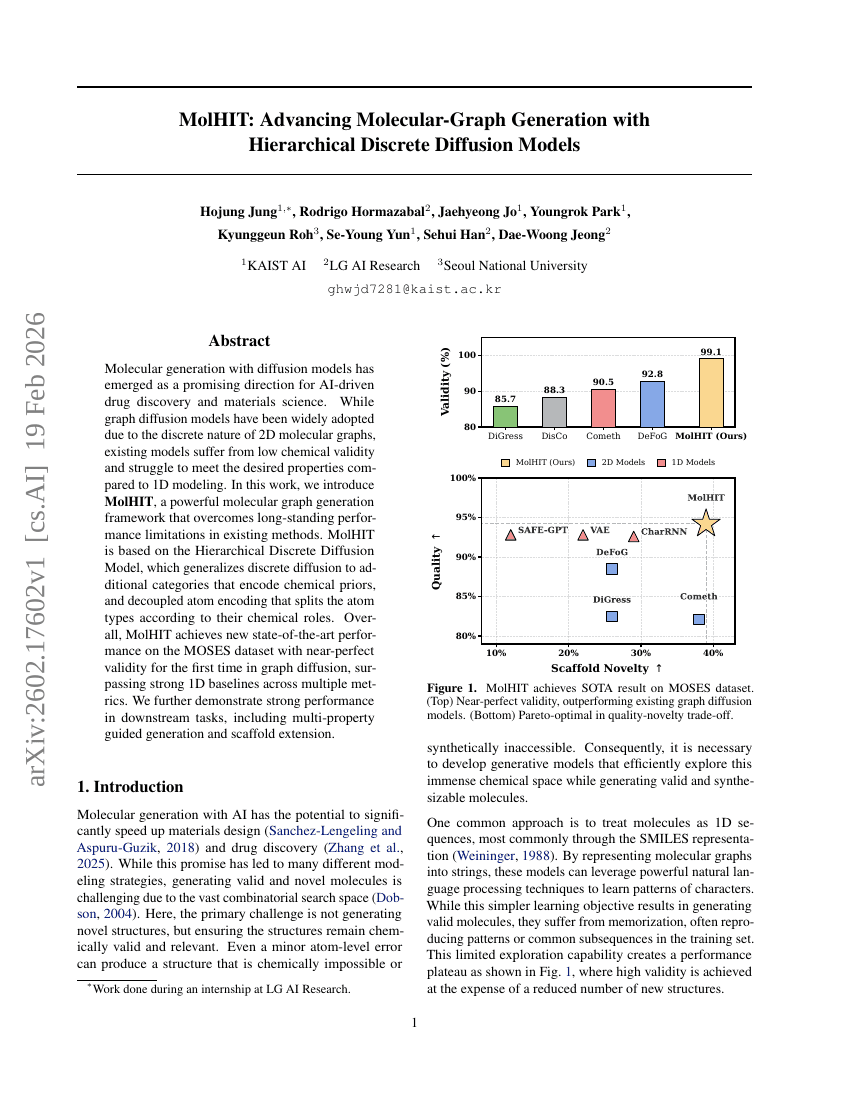
MolHIT:階層的離散拡散モデルによる分子グラフ生成の進展
拡散モデル
サイエンスのためのAI
Hojung Jung, Rodrigo Hormazabal, Jaehyeong Jo, et al.
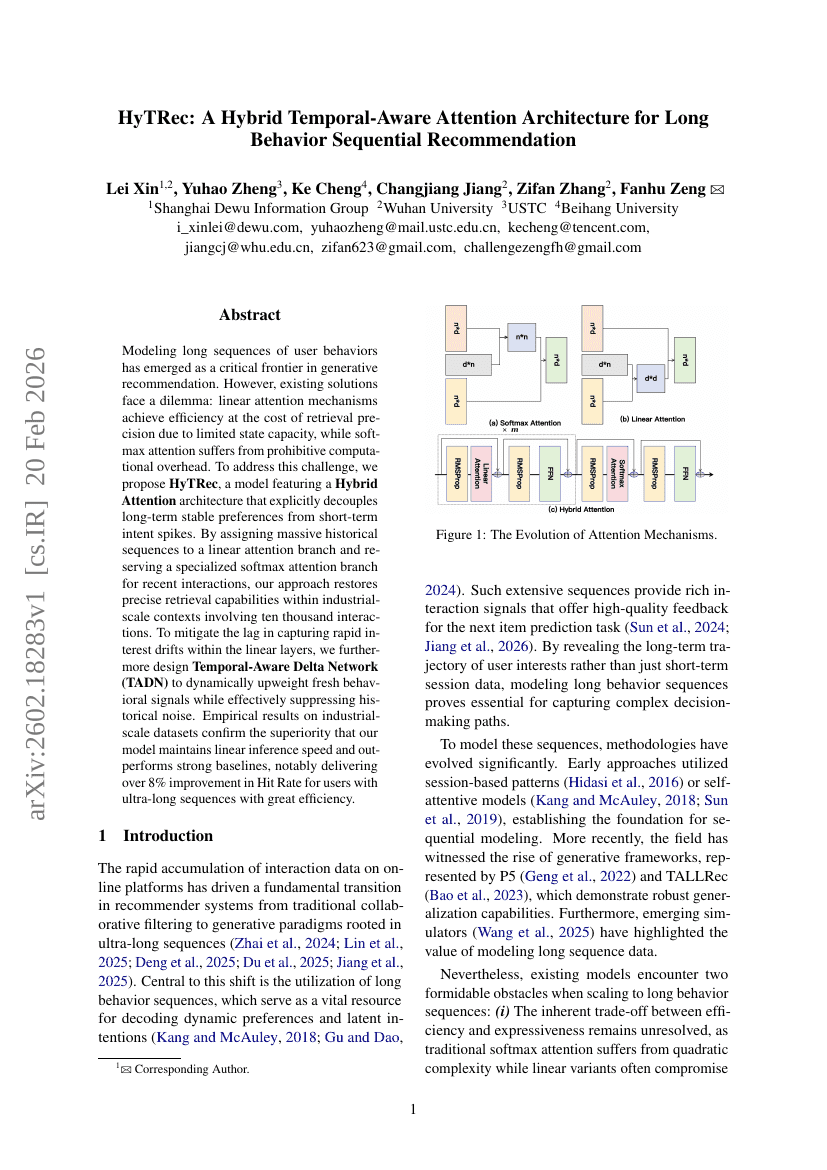
HyTRec:長期間行動順序推薦のためのハイブリッド時系列認識アテンションアーキテクチャ
Transformer
Preference Modeling
Lei Xin, Yuhao Zheng, Ke Cheng, et al.
DREAM:エージェンティックメトリクスを用いたディープリサーチ評価
ベンチマーク
LLM
Elad Ben Avraham, Changhao Li, Ron Dorfman, et al.
LongCLI-Bench:コマンドラインインターフェースにおける長期視野型エージェントプログラミングのための初期ベンチマークと研究
エージェント
ベンチマーク
Yukang Feng, Jianwen Sun, Zelai Yang, et al.
PyVision-RL:RLを活用したオープン型エージェント視覚モデルの構築
ビデオ理解
エージェント
Shitian Zhao, Shaoheng Lin, Ming Li, et al.
知覚から行動へ:視覚推論のためのインタラクティブベンチマーク
マルチモーダル
マルチモーダル表現
Yuhao Wu, Maojia Song, Yihuai Lan, et al.
クエリ中心型かつメモリ認識型リランカーによる長文脈処理
LLM
検索拡張生成
Yuqing Li, Jiangnan Li, Mo Yu, et al.
LLM端末機能のスケーリングのためのデータ工学
LLM
モデル学習
Renjie Pi, Grace Lam, Mohammad Shoeybi, et al.
DSDR:LLM推論における探索のためのデュアルスケール多様性正則化
強化学習
Reasoning
Zhongwei Wan, Yun Shen, Zhihao Dou, et al.
Mobile-O:モバイルデバイス上の統合的マルチモーダル理解と生成
マルチモーダル
拡散モデル
Abdelrahman Shaker, Ahmed Heakl, Jaseel Muhammad, et al.
TOPReward:ロボティクスにおける隠れたゼロショット報酬としてのトークン確率
強化学習
マルチモーダル表現
Shirui Chen, Cole Harrison, Ying-Chun Lee, et al.
ManCAR:順次推薦における多様体制約付き潜在的推論と適応的テスト時計算
Preference Modeling
マルチタスク学習
Kun Yang, Yuxuan Zhu, Yazhe Chen, et al.
VLANeXt:強力なVLAモデル構築のためのレシピ
マルチモーダル
マルチモーダル表現
Xiao-Ming Wu, Bin Fan, Kang Liao, et al.
非常に大きなビデオ推論スイート
ビデオ理解
Reasoning
Maijunxian Wang, Ruisi Wang, Juyi Lin, et al.
視覚情報ゲインを用いた大規模視覚言語モデルの選択的訓練
マルチモーダル
監視付き微調整
Seulbi Lee, Sangheum Hwang
DeepVision-103K:視覚的に多様で広範なカバーを備え、検証可能な多モーダル推論向けの数学データセット
マルチモーダル
視覚質問応答
Haoxiang Sun, Lizhen Xu, Bing Zhao, et al.
SARAH:空間認識型リアルタイムエージェント人間
マルチモーダル表現
3D生成
Evonne Ng, Siwei Zhang, Zhang Chen, et al.
EgoPush:モバイルロボット向けエゴセントリック多対象再配置のエンドツーエンド学習
認識
オブジェクト追跡
Boyuan An, Zhexiong Wang, Yipeng Wang, et al.
生成された現実:手とカメラ操作を用いたインタラクティブな動画生成による人間中心の世界シミュレーション
拡散モデル
動画生成
Linxi Xie, Lisong C. Sun, Ashley Neall, et al.
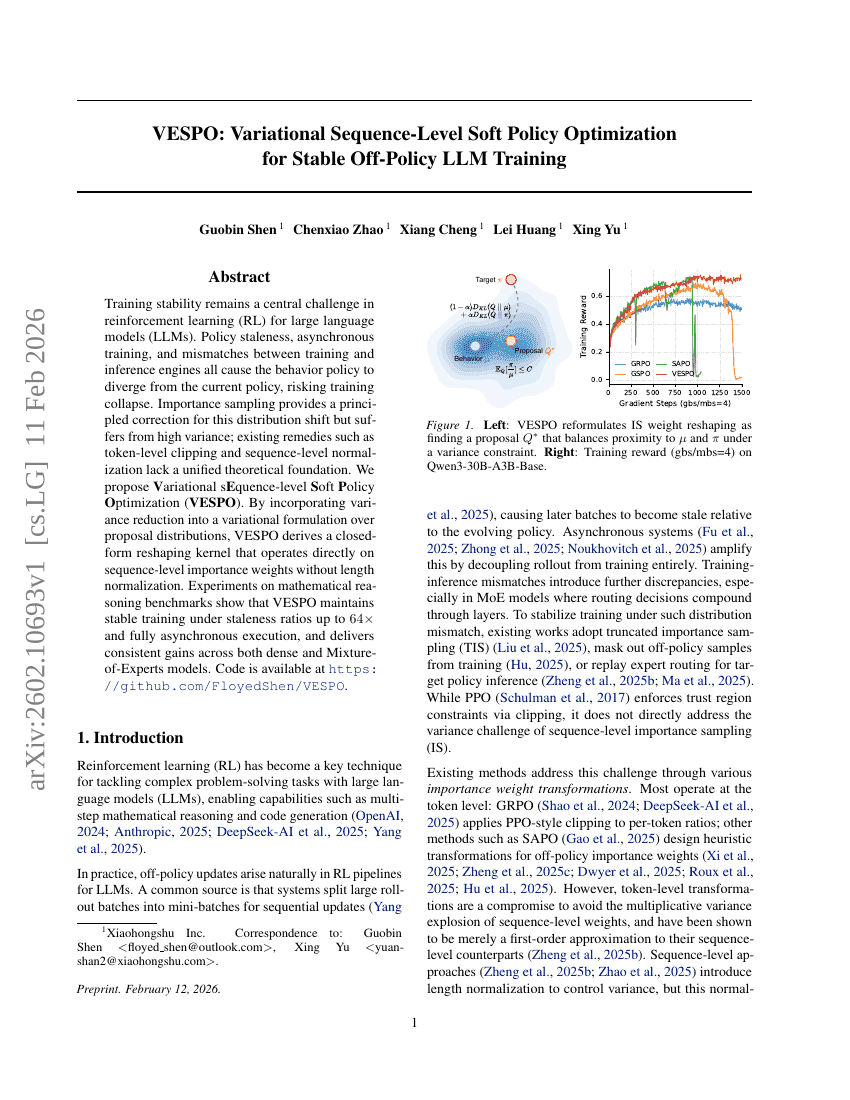
VESPO:安定したオフポリシー LLM 学習のための変分シーケンスレベルソフトポリシー最適化
強化学習
LLM
Guobin Shen, Chenxiao Zhao, Xiang Cheng, et al.
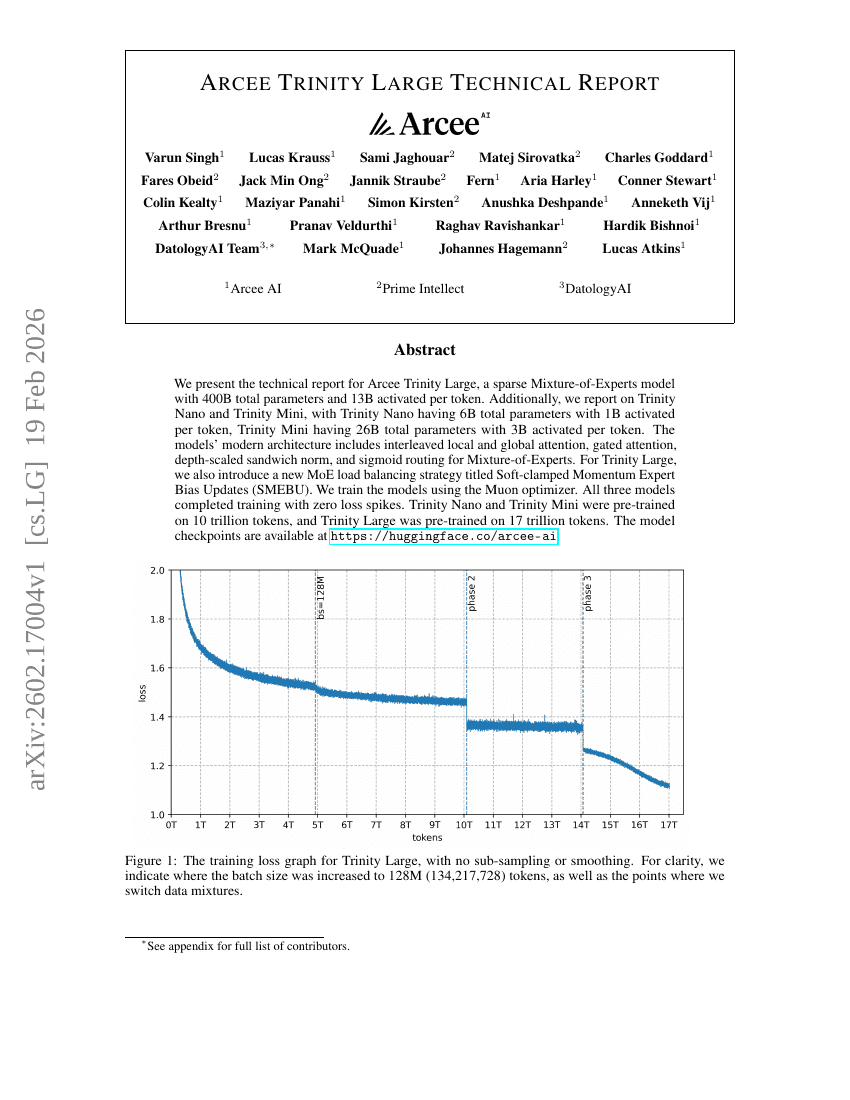
アーシー・トライニティ ラージテクニカルレポート
LLM
Transformer
Varun Singh, Lucas Krauss, Sami Jaghouar, et al.
実践におけるフロンティアAIリスク管理フレームワーク:リスク分析技術報告書 v1.5
LLM
エージェント
Dongrui Liu, Yi Yu, Jie Zhang, et al.
ユニファイド・ラテンス(UL):ラテンスをどのように訓練するか
拡散モデル
画像生成
Jonathan Heek, Emiel Hoogeboom, Thomas Mensink, et al.
Mobile-Agent-v3.5:マルチプラットフォーム基盤GUIエージェント
エージェント
LLM
Haiyang Xu, Xi Zhang, Haowei Liu, et al.
SpargeAttention2:ハイブリッドTop-k+Top-pマスキングおよび蒸留微調整を用いたトレーニング可能なスパースアテンション
拡散モデル
Transformer
Jintao Zhang, Kai Jiang, Chendong Xiang, et al.
AutoWebWorld:有限状態機械を用いた無限に検証可能なWeb環境の合成
エージェント
3D生成
Yifan Wu, Yiran Peng, Yiyu Chen, et al.
無限クライアントサーバーシステムに対するボーデッドモデルチェック
モデリング
ディープラーニング
Ramchandra Phawade, Tephilla Prince, S. Sheerazuddin
リトリーブ増強モデルはLLMに比べてどの程度の推論能力を追加するのか?ハイブリッド知識上のマルチホップ推論のためのベンチマーキングフレームワーク
検索拡張生成
ベンチマーク
Junhong Lin, Bing Zhang, Song Wang, et al.
1
2
3
4
51
GUI-Libra:アクション認識型の監督と部分検証可能なRLを用いたネイティブGUIエージェントの推論・実行訓練
監視付き微調整
エージェント
Rui Yang, Qianhui Wu, Zhaoyang Wang, et al.
SkyReels-V4:マルチモーダルな動画・音声生成、インペインティングおよび編集モデル
テキストから動画
拡散モデル
Guibin Chen, Dixuan Lin, Jiangping Yang, et al.
ARLArena:安定したエージェント強化学習を実現する包括的フレームワーク
強化学習
LLM
Xiaoxuan Wang, Han Zhang, Haixin Wang, et al.
DreamID-Omni:制御可能かつ人間中心型音声・映像生成のための統合枠組み
マルチモーダル
Any-to-Any
Xu Guo, Fulong Ye, Qichao Sun, et al.
MolHIT:階層的離散拡散モデルによる分子グラフ生成の進展
拡散モデル
サイエンスのためのAI
Hojung Jung, Rodrigo Hormazabal, Jaehyeong Jo, et al.
HyTRec:長期間行動順序推薦のためのハイブリッド時系列認識アテンションアーキテクチャ
Transformer
Preference Modeling
Lei Xin, Yuhao Zheng, Ke Cheng, et al.
DREAM:エージェンティックメトリクスを用いたディープリサーチ評価
ベンチマーク
LLM
Elad Ben Avraham, Changhao Li, Ron Dorfman, et al.
LongCLI-Bench:コマンドラインインターフェースにおける長期視野型エージェントプログラミングのための初期ベンチマークと研究
エージェント
ベンチマーク
Yukang Feng, Jianwen Sun, Zelai Yang, et al.
PyVision-RL:RLを活用したオープン型エージェント視覚モデルの構築
ビデオ理解
エージェント
Shitian Zhao, Shaoheng Lin, Ming Li, et al.
知覚から行動へ:視覚推論のためのインタラクティブベンチマーク
マルチモーダル
マルチモーダル表現
Yuhao Wu, Maojia Song, Yihuai Lan, et al.
クエリ中心型かつメモリ認識型リランカーによる長文脈処理
LLM
検索拡張生成
Yuqing Li, Jiangnan Li, Mo Yu, et al.
LLM端末機能のスケーリングのためのデータ工学
LLM
モデル学習
Renjie Pi, Grace Lam, Mohammad Shoeybi, et al.
DSDR:LLM推論における探索のためのデュアルスケール多様性正則化
強化学習
Reasoning
Zhongwei Wan, Yun Shen, Zhihao Dou, et al.
Mobile-O:モバイルデバイス上の統合的マルチモーダル理解と生成
マルチモーダル
拡散モデル
Abdelrahman Shaker, Ahmed Heakl, Jaseel Muhammad, et al.
TOPReward:ロボティクスにおける隠れたゼロショット報酬としてのトークン確率
強化学習
マルチモーダル表現
Shirui Chen, Cole Harrison, Ying-Chun Lee, et al.
ManCAR:順次推薦における多様体制約付き潜在的推論と適応的テスト時計算
Preference Modeling
マルチタスク学習
Kun Yang, Yuxuan Zhu, Yazhe Chen, et al.
VLANeXt:強力なVLAモデル構築のためのレシピ
マルチモーダル
マルチモーダル表現
Xiao-Ming Wu, Bin Fan, Kang Liao, et al.
非常に大きなビデオ推論スイート
ビデオ理解
Reasoning
Maijunxian Wang, Ruisi Wang, Juyi Lin, et al.
視覚情報ゲインを用いた大規模視覚言語モデルの選択的訓練
マルチモーダル
監視付き微調整
Seulbi Lee, Sangheum Hwang
DeepVision-103K:視覚的に多様で広範なカバーを備え、検証可能な多モーダル推論向けの数学データセット
マルチモーダル
視覚質問応答
Haoxiang Sun, Lizhen Xu, Bing Zhao, et al.
SARAH:空間認識型リアルタイムエージェント人間
マルチモーダル表現
3D生成
Evonne Ng, Siwei Zhang, Zhang Chen, et al.
EgoPush:モバイルロボット向けエゴセントリック多対象再配置のエンドツーエンド学習
認識
オブジェクト追跡
Boyuan An, Zhexiong Wang, Yipeng Wang, et al.
生成された現実:手とカメラ操作を用いたインタラクティブな動画生成による人間中心の世界シミュレーション
拡散モデル
動画生成
Linxi Xie, Lisong C. Sun, Ashley Neall, et al.
VESPO:安定したオフポリシー LLM 学習のための変分シーケンスレベルソフトポリシー最適化
強化学習
LLM
Guobin Shen, Chenxiao Zhao, Xiang Cheng, et al.
アーシー・トライニティ ラージテクニカルレポート
LLM
Transformer
Varun Singh, Lucas Krauss, Sami Jaghouar, et al.
実践におけるフロンティアAIリスク管理フレームワーク:リスク分析技術報告書 v1.5
LLM
エージェント
Dongrui Liu, Yi Yu, Jie Zhang, et al.
ユニファイド・ラテンス(UL):ラテンスをどのように訓練するか
拡散モデル
画像生成
Jonathan Heek, Emiel Hoogeboom, Thomas Mensink, et al.
Mobile-Agent-v3.5:マルチプラットフォーム基盤GUIエージェント
エージェント
LLM
Haiyang Xu, Xi Zhang, Haowei Liu, et al.
SpargeAttention2:ハイブリッドTop-k+Top-pマスキングおよび蒸留微調整を用いたトレーニング可能なスパースアテンション
拡散モデル
Transformer
Jintao Zhang, Kai Jiang, Chendong Xiang, et al.
AutoWebWorld:有限状態機械を用いた無限に検証可能なWeb環境の合成
エージェント
3D生成
Yifan Wu, Yiran Peng, Yiyu Chen, et al.
無限クライアントサーバーシステムに対するボーデッドモデルチェック
モデリング
ディープラーニング
Ramchandra Phawade, Tephilla Prince, S. Sheerazuddin
リトリーブ増強モデルはLLMに比べてどの程度の推論能力を追加するのか?ハイブリッド知識上のマルチホップ推論のためのベンチマーキングフレームワーク
検索拡張生成
ベンチマーク
Junhong Lin, Bing Zhang, Song Wang, et al.
1
2
3
4
51