Command Palette
Search for a command to run...
MIT は酵母 DNA の「言語」を学習する Pichia-CLM モデルを開発し、外因性タンパク質の収量を最大 3 倍に増やす可能性がある。

バイオ医薬品および産業バイオテクノロジーの分野において、組換えタンパク質の効率的な発現は、生産コストとプロセスの実現可能性を左右する重要な要素であり続けています。モノクローナル抗体やワクチン抗原から産業用酵素製剤に至るまで、発現レベルのわずかな増加でさえ、大きな経済的価値をもたらす可能性があります。
多くの表現系では、Pichia pastoris (Komagataella phaffii) は、高密度発酵能力、成熟した分泌発現システム、優れたタンパク質処理能力で高く評価されています。工業生産における重要な宿主の一つとなっています。しかし、アミノ酸配列が完全に同一であっても、コードDNA中の「同義コドン」を変更するだけで発現レベルが桁違いに異なる可能性があるという、長年にわたる産業界を悩ませてきた問題があります。
この現象はコドン使用バイアス(CUB)に起因します。多くの生物において、特定の同義コドンが優先的に使用されます。同義コドンの選択は、転写、mRNAの安定性、翻訳、タンパク質フォールディング、翻訳後修飾(PTM)、そして溶解性に影響を与え、タンパク質収量に影響を及ぼします。そのため、「コドン最適化」は外来タンパク質の発現における重要なステップとなっています。
現在、宿主CUBに基づく様々なコドン最適化ツールや手法が業界で開発されているが、これらの手法では依然として高い表現力を持つコンストラクトを安定して生成できない可能性がある。近年、人工知能、特に配列モデリング技術の発展により、研究者たちは遺伝子配列を一種の「言語」として捉え始めており、自然言語処理に似た手法を使って遺伝子配列内の暗黙のルールを学習しようとしている。
この文脈では、MIT の研究チームは、産業用宿主 Pichia pastoris のコドンを最適化し、組み換えタンパク質の収量を向上させるためのディープラーニングベースの言語モデル Pichia-CLM を提案しました。CUBメトリクス(通常は全体的なスコアのみを提供し、配列のコンテキストを無視する)に依存する従来の手法とは異なり、Pichia-CLMは宿主ゲノムデータを利用して、アミノ酸とコドンのマッピングをバイアスなく学習します。研究者らは、複雑性の異なる6つのタンパク質クラスでPichia-CLMを実験的に検証し、市販の4つのコドン最適化ツールと比較して、一貫して高い発現収率を確認しました。
「Pichia-CLM: Komagataella phaffii の言語モデルベースのコドン最適化パイプライン」と題された関連研究成果が PNAS に掲載されました。
研究のハイライト:
* Pichia-CLM は、宿主のゲノムデータを使用して、宿主の好みだけでなく、位置依存性や長距離のコンテキスト関係も考慮し、アミノ酸とコドンのマッピングを偏りなく学習します。
* Pichia-CLM は、複雑性の異なる 6 つのタンパク質で実験的に検証され、一貫して高い発現収率を示しました。
* モデルによって学習されたアミノ酸とコドンの埋め込みは、その物理化学的特性に応じてグループ化することができ、言語モデルが物理的に意味のあるパターンを捉えることができることを示しています。
用紙のアドレス:
https://www.pnas.org/doi/10.1073/pnas.2522052123
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「Pichia pastoris」と返信すると、完全な PDF を入手できます。
ピキア・パストリスを中心とした大規模配列データセットの構築
経験則に頼る従来の方法とは異なり、Pichia-CLMの核となる考え方は、宿主ゲノムから直接コーディングパターンを学習することです。この目的のために、研究チームは、Pichia pastoris を中心とした大規模な配列データセットを構築しました。
Pichia-CLMを訓練するために、研究者らはNCBIから2つのPichia pastoris変異体(CBS7435とGS115)のアミノ酸配列とコード配列データを収集した。これには、GS115、K. phaffii(NRRL Y11430)、およびK. pastorisのゲノム配列解析とアノテーションを含む、研究室で以前に完了したデータも追加された。合計で約 27,000 組のアミノ酸コード配列データが使用されました。
データ処理中に、研究者はアミノ酸とコドンをトークン化し、スターターを導入しました(…)。 )、終了( )と塗りつぶし(データセットはラベル付けされており、モデルが様々な長さのシーケンスを処理し、バッチトレーニングをサポートできるようにしています。さらに、データセットはトレーニングセットとテストセットに分割されており、約201 TP3Tを使用して、未知のデータに対するモデルの予測能力を評価しています。
このデータ構築手法は、人為的な「最適化目標」を導入せず、完全に天然ゲノムデータに基づいている点に注目すべきです。つまり、モデルは人為的に設定された近似ルールではなく、宿主の真の発現選好を学習し、その後のパフォーマンス向上の基盤を築きます。
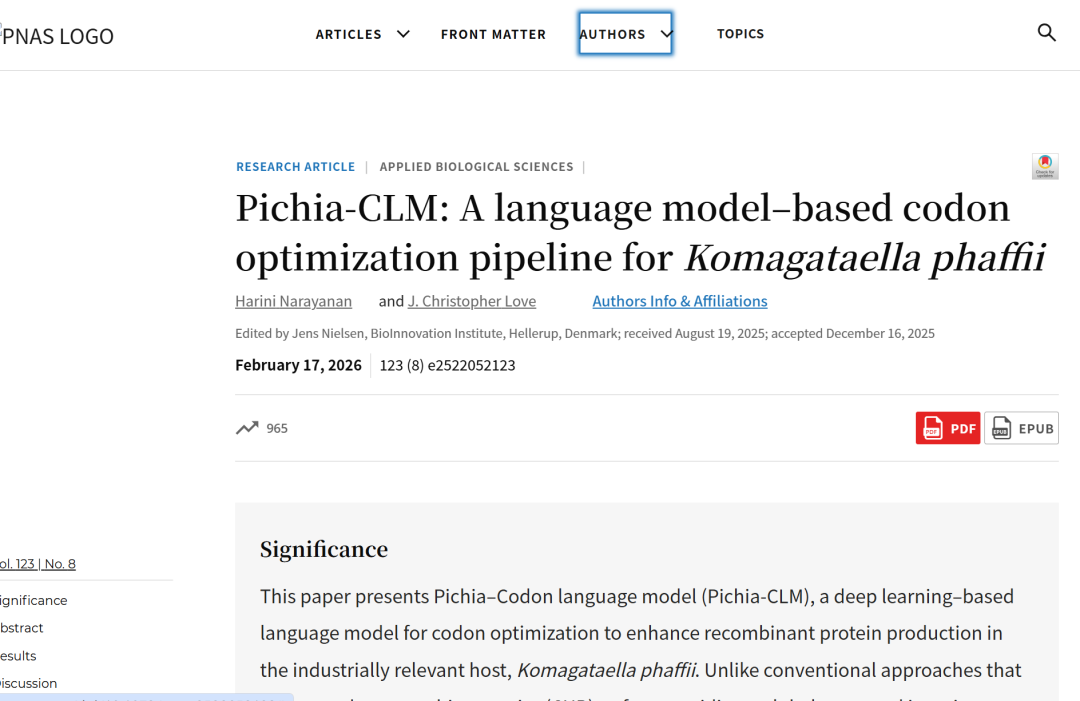
Pichia-CLM は、GRU ベースのエンコーダー/デコーダー アーキテクチャを採用しています。
モデルアーキテクチャ
Pichia-CLM は、ゲート再帰ユニット (GRU) に基づくエンコーダー/デコーダー アーキテクチャを採用しています。GRUは、シーケンスデータにおける長距離および短距離の依存関係を捉えるために設計された、改良されたリカレントニューラルネットワークアーキテクチャです。ゲーティングメカニズムを通じて情報の流れを制御することで、GRUは従来のRNNに共通する勾配消失問題を効果的に軽減します。さらに、GRUの性能はLong Short-Term Memory(LSTM)ネットワークに匹敵しますが、必要なパラメータ数と消費する計算リソースが少ないため、多くのシーケンスモデリングタスクにおいて効率性が大幅に向上します。
別の主流アーキテクチャである Transformer と比較すると、GRU は小規模から中規模のデータセットで計算効率が高く、リソース消費量が低くなります。研究によると、データ サイズが約 27,000 シーケンスの場合、Transformer を導入すると実際に不要な複雑さが増加する可能性がありますが、GRU を使用するとパフォーマンスと効率のバランスをより良く取ることができます。
このモデルは、タンパク質のアミノ酸配列を入力として受け取り、宿主のアミノ酸配列とコード配列から学習したパターンに基づいて、対応するDNA配列を生成します。全体的なアーキテクチャを下図に示します。
モデルのトレーニングプロセス
訓練中、研究者らはパラメータを最適化するために、検証セット(訓練セットの20%)を早期停止に使用しました。同時に、検証セットの損失(スパース分類クロスエントロピー)を最小化することを目的として、ハイパーパラメータの選択も行いました。ハイパーパラメータの最適化では、ベイズ最適化と呼ばれるグローバル最適化戦略と、研究者が内部的に実装したコードを組み合わせて使用します。
具体的には、このモデルには次のハイパーパラメータが含まれます。
* アミノ酸埋め込み次元
* コドン埋め込み次元
* エンコーダー層のユニット数
* デコーダー内のコドン完全結合層のサイズ
* デコーダー内のアミノ酸完全結合層のサイズ
モデルの学習中、デコーダーへの入力は実際にエンコードされた配列(つまり、実際のコドン)です。予測フェーズでは、モデルは前の位置で予測されたコドンを次の位置の入力として使用することで、完全な自己回帰予測を実現します。配列予測は、終止コドンに遭遇した時点で終了します。
アーキテクチャの選択とテストセットでの予測力の検証を完了した後、研究者らはデータセット全体を用いて最終モデルを再学習し、過学習を回避するために早期停止戦略を継続して採用しました。この最終モデルを用いて、外因性タンパク質のコード配列を設計しました。
Pichia-CLM は高タンパク質生産構造体を生成できます。
実験検証セクションでは、研究チームは、テスト対象として、以下の異なる複雑性レベルの 6 つのタンパク質を選択しました。
ヒト成長ホルモン(hGH)
* ヒト顆粒球コロニー刺激因子(hGCSF)
* VHHナノボディ3B2(34)
* 改変されたSARS-CoV-2 RBDサブユニット変異体(RBD)(35)
* ヒト血清アルブミン(HSA)
* IgG1モノクローナル抗体トラスツズマブ(トラスト)
ピキア・パストリスにおけるタンパク質分泌を促進するピキア-CLMの性能
初め、研究者らは、サイズと複雑さが異なる 3 つのヒト由来タンパク質 (hGH、hGCSF、HSA) を選択し、Pichia-CLM を使用して生成された遺伝子構築物とそのネイティブ コード配列間のタンパク質分泌収量 (力価) の違いを比較しました。全体的に、hGH や hGCSF などのタンパク質の場合、収量の増加は約 25% でしたが、HSA の場合は約 3 倍の大幅な増加が観察されました。
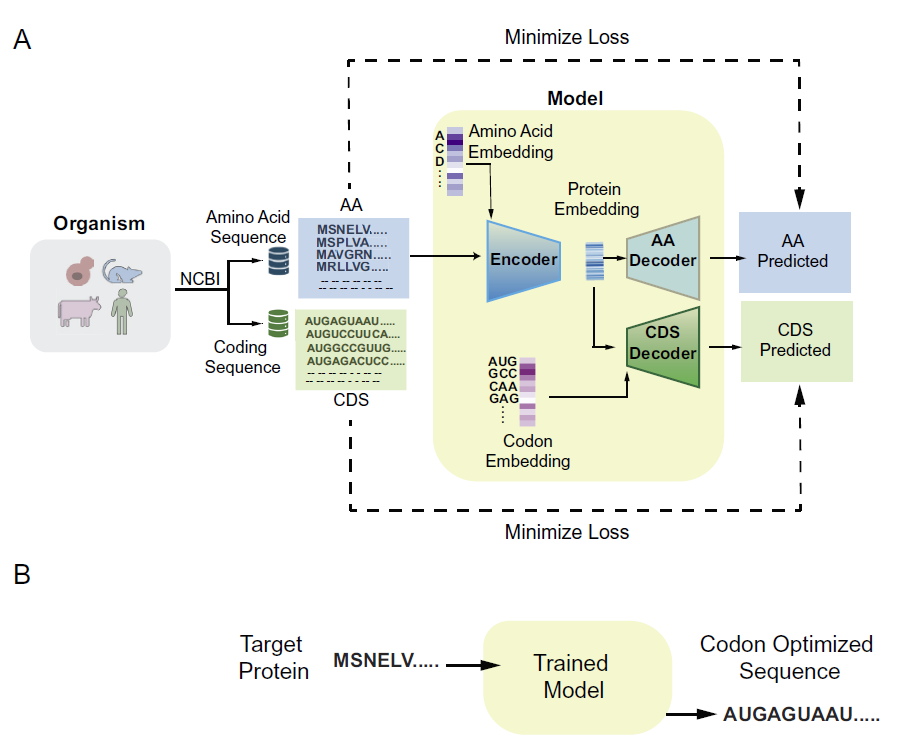
その後、研究者らは、Pichia-CLM を 4 つの市販コドン最適化ツール (Azenta、IDT、GenScript、Thermo Fisher (Thermo)) と比較し、2 つの指標を使用して 6 つのタンパク質を評価しました。
* BestTiter: 特定の方法で得られた最も高い力価を持つタンパク質の数。
* 集計スコア: さまざまなタンパク質の相対力価の合計 (最大値に正規化)。
全体、Pichia-CLM は、両方の測定基準において市販のアルゴリズムを上回りました (下の図 C)。6 つのタンパク質のうち 5 つで最高の力価を達成し、HSA では力価がわずかに低かったため、全体的なスコアがわずかに低下した (約 0.2) だけでした (下の図 D)。
遺伝子配列特性の評価
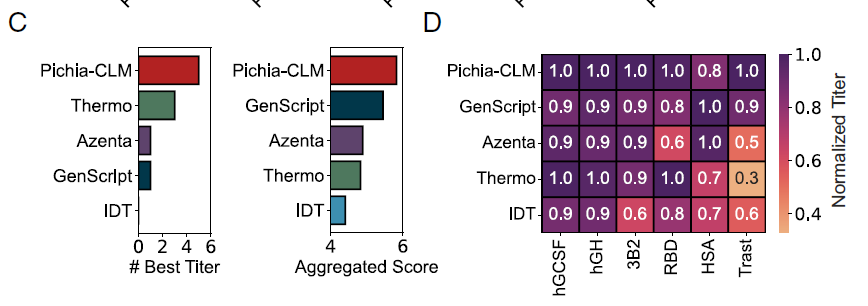
研究者らは、外来タンパク質の生産における Pichia-CLM の性能を検証した後、設計されたさまざまな構造物の遺伝子配列特性をさらに分析しました。報告されている他のタンパク質言語モデルを含め、コドン最適化は通常、設計または評価において1つ以上のコドン使用バイアス(CUB)指標に依存します。そのため、本研究では6つの試験タンパク質のデータを用いて、これらのCUB指標とタンパク質収量との相関関係を評価しました。
結果は、これらの指標のいずれも、異なるタンパク質間で収量と一貫して高い相関関係を示さなかったことを示しました。例えば、HSAの場合(下図A参照)、コドンボラティリティとコドン頻度分布(CFD)との最大正相関はわずか0.43であったのに対し、コドンペアスコア(CPS)との最大負相関はわずか0.25でした。
シーケンス全体に基づいて計算されたグローバル CUB メトリックには、外因性タンパク質の生成に関連する特徴を特徴付ける上で重大な制限があります。これは、多様なタンパク質の厳密な実験検証と組み合わせたコドン最適化ツールを評価するための新しい評価指標の必要性をさらに示しており、従来のコドン最適化の理論的基礎に直接疑問を投げかける結果となっています。
シーケンス特徴評価
研究者らはまた、さまざまなコドン最適化構造における負のシス調節要素の存在を評価した。この要素は宿主の調節機構に干渉する可能性があるため、外因性 DNA 配列では可能な限り回避する必要がある。
検査した6つのタンパク質のうち、Pichia-CLM を使用して設計されたコンストラクトでは、負のシス調節要素は検出されませんでした。対照的に、GenScript では 6 つのタンパク質のうち 3 つに 1 つの負のシス調節要素が含まれていました。Azenta と IDT では、少なくとも 1 つのタンパク質に 3 つから 4 つのそのような要素を含む配列を生成しました。図Bに示すように:
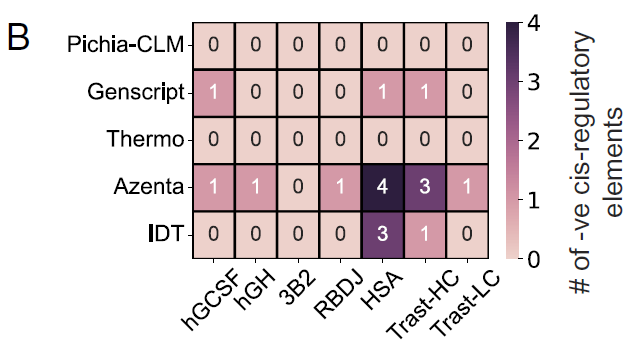
研究者らはまた、52 種類のバイオテクノロジー関連タンパク質における Pichia-CLM のパフォーマンスを分析し、次のような結果を示しました。75% のタンパク質配列には負のシス調節要素がまったく含まれませんが、残りの 25% にはそのような要素が最大 2 つ含まれています。対照的に、最も優れた性能を示す商用アルゴリズムである GenScript では、図 C に示すように、約 15% のタンパク質に 3 ~ 6 個の負のシス調節要素を含むコンストラクトが生成されました。
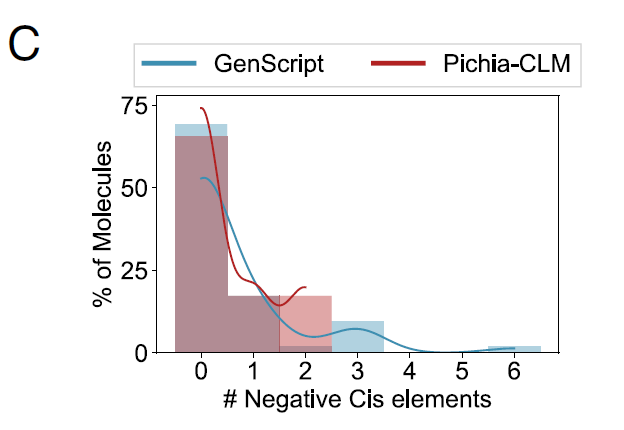
要約すると、これらの結果は、Pichia-CLM が高収量のタンパク質構造を生成できるだけでなく、重要な遺伝子配列の特徴を学習し、複数の因子間のバランスを実現して、宿主発現に適した堅牢なコード配列を設計できることを示しています。
AIがタンパク質生産の工業化を加速
バイオ医薬品業界において、タンパク質生産効率の向上は、研究開発の実用化と商業化の成否を左右する重要な要素であり続けています。モノクローナル抗体から組換えワクチン、そして様々な融合タンパク質や酵素製剤に至るまで、市場の需要は拡大を続けており、収量、安定性、一貫性に対する要求は絶えず高まっています。
この目標を達成するために、業界では多層的な最適化システムを開発しました。宿主レベルでは、従来の大腸菌やサッカロミセス・セレビシエに加え、優れた翻訳後修飾能力と発現効率を持つピチア・パストリスや哺乳類細胞が主流の生産プラットフォームとなっています。分子設計レベルでは、コドンの最適化に加え、プロモーター強度の調整、シグナルペプチドのスクリーニング、mRNAの構造工学、タンパク質の折り畳みと分泌経路の最適化などが行われます。プロセスレベルでは、高密度発酵、供給戦略の最適化、バイオリアクターのパラメータ制御も最終収量に決定的な役割を果たします。
このシステムの外では、新しいタイプの「脱細胞化」技術、無細胞タンパク質合成 (CFPS) が急速に登場しています。この技術は、細胞増殖プロセスを回避し、細胞溶解物中の転写・翻訳系を直接利用することで、迅速なタンパク質発現を実現します。抗体、酵素、さらには抗体薬物複合体の開発・製造において広く利用されています。しかし、CFPSシステム自体は、DNAテンプレート、酵素系、エネルギー供与体、アミノ酸、イオン環境など、数十もの構成要素を含む非常に複雑な多変量システムです。その組み合わせ空間は極めて広く、従来の経験に基づく最適化手法では、コストと収量の理想的なバランスを達成できないことがよくあります。
こうした背景から、AIを活用した自動最適化は破壊的な可能性を示しつつあります。最近、OpenAIは大手合成生物学企業Ginkgo Bioworksと共同で、画期的な研究成果を発表しました。GPT-5大規模言語モデル上に構築された「閉ループ自動化システム」は、無細胞タンパク質合成(CFPS)技術の二重最適化に成功し、技術の総生産コストを401 TP3T削減し、試薬コストを571 TP3T大幅に削減し、タンパク質合成力価を271 TP3T向上させました。
将来的には、同様のアプローチがより幅広いバイオ製造シナリオに拡大されるでしょう。細胞工場における代謝経路の最適化から、発酵プロセスのリアルタイム制御、発現構造のインテリジェント設計に至るまで、人工知能はタンパク質医薬品製造のあらゆる側面に徐々に組み込まれつつあります。
参考文献:
1.https://www.pnas.org/doi/10.1073/pnas.2522052123
2.https://phys.org/news/2026-02-ai-yeast-dna-language-boost.html#google_vignette
3.https://mp.weixin.qq.com/s/Qkl6j9HcFB7W_Y5Xh-9BCw








