Command Palette
Search for a command to run...
香港中文大学、浙江大学、マカオ理工大学のチームは、生物学的セマンティクスと化学的精度を統合し、350%による溶血性疾患予測の精度を向上させる汎用フレームワーク「Bi-TEAM」を提案した。

生化学および分子工学の分野において、特性評価学習は分子機能の解明と治療分子の発見を促進するための重要な技術となりつつあります。組み込まれた特徴量の品質は、ペプチド特性予測やde novo設計といった下流タスクのパフォーマンスの上限を決定することがよくあります。生物学的機能と化学的特性を繋ぐ中核分子として、ペプチド構造・機能モデリングは医薬品開発において重要な価値を有しています。近年、非古典的なアミノ酸の導入によりペプチドの機能空間が大幅に拡大し、その安定性と生物学的利用能が向上しましたが、複雑な化学修飾により従来のモデリング方法に新たな課題ももたらされています。生物学的進化情報と化学的合理性を同時にモデルに統合する方法は、この分野で早急に取り組む必要がある重要な課題になりつつあります。
現在、ペプチドモデリングは主に 2 つの技術的経路に沿って実行されています。一方では、ESM や ProtT5 などのタンパク質言語モデルは、大規模なシーケンスの事前トレーニングを通じて生物学的コンテキストと進化情報をキャプチャし、下流のタスクに転送可能な生物学的表現を提供します。一方で、非古典的なアミノ酸の改変の問題に対処するために、研究者は化学言語モデルを使用して、原子レベルの単語分割を通じて化学的詳細を捉え、化学レベルでのタンパク質モデルの欠点を補いました。
しかし、どちらのモデルにも固有の限界があります。タンパク質言語モデルは天然アミノ酸の文字セットに制限されるため、非古典的な残基の取り扱いが困難です。語彙を近似または拡張する既存の手法は、しばしばバイアスを導入したり、意味的スパース性をもたらしたりします。一方、化学言語モデルは全体的な生物学的文脈を無視しており、高密度な単語分割は容易に文脈ウィンドウを超えてしまうため、長い配列モデリングへの適応が困難です。一般的なモデルもドメインバイアスの影響を受けます。
上記の問題に対処するため、香港中文大学は、マカオ理工大学、浙江大学、中南大学湘雅第二病院、中国電子科学技術大学と共同で、選択的融合モデリングパラダイムを提案しました。「化学的変異は生物学的意味空間の局所的な摂動である」という理解に基づいて、局所的な化学的変異を全体的なタンパク質背景に注入するための一般的なフレームワーク Bi-TEAM が設計されました。
このフレームワークは、生物学的表現をセマンティックバックボーンとして用い、化学シグナルの適応的な注入を通じて、生物学的進化情報と化学的根拠を効果的に融合します。Bi-TEAMは複数のタスクにおいて、最先端のベースラインモデルを一貫して上回ります。骨格類似性に基づく厳密なデータ分割の下では、Matthews相関係数が最大661 TP3T向上し、溶血予測タスクでは精度が3501 TP3T向上します。
「Bi-TEAM: 化学的に修飾された生体分子のための統合クロススケール表現学習フレームワーク」と題された関連研究成果が、arXiv でプレプリントとして公開されています。
研究のハイライト:
Bi-TEAM フレームワークは、マルチスケールの生化学的特性を適応的に統合し、効率的なペプチド設計のための高忠実度の事前モデルとして機能します。
* 研究者らは、3 つの生化学領域にわたる 10 の多様なデータセットで Bi-TEAM を総合的に評価し、7 つの主要な予測タスクで最先端 (SOTA) のパフォーマンスを達成しました。
* このモデルは予測と生成のタスクで二重のブレークスルーを達成し、厳密なスキャフォールド類似性セグメンテーションで MCC を 66% 向上させると同時に、細胞浸透環状ペプチドの設計成功率をほぼ 4 倍に高めます。

用紙のアドレス:
https://arxiv.org/abs/2603.01873
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「Bi-TEAM」と返信すると、完全な PDF を入手できます。
3 つの主要な生化学分野と 10 の多様なデータセットを対象とした包括的な評価が実施されました。
この研究では、修飾ペプチド、翻訳後修飾 (PTM)、天然タンパク質という 3 つの主要な研究領域を網羅し、合計 10 個のデータセットを対象に、特性予測とガイド付き生成という 2 つの側面から特性を評価します。
修飾ペプチドの分野では、膜透過性を予測するモデルの能力を評価することに研究の焦点が置かれています。コアとなるトレーニングデータはProPAMPAデータベースから取得されます。このデータベースは12~46個の環原子を含み、配列長分布はほぼ正規分布ですが、両端に顕著なロングテールが見られます。また、天然および非古典的なアミノ酸残基を多数含み、高い化学的多様性を示しています。RDKitを用いた重複排除後、合計 6,876 個の非共役環状ペプチド配列が含まれています。
モデルの一般化能力を評価するため、本研究ではさらに3つの外部ウェット実験データセット(ProCacoPAMPA、CycPeptMPDB v1.2、Rezaiデータセット)を導入しました。これらのデータセットは、異なる長さと構造タイプの環状ペプチドサンプルをカバーしています。具体的には以下のとおりです。
プロカコパンパ:長さ 6 および 10 のすべての膜貫通環状ペプチド配列は既存の研究から収集され、標準化されたデータセットに構築されました。
サイクペプトMPDB v1.2:56本の論文からまとめられた、公開されている最大の非古典的環状ペプチド膜透過性データベースの最新版には、8,466件のレコードが含まれています。本研究では、研究者らはProPAMPAデータセットと重複するサンプルを除外し、最終的に1,230個のデータポイントを含む精緻化されたサブセットを取得しました。
レザイ:これには、11種類の環状ペプチドの受動膜透過性データが含まれています。これらのデータはPAMPA実験によって得られたもので、少量サンプル条件下での外部モデル検証によく使用されます。
モデルの薬剤類似性と疾患との関連性をさらに検証するために、研究者らは、PTM データセットで薬物類似性予測タスクを実施しました。使用されたデータは、医薬品グレードのデータセットと疾患関連データセットの2つのカテゴリーに分かれていました。前者は主に長いタンパク質配列で構成され、修飾部位は明確なロングテール分布を示していました。後者は主にdbPTMやゲノムワイド関連研究(GWAS)などのデータベースから取得され、修飾部位の分布は前者と類似していましたが、配列長の範囲が広く、より多様な構造的コンテキストを提供していました。
天然タンパク質の分野では、研究者らは、ペプチド溶血の主要なメカニズムとタンパク質溶解度の変化を探求するため、溶解度と溶血予測タスクにおけるモデルの性能評価に焦点を当てました。使用されたデータセットは主に、溶血、抗汚染、溶解度の3つのカテゴリーで構成されていました。
溶血データは DBAASP v3 データベースから取得されます。古典的な L 型アミノ酸で構成される合計 9,316 個の配列が含まれています。
公害防止データセットは主に短いペプチド配列で構成されています。長さは5~10アミノ酸残基に集中しており、LogP分布はほぼ正規分布に従う。サンプルは特徴空間において良好なクラスタリング構造を示している。
溶解度データセットは、PROSO II で注釈が付けられたタンパク質配列から得られます。このラベルは、Protein Structure Initiative の遡及的分析に基づいています。
Bi-TEAM: 化学的に修飾された生体分子のための統合されたクロススケール特性評価学習フレームワーク
Bi-TEAMは、既存の単一モードモデルが抱える、大域的な進化生物学的情報と局所的な化学構造の詳細(細粒度化学空間)を同時に捉えるという課題を解決することを目指しています。下図に示すように、その中心的なアイデアは、進化生物学的空間と化学構造空間を深く統合する二重視点の表現システムを構築することです。これにより、非古典的なアミノ酸を含むペプチド配列のより正確なモデリング機能が提供されます。
全体的なアーキテクチャに関しては、このモデルは、タンパク質言語モデルによって構築された生物学的空間を意味のバックボーンとして使用し、大規模な自然配列から学習した進化のルールとコンテキスト関係を最大限に活用します。一方、化学言語モデル(CLM)は、原子レベルの構造情報を捉えるために導入され、化学修飾を扱う際のタンパク質言語モデル(PLM)の固有の限界を補います。これら2種類のモデルは表現レベルで互いに補完し合い、入力配列の表現力を共同で拡張します。

修正されたペプチド配列を処理する際、Bi-TEAM は次の 2 つの補完的な情報ストリームを使用してそれらをエンコードします。1つは生物学的シーケンスストリームです。修飾アミノ酸は構造的に最も近い天然アミノ酸にマッピングされるため、単語分割テーブルの拡張が回避され、モデリングに使用できる進化的意味論が保持されます。もう1つは、SELFIESのような表現ストリームです。これは、修飾された残基の官能基の変化と化学結合構造を原子レベルで正確に記述するために使用され、化学言語モデルに安定した構造情報を提供します。
デュアルストリームエンコードが完了したら、このモデルは、位置認識装飾キューによって誘導されるデュアルゲート残差メカニズムを使用して融合されます。生物学的表現をセマンティックバックボーンとして用い、主要な化学シグナルはゲーティングユニットを用いてフィルタリングおよび注入されますが、生物学的特徴の残余のつながりは保持されます。これにより、モデルは学習の安定性を維持しながら、全体的な配列制約と局所的な化学変化の間に効果的な相関関係を確立することができます。
アプリケーションレベルでは、Bi-TEAM は優れた汎用性を備えています。改変されていない天然のタンパク質配列を処理する場合、モデルはマッピングとローカリゼーションの手順を直接省略できるため、全体的なアーキテクチャを調整することなく、日常的なタンパク質タスクに適応できます。
トレーニング戦略に関しては、この研究では、「事前トレーニングと微調整」という2段階のフレームワークを採用しています。まず、2種類の基本エンコーダーに対し、天然タンパク質配列と低分子化学コーパスそれぞれについてドメイン適応型の事前学習を実施しました。次に、マルチタスク共同微調整により、モデルは異なるタスクシナリオにおける生物学的特徴と化学的特徴の融合規則を学習し、全体的な汎化能力をさらに向上させました。
Bi-TEAMは浸透性環状ペプチドの設計において画期的な進歩を達成し、成功率を4.6倍に向上させました。
本研究では、Bi-TEAMの未知の化学空間への応用可能性を検証するため、非侵襲性薬物送達をシナリオとして、血管新生性加齢黄斑変性症(nAMD)の細胞透過性治療のための非典型的な環状ペプチド設計に焦点を当てています。本研究では、「予測誘導解析」の全プロセス実験を体系的に実施し、特性誘導分子設計におけるモデルの性能を評価しました。
nAMDは高齢者における不可逆的な失明の主な原因であり、その中核病態はVEGF誘導性の脈絡膜新生血管および漏出です。現在、臨床治療は主に高分子抗VEGF薬(アフリベルセプト、115kDなど)の硝子体内注射に依存しています。しかし、これらの薬剤は眼の生理的バリアを通過するのが難しく、長期の注射は合併症やコンプライアンスの問題を引き起こす可能性があります。アフリベルセプトに特異的に結合し、その透過輸送を促進するペプチド結合剤の設計は、非侵襲性点眼療法の新たな可能性をもたらすと考えられます。半減期が短く分解しやすい直鎖状ペプチドと比較して、より安定した構造と高い透過性を持つ環状ペプチドは、より理想的な送達キャリアと考えられており、これが研究者が環状ペプチドの設計に注力する主な動機となっています。
この研究では、まず細胞透過ペプチド (CPP) の予測と評価を実施し、その後の生成タスクの基礎を築きました。データセットはpLM4CPP標準スキームに従って構築され、CPPsite2.0、C2Pred、CellPPDなどのデータベースを統合しました。スクリーニングと重複除去の後、1,399個の陽性サンプル(実験的に検証された透過性ペプチド)と4,080個の陰性サンプルが得られました。比較モデルには、SeqVec、ESM2、ProtT5などの主流のタンパク質埋め込みモデルが含まれ、評価指標にはACC、BACC、Sn、Sp、MCC、AUCが使用されました。
結果は、Bi-TEAM がすべての指標で最高のパフォーマンスを達成したことを示しています。ACCはSeqVecと比較して5.521 TP3T、BACCはESM2-480と比較して5.881 TP3T、Snは12.581 TP3T、SpはProtT5-XL BFDと比較して1.451 TP3T、MCCはSeqVecと比較して14.681 TP3T、AUCはESM2-480と比較して8.451 TP3T向上しました。感度とMCCの大幅な向上は、このモデルが真の透過性ペプチドの同定において明確な優位性を持っていることを示しています。
この基盤を基に、特性に基づいた環状ペプチド生成実験に関するさらなる研究が行われます。BoltzDesign1 をベースライン フレームワークとして使用し、長さ 10 ~ 20 の環状ペプチド 1,000 個を 2 つの条件で生成しました。1 つはデフォルトの構造制約のみを使用する条件、もう 1 つは生成プロセス中に追加の勾配ガイドとして Bi-TEAM を導入する条件です。
成功基準は、Bi-TEAM予測の対数オッズが0.5を超えることでした。結果は…従来の方法では細胞浸透性環状ペプチドの生成成功率はわずか 6.71 TP3T でしたが、Bi-TEAM 誘導法ではこれが 30.71 TP3T に向上しました。一方、構造品質は低下せず、生成されたペプチド-アフリベルセプト複合体の平均 pLDDT は 0.82 を超えており、モデルは浸透を改善しながらも良好な構造信頼性と結合インターフェース安定性を維持していることを示しています。

ガイダンス機構を解明するため、研究者らは生成された配列の残基パターンをさらに解析した。これまでの研究で、トリプトファン(W)、フェニルアラニン(F)、チロシン(Y)からなる疎水性トリプレット、およびアルギニン(R)やリジン(K)などの正電荷残基が、細胞透過性ペプチドが膜輸送を達成するための重要な特徴であることが示されていた。
分析の結果、Bi-TEAM のガイドにより、生成された配列内の疎水性トリプレットと 2 つの正に帯電した残基の共起頻度が大幅に増加し、残基数の分布も一貫した傾向を示しました。このエンリッチメントパターンは、膜透過性ペプチドの既知の構造機能則と非常に一致しており、Bi-TEAMは関連する生物学的メカニズムを捉えるだけでなく、生成プロセスにおいて膜透過性を持つ配列の確率を大幅に高めることができることを示しています。さらに、制御変数分析によりペプチドの長さ(10~20残基)の影響が排除され、このモデルがサンプル分布を膜輸送にとってより好ましい化学生物学的共存空間へと誘導していることが示されました。
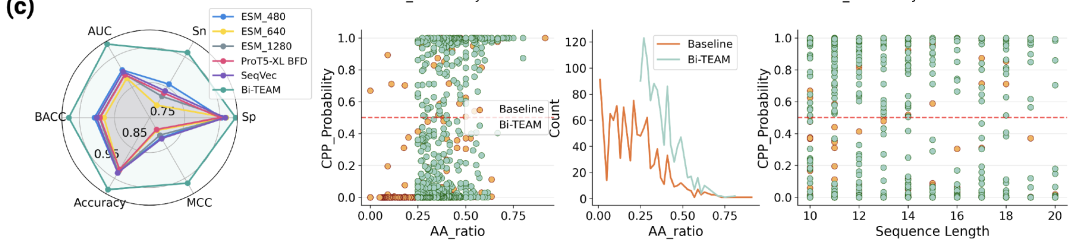
中央のセクション:主要な疎水性残基の存在量と浸透確率の関係。
右:環状ペプチドの長さと浸透確率の関係
最後に、本研究ではケーススタディを通じて構造レベルでの結果を検証しました。研究者らはまず、アフリベルセプト二量体の三次元構造を可視化し、静電ポテンシャルに基づいて分子表面を色分けしました。次に、AlphaFold3を用いて、アフリベルセプトを含む環状ペプチドの複合構造を予測・設計しました。解析の結果、環状ペプチド結合ポケットとして2つの可能性が特定されました。1つは3つの環からなる疎水性空洞、もう1つは環構造とβシートフラグメントからなる空洞です。この構造情報は、その後の環状ペプチドの最適化と潜在的な臨床応用にとって重要な基盤となります。

ペプチド医薬品開発分野における技術革新に焦点を当てる
ペプチド科学の分野では、基礎研究から臨床応用まで、世界中の多くの研究機関が主要な疾患を克服するための新しい技術的経路と治療オプションを積極的に模索しています。
たとえば、英国ブリストル大学生化学学部の構造生物学チーム。クライオ電子顕微鏡やX線結晶構造解析などの先進技術を用いて免疫系の微細構造を解析し、それに基づいて構造誘導ペプチド医薬品の設計を行っています。彼らは、ヒトの補体系を正確に活性化できる環状ペプチド分子を設計することで、自己免疫疾患の治療のための次世代の候補薬の開発を試みています。
一方、キングス・カレッジ・ロンドンとザグレブ大学の共同プロジェクトであるToxiCodeプロジェクトは、動物の毒から新しい薬を発見する独自の道を模索している。このプロジェクトは、人工知能と合成生物学を組み合わせ、ハイブリッド AI システムを使用してペプチド配列パターンとその構造活性相関を学習し、がん、神経疾患、感染症を標的とした新しい生理活性ペプチドの迅速な設計を可能にします。これにより、持続可能かつ倫理的な医薬品発見のための新しい方法論的枠組みが提供されます。
これは、ペプチド医薬品開発が徐々に新たな研究パラダイムを形成しつつあることを示しています。構造生物学、人工知能、ケミカルバイオロジーの融合が進み、基礎研究と産業開発の境界はますます曖昧になっています。新しい分子はしばしば学際的な技術の組み合わせから生まれますが、臨床応用に至るかどうかを真に決定づけるのは、実験室での発見から産業化へと徐々に確立されつつあるトランスレーショナルパスウェイです。このプロセスにおいて、ペプチド分子は、小分子と大分子の中間に位置する独自の特性により再評価され、ますます多くの疾患領域で新たな応用が示されています。
参考リンク:
1.https://www.bristol.ac.uk/news/2025/november/bristol-researcher-awarded-over-850000-to-develop-new-treatments.html
2.https://www.kcl.ac.uk/news/kings-to-collaborate-in-venom-based-drug-discovery-project
3.https://mp.weixin.qq.com/s/X67D1qrUzclwOsJ9cKUtZg








