Command Palette
Search for a command to run...
MOSS-TTS: CAT アーキテクチャに基づく分離されたプロダクション グレードの音声生成モデル。単一細胞分析の障壁を打ち破る: Pan-Cancer scRNA-Seq データセットを使用してクロスがん免疫アトラス ベンチマークを構築します。

現在、単一の音声生成モデルは、複雑な現実世界の要求に応えるには不十分であることが証明されています。実用化においては、音声は特定の音色を忠実に模倣するだけでなく、異なるコンテンツ間で自然な話し方を切り替え、数十分にわたる物語を通して安定した状態を保つ必要があります。さらに、対話、ロールプレイング、リアルタイムインタラクションなど、様々な形式に対応する必要があります。これらの要件は、単一のモデルの能力をはるかに超えています。
この文脈では、MOSI.AI と OpenMOSS は、音声生成モデルの MOSS-TTS ファミリーをリリースしました。このモデル群は、単一の大規模モデルを構築するのではなく、音声生成ワークフローを5つの実稼働グレードのモデルに分離します。これには、高忠実度音声基盤MOSS-TTSと複数話者対話モデルMOSS-TTSDが含まれます。そのコア技術は、16億パラメータの大規模オーディオトークナイザーMOSS Audio-Tokenizerをベースとしており、純粋なTransformerアーキテクチャ(CAT、Causal Audio Tokenizer with Transformer)を採用することで、高忠実度オーディオ再構成を実現します。このモデル群は、複雑なシナリオにおける多くのアプリケーション課題を解決し、オーサリングワークフローに直接統合できる音声生成分野のツールチェーンを提供します。
HyperAIのウェブサイトに「MOSS-TTS:高忠実度マルチシーン音声生成モデル」が掲載されました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/AtKvk
3月2日から3月6日までのhyper.ai公式ウェブサイトの更新の概要は次のとおりです。
* 高品質の公開データセット: 3
*厳選された高品質なチュートリアル: 8
* コミュニティ記事の解釈:3件
* 人気のある百科事典のエントリ: 5
* 3月に締め切りを迎えるトップカンファレンス: 4
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. ドローン音検出データセット
このデータセットには、未知の音声とドローンの2つのカテゴリの音声録音が含まれています。これは、実世界環境におけるドローン音を検出するバイナリ音声分類タスク用に設計されています。このデータセットの音声ファイルは、メルスペクトログラム抽出、MFCC特徴抽出、短時間フーリエ変換(STFT)、生波形のディープラーニングモデル化などの前処理に適した標準形式(WAVなど)で提供されています。
直接使用します:https://go.hyper.ai/vKHJC
2. 薬物有害反応シミュレーションデータセット
このデータセットは、医薬品副作用(ADR)の医薬品安全性監視報告書を模倣するように設計されており、医薬品安全性モニタリングにおける研究、機械学習実験、アルゴリズム開発を支援することを目的としています。症例安全性報告書(ICSR)は、FDA FAERSやEMA EudraVigilanceなどの実際の医薬品安全性監視システムに着想を得て、人工的に生成されています。
直接使用します:https://go.hyper.ai/Jex4v
3. 汎がんscRNA-Seqシングルセル転写アトラスデータセット
このデータセットには、7,930個の単一細胞からのトランスクリプトーム発現データが含まれており、3つの異なる生物学的状態(健常免疫ベースライン、液性腫瘍(骨髄性白血病)、固形腫瘍微小環境(メラノーマ))を網羅しています。本データセットは、コホート間統合単一細胞解析ベンチマークの構築を目的としており、アルゴリズムの性能評価と方法論の比較、マルチコホートバッチ効果補正、免疫疲弊状態解析、そして腫瘍タイプ間のバイオマーカーマイニングのためのベンチマークを提供します。
直接使用します:https://go.hyper.ai/CnZTc
選択された公開チュートリアル
1. ACE-Step 1.5: 音楽生成デモ
ACE-Step 1.5は、ACE StudioとStepFunが共同で立ち上げたオープンソースの音楽生成基盤モデルであり、オープンソース音楽生成機能の限界を押し広げることを目指しています。このモデルは革新的な2段階生成アーキテクチャを採用し、拡散トランスフォーマー(DiT)と言語モデル(LM)の協調的統合により、高品質で長時間の音楽コンテンツ生成を実現します。
オンラインで実行:https://go.hyper.ai/QZ6oi

2.Qwen3-ASR-1.7B: 新世代音声認識システム
Qwen3-ASRは、アリババクラウドの同義千文チームが立ち上げた、オープンソースのエンドツーエンド自動音声認識(ASR)モデルシリーズの新世代です。Qwen3-Omniマルチモーダル基盤モデルと自社開発のAuT音声エンコーダーをベースとしたこのモデルは、高精度、多言語対応、長時間音声、そしてストリーミングと非ストリーミングを統合した音声テキスト変換機能の実現に重点を置いています。生の音声信号を入力として取り、エンドツーエンドのアーキテクチャを通じて構造化テキスト出力に直接マッピングするとともに、文字/単語レベルからミリ秒レベルのタイムスタンプアライメントをサポートします。会議の文字起こし、インテリジェントな字幕作成、カスタマーサービスの音声アーカイブ、方言ベースの音声インタラクションなど、さまざまなシナリオに適しています。
オンラインで実行:https://go.hyper.ai/zb0Vi

3.Qwen3-Coder-Next を使用した vLLM+Open WebUI の導入
Qwen3-Coder-Nextは、アリババクラウドの同義千文氏がオープンソース化した軽量コード生成モデルで、あらゆるシナリオのプログラミング支援とコード生成タスクに重点を置いています。その主な利点は、「高性能、導入障壁の低さ、容易な導入」です。最適化されたQwen3大規模言語モデルアーキテクチャを基盤とし、コードドメインに特化した事前学習済みデータ(80以上の主要プログラミング言語と10億以上のコードスニペットをカバー)とRLHF(ヒューマンフィードバック強化学習)コードアライメント最適化を統合しています。HumanEval+、MBPP、MultiPL-Eという3つの権威あるコードベンチマークにおいて、オープンソースモデルの中でトップクラスの性能を達成し、CodeLlama-70Bに迫る性能を実現しています。アルゴリズム記述、ビジネスコード生成、コードコメント、クロスランゲージコード変換、バグ修正など、様々なプログラミングシナリオに適しています。
オンラインで実行:https://go.hyper.ai/ukxPt
4. VibeVoice-ASR: 多機能エンドツーエンド音声認識デモ
VibeVoice-ASRは、Microsoftがオープンソース化した高性能で多機能なエンドツーエンドの音声認識(ASR)モデルであり、長時間の音声コンテンツに対して構造化されたコンテキストアウェアな音声テキスト変換サービスを提供するように設計されています。このモデルは、高度な統合オーディオモデリングアーキテクチャを採用しており、最大60分の長さの音声ファイルを一度に処理できます。話者ID(誰が)、タイムスタンプ(いつ)、および書き起こされたコンテンツ(何を)を含む構造化された出力の生成をサポートし、ユーザーがコンテキスト情報を提供して認識精度を向上させることができます。その中核となる技術革新は、効率的なロングシーケンスモデリング機能とクロスリンガルマルチタスク学習メカニズムにあり、従来のASRモデルが長時間の音声ファイルを処理する際に抱えていた時間的アライメントと意味的一貫性の問題を完全に解決します。
オンラインで実行:https://go.hyper.ai/8eMFX
5. MOSS-TTS: 高忠実度のマルチシーン音声生成モデル
MOSS-TTSシリーズは、MOSI.AIとOpenMOSSチームが立ち上げたオープンソースの音声生成モデルシリーズです。単一の音声セグメントにおいて、人間のような発音、各単語の正確な発音、異なるコンテンツ間での話し方の切り替え、数十分にわたる安定性の維持、対話、ロールプレイング、リアルタイムインタラクションのサポートが求められる場合、単一のTTSモデルでは不十分な場合が多くあります。そこで、このプロジェクトでは、音声生成ワークフローを、コアとなるMOSS-TTS基本モデル、MOSS-TTSD多言語対話モデル、MOSS-VoiceGenerator音声設計モデル、MOSS-SoundEffect効果音生成モデル、そしてMOSS-TTS-Realtimeリアルタイムインタラクションモデルという、独立または組み合わせて使用できる5つのプロダクショングレードモデルに分離しています。このシリーズは 20 の言語をサポートし、主に、高忠実度のゼロサンプル音声クローニング、最大 1 時間の安定した長いテキスト合成、多言語および中国語と英語の混合生成、複雑なシナリオでのきめ細かい継続時間と音素レベルの発音制御など、実際のアプリケーションの課題に対処します。
オンラインで実行:https://go.hyper.ai/AtKvk
6.Z-Image: 60億のパラメータを持つアリババのオープンソースのテキストベースの画像モデル
Z-Imageは、アリババクラウド同義千文チームが立ち上げた新世代の高効率画像生成モデルです。Z-Image-Turboの蒸留版をリリースし、人工知能分析リストでオープンソースモデルのトップにランクインした後、Z-ImageチームはZ-Image標準版を正式にオープンソース化しました。Z-Imageシリーズのメインコミュニティベースモデルである標準版は、生成品質、スタイルの多様性、二次開発サポートに優れた、完全な非蒸留モデルです。コミュニティ開発者に強力で柔軟な画像生成基盤を提供し、カスタマイズ開発と微調整の可能性を広げることを目指しています。
オンラインで実行:https://go.hyper.ai/SsDMv
7. Qwen3-TTS: 高品質で制御可能な多言語音声合成デモ
Qwen3-TTS-12Hz-1.7B-CustomVoiceは、アリババ同義チームが発表した新世代の高品質テキスト読み上げ(TTS)モデルです。このモデルは、多言語音声合成、複数話者(カスタムボイス)制御、テキストベースのスタイルと感情の調整、そして高自然で低遅延の音声生成を単一の統合フレームワークで実現することに重点を置いています。17億個のパラメータを持つ12Hz音響モデリングフレームワークをベースとするこのモデルは、音声明瞭度、韻律の一貫性、そして言語間の安定性において優れた性能を発揮します。CustomVoiceメカニズムを導入することで、モデルは追加のトレーニングなしで推論段階でプリセット話者を直接切り替えることができ、自然言語スタイルの指示と組み合わせることで、より洗練された表現制御を実現します。
オンラインで実行:https://go.hyper.ai/xWsQ6
8. FoundationMotionビデオQ&Aシステム
FoundationMotionは、NVIDIAとMITが共同開発した、Qwen2.5-VLのファインチューニングをベースとした動画理解・質問応答システムです。動画内の空間的な動きを理解し、推論することを目的としています。視覚言語の事前学習技術を組み込むことで、アップロードされた動画コンテンツをインテリジェントに分析し、関連する質問に答えることができます。
オンラインで実行:https://go.hyper.ai/JlGZk
コミュニティ記事の解釈
1. 従来のマルチモーダル統合の限界を打破!MITは、細胞共有情報と細胞固有情報を明確に分離するAPOLLOフレームワークを提案します。
単一細胞技術の継続的な進化とデータ規模の急速な拡大に伴い、共通情報とモダリティ固有の情報を明確に分離しながら、マルチモーダルデータを効率的かつ自動的に統合する方法が、単一細胞生物学が直面する主要な課題となっています。この課題に対処するため、MITとETHチューリッヒの共同研究チームは、汎用的な深層学習コンピューティングフレームワークであるAPOLLO(Autoencoder with a Partially Overlapping Latent Space Learned through Latent Optimization)を提案しました。このフレームワークは、共通情報とモダリティ固有の情報を明示的にモデル化することで、細胞の状態とその制御ロジックをより包括的かつ正確に分析するための実現可能な技術的道筋を提供します。
レポート全体を表示します。https://go.hyper.ai/jaCKf
2. オンラインチュートリアル | 500 万時間の音声データに基づいて、Qwen3-TTS は 3 秒の音声複製と微調整を実現します。
生成AIが「テキスト生成」にとどまらず、真に「音声生成」を行うようになると、音声は単なる情報チャネルから、プログラム可能で柔軟な表現媒体へと進化します。こうした技術進化の過程で、新世代のモデルは従来のTTSの限界を打ち破ろうとし始めています。高い忠実度の追求だけでなく、多言語への汎用化ときめ細かな制御も重視しています。Qwenチームによって最近オープンソース化されたQwen3-TTSは、デュアルトラック言語モデル(LM)アーキテクチャを基盤としており、出力音声をきめ細かに制御しながら、同時にリアルタイムで音声を合成することが可能です。
レポート全体を表示します。https://go.hyper.ai/eKr7T
3. MIT は酵母 DNA の「言語」を学習する Pichia-CLM モデルを開発し、外因性タンパク質の生産を最大 3 倍に増やす可能性があります。
現在、業界では宿主CUBに基づく様々なコドン最適化ツールや手法が開発されていますが、これらの手法では高発現構造を安定的に生成できない可能性があります。近年、人工知能、特に配列モデリング技術の発展に伴い、研究者は遺伝子配列を一種の「言語」として扱い、自然言語処理に類似した手法を用いて、その中に潜む暗黙のルールを学習しようと試みています。こうした背景から、MITの研究チームは、産業用宿主ピキア・パストリスのコドン最適化を目的とした深層学習ベースの言語モデル、Pichia-CLMを提案し、組換えタンパク質の収量向上を目指しています。
レポート全体を表示します。https://go.hyper.ai/a4H2G
人気のある百科事典の項目を厳選
1. 視覚言語モデル(VLM)
2. ハイパーネットワーク
3. ゲート型注意
4. ヒューマン・イン・ザ・ループ(HITL)
5. 神経放射フィールド (NeRF)
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
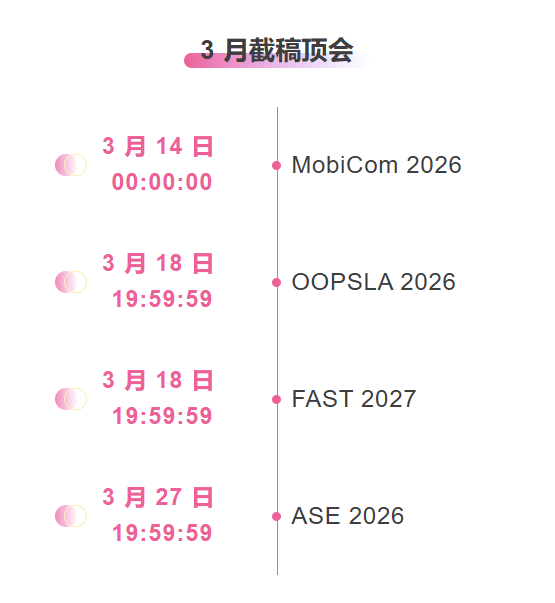
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








