Command Palette
Search for a command to run...
ケンブリッジ大学は血液細胞画像分類装置を開発しました。その拡散モデルは白血病の検出に役立ち、臨床専門家の能力を上回っています。
血液細胞画像解析は、臨床診断と科学研究において重要な役割を果たしています。白血球、赤血球、血小板の形態学的特徴は、血液系の健康状態を反映するだけでなく、白血病や骨髄異形成症候群といった疾患の早期兆候を明らかにする可能性もあります。しかしながら、従来の手作業による顕微鏡解析では、経験豊富な専門家による分類が不可欠であり、非効率的で時間がかかり、主観的なバイアスも生じます。
近年、ディープラーニング技術は医療画像解析分野への応用が拡大しており、特に畳み込みニューラルネットワーク(CNN)を中心とした識別モデルを血球形態評価に適用する研究もいくつか行われています。最も高性能な識別ML分類モデルは、細胞を定義済みのカテゴリーに分類する点で人間のパフォーマンスに匹敵しますが、主に専門家のラベルに基づいて決定境界を学習します。そのため、これらは本来、細胞形態の完全なデータ分布を捕捉するようには設計されていません。この制限により、特に臨床血液学データに固有の複雑さと変動性に直面した場合、その能力が低下します。
この文脈では、英国ケンブリッジ大学の研究チームは、拡散モデルに基づいた血球画像分類法「CytoDiffusion」を提案した。血球の形態分布を忠実にモデル化し、正確な分類を実現し、強力な異常検出能力、分布シフトへの耐性、解釈可能性、高いデータ効率、臨床専門家を上回る不確実性定量化能力を備えています。
このモデルは、異常検出 (AUC: 0.990 vs. 0.916)、分布シフトに対する堅牢性 (精度: 0.854 vs. 0.738)、および低データ シナリオでのパフォーマンス (バランスのとれた精度: 0.962 vs. 0.924) において最先端の判別モデルを上回っています。本研究で開発された包括的な評価フレームワークは、血液学的医用画像解析の多次元ベンチマークを確立し、臨床現場における診断精度の向上が期待されます。
「血液細胞形態の深層生成分類」と題された関連する研究成果が Nature 誌に掲載されました。
研究のハイライト:
* 潜在拡散モデルを血液細胞画像分類に適用する。
* 精度などの標準的な指標を超え、分布の変化に対する堅牢性、異常検出機能、データが少ないシナリオでのパフォーマンスを組み込んだ評価フレームワークを提案します。
* 既存のデータセットの主な制限に対処し、画像アーティファクトと注釈者の信頼性を含む新しい血液細胞画像データセットを構築します。

用紙のアドレス:
https://www.nature.com/articles/s42256-025-01122-7
公開アカウントをフォローして「細胞拡散完全なPDFを入手する
データセットアドレス:
AIフロンティアに関するその他の論文:
https://hyper.ai/papers
データセット: 公開データセットとカスタム構築データセットを組み合わせる
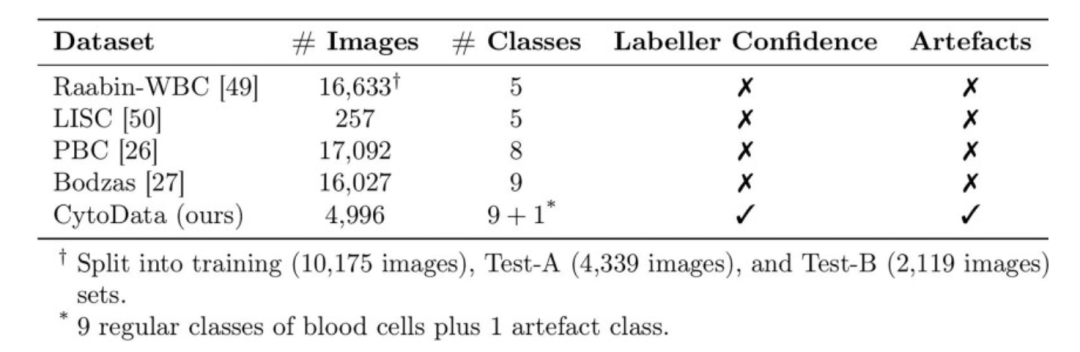
データは、血球画像解析の基盤であり、AI モデルのパフォーマンスと一般化能力の核となる保証です。 CytoDiffusion チームは 5 つのデータセットを使用しました。そのうち 4 つは公開されており、残りの 1 つは CytoData と呼ばれる独自に構築されたデータセットです。
CytoDataデータセットは、ケンブリッジのアデンブルック病院から提供された2,904枚の血液塗抹標本、合計559,808枚の単一細胞画像を含む匿名化されたデータセットです。このうち4,996枚の画像は、赤芽球、好酸球、単球、未熟細胞など10種類の血液細胞の種類でラベル付けされています。画像はCellaVision DM9600システムを用いて取得され、アノテーションには各アノテーション専門家による信頼度スコアが含まれており、後続の不確実性定量化のための重要な参考資料となります。CytoDataには、血液塗抹標本によく見られる非細胞構造の干渉に対処するためのアーティファクトカテゴリも含まれており、これは臨床応用において非常に価値があります。
ラビン-WBC、PBC、ボザス、LISCとして 4 つの公開データセットこのデータセットは、異なる顕微鏡、染色法、機器を用いて取得された血球画像で構成されています。Raabin-WBCはテストAとテストBのパーティションを提供しています。テストBでは、ドメインシフトをシミュレートするために、トレーニングセットとは異なる取得機器を使用しています。機器と染色法の違いにより、LISCデータセットではモデルの汎化能力を重視しています。
これらのマルチソースデータセットを組み合わせることで、チームはモデルトレーニングの多様性を確保しただけでなく、クロスドメインパフォーマンス評価、異常セル検出、およびデータが不足している状況でのモデルテストのための完全な基盤も提供しました。
データセットアドレス:
フレームワーク: 拡散モデルの血球画像分類への適用
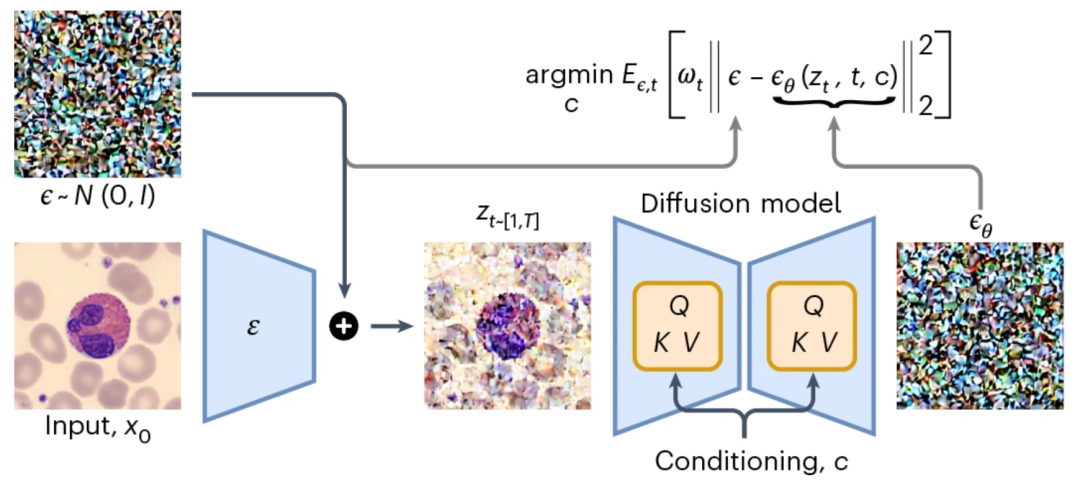
CytoDiffusion の核となる革新性は、拡散モデルを血球画像分類に適用することにあります。従来の識別モデルとは異なり、拡散モデルには生成特性があり、画像の完全な分布を学習し、ノイズ予測メカニズムを通じて分類することができます。
モデル原則
拡散モデルの基本原理は、ノイズを徐々に追加することでデータをノイズのような分布に変換する順方向拡散プロセスを定義することです。その後、モデルはデータのノイズを除去する逆プロセスを学習し、元のデータ分布を効果的に再構築します。
潜在空間エンコーディング:入力画像はまずエンコーダーによって潜在空間にマッピングされ、次にガウスノイズが追加されてノイズの多い潜在表現が形成されます。
条件付き拡散:このモデルは、各細胞タイプに対してノイズ予測を生成し、予測されたノイズと実際のノイズ間の誤差を最小限に抑えることで分類を実現します。
徐々に排除する:すべての候補カテゴリに対して反復サンプリングが実行され、最終的なカテゴリが決定されるまで、対応のあるスチューデントの t 検定を使用して不可能なカテゴリが段階的に排除されます。
一般的なトレーニング設定
研究者らは、Stable Diffusion 1.5 を基本モデルとして使用しました。カテゴリベースの条件では、トークナイザーとテキストエンコーダーをバイパスし、各カテゴリのワンホットエンコードされたベクトルを直接提供します。これらのベクトルは、想定される77×768次元行列に一致するように、垂直方向にコピーされ、水平方向にパディングされます。バッチサイズは10、学習率は10⁻⁵、線形ウォームアップは1000ステップで、A100-80GB GPUで学習を行いました。
訓練と推論
研究者らは、トレーニング中に、ランダムな対角線反転、ランダムな回転(0~359度の間の均一なサンプリング)、カラージッター(明度 = 0.25、コントラスト = 0.25、彩度 = 0.25、色相 = 0.125)、Mixup(α = 0.3、ターゲットではなく条件付き入力に適用)、RandAugment(デフォルトのパラメータを使用)など、さまざまなデータ拡張手法を適用しました。
学習にはAdamW最適化器(β1 = 0.9、β2 = 0.999、ϵ = 10⁻⁸、重み減衰0.01)、混合精度学習(fp16)、指数移動平均(0.9999)を使用しました。すべての画像は360 × 360ピクセルに均一にリサイズされました。
推論フェーズでは、学習フェーズと同じデータ拡張手法を適用しましたが、Mixupは除外しました。白血球は通常画像の中心に位置するという事実を利用し、画像エッジ領域の拡張による干渉を低減するため、潜在空間において画像中心から半径20ピクセル以内の範囲のみで推論誤差を計算しました。潜在空間の次元は45×45×4でした。
結果のショーケース: CytoDiffusion は、臨床展開における主要な課題の解決に役立ちます。
画像生成と真正性検証
人工知能システムの臨床応用には、高い性能だけでなく、モデルが信頼性の高い表現能力を備えていることが求められます。CytoDiffusionがアーティファクトなどの「近道」に頼ることなく、血液細胞の真の形態分布を学習できることを示すため、研究者らはリアリズムテストを実施しました。
32,619枚の学習画像に基づいて、CytoDiffusionによって生成された血球画像は、実画像と実質的に区別がつかないほど鮮明です。10人の血液専門医が2,880枚の画像を用いて識別テストを実施した結果、総合精度は0.523(ランダム推測レベル)、感度は0.558、特異度は0.489でした。この性能はランダム推測に近い値であり、経験豊富な専門家であっても、CytoDiffusionによって生成された血球画像は実画像と実質的に区別がつかないことを示しています。
実際の画像とほとんど区別がつかない画像を生成できるということは、下の図に示すように、CytoDiffusion が血液細胞の形態の真の分布を正常に学習したことを示しています。
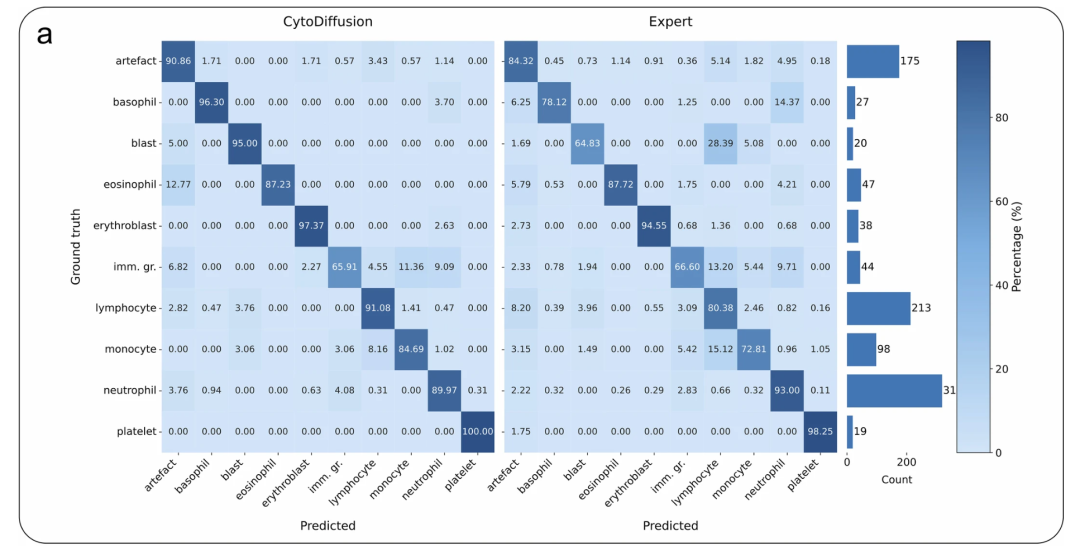
CytoData の比較: 左のマトリックスは CytoDiffusion の結果を示し、右のマトリックスは人間の専門家の平均的なパフォーマンスを示しています。
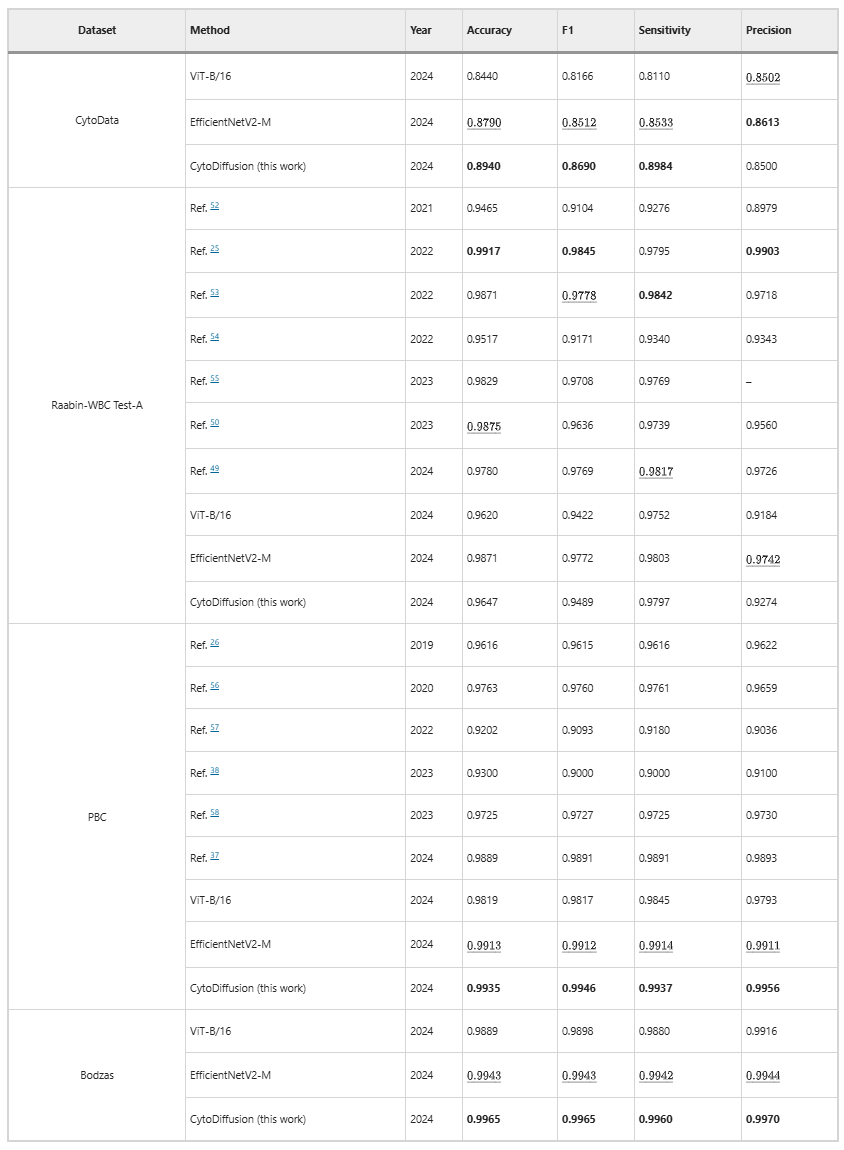
分類性能
CytoDiffusionは、4つのデータセット(CytoData、Raabin-WBC、PBC、Bodzas)において、従来の識別モデルと同等以上の性能を発揮しました。特にCytoData、PBC、Bodzasにおいて、このモデルは最先端の性能を達成しており、拡散ベースの手法が従来の識別モデルと同等かそれ以上の性能を発揮できることを実証しています(下表参照)。
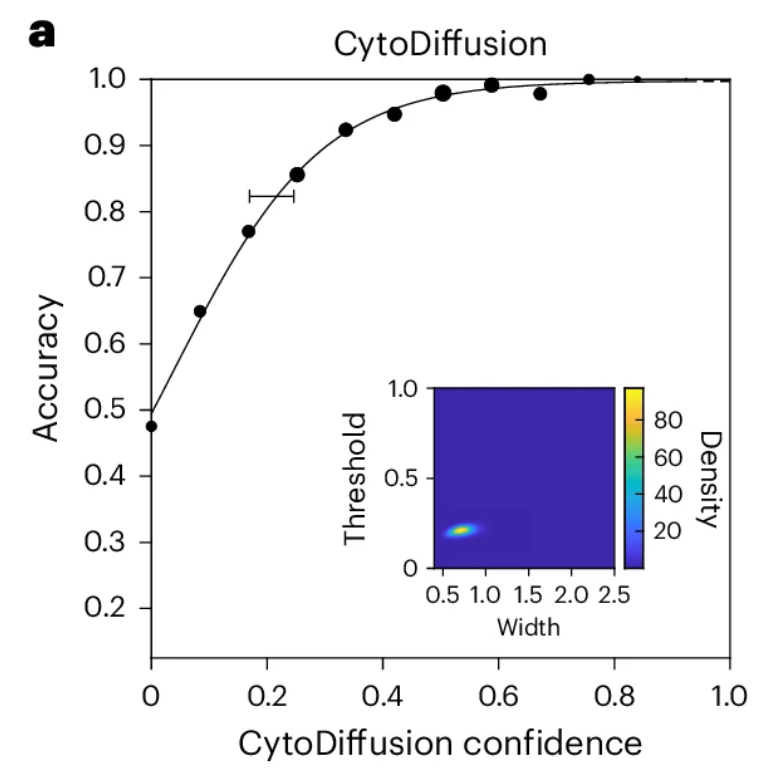
不確実性の定量化は人間の専門家よりも優れている
生物系は本質的に、排除不可能な不確実性を有しています。あらゆる分析タスクにおいて、測定は予測の精度だけでなく、行為者(人間か機械かを問わず)の不確実性にも焦点を当てるべきです。
研究者は、以下の図に示すように、確立されたベイズ心理測定モデリング手法を使用して、CytoDiffusion の心理測定機能を導き出しました。結果は、モデルが非常によく適合しており、主要なしきい値と幅のパラメータの事後分布が非常にコンパクトであることを示しています (下の図の埋め込まれた座標軸)。直接測定することはできませんが、これらの結果は、CytoDiffusion の不確実性は主に偶然の要素によって支配されており、その動作は理想的な観察者の動作に非常に似ていることを示唆しています。
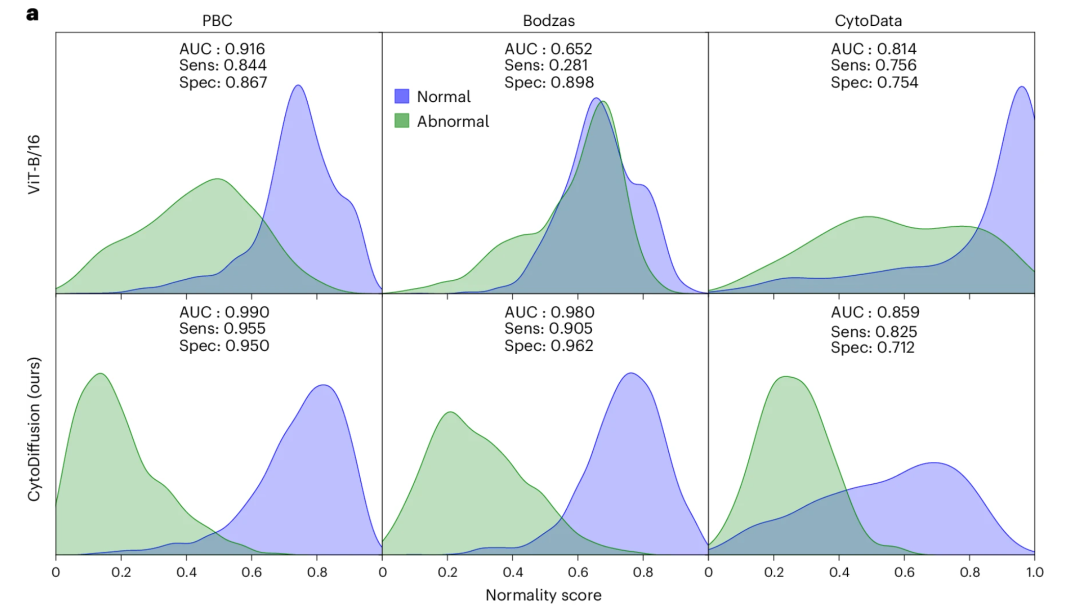
低データ環境における異常セル検出とパフォーマンス
CytoDiffusionは、Bodzasデータセットにおいて原始細胞を異常カテゴリーとして用いた場合、異常細胞検出において高い感度(0.905)と高い特異度(0.962)を達成しました。対照的に、ViTは感度が非常に低く(0.281)、下図に示すように臨床応用のニーズを明らかに満たしていません。
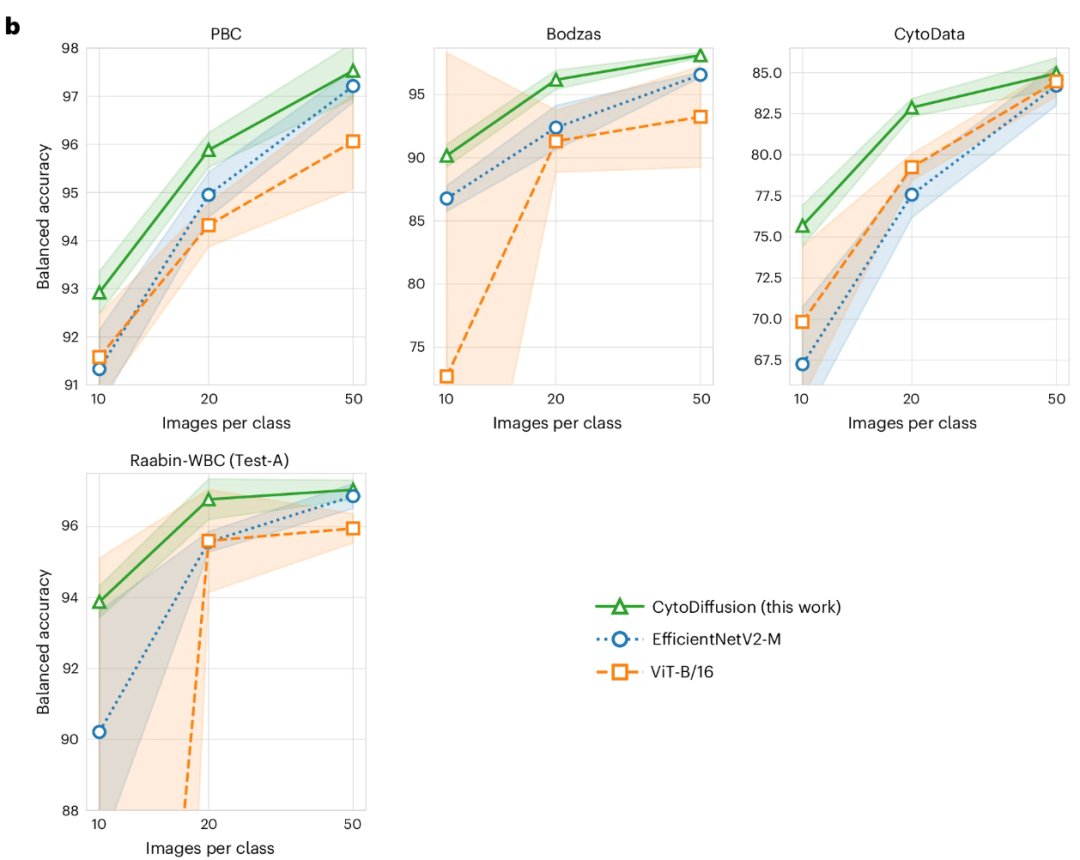
データの少ない環境では、クラスごとにトレーニング画像が 10 ~ 50 枚しかない場合でも、CytoDiffusion は EfficientNetV2-M や ViT-B/16 を大幅に上回り、データが少ない状況でも効率的な学習能力を発揮します (下の図を参照)。
モデルの一般化能力
モデルの汎化能力を評価するため、研究者らは様々なデータ領域でその性能をテストしました。Raabin-WBCでトレーニングしたモデルは、Test-B(異なる顕微鏡とカメラを使用)およびLISC(異なる顕微鏡、カメラ、染色法を使用)データセットでテストされました。CytoDataでトレーニングしたモデルは、PBCとBodzasでテストされました。CytoDiffusionは、4つのデータセットすべてで最高水準の精度を達成しました。さまざまなレベルのドメインドリフトにわたるこの一貫性の利点は、CytoDiffusion がデータセットの変化に対して堅牢であり、実際の臨床シナリオで優れた一般化能力を備えていることを示しています。
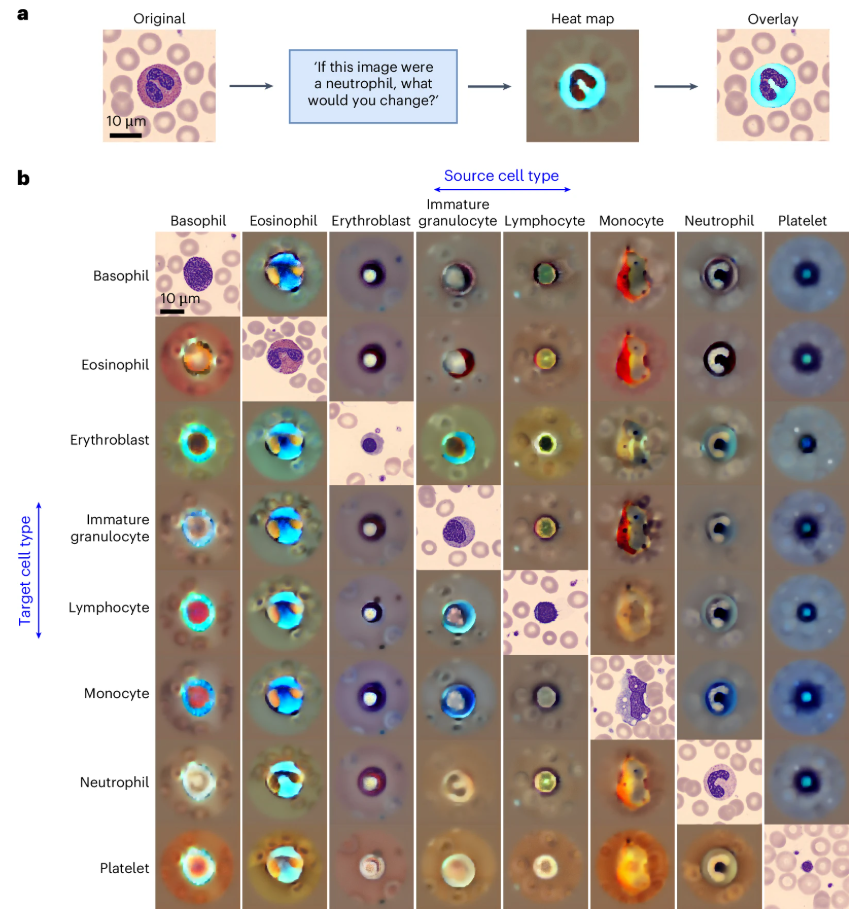
説明可能性の検証
反事実ヒートマップ分析により、モデルは細胞内の主要な形態学的特徴を特定できます(下図参照)。例えば、単球から未熟顆粒球への移行において、モデルは細胞質の酸性度と空胞充填特性の違いを強調しています。この可視化は、モデルの学習能力を検証するだけでなく、潜在的なバイアスを検出し、分類基準が臨床科学的ロジックと整合していることを保証するためにも使用できます。
拡散モデルはバイオメディカル分野で画期的なものであることが証明されています。
CytoDiffusion の研究は、血液細胞の形態分類における拡散モデルの可能性を実証するだけでなく、生物医学分野全体における拡散ベースの生成フレームワークの急速な台頭を反映し、複数のアプリケーション シナリオで画期的な価値を示しています。
例えば、医療データは限定的であることが多く、プライバシーに関する重大な懸念があるため、データの取得とアノテーションは大きな課題となります。拡散モデルは、合成医療画像を生成することでこの問題に対処できます。これにより、ディープラーニング モデルのトレーニングが容易になり、医用画像分析の精度が向上します。通常の医療画像の生成に加えて、拡張...分散モデルは、特定の状態(腫瘍、骨折など)の医療画像を生成するためにも使用できます。これは医療診断モデルの学習において特に重要であり、希少疾患や入手困難な画像に対して、より多くの学習サンプルを提供できるからです。同時に、拡散モデルは高品質で鮮明かつリアルな画像を生成するため、医師の診断精度を向上させるだけでなく、医療AIシステムによるより正確な予測にも役立ちます。
多くの臨床および研究の現場において、高品質な医療画像データセットの不足が、臨床応用における人工知能(AI)の潜在能力を阻害しています。2024年12月、温州医科大学付属眼科病院の張康教授と賈曲教授、北京大学の王金卓研究員が責任著者となり、北京大学の王凱博士と中山大学中山記念病院の于雲芳博士が共同筆頭著者となりました。拡散モデルに基づく新しいフレームワークMINIMが開発されました。このモデルは、テキストコマンドに基づいて、様々な臓器の様々な画像モダリティの医用画像を生成できます。臨床医による評価と厳格な客観的測定により、MINIMが生成した画像の高品質が実証されました。前例のないデータ領域に直面した際にも、MINIMは強化された生成能力を発揮し、汎用医療AI(GMAI)としての可能性を示しました。
論文のタイトル:合成医用画像生成と臨床応用のための自己改善型生成基盤モデル
用紙のアドレス:https://www.nature.com/articles/s41591-024-03359-y
細胞生物学研究において、生細胞は化学平衡からかけ離れた複雑な散逸系です。外部刺激に対する細胞集団の反応は、科学者が常に解明しようと努めてきた核心的な科学的課題です。2025年11月コロンビア大学、スタンフォード大学、その他の機関の研究チームが Squidiff 計算フレームワークを開発しました。このフレームワークは、条件付きノイズ除去拡散暗黙モデルに基づいて構築されており、分化誘導、遺伝子撹乱、薬物処理下における様々な細胞種のトランスクリプトーム応答を予測できます。その主な利点は、遺伝子編集ツールと薬物化合物からの明示的な情報を統合できることです。幹細胞分化の予測において、過渡的な細胞状態を正確に捉えるだけでなく、非相加的な遺伝子撹乱効果と細胞特異的な応答特性を特定できます。研究チームはさらに、Squidiffを血管オルガノイド研究に適用し、様々な細胞種への放射線曝露の影響を予測し、放射線防護薬の防御効果を評価することに成功しました。
論文のタイトル:Squidiff: 拡散モデルを用いた細胞発達と摂動への応答の予測
用紙のアドレス:https://www.nature.com/articles/s41592-025-02877-y
医療分野で生成基本モデルがさらに成熟するにつれて、拡散モデルはより実際の臨床シナリオに実装され、一般的な医療インテリジェンスの重要な基盤となり、将来の医療画像診断、病気の予測、インテリジェントな意思決定のためのより高い信頼性、より強力な一般化能力、より広い応用空間をもたらすことが予測されます。
参考文献:
1.https://www.nature.com/articles/s42256-025-01122-7
2.https://www.nature.com/articles/s41592-025-02877-y
3.https://mp.weixin.qq.com/s/9JEt-QwFxngv9XC0hSIcnw
4.https://bbs.huaweicloud.com/blogs/448218








