Command Palette
Search for a command to run...
洪水予測性能は米国国立気象局に匹敵する。知識誘導型機械学習モデルFHNNは、リアルタイムの観測データを組み合わせることで予測精度を向上させる。

洪水は世界で最も一般的かつ広範囲に及ぶ自然災害の一つであり、社会経済発展と公共の安全にとって長期的な脅威となっています。気候変動により豪雨の頻度が増加するにつれ、多くの地域で洪水リスクは著しく上昇傾向にあります。正確かつタイムリーな洪水予報は、災害予防と軽減に不可欠な情報を提供するだけでなく、水資源配分、都市管理、農業生産における重要な意思決定支援にもなります。
長らく、洪水予測は主に物理過程モデル(PBM)に依存してきた。水循環理論に基づき、降水量、蒸発量、土壌水分量の変化、地下水涵養量、河川合流点などのプロセスをシミュレーションすることで、流出量の変化を予測する。例えば、米国国立気象局が広く使用しているサクラメント土壌水分収支モデル(SacSMA)は、典型的な流域水文モデルです。物理モデルは明確な科学的根拠を持ち、水文研究や運用予測において重要な役割を果たします。しかし、これらのタイプのモデルは通常、複雑なパラメータ較正を必要とし、強い非線形特性を持つ水文過程においては、シミュレーション能力が制限されることが多い。
近年、水文学の分野ではAI技術が急速に発展しており、特に深層学習モデルを用いた流出予測の応用がますます広まっている。長短期記憶(LSTM)ネットワークなどの時系列ニューラルネットワークは、大量の過去データから複雑な降雨流出関係を学習することができ、多くの研究で従来モデルよりも優れた予測能力を示している。
しかし、純粋にデータ駆動型のモデルにも新たな課題が存在します。一方では、これらのモデルは物理的な解釈可能性に欠け、実際の水文過程を反映するのに苦労することが多く、他方では、極端な気候現象や観測されていない流域における一般化能力は依然として不確実です。そのため、水文学分野では新たな研究アプローチが徐々に生まれつつあります。これは、機械学習モデルにドメイン知識を統合し、高い予測精度と物理法則への適合性を兼ね備えたインテリジェントなモデルを構築することを意味します。この方向性は「知識誘導型機械学習(KGML)」として知られています。
こうした背景のもと、ミネソタ大学ツインシティ校の研究チームは、知識に基づいた新しい機械学習モデルを開発した。このモデルのアルゴリズム構造は水文学から直接着想を得ており、因子化階層型ニューラルネットワーク(FHNN)と呼ばれています。研究によると、予報発表後2~7日という期間において、このモデルは米国気象局の洪水予報と同等かそれ以上の性能を発揮し、物理科学の知識を構造に組み込んでいない主流の機械学習手法よりも優れた性能を示すことが分かっている。
「知識誘導型機械学習による洪水予測の実用化」と題された関連研究成果は、『Water Resources Research』誌に掲載された。
研究のハイライト:
* 提案手法は、逆モデルを通して観測情報を統合し、階層的なマルチスケール流域状態表現を構築する。
* 予測生成後12~18時間経過すると、FHNNモデルは一般的に、物理メカニズムモデルを使用する専門家による予測よりも優れた結果を示した。
* 提案手法は、特に他の手法では予測が難しいことが多い乾燥流域において、最先端の代替モデル(自己回帰LSTM)よりも優れた性能を発揮します。

用紙のアドレス:
https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2024WR039064
弊社の公式WeChatアカウントをフォローし、バックグラウンドで「FHNN」と返信すると、PDF全文を入手できます。
データセット:ベンチマークデータセットとビジネスデータセットのバランス調整
モデルの予測能力を検証するために、研究者たちは2種類のデータセットを使用した。
大規模サンプルCAMELS-USベンチマークデータセット
モデルのトレーニングおよび基本評価段階では、よく知られているCAMELS-USデータセットが使用されました。CAMELS(Catchment Attributes and Meteorology for Large-Sample Studies)は、近年の水文学研究において最も影響力のあるデータセットの1つであり、その中核的な特徴は、流域からの長期にわたる大量の水文および気象観測データを含んでいることです。 CAMELS-USデータセットは、米国本土の数百の流域を網羅しており、降水量、気温、蒸発散量、河川流量に関する日周期データに加え、豊富な流域属性情報も提供しています。例えば、地形、気候の種類、土壌の状態、植生被覆など。これらの情報は、さまざまな環境条件下における水文過程を研究するための重要な基礎となる。
この研究では、研究者たちは、実験対象として531の流域を選定した。データは、時間的な順序に従って、トレーニング、検証、テストの各フェーズに分割されます。
* 1985年~1993年は研修期間
* 検証期間:1993年~1995年
* 1995年~2005年は試験期間
ビジネス向け洪水予測データ
本研究では、標準データセットに加えて、実際の洪水予測環境におけるモデルの性能を検証するために、実際の運用洪水予測データも導入した。本研究では、国立気象局北部・中部河川予報センター(NCRFC)の管轄下にある複数の河川流域を事例研究として選定した。これらの流域は米国中西部に位置し、典型的な大陸性気候の特徴を備えており、豪雨による洪水と融雪による洪水の両方が発生するため、非常に代表的な地域と言えます。関連する水文データは主に米国地質調査所(USGS)による河川流量観測データから得られ、降水量や気温などの気象データは米国国立気象局の予報データベースから取得しています。
米国国立気象局の洪水予報システムは「複雑予報」モデルを採用していることに注目すべきである。このモデルでは、まず物理モデルが初期予報結果を生成し、その後、経験豊富な水文観測員がリアルタイムの観測と専門知識に基づいて調整を行い、最終的に公式予報を形成する。この方法は多くの場合、予報精度を大幅に向上させることができる。したがって、本研究では、人間の専門家による予測と自動化された機械学習モデルを比較することは、AIモデルが現実世界のビジネス環境でどの程度応用できるかを直接的に反映するため、非常に重要である。
モデルフレームワーク:知識誘導型アーキテクチャ FHNN
FHNNは、複数の時間スケールにわたる複雑な階層型システムダイナミクスプロセスをモデル化するために設計された、知識主導型のアーキテクチャです。
この階層的な相互作用構造は、流域の水文モデリングにとって極めて重要です。例えば、豪雨は地表付近の土壌水分貯留量を急速に変化させ、植物は蒸発散によってその水分を利用します。この蒸発散量は、時間単位、日単位、季節単位で変動する可能性があります。同時に、この降雨は、より深い土壌層を通して地下水貯留量を徐々に補充します。地下水貯留量の変化は通常、より緩やかです。さらに、地表付近の土壌水分貯留量は、降雨量や融雪量が洪水流出量にどれだけ変換されるかにも影響を与えます。
FHNN法は、水文学や流出生成において普遍的に見られる、こうした多段階的かつ階層的なプロセスを捉えることを目的としている。その全体的なアーキテクチャを以下の図に示す。
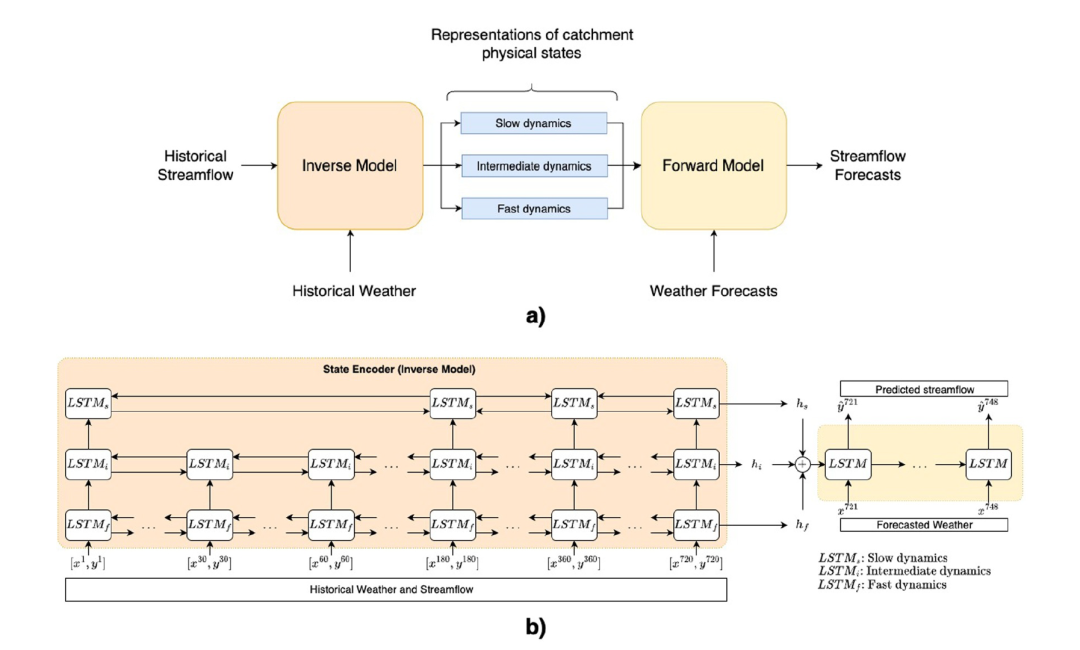
FHNNアーキテクチャでは、知識は2つの方法で導入されます。
方法1:エンコーダ・デコーダアーキテクチャの使用
このアプローチでは、状態エンコーダ(逆モデル)と応答デコーダ(順モデル)を用いて、順方向および逆方向のプロセスを明示的にモデル化します。エンコーダー部分は「逆モデル」とみなされ、その主な機能は、過去の気象データと流出データを用いて流域の現在の内部状態を推定することである。例えば、過去の降水量、気温、流出量の変化を分析することで、モデルは現在の土壌水分量や地下水貯留量といった重要な変数を推定できます。これらの変数は現実世界で直接観測することは困難ですが、機械学習の手法を用いることで効果的に推定できます。流域の状態を取得した後、モデルはデコード段階に入ります。
デコーダーは「順方向モデル」とみなされ、既知の流域状況と将来の気象予報に基づいて将来の流出量の変化を予測する役割を担う。
FHNNモデルは、予測データと実際の応答データの差を最小限に抑えるために、エンドツーエンドで学習されます。さらに、このアーキテクチャは、流出観測(応答)が得られるたびにエンコーダの状態をリアルタイムで更新し、動的なデータ統合を可能にします。
方法2:階層的因子分解設計によるFHNNアーキテクチャへの知識の導入
このデザインでは、FHNNのエンコーダーは、マルチスケールプロセスとその相互作用を捉えるように構築されている。階層型状態エンコーダは、複数の双方向LSTMを使用して、過去の流出観測データと気象データを入力として受け取り、異なる時間分解能/スケール(低速、中速、高速など)の埋め込みを生成します。
これらの埋め込みは、過去の運転データ、システム応答、およびそれらのマルチスケール相互作用(季節、サブシーズン、および日/サブデイスケール)に含まれる情報の圧縮表現を提供します。これらの埋め込みは、潜在的なシステム状態(土壌水分、空間接続性、積雪量など)の圧縮表現として連結され、デコーダの隠れ状態とユニット状態を初期化します。続いて、デコーダーは、将来の気象要因を入力として、河川流量予測を生成する。エンコーダーとデコーダーは、単一の目的関数を用いて共同で学習される。目的関数は、目標予測時間枠内における予測流出量と観測流出量との間の二乗平均平方根誤差(RMSE)を最小化する。
双方向LSTMは、両方向から同時にシーケンスを読み取ることで、エンコーダーが観測データ内の利用可能なすべての関係性を活用し、流域内の状態をより包括的に理解することを可能にします。このアプローチは水文学においても直感的に理解しやすい意味合いを持っています。例えば、研究者は降雨とその後の流出反応を観測することで土壌水分情報を取得できます。同様に、流出反応を最初に観測し、次にその事象を引き起こした降雨量を分析することで土壌水分状態を推測できます。双方向LSTMエンコーダーにより、モデルはこれら2つの「視点」から過去のデータを分析し、デコーダーの隠れ状態とセル状態を初期化するために使用される最終的な「最良推定値」を取得できます。
FHNNは、物理メカニズムモデルを用いる熟練した人間の予測者よりも全体的に優れた性能を発揮する。
研究者らは、複数の実験を通して、FHNNが水文予測において優れた予測能力を持つことを実証した。最初の実験では、大規模なCAMELSデータセットを用いて、FHNNと、同じ入力変数とデータ統合機能を備えた主要な深層学習手法であるLSTM-ARを比較した。2番目の実験では、運用予測環境におけるFHNNの性能に焦点を当て、米国中西部のNWS(米国気象局)公式予測サイトの性能を評価した。
LSTMモデルとの比較
CAMELS-USデータセットにおいて、FHNNは従来の自己回帰型LSTMモデル(LSTM-AR)と比較された。FHNNは、7日間の予測期間と全体的な予測の両方において、LSTM-ARを上回る性能を発揮する。両モデルとも1日予測データのみで学習させた場合でも、FHNNの方が優れた性能を示しました。総合的な性能は以下の表に示されています。
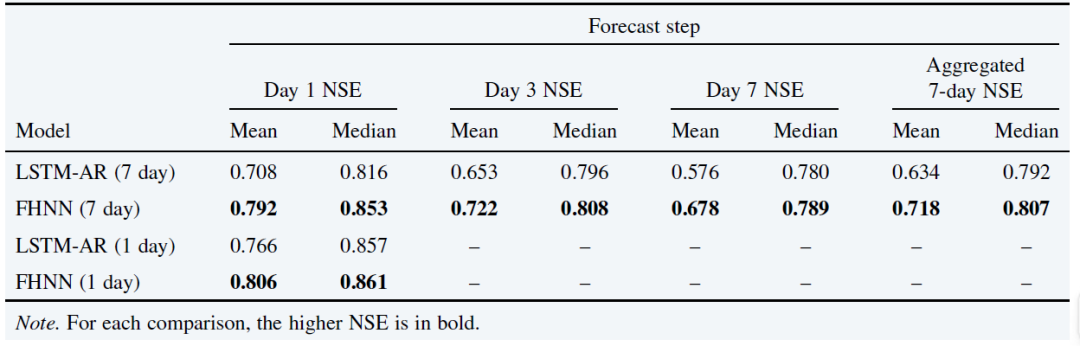
各流域のパフォーマンスの違いと特性との関係を分析することで、図表が作成された。研究者らはまた、降水量が少なく、流出係数が低く、干ばつレベルが高い流域では、FHNNがLSTM-ARよりも優れた性能を発揮することを発見した。以下に示すように:
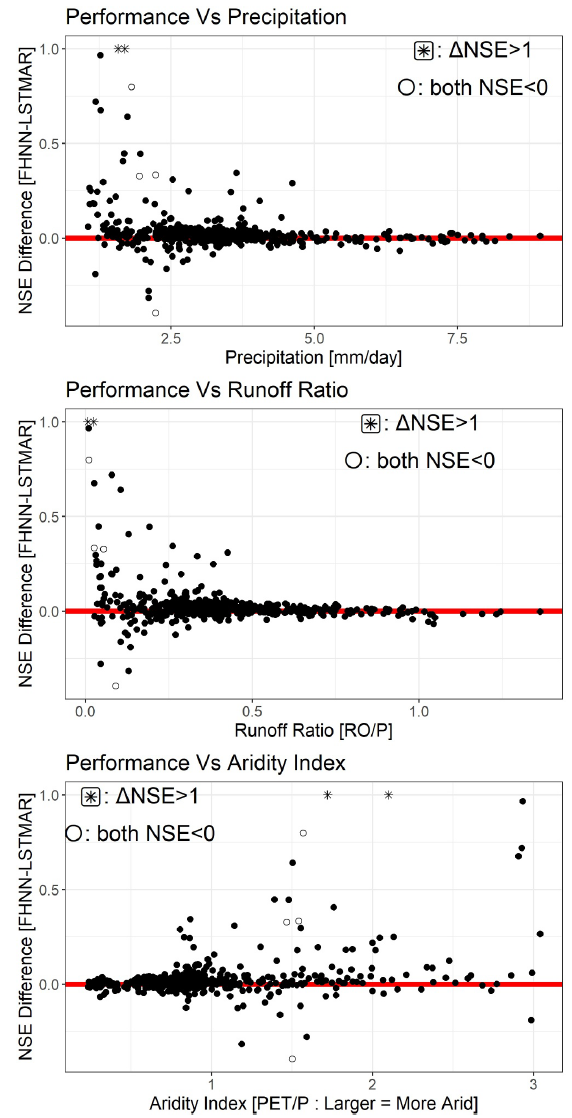
降水量、流出係数、干ばつ指数の関係
基底流量指数、潜在蒸発散量(PET)、流域勾配には明らかな傾向は見られなかった。この結果は、…乾燥した流域や、総流出量と総降水量の比率が低い流域では、FHNNはLSTM-ARよりも最大の性能上の優位性を示します。
研究者らはまた、NWSのKALI4流域においてFHNNとLSTM-ARを比較し、さらにNWSの専門予報官の予測能力と比較した(下図参照)。
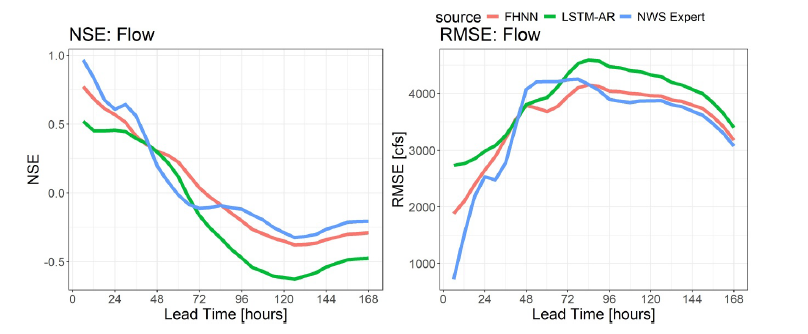
結果によると、予報が発表された翌日には、SacSMA モデルを使用する NWS の専門予報官の予測能力は FHNN および LSTM-AR よりも高いが、同じ期間内では、FHNNは依然としてLSTM-ARを凌駕しており、洪水発生時におけるデータ統合能力も優れている。2~4日以上の予測リードタイムにおいて、FHNNはNWSの予測やLSTM-ARと比較して、最も高い相対的予測能力を示す。
事業予測との比較
この研究では、実際に発生した46件の洪水事例も分析し、その結果は以下の通りである。FHNNは、65%イベントにおいて公式予測を上回る結果を示した。以下の表に示すように:
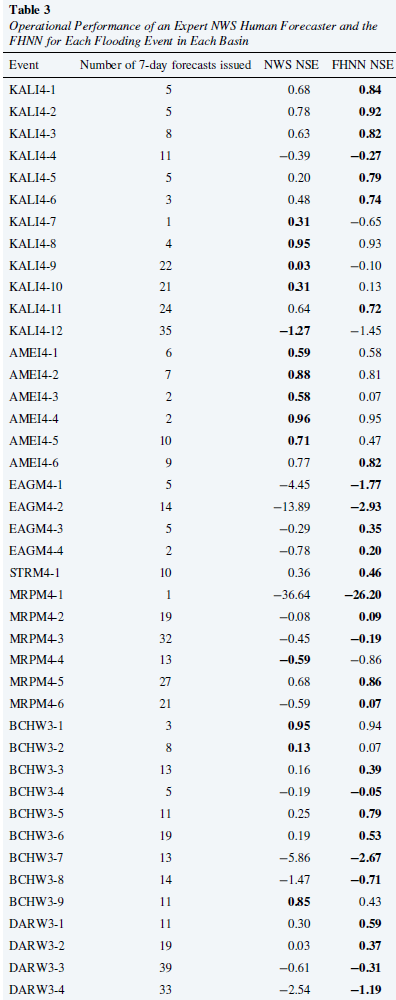
予測リードタイムに関して:水位予測(つまり、NWSが実際に発表する予測)の場合。FHNNは、予報発表から12時間(2タイムステップ)後には、NWSの専門予報官の予報精度を上回り始めた。交通量予測において、FHNNは18時間後(3タイムステップ後)にはNWSの専門予報官を上回る性能を発揮します。2日目から3~4日目(評価指標によって異なります)にかけて、FHNNの予測能力は人間の予報官よりも著しく高くなります。4日目以降は、FHNNと人間の予報官の予測能力に大きな差はなくなります。
洪水ピーク予測能力
重要な業績指標の一つは、河川水位のピークを予測する際の誤差である。これは、特定の降雨または融雪イベント中に流出ハイドログラフで到達した最高ピーク値を指します。そこで研究者らは、洪水ピーク予測におけるFHNNとNWSの人間による予測の性能を評価した(いずれも不確実な将来の降水予測を使用)。また、FHNNと人間による予測の性能を、予測者が使用する基盤となるSacSMAモデルと比較した。その結果、…FHNNは、洪水ピーク予測において、人間の修正を加えない物理モデルを大幅に上回る性能を発揮するが、専門家の予測にはわずかに及ばない。
下図に示すように、洪水ピーク予測において、人間の予測者は、ほぼすべてのリードタイム(約60時間以上のリードタイムを除く)でFHNN(洪水予測ニューラルネットワーク)を上回る性能を示した。
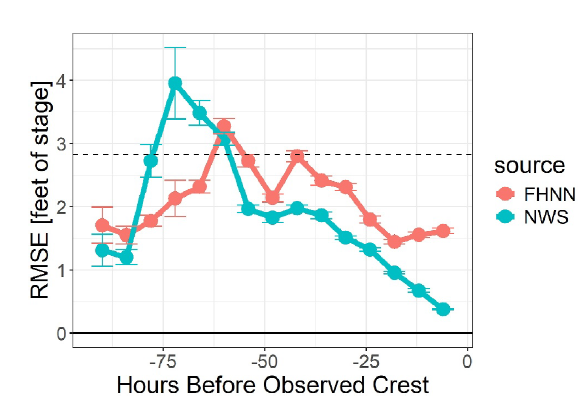
しかし、将来の気象条件が完全には分かっていない場合でも、FHNNによる洪水ピークの推定値は、観測された降水量のみに基づいており、予報官の介入がないSacSMAモデルよりも優れている。
洪水ピークの48時間から18時間前の間に、FHNNは、データ統合を通じて、人間の予測担当者と同等の予測精度向上率を達成する。この期間中、予測は6時間ごとに更新され、洪水ピーク予測誤差(RMSE)は約0.2フィート減少しました。しかし、洪水ピークの2.5日前までのすべての予測において、人間の予測担当者は予測の優位性を維持しました。洪水ピークの12~18時間前(2~3タイムステップ前)には、FHNNの洪水ピーク予測RMSEは基本的に減少が止まり、わずかに増加しました。
これは、洪水ピークが近づくにつれて、FHNNは人間の予報官よりもシステムの変化に対する感度が低いことを示している。この結果は、予報発表後最初の12~18時間ではNWSの方が高い予測能力を持つという、全体的な予報能力の比較とも一致する。洪水ピーク付近でのFHNNの反応の不十分さは、極値予測の問題に関連している可能性がある。LSTMモデルの場合、訓練データには極端な洪水事象が比較的少ないため、洪水の最高ピーク値を予測することはしばしば困難です。
水文学研究における人工知能の応用における進歩
近年、人工知能技術は水文研究および運用予測における技術的アプローチを大きく変革している。統計的回帰に基づく初期の手法から、深層学習に代表される今日のデータ駆動型モデルに至るまで、水文予測は徐々に、より高度で自動化された発展段階へと移行しつつある。
応用レベルでは、長短期記憶(LSTM)ネットワークに代表される時間的深層学習モデルが、水文予測の主流ツールの1つとなっている。数多くの研究が、...これらのタイプのモデルは、一般的に、複数の流域における流出シミュレーションにおいて、従来の物理モデルよりも優れた性能を発揮します。特にデータが豊富にある地域では、その予測能力はさらに際立ちます。
近年、Transformerアーキテクチャは水文学の分野に徐々に導入されてきました。長期シーケンスモデリングにおけるその利点は、長期的な水文学的記憶を捉える新たな可能性をもたらしました。同時に、学術界と工学界は、データ駆動型モデルだけに頼ることには一定の限界があることを徐々に認識し始めています。例えば、物理的な制約の欠如は、極端なケースでは水文学的法則に適合しない結果につながる可能性があり、モデルの解釈可能性も低いです。したがって、「物理情報駆動型」または「知識誘導型」の機械学習手法が、新たな研究のホットスポットとなっている。
近年の研究進展において、マルチソースデータ融合は水文モデルの性能向上に向けた重要な方向性となりつつある。衛星降水量、土壌水分、積雪水当量などのリモートセンシングデータと地上観測データを組み合わせることで、モデルはより包括的な流域情報を得ることができる。同時に、グラフニューラルネットワーク(GNN)も流域間の空間的関係をモデル化するために利用され始めており、地域規模での洪水予測能力の向上に貢献している。
最近、Google Researchは、非構造化データから検証済みの地表情報を抽出する洪水データセット「Groundsource」をオープンソース化しました。これにより、過去の災害被害の範囲をかつてない精度でマッピングすることが可能になります。研究者たちは、150カ国以上から寄せられた500万件を超えるニュース記事の処理を自動化し、最終的に260万件を超える過去の洪水記録を収集した。これにより、世界の洪水研究にとって前例のない規模と網羅性を持つデータが提供された。
現在のところ、「Groundsource Global Flood Events Dataset」は、HyperAIのウェブサイト(hyper.ai)のデータセットセクションで公開されており、オンラインで利用できます。
https://go.hyper.ai/KO3dB
以前、Google Researchのグレイ・ニアリング氏とそのチームは、最大5日前までの洪水予測を高い精度で行える機械学習ベースの河川予測モデルを開発した。5年に一度発生する洪水の予測においては、このモデルは1年に一度発生する洪水の予測に用いられる既存の手法と同等以上の性能を発揮する。このシステムは80カ国以上をカバーできる。
論文タイトル:観測地点のない流域における極端な洪水の世界的な予測
用紙のアドレス:https://www.nature.com/articles/s41586-024-07145-1
ビジネスアプリケーションの観点から見ると、人工知能は従来の水文予報士を完全に置き換えるのではなく、「人間と機械の協働」を通じて役割を果たす可能性が高い。AIモデルは迅速かつ安定した予測結果を提供できる一方、専門家は経験に基づいて重要なシナリオについて修正や判断を行うことができる。この協働モデルは、予測効率を向上させるだけでなく、極端な事象におけるシステムの信頼性を高めることにも役立つ。データ規模の継続的な拡大とアルゴリズム機能の継続的な向上に伴い、将来の洪水予測システムはよりインテリジェントで効率的かつ適応性の高いものとなり、防災・減災および水資源管理に対する強力な技術的支援を提供するだろう。
参考文献:
1.https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2024WR039064
2.https://phys.org/news/2026-03-ai-higher-accuracy-current-methods.html
3.https://mp.weixin.qq.com/s/ZWU-v_4k7FIm0MoDh6Rxuw
4.https://www.nature.com/articles/s41586-024-07145-1








