Command Palette
Search for a command to run...
スタンフォード大学、北京大学、UCL、カリフォルニア大学バークレー校は協力し、CNN を使用して 810,000 個のクエーサーから 7 つの希少なレンズ状サンプルを正確に識別しました。

1915年に提唱されたアインシュタインの画期的な一般相対性理論は、質量が重力を生み出すだけでなく、周囲の時空を歪ませ、光と物質の運動が曲がった時空経路をたどることを明らかにしました。そのため、質量の大きい天体は天然のレンズのように作用し、近くを通過する光線を屈折させます。
現代天文学において、強い重力レンズは宇宙の大規模構造やブラックホールと銀河の共進化を研究するための重要なツールです。強い重力レンズとして作用するクエーサーは、超大質量ブラックホールとその母銀河間のスケール関係(特にMBH-Mhost関係)の赤方偏移による進化を研究する極めて稀な観測機会を提供します。この強力なプローブを用いることで、アインシュタイン半径θEから母銀河の質量を正確に推定することができます。しかし、クエーサーは非常に珍しく、その特定は天文学者にとって常に大きな課題でした。スローン デジタル スカイ サーベイ (SDSS) でカタログ化された約 30 万個のクエーサーのうち、候補として見つかったのはわずか 12 個で、最終的に確認されたのは 3 個だけでした。
このような背景から、スタンフォード大学、SLAC国立加速器研究所、北京大学、イタリア国立天体物理学研究所ブレラ天文台、ユニバーシティ・カレッジ・ロンドン、カリフォルニア大学バークレー校など、数多くの研究機関からなるチームが、革新的な機械学習手法とダークエネルギー分光計のデータを活用して、もともと小さかったこのサンプルを大幅に拡大しました。
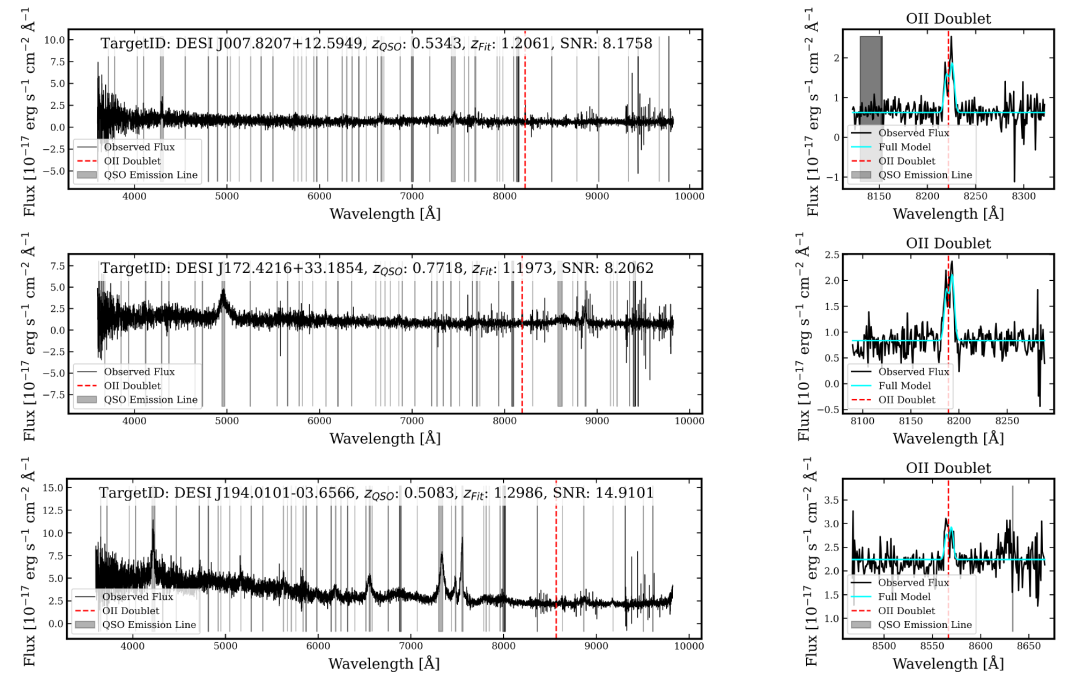
研究チームは、DESI DR1 のスペクトルデータ内で強力な重力レンズ効果の役割を果たすクエーサーを識別するためのデータ駆動型ワークフローを開発しました。赤方偏移の適用範囲は0.03 ≤ z ≤ 1.8です。この手法では、実際のDESI QSOスペクトルとELGスペクトルから構築された現実的な模擬レンズで学習させた畳み込みニューラルネットワーク(CNN)を利用します。このプロセスを適用することで、研究者らは7つの高品質(グレードA)クエーサーレンズ候補を特定しました。これらの候補はすべて、前景クエーサーの赤方偏移を超える強い[OII]二重線放射を示し、そのうち4つの候補はHβ、[OIII]λ4959Å、[OIII]λ5007Åの輝線も示しています。
注: DESI DR1 は、ダークエネルギー スペクトル サーベイ (DESI) によってリリースされた分光サーベイ データの最初のバッチです。
「DESI DR1 で強力なレンズとして機能するクエーサーが発見」と題された関連する研究結果が、arXiv で印刷物として公開されました。
研究のハイライト:
* 以前の研究で特定されたクエーサーレンズのサンプルを拡大しました (候補は 12 個のみ、そのうち 3 個は確認済み)。
* これにより、QSO の強いレンズ効果の最初の統計サンプルを確立する道が開かれ、このようなまれなシステムを大規模に識別するためのデータ駆動型方法の可能性が実証されました。
得られたサンプルは、宇宙の時間全体にわたる質量の直接測定を通じてスケールの関係を固定し、ブラックホールと銀河の共進化を研究するための強力な新しい手段を提供します。
用紙のアドレス:
https://arxiv.org/abs/2511.02009
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「quasar」と返信すると、完全な PDF を入手できます。
AIフロンティアに関するその他の論文:
https://hyper.ai/papers
データセット: DESI DR1から選択された812,118個のクエーサー
最初の DESI データ リリースでは、広範囲の赤方偏移をカバーする約 180 万個のクエーサー スペクトルが提供されます。この研究では、DESI DR1 メイン調査の HEALPixel 赤方偏移カタログに基づいて 812,118 個のクエーサーを選択し、青色カメラのノイズの増加による月光のスペクトルへの影響 (「明時間」手順) を回避するために「暗時間」手順を採用しました。
研究者らは、Redrockから提供された情報を使用しました。Redrockの出力には、クエーサーのTARGETID、赤方偏移(z)、赤方偏移誤差(Guy et al. 2023)が含まれています。この情報に基づき、OBJTYPE = TGTかつZCAT PRIMARY = 1の天体のみを選択し、優勢ではない、または赤方偏移に適合しない天空のターゲットとスペクトルを除外しました。最後に、ZWARN = 0かつSPECTYPE = QSOの天体をさらにフィルタリングし、クエーサーとして分類される可能性はあるもののスペクトル分類が異なる天体を除外しました。このフィルタリング方法により、赤方偏移の精度が確保され、赤方偏移計算に異常のないクエーサースペクトルのみからトレーニングサンプルが取得されることが保証されました。
クエーサーを選択した後研究者らは FastSpec カタログを使用して輝線銀河 (ELG) のサンプルを構築しました。このステップは、シミュレートされたレンズの構築に不可欠です。このカタログは、DESI天体のスペクトル情報(輝線フラックス、赤方偏移、分類など)を提供する軽量処理パイプラインであるFastSpecFit1に基づいています。FastSpecFitはテンプレートを用いて特定のパラメータとスペクトルモデルをフィッティングし、ノイズのないスペクトルを構築します。研究者たちはまず、クエーサーと同じ手法と赤方偏移範囲を用いて、SPECTYPE = GALAXYとしてELGを選択しました。この選別により16,500個の輝線銀河が抽出されましたが、選択された輝線がデータノイズレベルを超えていることを保証するため、メインサーベイOII 3726のフラックスが2 × 10^-17 erg cm^-2 s^-1を超えるELGのみが保持されました。
トレーニングセットには、あらゆる天体物理学的ノイズと機器ノイズを網羅するため、実世界の観測データが使用されました。しかし、同じデータバッチをトレーニングと実際のレンズ探索の両方に同時に使用することはできませんでした。そのため、データセットは2つのフェーズに分割され、フェーズ1では812,118個の天体のうち47%が使用され、残りはフェーズ2で使用されました。
ステージ 1:
* トレーニングサンプル:分類ネットワークと赤方偏移予測ネットワークは、フェーズ 1 のトレーニング サンプルの 384,873 個のクエーサーからの 70% を使用してトレーニングされました。
* 検証サンプル:フェーズ 1: トレーニング サンプルの残りの 30% は、トレーニング中にモデルのパフォーマンスを検証するために使用されます。
* ブラインドサンプル:ブラインドサンプルは、トレーニング、検証、テストに使用されなかった427,245個のクエーサーで構成されています。トレーニングが完了した後、このデータセットから実際のレンズが検索されます。
* テストサンプル:テストでは、フェーズ1のブラインドサンプルから3,170個のクエーサーが使用され、そのうち10%に対してシミュレーションによるレンズ系が構築されました。このテストサンプルは、ハイパーパラメータ最適化後のネットワーク性能を評価するために使用されました。
ステージ 2:
フェーズ 2 では、トレーニング サンプルとブラインド サンプルが交換され、同じプロセスが繰り返されます。
* トレーニングサンプル:CNN は、フェーズ 1 のブラインド サンプルで 427,245 個のクエーサーから取得した 70% サンプルを使用してトレーニングされました。
* 検証サンプル:検証に使用された 427,245 サンプルのうち 30% サンプルが採用されました。
* ブラインドサンプル:ブラインド サンプルは、トレーニング、検証、テストに使用されなかった 384,873 個のクエーサーで構成されています。
* テストサンプル:フェーズ2のテストでは、フェーズ2のブラインドサンプルから3,547個のクエーサーが使用されました。これらのサンプルは、トレーニング用および検証用のサブセットとは独立していました。そのうち、10%クエーサーは、シミュレートされたレンズ系の構築に使用されました。
シミュレートされたレンズ システムとクエーサーのレンズなしスペクトルで CNN をトレーニングします。
強力な重力レンズ天体として機能するクエーサーを正確に識別できるモデルを構築します。重要なのは、ラベル付けされたデータセットを使用してモデルをトレーニングし、レンズとして機能するクエーサー スペクトルの特徴と非レンズ クエーサー スペクトルの特徴を区別できるようにすることです。次の図は、完全なトレーニング プロセスを示しています。
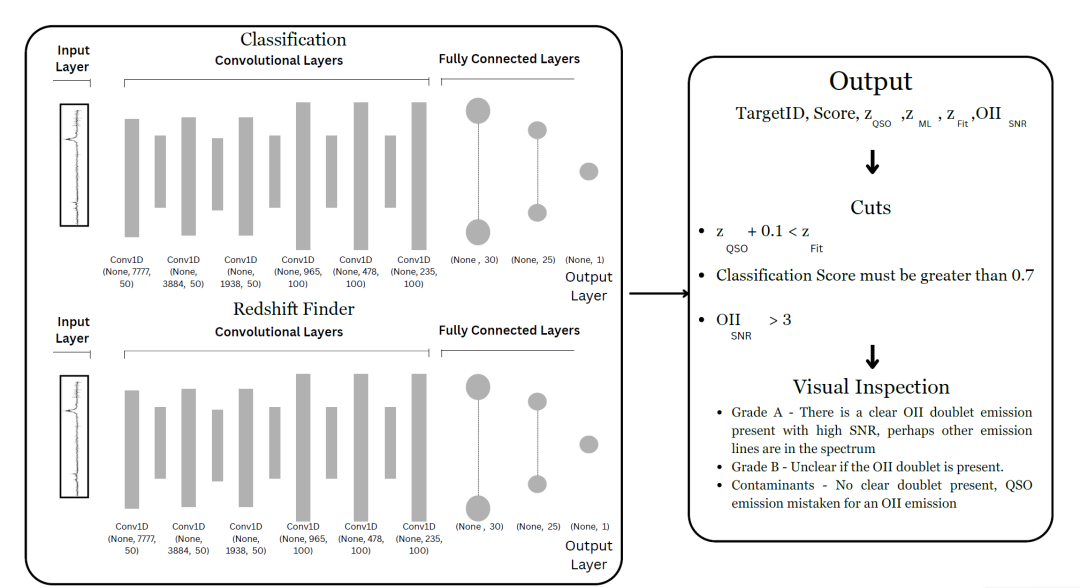
研究者らは、DESIによって観測されたクエーサー(QSO)と輝線銀河(ELG)のスペクトルを用いて、畳み込みニューラルネットワーク(CNN)を、シミュレートされたレンズ効果システム(正サンプル)とレンズ効果を受けていないクエーサースペクトル(負サンプル)で学習させた。学習セットにおける正サンプルと負サンプルの比率は、10%対90%であった。
① トレーニングセットの構築とシミュレートされたレンズシステム
シミュレーションスペクトルはQSOやELGのトレーニングセットを生成するために使用できますが、ただし、この研究は DESI スペクトルの固有の特性を維持することを目的としています。これらの特性は、観測機器、観測条件、あるいは天体自体によって引き起こされます。様々な理由(スペクトル線の広がり、光度差など)により、QSOとELGの[OII]スペクトル線は高い多様性を示します。そのため、研究者たちはDR1から得られた観測データを直接ニューラルネットワークの学習に用い、QSOとELGの全体的なサーベイ特性を一致させるように構築しました。
しかし、強力なレンズとして機能するQSOは非常に稀です。SDSSデータセットでは、297,301個のクエーサーのうち12個のみが候補となり、本研究で検討した赤方偏移範囲内ではDESI DR1データセットには1個しか含まれていません。したがって、本研究における正のサンプル、すなわちQSOレンズは…実際の QSO のスペクトルと高赤方偏移 ELG のスペクトルを重ね合わせることで、十分な数の正と負のサンプルを含むトレーニング セットを構築する必要があります。
② CNN分類器のトレーニングとアーキテクチャ
分類器ネットワークは、6つの畳み込み層(最初の3層に50個のフィルター、最後の3層に100個のフィルター)と2つの全結合層(それぞれ30ノードと25ノード)で構成されています。畳み込み層は、クエーサーやELGスペクトルの輝線など、スペクトル内の局所的な特徴を抽出し、最終的に0から1までのスコアを出力します。学習中は閾値0.5が設定され、予測スコアが0.5以上のサンプルがレンズ候補として識別されます。最後に、ブラインドサンプルに適用する際には、F1スコアを最大化するために閾値を0.7に最適化します。
CNNアーキテクチャは6つの畳み込み層で構成されています。最初の3層はそれぞれ50個のフィルターを持ち、最後の3層はそれぞれ100個のフィルターを持ちます。上図の左側に示すように、最初の完全結合層は30個のノードを持ち、2番目の層は25個のノードを持ちます。ネットワークは0から1の間のスコアを出力します。学習中、研究者は閾値を0.5に設定し、予測スコアが0.5以上のサンプルはすべて、ニューラルネットワークによってレンズとして識別されました。
トレーニング中は、Adamオプティマイザーを用いて指数関数的学習率減衰を適用し、500ステップごとに学習率を0.95倍に減少させました。トレーニングはTensorFlowを用いて行われ、トレーニングセットの分割、混同行列の計算、およびメトリックの計算にはscikit-learnが使用されました。
その後、研究者らはフェーズ 1 とフェーズ 2 のトレーニング サンプルをそれぞれ使用して 2 つの CNN をトレーニングしました。フェーズ 1 でトレーニングされた CNN はフェーズ 1 のブラインド サンプルに使用され、フェーズ 2 でトレーニングされた CNN はフェーズ 2 のブラインド サンプルに使用されます。トレーニング後、モデルはテストサンプルにおける分類性能を評価し、真陽性(TP)、偽陽性(FP)、偽陰性(FN)を合計したF1スコアに基づいて閾値を調整します。両段階における最高のF1スコアは、閾値0.7に相当します。
最後に、各ネットワークをブラインド サンプル (モデルでは確認できない観測クエーサー) に適用して、レンズ候補の最初のリストを生成します。
③ 赤方偏移予測
クエーサースペクトルにおける前景QSOの赤方偏移は測定が容易ですが、背景ELGの赤方偏移を直接取得することは困難です。研究チームは、以下の2つの方法を用いて性能を比較しました。
* レッドロック:スペクトルは PCA テンプレートを使用してフィッティングされ、χ² を最小化するためにグリッド検索が実行されました。
* Redshift CNN回帰モデル:分類器と同様の CNN 構造を採用していますが、出力は連続的な赤方偏移値であり、平均二乗誤差 (MSE) によってトレーニングされます。
研究チームは、CNN による赤方偏移予測を基に、Δz = 0.1 の範囲内で [OII] 双曲線に対して局所的な二重ガウスフィッティングを実行し、同時に信号対雑音比 (SNR) を計算して高品質の候補を選別することで、赤方偏移予測をさらに改良しました。
成果紹介:強力なレンズの候補となる天体を7つ発見
① CNN分類器のパフォーマンス:トレーニングセットと検証セットの両方で優れたパフォーマンス。
フェーズ 1 とフェーズ 2 のトレーニング セットと検証セットに適用された CNN 分類器のパフォーマンス メトリックを次の表に示します。
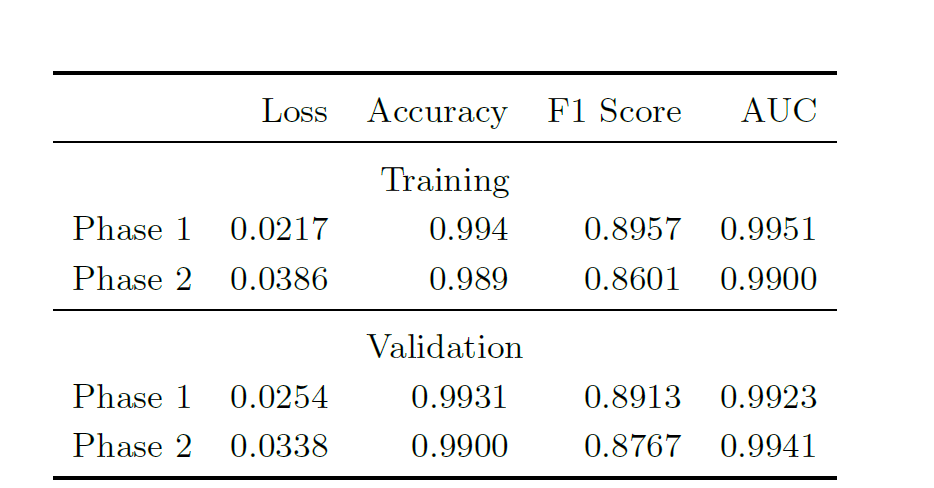
結果は、CNN 分類器がトレーニング セットと検証セットの両方で優れたパフォーマンスを発揮し、F1 スコアと AUC メトリックの両方がモデルが精度と再現率を効果的にバランスできることを示しています。
② 赤方偏移測定性能:すべての SNR 範囲にわたって、CNN 赤方偏移測定装置は Redrock 装置よりも大幅に優れています。
試験サンプルでは、研究者らは、高赤方偏移ELGの信号対雑音比(SNR)で各天体を分類し、[OII]放射特性の異なるSNR範囲にわたるCNNとRedrockのパフォーマンスを観察した。彼らは、パーセンタイルに基づいてサンプルを3つのグループに分けました。低SNR(3 ≤ SNR < 7.52)、中SNR(7.52 ≤ SNR < 16.63)、高SNR(SNR ≥ 16.63)です。
結果は次のとおりです。
* 高SNR:CNN は Δz = 0.1 以内で 100% のソース赤方偏移を回復しました。これは、ガウス フィッティング後は 99.48%、Redrock 後は 51.04% でした。
* 中国のSNR:CNN の TP3T は 99.481、ガウスフィットの TP3T は 1001、Redrock の TP3T は 37.701 です。
* 低SNR:CNN の TP3T は 100.001、ガウス フィットの TP3T は 96.881、Redrock フィットの TP3T は 29.171 です。
要約すれば、すべての SNR 範囲において、ガウス フィッティングと組み合わせた CNN 赤方偏移測定は、背景 ELG 赤方偏移の回復において Redrock を大幅に上回りました。赤外線チャンネルに顕著なスカイラインや残留ノイズ(マスク使用時も)があっても、CNNは標準的なRedrockアプローチよりも優れた性能を発揮します。ガウスフィッティングは中程度のSNR範囲ではほぼ正確な精度を実現しますが、非常に低いSNRでは性能が低下し、純粋なCNN手法の方が優れています。
③ ブラインドサンプルへの適用:クラスAの高優先度レンズ候補7個の特定
学習済みのCNNを812,118個のクエーサースペクトルに適用した結果、合計494個の候補が選出されました。SNRと赤方偏移情報を組み合わせた手作業による目視検査の結果、最終的に7個の高優先度(グレードA)レンズ候補が確定しました(下表参照)。
下の図に示すように、クラス A 候補の 7 つすべてが、QSO よりも高い赤方偏移で強い [OII] 二重線を示しているように見えます。また、これらの候補のうち 4 つは、同じ赤方偏移で [OIII] λ 4959˚A と Hβ 線も示しています。
ディープラーニングは天文学研究のパラダイムを変革しています。
過去10年間、AI、特にディープラーニングは天文学の研究パラダイムを急速に変革してきました。データの取得と特徴抽出から科学的発見のプロセスに至るまで、天文学におけるAIの役割は「補助的なツール」から最先端のブレークスルーを推進する中核的な原動力へと進化しました。その根本的な理由は以下のとおりです。天文学は前例のないデータ爆発の時代を迎えています。
大規模な天文観測(DESI、LSST、ユークリッドなど)は、年間数ペタバイト規模のデータを生み出し、従来の手作業による解析や古典的アルゴリズムの処理能力をはるかに超えています。ディープラーニングモデルは、膨大な観測データから複雑なパターンを自動的に抽出することに優れており、スペクトルデータ、画像データ、時系列データの処理に最適です。
代表的なものとして2025年11月、カリフォルニア大学バークレー校、ケンブリッジ大学、オックスフォード大学など、世界中の10以上の研究機関のチームが共同で…を立ち上げました。AION-1: 天文学のための最初の大規模マルチモーダル基礎モデルファミリー(天文オムニモーダルネットワーク)AION-1は、画像、スペクトル、星カタログデータといった異種の観測情報を統合・モデル化することで、統合型初期核融合バックボーンネットワークを構築し、ゼロショットシナリオにおいて優れた性能を発揮するだけでなく、特定のタスク向けに特別に訓練されたモデルに匹敵する線形検出精度を実現します。データの異種性、ノイズ、機器の多様性といった主要な課題に体系的に対処することで、AION-1は天文学をはじめとする科学分野において実現可能なマルチモーダルモデリングパラダイムを提供します。
論文のタイトル:AION-1: 天文学科学のためのオムニモーダル基礎モデル
用紙のアドレス:https://openreview.net/forum?id=6gJ2ZykQ5W
天体分類の分野では、ディープラーニングがスターテクノロジーとなっています。銀河の形態分類、超新星の識別、強い重力レンズ効果の探索など、CNN と Transformer の両方のアーキテクチャは、高次元の非構造化データ内の物理プロセスに関連する主要な特徴を見つけることができ、手動の方法をはるかに上回る速度と一貫性を実現します。
例えば、中国科学院雲南天文台の馮海成博士率いる研究チームは、鄭州大学の李睿博士とイタリアのナポリ・フェデリコ2世大学のニコラ・R・ナポリターノ教授と共同で、天体形態の特徴とSED情報を革新的に統合し、恒星、クエーサー、銀河などの天体の高精度自動識別を実現するマルチモーダルニューラルネットワークモデルが提案されました。この手法は、欧州南天天文台(ESO)のKiDSプロジェクトの第5回データリリースにおいて、1,350平方度の天空領域に適用され、23等級より明るいRバンド天体2,700万個以上の分類を完了しました。
論文のタイトル:ニューラルネットワークに基づくKiDS DR5源の形態光学的分類:包括的な星・クエーサー・銀河カタログ
用紙のアドレス:https://iopscience.iop.org/article/10.3847/1538-4365/adde5a
全体的に、AI は単に従来の天文学的手法に取って代わるものではなく、科学研究パラダイムのアップグレードを継続的に推進しています。つまり、天文学者を面倒なデータ処理から解放して基本的な物理的問題に集中できるようにし、希少天体が膨大な量のデータに圧倒されることを防ぎ、宇宙の構造と進化をより迅速かつ深く理解できるようにします。
参考文献:
1.https://arxiv.org/abs/2511.02009
2.https://phys.org/news/2025-11-machine-quasars-lenses.html
3.https://www.cpsjournals.cn/data/article/wl/preview/pdf/10.7693/wl20250701.pdf
4.https://mp.weixin.qq.com/s/6zlnE5-fIw21TQeg1QPPnQ
5.https://www.cas.cn/syky/202507/t20250711_5076040.shtml








