Command Palette
Search for a command to run...
Healthcare Agent は医療倫理と安全性の問題を自動的に検出し、そのプロアクティブで適切なコンサルティングは GPT-4 などのクローズドソース モデルを上回ります。

近年、大規模言語モデル(LLM)の医療相談への応用がますます注目を集めています。湖南省湘潭市玉湖区昭潭街道コミュニティ健康サービスセンターでは、家庭医の劉延波氏が、「スマート医療アシスタント」がリアルタイムで生成した投薬推奨と診療記録サマリーに基づき、72歳の糖尿病患者、王桂花氏のフォローアップ診療を行っています。この「AI + ヘルスケア」の応用シナリオは、玉湖区のプライマリヘルスケアサービスの標準的な実践となっています。「スマート医療アシスタント」は、電子カルテの品質を向上させるだけでなく、診断および治療リスクの軽減にも役立っていると報告されています。このプラットフォーム導入以来、地域の診療記録標準化率は96,64%に達し、診断コンプライアンス率は96,66%に上昇しました。
しかし、実際の医療シナリオにおける一般的な LLM の適用は、多くの場合、さまざまな課題に直面します。たとえば、AI モデルは、患者が自分の状態や関連情報を段階的に表現できるように効果的にガイドできないだけでなく、医療倫理や安全性の問題を管理するための必要な戦略や安全策が欠如しており、診察の会話を保存したり、病歴を取得したりすることもできません。
これを受けて、いくつかの研究チームは、医療用LLMをゼロから構築したり、特定のデータセットを用いて汎用LLMを微調整したりすることで、こうした問題を解決しようと試みてきました。しかし、この一度限りのプロセスは計算コストが高いだけでなく、実用的なシナリオに必要な柔軟性と適応性も欠いています。エージェントは再トレーニングなしでタスクを推論して管理可能な部分に分割できるため、複雑なタスクに適したものになります。
この文脈では、武漢大学と南洋理工大学の研究チームは共同で、対話、記憶、処理の3つの要素からなるヘルスケアエージェントを発表しました。このエージェントは、患者の医療目的を特定し、医療倫理や安全性の問題を自動検出することができます。医療従事者が患者の発言の途中で介入できるだけでなく、ユーザーはHealthcare Agentを通じて迅速に診察概要レポートを取得できます。Healthcare Agentは、医療診察におけるLLMの機能を大幅に拡張し、医療分野におけるLLMの応用に新たなパラダイムを提供します。
関連する研究成果は、「ヘルスケアエージェント:医療相談のための大規模言語モデルの力を引き出す」というタイトルで『Nature Artificial Intelligence』に掲載されました。
研究のハイライト:
* 対話、記憶、処理という 3 つの主要コンポーネントを提案します。これにより、トレーニングなしで LLM の医療相談機能を強化し、マルチタスクと安全な対話をサポートします。
* 「議論と修正」戦略を通じて倫理的、緊急、エラーのリスクを検出するための安全性と倫理の保証メカニズムを構築します。
* 現在の会話のメモリと過去の診察要約を組み合わせることで、情報の重複を避け、診察の継続性と個別ケアの効率性を向上させます。
* ChatGPT を使用して仮想患者をシミュレートし、自動評価システムを開発して、実際のデータに基づいてモデルを効率的にテストし、手動による評価コストを削減します。
用紙のアドレス:
https://go.hyper.ai/09lYX
公式アカウントをフォローし、「ヘルスケアエージェント」と返信すると、完全なPDFを入手できます。
AIフロンティアに関するその他の論文:
データセットから高品質のサンプルをスクリーニングし、実際の会話に基づいて患者のポートレートを作成します。
この研究ではMedDHealthcare Agent を構築および評価するための ialog データセット。研究者らは、データセットから40回以上の会話を含むサンプルを選択し、これらの実際の会話に基づいて患者のビネットを作成しました。MedDialogデータセットは、腫瘍学、精神医学、耳鼻咽喉科など20の異なる医療専門分野にわたる、実際の医師と患者の会話の大規模なコレクションを網羅しており、多様で包括的な実験環境を確保しています。データセットは、3つの主要な要素で構成されています。* 患者の状態に関する基本的な説明、* 複数回の医師と患者の会話の完全な記録、* 医療スタッフによる最終的な診断と治療の推奨。
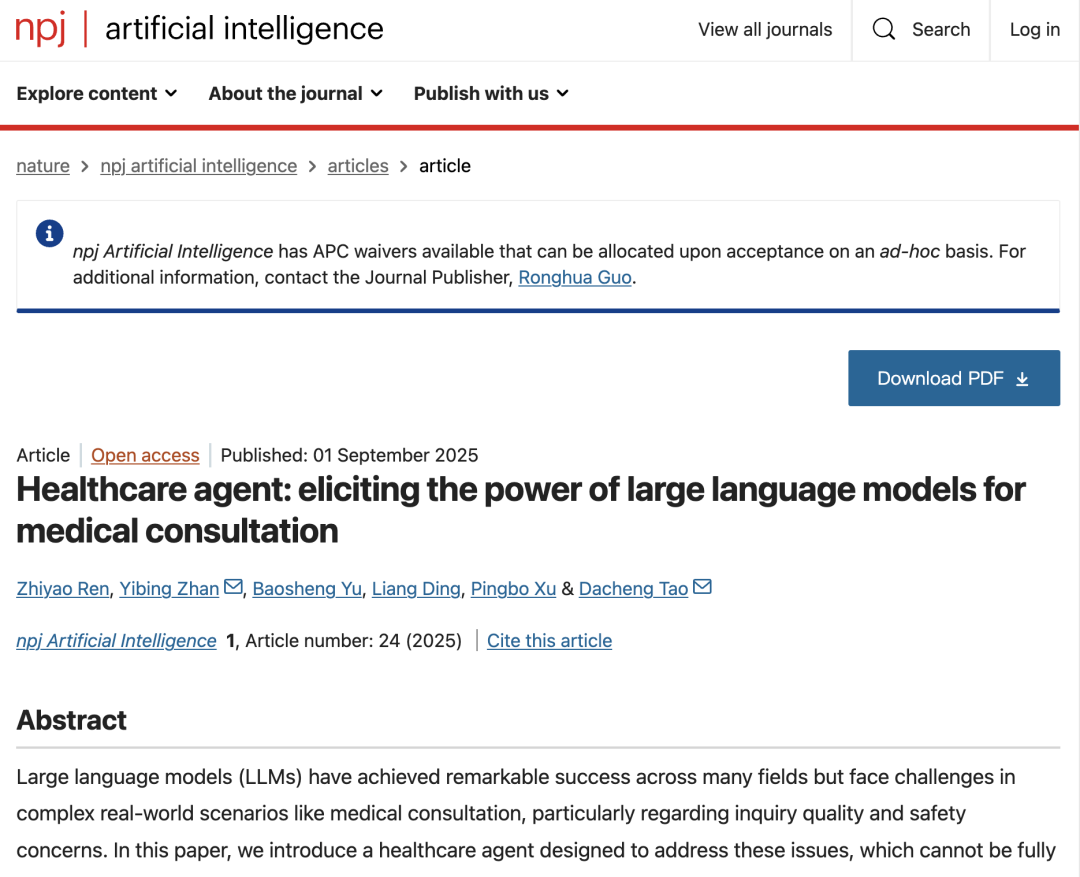
ヘルスケアエージェントのコアコンポーネントとモデルアーキテクチャ
ヘルスケア エージェントのコア アーキテクチャは、ダイアログ、メモリ、処理という 3 つの密接に連携したコンポーネントで構成されています。
* ダイアログコンポーネント:患者とのインタラクションを担当します。内部機能モジュールは、患者の入力に基づいて現在のタスクタイプを自動的に判断します。患者情報が不十分な場合、計画サブモジュールは問診サブモジュールを呼び出し、患者が的確な質問を通じて主要な症状や病歴を補足できるよう支援します。情報収集が完了すると、システムは予備的な診断、病因の説明、または治療の推奨を提供します。
* メモリコンポーネント:会話記憶と履歴記憶で構成され、二層構造に基づいて現在の会話の文脈を完全に記録することで、会話の継続性と個別化を実現します。また、過去の会話から重要な情報を要約形式で保存することで、患者の長期的な状態への理解を深めます。これにより、システムは繰り返しの質問を避け、運用効率を維持できます。
* 処理:LLM を使用して構造化された医療レポートを生成し、会話全体を整理し、状態の説明、診断、説明、フォローアップの提案を含むレポートを作成するなど、診察後の要約とアーカイブを担当し、それによって患者と医師に明確な診察要約と診察要約を提供します。
で、患者と対話するためのコアインターフェースである「ダイアログコンポーネント」には、次の 3 つのサブモジュールが含まれています。* 機能モジュール:プランナーを使用して、診察の意図(診断、説明、推奨など)を動的に識別し、「問い合わせサブモジュール」を駆動して複数回の積極的な質問を実施し、患者がより包括的な情報を提供できるように導きます。
* 安全モジュール:独立した倫理、緊急事態、およびエラー検出メカニズムを通じて、生成された応答は「議論と修正」戦略を使用してレビューおよび修正され、医療規制と安全基準への準拠が確保されます。
* ドクターモジュール:医療専門家が自然言語ガイダンスを通じて直接介入したり、応答を修正したりできるようにすることで、人間と機械のコラボレーションのための監視メカニズムを実現します。
二段階評価プロセス:自動評価と医師評価の二重検証
評価プロセスは、自動評価と医師評価の2段階に分かれています。自動評価ではChatGPTが評価者として使用され、医師評価では7人の医師からなるパネルが診察の対話をレビューし、採点します。評価結果は以下のとおりです。Healthcare Agent は、Claude、GPT4、Gemini などの一般的な LLM と比較して、自己認識、正確性、有用性、有害性が大幅に向上しています。同時に、ヘルスケアエージェントは強力な一般化能力も示しています。
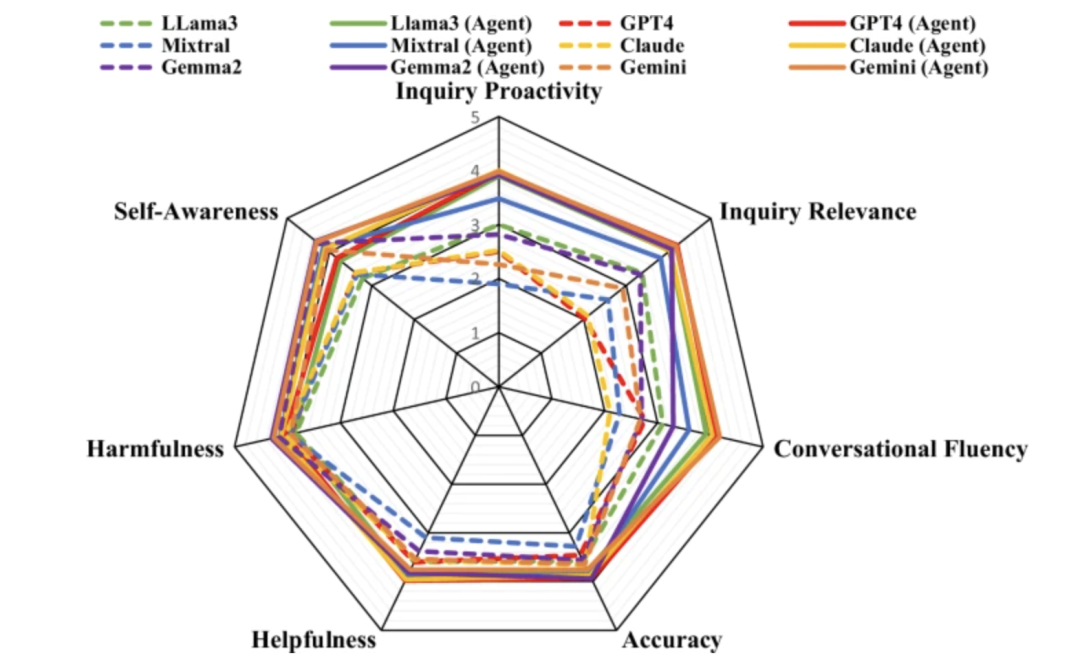
自動評価結果
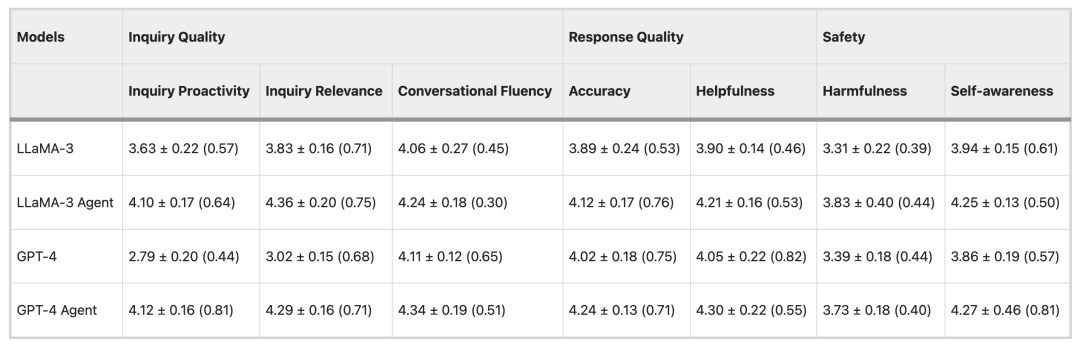
自動評価実験では、研究チームは3つの一般的なオープンソースLLM(LLama-3、Mistral、Gemma-2)と3つのクローズドソースLLM(GPT-4、Claude-3.5、Gemini-1.5)をベースモデルとして使用し、50個のデータを評価しました。
コンサルテーションの質という点では、MixtralやGPT-4などのLLMは通常、積極的に質問するのではなく、直接的な回答を提供する傾向があります。一方、Healthcare Agentのコンサルテーションは、比較的積極的かつ関連性の高いものです。回答の質という点では、Healthcare Agentはオープンソースモデルとクローズドソースモデルのパフォーマンス格差を大幅に縮小します。セキュリティの面では、Healthcare Agentはセキュリティモジュールの倫理、緊急性、エラー検出メカニズムを通じて、回答の有害性を効果的に低減します。
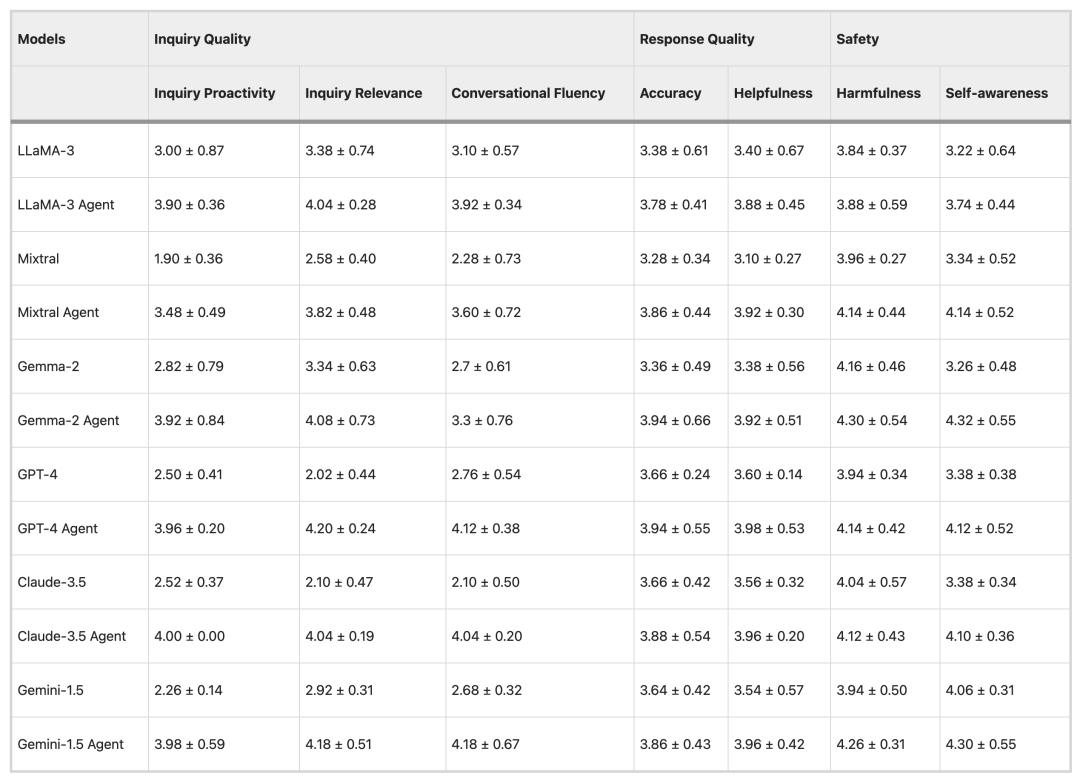
医師の評価結果
自動評価方法の信頼性を検証するために、LLaMA-3とGPT-4モデルを用いて15セットのデータを評価し、その後7人の医師に評価に参加してもらいました。その結果、医師の評価と自動評価の結果の間には高い一貫性があります。会話の流暢さと有害性の2つの指標にはわずかな差があったが、これは自動評価方法の正確性と大規模な臨床評価への応用の可能性を証明した。
医療記録の作成から診察の支援まで、大規模モデルの臨床シナリオへの導入が加速しています。
医療分野における LLM の急速な発展に伴い、研究者や業界は臨床ワークフローや医師と患者のコミュニケーションにおける LLM の応用価値を絶えず探求しています。医師の事務作業の負担を軽減したり、患者の診察や診断の質を向上させたりと、最新の成果は徐々に研究室から実際の臨床シナリオへと移行しつつあります。
これまで、多くの研究チームが医療文書と患者の診察の分野で広範な調査を行ってきました。 マイクロソフト・ニュアンスが開発した人工知能医療記録アシスタント「AI Scribe」は、音声認識と大規模言語モデル技術を使用して、外来診療や病棟回診中の医師と患者の会話を自動的に書き起こし、要約し、標準化された医療記録を生成することで、1回の診察記録にかかる時間を短縮します。この成果は、スタンフォード大学メディカルセンター、マサチューセッツ総合病院、ミシガン大学メディカルセンターなどの主要な医療システムに迅速に導入されています。カリフォルニア大学サンディエゴ校ヘルスセンターでは、医師の返信を作成するためのポータルシステムに大規模な言語モデルを組み込み、共感性とプレゼンテーションの質の両方において対照テキストを上回る返信を作成しました。
さらに、Google DeepMindとGoogle Researchのチームは、インテリジェントな医療相談と鑑別診断を促進するためのAMIE(Articulate Medical Intelligence Explorer)を共同で開発しました。複数の国を対象とした模擬外来診療所を対象としたランダム化横断研究において、研究者らはAMIEの診察実績を一般開業医のそれと比較しました。結果によると、専門医は 32 の評価項目のうち 28 項目で一般開業医より優れていると評価し、AMIE の診断精度も高く、複雑な症例の鑑別診断における AMIE の信頼性が実証されました。
今後、臨床試験が進むにつれて、これらの技術は安全性と信頼性を確保しながら臨床現場の重要なアシスタントとなり、医療サービスの効率と質の同時向上を促進することが期待されます。
参考リンク:
1.https://med.stanford.edu/news/all-news/2024/03/ambient-listening-notes.html
2.https://today.ucsd.edu/story/introducing-dr-chatbot
3.https://research.google/blog/amie-a-research-ai-system-for-diagnostic-medical-reasoning-and-conversations/
4.https://hnrb.hunantoday.cn/hnrb_epaper/html/2025-09/06/content_1753017.htm?div=-1








