Command Palette
Search for a command to run...
カーネギー研究所の学際的なチームは、406 個のサンプルに基づくランダム フォレスト モデルを使用して、33 億年前に遡る生命の証拠を捕らえることに成功しました。

地球の地表深くに埋もれた古代の岩石層に埋もれた有機分子を解読することは、地球の歴史を理解し、生命の進化を研究する上で極めて重要です。これらの生命活動の証人となる可能性のある物質は、地球における生命誕生の謎を解き明かし、特に光合成の起源と大気酸化との関連性を明らかにするだけでなく、生命進化のタイムラインの空白を埋め、初期地球の生態系の形成を理解するための重要な手がかりを提供します。しかし、目に見える化石を形成する大型生物とは異なり、これらの「証人」は地質学的侵食によって、はるか昔に跡形もなく消滅しています。そのため、高度に分解された有機残骸から生命の痕跡を特定することは、古生物学や地球科学の分野における大きな課題となっています。
科学者たちは長年にわたり、初期生命の探究において、主に古生物学的化石の形態学と同位体分析に頼ってきました。しかし、これらの方法は試料の保存状態によってしばしば制限されます。例えば、脂質やポルフィリンといった複雑な分子の明確な記録は約16億年前までしか遡ることができず、これは他の証拠によって明らかにされている生命の起源の時代よりもはるかに短いものです。さらに、始生代岩石中の有機分子の起源は不明瞭であり、生物起源と非生物起源の境界を特定することは困難です。これらの理由により、多くの重要な発見が推測の段階にとどまっています。
この行き詰まりを打破するためにカーネギー研究所の地球惑星研究所が主導し、世界中の多数の大学や研究機関から構成される学際的なチームと連携して、「技術融合」ソリューションが提案されました。彼らはまず、熱分解ガスクロマトグラフィー質量分析法(py-GC-MS)を用いて分析を行い、次に教師あり機械学習法を用いて分析データを分類・識別し、混沌とした分子断片の中に古代の生命の痕跡を捉えました。
これらの技術を統合したモデルは、実験により予想を上回る結果を示すことが示されました。このモデルは、1001 TP3Tの解像度で現代の有機物と隕石/化石有機物を正確に区別し、971 TP3Tの精度で化石植物組織と隕石有機物とを区別することができます。さらに重要なのは、研究チームがこのモデルを未知のサンプルに適用したところ、33億3000万年前と25億2000万年前の古始生代および新始生代の岩石中に、生命起源の分子集合体の証拠を特定することに成功したことです。これは、より古く、より残存率の低い生命の痕跡を探査するための新たな方法論的裏付けとなります。
「熱分解-GC-MSおよび教師あり機械学習によって特定された始生代岩石中の生命の有機地球化学的証拠」と題された関連研究が、米国科学アカデミー紀要(PNAS)に掲載されました。
研究のハイライト:
* 提案された技術融合アプローチは、熱分解ガスクロマトグラフィー質量分析と機械学習を組み合わせることで、従来の限界を打ち破り、分解後の分子を区別するという主要な課題を克服します。
* 研究サンプルは、現代の生命から数十億年前の岩石、陸生生物から地球外隕石まで広範囲に及び、モデルトレーニングのための包括的な比較を提供します。
* 実験により、この方法は科学的に健全かつ将来を見据えたものであることが示され、始生代の岩石における生命の痕跡の存在を検証するだけでなく、他の未知の生命の痕跡を探索するための新しい方法も提供します。

用紙のアドレス:
https://www.pnas.org/doi/10.1073/pnas.2514534122
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「熱分解ガスクロマトグラフィー」と返信すると、完全な PDF を入手できます。
データセット: 406 のサンプル、広範囲をカバーし、モデルの包括的な比較を提供します。
研究チームは、約38億年前(始生代)から1000万年前(新第三紀)までの古代および現代、生物および非生物起源を含む、様々な有機分子を含む合計406個の天然および合成サンプルを分析しました。サンプルの種類には、堆積岩(141個)、化石(65個)、現生生物(123個)、隕石(42個、うち39個は炭素質コンドライト)、そして実験室で合成された有機分子(35グループ)が含まれ、機械学習分析のための豊富で多様なデータ基盤を提供しました。
これら 406 個のサンプルのうち 272 個は系統関係と生理学的特徴に基づいて 9 つのカテゴリに明確に分類され、下の図に示すように、教師あり機械学習のトレーニング (75%) とテスト (25%) に使用されました。
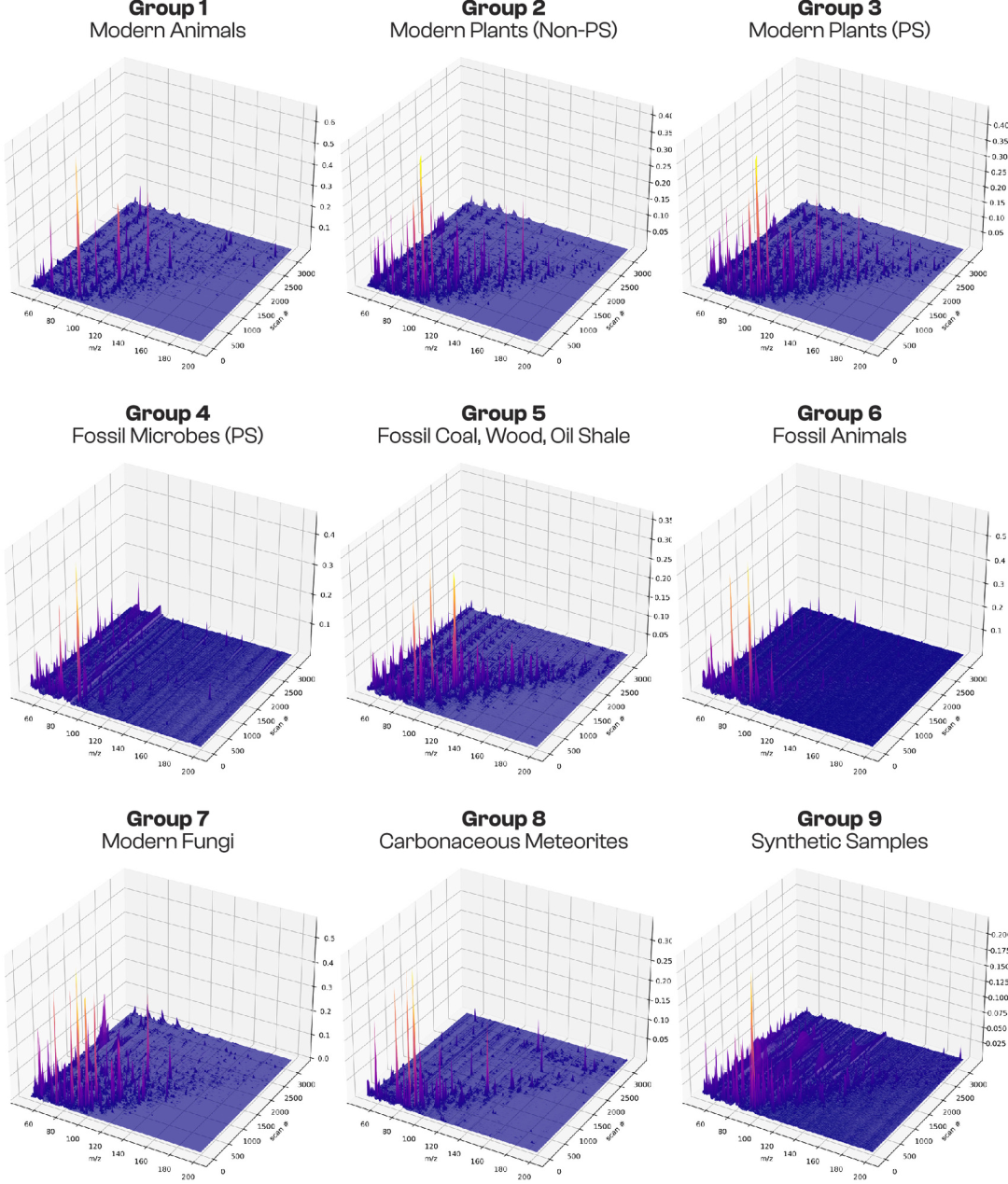
* 現代の動物:現代の非光合成従属栄養生物の有機分子特性は、最近死亡した様々な無脊椎動物および脊椎動物から得られた。サンプル数は21であった。
* 現代の植物(非光合成組織):この研究には、植物の根、種子、花、果実、樹液から得られる非光合成組織と分泌物が含まれており、植物の異なる機能組織間の分子的差異を反映するものである。サンプル数は40であった。
* 現代の植物(光合成組織):この研究は主に葉やその他の光合成組織に焦点を当てており、光合成生体分子の特性に関する現代の参考資料として役立ちます。サンプル数は36です。
* 光合成性シアノバクテリア/藻類の化石を含む堆積岩:頁岩またはフリント岩には、塩酸(HCl)およびフッ化水素酸(HF)を用いた酸溶解によって濃縮された有機残留物が含まれており、岩石にはシアノバクテリアまたは藻類の化石の信頼性の高い形態学的証拠が認められ、古代の光合成微生物の分子記録として機能します。サンプル数は24でした。
* 化石木、石炭、オイルシェール:サンプルは主に顕生代(5億4100万年前未満)のものですが、シュンガイトやアンスラクソライトといった原生代の複雑な炭化水素に富む堆積物も含まれており、古代の高等植物や炭化水素の分子保存特性を示しています。サンプルの総数は49です。
* 動物の化石:すべてのサンプルは顕生代に由来し、魚類化石や三葉虫化石の炭化した残骸、そして中新世の腹足類の殻から抽出された殻結合タンパク質など、古代動物の有機分子残骸が含まれています。サンプルは合計9つあります。
* 現代の菌類:木材腐朽菌と酵母の多様な種が含まれており、真核生物における非植物・非動物群の分子データの欠落を埋めるものです。サンプル数は16です。
* 隕石:サンプルは主に炭素質コンドライト(計39個)で、化学的に分解され、有機分子集合体が濃縮されたため、非生物由来の有機源の明確な基準として役立ちます。計42個のサンプルが採取されました。
* 実験室で合成されたサンプル:本研究では、メイラード反応やフォルモース反応といった実験室での合成プロセスによって得られた有機分子の集合体を用いて、非生物由来の有機物質の分子特性をシミュレートした。サンプル数は35であった。
その上、研究チームは、特定の機械学習モデル用に 2 つの追加補助クラス サンプルも設定しました。光合成生物と非光合成生物を区別するために、合計3つのサンプルが使用されました。2つの現生シアノバクテリアサンプルは、光合成原核生物のデータを補足するために使用されました。1つの現生好塩性細菌(ハロバクター)サンプルは、非光合成古細菌のデータを補足するために使用されました。
残りの131サンプルは、主に有機物に富む始生代または原生代の堆積岩由来の酸可溶性濃縮残渣でした。これらのサンプルに含まれる有機分子の起源と生理学的特性は不明または議論の余地がありますが、これは本実験における機械学習分析の適用性を検証するための新たな分類試験場を提供します。
研究手法とモデル:py-GC-MSと機械学習の深い統合
この実験は、主に次の 4 つのステップに要約できます。
* 最初のステップでは、現代や古代の生物や非生物のさまざまな源から 406 個の異なる炭素含有サンプルを収集しました。
* 2 番目のステップは、隕石や古代の堆積岩から炭素質高分子を抽出することです。
* 3 番目のステップでは、電子衝撃イオン化質量分析法と組み合わせた熱分解ガスクロマトグラフィーを使用して各サンプルを分析します。
* ステップ 4: 実験サンプル分析サブセット (機械学習手法) のデータを使用して、教師ありランダム フォレスト モデルをトレーニングします。
この方法の最も重要な側面は、py-GC-MS 分析技術と機械学習手法の「技術的統合」です。
まず、分析技術があります。この実験では、研究チームはCDS 6150サーマルプローブをAgilent 8860シリーズガスクロマトグラフおよびAgilent 5999四重極質量分析計と組み合わせました。クロマトグラフィー分離はAgilent 30 M 5%フェニルPDMSカラムを用いて行いました。熱分解生成物はヘリウムガスによって直ちにガスクロマトグラフカラムに流し込まれ、分析されました。具体的な手順は以下のとおりです。
* 熱分解:研究者らは、予熱した(空気中で550℃で3時間燃焼させた)石英管にサンプル(10~100μg)を入れ、それを熱プローブコイルに挿入してフラッシュ熱分解し、500℃/秒の速度で610℃まで加熱して10秒間保持した。
* クロマトグラフィー:初期温度は50℃で1分間保持し、その後5℃/分の速度で300℃まで昇温し、15分間保持した。キャリアガスには超高純度ヘリウム(UHP 5.5グレード)を使用した。
* 質量分析法:250℃でイオン化エネルギー70eV、スキャン範囲m/z 45-700、スキャン速度0.80秒/10倍、スキャン間遅延0.20秒の電子イオン化(EI)モードで動作します。
低分子揮発性物質(CO₂やH₂Oなど)による干渉を避けるため、実験開始後2分間はMSデータの収集は行いませんでした。さらに、クロマトグラムによく見られる夾雑物(パルミチン酸やステアリン酸など)の溶出領域からのシグナルを除外する必要がありました。各サンプルは2次元マトリックス(3,240個の溶出時間間隔×150個のm/z値)に変換され、489,240個の元素のシグナル強度が質量と保持時間の関数として記録されました。標準化と平滑化の後、最終的に8,149個の有効な特徴が保持されました。
次に、モデル選択が行われました。この実験ではランダムフォレスト法が採用されました。これは、高精度、低計算コスト、そして解釈可能性を備えたアンサンブル分類手法です。複数の相関除去決定木を構築することで、過学習のリスクを軽減します。このモデルは、レオ・ブレイマンが「Random Forests」で言及したランダムフォレストモデルを採用しています。
研究者らは、訓練済みの機械学習モデルに対して2つの検証戦略を用いた。まず、75%の訓練セットと25%のテストセットを用いた層別ランダムサンプリングにより、各サンプルクラスの割合が2つのグループ間で一貫していることを確認した。次に、10分割交差検証を10回繰り返してモデルの汎化能力を評価し、ランダム誤差を低減するために平均精度を算出した。
実験では、現代の生物起源源(植物と動物)と非生物起源源(隕石と合成サンプル)、古代の生物起源源(生物起源であることがわかっている堆積岩)と非生物起源、古代の生物起源源(化石化した木と石炭を除く)と非生物起源、光合成サンプルと非光合成サンプルを区別する 4 つのモデルをテストしました。
実験結果: 技術統合の実現可能性に関するマルチモデル、多次元検証
初期テストでは、研究者はランダムフォレストモデルを使用して、比較的バランスの取れたサンプルサイズを想定し、9 つの既知の属性を持つ 36 組のサンプルの組み合わせを分類しました。36 回のテストのうち、25 回はトレーニング セットとテスト セットの両方で 90% 以上の精度を持ち、そのうち 19 回は 95% 以上の精度を持ちました。すべての結果は以下の表に示されています。
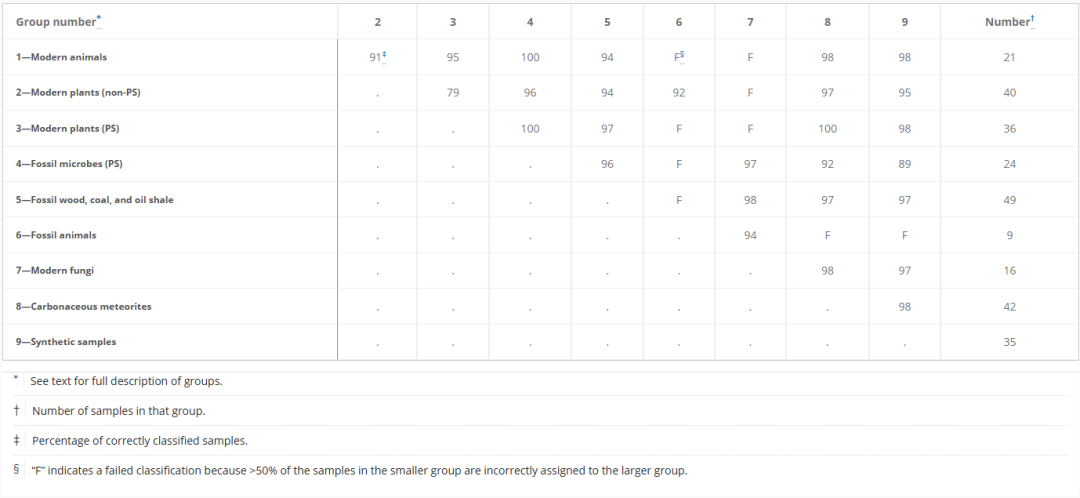
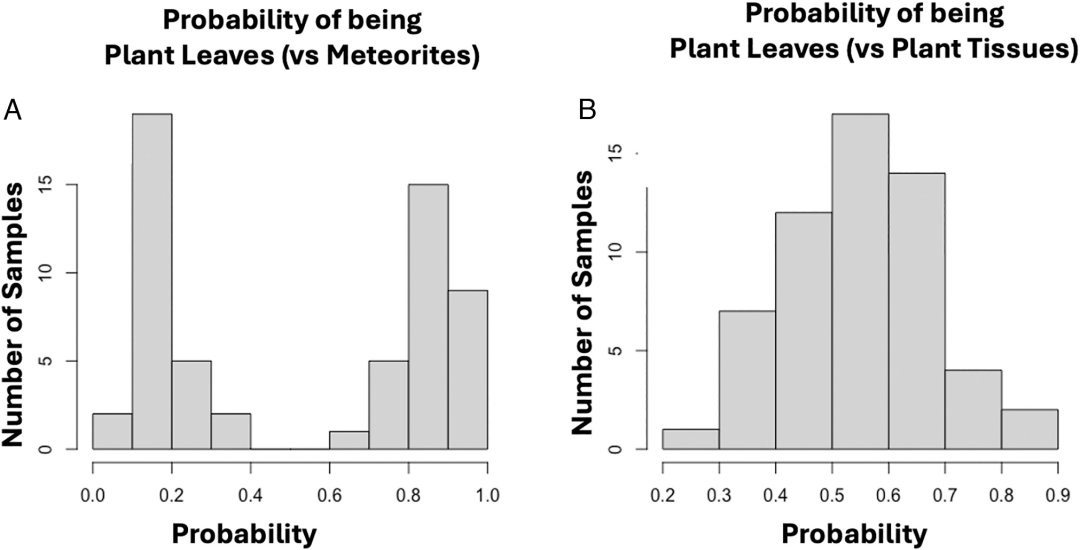
この手法をさらに説明するために、本論文では、様々なケースにおける効率性と非効率性の違いを示すいくつかのケーススタディを提示している。例えば、グループ3と8、すなわち現生植物(光合成組織)と隕石では、この方法により、植物と隕石を 100% の精度で区別できました。すべてのサンプルのクラス確率は0.6以上または0.4未満であり、分子特性に有意な差があることを示しています。下の図Aをご覧ください。
さらに、生物起源サンプルと非生物起源サンプルの識別は、古生物学および宇宙生物学研究の重要な目標です。この目的のため、研究チームは3つの異なるランダムフォレストモデルを構築・比較し、異なるサンプルの組み合わせにおける生物起源と非生物起源の識別能力を検証しました。
具体的には、モデル # 1 で、研究チームは、グループ 1、2、3 とグループ 8、9 で、それぞれサンプル数 97 と 77 の現代の植物と動物と非生物的発生源 (隕石と合成サンプル) を区別する能力をテストしました。全体の正解率は98%に達しました。AUC 値はトレーニング セットでは 0.977、テスト セットでは 1.000 です。10 倍クロス検証の精度は 98.3% です。
モデル# 2は、主に古代の生物サンプルと有機物に富む非生物サンプルを区別する能力を検証するために使用されました。対照サンプルはグループ4と5、グループ8と9から採取され、それぞれ87個と77個のサンプルが含まれていました。87 個の生物起源の古代有機サンプルのうち 83 個が正しく分類され、95.1 TP3T の精度率が達成されました。さらに、これらのサンプルのうち 70 個 (80%) は、生物起源の分類確率に高い信頼性 (> 0.6) がありました。非生物由来のサンプルのうち 69 個は正しく分類され、90% の精度を達成しました。AUC 値はトレーニング セットで 0.924、テスト セットで 0.926 でした。10 倍クロス検証の精度は 92.7% でした。
モデル# 2を生物起源不明の古代堆積岩109個に適用したところ、68個のサンプル(61%)で生物起源分類確率が0.50を超え、32個のサンプルで生物起源分類確率が0.60を超えていることが判明しました。
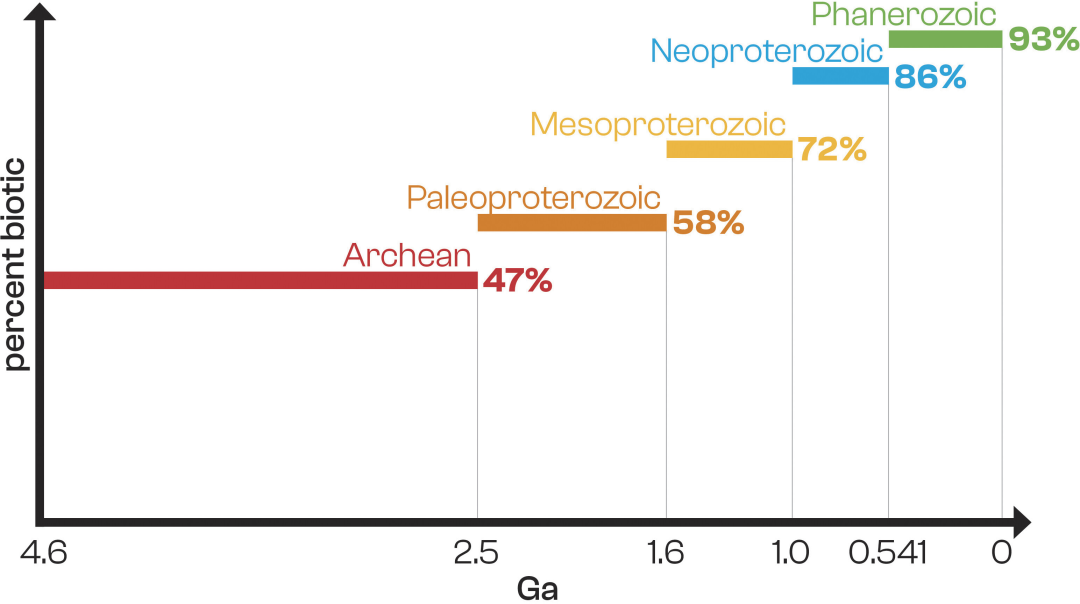
さらに、結果は、地質年代とともに生物起源サンプルの割合が減少傾向にあることを明らかにしました。顕生代サンプル82個のうち、76個(93%)が生物起源、43個(73%)が原生代、そして21個(47%)が始生代(45個)のサンプルでした。これは、年代が進むにつれて生物起源サンプルの割合が著しく減少していることを示しており、サンプルへの生体分子の分解または非生物的有機物の流入を反映している可能性があります。(下図参照)
モデル# 3は、主に古代の生物起源と非生物起源を区別する能力を検証するために使用されます。生物起源サンプルは、第4グループのサンプルを含む89個の頁岩およびフリントサンプルから採取され、非生物起源サンプルは第8グループと第9グループの77個のサンプルから採取されます。すべての生物学的サンプルは正しく分類されました。 80% サンプルは生物学的原因分類の信頼度確率が高く (> 0.60)、非生物学的原因サンプルの精度は 77% です。AUC 値はトレーニング セットで 0.873、テスト セットで 0.863 です。10 倍交差検証の精度は 91.6% です。
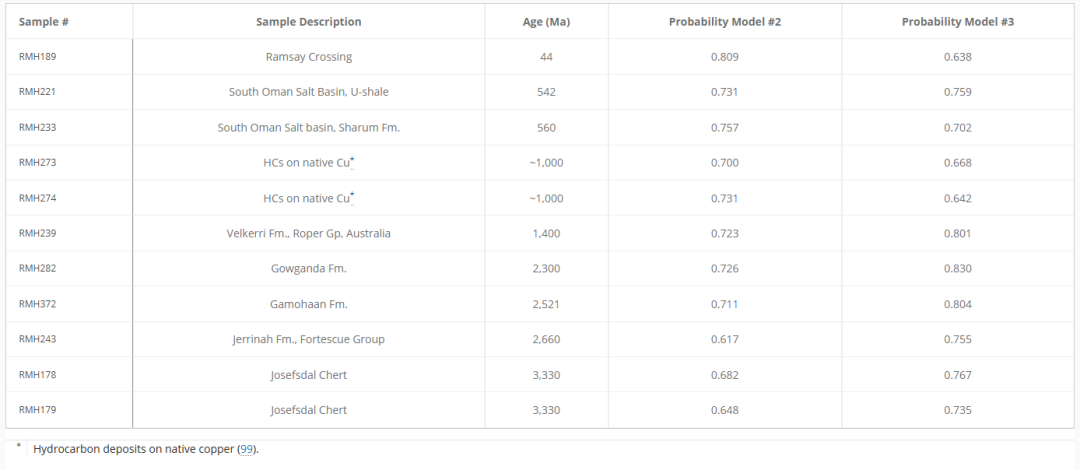
さらに、モデル# 2とモデル# 3を組み合わせることで、研究者らは11個の古代のサンプルが生物由来であると特定しており、最も古いものは南アフリカのバーバートン・グリーンストーン・ベルトで発見されたヨセフスダールのフリントで、33億3000万年前のものである。次の表に示すように:
技術の統合は生命の起源を探る上で重要な手段となっている。
近年、世界中の研究チームが、初期生命の痕跡の特定や地球外有機物の追跡といった中核的な課題に取り組むため、数多くの革新的な探査を行ってきました。これらの研究は、複雑な分子混合物の分析にも焦点を当てており、アルゴリズムモデルを用いて、従来の分析手法では捉えにくい生物学的特性を深く掘り下げ、技術統合の実現可能性と地球上の生命の起源の追跡のための確固たる基盤を築いています。
例えば、カーネギー科学研究所地球惑星研究所は、他の様々な機関と共同で、前述の手法を用いて研究を行いました。これらの手法は、惑星サンプル中の有機物の生物学的起源を解明するだけでなく、地球上の初期生命の痕跡を特定するためにも活用できます。この方法は、地球および地球外の炭素質物質の熱分解ガスクロマトグラフィー-質量分析測定と機械学習分類方法を組み合わせたものです。非生物由来のサンプルと生物サンプル(高度に分解された生物サンプルを含む)の区別において90%の精度を達成し、ダーウィンの生体分子選択機能の必要性を正確に反映しています。
論文タイトル: 機械学習に基づく堅牢で非依存的な分子バイオシグネチャー
用紙のアドレス:https://www.pnas.org/doi/10.1073/pnas.2307149120
py-GC-MSと機械学習の統合は、初期生命の探査における従来の手法の限界を打ち破るだけでなく、古生物学と人工知能の交差点に新たなパラダイムを確立します。しかし、前述の実験やその他の研究に見られるように、この技術統合アプローチには依然として最適化の余地があり、さらなる深遠な研究の方向性を示しています。継続的な技術進歩により、将来、人類は生命の起源についてより直感的で深い理解を獲得し、地球外生命の痕跡さえも探索できるようになると考えられています。








